






Pooja S. B. Rao pooja.rao@unil.ch
洛桑大学
瑞士洛桑
国际信息技术学院
印度班加罗尔
Sanja Šćepanović
sanja.scepanovic@nokia-bell-labs.com
诺基亚贝尔实验室
英国剑桥
周克
ke.zhou@nokia-bell-labs.com
诺基亚贝尔实验室
英国剑桥
英国诺丁汉大学
英国诺丁汉
Edyta Paulina Bogucka edyta.bogucka@nokia-bell-labs.com 诺基亚贝尔实验室 英国剑桥
英国剑桥大学 英国剑桥
Daniele Quercia
quercia@cantab.net
诺基亚贝尔实验室
英国剑桥
都灵理工大学
意大利都灵
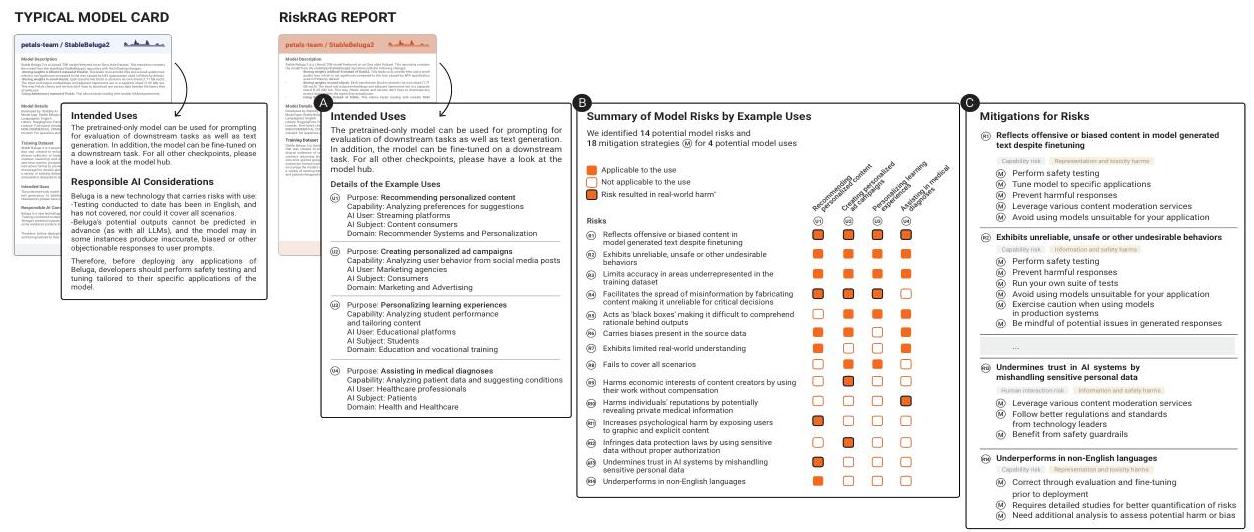
图1:典型的模型卡(左侧)与使用RiskRAG生成的报告(右侧)的对比。典型模型卡忽略了风险讨论(86%的模型卡如此),而RiskRAG报告包括示例模型用途(A)、按用例分类的风险摘要(B)和相应的缓解措施(C)。
摘要
风险报告对于记录AI模型至关重要,但只有14%的模型卡提到风险,其中96%复制了少量卡片的内容,导致缺乏可操作见解。现有改进模型卡的提议未能解决这些问题。为应对这一挑战,我们引入了RiskRAG,这是一种基于检索增强生成的风险报告解决方案,由我们从文献中识别出的五个设计要求指导,并与16位开发者共同设计:识别多样化的模型特定风险、清晰呈现并优先排序这些风险、针对实际应用情境进行上下文化处理,并提供可操作的缓解策略。通过结合45万张模型卡和600个真实世界事件,RiskRAG预填充了上下文化的背景化风险报告。初步研究表明,50位开发者更倾向于RiskRAG而非标准模型卡,因为它更好地满足了所有设计要求。最终研究显示,38位开发者、40位设计师和37位媒体专业人士认为RiskRAG改善了他们选择特定应用场景AI模型的方式,鼓励了更加谨慎和深思熟虑的决策过程。RiskRAG项目页面可通过以下链接访问:https://social-dynamics.net/ai-risks/card.
CHI '25, 2025年4月26日-5月1日,日本横滨
(c) 2025 版权由作者/版权所有者持有。
这是作者版本的作品。它发布在这里仅供您个人使用。禁止重新分发。正式版本已发表在CHI Conference on Human Factors in Computing Systems (CHI '25),2025年4月26日-5月1日,日本横滨,https://doi.org/10.1145/3706598.3713979。
## CCS概念
- 以人为中心的计算 → 实证研究在协作和社会计算中; · 计算方法论 → 人工智能;机器学习。
关键词
AI风险,负责任的AI,AI模型,模型卡,风险报告,危害,事件
ACM参考格式:
Pooja S. B. Rao, Sanja Srepanović, Ke Zhou, Edyta Paulina Bogucka 和 Daniele Quercia。2025年。RiskRAG:一种数据驱动的改进AI模型风险报告解决方案。在CHI Conference on Human Factors in Computing Systems (CHI '25),2025年4月26日-5月1日,日本横滨。ACM,纽约,NY,美国,26页。https://doi.org/10.1145/3706598.3713979
1 引言
随着人工智能(AI)日益普及,识别和报告AI模型的潜在风险对于其负责任和值得信赖的发展和使用至关重要[18]。确保AI安全贯穿于AI生命周期中的各利益相关者之间[53]。通过系统地报告风险,AI开发者可以解决诸如公平性、问责制和偏见等伦理问题[32, 70],使AI模型与社会价值观保持一致并减少伤害。分享风险和缓解策略使应用开发者和组织能够提高AI技术的安全性和可靠性。最后,透明的风险报告帮助消费者和技术用户了解AI系统的潜在风险,从而做出知情决定[22],同时解决更广泛的社会考虑因素[71],支持符合如欧盟AI法案[14]和美国AI权利法案[30]等监管框架。
模型卡已成为报告AI模型的既定标准,被主要科技公司和个别AI开发者广泛采用。例如,HuggingFace 1 { }^{1} 1——最受欢迎的模型存储库平台之一,托管了75万个AI模型,其中有45万个具有模型卡。最初由Mitchell等人提出[48],模型卡旨在标准化伦理报告、澄清预期用途,并记录AI模型的风险和局限性。模型卡包含技术信息部分,如模型描述、模型使用、训练和评估细节、版本和许可证,以及关于预期用途、伦理考虑、风险和局限性、超出范围的用途和误用的部分。
尽管模型卡有其意图,研究表明只有 17 % 17 \% 17%的模型卡简要提及了与偏差或伦理相关的问题 [4, 37]。我们对2024年7月的450 K模型卡快照分析发现,这个比例为 14 % 14 \% 14%(即,64 K模型卡报告了风险)。此外,令人震惊的是, 96 % 96 \% 96%的这些卡片内容是从最初的2672张卡片复制而来(即完全相同)。此外,大多数模型文档不足以推理模型采用的影响,因为模型卡中的风险部分经常因过于模糊和通用而受到批评,这限制了它们在决策过程中的实际应用 [ 4 , 15 ] [4,15] [4,15]。即使是对拥有AI知识的从业者和研究人员来说,预见AI系统或模型的风险也是一项困难的任务 [8, 19]。越来越多的真实世界AI事件和伤害 [45, 68] 可能部分归因于部署模型时与之相关的风险缺乏透明度 [4, 13]。风险可以报告为“模型特定”,即源于模型的独特能力和局限性(例如,延续训练数据中的有害偏见),或者“用途特定”,即与特定应用相关的上下文化风险(例如,在转录虚拟会议时影响参与者的偏见)。
两个关键的研究领域试图解决这些挑战(表7)。第一个领域关注增强AI风险文档和开发支持工具包。现有研究探讨了改进模型卡可用性和有效性的方法,例如引入交互性 [15]、采用提示格式如DocML [4]、将AI文档视为正式项目交付物 [13] 来鼓励更好的文档实践。这些努力有助于改进特定模型的风险报告,特别是技术和能力相关风险。然而,它们往往未能针对具体用途进行风险情境化 [58]。随着法律框架(如欧盟AI法案)越来越重视在使用情境中评估AI系统 [14],这一差距变得愈发重要。为了补充模型文档,研究人员引入了Risk Cards [17],一种新的文档格式。虽然Risk Cards强调针对具体用途情境化风险的重要性,但它们设计用于单独记录各个风险。因此,代表单一AI模型的完整风险光谱需要多个Risk Cards。此外,Risk Cards明确不鼓励记录具体模型,使其不适合全面的模型级风险评估。
第二个研究领域专注于开发用于填充拟议文档的工具。这些工具旨在帮助从业者设想潜在用途 [29] 并识别与AI系统相关的风险和危害 [11, 69]。然而,现有工具未考虑底层特定模型,因此不会生成特定模型风险,即那些与特定模型设计、开发或部署相关的独特漏洞或局限性。例如,虽然这些工具可能识别文本生成语言模型的一般风险,但它们无法区分不同模型之间的独特风险,例如由于特定训练数据(例如,非工作安全图像)而导致的风险。对于模型卡而言,已经提出了一个名为CardGen [39] 的检索增强生成(RAG)[36] 解决方案来协助填写它们。然而,CardGen在填充风险部分时遵循现有的文本格式,强化了先前研究中所批评的相同缺点 [4,37] 而不是解决问题 [4,15]。
为了应对AI模型风险报告的挑战,我们在两个研究领域的基础上进行了改进和贡献。在此过程中,我们做出了三项关键贡献:
(1) 提升的AI模型风险报告 ($3)。包括风险报告在内的模型报告对AI发展的三个阶段(开发、部署和使用)中的各种利益相关者都很重要 [48],因为它促进了具有不同角色的群体之间的有效沟通 [27]。我们的关键目标受众是通常创建模型卡的AI开发者。我们通过文献回顾和与16位有经验的AI开发者进行迭代共设计研究,确定了AI模型风险报告的五个关键设计要求。这些要求包括:识别多样化的模型特定风险、清晰展示风险、优先排序、针对实际用途进行情境化处理,并提供可操作的缓解策略。
(2) 使用RiskRAG自动填充报告 ($4)。我们开发了一种解决方案,以支持开发者生成符合上述五个设计要求的可行且易于理解的模型风险报告。我们的方法是数据驱动的,利用现有数据库中的人工编写的AI模型风险和局限性(即,开发者在模型卡中报告的风险和媒体专业人员在AI事件报告中报告的风险)。具体而言,从HuggingFace的初始450 K模型卡中,我们编制了一个包含2672张卡片的数据集,这些卡片包含独特的风险部分,并纳入了来自AI事件数据库 [45] 的649个真实世界AI事件,以捕捉多样化的风险光谱。RiskRAG利用RAG框架从这些来源检索相关风险和缓解策略,并以清晰和结构化的格式呈现(图1显示了一个例子)。
(3) 对RiskRAG报告进行实证验证 ($5)。我们首先进行了基线评估 ($5.1),以验证RiskRAG内容的质量和相关性与现有高质量模型卡(由开发者编写)相比。接下来,我们进行了一项初步用户研究 ($5.2),涉及50名AI开发者,他们在高风险招聘应用程序中倡导采用AI模型。参与者更喜欢使用RiskRAG报告完成此任务(相对于基准模型卡,74%),并在满足所有设计要求方面给予了更高评分。虽然AI开发者通常创建模型卡,但这些报告被更广泛的受众消费,包括非技术人员。因此,在最终用户研究 ($5.3) 中,我们也涉及了非技术人员,以评估RiskRAG的更广泛相关性和其一般适用性的最低性能。这项研究涉及38名开发者、40名设计师和37名媒体专业人士,他们的任务是在媒体行业任务中选择两个AI模型之一。在所有组别中,RiskRAG提高了模型选择解释中的论证,并鼓励了更加谨慎的决策过程。参与者一致更喜欢RiskRAG报告,称赞其清晰度和支持决策的能力。
我们的解决方案通过提供:(1)改进的格式,以及(2)减少开发者以该格式记录高质量风险所需的努力,从而改善风险报告。重要的是,我们视RiskRAG不仅为最终解决方案,而是协助AI开发者创建有效风险报告的工具。
2 相关工作
两个平行的相关研究领域集中在AI风险报告上(表7):(1) 开发用于记录AI风险的格式 ($2.1),和 (2) 创建自动化工具以帮助填写此类文档 ($2.2)。
2.1 AI风险文档
已提出多种形式的文档来支持负责任的AI(RAI)实践:从模型文档(如模型卡 [48])、数据集文档(如数据表单 [24]、NLP的数据声明 [3])、为使用AI的目的而制作的文档(即AI任务的伦理表单 [49]),到最近的AI风险文档(即风险卡 [17])。
Mitchell等人 [48] 引入了模型卡以实现透明的模型报告,涵盖了敏感数据、潜在风险、不当使用和缓解策略等伦理考虑。随着时间的推移,模型卡已经成为标准,得到了法规 [14]、治理框架 [63] 和主要科技公司的认可 [27]。
挑战。然而,模型文档格式仍在演变,某些部分比其他部分更常完成。对HuggingFace上的32K模型卡的分析显示,只有
17
%
17 \%
17%的所有卡片和
39
%
39 \%
39%的前100下载量最高的卡片包含风险和限制部分 [37]。另一项研究在定性分析GitHub和组织网站上的模型卡后得出了类似的发现 [4]。同样,对数据表单的分析 [24] 发现,尽管数据描述通常是完整的,但对适当数据使用的考虑却很少得到关注 [73]。梁等人 [37] 的进一步分析表明,模型卡的风险部分通常涉及数据和模型限制,主要关注技术方面。结果,开发者常常发现当前风险部分模糊且缺乏具体性 [15],导致用户需求与所提供内容之间的差距 [4]。
解决方案。为了应对这些问题,Crisan等人 [15] 探讨了互动版模型卡的设计选择,而Bhat等人 [4] 引入了DocML,一种通过提示和可追溯性改进文档实践的工具。类似地,为了激励风险报告,Chang和Custis [13] 建议将模型文档作为强制性的AI项目交付成果。此外,Kennedy-Mayo和Gord [34] 提出了重构伦理考虑部分以明确列出监管、声誉和运营风险。超越改进模型卡,Derczynski等人 [17] 引入了Risk Cards,一种专门设计用于解决风险的新类型RAI文档。Risk Cards旨在补充其他文档,通过启用个体风险目录化。
研究空白。总而言之,尽管之前的研究探索了改进AI模型文档的方法,但主要集中在一般实践上,而不是特别针对风险报告。像[34]这样的努力仍然未能将风险针对具体用途进行情境化。我们认为,只有当风险针对具体用途进行情境化时,其他类型的风险,如人机交互或系统性风险 [68],才开始显现。此外,法律框架如欧盟AI法案优先考虑在其使用情境中评估AI系统 [14]。Risk Cards确实针对具体用途情境化了风险;然而,它们只能作为补充形式的文档,而不是替代模型卡,因为它们关注个体风险而非模型,并明确反对记录与这些风险相关的具体模型。为应对这些局限性,我们通过文献知情的共设计过程导出了有效解决方案的关键设计要求。
2.2 用于填充AI风险文档的工具
报告AI风险的需求部分是由如NIST AI风险管理框架 [51] 和欧盟AI法案 [14] 等标准推动的,这些法规规定了根据特定用途和背景进行风险文档的要求 [26, 31]。因此,提出了各种AI影响评估报告
[
1
,
6
,
65
]
[1,6,65]
[1,6,65] 和卡片 [25] 来帮助AI开发者准备所需的文档,特别是对于高风险系统。
挑战。填写此文档需要想象AI系统的用途和风险。此外,AI风险评估面临的挑战 [4, 13] 是AI开发者通常难以想象具体的用途并识别相关风险 [29, 69]。
