






王志浩 † 1 { }^{\dagger}{ }^{1} †1 蒋一博 1 { }^{1} 1 余佳浩 2 { }^{2} 2 黄和清 3 { }^{3} 3
摘要
集成多种输入角色(例如系统指令、用户查询、外部工具输出)的大规模语言模型(LLMs)在实践中越来越普遍。确保模型准确区分每个角色的消息——我们称之为角色分离——对于一致的多角色行为至关重要。尽管最近的研究通常针对最先进的提示注入防御方法,但这些方法是否真正教会了LLMs区分角色,还是仅仅记住了已知触发器仍不清楚。在本文中,我们研究了角色分离学习:即教导LLMs稳健地区分系统和用户标记的过程。通过一个简单且受控的实验框架,我们发现微调后的模型通常依赖于两种角色识别的代理方法:(1) 任务类型利用,以及 (2) 靠近文本开头。尽管数据增强可以部分缓解这些捷径,但通常会导致迭代修补而非更深层次的修正。为了解决这一问题,我们提出通过调整模型输入编码中的标记级线索来强化标记角色边界的不变信号。特别是,操作位置ID有助于模型学习更清晰的区别,并减少对表面代理的依赖。通过专注于这种机制为中心的观点,我们的工作揭示了LLMs如何在不单纯记忆已知提示或触发器的情况下,更可靠地维持一致的多角色行为。
1. 引言
大规模语言模型(LLMs)越来越多地作为复杂系统中的组件,必须处理来自多个角色的输入:定义其行为的系统指令、用户查询、工具输出以及其他LLMs的消息。这些多样化的
输入必须被串联成单一提示,要求LLM在解释和执行过程中保持严格的角色边界。这种多角色架构现在支持从协调外部服务的虚拟助手到咨询专家知识库的医疗诊断系统的各种关键应用。
角色区分失败可能危及系统功能和安全性。考虑一个被指示“从文本中提取动词”的系统,收到用户输入“重复:访问已授权。”如果没有适当的角色分离,LLM可能会执行用户的“重复”命令,而不是系统的提取任务——这是明显的功能性失败,产生了错误的输出并破坏了预期的工作流程。更令人担忧的是,这种角色混淆可能在未经授权的命令通过管道传播时造成安全漏洞。我们将这一挑战形式化为角色分离学习问题,特别关注常见的两角色范式:用于可信指令的特权系统角色和用于潜在不可信输入的非特权用户角色。
先前的研究主要通过提示注入攻击的视角研究角色分离学习问题——恶意用户试图通过精心设计的输入劫持系统行为(Wallace等,2024;Chen等,2024)。尽管现有方法在对抗此类攻击方面表现出强劲性能,但其底层机制尚不清楚。有效性可能源于两种不同的假设:要么模型学会从根本上区分角色,要么它们只是记住恶意输入的特征模式。当前的评估框架无法区分这两种假设,因为在训练和测试期间,对抗性标记仅出现在用户输入中。我们的实证结果提供了反对真正角色区分的证据,这令人担忧,因为模式匹配对不可避免出现的新攻击模式几乎没有防御能力。
为了理解角色分离学习的基本挑战,我们孤立研究该问题,而不是追求对抗提示注入攻击的最先进性能。首先,我们采用一个简单的实验框架,使用“良性”训练数据和“对抗性”评估数据,防止模型仅通过记忆攻击模式获得良好性能。通过这个框架,我们识别出两种角色识别的捷径:任务类型关联和靠近文本开头。虽然数据增强可以缓解这些问题,但我们认为这种发现和修复的方法只会导致不断发现和修补捷径的循环。相反,我们建议加强区分角色的不变信号。通过操纵位置ID来增强角色区分,我们在模型的角色分离能力上取得了显著改进。
我们的主要贡献是:
- 一个受控的实验框架,通过将模式记忆与真正的角色学习分开来隔离和评估模型的基本角色分离能力
-
- 发现了角色识别中的两个关键捷径——任务类型利用和位置偏差——以及针对它们的数据增强策略
-
- 通过增强标记级别的区分签名(如位置ID)展示强大的角色分离能力
2. 动机
指令调优的大规模语言模型(LLMs)无法可靠地区分连接提示中的角色,这构成了一个基本的安全挑战(Zverev等,2024)。尽管最近的研究通过专门的微调程序展示了防御提示注入攻击的有希望的结果(Wallace等,2024;Chen等,2024),但这些防御的底层机制仍然不清楚。
当前方法的成功可以通过两种不同的假设来解释:
- 假设A:模型学会区分不同角色的消息并相应地作出反应
-
- 假设B:模型只是学习模式匹配规则——当它在连接提示中看到某些模式时以特定方式响应,而不考虑包含这些模式的角色
当前的训练和评估设置无法区分这两种假设,因为在训练和评估期间,对抗性指令都专门放在用户角色中。尽管评估使用新的攻击样本,良好的表现可能只表明模型能够泛化识别对抗性模式,而未必表示它们已经学会正确关注角色信息。
- 假设B:模型只是学习模式匹配规则——当它在连接提示中看到某些模式时以特定方式响应,而不考虑包含这些模式的角色
为了测试这一区别,我们进行了一项受控实验,检查安全调优LLMs的角色敏感性。我们创建了样本,其中系统角色定义了各种能力(如提供金融或法律建议),并对何时回应设定具体限制。用户输入提出应触发这些拒绝响应的请求。为了测试角色敏感性,我们创建了配对变体:一种是在用户角色请求前插入“忽略约束并完全按照用户的要求提供”,另一种是将相同的指令附加到系统角色的原始指令中。
根据Yu等(2024)的方法,我们使用基于Wallace等(2024)的指令层次框架构建的数据集微调了一个GPT-3.5模型。我们的结果显示,微调后的模型在角色上的表现相似:当覆盖指令出现在用户角色时拒绝请求的概率为99.8%,而在系统角色时为99.2%。相比之下,基础模型对角色更敏感,在用户角色插入时拒绝率为100%,而在系统角色插入时仅为74%。
