










一、引言
近年来,深度学习的迅猛发展推动了人工智能在视觉、自然语言处理等领域的广泛应用。然而,传统监督学习对大规模标注数据的依赖逐渐暴露其局限性:数据标注成本高昂、时间耗费巨大,尤其是在医疗影像、工业检测等专业领域。自监督学习(Self-Supervised Learning, SSL) 应运而生,它通过从数据本身挖掘监督信号,避免了对人工标注的依赖,成为学术界和工业界的研究热点。
在众多自监督学习方法中,DINO(Distillation with No Labels,无标签蒸馏) 以其独特的设计和优异的性能脱颖而出。2021 年由 Facebook AI 团队提出,DINO 不仅在视觉任务中表现出色,还因其简单高效的框架受到广泛关注。本文将从原理到实践,全面解析 DINO 的核心思想,并提供 PyTorch 代码示例,帮助技术爱好者快速上手。
二、什么是 DINO?
DINO 的全称是“Distillation with No Labels”,即“无标签蒸馏”。它是一种自监督学习框架,主要针对视觉任务,通过对未标注图像数据进行表征学习,生成高质量的特征表示。DINO 的设计灵感来源于 知识蒸馏(Knowledge Distillation),但与传统方法不同的是,它不需要一个预训练的教师模型,而是通过“自蒸馏”的方式,让模型在训练过程中自我优化。
论文作者称 DINO 为“视觉中的 BERT”,因为它在 视觉 Transformer(Vision Transformer, ViT) 上的表现尤为突出,能够从图像中提取丰富的语义信息,甚至在某些任务中超越了监督学习模型。DINO 的成功不仅在于其性能,还在于其优雅的理论设计和工程实现的简洁性。
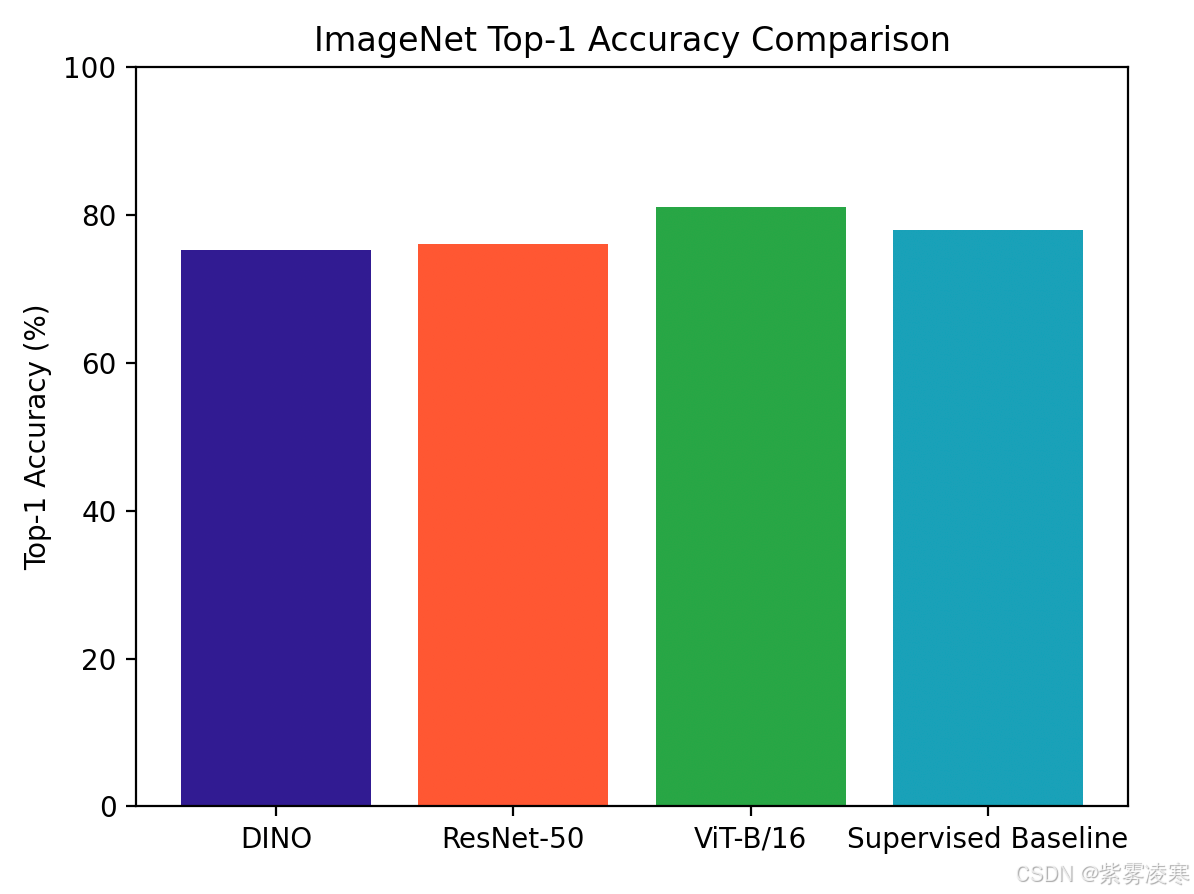
如图为 ImageNet 上的 Top-1 准确率对比,数据来源于Papers with Code
三、DINO 的核心原理
DINO 的成功离不开其精心设计的核心机制。以下从网络结构、数据处理、损失函数和避免表示崩塌的技巧四个方面,详细探讨 DINO 的每一个技术细节。
3.1 学生-教师网络对称结构
DINO 的核心架构由两个网络组成:学生网络 和 教师网络。这两个网络在初始化时共享相同的结构(通常是 ViT),但在训练过程中的更新方式截然不同。
学生网络
学生网络是 DINO 中唯一通过梯度下降更新的部分。它接收输入图像,经过前向传播生成特征表示,并根据损失函数的反向传播调整参数。学生网络的目标是“模仿”教师网络的输出分布,从而学习到鲁棒的表征。
教师网络
教师网络的参数不参与梯度计算,而是通过 指数移动平均(EMA) 从学生网络更新。EMA 的更新公式为:
θ
t
←
λ
θ
t
+
(
1
−
λ
)
θ
s
