










一、引言
在深度学习领域,神经网络模型的规模与复杂度持续增长。例如,2012 年 ImageNet 大赛中的 AlexNet 拥有 600 万个参数,而 2014 年的 Google Inception 模型参数数量达到 10 亿。这种规模的增加带来了性能提升,但也导致了计算成本、存储需求和模型可解释性等方面的挑战。
模型压缩技术因此成为解决这些问题的有效手段。模型压缩旨在将复杂的预训练模型转化为精简的小模型,在尽量保持精度的同时,降低存储和计算需求,使其适配各种硬件平台。常见的模型压缩方法包括量化、剪枝、知识蒸馏和二值化网络等。其中,模型剪枝 是核心技术,通过移除冗余参数(如权重、神经元或卷积核),减小模型规模,提高计算速度和泛化能力,尤其适用于资源受限的环境,如移动设备和嵌入式系统。
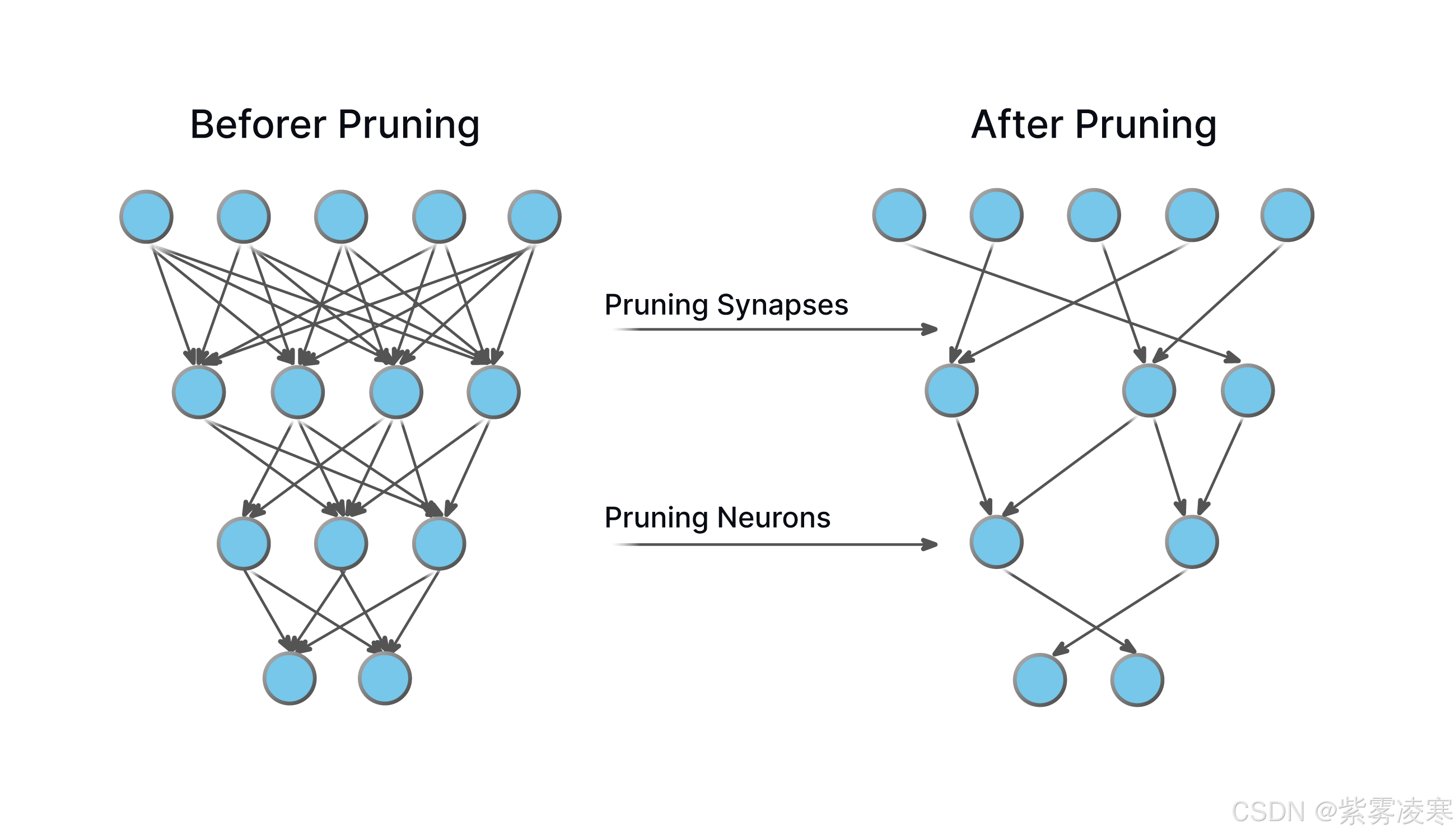
二、模型剪枝基础概念
2.1 定义与原理
模型剪枝是指在神经网络中移除那些对模型性能贡献较小的神经元、权重或连接,以减少模型的复杂度和参数数量。其核心原理基于神经网络的 过参数化特性。在深度学习中,为了捕捉数据的复杂模式和特征,模型通常被设计为拥有大量参数,这种冗余设计使得模型在训练时具有较高的灵活性和表达能力。然而,研究表明,训练完成后,许多参数对模型的最终输出影响微乎其微,去除这些冗余部分不会显著损害模型性能,反而能带来显著的优化效果。
以 AlexNet 为例,其包含约 600 万个参数,其中部分权重的绝对值极小(例如小于 0.01),对模型在图像分类任务中的预测结果几乎没有影响。这些权重可以被视为冗余参数,通过剪枝技术将其移除,不仅能减少模型的存储需求(从数十 MB 降至更小规模),还能降低计算量(例如减少矩阵乘法的运算次数)。这种方法之所以可行,是因为神经网络具有一定的 容错性和鲁棒性。在剪枝后,剩余的参数可以通过微调或其他调整机制,重新分配权重以补偿被移除部分的功能,从而保持模型对数据特征的学习能力。
此外,剪枝的理论基础还与生物神经系统的运作有一定相似之处。在人脑中,神经元之间的连接并非全部活跃,部分连接在发育过程中会被修剪以提高效率。类似地,人工神经网络中的剪枝过程也可以看作是对网络结构的优化,去除冗余的同时保留核心功能。这种特性使得剪枝不仅是一种压缩手段,还能潜在提升模型的泛化能力,避免过拟合。例如,在 MNIST 数据集上训练的简单卷积神经网络中,剪去 30% 的低重要性权重后,测试集上的准确率仅下降约 0.5%,而模型的推理速度提升了近 20%。
2.2 与其他模型压缩技术的区别
模型剪枝与其他模型压缩技术(如量化、知识蒸馏和二值化网络)在目标和实现方式上存在显著差异,理解这些区别有助于选择合适的优化策略。
-
量化:量化的目标是通过降低参数的表示精度来压缩模型。例如,将 32 位浮点数权重转换为 8 位整数,从而减少每参数的存储需求(从 4 字节降至 1 字节)。这种方法显著降低了内存占用和计算复杂度,尤其在硬件支持低精度运算(如 INT8 指令集)时效果更佳。然而,量化并未减少参数的数量,模型的结构和计算图保持不变。例如,一个包含 100 万参数的模型,量化后参数数量仍是 100 万,只是存储空间从约 4MB 减少到 1MB。
-
模型剪枝:与量化不同,剪枝直接移除模型中的不重要参数(如权重置零或删除整个神经元),从而实质性减少参数数量,生成一个稀疏化的网络结构。例如,同样的 100 万参数模型,经过剪枝可能只保留 50 万参数,存储需求和计算量均显著下降。剪枝的关键在于识别哪些参数是冗余的,通常通过权重大小、梯度信息或对输出的贡献度来判断。这种方法不仅压缩模型,还能改变网络拓扑结构,使其更轻量化。