解决方案。为解决此问题,提出了几种半自动化工具。Herdel等人 [29] 引入了一个基于大型语言模型(LLM)的工具ExploreGen,以支持开发者设想潜在用途并评估每个用途相关的监管风险。Buçinca等人 [11] 提出了AHA!,这是一个结合LLM和众包的工具,有助于在开发或部署AI系统之前预测潜在危害和意外后果。Wang等人 [69] 引入了FarSight,这是另一个基于LLM的工具,专为支持处理LLM的提示开发者而设计。Bogucka等人 [7] 编制了导致现实世界危害的各种AI用途的风险,并以吸引公众的可视化方式呈现。所有这些工具都利用LLM来识别给定AI系统的潜在用途或风险。最后,Liu等人 [39] 引入了CardGen,这是一个RAG管道,帮助填补模型卡中缺失的部分,包括风险部分,使用来自相关论文和GitHub项目的资料。
研究空白。ExploreGen [29] 仅生成模型用途,而AHA![11] 和 FarSight [69] 则生成特定用途但非特定模型的风险。例如,它们无法区分两个图像生成模型之间的风险,比如一个训练于NSFW(非工作安全)图像的模型,另一个训练于安全图像的模型。前者在被滥用时应突出生成虐待、暴力或色情内容的风险,而后者可能不存在此类风险。我们将展示RiskRAG如何做出这种区分(附录E)。此外,大多数现有工具仅依赖LLM,这些工具在处理领域特定或知识密集型任务时因幻觉问题和缺乏特定领域知识的支撑而挣扎 [33, 76]。相比之下,RAG [36] 将检索与AI生成的响应相结合,减少了幻觉现象,并在无需额外训练的情况下增强了任务特定准确性 [23, 55]。
虽然CardGen [39] 使用RAG,旨在填充HuggingFace上的模型卡缺失部分,包括与风险相关的部分,但它复制了现有格式及其在先前研究中确定的局限性 [4, 37]。此外,许多HuggingFace上的模型缺乏相关研究论文或存储库,限制了CardGen在为这些模型生成风险相关内容方面的有效性。与CardGen不同,RiskRAG为所有模型卡生成更细致的风险报告,即使缺乏相关论文或外部存储库也能满足我们确定的五个设计要求。
3 从文献和迭代共设计过程得出的设计要求
我们通过回顾文献来确定初始要求(§3.1),并通过与AI开发者进行共设计研究扩展了这些要求(§3.2)。
3.1 文献中的设计要求
为了收集AI模型风险报告的要求,我们从最近的文献综述开始(图2,步骤1A)。我们的目标是创建一个基础框架,以便在后续的共设计迭代中改进模型卡风险部分。我们通过分析精选的高质量论文,而非通过详尽审查识别的大规模论文集合,揭示风险报告中的主要缺陷。先前的文献已证明这种方法能有效生成初始设计考虑 [6, 16]。
我们在ACM数字图书馆(DL)内进行了关键词搜索,如图3所示,选择这个资源是因为它包含了SIGCHI出版物和AIES及FAccT会议的会议记录,我们预计可以在其中找到相关论文。我们的搜索针对2019年及以后发表的文章,这一年标志着第一份模型报告提案——模型卡 [48] 的发表年份。初始搜索产生了326篇文章。去除扩展摘要、杂志文章和其他短篇论文或报告后,剩下263篇文章。 2 { }^{2} 2 为确保这些文章的相关性和质量,我们采用了以下纳入标准:(1) 与AI模型风险报告相关,(2) 关注AI模型的文档实践,(3) 提供用于记录AI模型的工具。
基于这些标准,我们通过标题和摘要筛选文章。这消除了大部分专注于评估模型或领域特定(如医疗保健和教育)的论文,将我们的选择缩小到六篇论文。鉴于伦理、负责任和可信AI研究的快速发展,我们还在Arxiv上进行了类似的搜索,以涵盖最新研究,这增加了两篇尚未发表但被其他研究频繁引用的论文,证明了它们的质量。最终选定的八篇论文 [ 4 , 13 , 15 , 21 , 34 , 37 , 48 , 52 ] [4,13,15,21,34,37,48,52] [4,13,15,21,34,37,48,52] 提供了关于模型文档中AI风险报告的不同方面的见解,使我们能够综合出风险报告的初始设计要求。 3 { }^{3} 3 我们对这八篇论文进行了全文定性分析。采用主题分析 [ 9 , 10 ] [9,10] [9,10],聚焦于与风险报告相关的章节,以识别报告AI模型风险的关键设计要求。前两位作者将论文分配给自己,并进行审阅以熟悉内容。采用自下而上的方法,我们对每篇论文的不同章节进行编码,并随着编码的进展不断优化。这一过程产生了20个代码,随后组织成主题地图并归纳为6个子主题。
2
{ }^{2}
2 补充材料(Supp. Mat.)可在OSF上获取 https://osf.io/chjggc。我们在Supp. Mat. 1.1中提供了所有论文的完整列表。
3
{ }^{3}
3 参见
§
2
\S 2
§2 对这些论文的回顾。附录A列出了这些论文及其与模型卡风险报告的相关性。
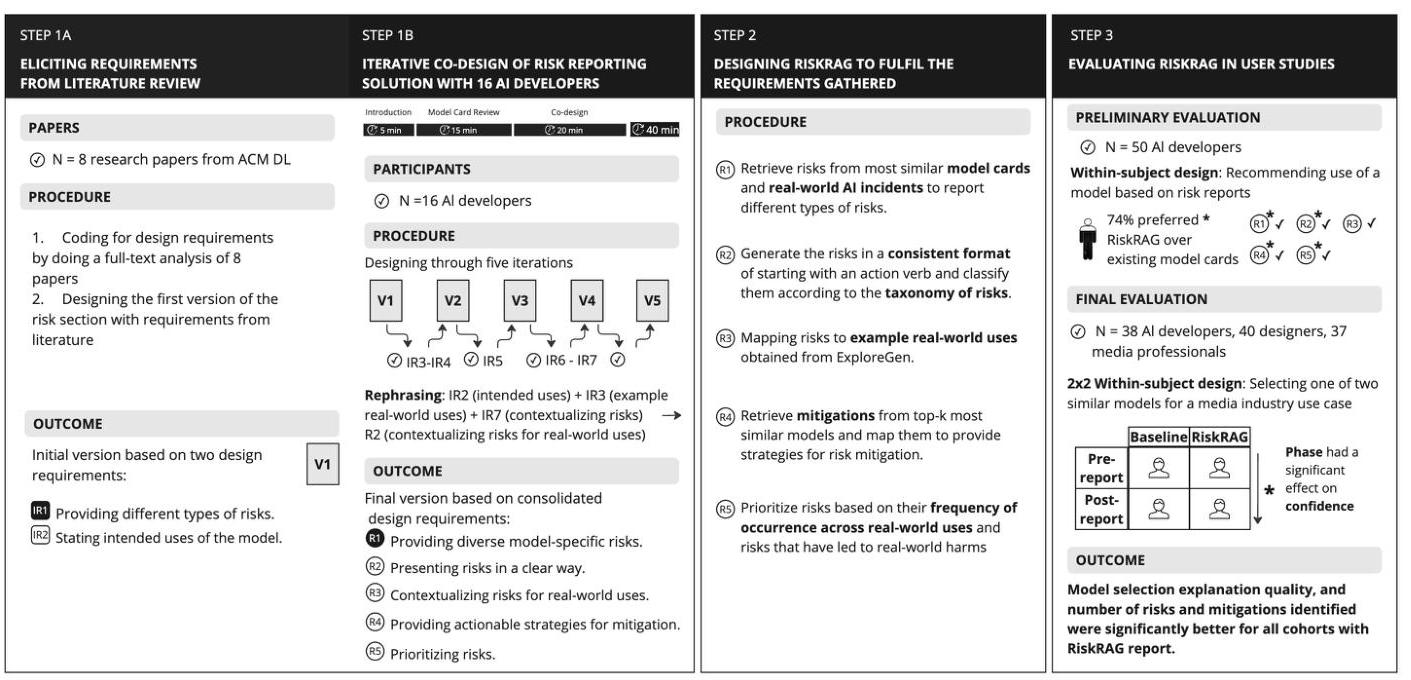
图2:我们的方法包括三个步骤。步骤1:我们通过文献和与AI开发者的共设计研究确定了设计要求(§3)。每次共设计会议包括介绍(
∼
5
m
i
n
\sim 5 \mathrm{~min}
∼5 min)、模型卡评审(
∼
15
m
i
n
\sim 15 \mathrm{~min}
∼15 min)和共设计任务(
∼
20
m
i
n
\sim 20 \mathrm{~min}
∼20 min)。经过五次迭代后,我们最终确定了关键设计要求。步骤2:我们开发了RiskRAG,使用检索增强生成来生成符合这些设计要求的风险报告,利用模型卡和事件报告的数据(§4)。步骤3:我们在两项用户研究中评估了RiskRAG报告(§5)。在初步研究中,50名AI开发者比较了RiskRAG报告和基线模型卡,评估一个AI模型用于高风险招聘场景时的表现。在最终研究中,38名AI开发者、40名UX设计师和37名媒体专业人士比较了RiskRAG报告和基线模型卡,选择两个相似AI模型用于媒体行业任务时的表现。
搜索(顶部)
关键词:(‘model cards’ OR ‘model documentation’ OR ‘model reporting’)
AND
(‘risk*’ OR ‘ethic*’ OR ‘harm*’ OR ‘bias*’ OR ‘abuse*’ OR ‘misuse*’)
AND
(‘AI’ OR ‘artificial intelligence’ OR ‘ML’, OR ‘machine learning’)
图3:用于ACM DL存储库文献综述的搜索查询。
我们生成的代码手册在Supp. Mat. 1.2中提供。最终,这些导致了两个初始设计要求(IR)(图2,步骤1A):
IR1. 提供不同类型的具体模型风险。模型的风险报告应包括与模型使用相关的各种潜在风险,包括数据和模型的局限性。
IR2. 说明模型的预期用途。模型的风险报告应包括模型的预期用途,以及超出范围的用途和误用,因为所有这些都与风险报告相关。
我们使用这些要求生成了初始风险报告,旨在引导AI开发者逐步评估其模型的预期用途、评估模型风险,并识别潜在的不足之处。
3.2 共设计中的设计要求
我们进行了一系列一对一的共设计会话(图2,步骤1B),涉及16名AI开发者(数据科学家、研究人员和工程师),因为他们是我们解决方案的主要目标用户。我们的共设计会话分为五个迭代。在每次迭代之后,我们根据用户反馈开发了一个改进的风险报告。与先前的研究一致
[
6
,
16
]
[6,16]
[6,16],我们的会话结合了半结构化访谈和共设计活动,以增强研究流程和效率。由此产生的顺序
表1:参与我们共设计会话的AI开发者(P1-P16)的人口统计特征。我们的参与者具备丰富的实践经验,在各种现实应用中部署AI模型方面有着丰富的动手经验。
| 版本 | ID | 性别 | 年龄 | 教育 | 专长 | 在AI领域的经验 (年) | 角色 | 动手经验 |
|---|---|---|---|---|---|---|---|---|
| V1 | P1 | 男 | 25 | 硕士 | NLP | 4 | 数据科学家 | 面向电子商务应用的聊天机器人 |
| P2 | 男 | 24 | 硕士 | NLP, CV | 5 | 研究员 | 用于交互式用户应用的面部表情生成 | |
| P3 | 女 | 22 | 博士 | NLP, CV | 5 | 研究员 | 复杂网络分析模型 | |
| V2 | P4 | 男 | 22 | 学士 | NLP, CV | 5 | 软件工程师 | 面向酒店和金融应用的聊天机器人 |
| P5 | 男 | 28 | 硕士 | CV | 5 | 研究员 | 面向虚拟用户应用的人脸生成 | |
| P6 | 男 | 33 | 博士 | 推荐系统 | 5 | 讲师 | 推荐系统和数据科学 | |
| P7 | 男 | 32 | 博士 | CV, 不确定性量化 | 7 | 研究员 | 卫星数据地球观测模型 | |
| V3 | P8 | 男 | 30 | 博士 | NLP | 4 | 研究员 | 提升用户交互的智能回复系统 |
| P9 | 男 | 34 | 博士 | 隐私保护ML | 10 | 研究员 | 用于保护用户隐私的增强现实应用 | |
| P10 | 男 | 29 | 博士 | 强化学习 | 6 | 研究员 | 建模物理活动如跑步 | |
| P11 | 男 | 33 | 博士 | NLP, 贝叶斯ML | 5 | 数据科学家 | 建模营销任务和微观数据 | |
| V4 | P12 | 男 | 40 | 博士 | 数据科学, ML工程 | 2 | 研究员 | 健康监测中心电图信号异常检测 |
| P13 | 女 | 31 | 博士 | ML安全与隐私, NLP | 7 | 研究员 | 用于AI安全的扩散模型 | |
| P14 | 男 | 22 | 学士 | CV | 1 | 数据科学家 | 社交媒体中的虚假信息检测 | |
| V5 | P15 | 男 | 38 | 博士 | ML, 生成式AI | 5 | 数据科学家 | 零售个性化以提供目标客户优惠 |
| P16 | 女 | 26 | 博士 | 设备端ML | 5 | 研究员 | 小型设备如微控制器上的模型部署 |
每次迭代后生成的风险报告工件序列见附录B,图8。
3.2.1 目标。这些会话的目标是了解AI开发者在模型卡中报告风险的需求。目标还包括在迭代共设计过程结束时开发一份满足已识别需求的改进风险报告。
3.2.2 参与者。我们通过滚雪球抽样方法力求获得多样化的参与者样本,让参与者识别其他潜在对象。我们使用了以下筛选标准:(1) 接受过机器学习、统计学或相关领域的研究生或本科培训,或在过去两年中每周使用AI超过两次;(2) 在过去六个月内从GitHub或HuggingFace下载或上传过模型;以及(3) 年满18岁或以上。我们招募了总共16名参与者,其中包括13名男性和3名女性,学术界和工业界的参与者人数相等。参与者带来了多样的专业知识,拥有在各种实际应用中开发和部署AI模型的丰富动手经验(参见表1)。每次迭代有三到四名参与者。
3.2.3 设置。在会话之前,我们通过电子邮件向参与者发送了一份人口统计调查表和简要描述会话目标的说明。我们还要求他们为我们提供过去六个月内使用过的模型的模型卡。我们根据初始要求准备了一个初始版本的模型卡,仅包含预期用途和与风险相关的部分
4
{ }^{4}
4(详见附录图8)。我们选择了bert-base-uncased
5
{ }^{5}
5 作为来自HuggingFace的模型。该模型是仓库中下载量最多的前十名模型之一,也是下载量第二多的具有风险相关部分的模型。
3.2.4 流程。每个40分钟的会话包括三个活动:介绍(5分钟):参与者自我介绍,描述他们的AI/ML项目,分享他们在GitHub和HuggingFace等平台上的经验,并讨论他们所使用模型的文档实践。
模型卡审查(15分钟):参与者讨论他们带来的模型卡,重点关注与风险相关的部分。他们识别出在模型选择中最重要的一些部分,并评估当前风险相关内容在预测潜在模型风险和挑战方面的有用性。
共设计任务(20分钟):我们介绍了我们版本的模型卡(基于迭代)以及一个任务,以确定他们是否会将模型用于特定的高风险用途案例(即,回答求职简历问题的聊天机器人,并帮助筛选简历),并解释他们的理由。鼓励参与者为每个模型卡部分提出改进建议,重点关注有助于他们更好完成任务的信息,识别缺失或表示不充分的细节,并改进风险部分内容和呈现。在早期迭代中,会话重点在于理解参与者评估风险和证明模型选择所需的内容。在后期迭代中,则更多时间分配给对工件本身的批评和共设计。
两位作者分别主持每次会话:一位负责提问,另一位详细记录。在获得参与者同意后,会话通过在线会议软件录制。每次会话后,我们分析关键问题并根据发现的要求更新模型卡。然后,这个修订后的模型卡在后续的共设计会话中测试下一组参与者。当我们开发出五个版本的模型卡时(参见附录图8的迭代概述,详细内容见Supp. Mat. 2.1),很明显我们的共设计努力已经获得了足够的见解。没有出现新的重大问题,表明设计已经达到饱和点。根据循环行动研究的既定做法 [67],我们决定在此处结束迭代过程(见图1快速概览,最终版本的风险报告见Supp. Mat. 4.2)。
3.2.5 从参与者那里收集初始设计要求。每次迭代后,两位作者对会话记录进行了主题分析 [9, 10],并用会话笔记加以丰富。我们
4
{ }^{4}
4 从文献回顾中,我们发现AI模型的风险分布在不同部分。因此,我们认为以下任何部分都可以与风险相关:预期用途、超出范围的用途、风险、限制、偏差、伦理考虑、责任和安全性。对于缓解措施,我们添加了建议子部分。
5
{ }^{5}
5 https://huggingface.co/google-bert/bert-base-uncased
