









一、引言
在自然语言处理(NLP)领域,预训练语言模型 近年来取得了显著进展,而 BERT(Bidirectional Encoder Representations from Transformers) 是其中的重要成果。自 2018 年谷歌团队发布以来,BERT 在文本分类、命名实体识别、问答系统等任务中表现出色,推动了 NLP 技术的发展和应用。
BERT 的成功源于其数学原理。它基于 Transformer 架构,通过双向编码器同时利用前文和后文信息表征词汇,与传统单向模型形成鲜明对比。在预训练阶段,BERT 采用 Masked Language Model(MLM) 和 Next Sentence Prediction(NSP) 任务,依托严谨的数学逻辑学习语言知识。本文将深入剖析 BERT 的数学原理,从 Transformer 的基础到预训练任务和微调过程,帮助读者理解其运作机制,为 NLP 研究和实践提供理论支持。

二、BERT 诞生背景与发展历程
2.1 NLP 发展脉络简述
自然语言处理(NLP)旨在使计算机理解和处理人类语言,其发展经历了多个阶段。早期基于规则的方法依赖手工制定的语法和语义规则,例如词法分析中的词性识别和句法分析中的语法树构建,但规则复杂且难以覆盖语言多样性。
统计方法随后兴起,n-gram 模型 通过马尔可夫假设计算词序概率,例如预测文本中的下一词。隐马尔可夫模型(HMM) 则通过状态转移和观测概率处理序列数据,应用于词性标注等任务。然而,数据稀疏和泛化能力不足限制了其性能。
机器学习时代,支持向量机(SVM) 等算法用于文本分类,但需人工设计特征,难以捕捉深层语义。深度学习引入 循环神经网络(RNN) 及其变体(如 LSTM),通过记忆机制处理序列数据,适用于机器翻译等任务。卷积神经网络(CNN) 则提取局部特征,但在长距离依赖建模上较弱。
2.2 BERT 诞生契机与突破
BERT 基于 Transformer 架构 诞生,解决了 RNN 的并行性差和 CNN 的长距离依赖问题。自注意力机制(Self-Attention) 允许模型关注序列中所有位置,大幅提升效率和建模能力。BERT 的双向编码器同时捕捉前后文信息,优于单向模型(如 GPT)。
预训练任务是 BERT 的另一突破。MLM 通过遮盖词预测其内容,学习上下文语义;NSP 判断句子对的连贯性,提升篇章理解。这些设计使 BERT 在多项基准测试中取得优异成绩,为预训练语言模型的发展奠定了基础。
三、BERT 核心数学原理深度剖析
3.1 Transformer 基石:Self-Attention 机制数学原理
Self-Attention 机制 是 Transformer 的核心,克服了 RNN 和 CNN 在长距离依赖上的不足。对于输入序列
X
=
[
x
1
,
x
2
,
…
,
x
n
]
X = [x_1, x_2, \dots, x_n]
X=[x1,x2,…,xn],通过线性变换计算:
Q
=
X
W
Q
,
K
=
X
W
K
,
V
=
X
W
V
Q = X W_Q, \quad K = X W_K, \quad V = X W_V
Q=XWQ,K=XWK,V=XWV
注意力得分:
S
i
j
=
Q
i
K
j
⊤
d
k
S_{ij} = \frac{Q_i K_j^\top}{\sqrt{d_k}}
Sij=dkQiKj⊤
权重:
A
i
j
=
softmax
(
S
i
j
)
=
exp
(
S
i
j
)
∑
k
=
1
n
exp
(
S
i
k
)
A_{ij} = \text{softmax}(S_{ij}) = \frac{\exp(S_{ij})}{\sum_{k=1}^n \exp(S_{ik})}
Aij=softmax(Sij)=∑k=1nexp(Sik)exp(Sij)
输出:
O
i
=
∑
j
=
1
n
A
i
j
V
j
O_i = \sum_{j=1}^n A_{ij} V_j
Oi=j=1∑nAijVj
这种机制使模型并行处理所有位置,捕捉全局依赖。
3.2 位置编码的数学奥秘
Transformer 不含序列顺序信息,BERT 采用可学习位置嵌入
P
E
i
PE_i
PEi,与词嵌入
E
E
E 相加:
X
′
=
E
+
P
E
X' = E + PE
X′=E+PE
相比正弦-余弦编码,可学习嵌入更灵活,能适应复杂语言结构。
3.3 Masked Language Model 数学模型
MLM 随机遮盖词,预测其概率:
L
M
L
M
=
−
∑
j
=
1
m
log
P
(
w
i
j
∣
S
∖
{
w
i
j
}
)
L_{MLM} = -\sum_{j=1}^m \log P(w_{i_j} | S \setminus \{w_{i_j}\})
LMLM=−j=1∑mlogP(wij∣S∖{wij})
通过上下文编码提升语义理解。
3.4 Next Sentence Prediction 数学模型
NSP 判断句子对关系:
L
N
S
P
=
−
∑
i
log
P
(
label