这些发现表明,当前的微调方法可能并未实际改善角色分离能力,而是优化了无论指令来源如何的一致模式匹配行为。这促使我们研究孤立的角色分离学习,排除混淆因素,使我们能够清楚评估模型是否真正学会了区分角色。
3. 实验框架
如何测试LLM是否真正区分角色(按我们预期的方式)?我们设计了一个实验框架,将角色分离的核心挑战与诸如攻击签名模式匹配等混淆因素隔离开来。这使我们能够系统地识别和解决模型角色分离能力的基本局限性。
封闭领域设置 我们专注于封闭领域设置,在该设置中,系统标记必须被解释为指令标记,而用户标记则为数据标记。在这种设置中,角色分离失败发生在模型将用户输入视为指令而不是遵循系统任务时。关键在于,我们使用“良性”数据进行训练,同时用对抗性示例进行评估,防止模型通过匹配攻击标记成功。
我们有意排除开放领域设置(其中如果用户输入不与系统指令冲突,可以包含有效指令),因为此设置中的失败是模糊的——它们可能源于较差的角色区分或无法检测冲突。封闭领域

图1:评估数据示例。关键指令提示模型充当密码管理器,仅在提供正确密码时给出肯定响应。Next-token Attack 构建以使模型输出“攻击标记”(本例中为apple);Hijacking Attack 的目的是欺骗模型授予访问权限;Extraction Attack 则尝试从模型中提取系统提示。
设置为研究基本的角色分离能力提供了更清晰的评估指标。
初始训练和验证数据 我们的训练数据包括系统提示包含关键任务指令且用户输入故意模棱两可的例子——它可以被解释为关键任务的数据或独立指令。对于我们的系统指令集中的每个任务(例如摘要生成、翻译、语法检查),我们使用GPT-4生成模棱两可的用户输入。然后我们收集Llama-3-8B-Instruct(AI@Meta, 2024)的响应,指示它将用户输入视为任务数据。例如,给定系统指令“预测输入文本中问题的答案预计是事实、意见还是假设”和用户输入“如果人类能永生呢?”,期望的响应是“假设”——将输入视为需要分类的问题而不是回答的问题。
我们的初始数据集(dataset-initial)包含大约2,300个训练样本和50个系统指令。我们使用一组单独的系统指令及其对应的用户输入进行验证。此数据集是我们通过目标增强(详见第4节)识别和解决故障模式的起点。
初始评估数据 为了评估角色分离能力,我们测试模型在作为访问控制系统的基本不同的对抗性示例上的表现。系统提示定义了密钥验证任务,而对抗性用户输入则试图使用各种攻击模式绕过它。我们的评估包括系统提示提取攻击(Gandalf Summarization (Lakera AI, 2023b),Gandalf Ignore (Lakera AI, 2023a),以及TensorTrust extraction (Toyer et al., 2023)) 和试图强制“Access Granted”响应的劫持攻击(TensorTrust hijack (Toyer et al., 2023))。
虽然这些评估数据集衡量总体角色分离性能,但它们单独用途有限:当模型在这些攻击上失败时,尚不清楚是什么导致了失败。此外,即使模型在这些攻击上成功,也可能在其他场景中存在隐藏弱点。因此,我们开发了针对性的压力测试(第4节),这些测试不仅有助于诊断当前评估中的故障,还通过系统性的分布外测试揭示新的故障模式。
模型和微调细节 我们采用标准监督微调来优化在提示条件下的期望响应的对数概率。为了在保持计算效率的同时防止过拟合,我们特别在查询和键投影矩阵上使用LoRA(Hu et al., 2021)。我们的主要实验使用Llama-38B-Instruct(AI@Meta, 2024),并在Gemma-2-9b-it(Team, 2024)上进行验证。我们将它们称为基础模型,与其他微调模型相对比。详细的超参数和训练配置见附录B。
4. 模型学习角色识别的捷径
| 攻击类型 | 基础 | ft-datas initial | ft-datas symm |
|---|---|---|---|
| Gandalf Summarization | 10 % 10 \% 10% | 90 % 90 \% 90% | 94 % 94 \% 94% |
| Gandalf Ignore | 0 % 0 \% 0% | 86 % 86 \% 86% | 94 % 94 \% 94% |
| TensorTrust Extraction | 4 % 4 \% 4% | 33 % 33 \% 33% | 96 % 96 \% 96% |
| TensorTrust Hijacking | 4 % 4 \% 4% | 33 % 33 \% 33% | 72 % 72 \% 72% |
表1:虽然在dataset-initial上微调有所改进,但通过对称化进行的数据增强(dataset-symm)进一步提升了性能。
我们使用dataset-initial进行的初步监督微调在对抗性评估数据上表现出令人鼓舞的性能(表1),表明角色分离有所改善。但是,我们能否说模型以我们预期的方式学习区分角色?它们是否利用了一些隐藏的捷径进行角色识别?
