






阴文婧 1 ∗ { }^{1 *} 1∗,孙天泽 2 { }^{2} 2,余一 jong 3 { }^{3} 3,方佳伟 4 { }^{4} 4,苏广耀 4 { }^{4} 4,王建城 4 { }^{4} 4,王泽坤 5 { }^{5} 5,汪威 5 { }^{5} 5,陈然 5 { }^{5} 5,戴子云 5 { }^{5} 5,袁帅 1 { }^{1} 1,董孟航 1 { }^{1} 1,罗鹏 5 { }^{5} 5,曹东 5 { }^{5} 5,雷达 5 { }^{5} 5,张亚军 5 { }^{5} 5,陈昊 5 { }^{5} 5,马翔 5 { }^{5} 5,刘勇 5 { }^{5} 5,刘卫锋 5 { }^{5} 5,徐元剑 6 { }^{6} 6,裴继 5 { }^{5} 5, 1 { }^{1} 1 北京大学, 2 { }^{2} 2 哈尔滨工业大学, 3 { }^{3} 3 清华大学, 4 { }^{4} 4 中国联通软件研究院, 5 { }^{5} 5 OpenCSG, 6 { }^{6} 6 香港科技大学(广州)
摘要
大型语言模型(LLMs)在软件工程中起着至关重要的作用,在代码生成和维护等任务上表现出色。然而,现有的基准测试通常范围狭窄,专注于特定任务,并缺乏一个能反映实际应用的综合评估框架。为了解决这些不足,我们引入了CoCo-Bench(综合代码基准),旨在从四个关键维度评估LLMs:代码理解、代码生成、代码修改和代码审查。这些维度涵盖了开发人员的核心需求,确保更系统和更具代表性的评估。CoCo-Bench 包含多种编程语言和不同难度的任务,并通过严格的人工审核来确保数据质量和准确性。实证结果表明,CoCo-Bench 与现有基准一致,同时揭示了模型性能上的显著差异,有效突出了其优缺点。通过提供全面和客观的评估,CoCo-Bench 为未来代码导向型LLMs的研究和技术进步提供了宝贵的见解,建立了该领域的可靠基准。
1 引言
近年来,人工智能在软件工程中的应用(AI4SE)(McDermott 等人,2020)迅速发展,从代码生成和错误检测到软件测试。然而,这些进展暴露了现有代码基准的局限性。许多基准无法全面评估大型语言模型(LLMs),往往高估了它们的真实性能,导致有偏见的结论。
如表1所示,当前的基准如HumanEval(Chen等人,2021)和MBPP(Austin
等人,2021)专注于在线容易获取的简单测试用例,这使得它们容易被模型过度拟合。像CoderEval(Zhang等人,2024b)和ClassEval(Du等人,2023)这样的基准针对特定的LLM能力,但缺乏全面覆盖以进行整体评估。迫切需要一个客观、系统和全面的基准来支持AI4SE的持续发展。
我们认为,一个有效的基准应该紧密贴合真实场景,并评估LLMs在程序员四项关键能力上的表现:代码理解(CU,理解现有代码的能力)、代码生成(CG,根据给定上下文生成代码的能力)、代码修改(CM,检测并修改代码错误的能力)和代码审查(CR,评估和改进代码质量的能力)。这四个维度提供了一个强大的框架来评估LLMs,确保对其在实际开发环境中的表现进行全面而系统的测量。
为了满足这些需求,我们引入了CoCoBench,这是一个设计用于评估LLMs在四个关键维度上的综合代码基准。它评估了一系列编程语言和不同难度的任务,并通过严格的审核确保质量和准确性。与现有基准不同,CoCo-Bench具有创新的任务设计,例如CU的逆向推理和CG的多层次代码补全,提供了对模型能力的更全面评估。CoCo-Bench通过包含简单和复杂任务,确保任务多样性并与实践对齐。这种方法防止了过拟合并更好地反映了模型在实际开发环境中的表现,提供了一个细致的框架来识别不同能力维度上的优势和劣势。
我们的实证结果表明,CoCoBench不仅与现有基准一致,还揭示了模型在不同能力维度上的显著差异。这有效地指出了各种代码LLMs的优势和劣势。通过提供更全面和客观的评估,CoCoBench旨在指导未来研究,推动代码导向型LLMs的技术进步,并为软件工程领域建立可靠的基准标准。
* ameliayin@stu.pku.edu.cn
* 
图1:CoCo-Bench核心评估维度概述。该框架评估了代码LLMs的四个关键能力:代码理解(CU)、代码生成(CG)、代码修改(CM)和代码审查(CR)。评估流程突出了这些能力在现实世界软件开发场景中的相互关联性。
marks但也在不同能力维度上揭示了模型性能的重大差异。这有效地指出了各种代码LLMs的优势和劣势。通过提供更全面和客观的评估,CoCoBench旨在指导未来研究,推动代码导向型LLMs的技术进步,并为软件工程领域建立可靠的基准标准。
2 相关工作
用于LLMs的代码基准测试最近经历了显著的发展,反映了该领域的显著进展。早期作品如HumanEval(Chen等人,2021)、Mostly Basic Programming Problems (MPBB)(Austin等人,2021)和The Code/Natural Language Challenge (CoNaLa)(Yin等人,2018)专注于基本的CG任务。HumanEval评估了模型使用真实世界任务生成Python函数的能力,而MPBB包括974个面向入门级程序员的任务,评估了从复杂文本描述生成代码的能力。
大多数代码基准主要集中在与CG相关的任务上。APPS(Hendrycks等人,2021)挑战模型根据自然语言生成Python代码,模拟真实的开发者任务。CoderEval(Zhang等人,2024b)通过关注开源项目中常见的非独立函数扩展了评估,提供了一个评估功能正确性的平台。ClassEval(Du等人,2023)引入了一个面向类级别CG的基准,通过关注更复杂的任务解决了现有评估中的空白。Concode(Iyer等人,2018)目标是从英文文档生成Java类成员函数,解决了类成员函数生成的挑战。CodeXGLUE(Lu等人,2021)和CodeEditorBench(Guo等人,2024)推进了代码理解和编辑的研究,评估了诸如调试和需求切换等任务。
随着任务复杂性的增加,新的基准出现了,以涵盖更广泛的场景。DyPyBench(Bouzenia等人,2024)是第一个全面的Python项目动态程序分析基准。SWE-BENCH(Jimenez等人,2024)通过将GitHub问题与合并的拉取请求链接起来,评估模型生成通过真实测试的补丁的能力。CRUXEval(Gu等人,2024)使用800个不同的Python函数测试模型在实际编码任务上的表现,而Debugbench(Tian等人,2024)则专注于评估调试能力,反映了超越CG的更复杂评估需求。LiveCodeBench(Jain等人,2024)通过不断从竞争平台上获取新的编程挑战,采用动态方法评估模型在代码自我修复和测试输出预测方面的真实世界能力。CodeMind(Liu等人,2024)引入了独立执行推理和规范推理等维度,评估模型在复杂任务中的表现,超越了简单的CG。