\theta_t \leftarrow \lambda \theta_t + (1 - \lambda) \theta_s
θt←λθt+(1−λ)θs
其中:
- ( θ t ) ( \theta_t ) (θt)是教师网络的参数;
- ( θ s ) ( \theta_s ) (θs)是学生网络的参数;
- ( λ ) ( \lambda ) (λ)是动量系数,通常取值接近 1 1 1(如 0.996 0.996 0.996)。
这种更新方式使得教师网络的参数变化更加平滑,避免了训练初期的剧烈波动。EMA 的引入是 DINO 的一大创新,它不仅降低了计算成本(无需预训练教师模型),还保证了训练过程的稳定性。
对称设计的动机
为什么采用对称结构?传统知识蒸馏依赖一个强大的预训练教师模型,而 DINO 的目标是完全无监督,因此它必须从零开始构建教师网络。通过让教师网络动态跟随学生网络,DINO 实现了“自教自学”的闭环。这种设计不仅简化了流程,还让模型能够在未标注数据上逐步收敛。
与其他方法的对比
与 SimCLR、MoCo 等自监督方法相比,DINO 的学生-教师结构更接近知识蒸馏的范式,但它无需负样本对或动量编码器,使得内存占用更低,计算效率更高。
3.2 多视角数据增强
DINO 的输入处理是其成功的关键之一。它通过对同一张图像应用多种随机裁剪(multi-crop),生成 全局视角(global view) 和 局部视角(local view),从而让模型从不同尺度学习图像特征。
数据增强的具体实现
- 全局视角:通常是较大的图像裁剪(如 ( 224 × 224 (224 \times 224 (224×224)),覆盖图像的大部分内容,捕捉整体语义。
- 局部视角:较小的裁剪(如 ( 96 × 96 96 \times 96 96×96)),聚焦图像的局部区域,提取细节信息。
例如,对于一张原始图像,DINO 可能会生成 2 个全局视角和 6 个局部视角,总共 8 个增强视图。这种多视角策略源于 BYOL 和 SwAV,但 DINO 进一步优化了裁剪比例和数量。
多视角的数学意义
假设输入图像为 ( x ) ( x ) (x),经过增强后生成视图集合 ( { v 1 , v 2 , … , v n } ) ( \{v_1, v_2, \dots, v_n\} ) ({v1,v2,…,vn})。学生网络对所有视图 ( v i ) ( v_i ) (vi) 进行编码,输出特征 ( z s ( v i ) ) ( z_s(v_i) ) (zs(vi));教师网络仅对全局视角 ( v g ) ( v_g ) (vg) 编码,输出 ( z t ( v g ) ) ( z_t(v_g) ) (zt(vg))。目标是让学生网络的输出与教师网络的输出在分布上一致。这种设计强制模型学习全局与局部之间的语义关联。
为什么多视角有效?