采用归纳编码方法,对数据进行编码以理解和突出参与者在风险报告中提出的要求和问题。这些代码随后联合讨论并解决任何分歧。然后将这些代码安排成相关主题,以确定下一迭代模型卡需解决的设计要求(每次迭代使用的代码手册见Supp. Mat. 2.2)。这些与AI开发者的共设计会话浮现了五个额外的设计要求,最终形成了一个无需进一步改进的模型卡工件(图2,步骤1B):
IR3. 提供模型的实际用途示例。风险报告应包括模型的实际用途示例,因为它可以帮助用户可视化模型如何适当地使用以及与实际情况相关的潜在风险。请注意,这一要求不同于提供预期用途(IR2),后者更为概括(例如,文本生成任务),而参与者要求具体和具体的示例(例如,记者可以使用该模型生成新闻摘要)。例如,P3提到 “如果有一些应用示例会很有帮助。就像一些具体的应用程序,可能会产生风险。那么这将很有帮助。”,而P1解释说 “它可以给出一些实际应用,其中只说明序列分类…一些实际应用。”
IR4. 提供缓解策略。风险报告应包括如何缓解风险的建议或指南。例如,P4表达了对原始模型卡的沮丧情绪 “… 因为它没有针对那个特定任务进行微调… 即使他们给出了使用说明,也没有提供替代解决方案。”
IR5. 以结构化和易于理解的方式呈现风险。风险应以清晰简洁的方式组织,便于理解和采取行动。例如,P7评论道 “我认为某种清晰的结构会很有帮助,很少有人会读完整个文本部分,除非他们深入研究这个话题… 所以清晰地结构化… 我猜应该是要点或一些图表,快速总结这些风险和偏差等。然后下面是更详细的信息… 人们的注意力很短暂。”
IR6. 风险优先级排序。应按优先级顺序呈现风险,反映其影响和重要性。正如P8指出的那样:“可能有一种方式可以直观地显示,OK,六个中有三个被标记为主要风险。”
IR7. 针对特定实际用途的情境化风险。风险应清楚地与特定的实际用途相关联,使更容易理解其在特定情境中的相关性和影响。例如,P3通过表达此要求说 “当我询问我的应用时,如果它能回答可能的风险,那将非常有帮助。”
3.2.6 重述设计要求。我们将从文献和共设计过程中收集的设计要求整合为五个主要要求。这样做的目的是使它们更加集中和彼此正交,例如,某些要求是其他要求的更具体版本。这
还提高了清晰度,使在实践中更容易实施这些要求。例如,初始要求IR2(预期用途)、IR3(实际用途示例)和IR7(情境化风险)都被合并为一个新的要求
R
3
R 3
R3,将其全部涵盖。
最终设计要求:
R1. 提供不同类型的特定模型风险。
R2. 以结构化和易于理解的方式呈现风险。
R3. 针对特定实际用途情境化风险。
R4. 提供可操作的缓解风险策略。
R5. 风险优先级排序。
4 根据要求设计风险报告解决方案(RiskRAG)
为了满足已识别的AI模型风险报告设计要求(图2,步骤2),我们开发了RiskRAG(图4),一种基于检索增强生成(RAG)的解决方案。自动化解决方案可以通过简化设想和记录AI模型风险这一复杂任务,有效地协助AI开发者,确保跨不同模型的一致和彻底报告。RAG非常适合这项任务,因为它结合了检索和生成方法,确保识别的风险与现实世界的知识源相关。通过利用包含风险的真实世界和人类书写的数据库,RiskRAG提供了一个可靠的解决方案,补充了开发者的专业知识,使记录满足所有收集到的设计要求的风险变得更加容易。
4.1 RiskRAG架构
RiskRAG使用标准RAG架构 [36](如 [23] 所描述的朴素RAG),结合两个阶段:检索模型和生成模型。我们使用预训练模型,因为先前的工作 [55] 显示这种方法无需额外训练即可表现良好,并且通常优于使用特定数据微调模型。
4.1.1 数据集。我们使用了两个互补的数据集进行检索:模型卡(模型风险和缓解策略的来源)和AI事件数据库(导致实际伤害的风险来源)。
模型卡数据集。我们使用HF Hub API
7
{ }^{7}
7 在2024年7月从HuggingFace
®
{ }^{\circledR}
® 下载了模型存储库快照。其中包含765,973个模型存储库,其中461,181个(60%)有模型卡。对于每个收集的模型卡,我们使用正则表达式搜索与风险相关的部分。特别是,我们搜索了风险、限制、偏差、伦理考虑、超出范围的用途、误用、责任和安全部分。这导致了64,116张(14%)带有与风险相关部分的模型卡。由于HuggingFace没有标准化和严格的内容要求,收集的模型卡大多不完整,许多风险部分只是现有内容的轻微修改副本。具体而言,在64,116张带有风险相关部分的模型卡中,绝大多数(96%)的风险部分与其他卡片完全重复。我们进一步过滤了这个数据集
6
{ }^{6}
6 https://huggingface.co/models
7
{ }^{7}
7 https://huggingface.co/docs/huggingface_lmb/v0.5.1/en/package_reference/hf_api
并保留了2672张具有独特风险相关部分的模型卡(我们保留了下载次数最多且部分重复的卡片),作为我们的最终模型卡数据集(统计数据见表2)。AI事件数据集。AI事件数据库
8
{ }^{8}
8 是一个公开可访问的资源,记录了AI系统造成伤害或失败的重大实例。通过记录这些事件,数据库旨在促进透明度,提高对AI风险的理解,并指导更安全、更可靠AI系统的开发。我们选择利用这个数据库作为额外的风险信息来源,因为它提供了在部署中已经显现的各种AI模型风险的具体视角。截至2024年3月,该数据库记录了649个事件和3412份报告,每个事件都源自一份或多份报告。例如,其中一个事件描述为“Meta的开源大型语言模型LLaMA据称被用于创建带有图形和明确内容的聊天机器人 […] 参与基于文本的角色扮演,据称涉及暴力场景如强奸和虐待。”
9
{ }^{9}
9 我们收集了这649个事件的描述、元数据以及相关的新闻报道,作为我们的AI事件数据集。
4.1.2 检索器。RAG检索器用于诸如问答等任务中,通过比较查询和源文档之间的余弦相似度来检索答案。我们采用这种方法从类似模型中检索风险相关部分,并从事件中检索类似的描述,将模型描述视为查询。我们的源文档包括模型卡和AI事件描述。我们计算查询模型描述和源文档的情境嵌入。我们计算查询和源文档之间的相似度得分,以识别每个
数据集中最相似的前-
k
k
k个模型和事件描述。尽管在表现上存在差异,情境嵌入能够有效捕捉模型卡和事件描述中的语义意义,正如先前研究所示,它们能够处理复杂的语言结构、模糊的词汇使用和新颖或领域特定的术语 [2, 50, 58]。一些事件指定了模型名称,例如
§
4.1.1
\S 4.1 .1
§4.1.1中涉及Llama模型的事件,它被匹配到Llama变体以及类似的文本生成模型,如falcon-7b或phi-2。其他事件未指定具体模型名称,但允许推断AI系统的功能,将其链接到相关模型类型。例如,描述为“据称AI生成的照片修改导致演讲者会议照片出现不当修改”的事件,
10
{ }^{10}
10 来自图像到图像生成模型,并与flux-ip-adapter-v2或instruct-pix2pix等模型相关联。我们实验了
k
=
5
,
10
,
15
k=5,10,15
k=5,10,15以优化最佳结果。从最接近的-
k
k
k个模型描述中,我们提取了其相应的风险相关部分。这些最接近的-
k
k
k个风险相关部分和检索到的事件描述被作为输入提供给生成器。
分析我们的模型卡数据集显示,缓解策略要么在一个专门的部分(如建议或责任和安全)中,要么集成在风险相关部分内。因此,我们使用了最接近的- k k k个检索到的风险相关和建议部分组合,以提取缓解策略。
我们尝试了一种稀疏模型:tfidf n-gram 和三种密集嵌入模型:SFR-Embedding-2_R、Linq-EmbedMistral 和 bge-large-en-v1.5。 11 { }^{11} 11 密集模型是根据2024年7月的大量文本嵌入基准测试(MTEB)排行榜上的高排名选择的。第一个模型
1
8
{ }^{8}
8 https://incidentdatabase.ai/
9
{ }^{9}
9 https://incidentdatabase.ai/cite/578
10
{ }^{10}
10 https://incidentdatabase.ai/cite/820
11
{ }^{11}
11 https://huggingface.co/Salesforce/SFR-Embedding-2_R, https://huggingface.co/Linq-AI-Research/Linq-Embed-Mistral, https://huggingface.co/BAAI/bge-large-en-v1.5
在56个数据集中总体表现最好,第二个模型在检索任务中表现出色,而第三个模型参数最少却表现最佳。包含tfidf n-gram模型是为了比较传统稀疏表示与最先进的密集嵌入的表现。我们使用了1-2范围的n-gram。
4.1.3 生成器。RiskRAG 使用 GPT-40 [20] 作为生成器(提示词见 Supp. Mat. 5.1),因为它是一系列生成任务中最领先的 LLMs 之一 [40],并且在平衡成本与效率方面表现出色。我们设计了一个两步生成风险的方法:
(1) 从最接近的-
k
k
k个检索到的风险相关部分和事件描述中,我们以动词+对象+[解释]的格式生成所需的风险,以一个动词开头。我们从每个检索到的风险相关部分生成零个或多个独特风险,从风险和缓解相关部分生成零个或多个独特的缓解策略。此外,我们根据 Weidinger 等人 [71] 提出的分类法,按照两个维度对风险进行分类:发生位置(能力、人类互动或系统性),以及所代表的危害类型(例如,表征和毒性、错误信息、恶意使用)。从事件描述中生成的风险被标记为已造成实际伤害的风险。
(2) RiskRAG 使用 ExploreGen [29] 根据五成分格式生成一组现实且多样的模型用途:领域、目的、能力、AI部署者和AI主体 [26]。我们提示它还按可能性排序这些用途,并取前四个作为示例。每个生成的风险根据其与用途的相关性映射到一个现实用途。
我们设计了一个类似的两步生成缓解策略的方法:
(1) 从最接近的-
k
k
k个检索到的风险相关和推荐相关部分中,我们在与风险相同的期望格式下生成一个或多个独特的缓解策略。
(2) 此外,每个生成的缓解策略被映射到与其相关的生成风险。
生成后,RiskRAG 根据这些风险映射到示例实际用途的频率对其进行优先级排序(图4,生成后),假设影响更多用途的风险具有更大的潜在影响。此外,根据 AI 事件数据中已导致实际危害的风险给予更高的优先级。虽然量化风险的影响和优先级仍然是一个开放的研究挑战 [56, 57],但这种方法提供了一种简单且实用的初始方法来进行风险优先级排序。
4.2 满足设计要求
RiskRAG 满足 R 1 R 1 R1(不同类型的特定模型风险),因为检索器从最相似的模型卡中提取风险,而相似模型通常共享可比的风险和限制。例如,训练于相似数据集或从相同父模型微调的模型往往表现出相似的偏差、伦理问题和公平性问题。例如,bert-base-uncased 12 { }^{12} 12 和distilbert-base-uncased 13 { }^{13} 13(后者由前者衍生而来)在其模型卡中展示了与性别和种族相关的相似偏差。同样,无论具体应用领域如何,在具有相似架构的模型中通常会出现与模型可解释性和鲁棒性相关的问题。通过检索$k = 5 到 到 到 k = 15 $ 之间的相似模型卡,检索器使我们能够捕捉目标模型关联的大部分特定模型风险,这些风险主要是技术性和模型能力相关的[58]。为了涵盖更广泛的风险,特别是人际互动方面的风险[68],RiskRAG 还从与模型使用相关的实际AI事件中检索风险。例如,ChatGPT模型与AI事件642相关联,该事件描述了一个漏洞,破坏了用户交互并产生了无意义的输出。 14 { }^{14} 14 由于并非所有事件都指明了底层AI模型,我们将事件链接到执行相同任务的模型(例如,事件642还会链接到其他类似的文本生成模型)。这些事件通常揭示了模型卡中代表性不足的人工智能交互带来的危害,进一步帮助满足$ R 1 $。此外,生成器将来自相似模型和相关事件的所有已识别风险适应到目标模型的独特上下文中。这种适应过程可能涉及删除不适用于目标模型的风险或修改它们以反映模型的具体特征。例如,像“低估使用非英语语言的文化”这样的风险可能会被调整为“低估使用非中文语言的文化”,如果目标模型是在中文而非英文文本上训练的。
RiskRAG 满足 R 2 R 2 R2(结构化且易于理解的风险),因为它以一致且可行的格式生成风险(如 § 4.1 \S 4.1 §4.1 所述)。分配给文本生成模型的一个示例风险是:“通过提供不适当的建议削弱用户信任。” 这种明确的格式确保风险清晰表达,最大限度减少歧义。当风险以行动为导向时,实施有效的缓解策略变得更加容易。RiskRAG 还使用风险分类学 [71] 对这些风险进行结构化,进一步帮助满足 R 2 R 2 R2。例如,上述示例风险被归类在信息与安全危害类别下,并位于人机交互层。
RiskRAG 满足 R 3 R 3 R3(针对特定用途情境化风险),通过将每项风险映射到由ExploreGen生成的示例用途上,使其适用于这些特定的实际应用。例如,如果问题是针对文本生成模型设计的,那么风险“通过提供不适当的建议削弱用户信任”适用于检测有害内容的用途,而其风险“通过给出假阳性结果违反招聘中的公平性”则适用于增强工作匹配的用途。
RiskRAG 满足 R 4 R 4 R4(可行的缓解策略),通过从最相似的模型卡中检索缓解措施并将它们映射到特定风险,提供风险缓解策略。对于上述提到的风险,一个示例缓解策略是:“过滤模型输出以排除无关或不适当的建议。”
最后,RiskRAG 满足 R 5 R 5 R5(风险优先级排序),通过利用风险在实际用途中的发生频率,并给予那些在AI事件数据中导致实际危害的风险更高重要性。
总之,检索前5至10个最相似的模型卡使检索器能够捕获目标模型周围的更广泛背景,而生成器则细化此内容以解决模型的独特特性和细微、情境特定的风险。