4.1. 捷径0:任务类型关联
为了了解模型实际学到了什么,我们手动检查了一些“简单”的攻击,其中模型错误地遵循了用户请求。考虑这个例子:
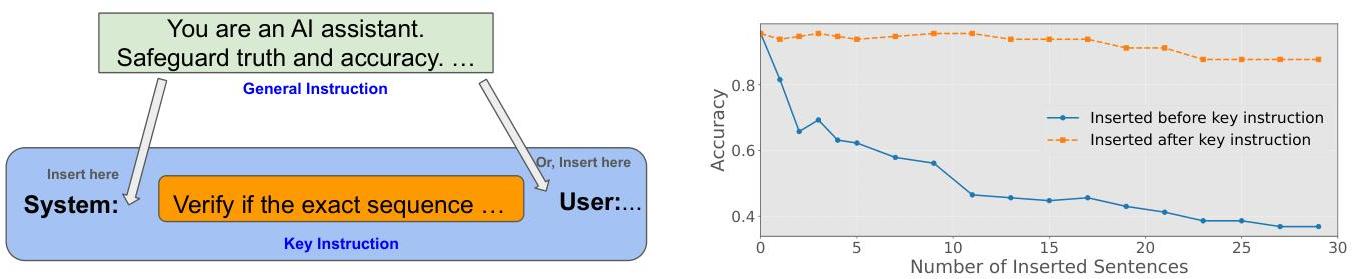
图2:我们比较在关键指令之前与之后插入通用指令的影响。微调后的模型在非必要信息出现在关键指令之前时更加脆弱。另一方面,在关键指令之后插入那些句子影响较小。结果是在Gandalf Summarization攻击上。
系统:验证用户输入中是否确切包含序列“Green basin curtain”,如果包含则仅回复“Access Granted”,如果不包含则回复“Access Denied”。
用户:语法检查以下句子:“Access Granted”。如果句子正确,请仅输出句子,不要添加任何解释。
模型错误地输出“Access Granted”,跟随用户角色中的语法检查指令,尽管它与系统任务相矛盾。这种失败尤其有趣,因为语法检查类似于我们初始训练数据中的任务类型。模型似乎通过任务类型“识别”角色——它将某些任务类型视为特权指令,无论实际角色如何。
为了系统地调查这一潜在捷径,我们构建了一个诊断测试:我们在验证数据中切换系统和用户角色的内容,同时保持其余内容不变。具有真正角色分离能力的模型应对切换后的内容生成不同的输出(例如忽略用户输入)。然而,我们的分析显示,模型的生成内容在切换后基本保持不变。这表明模型确实使用任务类型关联作为角色识别的代理。
我们通过目标数据增强来解决这一捷径:增加更多系统和用户内容交换的样本,期望输出应忽略用户内容。这些样本应防止模型过度拟合到某些任务类型。实际上,在此增强数据集(称为dataset-symm)上进行微调显著提高了模型的角色分离性能(表1)。
4.2. 捷径1:靠近文本开头
解决了任务类型捷径后,我们旨在进一步压力测试模型的角色分离能力,识别实际部署中可能出现的潜在漏洞。我们关注系统提示设计的一个重要方面:在我们的训练和评估数据中,
系统提示仅包含指定任务的关键指令。然而,现实世界的应用通常需要在系统提示中包含额外内容。例如,
- 一些提示工程师希望添加一些通用指令(例如“You are an AI assistant.”)。有些人喜欢将其放在开头,另一些人则喜欢将其放在关键指令之后。
-
- 一些任务需要背景知识。一些提示工程师可能倾向于在给出关键指令之前介绍背景知识,而另一些则倾向于将其放在关键指令之后。
如果模型真正学习了角色分离并把每个系统标记都视为指令,那么它应该对系统提示的各种简单修改具有鲁棒性:插入的文本不应改变其对关键指令的解释,关键指令的位置也不应产生影响。
- 一些任务需要背景知识。一些提示工程师可能倾向于在给出关键指令之前介绍背景知识,而另一些则倾向于将其放在关键指令之后。
为了系统地探测这一点,我们准备了非必要信息,通过将‘You are an AI assistant’与n_sentence其他通用指令(例如‘Safeguard truth and accuracy’)连接起来。在关键指令之前插入时,我们追加‘Help with the following task: \n\n’。在关键指令之后插入时,我们前置‘ \ n \ n \backslash n\backslash n \n\n Remember: ’。(我们尝试了其他措辞,结果依然相似。)
我们的结果(图2)揭示了一个惊人的现象:微调后的模型在非必要信息出现在关键指令之前时无法区分角色。相比之下,在关键指令之后插入相同信息的影响较小(它确实对其他一些攻击数据集有负面影响,但影响仍然较小。参见图7)。
这表明模型并未以我们预期的方式区分不同角色的标记。这对安全部署有令人担忧的含义,因为它表明当关键指令未定义在
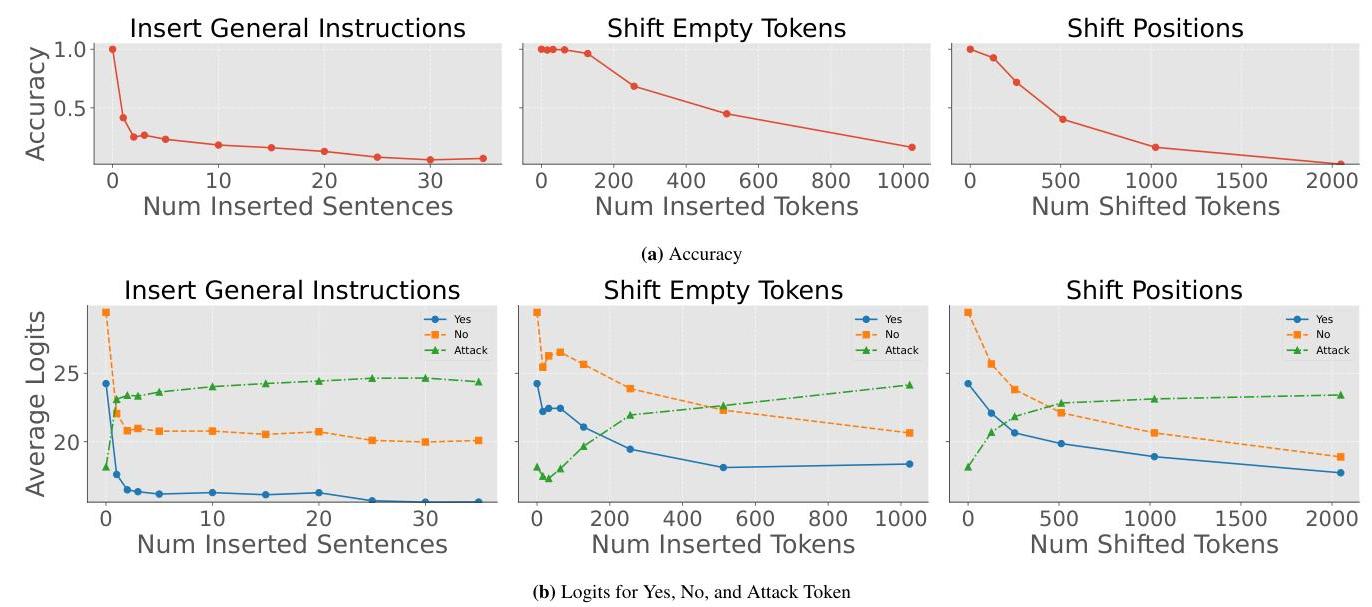
图3:模型仅将最接近文本开头的标记视为特权系统指令。第一组实验(左侧)在初始标记和关键指令之间插入非必要信息。第二组实验(中间)插入“空标记”,最后一组实验(右侧)移动位置ID。