多视角增强的核心在于增加数据的多样性。如果仅使用单一视角,模型可能过拟合某些局部模式;而引入多尺度视图后,模型必须捕捉跨尺度的不变性。这种不变性正是高质量特征表示的基础。
与传统增强的区别
相比传统的随机翻转、颜色抖动等增强,多视角裁剪更注重空间结构的多样性。这种策略特别适合 ViT,因为 ViT 将图像划分为 patch,能够自然适应不同尺度的输入。
建议插入图片:一张展示多视角增强的示意图,包含原始图像、2 个全局视角和 6 个局部视角的裁剪示例,标题为“DINO 的多视角增强策略”。
3.3 损失函数:交叉熵蒸馏
DINO 的损失函数是其训练的核心驱动力。它基于学生网络和教师网络输出分布之间的 交叉熵,形式如下:
L
=
−
∑
i
P
t
(
x
i
)
log
P
s
(
x
i
)
L = -\sum_{i} P_t(x_i) \log P_s(x_i)
L=−i∑Pt(xi)logPs(xi)
其中:
- ( P t ( x i ) ) ( P_t(x_i) ) (Pt(xi)) 是教师网络对输入 ( x i ) ( x_i ) (xi) 的输出概率分布;
- ( P s ( x i ) ) ( P_s(x_i) ) (Ps(xi)) 是学生网络的输出概率分布。
输出分布的构建
为了将网络的特征转化为概率分布,DINO 在最后一层添加了一个投影头(projection head),并通过 softmax 函数归一化输出:
P
(
x
)
=
exp
(
z
(
x
)
/
τ
)
∑
j
exp
(
z
j
(
x
)
/
τ
)
P(x) = \frac{\exp(z(x)/\tau)}{\sum_j \exp(z_j(x)/\tau)}
P(x)=∑jexp(zj(x)/τ)exp(z(x)/τ)
其中:
- ( z ( x ) ) ( z(x) ) (z(x)) 是投影头的输出;
- ( τ ) ( \tau ) (τ) 是温度参数,用于控制分布的平滑度。
教师网络和学生网络的温度参数通常不同:教师网络使用较小的 ( τ ) ( \tau ) (τ)(如 0.04 0.04 0.04)以锐化分布,学生网络使用较大的 ( τ ) ( \tau ) (τ)(如 0.1 0.1 0.1)以保持柔性。
损失计算的细节
在多视角设置下,损失函数会分别计算全局视图和局部视图的贡献。例如:
- 学生网络对所有视图(全局+局部)的输出与教师网络对全局视图的输出进行对比;
- 总损失是所有视图损失的平均值。
公式扩展为:
L
total
=
1
N
∑
i
=
1
N
L
(
P
t
(
v
g
)
,
P
s
(
v
i
)
)
L_{\text{total}} = \frac{1}{N} \sum_{i=1}^N L(P_t(v_g), P_s(v_i))
Ltotal=N1i=1∑NL(Pt(vg),Ps(vi))
其中
(
N
)
( N )
(N) 是视图总数,
(
v
g
)
( v_g )
(vg) 是全局视图。
为什么用交叉熵?