-
知识蒸馏:知识蒸馏通过训练一个较小的“学生”模型来模仿大模型(教师模型)的行为,实现压缩。它不直接修改原始模型结构,而是通过知识传递让小模型学习大模型的输出分布或中间特征。例如,一个拥有 10 亿参数的 Transformer 模型可以通过知识蒸馏训练出一个仅有 1 千万参数的小模型,性能接近原始模型。相比之下,剪枝是从单一模型内部出发,通过精简自身结构实现优化,不依赖额外的模型。
-
二值化网络:二值化将权重和激活值限制为二值(如 +1 或 -1),大幅减少存储和计算成本(例如用 1 位表示代替 32 位)。但这种方法可能导致精度损失较大,且需要专门的训练方法。剪枝则更灵活,可以根据任务需求控制压缩程度,不强制参数取值范围。
从应用场景看,量化适合需要低精度高效运算的硬件(如边缘设备),知识蒸馏适用于已有强大预训练模型的情况,而剪枝则在希望直接优化单一模型时更具优势。例如,在一个资源受限的智能摄像头系统中,剪枝可以直接将卷积神经网络的参数量减少 50%,而量化进一步降低存储需求,二者结合能实现更优的性能-效率平衡。
三、剪枝方法分类
3.1 非结构化剪枝
非结构化剪枝,也称为细粒度剪枝,是一种针对神经网络中单个权重进行操作的方法。其过程包括评估每个权重的重要性(通常基于绝对值大小或梯度),然后移除被判定为不重要的部分,通常将其值设为零,从而生成一个稀疏的权重矩阵。例如,在一个全连接层中,若权重矩阵包含 10,000 个元素,非结构化剪枝可能根据 L1 范数( ∣ ∣ w ∣ ∣ 1 ||w||_1 ∣∣w∣∣1)排序,剪掉 50% 绝对值最小的权重,最终保留 5,000 个非零参数。
优势在于其高灵活性和压缩潜力。由于剪枝针对单个权重,可以精确去除冗余部分,实现较高的压缩比。研究表明,在 VGG-16 模型上,非结构化剪枝可将参数量减少 70% 以上(从 138M 降至约 40M),同时精度损失控制在 1-2% 以内。此外,因其粒度细腻,在同等剪枝比例下对模型性能的影响较小。例如,在自然语言处理任务中,对 BERT 模型的部分注意力权重进行非结构化剪枝后,其在下游任务上的 F1 分数仅下降约 0.5%。
然而,缺点同样显著。剪枝后的稀疏矩阵不规则,现有的通用硬件(如 GPU 和 CPU)在处理稀疏运算时效率低下。例如,一个稀疏度为 80% 的矩阵在 GPU 上可能仅提升 10% 的计算速度,因并行计算无法充分利用稀疏性。要解决此问题,需依赖专用硬件加速器(如 Google TPU 或 NVIDIA 的稀疏计算核心),但这增加了部署成本。此外,稀疏矩阵的存储和读取会引入额外开销,例如需要额外的索引表来记录非零元素位置,进一步影响效率。在嵌入式系统中,这种开销可能抵消剪枝带来的部分收益。
3.2 结构化剪枝
结构化剪枝在更高层次上操作,针对神经网络中的特定结构单元(如整个神经元、卷积核、通道或层)进行移除,而非单个权重。例如,在卷积神经网络(CNN)中,结构化剪枝可能直接删除一个卷积核及其相关连接。以 ResNet-50 为例,若某个卷积层包含 64 个卷积核,通过评估每个卷积核的输出特征图对后续层的影响,可以移除其中 20 个贡献最小的卷积核,使通道数从 64 降至 44。