5 评估我们的风险报告解决方案
在评估RiskRAG是否产生符合设计要求的风险报告之前,我们首先需要确定其初步生成相关风险内容的有效性。为此,我们最初进行了基线评估(§5.1)以评估RiskRAG生成的内容。一旦确认我们的方法表现良好,在初步用户研究(§5.2)中,我们评估了RiskRAG报告与设计要求的一致性。在最终用户研究(§5.3)中,我们评估了RiskRAG是否可以帮助选择最适合特定用途的AI模型,并支持决策制定。
5.1 基线RiskRAG评估
目前尚无标准化方法来评估RAG生成的内容 [66]。挑战在于检索内容的变化以及定制生成管道中常见的缺乏地面实况 [23, 46]。在我们的案例中,也缺乏地面实况,因为尚未存在符合我们所有要求的模型风险部分(例如,基于用途排序的风险)。为应对这一挑战,我们专注于评估与现有模型卡中最接近的风险内容格式(即单个风险/缓解描述)。
5.1.1 目标。基线评估的主要目标是建立它可以生成相关风险内容,从而可以生成满足设计要求的最终风险报告。另一个目标是确定RiskRAG的最佳参数,即检索器中使用的嵌入模型以及要检索的相似模型卡片数量
(
k
)
(k)
(k)。
5.1.2 评估设置。我们评估的一个挑战是现有的模型卡片中的风险部分常常不完整或稀疏,使得传统的训练和测试数据分割评估方法难以进行(例如,我们无法在训练或测试集中包含许多风险部分稀疏的模型卡片)。为解决此问题,我们使用高质量模型卡片创建了一个评估集作为伪地面实况。具体而言,我们自动提取了267张模型卡片,即下载量最高的前
10
%
10 \%
10%(参见表2中的“评估集”)。我们用流行度作为模型卡片质量的代理 [37]。为确保这些卡片确实质量较高,我们手动检查了其中30张子集。表2显示,平均而言,这些卡片的风险报告比其他卡片更长,我们的手动检查确认它们包含非稀疏且一般精心编写的风险内容。由于RiskRAG生成的是单独的风险而不是完整的部分,我们需要调整评估集以匹配我们的输出格式。我们通过RiskRAG生成器的第一步(图4)处理评估集中的所有风险部分来实现这一点。这产生了一组包含单独风险的215张模型卡片(即使在最受欢迎的模型卡片中,也有一些没有风险内容,我们丢弃了这些),创建了我们提出的格式下的伪地面实况(G)。最后,我们比较了不同的检索(嵌入)模型,并测试了参数
k
k
k的各种值,以识别表现最佳者并确定最优
k
k
k。完整的评估设置如图5所示。为了确定系统的超参数,我们还通过随机抽样模型卡片
(
n
=
25
)
(n=25)
(n=25) 编制了一个单独的验证集,选择标准是从下载量最高的前
10
%
10 \%
10% 到前
20
%
20 \%
20% 的卡片中抽取。
5.1.3 度量标准。我们使用两种类型的度量标准评估RiskRAG。首先,BERTScore [75] 测量检索到的风险 ® 与伪地面实况 (G) 之间的整体相似性。其次,精确率和召回率评估从伪地面实况中检索单个风险的效率。为了计算精确率和召回率,我们使用BERTScore而不是直接字符串匹配来将每个检索到的风险
(
∈
R
)
(\in R)
(∈R) 与伪地面实况风险
(
∈
G
)
(\in G)
(∈G) 匹配。直接字符串匹配经常错过措辞不同的上下文相似风险,而BERTScore通过利用上下文嵌入,更准确地评估检索到的风险与伪地面实况之间的对齐情况。我们认为,如果某个检索到的风险的BERTScore超过阈值0.6,则认为正确匹配。该阈值是通过对单独验证集中的随机抽样风险对(检索到的和伪地面实况)进行人工标注确定的。对于每一对,两位作者评估了检索到的风险是否在上下文上与伪地面实况风险相关。然后我们选择了与这些人工标注最一致的BERTScore匹配的阈值。
召回率计算为正确检索到的风险数与伪地面实况风险总数的比率
(
R
∩
G
)
/
G
(R \cap G) / G
(R∩G)/G,而精确率计算为正确检索到的风险数与总检索到风险数的比率
(
R
∩
G
)
/
R
(R \cap G) / R
(R∩G)/R。我们使用预训练语言模型DistilBERT [62] 的上下文嵌入实现了BERTScore的原始实现。
5.1.4 结果。我们的评估结果如表3所示。虽然没有直接针对我们特定任务的先前研究,但最接近的对比方法是CardGen [39]。CardGen利用RAG根据相关论文和GitHub存储库生成模型卡部分。CardGen报告的风险相关部分的BERTScores,使用各种嵌入模型,范围从0.53到0.59,这与我们的结果相当(顶部-
k
=
5
k=5
k=5和tfidf n-gram的0.53)。需要注意的是我们的
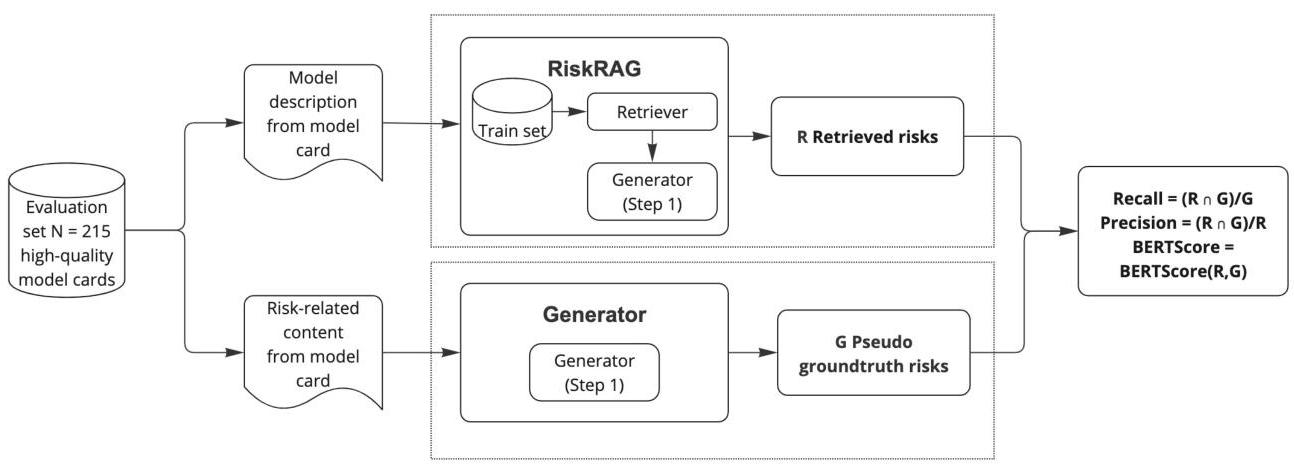
图5:基线RiskRAG评估。此评估是在由下载量最多的前10%模型卡片组成的评估集上进行的(表2)。我们仅使用它们的模型描述,通过RiskRAG为每个卡片生成风险R。为了评估RiskRAG的输出质量相对于这些卡片现有的风险部分,我们将这些风险部分通过RiskRAG生成器的第一步(步骤1)进行解析,生成伪地面实况G,以便与RiskRAG生成的风险内容进行直接比较。
表3:基线RiskRAG评估的结果。信息检索(精确率和召回率),以及文本生成(BERTScore)指标如下所示。参数top- k k k 表示从中检索风险的最相似模型卡片的数量。
| top- k = 5 k=5 k=5 | top- k = 10 k=10 k=10 | top- k = 15 k=15 k=15 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| 精确率 | 召回率 | BERTScore | 精确率 | 召回率 | BERTScore | 精确率 | 召回率 | BERTScore | |
| Linq-Embed-Mistral | 0.32 | 0.71 | 0.51 | 0.20 | 0.75 | 0.42 | 0.15 | 0.78 | 0.37 |
| SFR-Embedding-2_R | 0.32 | 0.69 | 0.51 | 0.20 | 0.75 | 0.42 | 0.14 | 0.76 | 0.36 |
| bge-large-en-v1.5 | 0.27 | 0.60 | 0.48 | 0.18 | 0.66 | 0.40 | 0.13 | 0.68 | 0.35 |
| tfidf n-gram | 0.34 | 0.71 | 0.53 | 0.21 | 0.75 | 0.42 | 0.16 | 0.77 | 0.37 |
我们的任务需要以不同于原始模型卡片的格式输出风险部分,这为检索过程增添了额外的复杂性,使其相较于CardGen更具挑战性。
表3列出了精确率、召回率和BERTScore。较高的召回率表明RiskRAG成功检索到了伪地面实况模型卡片中的更多风险,而较高的精确率反映了较少的误报,意味着检索到的风险中有更多的实际上是伪地面实况的一部分。对于top- k = 5 k=5 k=5,tfidf n-gram达到了最高的精确率(0.34)和BERTScore(0.53)。Linq-Embed-Mistral和SFR-Embedding-2_R也表现良好,各自的精确率为0.32,BERTScore为0.51,显示出它们的竞争准确性与相似性。随着top- k k k值的增加,所有三个模型都保持了强召回率,Linq-Embed-Mistral略微领先,top- k = 15 k=15 k=15时召回率达到0.78。这表明尽管tfidf n-gram在精确率和BERTScore方面表现优异,但Linq-Embed-Mistral在检索更广泛的相关风险方面略胜一筹。精确率相对较低,并随着top- k k k值的增加而下降。然而,由于我们评估集中的模型卡片风险部分可能不完整,较低的精确率并不总是意味着误报。许多检索到的风险可能并未包含在伪地面实况中,但仍然与模型相关,因为它们来源于相似的模型。此外,生成器的第二步(本部分评估未包括)可以过滤掉无关风险,进一步改进结果。因此,在我们的评估中,精确率的重要性低于召回率或BERTScore。
为了确认RiskRAG尽管精确率低但仍能生成广泛且相关的一系列风险,并解决tfidf n-gram和Linq-Embed-Mistral之间的平局,我们对评估集中下载次数最多的十张模型卡片的风险进行了定性检查。我们选择了
k
=
10
k=10
k=10,因为它比
k
=
5
k=5
k=5提供了更广泛的覆盖范围,同时避免了
k
=
15
k=15
k=15时过长列表的情况。实际上,初步的手动分析验证集显示,
k
=
10
k=10
k=10在风险部分不完整的许多模型卡片中,最佳平衡了覆盖范围和简洁性。经过手动评估十张下载次数最多卡片后,我们发现大多数检索到的风险与相关模型有关,并且确实缺失在原始卡片中。例如,google/flan-t5-large
15
{ }^{15}
15 的卡片,这是一个多语言文本生成模型,列出了一些风险,如训练数据中的偏差和有害、不恰当或明确内容的生成。RiskRAG扩展了这些,识别出额外相关风险,包括幻觉、毒性、虚假信息、不支持的语言、恶意使用以及在线数据中的种族和性别刻板印象等表征性危害。尽管这些风险
15
{ }^{15}
15 https://huggingface.co/google/flan-t5-large
没有在原始卡片中记录,但它们与全面的风险评估相关。我们还观察到低精确率部分是因为顶级结果中措辞相似的风险,以及来自类似模型但不直接适用于所检索模型的特定用途风险。这些问题在生成器的第二步中得到缓解,这里会删除无关风险并调整特定风险。
我们选择Linq-Embed-Mistral用于后续用户评估 ($5.2),原因有二:(1) 全面覆盖。Linq-Embed-Mistral提供了更广泛和详细的系列风险。对于DistilBERT,tfidf n-gram主要强调了“尽管训练数据中立,仍产生偏差预测”和“将偏差传递给所有微调版本”。Linq-Embed-Mistral包括了与领域特定性能和语言问题相关的额外风险,例如“在不同领域的文本上表现不佳”和“在非英语语言上表现不佳”。(2) 相关性。Linq-Embed-Mistral识别了与特定任务更相关的风险。例如,它捕捉到了OpenAI CLIP
16
{ }^{16}
16 模型的图像分类相关风险,如“当输入图像调整大小时性能降低”和“记住训练数据中的重复图像”,这些都是tfidf n-gram未能捕捉到的。总的来说,尽管tfidf n-gram突出了主要风险,但Linq-Embed-Mistral提供了更广泛和相关性的评估,使其成为详细风险报告的更好选择。
5.2 初步用户研究
我们进行了初步用户研究(图2,步骤3顶)以了解AI开发者如何看待RiskRAG的风险报告与现有模型卡风险报告相比。
5.2.1 目标。评估RiskRAG的报告是否满足已确定的设计要求,并在决定是否使用AI模型完成给定任务时优于标准模型卡风险报告。
5.2.2 研究设计。我们进行了一项内被试研究,每位参与者评估了两种版本的模型风险报告:包含原始模型卡风险相关部分的基线版本(对照组),以及由RiskRAG生成的模型风险报告(实验组)。具体来说,我们选择了两个相似的文本生成模型:Phi-3-mini-128k-instruct
17
{ }^{17}
17(2024年7月下载量超过20万次)和StableBeluga2
18
{ }^{18}
18(在同一时期下载量超过13万次)。这些模型被选中是因为它们的原始模型卡包含了较为丰富的风险部分,允许对基线与RiskRAG报告进行公平比较。然后要求参与者考虑两种高风险(根据欧盟AI法案)用途之一:(1) 用于评估和排名面试前评估的聊天机器人;(2) 回答求职简历问题并帮助筛选简历的聊天机器人。我们关注高风险情景,因为在这种情况下有效的风险报告至关重要。此外,选择团队成员是一个开发人员常见经历的任务,使这些模型用途对我们的参与者来说相关且有意义。
我们开发了一个基于网络的调查问卷,其中包括控制和实验条件下都要完成的真实世界任务:
“写一封简短的邮件给你的直线经理,请求批准使用这个模型。在邮件中,解释为什么应该使用这个模型的技术和道德原因,同时也坦诚地说明任何潜在风险并讨论如何进行缓解。”
当今AI模型的广泛可用性使开发者为任何特定模型进行论证并与管理层讨论权衡变得切实可行。在后疫情时代,大量的工作交流在线上进行,许多人仍然选择远程工作 [59],发送邮件也被认为是一项实际且相关的任务。
5.2.3 指标。为了评估RiskRAG在满足要求方面的效果与基线模型卡风险部分相比,我们测量了以下指标(左侧面板图6):
Q1. 风险报告是否提供了可靠的信息并涵盖了广泛的风险?(R1)
我们通过调整AIMQ信息质量评估量表 [35] 中的一项完整性指标和另一项感知准确性指标来测量这一点。
Q2. 风险报告是否以清晰简洁的方式解释了风险,便于理解?(R2)
我们使用AIMQ量表 [35] 中的可理解性和简洁表示项目来衡量这一点。
Q3. 风险报告的内容是否与任务中呈现的用例相关?(R3)
我们调整并测量了AIMQ量表 [35] 中的一项信息相关性指标。
Q4. 风险报告是否提供了清晰的风险缓解策略?(R4)
我们调整了AIMQ量表 [35] 中的操作简易性项目来衡量这一点。
Q5. 风险报告是否有效地优先排序了风险?(R5)
我们开发了一个定制项目来衡量这一在共设计会话期间出现的具体要求。
每个问题都在1(强烈不同意)到5(强烈同意)的范围内评分。
最后一个我们测量的指标是对基线风险报告还是RiskRAG生成的风险报告的偏好。为了统一性,所有指标均使用5点李克特量表测量。最后,我们还有两个开放式问题:"这份报告在哪些方面成功协助您完成了任务?“和"这份报告在哪些方面未能充分协助您完成任务?”