交叉熵损失本质上是一种分布对齐的度量。它鼓励学生网络学习教师网络的知识,而教师网络的 EMA 更新又保证了知识的稳定性。这种“自蒸馏”过程让 DINO 在无监督场景下也能逐步逼近监督学习的效果。
与对比学习的区别
与 SimCLR 等基于对比学习的自监督方法不同,DINO 不依赖正负样本对,而是直接优化分布一致性。这种设计避免了负样本选择带来的复杂性,使得 DINO 更适合大规模数据集。
3.4 避免表示崩塌
自监督学习的一个经典难题是 表示崩塌(representation collapse),即模型输出退化为常量或低维表示,导致特征无意义。DINO 通过以下技巧巧妙规避了这一问题。
Centering 操作
教师网络的输出分布容易偏向某个均值,导致多样性下降。DINO 引入了 中心化 操作:
z
t
←
z
t
−
mean
(
z
t
)
z_t \leftarrow z_t - \text{mean}(z_t)
zt←zt−mean(zt)
其中
(
mean
(
z
t
)
)
( \text{mean}(z_t) )
(mean(zt)) 是教师输出的批量均值。这种操作强制输出分布围绕零点分布,防止退化。
Sharpening 操作
为了进一步增加输出的区分度,DINO 通过降低教师网络的温度参数 ( \tau ) 来“锐化”分布:
P
t
(
x
)
=
exp
(
z
t
(
x
)
/
τ
t
)
∑
j
exp
(
z
t
,
j
(
x
)
/
τ
t
)
,
τ
t
<
τ
s
P_t(x) = \frac{\exp(z_t(x)/\tau_t)}{\sum_j \exp(z_{t,j}(x)/\tau_t)}, \quad \tau_t < \tau_s
Pt(x)=∑jexp(zt,j(x)/τt)exp(zt(x)/τt),τt<τs
较小的
(
τ
t
)
( \tau_t )
(τt) 使得概率分布更尖锐,增强了特征的区分性。
多裁剪策略的作用
多视角输入本身也是一种天然的正则化手段。不同视图之间的差异迫使模型学习更鲁棒的表示,避免陷入简单的恒等映射。
理论分析
表示崩塌的根本原因是损失函数的全局最优解可能是退化的。DINO 通过上述机制引入了额外的约束条件,使得全局最优解必须满足跨视图一致性和分布多样性。这种设计在理论上保证了特征的有效性。
与 BYOL 的对比
BYOL 通过额外的预测头(predictor)避免崩塌,而 DINO 则依赖多视角和分布调整。DINO 的实现更简洁,但在小数据集上可能需要更仔细的参数调优。
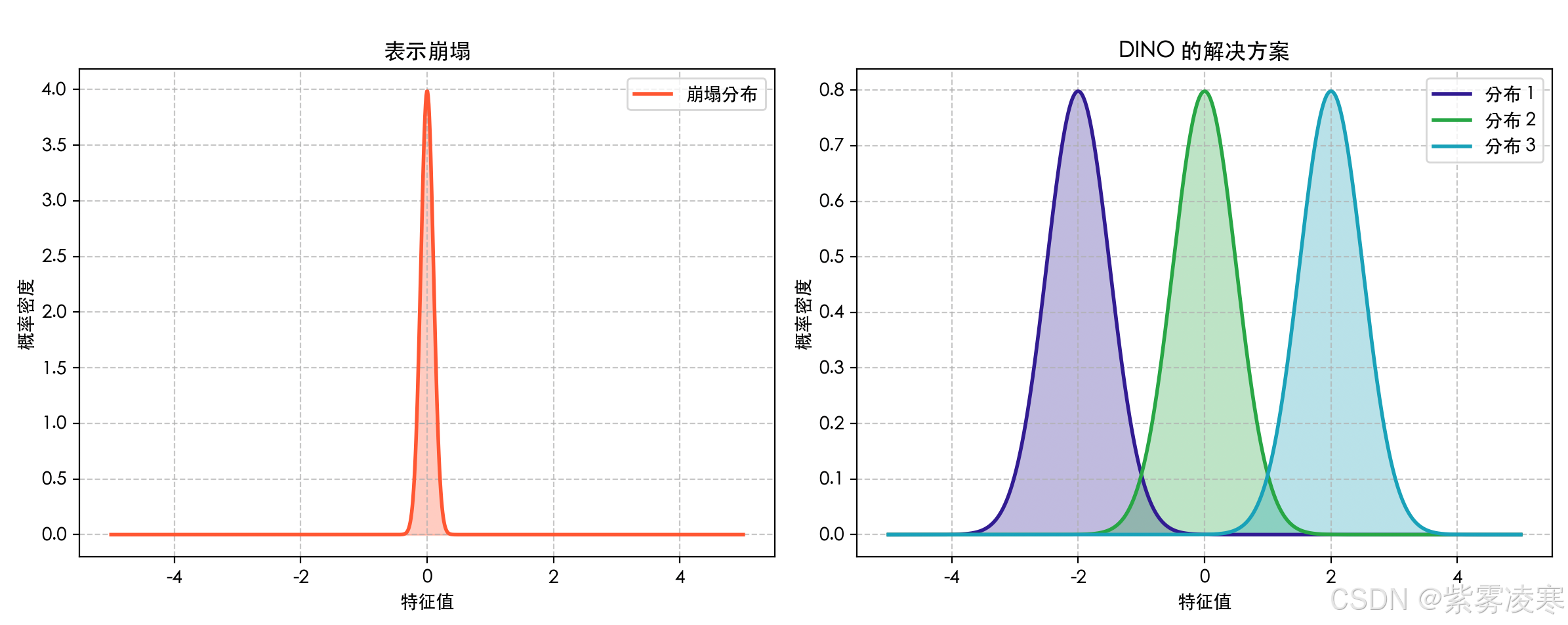
如图所示:一张对比表示崩塌的示意图,左侧展示崩塌情况(输出分布趋于单一),右侧展示 DINO 的分布。
四、DINO 的优势与应用场景
DINO 作为自监督学习领域的佼佼者,其优势和应用场景值得深入探讨。以下从技术性能、实用性以及未来潜力三个维度,全面分析 DINO 的价值,并结合具体案例说明其在实际项目中的潜力。
4.1 优势
1. 无标签依赖,降低数据成本
DINO 的最大亮点在于完全无需人工标注数据。在传统监督学习中,标注一张图像可能需要数分钟甚至数小时,而 DINO 通过自蒸馏和多视角增强,直接从原始数据中提取监督信号。例如,在 ImageNet 数据集上,DINO 仅使用未标注的 130 万张图像,就能在线性分类任务中达到 75.3% 的 Top-1 准确率,接近甚至超过部分监督模型。这种无标签依赖性极大降低了数据准备的成本,尤其适合数据稀缺或标注昂贵的场景。