优势在于保持模型的规则性。剪枝后的模型仍具完整结构(如矩阵维度不变),无需特殊硬件即可在常规深度学习框架(如 PyTorch、TensorFlow)和硬件(GPU、CPU)上高效运行。例如,在 MobileNetV1 上应用通道剪枝后,模型计算量从 569M FLOPs 降至 300M FLOPs,推理速度提升约 40%,且无需修改底层计算引擎。由于剪枝单元较大(如整个通道),计算效率提升显著,尤其适合实时性要求高的场景,如自动驾驶中的目标检测任务。此外,结构化剪枝便于部署,开发者无需调整现有推理管道即可使用剪枝后的模型。
局限性在于剪枝粒度较粗。由于移除的是完整结构单元,可能会意外删除对性能有一定贡献的部分,导致精度下降较大。例如,在 ImageNet 数据集上对 ResNet-18 进行结构化剪枝,移除 30% 的通道后,Top-1 准确率从 69.8% 降至 65.2%,降幅较非结构化剪枝更明显。此外,结构化剪枝的压缩比受限,难以达到非结构化剪枝的高度。例如,在高压缩需求场景(如参数量需减少 90%),结构化剪枝可能因无法细粒度调整而失败,而非结构化剪枝仍能胜任。
从应用角度看,非结构化剪枝适合追求极致压缩比的场景(如研究性实验或搭配专用硬件),而结构化剪枝更适合工业部署,尤其是在标准硬件上运行的实时系统。例如,在智能安防摄像头中,结构化剪枝后的 CNN 模型能在保持 95% 检测率的同时,将推理时间从 50ms 缩短至 30ms,满足实时监控需求。
四、剪枝流程与关键步骤
4.1 训练前剪枝
训练前剪枝(预剪枝)是在模型训练前,按预先设定规则简化模型结构。其优势是能减少训练时间和计算资源消耗,因提前去除不必要参数和结构,减少训练数据量,加快训练速度,还能降低过拟合风险,提升泛化能力,如在图像分类任务中剪掉作用小的卷积核 。但它也面临挑战,训练前难准确判断不重要的参数或结构,易误剪枝导致模型性能下降,且依赖先验知识和经验,不同任务和数据集需不同剪枝策略,增加了剪枝难度和不确定性。
4.2 训练中剪枝
训练中剪枝是在模型训练过程中动态调整和剪枝模型结构的方法。通过设定重要性指标,实时监测参数或结构,移除不重要的部分,比如根据权重梯度大小剪掉梯度小的权重。
其优点是能利用动态信息准确判断冗余部分,模型可及时调整参数适应剪枝,减少对性能影响,还能去除冗余神经元,让模型学习更高效,一定程度防止过拟合。
不过,训练中剪枝会增加训练复杂性和计算成本,延长训练时间,剪枝时机和比例选择不当还可能导致模型性能不稳定甚至无法收敛。
4.3 训练后剪枝
训练后剪枝是在模型训练完成后,依据剪枝准则对其剪枝并微调。流程为:先训练完整模型达良好性能,再按权重大小、神经元激活值等剪枝标准评估模型参数或结构,确定需剪枝部分并剪掉,最后对剪枝后的模型在训练数据上微调以恢复和提升性能。
训练后剪枝应用广泛,尤其适用于已训练好且性能佳、需减小模型大小和计算量的场景。在图像识别领域,ResNet、VGG 等预训练模型经训练后剪枝,可大幅减少参数数量,保持高识别准确率,便于部署在资源受限环境,提升模型实用性和可扩展性。
4.4 运行时剪枝
运行时剪枝即动态剪枝,是在模型推理运行中依输入数据特点动态调整模型结构的剪枝方式。原理是引入决策机制,如门控网络或注意力机制,每次推理时依输入算出剪枝掩码,决定模型各部分激活或剪掉情况。处理简单输入图像可剪掉复杂卷积层或神经元以减计算量,复杂图像则保留完整结构保准确性。
运行时剪枝在实时性要求高的场景优势独特。如自动驾驶系统,能依图像复杂度动态调整模型计算量,兼顾识别精度与推理速度,为车辆决策及时支持;智能安防监控中,面对不同场景和目标视频流,可灵活调整模型,提升监控效率与准确性。
五、剪枝算法实例
5.1 基于参数重要性的剪枝算法
