







sns.clustermap() —— 层次聚类热力图(Cluster Map)
seaborn.clustermap() 用于 对数据进行聚类(Clustering)并可视化热力图,适用于 数据分布分析、特征关联、相似性分析,特别适合 机器学习和数据挖掘。
1. 语法
import seaborn as sns
sns.clustermap(data, method="average", metric="euclidean", cmap=None, standard_scale=None, z_score=None, annot=False)
主要参数
| 参数 | 作用 |
|---|---|
data | 矩阵数据(DataFrame / Numpy 数组) |
method | 聚类方法("single"、"complete"、"average"、"ward") |
metric | 距离度量("euclidean"、"cosine"、"correlation") |
cmap | 颜色方案(如 "coolwarm"、"Blues") |
standard_scale | 对行/列归一化(0 归一化行,1 归一化列) |
z_score | Z-score 标准化(0 行标准化,1 列标准化) |
annot | 是否 显示数值(True 显示) |
2. 相关性聚类
2.1 计算相关性矩阵并聚类
import seaborn as sns
import matplotlib.pyplot as plt
# 加载数据
data = sns.load_dataset("penguins")
# 计算相关性
corr = data.corr(numeric_only=True)
# 绘制层次聚类热力图
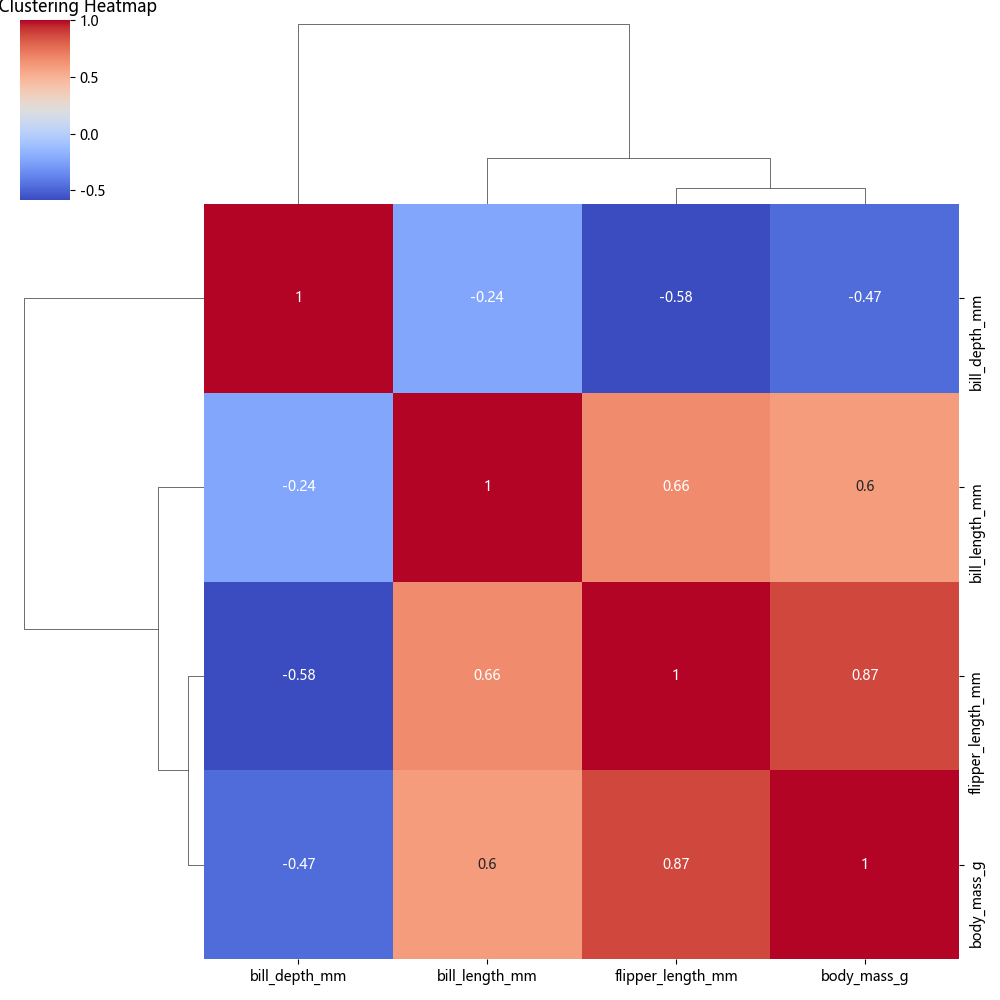
sns.clustermap(corr, method="average", cmap="coolwarm", annot=True)