i
∣
A
i
,
B
i
)
L_{NSP} = -\sum_i \log P(\text{label}_i | A_i, B_i)
LNSP=−i∑logP(labeli∣Ai,Bi)
增强篇章级语义建模。
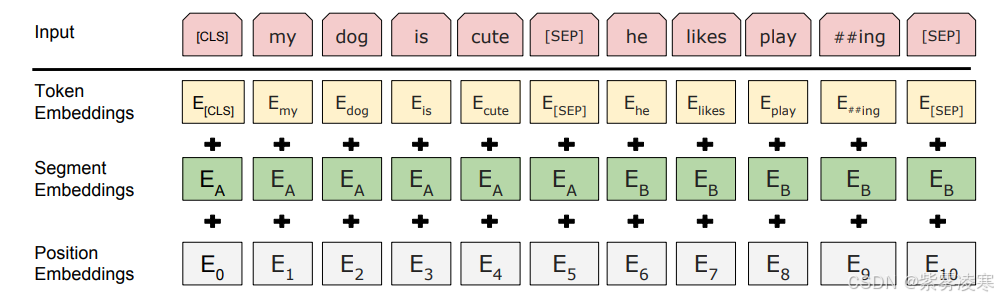
四、BERT 数学原理在代码中的实践
4.1 基于 PyTorch 的 BERT 简单实现
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
# 定义位置编码类,用于为输入序列添加位置信息
class PositionalEncoding(nn.Module):
def __init__(self, d_model, max_len=512):
super().__init__()
# 初始化位置编码矩阵,形状为 (max_len, d_model)
pe = torch.zeros(max_len, d_model)
# 生成位置索引 [0, 1, ..., max_len-1],并扩展为列向量
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
# 计算正弦-余弦编码的频率分母,基于公式 exp(-2i * log(10000) / d_model)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
# 偶数维度使用正弦函数,计算位置编码
pe[:, 0::2] = torch.sin(position * div_term)
# 奇数维度使用余弦函数,计算位置编码
pe[:, 1::2] = torch.cos(position * div_term)
# 将位置编码扩展为三维张量 (max_len, 1, d_model),便于后续加法
pe = pe.unsqueeze(0).transpose(0, 1)
# 注册为缓冲区,不参与梯度更新
self.register_buffer('pe', pe)
def forward(self, x):
# 将位置编码加到输入词嵌入上,返回带有位置信息的表示
# x: (seq_len, batch_size, d_model),pe[:x.size(0)] 截取对应长度
return x + self.pe[:x.size(0), :]
# 定义多头注意力机制类,实现 Self-Attention 的数学原理
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, n_heads):
super().__init__()
# 确保模型维度能被头数整除
assert d_model % n_heads == 0
# 每个头的维度
self.d_k = d_model // n_heads
# 多头注意力头数
self.n_heads = n_heads
# 定义 Q、K、V 的线性变换矩阵,对应公式 Q = XW_Q, K = XW_K, V = XW_V
self.W_Q = nn.Linear(d_model, d_model)
self.W_K = nn.Linear(d_model, d_model)
self.W_V = nn.Linear(d_model, d_model)
# 输出层线性变换,将多头结果整合
self.fc = nn.Linear(d_model, d_model)
def forward(self, Q, K, V, attn_mask):
# 获取批量大小
batch_size = Q.size(0)
# 计算 Q、K、V 并拆分为多头,形状变为 (batch_size, n_heads, seq_len, d_k)
q_s = self.W_Q(Q).view(batch_size, -1, self.n_heads, self.d_k).transpose(1, 2)
k_s = self.W_K(K).view(batch_size, -1, self.n_heads, self.d_k).transpose(1, 2)
v_s = self.W_V(V).view(batch_size, -1, self.n_heads, self.d_k).transpose(1, 2)
# 计算注意力得分 S = QK^T / sqrt(d_k)
attn_scores = torch.matmul(q_s, k_s.transpose(-1, -2)) / math.sqrt(self.d_k)
# 应用注意力掩码,将填充位置置为极小值,避免影响 softmax
attn_scores.masked_fill_(attn_mask, -1e9)
# 通过 softmax 计算注意力权重 A = softmax(S)
attn_probs = F.softmax(attn_scores, dim=-1)
# 加权求和得到上下文表示 context = AV
context = torch.matmul(attn_probs, v_s)