5.2.4 参与者。我们重点关注AI开发者,他们负责评估AI系统在特定用例中的表现,包括评估人类交互效应和技术能力在其应用中的表现 [71]。我们通过在线招募平台Prolific招募了50名AI开发者。
19
{ }^{19}
19 为了确保参与者的适用性,我们采用了四项预先设定的纳入标准,针对那些担任个体贡献者角色、在其组织内的工程职能中工作、专门为编码任务雇佣、每周多次使用AI的个人。此外,我们使用了AI素养量表中的两项
1
16
{ }^{16}
16 https://huggingface.co/openai/clip-vit-large-patch14
17
{ }^{17}
17 https://huggingface.co/microsoft/Phi-3-mini-128k-instruct
18
{ }^{18}
18 https://huggingface.co/petals-team/StableBeluga2
图6:初步用户研究的定量结果:RiskRAG报告在所有指标上均优于基线模型卡。我们有七个问题对应我们的设计要求,参与者需在李克特量表上从1(“强烈不同意”)到5(“强烈同意”)回答。RiskRAG显著优于基线模型卡,评分高出一个点,从轻微同意提升到明显同意风险覆盖,从中立提升到同意缓解策略清晰度。
量表 [12] 控制参与者对AI的素养及其对AI的态度。
参与者年龄分布在18至29岁之间(占40%)和30至39岁之间(占60%)。所有参与者均为男性,居住在美国,并在非管理技术岗位上担任个人贡献者,包括工程(33%)、设计(17%)、数据分析(17%)和研究与教育(17%)。就种族而言,40%认定为亚洲人,20%为黑人,20%为混血,20%为白人。按照我们的研究要求,60%的参与者报告每周多次使用AI,而40%每天使用AI。
5.2.5 流程。整个流程分为三个步骤。第一步,参与者回答人口统计问卷。第二步,参与者获得简短的任务介绍,随后进行第一个任务,其中参与者需阅读控制或实验风险报告,并撰写电子邮件。第三步,他们回答关于选定指标的问题。然后继续查看另一个风险报告并回答相同的问题。
为了避免顺序效应,向参与者展示基线和实验风险报告的顺序是随机化的。为了消除因展示的AI模型类型不同而产生的影响,每位参与者审查了两个不同模型的风险报告,这些模型具有不同的实际用途,随机分配以确保彻底评估。两个模型的基线和RiskRAG报告见Supp. Mat. 4。
表4:初步用户研究结果的统计显著性:基线模型卡与RiskRAG报告之间的Wilcoxon符号秩检验结果。测试显示,在多数选定的定量指标上具有统计显著性,表明RiskRAG报告在所有已确定的要求上均优于基线: ∗ p < 0.05 ; ∗ ∗ p < 0.01 ; ∗ ∗ ∗ p < 0.001 ; n s : p > 0.05 { }^{*} \mathbf{p}<\mathbf{0 . 0 5 ;}{ }^{* *} \mathbf{p}<\mathbf{0 . 0 1 ;}{ }^{* * *} \mathbf{p}<\mathbf{0 . 0 0 1 ;} n s: \mathbf{p}>0.05 ∗p<0.05;∗∗p<0.01;∗∗∗p<0.001;ns:p>0.05。
| 指标 | z-统计量 | p-值 |
|---|---|---|
| 提供可靠信息 (R1) | 63 | ∗ * ∗ |
| 覆盖广泛风险 (R1) | 60 | ∗ ∗ ∗ * * * ∗∗∗ |
| 以易于理解的方式解释风险 (R2) | 100.5 | ns |
| 清晰简洁地呈现风险 (R2) | 103 | ∗ * ∗ |
| 是否与任务中的用例相关 (R3) | 87 | ns |
| 提供明确的风险缓解策略 (R4) | 77 | ∗ ∗ ∗ * * * ∗∗∗ |
| 有效优先排序风险 (R5) | 149 | ∗ * ∗ |
| RiskRAG报告与基线之间的偏好 | 531.5 | ∗ ∗ * * ∗∗ |
5.2.6 分析。在确认非正态分布后,我们应用Wilcoxon符号秩检验评估RiskRAG改进是否在统计上显著优于基线。开放式问题的定性反馈的主题分析结果详见附录D。
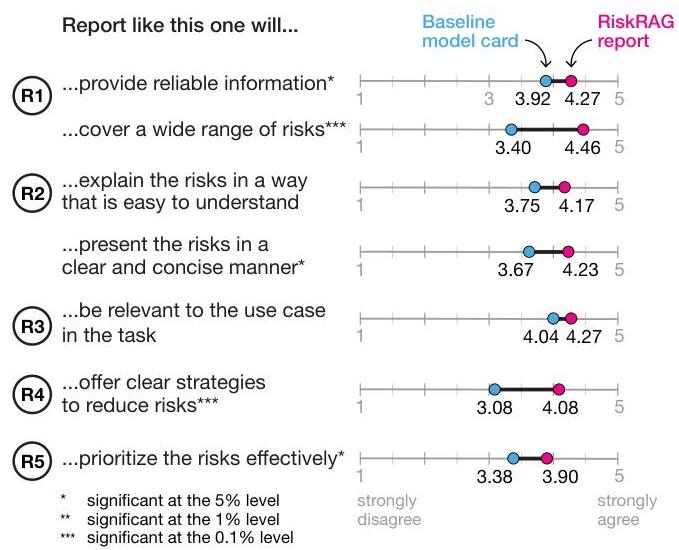
5.2.7 结果。图6展示了定量结果的分解。在各个问题中,参与者对RiskRAG报告的评价高于基线模型卡。最大的差异体现在提供清晰缓解策略的问题上(R4),RiskRAG报告得分为4.08(“同意”),而基线卡得分为3.08(“中立”);在覆盖广泛风险的问题上(R1),报告得分为4.46(“明显同意”),而卡片得分为3.40(“稍微同意”)。虽然参与者对RiskRAG报告在易懂方式解释风险(R2)(我们的报告得分为4.17,基线得分为3.75)和与任务相关性(R3)(4.27 vs. 4.04)方面给出了更高分,但统计测试在这两个问题上未显示出统计显著性。其他问题中的差异,即提供可靠信息、以清晰简洁的方式呈现风险和有效优先排序风险,具有统计显著性(表4)。对RiskRAG报告的偏好显著高于基线,74%的参与者更喜欢它。
5.3 最终用户研究
通过初步用户研究,我们证实RiskRAG生成的风险报告满足所有已确定的设计要求,并优于现有模型卡中的风险报告。随后,我们进行了最终用户研究(图2,步骤3底),以评估其在决策和可行性方面的有效性。
5.3.1 目标。评估RiskRAG报告是否比标准模型卡风险报告更好地提高对模型风险的理解、促进批判性评估和支持设想缓解策略。
5.3.2 研究设计。本研究采用了一个
2
×
2
2 \times 2
2×2的内被试设计。任务是评估两个模型用于真实世界的用例,并选择被认为更合适的那个。每位参与者在此任务中完成两个条件:
(1) 对照组:原始模型卡的风险相关部分;和
(2) 实验组:RiskRAG生成的风险报告。
对于这两个条件,任务分为两个阶段:
(1) 报告前阶段。参与者在审阅两个模型的描述及其预期用途后选择模型,并提供选择理由。
(2) 报告后阶段。参与者审阅与预期用途相关的简短事件及风险报告(对照组为原始模型卡,实验组为RiskRAG)。他们可以重新考虑并更改之前的模型选择,并在任一情况下解释最终决定。此步骤评估了风险报告对其决策的影响。
此设计允许直接比较参与者在有无RiskRAG报告情况下的决策,以及有无基线模型卡风险部分情况下的决策,提供对模型选择中不同影响的见解。
为了测试RiskRAG在超出我们在初步研究中使用的文本生成模型之外的泛化能力,我们选择了两对模型,这两对模型的类型都不属于文本生成,每对模型分别配有一个适当的实际用途和相关事件:
(1) 多模态模型(图像或文本到文本):idefics-80b-instruct
20
{ }^{20}
20 和 paligemma-3b-mix-448
21
{ }^{21}
21,这些模型接受图像和文本输入,并生成文本输出。用途:为媒体机构开发一个系统,用于识别照片中的人物和物体,并生成网页的替代文本描述。事件:模型错误地标记了一对黑人为“大猩猩”。
22
{ }^{22}
22
(2) 自动语音识别(ASR)模型(语音到文本):whisper-large-v3a
23
{ }^{23}
23 和 canary-1b
24
{ }^{24}
24,这些模型处理语音输入并将其转换为文本。用途:创建一个系统,将语音内容转录成文字以用于广播字幕。事件:模型幻想出暴力语言并捏造细节,尤其是在语音停顿延长期间。
25
{ }^{25}
25
这些中等到高人气的模型在其原始卡片中拥有丰富风险相关内容,为RiskRAG提供了坚实的基线。这些模型被选择为具有可比的优势和风险,确保两者之间没有明确的“正确”选择。这使我们可以专注于参与者在面对不同模型对时的权衡过程。
关于报告偏好的问题,RiskRAG报告受到58%的开发者的青睐,63%的设计者,以及70%的媒体专业人士的喜爱。
表6:最终用户研究的决策信心结果。基于两个因素(基线 vs. 实验)和阶段(报告前 vs. 报告后)的2x2分析。显著结果以粗体突出显示。对于开发者和媒体专业人士群体,决策信心在看到风险报告后显著下降,尤其是看到RiskRAG报告后的降幅更大于基线报告。
∗
p
<
0.05
;
∗
∗
p
<
0.01
;
∗
∗
∗
p
<
0.001
{ }^{*} \mathbf{p}<0.05 ;{ }^{* *} \mathbf{p}<0.01 ;{ }^{* * *} \mathbf{p}<0.001
∗p<0.05;∗∗p<0.01;∗∗∗p<0.001
| 指标 | 因素 | AI开发者(n=38) | UX设计师(n=40) | 媒体专业人士(n=37) |
|---|---|---|---|---|
| 决策信心 | 条件(主效应) | F ( 1 , 37 ) = 0.39 \mathrm{F}(1,37)=0.39 F(1,37)=0.39 | F ( 1 , 39 ) = 0.00 \mathrm{F}(1,39)=0.00 F(1,39)=0.00 | F ( 1 , 36 ) = 2.26 \mathrm{F}(1,36)=2.26 F(1,36)=2.26 |
| 阶段(主效应) | F ( 1 , 37 ) = 6.1 3 ∗ \mathbf{F ( 1 , 3 7 )}=\mathbf{6 . 1 3 ^ { * }} F(1,37)=6.13∗ | F ( 1 , 39 ) = 0.09 \mathrm{F}(1,39)=0.09 F(1,39)=0.09 | F ( 1 , 36 ) = 5.1 0 ∗ \mathbf{F ( 1 , 3 6 )}=\mathbf{5 . 1 0 ^ { * }} F(1,36)=5.10∗ | |
| 条件 x 阶段(交互) | F ( 1 , 37 ) = 0.59 \mathrm{F}(1,37)=0.59 F(1,37)=0.59 | F ( 1 , 39 ) = 1.06 \mathrm{F}(1,39)=1.06 F(1,39)=1.06 | F ( 1 , 36 ) = 2.03 \mathrm{F}(1,36)=2.03 F(1,36)=2.03 |
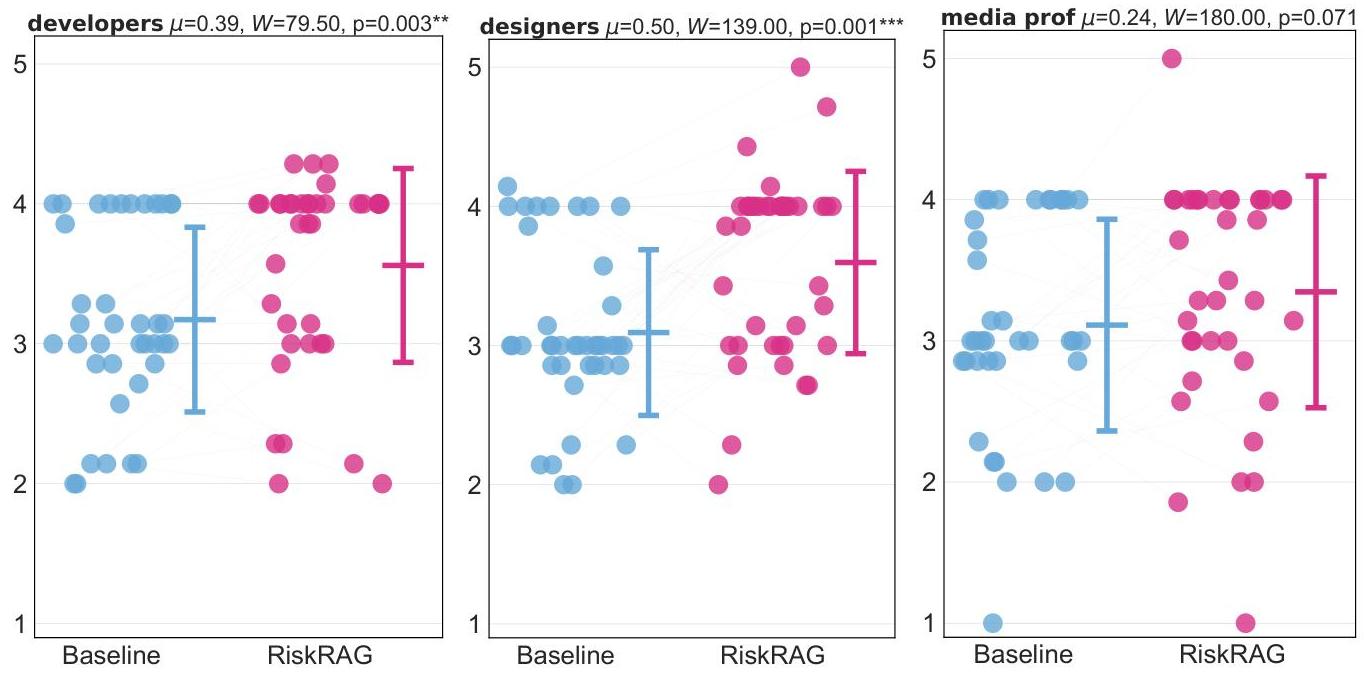
图7:最终用户研究中三组人群——开发者、设计师和媒体专业人士——对解释质量 ( μ \mu μ-轴) 的结果。使用RiskRAG后,所有组别的平均解释质量 ( μ \mu μ) 都有所提高,相比于基线报告,统计显著性由Wilcoxon检验结果 ( W , p W, p W,p) 显示,对于开发者和设计师尤为明显。 ∗ p < 0.05 , ∗ ∗ p < 0.01 { }^{*} p<0.05,{ }^{* *} p<0.01 ∗p<0.05,∗∗p<0.01, ∗ ∗ ∗ p < 0.001 { }^{* * *} p<0.001 ∗∗∗p<0.001。使用RiskRAG报告后,参与者识别出更多相关风险和缓解策略,并提供了更高质量的模型选择解释,相比于基线。
定性结果。参与者对RiskRAG报告的偏好揭示了五个关键主题。以下是这些主题及其主要子主题的描述。
26
{ }^{26}
26
辅助决策:在这个主要主题中,参与者赞赏报告简化了分析的认知负担,因其提供了清晰的结构、优先级的风险以及利益相关者影响,从而有助于跨模型的有效比较和决策。“风险热力图对于总结复杂数据非常有效,尤其在快速决策场景中特别有用。”(P0,dev)。
27
{ }^{27}
27 “我可以轻松理解什么好什么坏,进行比较并更容易做出决策。”(P11,des)。出现的一个关键子主题贯穿所有组别是谨慎决策。参与者表示对潜在风险有了更高的意识,导致更加深思熟虑的选择:“我会谨慎使用MODELX,鉴于过去事件中突出的严重伦理和声誉风险。”(P1,des)“我会特意对参与生成内容信息敏感性、声誉和信息一致性进行培训。”(P4,dev)“这个模型因其大规模和基于指令的设计,有可能产生更准确和细致的描述……然而,即使是大规模模型也必须在多样化情境下彻底测试偏差,以避免造成有害关联。”(P35,med)清晰且上下文化的风险报告强调实际危害,促使参与者更加谨慎地对待模型选择。过去事件的具体例子增加了对潜在后果的认识,促使他们重新考虑最初仅基于技术细节的选择。这种意识的转变导致RiskRAG组在报告后阶段显著降低决策信心。尽管两组在查看风险报告后都表现出信心下降,但在基线条件下我们并未观察到详细的
审议。通过提供具体的伤害示例,RiskRAG鼓励了更为深思熟虑、自我反思的决策过程,将模型选择从纯粹的技术焦点转向更为谨慎、风险感知的方法。
有效的风险沟通:参与者重视关于潜在风险的一致、全面、可操作的见解。“它有更详细和全面的分析,也有平衡的评估。”(P5,med)。“我选择风险热力图,因为它是一个有价值的工具,可以视觉化并有效地识别、评估和传达广泛背景下的风险。”(P2,dev)。
易于理解的呈现方式:这一主题强调视觉效果和易用格式在可用性中的作用。“我更喜欢风险报告A [RiskRAG],因为它视觉上吸引人、详尽,并使用简单易懂的语言。风险报告B则浅显和平淡,无法激发人们阅读和理解其内容的兴趣。”(P28,med)。即使是最具知识水平的开发者群体也承认该报告简化了技术术语,使其更容易理解。“风险被明确列出……这有助于揭开技术术语的神秘面纱,使用户能够做出道德决策。”(P30,dev)。
风险优先级用于缓解:参与者指出结构化的分类支持更好的优先级排序和规划。“我更喜欢风险报告A,因为热力图类型让我更容易快速发现关键风险并优先采取行动。”(P36,des)。
初始学习曲线:出现了一个挑战,一些参与者提到需要一定的认知负担来熟悉报告。“虽然理解热力图有点困难,但一旦理解了就会变得容易。”(P1,dev)。
对于偏好基线的用户,出现了两个关键主题,突出了RiskRAG可能改进的领域。
详细的文本解释:基线允许某些参与者更容易解读。“基于文本的格式允许对风险和缓解策略进行更全面的解释。”(P34,des)。“结构化的文本澄清了细微差别并提供了具体示例,使评估伦理影响更容易。”(P22,dev)。
熟悉度和经验:参与者强调了他们对基线风险内容熟悉的文本风格的舒适感,这与他们在类似任务中的先前经验一致。“因为我之前见过这样的东西……这使我更容易表达我的想法。”(P11,dev)。
5.4 道德
所有三项研究,包括共设计和评估,均已获得作者所在机构的批准。参与者收到知情同意书,详细说明了研究的目的、数据用途及他们的权利。确保了保密性和匿名性,数据处理遵循既定的道德准则。通过Prolific招募的参与者以每小时至少$12的最低费率得到补偿。研究材料如研究工件和主题分析代码手册按照Salehzadeh Niksirat等人[61]概述的透明标准共享。
6 讨论
在这项研究中,我们介绍了RiskRAG,这是一个基于检索增强生成的系统,旨在改善AI模型的风险报告流程。我们的工作填补了当前AI模型文档实践中的一个空白,特别是在模型卡方面,这些模型卡往往缺乏针对模型和AI使用的全面而具体的风险评估。通过与总共181名AI开发者、UX设计师和媒体专业人士进行迭代共设计和用户研究,我们实证证明了RiskRAG相比基准模型卡风险部分提供了更情境化和可行的风险报告。RiskRAG鼓励了一种更为谨慎和深思熟虑的模型选择方法,有效地支持决策。
6.1 AI开发者风险文档的数据驱动解决方案
与之前利用大型语言模型(LLM)设想AI风险的努力不同[11, 29, 69],RiskRAG扎根于现实世界数据集,确保了稳健和适应性强的解决方案。它采用检索增强生成方法,从模型卡或记录的实际危害中获取人类编写的风崄,最大限度减少了幻想和通用风险。RiskRAG增强了现有的解决方案,这些解决方案复制预定义格式或专注于模型卡子集(例如,CradGen与研究论文或GitHub存储库相关联[39])。相反,它适用于所有模型卡,解决了表7中强调的当前风险报告方法中的关键差距。Risk Cards [17] 不包含特定模型的风险或缓解策略,Kennedy-Mayo和Gord [34] 忽略了风险分类,而且这两种文档解决方案都没有涉及风险优先级。当前解决方案提供了部分解决方案,但未能满足已确定的风险文档全面要求。ExploreGen [29] 生成用途而非风险,而AHA! [11] 和 FarSight [69] 则为抽象AI系统生成风险,未针对特定模型进行定制或优先级排序。此外,没有任何方案提出可行的缓解策略。相比之下,RiskRAG独特地根据实际危害优先级排序风险,并将每个风险与定制的缓解策略相关联。然而,我们认为这些之前的解决方案可以补充RiskRAG。例如,RiskRAG在参与者回应中关于风险是否充分情境化到用例方面没有显示出统计显著性。结合像FarSight这样为特定应用生成风险的工具,可以增强RiskRAG在提供更全面和情境敏感风险评估方面的能力。