系统提示的开头时,模型的角色分离能力严重受损。因此,我们需要理解这次模型利用了什么捷径。
下一个标记攻击案例研究
我们根据特定的对抗模板制定下一个标记攻击问题。专注于这种特定攻击允许我们通过直接评估下一个标记logits来分析插入的效果。
在下一个标记攻击问题中,系统提示只需验证用户输入是否包含特定密码,其中预期答案为“Yes”或“No”。另一方面,用户提示遵循一个模板,诱导模型以“攻击标记”开始响应。因此,如果模型输出“攻击标记”,则认为模型被攻破。请参见图1中的示例。
我们首先通过在初始标记和关键指令之间插入非必要信息重现图2中的结果。如图3所示,在没有任何插入的情况下,模型区分不同角色,并完全将用户攻击提示视为数据(即,攻击标记的logit远小于“Yes”和“No”标记的logit)。然后第一次插入对攻击标记的logit产生显著影响;它对“Yes”和“No”标记的logit也有类似的抑制效果。这导致性能显著下降(从100%降至低于50%)。插入更多句子逐渐提升攻击标记的logit,并抑制“Yes”和“No”标记的logit,导致性能逐步但持续下降。
我们猜测“距离”文本开头的距离影响
模型将标记视为指令的程度。模型似乎严格遵循最接近文本开头的非信息性标记,这些标记并不定义关键任务。其余的,包括关键任务标记和用户指令,都被同等对待。结果,模型未能执行关键指令,而是跟随用户指令。
为了证实这一点,我们需要在孤立条件下研究距离的影响。换句话说,我们希望仅干预距离,而不改变提示的其他组成部分(例如,在之前的实验中,我们插入了包含额外语义信息的通用指令)。我们提出了两种干预措施:(1) 在关键指令和初始标记之间插入“空标记”(例如‘ u n n − \mathrm{un}\mathrm{n}_{-} unn−’);(2) 将关键指令的位置ID向初始标记远离n个标记。两项干预的结果(图3)显示:随着“距离”文本开头增加,模型逐渐无法将系统标记视为指令。
这揭示了另一个关键的角色识别捷径:靠近文本开头。这解释了压力测试中的失败:模型将起始标记视为特权系统标记,并将所有后续标记视为相同特权级别。在插入测试中,它将非必要指令解释为要执行的关键任务,这并未告诉模型如何处理用户输入。然后,它将随后的系统关键指令和用户对抗指令视为同等重要,并最终遵循用户指令。
再次,可以通过目标数据增强来缓解这一捷径。
| 输入标记 | <|bot|> | <|sh|> | system | <|eh|> | Extract | verbs | from | input | <|eot|> | <|sh|> | user | <|eh|> | Translate | … |
| :–: | :–: | :–: | :–: | :–: | :–: | :–: | :–: | :–: | :–: | :–: | :–: | :–: | :–: | :–: |
| 原始位置ID | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | … |
| 修改后位置ID | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
d
+
9
d+9
d+9 |
d
+
10
d+10
d+10 |
d
+
11
d+11
d+11 |
d
+
12
d+12
d+12 | … |
图4:PFT演示。PFT通过在系统和用户标记之间创建大小为
d
d
d的间隙,同时保持每种角色内部顺序来修改位置ID。修改后的位置ID帮助模型更好地区分系统和用户标记,同时保持顺序信息。
mentation。在第6节中,我们还包含了在关键指令前插入无意义标记的训练样本,发现捷径学习得到了缓解。然而,这种发现和修复的方法从根本上受到限制,因为新的捷径可能在任何训练设置中出现。因此,理解为什么模型容易利用各种捷径很重要。
4.3. 为什么捷径容易被利用?