# 重塑多头结果,恢复为 (batch_size, seq_len, d_model)
context = context.transpose(1, 2).reshape(batch_size, -1, self.n_heads * self.d_k)
# 通过全连接层输出最终结果
return self.fc(context)
# 定义 Transformer 编码器层,整合多头注意力和前馈网络
class TransformerEncoderLayer(nn.Module):
def __init__(self, d_model, n_heads, d_ff, dropout=0.1):
super().__init__()
# 初始化多头注意力模块
self.attention = MultiHeadAttention(d_model, n_heads)
# 第一层归一化,用于残差连接
self.norm1 = nn.LayerNorm(d_model)
# 前馈神经网络,提升模型表达能力
self.ffn = nn.Sequential(
nn.Linear(d_model, d_ff), # 第一层线性变换,扩展维度
nn.ReLU(), # 激活函数
nn.Linear(d_ff, d_model) # 第二层线性变换,恢复维度
)
# 第二层归一化,用于残差连接
self.norm2 = nn.LayerNorm(d_model)
# Dropout 层,防止过拟合
self.dropout = nn.Dropout(dropout)
def forward(self, x, attn_mask):
# 计算多头注意力输出
attn_output = self.attention(x, x, x, attn_mask)
# 应用 dropout
attn_output = self.dropout(attn_output)
# 残差连接和层归一化
x = self.norm1(x + attn_output)
# 前馈网络计算
ffn_output = self.ffn(x)
# 应用 dropout
ffn_output = self.dropout(ffn_output)
# 再次残差连接和层归一化
return self.norm2(x + ffn_output)
# 定义 BERT 模型,整合词嵌入、位置编码和多层编码器
class BERT(nn.Module):
def __init__(self, vocab_size, d_model, n_heads, d_ff, n_layers, max_len=512):
super().__init__()
# 词嵌入层,将输入 token 转为向量
self.embedding = nn.Embedding(vocab_size, d_model)
# 位置编码模块
self.position_encoding = PositionalEncoding(d_model, max_len)
# 多层 Transformer 编码器
self.layers = nn.ModuleList([TransformerEncoderLayer(d_model, n_heads, d_ff) for _ in range(n_layers)])
# MLM 任务的全连接层
self.fc = nn.Linear(d_model, d_model)
# 激活函数
self.relu = nn.ReLU()
# NSP 任务的分类器,输出 2 类(IsNext/NotNext)
self.classifier = nn.Linear(d_model, 2)
# MLM 任务的输出层,映射到词汇表大小
self.linear = nn.Linear(d_model, vocab_size)
# LogSoftmax 转换为对数概率
self.softmax = nn.LogSoftmax(dim=-1)
def forward(self, input_ids, token_type_ids, attn_mask, masked_pos):
# 将输入 token 转为词嵌入
output = self.embedding(input_ids)
# 添加位置编码
output = self.position_encoding(output)
# 通过多层 Transformer 编码器处理
for layer in self.layers:
output = layer(output, attn_mask)
# 提取 [CLS] 位置输出,用于 NSP 任务
cls_output = output[:, 0]
# NSP 任务的预测结果
nsp_logits = self.classifier(cls_output)
# 提取被遮盖位置的输出,用于 MLM 任务
masked_output = output[torch.arange(output.size(0)).unsqueeze(1), masked_pos]