2. 高性能表征,媲美监督学习
DINO 生成的特征表示质量极高,尤其是在 视觉 Transformer(ViT) 架构下表现突出。以 ImageNet 为例,DINO 在无监督预训练后,仅通过一个简单的线性分类器就能达到接近监督学习的效果。更令人惊讶的是,DINO 的特征在 k-NN 分类任务中也能取得优异结果(无需任何微调),这表明其表征具有很强的通用性和鲁棒性。与 SimCLR、MoCo 等方法相比,DINO 的性能更稳定,尤其在小型模型(如 ViT-Small)上也能保持竞争力。
3. 计算效率与实现简洁
尽管 DINO 引入了多视角增强,但其整体计算复杂度并不高。它避免了对比学习中的负样本采样和动量编码器设计,内存占用更低。例如,在单张 GPU(如 NVIDIA V100)上,DINO 可以轻松训练中小规模模型,而在多 GPU 分布式环境下,其扩展性也得到了验证。此外,DINO 的代码实现非常简洁,核心逻辑仅需几百行代码即可完成,这对工程落地和学术研究都极具吸引力。
4. 迁移能力强,适配多种任务
DINO 的特征表示不仅适用于分类任务,还能无缝迁移到目标检测、图像分割和检索等下游任务。以 COCO 数据集为例,使用 DINO 预训练的 ViT 模型在 Faster R-CNN 框架下的目标检测性能提升了 2-3 个 mAP 百分点。这种迁移能力源于 DINO 对图像全局和局部语义的深刻理解,使其成为视觉任务的通用预训练方案。
5. 可解释性与可视化优势
DINO 的一个意外收获是其特征的 可视化能力。在 ViT 架构下,DINO 的注意力图(attention map)能够清晰地突出图像中的语义区域,如物体轮廓或关键部件。这种特性不仅便于调试,还为无监督语义分割提供了可能性。例如,在无任何标注的情况下,DINO 的注意力图可以直接用于初步的图像分割任务,效果令人惊叹。
4.2 应用场景
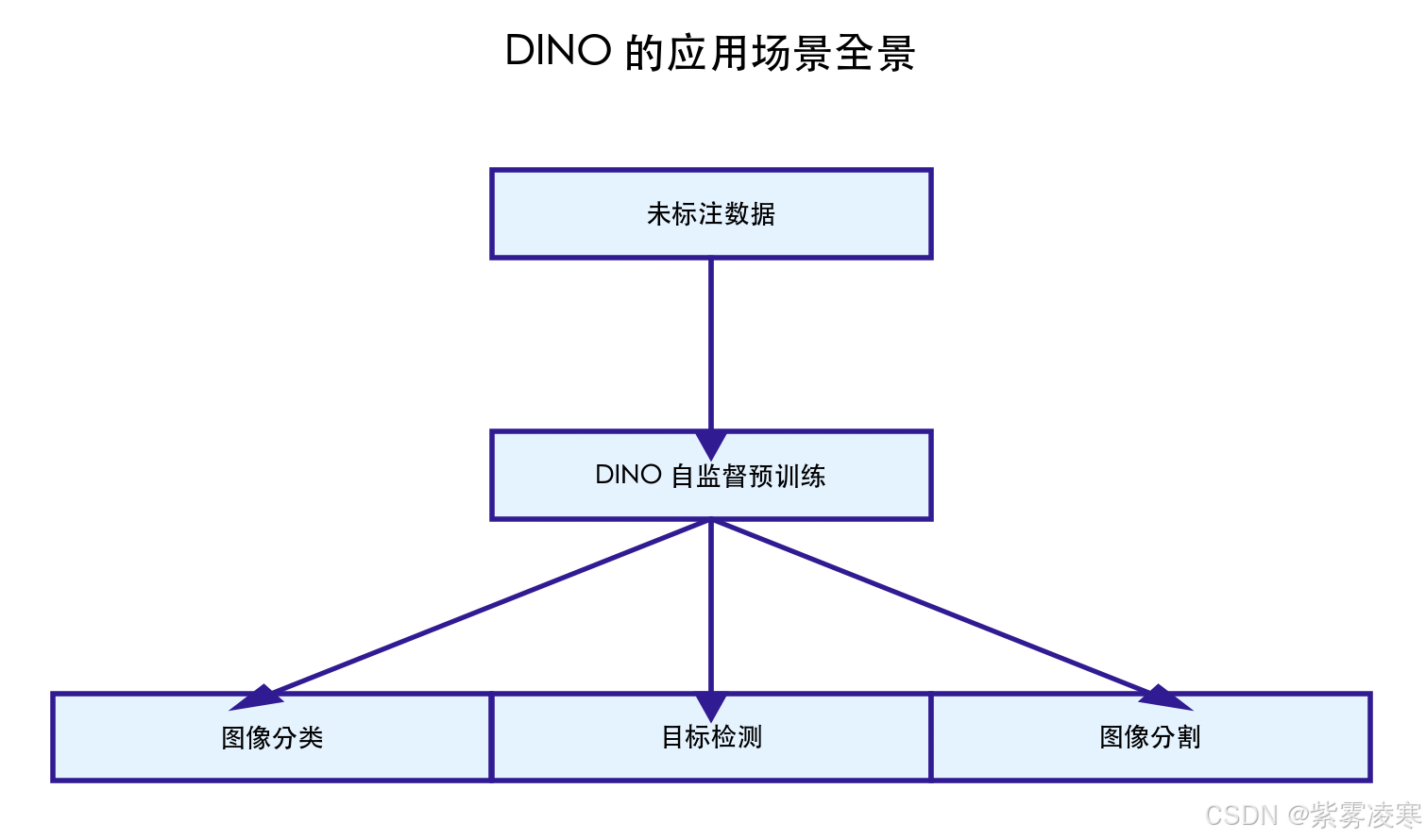
1. 视觉预训练的基础设施
DINO 可作为视觉模型预训练的“基础设施”。在工业界,许多公司拥有海量未标注图像数据(如用户上传的照片或监控视频),但缺乏足够的标注资源。DINO 可以利用这些数据训练一个强大的视觉主干网络(如 ViT 或 ResNet),然后通过少量标注数据微调下游任务。例如,一个电商平台可以用 DINO 预训练模型提取商品图像特征,再结合少量标注数据实现商品分类或推荐系统。
2. 数据稀缺领域的救星
在医疗影像、工业缺陷检测等数据稀缺领域,DINO 展现了巨大潜力。以医疗影像为例,CT 或 MRI 图像的标注需要专业医生参与,成本极高。DINO 可以利用未标注的影像数据进行预训练,生成高质量特征。例如,在肺部 CT 图像上,DINO 预训练的模型能够捕捉病灶区域的细微特征,随后通过少量标注样本微调即可实现病灶分类或分割,显著减少标注需求。
3. 无监督聚类与数据探索
DINO 的特征表示非常适合 无监督聚类任务。在无任何标签的情况下,直接对 DINO 特征应用 K 均值聚类,就能实现接近监督学习的分组效果。例如,在一个包含数百万张未标注图片的数据集中,DINO 可以帮助自动将图像按语义分组(如动物、风景、人物),为后续数据分析或标注提供参考。这种能力在内容管理系统或图像搜索引擎中尤为实用。