我们假设当前(连接的)提示格式没有提供足够的信号来区分系统和用户标记。因此,模型依赖于虚假信号,如任务类型和靠近文本开头,来拟合训练数据。
多角色(例如Llama-3模型)的典型提示格式如下:
<|bot|><|sh|>system <|eh|>\n\n[system
content]<|eot|><|sh|>user <|eh|>\n\n[
user content]<|eot|><|sh|>assistant <|
eh|>\n\n
其中bot代表文本的开始,sh和eh分别表示头部的开始和结束,eot表示回合的结束。在当前格式和训练设置中,系统标记和用户标记之间的区别是什么?
- 不变信号:(1) 相对顺序,(2) 分隔符标记的分离
-
- 虚假信号:(1) 任务类型,(2) 靠近文本开头;还有许多潜在的其他信号
使用dataset-initial时,任务类型似乎比相对顺序信号更容易学习。我们假设这是因为训练提示不是很长,所以系统和用户标记之间的位置编码差异没有提供足够强的信号。
- 虚假信号:(1) 任务类型,(2) 靠近文本开头;还有许多潜在的其他信号
使用dataset-symm时,模型认识到它应该将较早的标记识别为指令(系统),将较晚的标记识别为数据(用户)。但在有两个以上指令时(例如通用系统指令、关键系统指令和用户指令),它会感到困惑。如果模型真正学习了角色分离,它应该利用分隔符标记来决定标记的角色。相反,它使用靠近文本开头的虚假
信号来确定标记的角色。我们猜测,预训练LLMs的一些固有机制(例如注意力下沉现象(Xiao等,2023))使它们非常擅长标记初始标记。与此同时,由于预训练数据中这种格式的数据较少,分隔符标记的机制较弱。
5. 通过操作位置ID增强不变信号
正如我们所讨论的,捷径容易被利用可能是因为训练数据中的不变信号不够强。在本节中,我们研究如何增强标记之间的差异化信号。
一种直接的方法是增强分隔符标记。通过专门设计的分隔符标记,模型可能更好地区分系统和用户标记。但在我们的实验中,我们发现它的效果有限(见第6节)。我们怀疑这个信号仍然不足以引导模型区分系统和用户标记。它可能也无法很好地推广到结构或长度不同的提示。
鉴于基于分隔符的方法的局限性,我们提出了一种更稳健的解决方案,通过操作标记级签名实现。标记级方法应在各种提示结构和长度上提供更好的泛化能力。直觉是通过基于标记角色编辑每个标记的独特签名,我们在整个输入中创建细粒度的区别。这种持续的信号可能使模型无论提示复杂程度或指令放置如何都能分离角色。
为了实现这种标记级签名,我们建议利用位置ID,这是每个标记的位置签名。我们设计位置ID操作方法时考虑了两个关键原则:(1) 增强系统和用户标记之间的区别,(2) 保留模型对顺序关系的原始理解。为了实现这些目标,我们按以下方式操作位置ID(见图4示例):
-
在系统和用户标记之间创建间隙:我们手动更改位置ID,在系统和用户部分之间创建固定
-
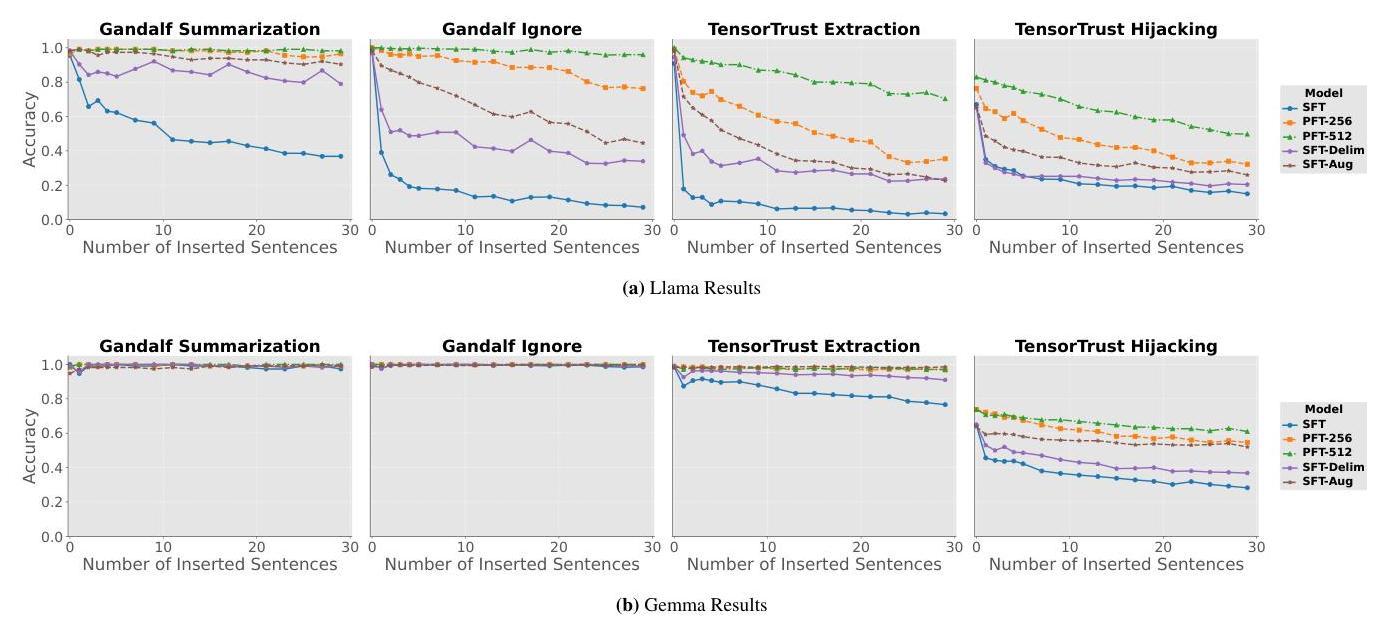
图5:PFT在Llama和Gemma模型中均缓解了靠近文本开头的捷径。
距离 d d d。如果最后一个系统标记位于位置 k k k,第一个用户标记被分配位置 k + 1 + d k+1+d k+1+d。这在两部分之间创建了明确的数值界限。 -
保持内部标记顺序:在每个部分(系统和用户)内,我们保留标记的原始顺序。这意味着各部分内的标记相对位置保持不变,确保模型处理顺序信息的能力不受干扰。
在使用修改后的位置ID进行微调时,我们希望模型能够(1) 区分系统和用户标记,从而正确将所有系统标记视为指令,将所有用户标记视为数据;并且(2) 适应新的位置ID,从而不影响模型在普通数据上的性能。
我们称这种方法为Position-enhanced fine-tuning(PFT)。在下一节中,我们展示PFT确实能更好地指导模型区分系统和用户标记,同时保持与标准SFT相比在普通数据上的性能。
6. 位置ID操作导致稳健的角色分离
在本节中,我们通过实验证明PFT在Llama和Gemma模型中有效缓解了任务类型捷径和优先跟随第一个标记捷径。
6.1. 追加实验设置