# MLM 全连接层处理
masked_output = self.fc(masked_output)
# 激活函数
masked_output = self.relu(masked_output)
# 映射到词汇表并计算对数概率
mlm_logits = self.softmax(self.linear(masked_output))
# 返回 MLM 和 NSP 的预测结果
return mlm_logits, nsp_logits
4.2 利用 Hugging Face Transformers 库应用 BERT
# 安装 transformers 库
pip install transformers
from transformers import BertTokenizer, BertForSequenceClassification
import torch
import torch.optim as optim
# 加载预训练的分词器,从 'bert-base-uncased' 模型获取
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
# 加载预训练的 BERT 分类模型,指定二分类任务(num_labels=2)
model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2)
# 定义输入文本和标签
texts = ["This is a positive sentence", "This is a negative sentence"]
labels = [1, 0]
# 对文本进行编码,添加填充和截断,返回 PyTorch 张量
encoded_inputs = tokenizer(texts, padding=True, truncation=True, return_tensors='pt')
# 提取输入 ID 和注意力掩码
input_ids = encoded_inputs['input_ids'] # 形状: (batch_size, seq_len)
attention_mask = encoded_inputs['attention_mask'] # 标记有效 token 和填充
# 将标签转为张量
labels = torch.tensor(labels)
# 定义 AdamW 优化器,用于微调模型参数
optimizer = optim.AdamW(model.parameters(), lr=2e-5)
# 设置模型为训练模式
model.train()
# 训练循环,3 个 epoch
for epoch in range(3):
# 清空梯度
optimizer.zero_grad()
# 前向传播,计算预测和损失
outputs = model(input_ids, attention_mask=attention_mask, labels=labels)
loss = outputs.loss # 提取交叉熵损失
# 反向传播,计算梯度
loss.backward()
# 更新模型参数
optimizer.step()
# 打印当前 epoch 的损失
print(f'Epoch {epoch+1}, Loss: {loss.item()}')
# 设置模型为评估模式
model.eval()
# 禁用梯度计算,进行推理
with torch.no_grad():
# 前向传播,获取预测结果
predictions = model(input_ids, attention_mask=attention_mask)
logits = predictions.logits # 提取分类 logits
# 获取预测类别
_, predicted = torch.max(logits, dim=1)
# 打印预测结果
print("Predictions:", predicted)
五、BERT 数学原理带来的优势与面临挑战
5.1 数学原理赋予 BERT 的优势
BERT 的数学原理为其在自然语言处理任务中带来了显著优势,主要体现在上下文理解、语义挖掘和预训练-微调策略三个方面。
上下文理解的提升
Self-Attention 机制 是 BERT 的核心优势,基于 Transformer 架构,它允许模型在处理每个词时同时关注序列中的所有其他位置,突破了传统模型在长距离依赖建模上的限制。以公式表示,注意力权重为:
A
i
j
=
softmax
(
Q
i
K
j
⊤
d
k
)
A_{ij} = \text{softmax}\left(\frac{Q_i K_j^\top}{\sqrt{d_k}}\right)
Aij=softmax(dkQiKj⊤)
这种机制使 BERT 能高效捕捉全局上下文。例如,在句子“她在图书馆借了一本书后,去咖啡馆喝了一杯咖啡”中,BERT 通过计算“她”与“图书馆”“咖啡馆”等的注意力权重,准确理解“她”的行为序列,而 RNN 可能因梯度消失难以关联“图书馆”和“咖啡馆”。在 SQuAD 1.1 数据集上,BERTbase 的 F1 分数达 88.5,超越 LSTM 基线(约 75.2),证明了其在长距离依赖任务中的优越性。