plt.title("Feature Clustering Heatmap")
plt.show()
📌 作用
- 自动对相关性矩阵聚类,找到相似的特征。
method="average"使用 平均距离 计算聚类。
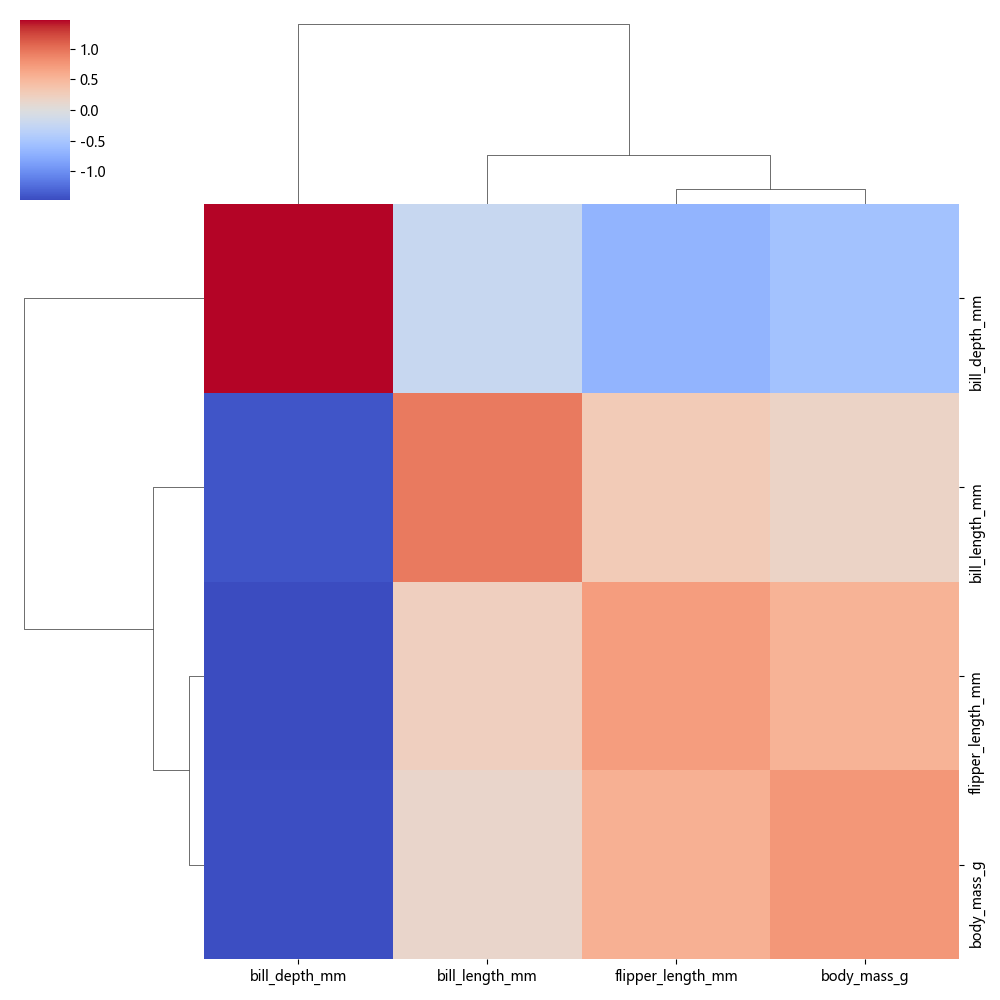
2.2 只对行或列标准化
sns.clustermap(corr, cmap="coolwarm", z_score=0) # 按行标准化
plt.show()
📌 作用
z_score=0→ 对行进行标准化,使不同变量可比较。
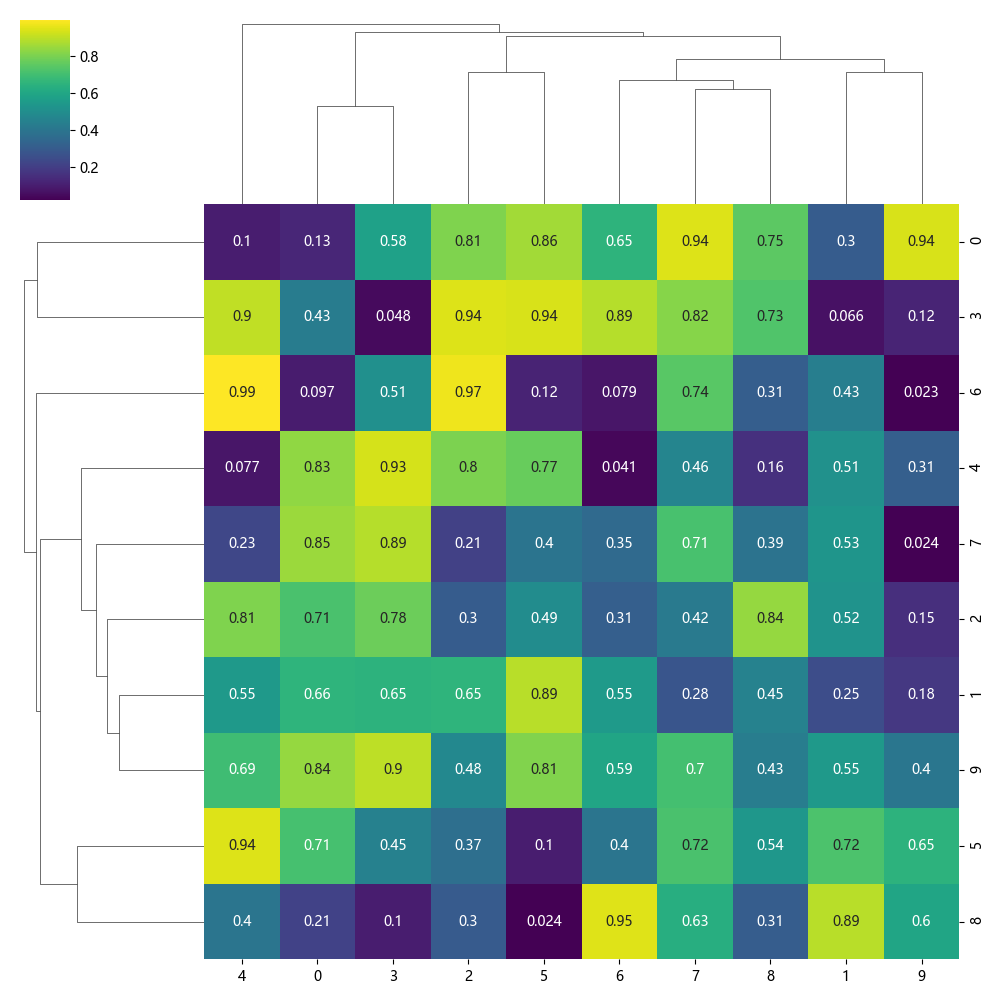
3. 适用于数据分布分析
3.1 生成随机数据并聚类
import numpy as np
# 生成 10x10 矩阵
data = np.random.rand(10, 10)