RiskRAG展示了强大的泛化潜力,为未曾见过和知名度较低的模型提供了两项关键优势:其结构化模板提示开发人员生成有意义的风险内容,而生成的报告则成为比空白页更有价值的起点。为了评估这一能力,我们从HuggingFace的45万模型快照中选择了四个知名度较低的模型(选择过程和模型描述见附录E)。对其由RiskRAG生成的报告进行手动评估确认了输出的实用性和相关性。这些生成的报告见Supp. Mat. 3.2,说明了RiskRAG如何支持有效风险文档编制,即使对于缺乏广泛前期信息的模型,也强化了其适应性和更广泛的适用性。
进一步地,RiskRAG的架构设计具有可扩展性,能够无缝集成更大和更全面的数据集,例如MIT AI风险存储库 28 { }^{28} 28 [64]、自动化事件存储库(AIAAIC)存储库 29 { }^{29} 29 和OECD AI事件监控系统(AIM) 30 { }^{30} 30。这确保了RiskRAG保持灵活性和前瞻性,随着新数据的出现而不断演进。此外,RiskRAG报告为每个已识别的风险提供清晰且可行的缓解策略,赋予模型用户在部署前主动应对潜在问题的能力。重要的是,我们视RiskRAG不仅为最终解决方案,而是作为支持AI开发者生成有效风险报告的工具。从其生成的内容和结构化格式开始,开发者可以更新、省略无关风险,并受到启发生成新的风险,从而促进协作和迭代的AI风险文档编制过程。这一过程不仅简化了风险评估,还解决了AI开发者识别潜在危害的动力不足的问题 [ 42 , 43 ] [42,43] [42,43],通过提供结构化和易访问的基础来支持风险文档编制。
6.2 提高认识和促进负责任的AI使用
截至2024年7月,在HuggingFace上的450K模型卡片中,只有64K包含了与风险相关的部分,其中只有2672张是独特的。这意味着大约 86 % 86 \% 86%的HuggingFace模型卡片没有提及任何风险。这些数字与之前研究的结果一致[4, 37]。我们的共设计研究支持这些结果,因为AI开发者报告说他们通常关注模型文档的技术方面,常常忽略与风险相关的部分。然而,他们也报告说在研究过程中我们提供的风险内容让他们感到受到启发和启迪,这与研究表明即使AI从业者和研究人员也难以预见与AI系统和模型相关的风险相一致[8,19]。
RiskRAG的实际潜力在于其与HuggingFace、GitHub、Model Zoo 31 { }^{31} 31、PyTorch Hub 32 { }^{32} 32 或 Google AI Hub 33 { }^{33} 33 等平台的整合。它可以作为模型卡创建的模板或交互界面,使AI开发者能够优先考虑特定于模型的风险和针对多种用途的情境化缓解措施。通过交互过程,开发者可以完善风险评估,检索相关的AI事件示例,并以较少的努力识别缓解策略。众包反馈可以进一步增强RiskRAG,改进其优先级技术,并随时间生成定制且可行的报告。
我们的研究结果突显了RiskRAG在促进审慎和负责任决策方面的能力。初步研究表明RiskRAG满足了所有期望的要求,而最终研究则表明其在提高用户(无论是开发者、设计师还是媒体专业人士)识别风险、制定缓解措施和提升解释质量方面具有有效性。通过加深用户对模型影响的理解,RiskRAG可以促成更明智的决策,例如选择不合适的模型,加强风险管理,并在部署前做出关键调整。这种方法有助于防止有害事件的发生,推动道德AI的使用,确保AI技术按负责任和安全的方式开发和部署。
6.3 更广泛的含义:模型卡、公众宣传和政策制定
最近的努力旨在增强模型卡中的伦理考量和风险部分 [17, 34]。通过将我们的研究成果整合到当前的标准AI模型文档——模型卡中,可以显著提升其功能。具体而言,风险部分可以转化为
1
28
{ }^{28}
28 https://airisk.mit.edu/
29
{ }^{29}
29 https://www.aiaaic.org/aiaaic-repository
30
{ }^{30}
30 https://oecd.ai/en/incidents
反映由RiskRAG生成的详细风险评估,使风险文档更加全面。这种增强有潜力建立新的最佳实践,鼓励更深入地参与潜在风险。因此,这可以将模型卡定位为影响评估报告的强大基础
[
5
,
6
,
44
]
[5,6,44]
[5,6,44],在部署前实现彻底评估。RiskRAG还开辟了关于在模型文档中展示特定用途的风险和缓解措施的新研究方向。通过为特定用途定制风险信息,模型卡可以演变为类似于影响评估报告的形式,为在各种情境中部署AI模型的后果提供更具结构化的决策方法。
除了风险部分,我们面向用户的RiskRAG开发方法还可以激励改进模型卡的其他部分,例如模型和数据规范。通过优化模型卡的展示和可用性,它们可以变得更加易访问、信息丰富且对各级开发者更有效。
随着围绕AI技术的监管审查力度加大 [ 14 , 30 ] [14,30] [14,30],企业和开发者必须确保符合不断变化的法律法规。RiskRAG可以通过识别风险并将其报告与特定监管要求对齐,简化这一过程,减少导航法律框架的复杂性,并帮助组织主动解决潜在的合规差距。这种对齐确保模型从一开始就能符合监管标准。此外,RiskRAG还有潜力增强风险信息对公众和政策制定者的可访问性。我们的研究参与者指出了传统风险报告缺乏透明度的问题,认为缺失或不清楚的信息是故意为之,影响了信任和责任。正如一位参与者所言,“在其文档中似乎假装传达了实际信息。” (P25, dev),而另一位则表示,“这让我觉得它实际上隐藏了关于其风险的信息,希望人们不知道。” (P24, dev)。通过提供更清晰和全面的见解,RiskRAG可以促进更大的信任,使利益相关者能够做出更明智的决策,并促进更负责任的AI治理。
6.4 局限性
RAG模型偏差和幻觉。检索增强生成(RAG),虽然比大型语言模型(LLMs)更能将生成的信息根植于外部数据库并减少幻觉,但也存在局限性。如果某些模型卡片过量代表,可能会发生检索偏差,不过我们在使用多样模型类型(如文本生成、图像和文本到文本、语音到文本)的用户研究中显示了高质量风险生成。通过纳入实际事件风险,我们进一步减少了对模型卡片的依赖,并捕捉到了未记录的风险。频率偏差在基于事件频率的风险优先级排序中可能出现,如果事件存储库(在这种情况下为AIID)存在偏差,则可能导致对某些风险的过度关注和其他风险的忽视。这可以通过整合多个存储库如OECD AIM [54] 和AIAAIC来缓解。尽管RAG系统比LLMs产生的幻觉更少 [23, 55],但仍偶尔会生成错误风险。例如,RiskRAG错误地标记了“通过生成误导或虚假图像制造虚假信息”的风险,针对的是处理但不生成图像的模型(即,图像到文本模型)。在实验中,强调模型类型以及模型输入和输出类型在提示中,最小化了此类错误。由于RiskRAG旨在辅助而不是取代开发者,这些错误带来的风险有限,因为开发者可以并且预计会精炼输出。未来的工作可以添加一个次级生成代理来验证风险并进一步减少幻觉。
最后,我们承认,我们方法提取的一些风险可能并不完全适用于特定模型。在§5.1的详细评估中,我们自动验证了检索到的风险的质量和相关性;然而,由于难以招募对特定模型具有高度专业知识和伦理知识的专家进行大规模专家研究,我们无法对此问题进行全面研究。相反,我们手动评估了两组模型的风险质量:三位作者拥有高专业知识的四个模型和四个不太知名的模型(详见附录E)。当被问及“这些风险是否与模型及其类型相关?”时,评分范围为1至5,所有模型的平均响应为4.75,表明对其相关性的强烈认同。
数据评估的局限性。我们选择了最受欢迎的模型卡片作为伪地面实况数据集,这可能无意中偏向于与现有知名模型紧密对齐的较新模型。为了验证RiskRAG在不太知名的模型上的性能,我们进行了额外的实验(详见附录E),证实了其有效性。未来的研究可以探索将与新模型相关的特定信息(例如,其关联论文,类似于CardGen)纳入以提高此类情况下的输出质量。
人工设置和研究范围。尽管我们在两项研究中与165名AI利益相关者合作并提供了现实任务,但这些研究是在受控环境中进行的,而非真实环境,并且是一次性实验而非纵向研究。这限制了我们发现的外部有效性,特别是关于RiskRAG的长期性能。
学习曲线和适应RiskRAG。主题分析显示,一些偏爱RiskRAG的参与者起初面临适应挑战,而那些偏爱基线报告的人则经常引用熟悉度作为选择的关键因素。这种差异,加上最终研究中的偏好得分——开发者为58%对比媒体专业人士为70%——表明习惯于传统报告的AI利益相关者可能需要额外努力来适应RiskRAG。未来的研究应探索混合方法,将RiskRAG的视觉结构矩阵与现有报告中常见的文本解释和表格示例相结合,正如我们的一些参与者提出的:“尽管热力图可以让您一目了然,但我更喜欢文本…我认为理想的应该是两者的结合”(P6,des)。
不完整(系统性)风险覆盖。尽管参与者认为RiskRAG的报告更为详细,但源自相似模型的风险仍可能存在错误,如上所述。此外,系统性风险需要更长时间才能显现,即使使用实际事件数据也难以完全捕捉 [68]。因此,RiskRAG对系统性危害的覆盖可能仍然不完整。
预训练模型。我们使用了未经进一步微调的预训练嵌入模型构建RiskRAG,基于先前研究的建议,这种方法通常表现良好。然而,鉴于生成详细风险内容的复杂性,未来研究应探讨是否预训练RAG组件在模型卡片数据或实际事件上能改进风险评估的质量。静态展示。我们专注于静态PDF形式的模型卡片展示,但很可能交互式格式会更有效。未来研究应探索开发者如何与动态、交互式的RiskRAG版本互动,其中风险和缓解措施根据选定的用例自适应调整。此外,社区驱动的反馈机制可以邀请开发者报告生产过程中遇到的新风险,随着时间推移丰富风险数据库。
7 结论
我们的RiskRAG研究展示了数据驱动、AI辅助风险报告系统的潜力,该系统与AI开发者的需要相一致。通过弥补当前模型卡风险报告中的空白并提供可行的见解,RiskRAG促进了负责任的AI使用并改进了风险文档实践。随着进一步完善和采用,RiskRAG可以显著提升AI模型在现实世界中的评估和部署方式,为更安全和透明的AI系统做出贡献。
参考文献
[1] Ada Lovelace Institute. 2022. 算法影响评估:AIA模板。Ada Lovelace Institute. Retrieved January 22, 2024 from https://www.adalovelaceinstitute.org/resource/aia-template/
[2] Simran Arora, Avner May, Jian Zhang, and Christopher Ré. 2020. 上下文嵌入:何时值得?https://doi.org/10.48550/arXiv.2005.09117 arXiv:2005.09117 [cs]
[3] Emily M Bender 和 Batys Friedman. 2018. 自然语言处理的数据声明:减轻系统偏差和促进更好科学研究的方法。Transactions of the Association for Computational Linguistics 6 (2018), 587-604.
[4] Avimash Bhat, Austin Coursey, Grace Hu, Sixian Li, Nadia Nahar, Shurui Zhou, Christian Kästner, 和 Jin L.C. Guo. 2023. ML模型文档的理想与实践:通过提示和可追溯性推动进展。In Proceedings of the 2023 CHI Conference on Human Factors in Computing Systems. ACM, 汉堡德国, 1-17. https://doi.org/10.1145/3544548.3581318
[5] Edyta Bogucka, Marios Constantinides, Sanja Šćepanović, 和 Daniele Quercia. 2024. AI设计:用于预先填充影响评估报告的责任人工智能框架。IEEE Internet Computing 28, 5 (2024年9月), 37-45. https://doi.org/10.1109/MIC.2024.3451351
[6] Edyta Bogucka, Marios Constantinides, Sanja Šćepanović, 和 Daniele Quercia. 2024. 与AI从业者和AI合规专家共同设计AI影响评估报告模板。AAAI/ACM AI、伦理和社会会议论文集 7, 1 (2024年10月), 168-180. https://doi.org/10.1609/aies.v7i1.35427
[7] Edyta Bogucka, Sanja Šćepanović, 和 Daniele Quercia. 2024. AI风险地图集:增强公众对AI风险的理解。AAAI人类计算与群体智能会议论文集 12 (2024年10月), 33-43. https://doi.org/10.1609/bcomp.v12i1.31598
[8] Margarita Boyarskaya, Alexandra Olteanu, 和 Kate Crawford. 2020. 克服AI系统开发和部署中的想象力失败。https://doi.org/10.48550/arXiv.2011.13416 arXiv:2011.13416 [cs]
[9] Virginia Braun 和 Victoria Clarke. 2006. 心理学中的主题分析应用,定性心理学研究 3, 2 (2006年1月), 77-101. https://doi.org/10.1191/1478088706ag0063oa
[10] Virginia Braun 和 Victoria Clarke. 2012. 主题分析。在APA心理学研究方法手册,第2卷:研究设计:定量、定性、神经心理学和生物学。美国心理学会,华盛顿特区,US, 57-71. https://doi.org/10.1037/13620-004
[11] Zana Bozinca, Chau Minh Pham, Maurice Jakesch, Marco Tulio Ribeiro, Alexandra Olteanu, 和 Saleema Amershi. 2023. AHA!:通过生成危害示例促进AI影响评估。https://doi.org/10.48550/arXiv.2306.03280 arXiv:2306.03280 [cs]
[12] Astrid Carolus, Martin J. Koch, Samantha Steaka, Marc Erich Latoschik, 和 Carolin Wienrich. 2023. MADLS - Meta AI素养量表:基于扎实能力模型和心理变化及元能力的AI素养问卷的发展与测试。人类行为计算机:人工人类 1, 2 (2023年8月), 100014. https://doi.org/10.1016/j.chbab.2023.100014
[13] Jiyoo Chang 和 Christine Custis. 2022. 理解机器学习文档实施中的挑战。在算法、机制和优化中的公平性和平等会议中。ACM, 弗吉尼亚州阿灵顿美国, 1-8. https://doi.org/10.1145/3531624.3535301
[14] 欧盟理事会。2024. 欧洲议会和欧盟理事会条例 (EU) 2024/1689。欧洲联盟官方期刊 L 168 (2024), 1-15. https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=OJAL_202401689 Accessed: 2024-07-29.