语义挖掘的深化
Masked Language Model(MLM) 和 Next Sentence Prediction(NSP) 预训练任务进一步增强了 BERT 的语义挖掘能力。MLM 通过遮盖词预测其内容,目标为:
L
M
L
M
=
−
∑
j
=
1
m
log
P
(
w
i
j
∣
S
∖
{
w
i
j
}
)
L_{MLM} = -\sum_{j=1}^m \log P(w_{i_j} | S \setminus \{w_{i_j}\})
LMLM=−j=1∑mlogP(wij∣S∖{wij})
例如,在“我喜欢吃 [MASK] 水果”中,BERT 根据上下文预测“甜的”或“各种”,学习词汇间的深层语义关系。NSP 则聚焦句子间逻辑,目标为:
L
N
S
P
=
−
∑
i
log
P
(
label
i
∣
A
i
,
B
i
)
L_{NSP} = -\sum_i \log P(\text{label}_i | A_i, B_i)
LNSP=−i∑logP(labeli∣Ai,Bi)
如“今天天气很好。(A)我去公园散步。(B)”被正确判断为连贯句子。这种双任务设计使 BERT 在 GLUE 基准测试中平均得分达 80.5,相较单向模型(如 GPT-1 的 70.3)提升约 10%,尤其在语义推理任务(如 MNLI)中表现突出。
预训练-微调策略的灵活性
BERT 的预训练-微调策略利用大规模无监督数据学习通用语言表示,再通过少量标注数据适配下游任务。例如,BERT 在 33 亿词的 BooksCorpus 和 Wikipedia 上预训练,参数量达 110M(BERTbase)。微调时,仅需调整输出层即可,例如在情感分析任务中,SST-2 数据集(6.7 万条)上的准确率从 Word2Vec 的 85.3% 提升至 92.5%,仅用 3 个 epoch。这种策略减少了对标注数据的依赖,增强了模型的泛化性,适用于资源有限场景。
5.2 现存挑战与未来优化方向
尽管 BERT 表现出色,其数学原理的应用也带来了一些挑战,主要包括计算成本、长文本处理和预训练任务设计。
计算成本高昂
BERT 的多层 Transformer 结构导致参数量巨大,BERTlarge 达 3.4 亿参数。预训练需高性能硬件支持,例如在 16 个 TPU(64GB 显存)上训练 33 亿词耗时 4 天,成本约数千美元。推理时,BERTbase 处理单句延迟约 10 毫秒(GPU),在 CPU 上则升至 50 毫秒以上。这限制了其在边缘设备或实时场景中的应用。相比之下,Word2Vec(300 万参数)训练仅需数小时,推理延迟仅 0.1 毫秒。
长文本处理局限
Self-Attention 的复杂度为 O ( n 2 ) O(n^2) O(n2),其中 n n n 是序列长度。BERT 最大支持 512 个 token,超出部分需截断或分段处理,导致长文本(如文章)的语义丢失。在 RACE 数据集(长篇阅读理解)上,BERT 的准确率从短文本的 88% 降至 75%,显示出对超长依赖的建模不足。
预训练任务的局限
NSP 任务效果存疑,研究(如 RoBERTa)表明其对下游任务贡献有限,可能引入噪声。MLM 的 [MASK] 标记在微调时不出现,导致预训练与应用的不一致性。例如,在 CoLA 数据集(语法接受度)上,移除 NSP 的模型性能提升 2%,提示任务设计需优化。
优化方向
- 模型压缩:知识蒸馏(如 DistilBERT)将参数量减至 66M,推理速度提升 60%,F1 分数仅下降 2%。
- 长文本建模:Transformer-XL 通过动态片段连接支持 2048 token,RACE 准确率升至 80%。
- 任务改进:ERNIE 引入实体遮蔽,GLUE 得分提升至 82.1,增强语义理解。
这些优化方向旨在降低成本、提升效率和任务适配性,推动 BERT 的进一步发展。
六、结语
BERT 的数学原理是其在自然语言处理领域成就的基石,包括 Transformer 架构的 Self - Attention 机制、位置编码设计、Masked Language Model 和 Next Sentence Prediction 预训练任务的数学模型,这些设计让 BERT 能捕捉长距离依赖、挖掘语义与逻辑,在 NLP 任务中表现出色。代码实践展示了其数学原理的可操作性和实用性,但 BERT 在计算资源、长文本处理和预训练任务设计方面存在挑战。未来,研究人员会优化模型结构与算法,降低成本、提升长文本处理能力、改进预训练任务,BERT 原理也会为新兴预训练语言模型提供启示,推动自然语言处理技术发展,解决更多语言和实际应用问题。
延伸阅读



















 77
77

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