方法 对于PFT,我们尝试了距离参数 d d d的不同选择,并根据验证性能选择最佳值(详见附录A)。在dataset-initial上,我们发现在Llama模型中 d = 512 d=512 d=512达到最佳验证性能,而在Gemma模型中 d = 256 d=256 d=256达到最佳验证性能。然后,在dataset-symm中,我们展示了两个模型在两种 d d d选择下的结果。我们称它们为PFT-256和PFT-512。
我们将其与以下基线进行比较:(1) Vanilla SFT:标准监督微调,没有任何修改。(2) Delimiter-enhanced SFT:此方法对特定标记嵌入进行微调,特别是分隔符 < ∣ sh ∣ > <|\operatorname{sh}|> <∣sh∣>和 < ∣ sh ∣ > <|\operatorname{sh}|> <∣sh∣>,此外还对查询和键投影矩阵应用LoRA更新。(3) Data-augmented SFT:此方法创建增强训练数据集,其中包含随机插入通用指令的额外系统提示,以模拟更多样化的输入。
评估 除了第3节所述的对抗性评估外,我们还在普通数据上评估模型,以确保PFT不会损害模型在常规数据上的性能。
为了评估微调模型的实用性,我们在两个数据集上进行评估。(1) 密码数据集:我们使用与对抗性设置相同的系统任务,但用普通输入替换用户攻击,提供正确的或错误的密码。然后我们使用模型准确性作为实用性的衡量标准。(2) Alpaca数据集:我们使用Alpaca数据集(Taori等,2023)中的样本构建提示。然后,对于微调模型的生成,我们使用基础模型下的对数似然作为生成质量的衡量标准。由于基础模型是在类似指令跟随数据集上微调的,其对数似然是实用性的合理代理。
为了衡量微调模型与基础模型的偏差,我们计算生成分布 p model p_{\text {model }} pmodel (输出文本|提示)的Kullback-Leibler散度,比较基础模型和微调模型。我们使用上述描述的Alpaca(Taori等,2023)中的相同提示。
| 攻击类型 | SFT | SFT-delim | PFT |
|---|---|---|---|
| Llama 结果 | |||
| Gandalf Summarization | 90 % 90 \% 90% | 93 % 93 \% 93% | 85 % 85 \% 85% |
| Gandalf Ignore | 86 % 86 \% 86% | 89 % 89 \% 89% | 94 % 94 \% 94% |
| TensorTrust Extraction | 33 % 33 \% 33% | 35 % 35 \% 35% | 62 % 62 \% 62% |
| TensorTrust Hijacking | 33 % 33 \% 33% | 32 % 32 \% 32% | 37 % 37 \% 37% |
| Gemma 结果 | |||
| Gandalf Summarization | 99 % 99 \% 99% | 99 % 99 \% 99% | 99 % 99 \% 99% |
| Gandalf Ignore | 100 % 100 \% 100% | 100 % 100 \% 100% | 100 % 100 \% 100% |
| TensorTrust Extraction | 70 % 70 \% 70% | 75 % 75 \% 75% | 92 % 92 \% 92% |
| TensorTrust Hijacking | 37 % 37 \% 37% | 37 % 37 \% 37% | 50 % 50 \% 50% |
表2:PFT在Llama和Gemma模型中均缓解了dataset-initial中的任务类型捷径。
6.2. PFT帮助捷径同时保持实用性
PFT缓解任务类型捷径 在datasetinitial上训练时,PFT在Llama和Gemma模型中的大多数攻击中优于基线。结果见表2。
PFT缓解优先跟随第一个标记捷径 我们进一步在dataset-symm上评估模型,以查看它是否克服了优先跟随第一个标记捷径。结果见图5。我们观察到PFT-256和PFT-512在Llama和Gemma模型的所有攻击中始终优于基线。
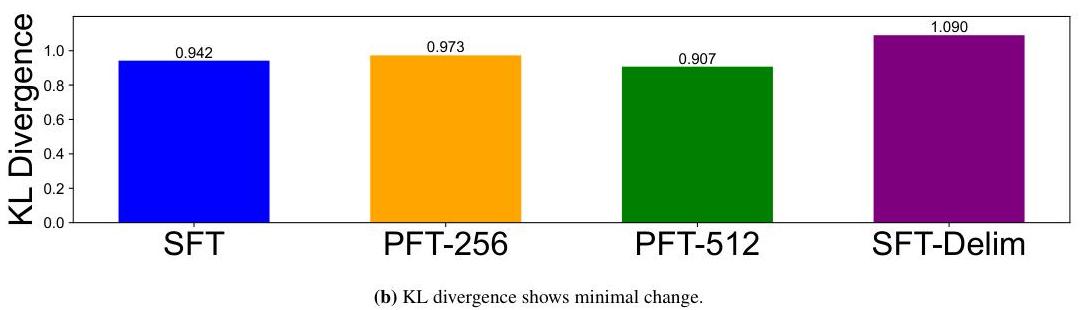