sns.clustermap(data, cmap="viridis", annot=True)
plt.show()
📌 作用
- 适用于 查看数据分布 & 聚类结构。
3.2 选择不同距离度量
sns.clustermap(corr, metric="cosine", cmap="coolwarm", annot=True)
plt.show()
📌 作用
metric="cosine"使用余弦相似度进行聚类。
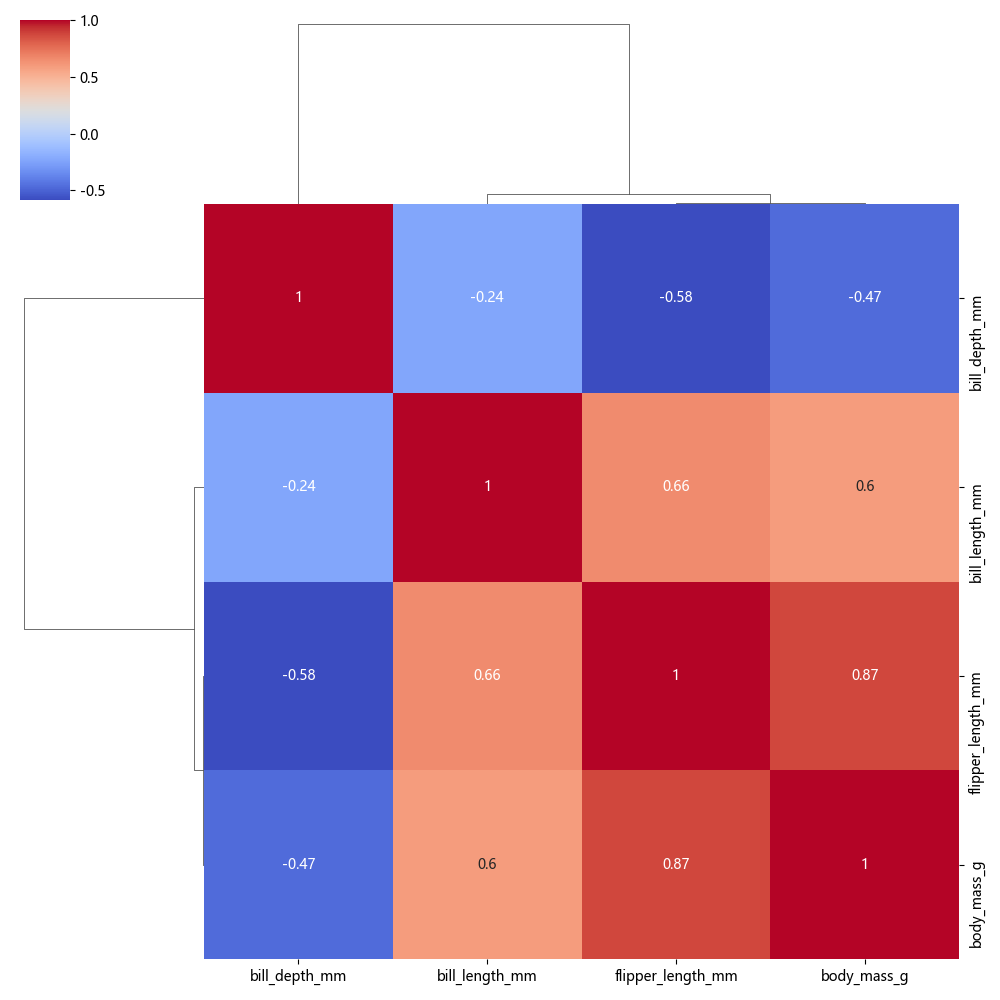
3.3 选择不同聚类方法
sns.clustermap(corr, method="ward", cmap="coolwarm", annot=True)
plt.show()
📌 作用
method="ward"使用ward进行层次聚类。
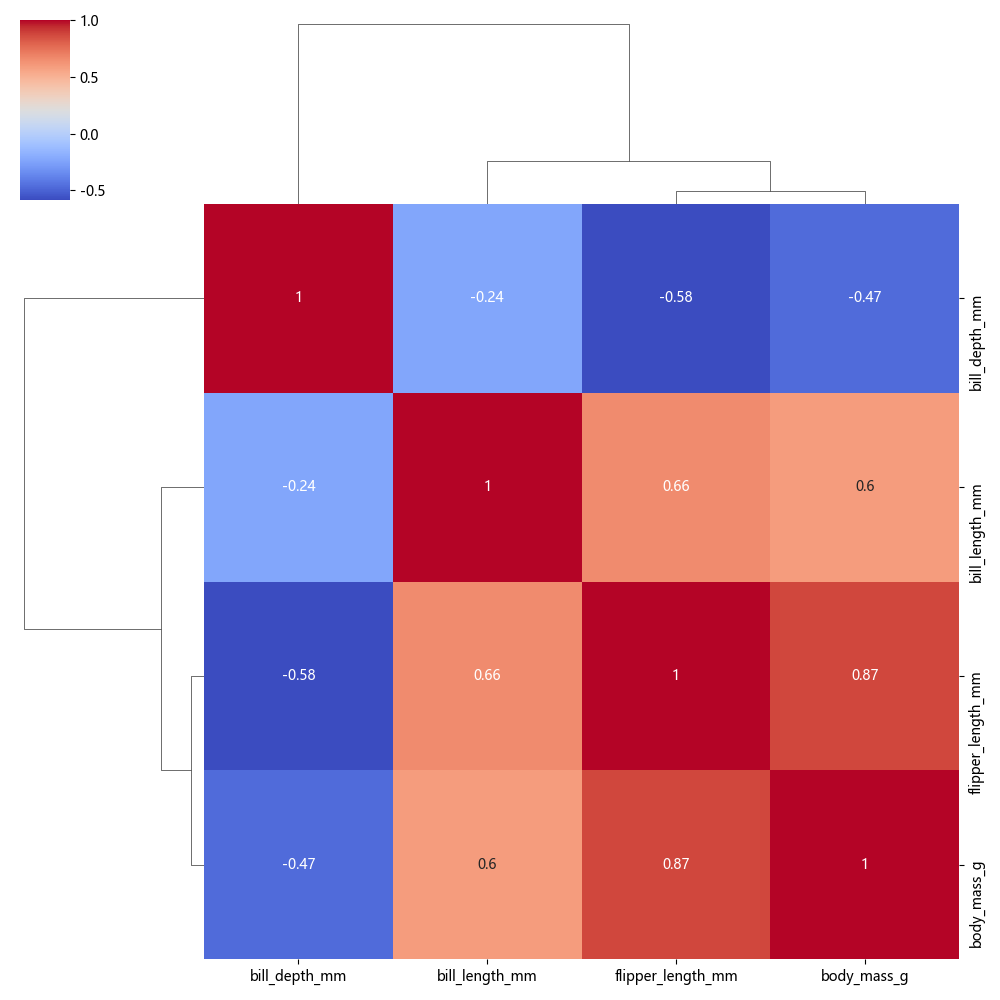
4. sns.clustermap() vs sns.heatmap()