多任务基准也变得越来越重要。CodeFuseEval(Di等人,2024)结合了HumanEval-x和MPBB的标准,引入了代码补全和跨语言翻译等多任务场景。UltraEval(He等人,2024)提供了一个轻量级的综合框架,评估LLMs在各种任务中的表现,提供了一个统一的评估平台。
3 任务定义
在CoCo-Bench中,我们定义了四个主要任务,以全面评估LLMs在软件工程中的能力。每个任务都通过数学符号形式化定义,以确保评估的清晰性和精确性。图2显示了一些示例。
3.1 代码理解(CU)
CU被形式化为双向推理问题。设 C \mathcal{C} C表示所有可能代码片段的集合, I \mathcal{I} I表示所有可能输入参数的集合, O \mathcal{O} O表示所有可能输出的集合。CU任务由两个函数组成: f C U : C × I → O f_{\mathrm{CU}}: \mathcal{C} \times \mathcal{I} \rightarrow \mathcal{O} fCU:C×I→O 和 f C U − 1 : C × O → P ( I ) f_{\mathrm{CU}}^{-1}: \mathcal{C} \times \mathcal{O} \rightarrow \mathcal{P}(\mathcal{I}) fCU−1:C×O→P(I)。其中, f C U ( C , I ) = O f_{\mathrm{CU}}(C, I)=O fCU(C,I)=O预测给定代码片段 C C C和输入参数 I I I的输出 O O O,而 f C U − 1 ( C , O ) = I ′ f_{\mathrm{CU}}^{-1}(C, O)=\mathcal{I}^{\prime} fCU−1(C,O)=I′推导出能够产生输出 O O O的一组可能输入参数 I ′ ⊆ I \mathcal{I}^{\prime} \subseteq \mathcal{I} I′⊆I,当执行代码 C C C时。
正式地,对于给定的代码片段 C ∈ C C \in \mathcal{C} C∈C,输入 I ∈ I I \in \mathcal{I} I∈I,以及输出 O ∈ O , f C U ( C , I ) = O O \in \mathcal{O}, f_{\mathrm{CU}}(C, I)=O O∈O,fCU(C,I)=O当且仅当execute ( C , I ) = O (C, I)=O (C,I)=O,并且 f C U − 1 ( C , O ) = f_{\mathrm{CU}}^{-1}(C, O)= fCU−1(C,O)= { I ′ ∈ I ∣ execute ( C , I ′ ) = O } \left\{I^{\prime} \in \mathcal{I} \mid \operatorname{execute}\left(C, I^{\prime}\right)=O\right\} {I′∈I∣execute(C,I′)=O}。
CU强调模型对代码逻辑的深刻理解及其执行前向和后向推理的能力。为确保广泛适用性,收集的代码片段涵盖了多个技术领域,包括人工智能和机器学习、数据处理和分析、Web开发和数据库管理。例如,在Web开发和数据处理中,我们利用了关键工具如PyTorch(Paszke等人,2019)、TensorFlow(Abadi等人,2016)、Keras(Chollet,2015)、Scikit-learn(Pedregosa等人,2018)、NumPy(Harris等人,2020)、Pandas(McKinney,2010)和Matplotlib(Hunter,2007)。
具体来说,CU任务由两个子任务组成:预测代码输出 ( C U F ) \left(C U_{F}\right) (CUF)和推导代码输入 ( C U R ) \left(C U_{R}\right) (CUR)。例如,给定函数def add(a, b): return a + b和输入 ( 3 , 5 ) (3,5) (3,5),模型应准确预测结果8 。反之,基于输出8 ,模型应推导出潜在输入如 { ( 3 , 5 ) , ( 4 , 4 ) , ( 6 , 2 ) } \{(3,5),(4,4),(6,2)\} {(3,5),(4,4),(6,2)}。通过评估模型在 C U F C U_{F} CUF和 C U R C U_{R} CUR上的准确性,我们可以全面衡量其对代码逻辑的理解。
3.2 代码生成(CG)
CG定义为将自然语言描述转换为可执行代码的过程。设
D
\mathcal{D}
D表示所有可能的自然语言描述的集合,
C
\mathcal{C}
C表示所有可能代码片段的集合。CG任务由函数
f
C
G
:
D
→
C
f_{\mathrm{CG}}: \mathcal{D} \rightarrow \mathcal{C}
fCG:D→C表示,其中
f
C
G
(
D
)
=
C
f_{\mathrm{CG}}(D)=C
fCG(D)=C生成
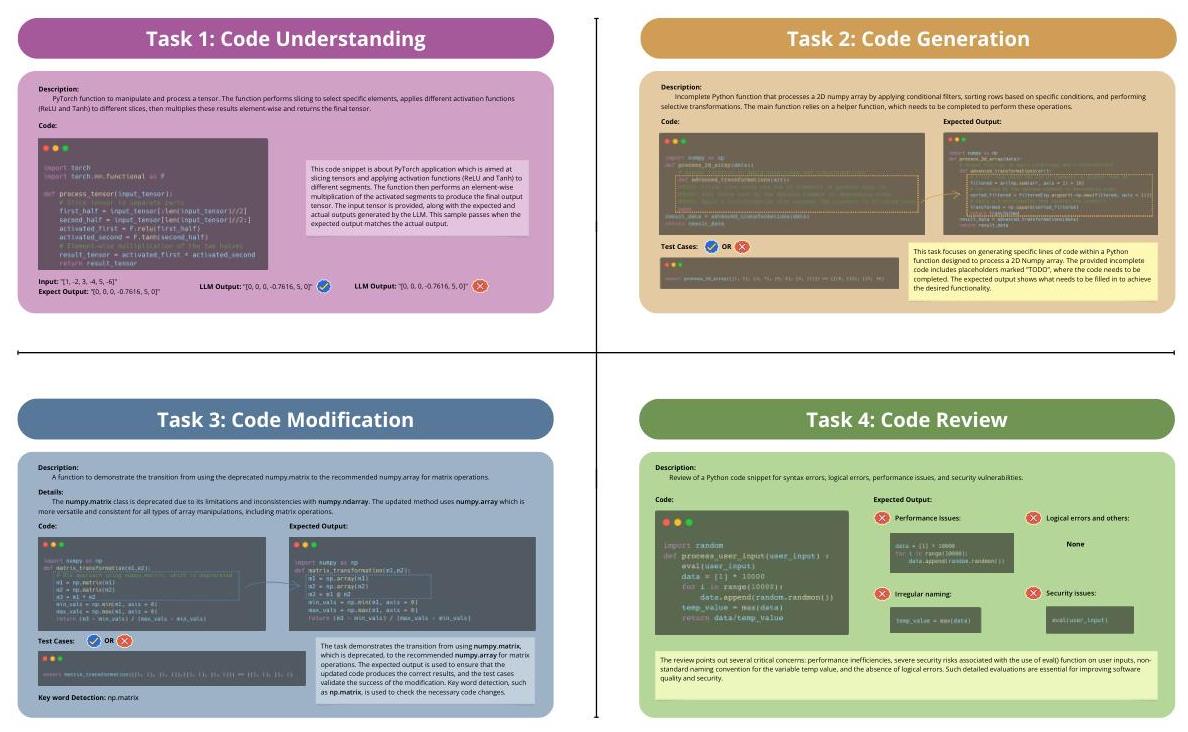
图2:CoCo-Bench中的四个主要任务说明——代码理解(CU)、代码生成(CG)、代码修改(CM)和代码审查(CR)——每个任务都定义为评估大型语言模型(LLMs)在软件工程中的能力。
代码片段
C
C
C对应于自然语言描述
D
D
D。正式地,对于给定的描述
D
∈
D
,
C
=
f
C
G
(
D
)
D \in \mathcal{D}, C=f_{\mathrm{CG}}(D)
D∈D,C=fCG(D)使得execute©执行由
D
D
D描述的任务。
此函数使程序员能够快速将想法转化为代码,并允许非技术人员参与软件开发。通过自动化常规编程任务,CG减少了人为错误,提高了代码质量和一致性,并加速了产品迭代周期。我们设计了函数级CG任务和句子级CG任务来测试模型的能力。
3.3 代码修改(CM)