[15] Anamaria Crisan, Margaret Droshard, Jesse Vig, 和 Nazneen Rajani. 2022. 互动模型卡:以人为中心的模型文档方法。在2022年ACM公平性、问责制和透明度会议论文集 (FAoT '22) 中。计算机械协会,纽约,NY,美国,427-439. https://doi.org/10.1145/3531146.3533108
[16] Wesley Hanwen Deng, Solon Barocas, 和 Jennifer Wortman Vaughan. 2025. 支持行业计算研究人员评估、阐述和应对其工作潜在负面社会影响。https://doi.org/10.1145/3711076 arXiv:2408.01057 [cs]
[17] Leon Derczynski, Hannah Rose Kirk, Vidhisha Balachandran, Sachin Kumar, Yulia Tsvetkov, M. R. Leiser, 和 Saif Mohammad. 2023. 使用风险卡片评估语言模型部署。arXiv:2303.18190 [cs]
[18] Natalia Diaz-Rodriguez, Javier Del Ser, Mark Coeckelbergh, Marcos López de Prado, Enrique Herrera-Viedma, 和 Francisco Herrera. 2023. 在可信人工智能中连接点:从AI原则、伦理和关键要求到负责任的AI系统和法规。Information Fusion 99 (2023年11月), 101896. https://doi.org/10.1016/j.inffus.2023.101896
[19] Kimberly Do, Rock Yuren Pang, Jiachen Jiang, 和 Katharina Reinecke. 2023. “这很重要,但是…”:计算机科学研究人员如何预见其研究创新的意外后果。在2023年CHI人机交互会议论文集 (CHI '23) 中。计算机械协会,纽约,NY,美国,1-16. https://doi.org/10.1145/3544548.3581347
[20] OpenAI et al. 2024. GPT-4技术报告。https://doi.org/10.48550/arXiv.2303.08774 arXiv:2303.08774 [cs]
[21] Sabri Eyuboglu, Karan Goel, Arjun Desai, Lingjiao Chen, Mathew Monfort, Chris Ré, 和 James Zou. 2024. Model ChangeListés:表征ML模型的更新。在2024年ACM公平性、问责制和透明度会议论文集中。ACM, 巴西里约热内卢, 2432-2453. https://doi.org/10.1145/3630106.3659047
[22] Lynn Frewer. 2004. 公众与有效的风险沟通。毒理学通讯 149, 1-3 (2004年4月), 391-397. https://doi.org/10.1016/j.tuxlet.2003.12.049
[23] Yunfan Gao, Yun Xiong, Xinyu Gao, Kangxiang Jia, Jinlin Pan, Yuxi Bi, Yi Dai, Jiawei Sun, Meng Wang, 和 Haofen Wang. 2024. 大型语言模型的检索增强生成:综述。arXiv:2312.10997 [cs]
[24] Timnii Gofen, Jamie Morgenstern, Briana Vecchione, Jennifer Wortman Vaughan, Hanna Wallach, Hal Daumé Iil, 和 Kate Crawford. 2021. 数据集说明书。CACM 64, 12 (2021), 86-92.
[25] Delaram Goipsyegani, Isabelle Hupont, Cecilia Panigutti, Hardsvardhan J. Pandit, Sven Schade, Declan O’Sullivan, 和 Dave Lewis. 2024. AI卡片:迈向机器可读AI和风险文档的应用框架,灵感来自欧盟AI法案。在隐私技术和政策:第12届年度隐私论坛APP 2024,瑞典Karitriad,2024年9月4-5日,会议记录。Springer-Verlag, Berlin, Heidelberg, 48-72. https://doi.org/10.1007/978-3-031-68024-3_3
[26] Delaram Goipsyegani, Hardsvardhan J. Pandit, 和 Dave Lewis. 2023. 是否属于高风险,或者不属于——AI法案的高风险AI应用和协调标准的语义规范及影响。在2023年ACM公平性、问责制和透明度会议上。ACM, 美国伊利诺伊州芝加哥, 905-915. https://doi.org/10.1145/3593013.3594050
[27] 谷歌。2024. 模型卡:朝向AI透明度的一步。https://modelcards.withgoogle.com/about. Accessed: 2024-07-29.
[28] Greg Guest, Arwen Bunce, 和 Laura Johnson. 2006. 多少访谈足够?数据饱和和变异性的实验。Field Methods 18, 1 (2006), 59-82. https://doi.org/10.1177/1525822X05279903
[29] Viviane Herdel, Sanja Šćepanović, Edyta Bogucka, 和 Daniele Quercia. 2024. ExploreGen:用于构想AI技术用途和风险的大型语言模型。https://doi.org/10.48550/arXiv.2407.12454 arXiv:2407.12454 [cs]
[30] 白宫。2022. 《AI权利法案蓝图》| OSTP. https://www.whitehouse.gov/ontp/ai-bill-of-rights/
[31] Isabelle Hupont, David Fernández-Llorca, Sandra Baldassarri, 和 Emilia Gómez. 2024. 用例卡片:受欧洲AI法案启发的用例报告框架。伦理与信息技术 26, 2 (2024年3月), 19. https://doi.org/10.1007/s10676-024-09757-7
[32] Ben Hutchinson, Andrew Smart, Alex Hanna, Emily Denton, Christina Greer, Oddur Kjartansson, Parker Barnes, 和 Margaret Mitchell. 2021. 朝向机器学习数据集问责:来自软件工程和基础设施的做法。在2021年ACM公平性、问责制和透明度会议论文集中,ACM, 加拿大虚拟会议,560-575. https://doi.org/10.1145/3442188.3445918
[33] Nikhil Kandpal, Haikang Deng, Adam Roberts, Eric Wallace, 和 Colin Raffel. 2023. 大型语言模型难以学习长尾知识。在第40届国际机器学习会议论文集中,PMLR, 夏威夷, 15696-15707.
[34] DeBrae Kennedy-Mayo 和 Jake Gord. 2024. "模型卡片用于模型报告"在2024年:根据可靠性和风险管理重新分类伦理考虑类别。https://doi.org/10.48550/arXiv.2403.15394 arXiv:2403.15394 [cs]
[35] Yang W Lee, Diane M Strong, Beverly K Kahn, 和 Richard Y Wang. 2002. AIMQ:一种信息质量评估方法。信息与管理
40
,
2120021
,
133
−
146
40,2120021,133-146
40,2120021,133−146.
[36] Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fahio Petroni, Vladimir Karpukhin, Numan Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, 和 Douwe Karla. 2020. 检索增强生成用于知识密集型NLP任务。在神经信息处理系统进展中,第35卷。Curran Associates, Inc., 加拿大温哥华,9459-9474.
[37] Weixin Liang, Nazneen Rajani, Xinyu Yang, Ezinwanne Ozsani, Eric Wu, Yiqun Chen, Daniel Scott Smith, 和 James Zou. 2024. AI中记录了什么?32K AI模型卡片的系统分析。arXiv:2402.05160 [cs]
[38] Chin-Tew Lin. 2004. ROUGE:自动摘要评价包。在The Summarization Branches Out中。计算语言学协会,西班牙巴塞罗那,74-91.
[39] Jianxi Liu, Wenkai Li, Zhijing Jin, 和 Mona Diab. 2024. 模型和数据卡的自动生成:朝向负责任AI的一步。arXiv:2405.06258 [cs]
[40] LMSYS. 2024. LMSYS排行榜领袖。Huggingface. Retrieved July 9, 2024 from https://lmsys.org/blog/2023-06-22-leaderboard/
[41] Bill MacCartney 和 Christopher D. Manning. 2008. 自然语言推理中语义包含和排除的建模。在第22届计算语言学国际会议(Coling 2008)论文集中,Donia Scott 和 Hans Uszkoreit (Eds.)。Coling 2008 组织委员会,英国曼彻斯特,
521
−
528
521-528
521−528.
[42] Michael Madaio, Lisa Egede, Hariharan Subramonyam, Jennifer Wortman Vaughan, 和 Hanna Wallach. 2022. 评估AI系统的公平性:AI从业者的流程、挑战和支持需求。Proc. ACM Hum. Comput. Interact. 6, CSCW1 (2022年4月), 52:1-52:26. https://doi.org/10.1145/3512899
[43] Michael A. Madaio, Luke Stark, Jennifer Wortman Vaughan, 和 Hanna Wallach. 2020. 共同设计清单以了解AI中的公平性挑战和机遇。在2020年CHI人机交互会议论文集(CHI '20)中。计算机械协会,纽约,NY,美国,1-14. https://doi.org/10.1145/3313831.3376445
[44] Alessandro Mantelero 和 Maria Samantha Esposito. 2021. 人工智能数据密集型系统发展的人权影响评估(HRIA)的证据基础方法。计算机法律与安全评论 41 (2021), 105561.
[45] Sean McGregor. 2021. 通过编目事件预防重复的真实世界AI失败:AI事件数据库。AAAI人工智能会议论文集 35, 17 (2021年5月), 15458-15463. https://doi.org/10.1609/aaaiz35i17.17817
[46] Grégoire Mialon, Roberto Desol, Maria Lomeli, Christoforos Nalmpantis, Ram Pasunuru, Roberta Raineanu, Baptiste Rozière. Timo Schick, Jane Dwivedi-Yu, Asli Celikydmaz, Edouard Grave, Yann LeCun, 和 Thomas Scialom. 2023. 增强语言模型:综述。arXiv:2302.07842 [cs]
[47] Matthew B. Miles, A. Michael Huberman, 和 Johnny Saldana. 2013. 定性数据分析:方法指南。SAGE Publications, CA, 美国。
[48] Margaret Mitchell, Simone Wu, Andrew Zaldívar, Parker Barnes, Lucy Vasserman, Ben Hutchinson, Elena Spitzer, Inioluwa Deborah Raji, 和 Tinnüt Gebru. 2019. 模型卡用于模型报告。在公平性、问责制和透明度会议论文集中,ACM, 亚特兰大GA美国,220-229. https://doi.org/10.1145/3287560.3287596
[49] Sail M Mohammad. 2022. AI任务的伦理表单。计算语言学 48, 2 (2022), 239-278.
[50] Niklas Muennighoff, Nosamane Tazi, Loic Magne, 和 Nils Reimers. 2023. MTER:大规模文本嵌入基准。在欧洲计算语言学协会第17次会议论文集中,Andreas Vlachos 和 Isabelle Augenstein (Eds.)。计算语言学协会,克罗地亚杜布罗夫尼克,2014-2037。https://doi.org/10.18653/v1/2023.eacl-main.148
[51] 国家标准与技术研究院(NIST)。2023. AI风险管理框架。https://www.nist.gov/itl/ai-risk-management-framework 访问日期:2024-11-19。
[52] José Luiz Nunes, Gabriel D. J. Barbosa, Clarisse Sieckenius de Souza, Helio Lopes, 和 Simone D. J. Barbosa. 2022. 使用模型卡进行伦理反思:定性探索。在巴西人机交互系统研讨会论文集 (IHC '22) 中。计算机械协会,纽约,NY,美国,1-11。https://doi.org/10.1145/3554364.3539117
[53] 经济合作与发展组织(OECD)。2020. NNFa指南 - 经济合作与发展组织。https://omegaidebias.oecd.org/coo-and-digitalisation.htm.