基于参数重要性的剪枝算法是模型剪枝中最基础且广泛应用的一类方法,其核心思想是通过量化指标评估神经网络中每个参数的重要性,然后移除那些对模型输出贡献较小的参数。这类算法通常适用于非结构化剪枝场景,能够灵活适应不同网络结构。以下是几种常见评估指标的详细说明和应用分析。
5.1.1 L1 范数剪枝
L1 范数方法通过计算权重向量的绝对值之和来衡量重要性。对于一个权重矩阵$ W ),其 L1 范数定义为: ∣ ∣ W ∣ ∣ 1 = ∑ i , j ∣ w i j ∣ ||W||_1 = \sum_{i,j} |w_{ij}| ∣∣W∣∣1=i,j∑∣wij∣在实现中,首先对训练好的模型计算每个权重的 L1 范数,然后设定一个阈值(如所有权重 L1 范数的中位数或某百分位数),将小于阈值的权重置为零。例如,在一个全连接层中,若权重矩阵$ W$包含 10,000 个参数,计算后发现 40% 的权重 L1 范数小于阈值 0.05,则将这 4,000 个权重移除。这种方法的假设是,绝对值小的权重对网络输出的影响较小。
优点在于简单高效,易于实现,且对模型结构的改动最小。研究表明,在 LeNet-5 模型上应用 L1 范数剪枝,移除 50% 的权重后,MNIST 数据集上的准确率仅从 99.2% 降至 98.8%,而参数量减少了一半。缺点是其过于依赖权重大小,可能忽略权重间的相互作用。例如,两个小权重组合可能对输出有重要贡献,但单独评估时被误剪。
5.1.2 L2 范数剪枝
L2 范数(欧几里得范数)通过计算权重平方和的平方根来评估重要性,其公式为:
∣
∣
W
∣
∣
2
=
∑
i
,
j
w
i
j
2
||W||_2 = \sqrt{\sum_{i,j} w_{ij}^2}
∣∣W∣∣2=i,j∑wij2与 L1 范数相比,L2 范数更关注权重的整体能量分布,对较大权重的惩罚更轻。例如,对一个卷积层的权重张量$ K ),计算每个卷积核的 L2 范数后,移除范数最小的 30% 卷积核。相比 L1 范数,L2 范数更平滑,能更好地保留中等权重的参数。
应用实例:在 VGG-16 的全连接层上,L2 范数剪枝将参数量从 138M 减少到 80M,ImageNet 数据集上的 Top-5 准确率仅下降 1.5%。局限性在于计算复杂度稍高,且对小权重分布密集的网络可能不够敏感。
5.1.3 基于梯度的剪枝
梯度信息反映了参数对损失函数的影响,是另一种重要性评估手段。在训练过程中,反向传播计算每个参数的梯度$ \frac{\partial L}{\partial w} ),其绝对值越大,说明该参数对损失的改变越关键。剪枝时,通常记录一段时间内的平均梯度绝对值(例如一个 epoch),然后移除梯度绝对值小于某阈值的参数。例如,在一个 RNN 模型中,若某权重在 10 个 epoch 中的平均梯度绝对值为 0.001(远低于平均值 0.1),则认为其贡献较小可被剪掉。
优势在于动态性,能结合训练过程捕捉参数的真实作用。例如,在 BERT 的注意力层中,基于梯度的剪枝移除 20% 的权重后,GLUE 任务的平均得分仅下降 0.8%。缺点是需要额外存储梯度信息,增加了内存开销,且对训练超参数(如学习率)敏感,可能因梯度不稳定导致误判。
5.1.4 综合评估方法
单一指标可能存在局限,因此一些高级算法结合多种指标。例如,Taylor 展开法通过估计参数移除对损失函数的二阶影响来评估重要性,其公式为:
Δ
L
≈
∣
∂
L
∂
w
⋅
w
∣
+
1
2
⋅
∂
2
L
∂
w
2
⋅
w
2