CM涉及修改现有代码以满足特定要求或改进其功能。设 C old \mathcal{C}_{\text {old }} Cold 表示原始代码片段的集合, R \mathcal{R} R表示所有可能修改请求或要求的集合, C new \mathcal{C}_{\text {new }} Cnew 表示修改后的代码片段的集合。CM任务由函数 f C M : C old × R → C new f_{\mathrm{CM}}: \mathcal{C}_{\text {old }} \times \mathcal{R} \rightarrow \mathcal{C}_{\text {new }} fCM:Cold ×R→Cnew 定义,其中 f C M ( C old , R ) = C new f_{\mathrm{CM}}\left(C_{\text {old }}, R\right)=C_{\text {new }} fCM(Cold ,R)=Cnew 生成满足修改请求 R R R的修改后的代码片段 C new C_{\text {new }} Cnew 。正式地,对于给定的 C old ∈ C old C_{\text {old }} \in \mathcal{C}_{\text {old }} Cold ∈Cold 和 R ∈ R R \in \mathcal{R} R∈R, C new = f C M ( C old , R ) C_{\text {new }}=f_{\mathrm{CM}}\left(C_{\text {old }}, R\right) Cnew =fCM(Cold ,R)使得execute ( C new ) \left(C_{\text {new }}\right) (Cnew )满足要求 R R R。
此任务对于保持软件可靠性并适应不断变化的需求至关重要。我们的样本包括基于错误消息更新代码的代码修改,以及反映最新API更改的API更新。这些场景测试了代码LLMs是否可以提高软件可靠性和保持应用程序与最新技术进步同步的能力。
3.4 代码审查(CR)
CR被结构化为一个多标签分类问题,其中每个代码片段根据若干标准进行评估。设 C \mathcal{C} C表示所有可能代码片段的集合, E \mathcal{E} E表示评估标准的集合。CR任务由函数 f C R : C → P ( E ) f_{\mathrm{CR}}: \mathcal{C} \rightarrow \mathcal{P}(\mathcal{E}) fCR:C→P(E)定义,其中 f C R ( C ) = E ′ f_{\mathrm{CR}}(C)=\mathcal{E}^{\prime} fCR(C)=E′分配给代码片段 C C C满足或违反的一组子集评估标准 E ′ ⊆ E \mathcal{E}^{\prime} \subseteq \mathcal{E} E′⊆E。正式地,对于给定的代码片段 C ∈ C , E ′ = f C R ( C ) C \in \mathcal{C}, \mathcal{E}^{\prime}=f_{\mathrm{CR}}(C) C∈C,E′=fCR(C)其中 E ′ = { e ∈ E ∣ C \mathcal{E}^{\prime}=\{e \in \mathcal{E} \mid C E′={e∈E∣C 展现特征 e } e\} e}。
关键评估领域包括安全问题、性能问题、命名约定遵守情况和逻辑错误。具体而言,安全问题涉及漏洞,如SQL注入、缓冲区溢出和不安全的数据处理。性能问题涉及可能导致低效的代码段,包括不必要的计算、次优算法和资源密集型操作。遵守命名约定意味着符合既定的编码标准和命名惯例,从而增强代码的可读性和可维护性。逻辑错误涉及可能导致错误执行的缺陷,如无限循环、不正确的条件检查和错误的数据操作。
4 分析
在本节中,我们首先分析所有LLMs的整体得分。然后,在第4.2节中,我们检查不同子任务和数据集之间的相关性。在第4.3节中,我们分析上下文长度对模型推理的影响。在第4.4节中,我们关注解码策略对模型的影响,主要包括top-k、top-p和最大新标记数。
4.1 综合性能评估
我们在表2中展示了排行榜结果,其中实证结果表明DeepSeek-Coder-V2-Instruct和ChatGPT-4.0在各种与代码相关的任务中优于其他领先的LLMs。这种卓越的表现主要源于预训练过程中模型参数规模的扩大和数据量的增加。
模型扩展在提升性能方面起着关键作用。较大的模型,如DeepSeek-Coder-V2-Instruct,始终优于较小的模型,如DeepSeek-Coder-1.3b和DeepSeek-Coder-6.7b。这种扩展趋势并非在所有模型家族中均匀观察到,表明训练数据多样性和微调策略在最大化较大模型架构的好处方面起着关键作用。例如,虽然DeepSeek-Coder-33b-instruct实现了显著的性能提升,但在CodeLlama系列中类似的扩展并未带来相当的改进,这指向了各自训练范式中可能存在的效率低下或瓶颈。
指令微调模型在CoCo-Bench和HumanEval基准测试中一直优于其基础模型。这一趋势突显了指令微调在增强模型遵循复杂指令和执行专业任务能力方面的关键重要性。更大指令微调模型的增强性能进一步表明,将规模与有针对性的微调相结合会产生协同效益,使模型能够在复杂的代码相关任务中达到更高的熟练水平。
4.2 相关性分析
任务之间的相关性:我们在图3中可视化了任务间的Spearman相关热图,这为进一步洞察不同代码相关任务之间的相互依赖性提供了依据。值得注意的是,观察到
C
U
F
\mathrm{CU}_{F}
CUF和CG(0.94)之间以及
C
U
R
\mathrm{CU}_{R}
CUR和CG(0.84)之间存在强相关性。这些高相关值表明,代码理解(CU)的熟练程度显著增强了模型有效生成(CG)代码的能力。这种相互关联性表明,改进一个任务——如CU——可以导致相关任务如CG的更好表现。它突显了这些任务在实际应用中的集成性质,其中某一领域的进步可能会催化另一领域的进步,最终促进更通用和更有能力的代码模型的发展。
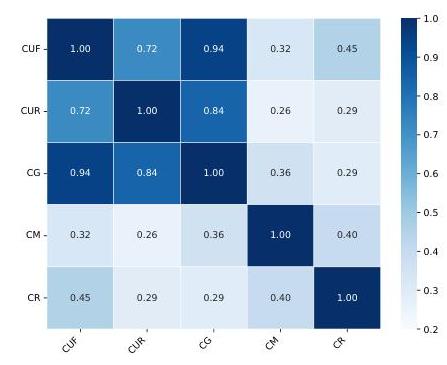
图3:CoCo-Bench中五个任务( C U F , C U R , C G , C M , C R \mathrm{CU}_{\mathrm{F}}, \mathrm{CU}_{\mathrm{R}}, \mathrm{CG}, \mathrm{CM}, \mathrm{CR} CUF,CUR,CG,CM,CR)两两之间的相关性。
然而,CU和CR之间的相对较低的相关性表明,CR涉及超出单纯代码理解之外的额外能力,如评估代码质量、效率和遵循最佳实践的能力。我们还观察到CG和CM之间的相对较低的相关性(0.36),表明CG中的表现不一定有助于CM。这一区别突显了模型不仅需要对代码有深刻的理解,还需要具备评估和改进它的关键能力,反映了软件工程的多面性。