sns.clustermap() | sns.heatmap() | |
|---|---|---|
| 作用 | 自动聚类 | 静态热力图 |
| 适用于 | 发现数据结构、聚类分析 | 可视化矩阵 |
sns.heatmap(corr, cmap="coolwarm", annot=True)
plt.show()
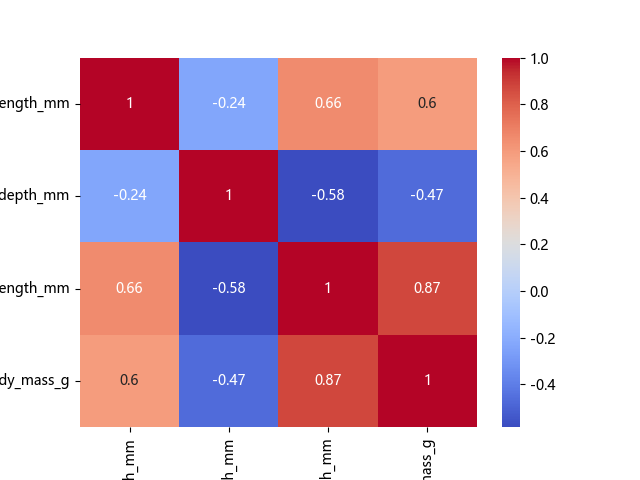
5. 总结
✅ sns.clustermap() 适用于层次聚类可视化,特别是相关性分析和数据挖掘。
✅ 常见参数
method="ward"不同聚类方法,metric="euclidean"不同距离度量。standard_scale=1列归一化,z_score=0行标准化。


















 5684
5684

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