4. 多模态学习的预备步骤
随着多模态学习的兴起,DINO 的视觉特征可以作为跨模态任务的预训练基础。例如,在图像-文本对齐任务(如 CLIP)中,DINO 可以提供高质量的图像特征,与文本特征结合后进一步优化模型性能。未来,DINO 可能扩展到视频、3D 点云等领域,成为多模态自监督学习的基石。
5. 教育与研究工具
对于学术研究者和学生,DINO 是一个理想的实验平台。其代码开源、实现简单,且效果显著,非常适合用来学习自监督学习的原理。例如,在课堂项目中,学生可以用 DINO 在小型数据集(如 CIFAR-10)上进行实验,探索多视角增强或 EMA 参数对性能的影响。这种易用性使其成为 CV 领域的教学利器。
4.3 未来潜力
DINO 的优势不仅限于当前应用。随着计算资源的提升和算法的优化,DINO 可能在以下方向进一步发展:
- 更大规模模型:结合更大参数量的 ViT(如 ViT-Large),DINO 可能接近甚至超越监督学习的上限。
- 实时应用:通过模型压缩和蒸馏,DINO 特征可能被部署到边缘设备,用于实时图像分析。
- 跨领域扩展:从视觉扩展到语音、时间序列等领域,探索更广泛的自监督范式。
总之,DINO 的优势和应用场景展示了其作为自监督学习框架的强大生命力,值得每个技术从业者深入研究和实践。
五、代码实践:用 PyTorch 实现 DINO
下面是一个简化的 DINO 实现示例,帮助你快速上手。我们以 ViT 为骨干网络,使用 PyTorch 框架。
import torch
import torch.nn as nn
import torchvision.transforms as T
from transformers import ViTModel
# 数据增强
global_transform = T.Compose([
T.RandomResizedCrop(224, scale=(0.4, 1.0)),
T.ToTensor(),
T.Normalize((0.5,), (0.5,))
])
local_transform = T.Compose([
T.RandomResizedCrop(96, scale=(0.05, 0.4)),
T.ToTensor(),
T.Normalize((0.5,), (0.5,))
])
# 定义 DINO 模型
class DINO(nn.Module):
def __init__(self):
super(DINO, self).__init__()
self.student = ViTModel.from_pretrained('google/vit-base-patch16-224')
self.teacher = ViTModel.from_pretrained('google/vit-base-patch16-224')
for param in self.teacher.parameters():
param.requires_grad = False
def forward(self, x_global, x_local):
student_global = self.student(x_global).last_hidden_state
student_local = self.student(x_local).last_hidden_state
with torch.no_grad():