| 模型 | CU | CG | CM | CR | CoCo-Score | |
|---|---|---|---|---|---|---|
| C U F \mathrm{CU}_{\mathrm{F}} CUF | C U R \mathrm{CU}_{\mathrm{R}} CUR | |||||
| CodeLlama-7b-base | 12.93 | 3.33 | 11.45 | 30.00 | 39.39 | 16.87 |
| CodeLlama-7b-instruct | 9.92 | 5.17 | 16.41 | 15.00 | 25.71 | 12.94 |
| CodeLlama-13b-base | 19.01 | 4.17 | 19.23 | 20.00 | 32.26 | 16.67 |
| CodeLlama-13b-instruct | 13.45 | 6.78 | 18.60 | 25.00 | 31.43 | 17.14 |
| CodeLlama-34b-base | 15.83 | 6.67 | 21.71 | 15.00 | 20.00 | 14.50 |
| CodeLlama-34b-instruct | 14.88 | 4.24 | 19.08 | 20.00 | 29.41 | 15.48 |
| DeepSeek-Coder-1.3b-base | 14.88 | 3.31 | 15.27 | 20.00 | 31.43 | 14.84 |
| Deepseek-Coder-1.3b-instruct | 15.13 | 5.98 | 19.85 | 20.00 | 25.71 | 15.62 |
| DeepSeek-Coder-6.7b-base | 26.05 | 5.08 | 25.78 | 25.00 | 28.57 | 19.68 |
| Deepseek-Coder-6.7b-instruct | 35.65 | 11.93 \mathbf{1 1 . 9 3} 11.93 | 46.92 \mathbf{4 6 . 9 2} 46.92 | 44.44 ‾ \underline{44.44} 44.44 | 28.12 | 30.62 |
| DeepSeek-Coder-33b-base | 21.37 | 8.40 | 23.81 | 35.00 | 32.35 | 21.91 |
| Deepseek-Coder-33b-instruct | 33.88 | 10.74 ‾ \underline{10.74} 10.74 | 39.53 | 50.00 ‾ \underline{50.00} 50.00 | 37.14 ‾ \underline{37.14} 37.14 | 31.05 ‾ \underline{31.05} 31.05 |
| ChatGPT4 | 53.72 ‾ \underline{53.72} 53.72 | 15.70 \mathbf{1 5 . 7 0} 15.70 | 44.27 ‾ \underline{44.27} 44.27 | 15.00 | 45.71 \mathbf{4 5 . 7 1} 45.71 | 32.06 \mathbf{3 2 . 0 6} 32.06 |
| DeepSeek-R1-Distill-Qwen-7B | 57.02 \mathbf{5 7 . 0 2} 57.02 | 9.09 | 35.88 | 20.00 | 34.29 | 28.26 |
| o1-mini | 66.12 ‾ \underline{66.12} 66.12 | 9.09 | 55.73 ‾ \underline{55.73} 55.73 | 45.00 \mathbf{4 5 . 0 0} 45.00 | 45.71 \mathbf{4 5 . 7 1} 45.71 | 39.60 \mathbf{3 9 . 6 0} 39.60 |
表2:模型在CoCo-Bench上的性能比较排行榜,第一名模型用阴影突出,第二名模型加粗,第三名模型下划线。表格比较了不同任务上的性能:
C
U
,
C
G
,
C
M
\mathbf{C U}, \mathbf{C G}, \mathbf{C M}
CU,CG,CM和
C
R
\mathbf{C R}
CR,涵盖五个主要模型系列:DeepSeek-Coder、CodeLlama、R1、GPT和o1。
C
U
F
\mathbf{C U}_{\mathbf{F}}
CUF和
C
U
R
\mathbf{C U}_{\mathbf{R}}
CUR是
C
U
\mathbf{C U}
CU的两种子任务。指标CoCo-Score(见C)提供了模型能力的综合评估。
能评估和改进它的关键能力,反映了软件工程的多面性。
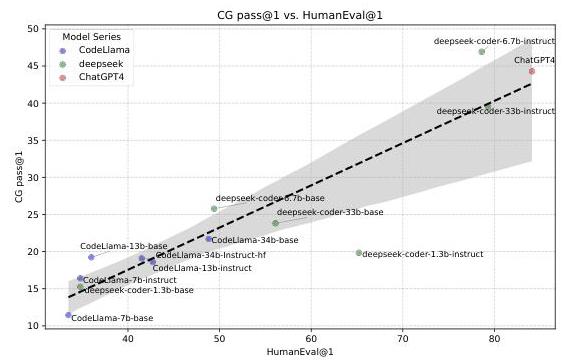
图4:模型在CoCo-Bench和HumanEval基准上的性能比较分析:该图说明了模型在CoCo-Bench(CG pass@1)和HumanEval(HumanEval@1)基准上的表现关系。虚线趋势线和阴影区域表示两个基准间性能的一般相关性。
数据集之间的相关性:图3和图4共同表明,与HumanEval相比,CoCo-Bench提供了更为严格和区分性的评估。CoCoBench和HumanEval分数之间的正相关性表明,基础能力在不同基准间是一致的。此外,分析还表明,增加模型大小通常与性能增强相关,特别是在DeepSeekCoder系列中。
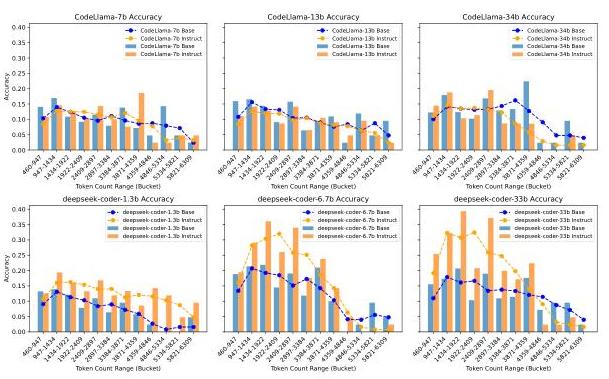
图5:相同模型的不同版本在CoCo-Bench上的性能差异
4.3 上下文长度与模型性能
图5和图8说明了模型在不同输入令牌数量范围内的准确性变化。无论模型大小和类型如何,所有模型都面临
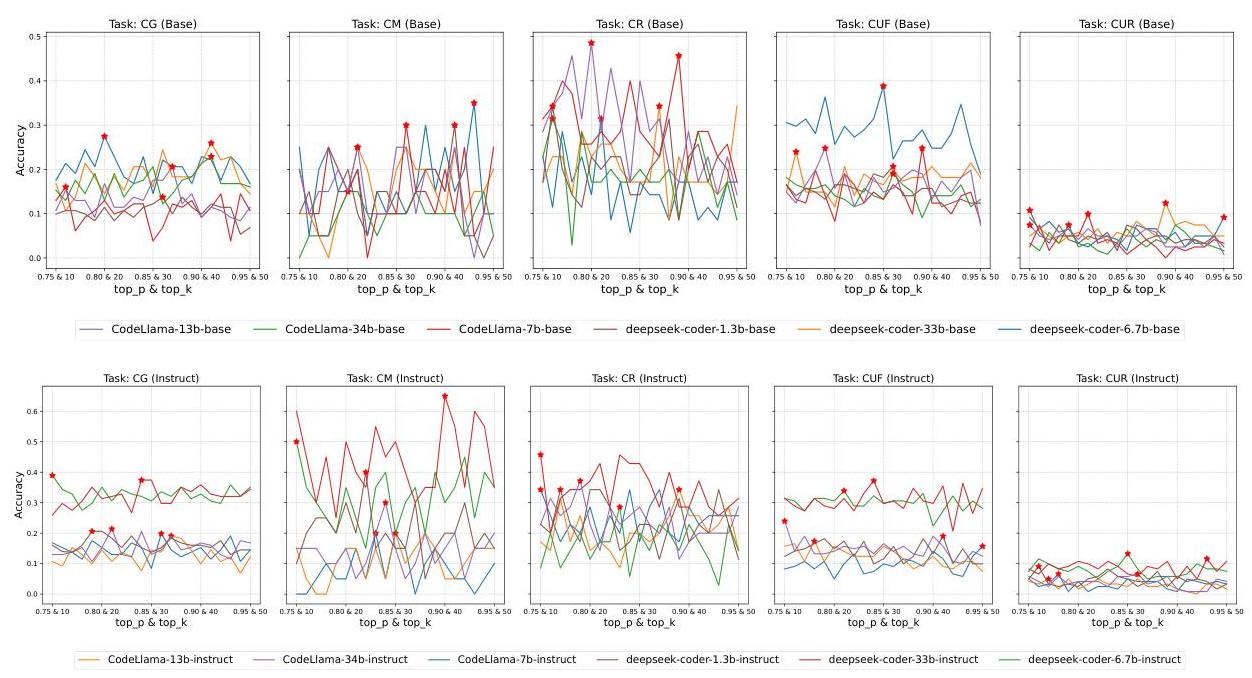
图6:在不同top_p和top_k配置下的性能差异
由于变压器中自注意力的二次成本,难以在较长上下文中保持注意力。指令微调可能有助于聚焦输入的相关部分,减轻指令模型的一些性能下降。
4.4 解码策略
Top-p 和 Top-k:如图6所示,不同任务对top-p和top-k的敏感度不同。结构化任务如CU任务受益于确定性输出,因为代码有更严格的正确性要求。较窄的令牌分布(较低的top-p和top-k)通常足以获得准确的结果。相比之下,开放性任务如CM和CG需要LLMs的创造力和多样性,因为有多种合理的方法来修改或改进代码。值得一提的是,由于LLMs具有更丰富的令牌分布和更大的表达能力,它们在生成更广泛的可能性预测时对top-p和top-k的变化更加敏感。当使用高top-p和topk进行推理时,LLMs的输出可能变得过于多样化或连贯性较差,可能会引入语法错误或无关的代码片段。相反,小型模型具有较少的表达性令牌分布,因此本质上更具确定性且受高top-p和top-k设置影响较小,从而更有效地保持代码的正确性。因此,我们可以得出以下经验结论:
结论1. 不同任务对top-p和top-k参数的敏感度不同。结构化任务如CU倾向于从更确定的输出中受益,而开放性任务如
C
M
C M
CM和
C
G
C G
CG则需要更多的创造力和多样性。
指令模型在代码相关任务中始终优于基础模型。我们认为这是由于指令模型在训练期间接触到了带有任务特定指令的例子,使它们能够更好地理解和遵循编码指南和要求。因此,我们可以得出以下经验结论:
结论2. 指令微调模型在代码相关任务中表现出色,因其与任务特定的编码目标紧密对齐,显著增强了在各种解码配置下的性能和鲁棒性。
中等令牌范围与大多数模型的预训练数据集和分词方案相符。较短的令牌(例如460-1191)可能导致稀疏表示,而较长的令牌可能会超载模型的容量。还注意到缩放定律如何与结果协调一致。较大的模型由于其更大的参数空间和更丰富的潜在表示,天生更能捕捉长距离依赖关系。较小的模型缺乏编码这种复杂性的能力
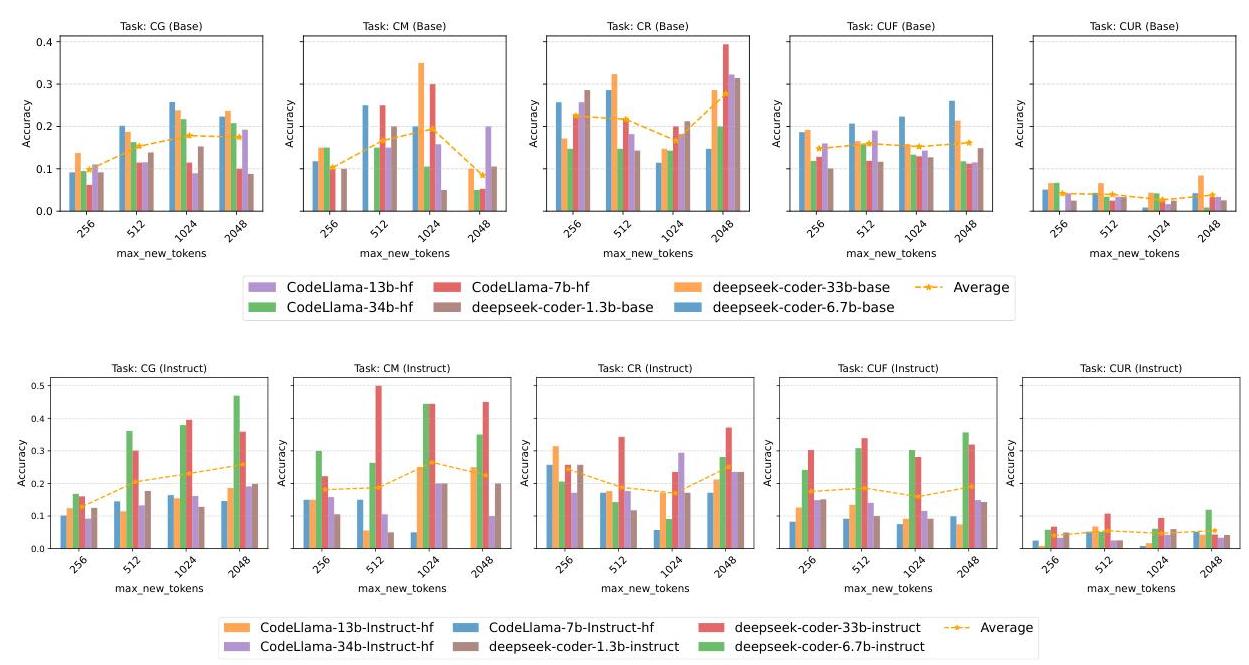
图7:在不同max_new_tokens配置下的性能差异
有效地。这使我们得出了以下经验结论:
结论3. LLMs在较长代码上下文中遇到挑战,但指令微调通过聚焦相关代码段帮助维持性能。大模型比小模型更有效地处理代码中的长距离依赖关系。
图8:相同类型的不同模型在CoCo-Bench上的性能差异
最大新令牌:图7显示,较高的最大新令牌直接与需要连贯和扩展输出的任务(如CG和CU)的更高准确性相关。它允许模型生成更长的序列,可能捕获更多上下文并完成更复杂的输出。一些任务如CM由于其固有的要求,收益较少,因为更长的序列增加了最小价值。相比之下,更大和指令微调的模型由于能够管理更广泛的上下文和依赖关系,因此更适合利用扩展的令牌生成。
基于此,可以得出以下经验结论:
结论4. 增加最大新令牌提高了需要扩展和连贯输出的代码任务的性能,特别是对更大和指令微调的模型有益,使它们能够管理更复杂的代码结构和依赖关系。
5 限制与未来工作
尽管CoCo-Bench为代码相关任务中的LLMs提供了一个有效和全面的评估框架,但仍有一些扩展领域。目前,基准缺乏多模态任务,这些任务需要模型将代码与其他数据类型(如图像或自然语言)结合起来,这在现代开发环境中变得越来越相关。认识到这一差距,我们计划在未来引入多模态任务,使我们能够评估模型在更复杂的项目中的表现,并提供对LLMs能力的更全面评估。为确保CoCoBench始终保持在LLM评估的前沿,我们将通过纳入新的编程语言和适应不断发展的开发实践来定期更新基准。
参考文献
Martín Abadi, Ashish Agarwal, Paul Barham, Eugene Brevdo, Zhifeng Chen, Craig Citro, Greg S. Corrado, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Ian Goodfellow, Andrew Harp, Geoffrey Irving, Michael Isard, Yangqing Jia, Rafal Jozefowicz, Lukasz Kaiser, Manjunath Kudlur, Josh Levenberg, Dan Mane, Rajat Monga, Sherry Moore, Derek Murray, Chris Olah, Mike Schuster, Jonathon Shlens, Benoit Steiner, Ilya Sutskever, Kunal Talwar, Paul Tucker, Vincent Vanhoucke, Vijay Vasudevan, Fernanda Viegas, Oriol Vinyals, Pete Warden, Martin Wattenberg, Martin Wicke, Yuan Yu, and Xiaoqiang Zheng. 2016. Tensorflow: 在异构分布式系统上的大规模机器学习。预印本,arXiv:1603.04467。
Open AI. 2024. 学习用LLMs推理。
Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and Charles Sutton. 2021. 使用大型语言模型进行程序合成。预印本,arXiv:2108.07732。
Islem Bouzenia, Piyush Krishan Bajaj, 和 Michael Pradel. 2024. DyPyBench:可执行Python软件的基准测试。ACM软件工程学报,1(FSE):338-358。
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian, Clemens Winter, Philippe Tillet, Felipe Petroski Such, Dave Cummings, Matthias Plappert, Fotios Chantzis, Elizabeth Barnes, Ariel Herbert-Voss, William Hebgen Guss, Alex Nichol, Alex Paino, Nikolas Tezak, Jie Tang, Igor Babuschkin, Suchir Balaji, Shantanu Jain, William Saunders, Christopher Hesse, Andrew N. Carr, Jan Leike, Josh Achiam, Vedant Misra, Evan Morikawa, Alec Radford, Matthew Knight, Miles Brundage, Mira Murati, Katie Mayer, Peter Welinder, Bob McGrew, Dario Amodei, Sam McCandlish, Ilya Sutskever, 和 Wojciech Zaremba. 2021. 评估经过代码训练的大型语言模型。预印本,arXiv:2107.03374。
François Chollet. 2015. keras. https://github.com/fchollet/keras.