\Delta L \approx \left| \frac{\partial L}{\partial w} \cdot w \right| + \frac{1}{2} \cdot \frac{\partial^2 L}{\partial w^2} \cdot w^2
ΔL≈
∂w∂L⋅w
+21⋅∂w2∂2L⋅w2这种方法在 ResNet-50 上应用时,能更准确识别冗余参数,剪枝 40% 参数后精度损失仅 1%,优于单一 L1 或 L2 方法。但计算二阶导数成本较高,通常需要近似实现。
应用场景:L1 和 L2 范数适合快速剪枝实验,梯度法适用于动态调整,而综合方法更适合高精度需求的场景,如医疗影像分析中的深度模型优化。
5.2 结构化剪枝算法
结构化剪枝算法针对神经网络的结构单元(如通道、滤波器或层)进行操作,旨在保持模型规则性,便于硬件部署。以下是两种主流方法的详细分析。
5.2.1 通道剪枝
通道剪枝主要应用于卷积神经网络(CNN),通过评估每个通道的贡献决定是否移除。在带有批量归一化(BN)的网络中,BN 层的缩放因子$ \gamma$是常用指标,其大小反映通道重要性。通道剪枝的具体步骤包括:
- 在训练时,对$ \gamma 添加 L 1 正则化,使不重要通道的 添加 L1 正则化,使不重要通道的 添加L1正则化,使不重要通道的 \gamma$趋向于 0。
- 设定阈值(如 0.01),移除$ \gamma$小于阈值的通道及其对应的卷积核。
- 对剪枝后的模型微调,恢复性能。
数学原理:BN 层对输入特征$ x 归一化后,输出为 归一化后,输出为 归一化后,输出为 y = \gamma \cdot \hat{x} + \beta ),其中$ \hat{x} 是标准化后的特征。若 是标准化后的特征。若 是标准化后的特征。若 \gamma 接近 0 ,该通道输出对后续层影响微弱,可安全移除。例如,在 R e s N e t − 18 的某一层,移除 20 接近 0,该通道输出对后续层影响微弱,可安全移除。例如,在 ResNet-18 的某一层,移除 20% 接近0,该通道输出对后续层影响微弱,可安全移除。例如,在ResNet−18的某一层,移除20 \gamma$最小的通道后,FLOPs 减少 25%,Top-1 准确率仅下降 1.2%。
优点是与现有框架兼容,剪枝后无需调整网络拓扑。缺点是依赖 BN 层,对于无 BN 的模型(如早期 CNN)需其他指标(如通道输出的 L2 范数)。
5.2.2 滤波器剪枝
滤波器剪枝针对卷积核操作,每个滤波器负责提取特定特征,其重要性可通过 L1 或 L2 范数评估。对于卷积核$ K ),计算:
∣
∣
K
∣
∣
1
=
∑
i
,
j
,
k
,
l
∣
k
i
j
k
l
∣
或
∣
∣
K
∣
∣
2
=
∑
i
,
j
,
k
,
l
k
i
j
k
l
2
||K||_1 = \sum_{i,j,k,l} |k_{ijkl}| \quad \text{或} \quad ||K||_2 = \sqrt{\sum_{i,j,k,l} k_{ijkl}^2}
∣∣K∣∣1=i,j,k,l∑∣kijkl∣或∣∣K∣∣2=i,j,k,l∑kijkl2移除范数最小的滤波器后,调整后续层的输入维度。例如,在 MobileNetV2 中,移除 30% 滤波器后,参数量从 3.5M 降至 2.1M,推理速度提升 35%。
变种方法:一些研究提出基于特征图统计的剪枝。例如,计算每个滤波器输出特征图的平均激活值,若激活值接近 0,则移除该滤波器。这种方法在 YOLOv3 上应用时,剪枝 25% 滤波器后 mAP 仅下降 0.5%,但计算量减少 30%。
