







论文:Focal Loss for Dense Object Detection
论文链接:https://arxiv.org/abs/1708.02002
解决问题:
提出一种新的损失函数:focal loss。该函数通过减少容易分类的样本的权重,使得模型在训练时更专注难分类的样本,从而改善样本的类别不均衡问题,改善模型的优化方向。
难分类样本:
举例说明:假设一个二分类,样本x1属于类别1的概率pt=0.9,样本x2属于类别1的概率pt=0.6,显然x1更可能为类别1,x2更加难以分类。因此,相对而言,x2为难分类样本。
出发点:
提高one-stage detector的准确率。作者认为:one-staget detector的准确率比不上two-stage detector,是样本的类别不均衡导致的。由于YOLO,SSD这类算法,是对bounding box直接进行回归,使得负样本数量太大,占总的loss的大部分,而且多是容易分类的,因此使得模型的优化方向并不是我们所希望的那样。
现有算法:
OHEM (online hard example mining)
思想:在OHEM中,利用每个样本的loss对其进行从大到小排序,然后采用非最大性抑制,选取前N个loss最高的样本。
缺点:OHEM算法虽然增加了错分类样本的权重,但是忽略了容易分类的样本。也就是说,loss高的样本同时包括难分类样本和容易分类的样本,应该更多的去保留难分类样本,而不是容易分类的样本。
算法细节:
1.交叉熵损失,以二分类为例:
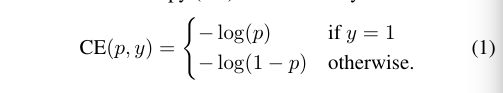
因为是二分类,所以y为+1或者-1,因此p的范围为[0,1]。
为了方便,利用pt来表示p,pt定义如下:
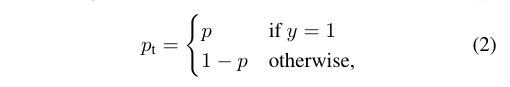
因此,公式(1)可以重写为:
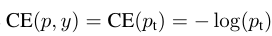
2.增加系数at,以控制正负样本比例:
下面介绍一个最基本的对交叉熵的改进,将作为本文实验的Baseline。
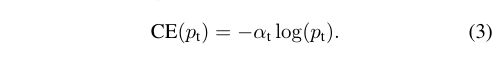
系数at,与pt的定义类似,当label=1的时候,at=a;当label=-1的时候,at=1-a,a的范围也是0到1。因此,可以通过设定a的值来控制正负样本对总的loss的共享权重。
比如说,假如1这个类的样本数比-1这个类的样本数多很多,那么a会取0到0.5来增加-1这个类的样本的权重。
3.利用γ,以控制难易样本比例:

这里的 γ 称作focusing parameter,γ>=0 .
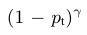
因此,focal loss具有两个重要性质:
1)当一个样本被分错的时候(结合公式2,例如当y=1时,p小于0.5才是错分类,此时pt就比较小,反之亦然),pt是很小的,因此调制系数趋于1,也就是说,相比原来的loss没有大的改变。而当样本分类正确而且是易分类样本的时候,pt趋于1,调制系数趋于0,对总的loss贡献很小。
2)当γ=0的时候,focal loss就是传统的交叉熵损失。当γ增加的时候,调制系数也会增加。
也就是,focal loss这个公式可以度量难分类和易分类样本对总的损失的贡献。
4.最终focal loss:
结合公式(3)和 公式(4),得出公式(5):
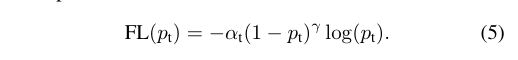
该公式既可以调整正负样本的权重,又能控制难易分类样本的权重。
实验结果:
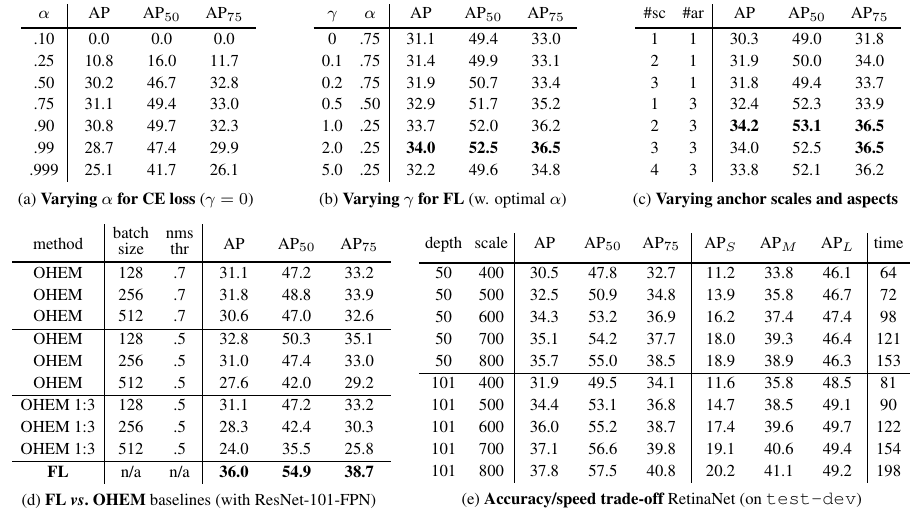
可以看到,γ=2,a=0.25的时候效果最好。















 2260
2260

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