teacher_global = self.teacher(x_global).last_hidden_state
return student_global, student_local, teacher_global
# EMA 更新教师网络
def update_teacher(teacher, student, momentum=0.996):
for t_param, s_param in zip(teacher.parameters(), student.parameters()):
t_param.data = momentum * t_param.data + (1 - momentum) * s_param.data
# 训练循环
model = DINO()
optimizer = torch.optim.Adam(model.student.parameters(), lr=0.0005)
criterion = nn.CrossEntropyLoss()
for epoch in range(100):
for images in dataloader:
global_views = torch.stack([global_transform(img) for img in images])
local_views = torch.stack([local_transform(img) for img in images])
s_global, s_local, t_global = model(global_views, local_views)
# 计算损失
loss = criterion(s_global, t_global.softmax(dim=-1)) + criterion(s_local, t_global.softmax(dim=-1))
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 更新教师网络
update_teacher(model.teacher, model.student)
代码说明
- 数据增强:实现多视角裁剪。
- 模型:基于 Hugging Face 的 ViT。
- 训练:学生网络优化,教师网络 EMA 更新。
具体结果如上图所示,完整实现需要更多细节,建议参考官方代码。
六、总结与展望
DINO 以其优雅的设计和强大的性能,为自监督学习开辟了新方向。它的学生-教师结构、多视角增强和分布对齐策略,值得每位深度学习从业者深入研究。未来,DINO 可能与多模态学习结合,应用于更广泛的场景。如下图所示为DINO 的训练流程:
动手实践是理解 DINO 的最佳方式。欢迎大家基于自己的数据集跑一跑,分享你的实验结果和心得!
七、参考资料
- Caron, M., et al. “Emerging Properties in Self-Supervised Vision Transformers.” ICCV 2021.
- DINO 官方代码:https://github.com/facebookresearch/dino
- PyTorch 官方文档:https://pytorch.org/
延伸阅读



















 1075
1075

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