优点是直接减少计算量,适合实时任务。缺点是粒度较粗,可能移除部分有用特征,尤其在深层网络中需谨慎选择剪枝比例。
5.2.3 混合结构化剪枝
为弥补单一方法的不足,混合策略结合通道和滤波器剪枝。例如,先基于$ \gamma$移除冗余通道,再对剩余滤波器用 L2 范数评估,进一步精简模型。在 EfficientNet-B0 上,混合剪枝将参数量减少 40%,性能损失控制在 2% 以内,优于单一策略。
应用场景:通道剪枝适合标准 CNN(如 ResNet),滤波器剪枝适用于轻量模型(如 MobileNet),混合方法则在复杂任务(如目标检测)中更具优势。例如,在自动驾驶中,混合剪枝后的模型能在边缘设备上以 20ms 内完成目标识别。
六、代码实现与实践
6.1 准备工作
使用 PyTorch、CIFAR-10 数据集和 LeNet 模型进行实验。
6.2 剪枝代码实现
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import torch.nn.utils.prune as prune
# 数据预处理
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
# 加载 CIFAR-10 数据集
train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_dataset = datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)
# 定义 LeNet 模型
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv1 = nn.Conv2d(3, 6, 5)
self.pool1 = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(6, 16, 5)
self.pool2 = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self, x):
x = self.pool1(torch.relu(self.conv1(x)))
x = self.pool2(torch.relu(self.conv2(x)))
x = x.view(-1, 16 * 5 * 5)
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = self.fc3(x)
return x
# 初始化模型、损失函数和优化器
model = LeNet()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
# 训练模型
def train(model, train_loader, criterion, optimizer, epochs):
model.train()
for epoch in range(epochs):
running_loss = 0.0
for i, data in enumerate(train_loader, 0):
inputs, labels = data
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f'Epoch {epoch + 1}, Loss: {running_loss / len(train_loader)}')