[54] 经济合作与发展组织(OECD)。2024. AI事件。https://oecd.ai/en/incidents 访问日期:2024-11-27。
[55] Oded Ovadia, Menachem Brief, Moshik Mishaeli, 和 Oren Elisha. 2024. 微调还是检索?比较LLM中的知识注入方法。https://doi.org/10.48550/arXiv.2312.05934 arXiv:2312.05934 [cs]
[56] David Piorkowski, Michael Hind, 和 John Richards. 2024. 定量AI风险评估:机遇与挑战。https://doi.org/10.48550/arXiv.2209.06317 arXiv:2209.06317 [cs]
[57] Charvi Rastogi, Marco Tulio Ribeiro, Nicholas King, Harsha Nori, 和 Saleema Amershi. 2023. 在审计LLM时使用LLM支持人类-AI协作。在AAAI/ACM人工智能、伦理和社会会议论文集 (AIES '23) 中。计算机械协会,纽约,NY,美国,913-926。https://doi.org/10.1145/3600211.3604712
[58] Maribeth Rauh, Nahema Marchal, Arianna Manzini, Lisa Anne Hendricks, Ramona Comanescu, Canfer Akbulut, Tom Stephrion, Juan Mateos-Garcia, Stevie Bergman, Jackie Kay, Conor Griffin, Ben Bariach, Jason Gabriel, Verena Rieser, William Isaac, 和 Laura Weidinger. 2024. 生成式AI安全性评估中的空白。AAAI/ACM人工智能、伦理和社会会议论文集 7, 1 (2024年10月), 1200-1217。https://doi.org/10.1609/aiex.v7i1.31717
[59] Athena Richards, Sheila Convery, Margaret O’Mahony, 和 Brian Caulfield. 2024. 疫情前后在家工作的偏好。旅行行为与社会 34 (2024), 100679。
[60] Johnny Saldana. 2015. 定性研究编码手册。SAGE, CA, 美国。
[61] Kavous Salehzadeh Niksirat, Lahari Goswami, Pooja S. B. Rao, James Tyler, Alessandro Silacci, Sadin Aliyu, Annika Aebli, Chat Wacharamanotham, 和 Mason Cherubini. 2023. CHI 2017至CHI 2022间实证研究中研究伦理、开放性和透明性的变化。在2023年CHI人机交互会议论文集 (CHI '23) 中。计算机械协会,纽约,NY,美国,1-23。https://doi.org/10.1145/3544548.3580848
[62] Victor Sanh, Lysandre Debut, Julien Chaumond, 和 Thomas Wolf. 2020. DistilBERT:一个更小、更快、更便宜和更轻便的BERT版本。https://doi.org/10.48550/arXiv.1910.01108 arXiv:1910.01108 [cs]
[63] Hong Shen, Leijie Wang, Wesley H. Deng, Ciall Brusse, Ronald Velgervallik, 和 Hanyi Zhu. 2022. 模型卡片创作工具包:迈向以社区为中心、以审议驱动的人工智能设计。在2022年ACM公平性、问责制和透明度会议论文集 (FAoT '22) 中。计算机械协会,纽约,NY,美国,440-451。https://doi.org/10.1145/3531146.3533110
[64] Peter Slattery, Alexander K. Saeri, Emily A. C. Grundy, Jess Graham, Michael Noetel, Risto Uuk, James Dao, Sorosuh Pour, Stephen Casper, 和 Neil Thompson. 2024. AI风险存储库:人工智能风险的综合元评论、数据库和分类法。https://doi.org/10.48550/arXiv.2408.12622 arXiv:2408.12622 [cs]
[65] Bernd Carsten Stahl, Josephina Antoniou, Nitika Bhalla, Laurence Brooks, Philip Jansen, Bletta Lindqvist, Alexey Kirichenko, Samuel Marchal, Rowena Rodrigues, Nicole Santiago, Zuzanna Waxo, 和 David Wright. 2023. 人工智能影响评估的系统综述。人工智能评论 56, 11 (2023), 12799-12831。https://doi.org/10.1007/s10462-023-10420-8
[66] Nandan Thakur, Nils Reimers, Andreas Rücklé, Abhishek Srivastava, 和 Iryna Gurevych. 2021. BEIB:用于零样本评估信息检索模型的异构基准。https://doi.org/10.48550/arXiv.2021.04.08663 arXiv:2021.04.08663 [cs]
[67] Vilie Vakkuri, Kai-Kristian Kemell, Marianna Juntunen, Erika Halme, 和 Pekka Abrahamsson. 2021. ECCOLA - 实施符合伦理的人工智能系统的实用方法。系统与软件杂志 182 (2021年12月), 111067。https://doi.org/10.1016/j.jss.2021.111067
[68] Julia De Miguel Velázquez, Sanja Šćepanović, Andrés Gvirtz, 和 Daniele Quercia. 2024. 解码真实世界的人工智能事件。计算机 57, 11 (2024年11月), 71-81。https://doi.org/10.1109/MC.2024.3432492
[69] Zijie J. Wang, Chinmay Kulkarni, Lauren Wilcox, Michael Terry, 和 Michael Madaio. 2024. Farsight:在AI应用原型设计期间促进负责任AI意识。在2024年CHI人机交互会议论文集 (CHI '24) 中。计算机械协会,纽约,NY,美国,1-40。https://doi.org/10.1145/3613904.3642335
[70] Hilde Weerts, Miroslav Dudík, Richard Edgar, Adrin Jalali, Roman Lutz, 和 Michael Madaio. 2023. Fairlearn:评估和改进AI系统的公平性。机器学习研究期刊 24, 1 (2023年1月),257:12058-257:12065。
[71] Laura Weidinger, Maribeth Rauh, Nahema Marchal, Arianna Manzini, Lisa Anne Hendricks, Juan Mateos-Garcia, Stevie Bergman, Jackie Kay, Conor Griffin, Ben Bariach, Jason Gabriel, Verena Rieser, 和 William Isaac. 2023. 生成式AI系统的社会技术安全性评估。arXiv:2310.11986 [cs]
[72] Adina Williams, Nikita Nangia, 和 Samuel Bowman. 2018. 推理理解句子的广覆盖挑战语料库。在NAACL-HLT 2018会议论文集第1卷(长篇论文)中,Marilyn Walker, Heng Ji, 和 Amanda Stent (Eds.),计算语言学协会,新奥尔良,路易斯安那州,1112-1122。https://doi.org/10.18653/v1/N181101
[73] Xinyu Yang, Weixin Liang, 和 James Zou. 2024. AI数据集中导航数据文档:Hugging Face上数据卡的大规模分析。https://doi.org/10.48550/arXiv.2401.13822 arXiv:2401.13822 [cs]
[74] Weizhe Yuan, Graham Neubig, 和 Pengfei Liu. 2021. BARTScore:作为文本生成评估的生成文本评估。在神经信息处理系统进展会议论文集,第34卷。Curran Associates, Inc., 加拿大温哥华,27263-27277。
[75] Tianyi Zhang, Varsha Kishore, Felix Wu, Kilian Q. Weinberger, 和 Yoav Artzi. 2020. BERTScore:用BERT评估文本生成。https://doi.org/10.48550/arXiv.1904.09675 arXiv:1904.09675
[76] 张悦,李雅芙,崔乐洋,蔡登,刘磊茂,傅廷晨,黄鑫婷,赵恩博,张宇,陈玉龙,王龙越,陆安图,韦比,石峰,和史树明。2023. 大规模语言模型中的幻觉问题调查。https://doi.org/10.48550/arXiv.2309.01219 arXiv:2309.01219 [cs]
A 从文献中选取的用于引出风险报告设计要求的论文列表
(1) 模型卡用于模型报告 [48]。本文介绍了模型卡的概念,旨在提供AI模型的透明文档。伦理考虑部分旨在展示模型开发过程中的伦理考量,揭示伦理挑战和风险,并说明所使用的缓解策略。模型卡应识别与模型使用相关的潜在风险和危害。它应明确说明AI模型的主要预期用途。这有助于用户了解模型的范围和局限性,减少误用的风险。
(2) 互动模型卡:以人为中心的模型文档方法 [15]。本文讨论了通过互动模型卡增强模型文档的方法。他们发现当前的风险部分模糊不清,安全和伦理主题过于抽象。
(3) 使用模型卡进行伦理反思:定性探索 [52]。本文讨论了模型卡在伦理反思中的作用,这对于理解和记录AI风险至关重要。文章发现开发者选择性地记录AI模型卡中的伦理问题,突显了AI开发中不完整伦理反思的潜在风险。这表明需要更好的文档实践来确保更符合伦理的AI设计。
(4) ML模型文档的理想与实践:通过提示和可追溯性推动进展 [4]。本文重点在于提议的模型文档实践与实际实践之间的差距。他们发现只有约
35
%
35 \%
35%的模型文档讨论了偏差或伦理问题,而只有
10
%
10 \%
10%讨论了如何缓解这些问题。
(5) 理解机器学习文档实施中的挑战 [13]。本文解决了实施ML文档的挑战,这对于理解报告AI风险中的障碍至关重要。他们建议将文档作为项目交付物,以激励更好的实践。
(6) 模型ChangeLists:描述ML模型更新 [21]。本文探讨了记录ML模型更新的方法,这直接关系到在整个模型生命周期中维护和报告AI风险。
(7) AI中记录了什么?32K AI模型卡的系统分析 [37] 对HuggingFace上的32K模型卡的分析显示,只有
17
%
17 \%
17%的所有卡片和
39
%
39 \%
39%下载量最高的前100个卡片包含关于风险和限制的部分。他们发现模型卡报告了训练数据的限制以及AI模型的技术和社会限制。
(8) “模型卡用于模型报告”在2024年:根据可靠性和风险管理重新分类伦理考虑类别 [34],提出了重构伦理考虑部分以明确列出监管、声誉和运营风险。
B 共设计过程中生成的报告工件
我们在图8中概述了共设计过程中风险报告的迭代开发。
C RiskRAG和CardGen
我们使用CardBench评估集对比了RiskRAG和CardGen(表8)。在CardBench的294张模型卡中,只有40张包含任何风险相关内容(在[39]中称为“偏差”)。为了公平评估,我们专注于这40张模型卡。为了评估RiskRAG,我们将CardBench中的地面真相模型卡调整为关注个体风险,详见 § 5.1.2 \S 5.1 .2 §5.1.2 并如图5所示。对于CardGen,我们仅评估其在CardBench中的风险相关内容(“偏差”),与[39]中报告的评估一致。对于两种方法(RiskRAG和CardGen),我们报告了应用于CardGen的相同自动化指标:ROUGE [38], BERTScore [75], BARTScore [74], 和 NLI微调模型 [41, 72]。
如表8所示,RiskRAG在所有指标上始终匹配或优于CardGen。尽管两种方法的风险相关内容格式有所不同,但我们认为评估结果仍然具有参考价值,证明RiskRAG提供了有竞争力的风险相关内容。
D 初步研究反馈的定性分析
两位作者对开放式问题的定性反馈进行了归纳主题分析 [9],采用了既定的定性编码方法 [47, 60]。参与者响应被记录为便利贴,基于这些数据共同开发主题。作者通过讨论解决分歧,确保达成共识。每个确定的主题都由至少两名参与者的引用支持,展示了数据饱和 [28]。
已确定参与者更喜欢RiskRAG报告而不是基线报告,我们对他们定性响应的内容进行了主题分析,以了解原因。在他们的偏好解释回答中,参与者赞扬了RiskRAG报告在以下方面的表现:(R1) 详细且深入的信息 (P11: ‘它的内容也更加详细,节省了我回答潜在后续问题的时间。’); (R2) 清晰且结构化的表达 (P28: ‘表格视图使得更容易理解每种用途下的风险级别,并能快速查看我的用途是否属于高风险。’); (R3) 针对具体情境的相关性 (P3: ‘我更喜欢风险报告A,因为风险是根据它们是否适用于所展示的用途来呈现和分类的。’); (R4) 可操作的缓解策略 (P36: ‘报告B更有帮助,因为它特别列出了潜在的道德和安全危害及应对这些危害的可能解决方案。’); 和 (R5) 风险信息的优先级排序 (P2: ‘它更清楚地优先考虑某些风险及其现实世界的危害,以便更关注重要的风险。’)。除了这些与我们的设计要求相关主题外,还出现了参与者的以下三个主题:(1) 决策和沟通的可用性 (P7: ‘A中提供的信息足以让我写一封知情且有用的邮件。’ 和 P26: ‘风险报告A对任务更有帮助。’); (2) 视觉效果和布局
(P19: ‘带有图形的那个更好,因为它更具视觉性,可以让你立即获取更多信息。’ 和 P29: ‘风险报告A提供了更容易浏览和理解的因素概览。’); 和 (3) 相较于基线报告,对透明度的信任 (P24: ‘它让我觉得风险报告B实际上隐藏了与其风险相关的信息,宁愿人们不知道这些信息。’)。
E RiskRAG对未见过和知名度较低模型的泛化能力
为了评估RiskRAG的泛化能力,我们从HuggingFace上461,181张模型卡的快照中选择了四张知名度较低的模型卡。使用余弦相似度,我们将这些模型的名字与我们数据集中2.6K个模型名字进行比较(见4.1.1节),量化其语义一致性。确定了相似度得分最低的四个模型,确保它们是我们用来开发RiskRAG的模型中最不相似的。这种方法为我们测试RiskRAG在新颖和不太熟悉的案例中的稳健性提供了一个多样化且具有挑战性的子集。所选模型 34 { }^{34} 34 涵盖了各种类型——文本到图像、文本分类和文本生成——并且使用率低,下载次数从5到60次不等。生成的风险报告可在Supp. Mat. 3.2中找到。
这四个选定模型原本没有任何与风险相关部分。相比之下,RiskRAG分别为每个模型生成了21、25、21和19个风险。我们手动检查了这些模型的报告,发现它们不仅相关,而且为创建其他缺失的风险部分提供了大量支持。例如,文本到图像模型CyberHarem/toyokawa_fuuka_theidolmstermillionlive,该模型生成NSFW动漫角色,收到了一份包含25个相关风险的报告——其中13个来源于AIID数据集。确定的风险包括:“由于CSAM包含在数据集中产生非法内容”,“如果被滥用,会推广虐待暴力或色情材料”,“强化或加剧社会偏见"以及"通过关联个人或群体与冒犯性内容损害声誉”。这证实了这些报告中的风险和缓解措施是相关的,展示了RiskRAG即使对于不太知名的模型也能生成有意义输出的能力。
为了评估这些较少知名模型是否满足已识别的设计要求,三位作者独立使用初步研究(§5.2.3)中的相同评估标准对报告进行了评分。五个要求的平均得分分别为4.17(R1)、4.33(R2)、4.00(R3)、2.67(R4)和3.17(R5)。大多数要求得到了充分满足,得分与用户研究(图6)中的得分类似。较低的缓解策略得分(R4)可能反映了模型卡中的常见模式,即缓解细节通常不如识别到的风险那么详尽;而对于较少知名模型,这种差距更为明显,因为它们的风险和缓解策略往往很少或完全缺失。
${ }^{34}$ https://huggingface.co/artificialguybr/studioghibli-redmond-2-1v-studioghibli-lora-for-freedom-redmond-sd-2-1, https://huggingface.co/CyberHarem/toyokawa_fuuka_theidolmstermillionlive, https://huggingface.co/MouezYazidi/XML-RoBERTa-CampingReviewsSentiment, https://huggingface.co/TahaCakir/enhanced_turkishReviews-generativeAI
表8:使用ROUGE-L (R)、BERTScore (BE)、BARTScore (BA) 和 NLI预训练评分器 (NLI) 对RiskRAG进行评估。我们提供了CardGen在风险相关部分(在[39]中称为‘bias’)的top-k = 10的分数,因为这些是在[39]中唯一报告的用于比较的数据。RiskRAG在所有指标上均匹配或优于CardGen,表明RiskRAG能够提供具有竞争力的风险相关内容。
| top-k = 5 | top-k = 10 | top-k = 15 | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 模型↓指标→ | R | BE | BA | NLI | R | BE | BA | NLI | R | BE | BA | NLI |
| AI风险文档 | ||||||||||||
| 风险卡 [17] | β \boldsymbol{\beta} β | ✓ \checkmark ✓ | ✓ \checkmark ✓ | β \boldsymbol{\beta} β | β \boldsymbol{\beta} β | β \boldsymbol{\beta} β | - | |||||
| 模型卡2024 [34] | ✓ \checkmark ✓ | β \boldsymbol{\beta} β | ✓ \checkmark ✓ | ✓ \checkmark ✓ | β \boldsymbol{\beta} β | ✓ \checkmark ✓ | - | |||||
| 填充AI风险文档的工具 | ||||||||||||
| ExploreGen [29] | β \boldsymbol{\beta} β | β \boldsymbol{\beta} β | ✓ \checkmark ✓ | β \boldsymbol{\beta} β | β \boldsymbol{\beta} β | β \boldsymbol{\beta} β | β \boldsymbol{\beta} β | |||||
| AHA! [11] | β \boldsymbol{\beta} β | ✓ \checkmark ✓ | ✓ \checkmark ✓ | β \boldsymbol{\beta} β | β \boldsymbol{\beta} β | β \boldsymbol{\beta} β | β \boldsymbol{\beta} β | |||||
| Faruight [69] | β \boldsymbol{\beta} β | ✓ \checkmark ✓ | ✓ \checkmark ✓ | β \boldsymbol{\beta} β | ✓ \checkmark ✓ | β \boldsymbol{\beta} β | β \boldsymbol{\beta} β | |||||
| CardGen [39] | ✓ \checkmark ✓ | β \boldsymbol{\beta} β | β \boldsymbol{\beta} β | β \boldsymbol{\beta} β | β \boldsymbol{\beta} β | ✓ \checkmark ✓ | ✓ \checkmark ✓ | |||||
| RiskRAG(我们的) | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ | ✓ \checkmark ✓ |
表:将RiskRAG与两个主要研究领域中密切相关的先前工作进行比较:AI风险文档和填充此类文档的工具。对于AI风险文档解决方案,我们检查它们是否满足我们确定的每个设计要求,以及是否专门为模型卡设计。对于填充AI风险文档的工具,我们评估其内容是否满足要求,是否针对模型卡定制,以及是否利用RAG技术。AI文档提案如Risk Cards和Model Cards在2024年缺乏风险优先级排序(R5),未解决缓解策略(R4),或未按分类学结构化(R2)。填充AI风险文档的工具如ExploreGen、AHA!、FarSight和CardGen未专注于生成特定于模型的风险(R1)、缓解策略(R4)或优先级排序(R5),并且主要依赖于大型语言模型(LLMs)。虽然CardGen使用了RAG技术,但它生成的风险内容模仿现有的模型卡,而这本身未能满足设计要求。

图8:风险报告迭代开发的概述,突出显示了五轮中的结构、展示和优先级的变化。
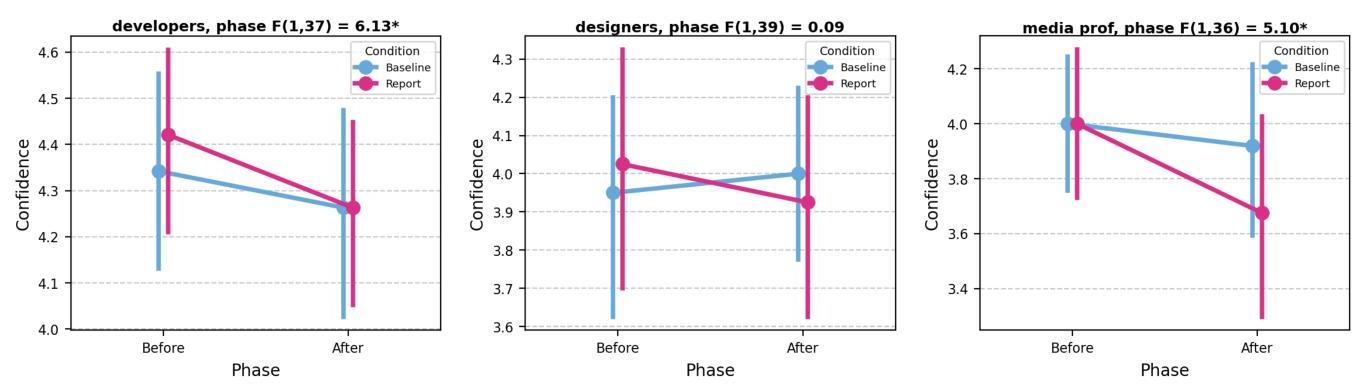
图9:最终研究:与基线报告相比,三个组别在与RiskRAG报告互动前后的决策信心差异(y轴)。阶段(互动前和后风险报告)对开发者和媒体专业人士的决策信心产生了显著的主要影响,RiskRAG报告比基线报告导致信心下降更多(* p<0.05)。
参考论文:https://arxiv.org/pdf/2504.08952


















 486
486

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