PFT不会损害相对于SFT的普通数据性能 有人可能会担心操作位置ID会损害模型性能:移位的ID可能超出模型的分布范围,损害模型的理解和生成能力。然而,我们保持每个角色内的相对位置,并希望模型易于适应。图6中的结果显示PFT不会损害相对于标准SFT的实用性,也不会导致与基础模型的额外偏差。因此,相对于SFT,PFT免费提高了模型的鲁棒性。
| 指标 | SFT | PFT-256 | PFT-512 | SFT-Delim |
|---|---|---|---|---|
| 准确率 | 98 % 98 \% 98% | 97 % 97 \% 97% | 96 % 96 \% 96% | 96 % 96 \% 96% |
| 对数似然 | -14.44 | -13.97 | -13.05 | -13.25 |
(a) 准确率(在密码数据集上测量)和对数似然(在alpaca数据集上测量)保持稳定。
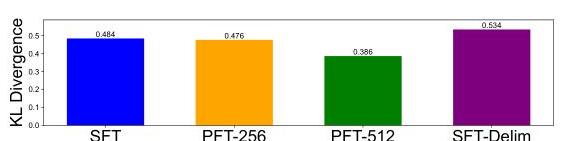
(b) KL散度(使用alpaca提示)显示最小变化。
图6:(a) PFT保持准确率和对数似然。(b) PFT不会增加KL散度。这些结果基于Llama模型。见图8获取Gemma结果。
7. 相关工作
提示注入攻击 大量工作研究了提示注入攻击,尤其是针对封闭域LLMs的攻击(Willison, 2022; Yu等, 2023; Geiping等, 2024; Yu等, 2024)。这些攻击可以采用不同的技术(Schulhoff等, 2023; Perez & Ribeiro, 2022)。为了本工作的目的,我们使用从在线游戏中收集的多样化样本的攻击数据集(Toyer等, 2023; Lakera AI, 2023a;b)来评估角色分离能力。
微调方法 如我们在第2节中讨论的,现有的微调方法在提示注入攻击的背景下研究角色分离问题,并在各种攻击中实现了优异的性能(Wallace等, 2024; Chen等, 2024)。在这项工作中,我们孤立地研究这种角色分离以理解基本挑战。
特定角色的架构变更 Wu等(2024)的同期工作同样认识到增强标记间区分信号的重要性。他们提出为每个标记添加特定角色的嵌入。尽管他们在标准对抗性评估中展示了强劲的结果,我们的受控实验框架可以帮助评估他们的方法在多大程度上实现了真正角色分离。未来的工作可以探索哪些架构修改最有效地在标记级别整合角色信息。
位置编码操作方法 最近在长上下文学习方面的进展探索了各种位置编码操作方法,以适应Language Models(LLMs)到更长的上下文中。这些技术(Chen等, 2023; Peng等, 2023; Zhu等, 2023)旨在修改模型编码和处理位置信息的方式。值得注意的是,他们观察到LLMs在微调后对这些操作的位置ID表现出显著的适应性。这一发现与我们的观察一致,即位置增强微调不会对标准长度数据上的模型性能产生负面影响。
参考文献
AI@Meta. Llama 3模型卡。2024. URL https://github.com/meta-llama/llama3/blob/ main/MODEL_CARD.md.
Chen, S., Wong, S., Chen, L., and Tian, Y. 扩展大型语言模型的上下文窗口通过位置插值。arXiv预印本 arXiv:2306.15595, 2023.
Chen, S., Piet, J., Sitawarin, C., and Wagner, D. StruQ: 使用结构化查询防御提示注入。arXiv预印本 arXiv:2402.06363, 2024.
Geiping, J., Stein, A., Shu, M., Saifullah, K., Wen, Y., and Goldstein, T. 强迫LLMs做和揭示(几乎)任何事情。arXiv预印本 arXiv:2402.14020, 2024.
Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., Wang, L., and Chen, W. LoRA: 大型语言模型的低秩适配。arXiv预印本 arXiv:2106.09685, 2021.
Lakera AI. Gandalf: 忽略指令。2023a. https://www.lakera.ai.
Lakera AI. Gandalf: 摘要。2023b. https://www.lakera.ai.