Peng Di, Jianguo Li, Hang Yu, Wei Jiang, Wenting Cai, Yang Cao, Chaoyu Chen, Dajun Chen, Hongwei Chen, Liang Chen, Gang Fan, Jie Gong, Zi Gong, Wen Hu, Tingting Guo, Zhichao Lei, Ting Li, Zheng Li, Ming Liang, Cong Liao, Bingchang Liu, Jiachen Liu, Zhiwei Liu, Shaojun Lu, Min Shen, Guangpei Wang, Huan Wang, Zhi Wang, Zhaogui Xu, Jiawei Yang, Qing Ye, Gehao Zhang, Yu Zhang, Zelin Zhao,
Xunjin Zheng, Hailian Zhou, Lifu Zhu, 和 Xianying Zhu. 2024. CodeFuse-13b:一种预训练的多语言代码大型语言模型。在第46届国际软件工程会议:软件工程实践分会,ICSESEIP '24。ACM。
Mingzhe Du, Anh Tuan Luu, Bin Ji, Qian Liu, 和 See-Kiong Ng. 2024. Mercury:一种代码大型语言模型的代码效率基准。预印本,arXiv:2402.07844。
Xueying Du, Mingwei Liu, Kaixin Wang, Hanlin Wang, Junwei Liu, Yixuan Chen, Jiayi Feng, Chaofeng Sha, Xin Peng, 和 Yiling Lou. 2023. ClassEval:一种手工制作的基准,用于评估LLMs在类级别代码生成上的表现。预印本,arXiv:2308.01861。
Alex Gu, Baptiste Rozière, Hugh Leather, Armando Solar-Lezama, Gabriel Synnaeve, 和 Sida I. Wang. 2024. CruxEval:一种用于代码推理、理解和执行的基准。预印本,arXiv:2401.03065。
Jiawei Guo, Ziming Li, Xueling Liu, Kaijing Ma, Tianyu Zheng, Zhouliang Yu, Ding Pan, Yizhi LI, Ruibo Liu, Yue Wang, Shuyue Guo, Xingwei Qu, Xiang Yue, Ge Zhang, Wenhu Chen, 和 Jie Fu. 2024. CodeEditorBench:评估大型语言模型代码编辑能力的基准。预印本,arXiv:2404.03543。
Yiyang Hao, Ge Li, Yongqiang Liu, Xiaowei Miao, He Zong, Siyuan Jiang, Yang Liu, 和 He Wei. 2022. AixBench:一种代码生成基准数据集。预印本,arXiv:2206.13179。
Charles R Harris, K Jarrod Millman, Stéfan J Van Der Walt, Ralf Gommers, Pauli Virtanen, David Cournapeau, Eric Wieser, Julian Taylor, Sebastian Berg, Nathaniel J Smith, et al. 2020. 使用NumPy进行数组编程。Nature, 585(7825):357-362。
Chaoqun He, Renjie Luo, Shengding Hu, Yuanqian Zhao, Jie Zhou, Hanghao Wu, Jiajie Zhang, Xu Han, Zhiyuan Liu, 和 Maosong Sun. 2024. UltraEval:一种用于灵活和全面评估LLMs的轻量级平台。预印本,arXiv:2404.07584。
Dan Hendrycks, Steven Basart, Saurav Kadavath, Mantas Mazeika, Akul Arora, Ethan Guo, Collin Burns, Samir Puranik, Horace He, Dawn Song, 和 Jacob Steinhardt. 2021. 使用Apps测量编码挑战能力。预印本,arXiv:2105.09938.
J. D. Hunter. 2007. Matplotlib:一个二维图形环境。《计算科学与工程》杂志,9(3):9095。
Srinivasan Iyer, Ioannis Konstas, Alvin Cheung, 和 Luke Zettlemoyer. 2018. 在程序上下文中映射语言到代码。预印本,arXiv:1808.09588。
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando SolarLezama, Koushik Sen, 和 Ion Stoica. 2024. LiveCodeBench:对大型语言模型进行完整且无污染的评估。预印本,arXiv:2403.07974。
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, 和 Karthik Narasimhan. 2024. Swe-bench:语言模型能否解决现实世界的GitHub问题?预印本,arXiv:2310.06770。
刘闯舒,张世卓·迪伦。2024. CodeMind:一个挑战大型语言模型进行代码推理的框架。预印本,arXiv:2402.09664。
卢帅,郭大君,任硕,黄俊杰,Alexey Svyatkovskiy,安布罗西奥·布兰科,Colin Clement,Dawn Drain,江大鑫,唐杜宇,李戈,周立东,寿林军,周龙,米歇尔·图法诺,龚明,周明,段南,尼尔·桑达雷斯,邓少昆,付盛宇 和 刘淑杰。2021. CodeXGLUE:一个用于代码理解和生成的机器学习基准数据集。预印本,arXiv:2102.04664。
汤姆·麦克德莫特,丹·德拉伦蒂斯,彼得·贝林,马克·布莱克本 和 玛丽·博恩。2020. AI4SE 和 SE4AI:研究路线图。洞察力,23(1):8-14。
韦斯·麦金尼。2010. 用于统计计算的Python数据结构。第9届Python in Science Conference会议录,第51 - 56页。
汤姆·明卡,瑞安·克利文 和 尤尔丹·扎伊科夫。2018. TrueSkill 2:改进的贝叶斯技能评分系统。技术报告。
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, Alban Desmaison, Andreas Köpf, Edward Yang, Zach DeVito, Martin Raison, Alykhan Tejani, Sasank Chilamkurthy, Benoit Steiner, Lu Fang, Junjie Bai 和 Soumith Chintala。2019. PyTorch:一种命令式风格、高性能的深度学习库。预印本,arXiv:1912.01703。
Fabian Pedregosa, Gaël Varoquaux, Alexandre Gramfort, Vincent Michel, Bertrand Thirion, Olivier Grisel, Mathieu Blondel, Andreas Müller, Joel Nothman, Gilles Louppe, Peter Prettenhofer, Ron Weiss, Vincent Dubourg, Jake Vanderplas, Alexandre Passos, David Cournapeau, Matthieu Brucher, Matthieu Perrot 和 Édouard Duchesnay。2018. Scikit-learn:Python中的机器学习。预印本,arXiv:1201.0490。