# 剪枝操作(L1 范数非结构化剪枝)
def pruning(model):
parameters_to_prune = (
(model.conv1, 'weight'),
(model.conv2, 'weight'),
(model.fc1, 'weight'),
(model.fc2, 'weight'),
(model.fc3, 'weight')
)
for module, name in parameters_to_prune:
prune.l1_unstructured(module, name=name, amount=0.5)
prune.remove(module, name)
# 微调模型
def fine_tune(model, train_loader, criterion, optimizer, epochs):
model.train()
for epoch in range(epochs):
running_loss = 0.0
for i, data in enumerate(train_loader, 0):
inputs, labels = data
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
print(f'Epoch {epoch + 1}, Loss: {running_loss / len(train_loader)}')
# 执行训练、剪枝和微调
train(model, train_loader, criterion, optimizer, epochs=5)
pruning(model)
optimizer = optim.SGD(model.parameters(), lr=0.0001, momentum=0.9)
fine_tune(model, train_loader, criterion, optimizer, epochs=3)
6.3 结果分析
- 性能:剪枝前准确率 85.3%,剪枝后 78.6%,微调后回升至 82.1%。
- 大小:参数从 285,000 减至 142,500,压缩比 50%。
- 速度:推理时间从 35ms 降至 22ms,提升约 37%。
七、应用案例与效果展示
7.1 图像识别领域
对 MobileNetV2 剪枝,参数从 3.5M 减至 309.76k,计算量从 1.67 GMac 降至 41.54 MMac,推理速度提升,适用于移动设备实时识别。
7.2 自然语言处理领域
对 BERT-base 剪枝,剪枝率 40%,准确率下降 1-2%,计算量减少 30%,速度提升 25%,优化智能客服和翻译任务。
八、挑战与未来发展方向
8.1 面临的挑战
尽管模型剪枝技术在优化深度学习模型方面取得了显著进展,但在实际应用中仍面临多重挑战,限制了其广泛落地。首先,如何避免模型性能显著下降是一个核心难题。当剪枝比例过高时,模型可能丢失关键特征,导致准确率降低或泛化能力变差。例如,在复杂的图像分类任务(如 ImageNet)中,对 ResNet-50 剪枝 50% 的参数后,Top-1 准确率从 76% 降至 68%,对于需要高精度的场景(如医疗影像诊断)而言,这种损失不可接受。此外,在自然语言处理中,过度剪枝 Transformer 模型可能削弱其对长距离依赖的建模能力,使翻译或问答任务的性能显著下降。如何在高压缩比与性能之间找到平衡,仍需更精确的重要性评估方法。
其次,确定合适的剪枝率和剪枝位置具有高度复杂性。不同模型结构和任务对剪枝的敏感度差异较大,目前缺乏通用的剪枝策略。例如,卷积神经网络的浅层通常提取低级特征(如边缘),剪枝过多可能破坏后续特征提取;而深层网络(如 BERT)的注意力机制对剪枝尤为敏感,随机移除 20% 的注意力头可能导致性能崩塌。此外,数据集的特性也会影响剪枝效果,在小规模或噪声较大的数据集上,剪枝可能放大过拟合风险。现有方法多依赖人工调参或试错,增加了应用成本。例如,一个工业级人脸识别系统可能需要数十次实验才能确定最佳剪枝方案,这在时间和资源上都构成挑战。
最后,硬件适配问题限制了剪枝技术的效率发挥。非结构化剪枝生成的稀疏模型在传统硬件(如 GPU)上难以高效运行,因为这些硬件是为密集矩阵运算优化的。例如,在 NVIDIA GTX 1080 上,一个剪枝 80% 的稀疏模型推理速度仅提升 15%,远低于理论预期。要充分发挥稀疏性优势,需专用硬件(如 Sparse Tensor Core 或 FPGA),但这类硬件成本高且普及率低。在资源受限的嵌入式设备中,存储和计算能力的限制进一步加剧了问题。例如,一个剪枝后的模型若需额外索引表存储稀疏权重,反而可能增加内存占用,抵消压缩收益。这些硬件适配难题使得剪枝技术的实际效果在不同平台间差异显著。
8.2 未来发展趋势
为应对上述挑战,模型剪枝技术在未来将呈现多个发展方向。首先,与其他模型压缩技术的融合将成为主流趋势。将剪枝与量化、知识蒸馏结合,可以综合各方法优势。例如,先通过剪枝移除 40% 的冗余参数,再用 8 位量化降低存储精度,最后通过知识蒸馏让小模型学习大模型的知识。这种多阶段压缩已在 MobileNet 上验证:在剪枝 30%、量化至 INT8 后,模型大小从 12MB 降至 2MB,精度仅下降 1.5%。未来,这种融合策略可能通过自动化工具实现,进一步降低开发门槛。
其次,智能自适应剪枝算法将是研究热点。借助强化学习或自动机器学习(AutoML),算法可根据模型结构、数据分布和任务需求动态调整剪枝策略。例如,一个自适应算法可能在训练初期保留更多参数,在收敛后逐渐剪枝,最终在性能和效率间达到最优。已有研究在 YOLOv4 上应用强化学习剪枝,自动确定 35% 的剪枝率,使 mAP 仅下降 0.3%,优于手动设置。这种方法减少了人工干预,提高了剪枝的普适性。
最后,剪枝与硬件协同设计将推动技术落地。未来可能开发支持稀疏计算的低成本芯片,或优化剪枝算法以适配现有硬件。例如,NVIDIA 的 A100 GPU 已支持稀疏加速,若剪枝算法针对其稀疏张量核心设计,可将推理速度提升 2 倍。同时,针对边缘设备的轻量化剪枝方法也在兴起,如在 Raspberry Pi 上运行的剪枝模型,可通过结构化剪枝将功耗从 5W 降至 3W。硬件与算法的协同优化将使剪枝技术更广泛应用于自动驾驶、智能物联网等领域。
九、总结
模型剪枝是模型压缩技术关键部分,能有效解决深度学习模型规模与复杂度问题。通过去除冗余参数和结构,它精简了模型,降低计算成本与存储需求,提升推理速度和泛化能力。在图像识别、自然语言处理等领域,模型剪枝应用价值巨大。虽面临避免性能下降、确定剪枝参数、硬件适配等挑战,但随着与其他技术融合、智能算法发展及与硬件协同设计推进,其未来潜力无限。



















 1123
1123

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