邱瑞忠, 曾伟良 Will, 董航航, 易兹 Ezick James, 和 Christopher Lott。2024. LLM生成的代码有多高效?一个严格且高标准的基准测试。预印本,arXiv:2406.06647。
查尔斯·斯皮尔曼。1961. 两事物之间关联性的证明与测量。
天如楚, 叶伊宁, 秦雨佳, 聂新聪, 林彦凯, 潘银旭, 武野赛, 惠浩田, 刘卫川, 刘志远, 和 孙茂松。2024. DebugBench:评估大型语言模型调试能力的基准。预印本,arXiv:2401.04621。
颜维祥, 刘海天, 王云坤, 李云泽, 陈倩, 王文, 林廷宇, 赵玮山, 朱莉, 哈里·桑德朗, 和 邓树光。2024. CodeScope:一个多语言多任务多维度基准,基于执行评估LLMs在代码理解和生成方面的能力。预印本,arXiv:2311.08588。
尹鹏程, 邓博文, 陈 Edgar, Bogdan Vasilescu, 和 Graham Neubig。2018. 从Stack Overflow中挖掘对齐的代码和自然语言对。预印本,arXiv:1805.08949。
曾道光, 陈贝, 杨德建, 林泽楷, 金敏洙, 关北, 王永基, 陈卫珠, 和 楼健光。2022. CERT:面向库导向代码生成的草图连续预训练。预印本,arXiv:2206.06888。
张淑丹, 赵汉霖, 刘晓, 郑勤凯, 戚泽潮, 顾小涛, 张晓涵, 董昱轩, 和 唐杰。2024a. NaturalCodeBench:在Humaneval和自然用户提示下检查编码性能不匹配。预印本,arXiv:2405.04520。
张亚坤, 张文杰, 冉德志, 祝其昊, 杜成峰, 郝丹, 谢涛, 和 张路。2024b. 基于学习的GUI测试用例迁移的小部件匹配方法。第46届IEEE/ACM国际软件工程会议论文集,ICSE '24。ACM。
A 数据统计详情
A. 1 数据统计
CoCo-Bench通过细致的手动审核精心策划而成,包含705个高质量样本,这些样本是在几位经验丰富的开发人员(每位都有超过10年的SE经验)协助下开发的。一半的CoCo-Bench样本颇具挑战性。如图9所示,任务多样化,其中 56.7 % 56.7\% 56.7%的样本专注于CU, 21.3 % 21.3\% 21.3%专注于CG, 17.0 % 17.0\% 17.0%专注于CM, 5.0 % 5.0\% 5.0%专注于CR。这种分布强调了全面测试代码理解与生成各方面的方法。
除了任务的挑战性外,CoCo-Bench还支持广泛的编程语言。Python处于领先地位,占样本的
54.6
%
54.6\%
54.6%,其次是Java占
20.4
%
20.4\%
20.4%,C++占
19.0
%
19.0\%
19.0%,SQL占
6.0
%
6.0\%
6.0%。这种多样性确保模型在广泛的现实世界编码场景中得到评估。
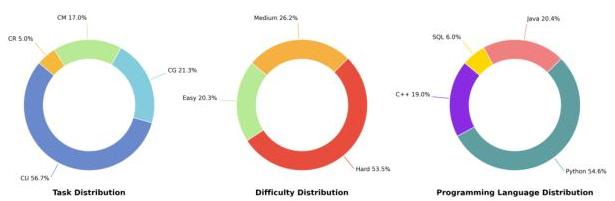
图9:CoCo-Bench中的任务、难度级别和编程语言分布。
| 任务类型 | |||||
|---|---|---|---|---|---|
| 难度 | CU | CG | CM | CR | 总计 |
| 简单 | 74 | 41 | 17 | 11 | 143 |
| 中等 | 94 | 54 | 22 | 15 | 185 |
| 困难 | 232 | 55 | 81 | 9 | 377 |
| 总计 | 400 | 150 | 120 | 35 | 705 |
表3:按难度级别的样本分布。该表格展示了数据集中不同难度级别的样本分布情况。任务分为四类:CU、CG、CU和CR。每个样本进一步划分为简单、中等和困难难度级别。
如表3所示的数据集清晰地突出了困难示例,这构成了数据集的主要部分,共377项任务。此外,如表4所示,每种任务类型在不同语言中均有良好代表,Python是最常使用的语言
| 任务类型 | |||||
|---|---|---|---|---|---|
| 编码语言 | CU | CG | CM | CR | 总计 |
| python | 208 | 87 | 55 | 35 | 385 |
| java | 80 | 29 | 35 | ∼ \sim ∼ | 144 |
| C++ | 70 | 34 | 30 | ∼ \sim ∼ | 134 |
| SQL | 42 | ∼ \sim ∼ | ∼ \sim ∼ | ∼ \sim ∼ | 42 |
| 总计 | 400 | 150 | 120 | 35 | 705 |
表4:按编程语言的任务类型分布。每一行代表一种编程语言,例如Python、Java、C++和SQL,并列出该语言在各类别中的任务数量。还提供了每种语言的总任务数以及所有语言的总任务数。
涵盖所有类别。
B 基准构建
CoCo-Bench的样本生成过程战略性地分为三个主要阶段,如图10所示:原始数据收集、特定任务数据转换和样本审查。每个部分都为数据集的整体有效性和质量做出了贡献。
原始数据收集:我们数据集构建管道的代码收集阶段旨在收集符合严格及时性标准的多样化编程样本,防止数据污染并确保数据用于训练和验证机器学习模型的质量和相关性。我们从Leetcode和各种项目存储库中获取代码,这些存储库在严格的条件下选择以确保数据的新鲜度。Leetcode提供了一个受控环境,其中经常审查和更新的代码包含了当前的编码实践和算法。这对于必须跟上最新编程趋势的模型训练至关重要。项目代码,特别是来自较少经验开发者贡献的存储库,具有双重目的。它捕获常见的编码错误和次优实践,这对针对CR和CM任务的模型训练非常有价值。此外,它使数据集与真实的编程任务对齐,因为项目代码通常涉及复杂的、操作驱动的设计。通过仔细选择像Leetcode和项目存储库这样的来源,我们确保我们的数据集避免过时或无关的数据,同时涵盖了广泛的现实世界编码场景。
特定任务数据转换:第二步
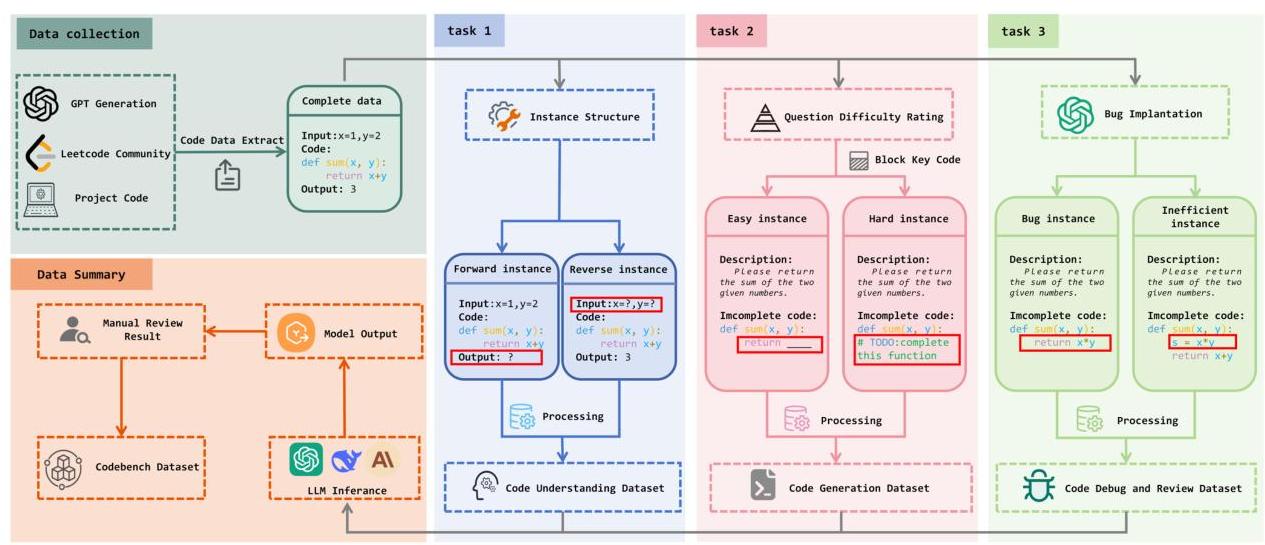
图10:CoCo-Bench的构建流程。流程从三个主要来源的数据收集开始:GPT生成、Leetcode社区解决方案和各种项目。收集的数据被结构化为样本,根据其特性适应不同的任务。CU:此数据集的构建涉及将收集的数据结构化为前向和反向实例。CG:此数据集涉及问题难度评级任务,其中收集的代码被分类为简单和困难实例。简单实例的特点是简单的、直接的任务,代码量最少,而困难实例涉及更复杂的任务,带有额外的注释或需要完成的不完整部分。CM和CR数据集从一个错误植入过程开始,其中代码片段被故意修改以引入错误和低效。管道的最后一步包括推理和人工检查,以确保CoCo-Bench的正确性和相关性。
我们在数据集构建管道中的第二步涉及特定任务的数据转换,定制代码样本来优化不同计算任务的模型训练和评估。对于CU,该过程创建前向实例(输入-输出对)和反向实例(输出-推理挑战)。在CG任务中,实例按难度分类,从简单的补全到复杂的修正。对于CM和CR任务,策略性地在代码样例中插入错误和低效,使用像GPT这样的模型生成现实场景,增强数据集在调试和优化任务中的稳健性。最后一步包括彻底的CR,首先使用高性能开源模型如GPT进行初步评估,然后进行人工审查,最后纳入基准库。在自动推理之后,样本由经验丰富的开发人员进行详细的人工审查。人工审查关注以下几个关键方面:
- 样本正确性:验证样本代码是否能无误地执行预期功能。这涉及到运行一组
- 测试用例以确保准确的输出。
-
- 合理的难度:评估样本的难度水平是否适当。确保样本既不太容易也不过分困难,从而在整个数据集中保持平衡的难度水平。
-
- 实际适用性:评估样本的实际相关性和实用性。确保代码样本反映开发人员可能遇到的实际场景和挑战。
-
- 易读性:检查样本代码是否易于理解和维护。这包括验证清晰简洁的变量名、适当的注释使用以及遵循编码标准。
在人工审查期间,每个方面都被仔细检查,以确保基准样本达到高质量和稳健性的标准。
- 易读性:检查样本代码是否易于理解和维护。这包括验证清晰简洁的变量名、适当的注释使用以及遵循编码标准。
C 基准指标
为了评估Code LLMs在CoCo-Bench上的表现,我们采用了一种基于每个样本难度的加权方案,确保对模型能力进行更准确的评估。
我们首先应用TrueSkill2(Minka等人,2018年)方法来评估每个任务的难度系数,标记为 μ i \mu_{i} μi。然后我们使用逆归一化计算 w i w_{i} wi:
w i = 1 / μ i ∑ j = 1 n 1 / μ j w_{i}=\frac{1 / \mu_{i}}{\sum_{j=1}^{n} 1 / \mu_{j}} wi=∑j=1n1/μj1/μi
确保 ∑ i = 1 5 w i = 1 \sum_{i=1}^{5} w_{i}=1 ∑i=15wi=1。令 w i w_{i} wi表示分配给第 i i i个样本的权重,反映每个任务对总体得分的贡献。较高的权重对应更复杂的样本。对于所有任务,我们定义考虑难度的通过率(DAPR)如下:
DAPR = ∑ i = 1 n ( Pass Rate i × w i ) ∑ i = 1 n w i \text { DAPR }=\frac{\sum_{i=1}^{n}\left(\text { Pass Rate }_{i} \times w_{i}\right)}{\sum_{i=1}^{n} w_{i}} DAPR =∑i=1nwi∑i=1n( Pass Rate i×wi)
其中Pass Rate i _{i} i表示第 i i i个样本的通过率——表明模型成功通过该特定测试用例的频率—— w i w_{i} wi是第 i i i个样本的难度权重, n n n是任务中的样本总数。
为了计算整体CoCo-Score,我们将每个任务的DAPR结合起来:
CoCo-Score = ∑ j = 1 4 ( n j N × DAPR j ) \text { CoCo-Score }=\sum_{j=1}^{4}\left(\frac{n_{j}}{N} \times \text { DAPR }_{j}\right) CoCo-Score =j=1∑4(Nnj× DAPR j)
其中 n j n_{j} nj是第 j j j个任务中的样本数, N N N是所有任务中的总样本数, D A P R j \mathrm{DAPR}_{j} DAPRj是每个相应任务的考虑难度的通过率。
我们的方法确保CoCo-Score不仅衡量模型的平均表现,还通过使用考虑难度的分数强调它们处理更复杂编码挑战的能力,提供对模型在各种编码任务中的实际效果和鲁棒性的全面评估。
D 推理提示
在CoCo-Bench的具体任务中,输入通常由前缀提示和后缀提示组成。前缀提示包含几个例子,以帮助大型模型理解特定任务要求和预期输出格式。这些例子有效地引导模型,确保其正确执行任务。后缀提示出现在输入的末尾,
用于强化所需的输出结构,确保模型的输出与提供的例子一致,从而便于后续自动化处理。
D. 1 CU推理提示
CU_F的前缀提示:
请根据以下代码片段和输入推导出输出。
CU_F的中缀提示:
代码片段如下:
import numpy as np
def power_sum(arr1,arr2):
powered_arr = np.power(arr1,
arr2)
result_sum = np.sum(powered_arr
1
return result_sum
CU_F的中缀提示:
输入如下:
[ [ 2 , 3 , 4 ] , [ 1 , 2 , 3 ] ] [[2,3,4],[1,2,3]] [[2,3,4],[1,2,3]]
CU_F的后缀提示:
仅给出推导出的代码片段输出。不要输出任何其他信息。
CU_R的前缀提示:
请根据以下代码片段和输出推导出输入。
CU_R的中缀提示:
代码片段如下:
import numpy as np
def power_sum(arr1,arr2):
powered_arr = np.power(arr1,
arr2)
result_sum = np.sum(powered_arr
)
return result_sum
CU_R的中缀提示:
输出如下:
102
CU_R的后缀提示:
仅给出推导出的代码片段输入。不要输出任何其他信息。
D. 2 CG推理提示
CG的前缀提示:
请根据描述填写以下不完整的代码。描述如下:
您获得一个正整数数组nums。Alice和Bob正在玩游戏。在游戏中,Alice可以从nums中选择所有一位数或所有两位数,剩下的数字给Bob。如果Alice的数字之和严格大于Bob的数字之和,则Alice获胜。如果Alice可以赢得这场比赛,请返回true;否则,请返回false。
CG的中缀提示:
不完整的代码如下:
def canAliceWin(self, nums: List[
int]) -> bool:
single=0
double=0
for it in nums:
if it>=10:
double=___
else:
single=___
return single !=double
CG的后缀提示:
仅给出完整的代码。不要输出任何其他信息。
D. 3 CM推理提示
CM的前缀提示:
请根据描述纠正以下代码。描述如下:
您获得一个由用户键入的0索引字符串 s s s。更改键定义为使用不同于上次使用的键。例如, s = s= s= "ab"有一个键的更改,而 s = s= s= "bBBb"则没有。返回用户必须更改键的次数。注意:修饰符如shift或caps lock不会计入更改键,也就是说,如果用户键入字母’a’然后键入字母’A’,这不会被视为键的更改。
CM的中缀提示:
要纠正的代码如下:
def countKeyChanges(self, s: str)
-> int:
if len(s) == 1:
return 0
s = s.upper()
count = 0
for i in range(len(s)-1):
if s[i] == s[i + 1]:
count += 1
return count
CM的后缀提示:
仅给出纠正后的代码。不要输出任何其他信息。
D. 4 CR推理提示
CR的前缀提示:
请根据描述查找以下代码中的错误。描述如下:
函数使用’eval’函数执行来自用户输入的动态表达式,造成严重的安全风险。
CR的中缀提示:
带有错误的代码如下:
def execute_expression(user_input):
result = eval(user_input) #
危险的eval使用
return result
CR的后缀提示:
有四种类型的错误:性能问题、安全问题、语法错误和逻辑错误。请给出准确的错误类型并纠正代码,形式如下
{
“performance_issues”:
“data = request.get(user_url)”, “security_issues”:
“password = getpass.getpass()”,
“syntax_errors”:
“print(a + b)”, “logical_errors”:
“continue if a > b else break” }
E 更多超参数分析
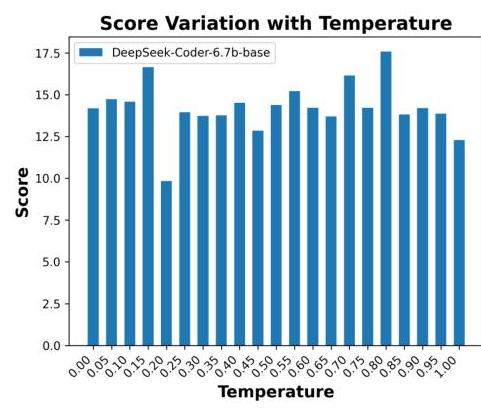
图11:DeepSeek-Coder-6.7b-Instruct在不同解码温度下的CoCo-Score波动。
从这些图11和图12可以观察到一个有趣的现象:较低性能的模型似乎对解码温度更加敏感。
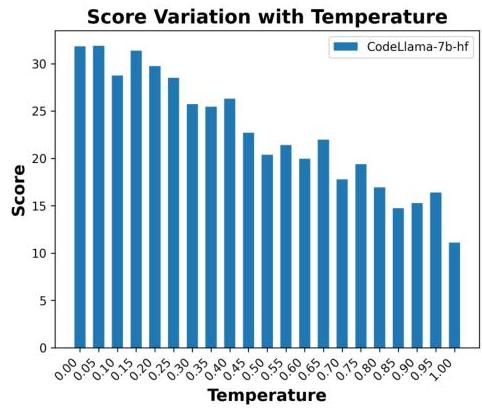
图12:CodeLlama-7b-hf在不同解码温度下的CoCo-Score波动。
具体来说,CodeLlama-7bhf在较低温度下取得了最高分,而DeepSeek-Coder-6.7b-Instruct在较高温度下显示出更大的分数波动。
这可以通过模型生成能力和解码温度之间的关系来解释。高性能模型通常具有更强的生成能力,使其能够在更广泛的温度范围内保持更稳定的性能。相反,低性能模型可能依赖特定的解码温度来提高在处理复杂任务时的输出质量。例如,CodeLlama-7b-hf在较低温度下可能会产生更确定的输出,避免在较高温度下引入的随机性,从而在某些任务中取得更好的分数。
另一方面,低性能模型对温度变化更为敏感,可能是因为它们难以在较高温度下保持输出的一致性和质量。随着温度升高,生成的文本可能变得更随机,导致任务性能下降。这也解释了为什么CodeLlama-7b-hf在较低温度下取得了最高分:在较低温度下,模型生成更确定和一致的内容,避免了不必要的随机性带来的噪音。
参考论文:https://arxiv.org/pdf/2504.20673


















 3229
3229

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