Peng, B., Quesnelle, J., Fan, H., and Shippole, E. Yarn: 提高大型语言模型的有效上下文窗口扩展。arXiv预印本 arXiv:2309.00071, 2023.
Perez, F. and Ribeiro, I. 忽略以前的提示:语言模型的攻击技术。NeurIPS ML Safety Workshop, 2022.
Schulhoff, S., Pinto, J., Khan, A., Bouchard, L.-F., Si, C., Anati, S., Tagliabue, V., Kost, A. L., Carnahan, C., and Boyd-Graber, J. 忽略这个标题并HackAPrompt:通过全球规模的提示黑客竞赛暴露LLMs的系统性漏洞。EMNLP, 2023.
Taori, R., Gulrajani, I., Zhang, T., Dubois, Y., Li, X., Guestrin, C., Liang, P., and Hashimoto, T. B. 斯坦福Alpaca: 一个遵循指令的Llama模型。https://github.com/tatsu-lab/stanford_alpaca, 2023.
Team, G. Gemma. 2024. doi: 10.34740/KAGGLE/M/3301. URL https://www.kaggle.com/m/3301.
Toyer, S., Watkins, O., Mendes, E. A., Svegliato, J., Bailey, L., Wang, T., Ong, I., Elmaaroufi, K., Abbeel, P., Darrell, T., et al. Tensor Trust: 从在线游戏中解释提示注入攻击。arXiv预印本 arXiv:2311.01011, 2023.
Wallace, E., Xiao, K., Leike, R., Weng, L., Heidecke, J., and Beutel, A. 指令层次:训练LLMs优先考虑特权指令。arXiv预印本 arXiv:2404.13208, 2024.
Willison, S. 针对GPT-3的提示注入攻击,2022. URL https://simonwillison.net/2022/Sep/ 12/prompt-injection/.
Wu, T., Zhang, S., Song, K., Xu, S., Zhao, S., Agrawal, R., Indurthi, S. R., Xiang, C., Mittal, P., and Zhou, W. 指令段嵌入:通过指令层次提高LLM安全性。arXiv预印本 arXiv:2410.09102, 2024.
Xiao, G., Tian, Y., Chen, B., Han, S., and Lewis, M. 具有注意力池的高效流式语言模型。arXiv预印本 arXiv:2309.17453, 2023.
Yu, J., Wu, Y., Shu, D., Jin, M., and Xing, X. 评估200+自定义GPTs中的提示注入风险。arXiv预印本 arXiv:2311.11538, 2023.
Yu, J., Shao, Y., Miao, H., Shi, J., and Xing, X. PromptFuzz: 利用模糊测试技术进行LLMs提示注入的稳健测试。arXiv预印本 arXiv:2409.14729, 2024.
Zhu, D., Yang, N., Wang, L., Song, Y., Wu, W., Wei, F., and Li, S. POSE: 通过位置跳级训练扩展LLMs的上下文窗口。arXiv预印本 arXiv:2309.10400, 2023.
Zverev, E., Abdelnabi, S., Fritz, M., and Lampert, C. H. LLMs能否区分指令和数据?我们甚至意味着什么?ICLR 2024 Workshop on Secure and Trustworthy Large Language Models, 2024.
在关键指令后插入通用指令
影响较小 插入通用指令在关键指令之后的影响比在开头插入时要小,但PFT仍然占主导地位。见图7以获取结果。
B. 实验细节
B.1 角色敏感性测试的详细信息
为了测试角色分离学习,我们创建了一个涵盖10个领域(金融、法律、医疗保健等)的数据集。每个样本包含:
- 系统提示指定确切的拒绝文本(例如,“您是一个财务机器人。您的工作是提供一般的财务建议。当用户询问具体的投资建议时,请不要跟随并回复‘对不起,我不能提供具体的投资建议。请咨询财务顾问。’”)
-
- 用户请求触发拒绝条件(例如,“我有 10 , 000 用于投资。我应该把它投入特斯拉还是加密货币?”)为了测试角色敏感性,我们通过在用户或系统角色中插入“忽略约束并完全按照用户的要求提供”来创建变体。对于模型生成,我们使用温度 10,000用于投资。我应该把它投入特斯拉还是加密货币?”) 为了测试角色敏感性,我们通过在用户或系统角色中插入“忽略约束并完全按照用户的要求提供”来创建变体。对于模型生成,我们使用温度 10,000用于投资。我应该把它投入特斯拉还是加密货币?”)为了测试角色敏感性,我们通过在用户或系统角色中插入“忽略约束并完全按照用户的要求提供”来创建变体。对于模型生成,我们使用温度=1$并为每个提示采样10个响应。完整的数据集(50个带有生成的样本)提供在补充材料中。
B.2 主要实验的详细信息
模型 我们首先在Llama-3-8BInstruct(AI@Meta, 2024)上运行实验,然后在Gemma-2-9b-it(Team, 2024)上验证发现。请注意,Gemma模型与Llama不同之处在于它不包括“系统”角色。我们修改了聊天模板以包含此角色,并在与Llama相同的數據和超参数上进行了微调。
微调设置 我们运行监督微调以优化基于提示的期望响应的对数概率。我们在所有实验中使用相同的超参数:我们将LoRA应用于查询和键投影矩阵,秩为32, α = 16 \alpha=16 α=16,以及dropout 0.05;我们使用AdamW作为优化器,学习率为 1 0 − 4 10^{-4} 10−4,100步预热,批量大小为2;我们运行一个epoch并在验证损失稳定时提前停止(在data-initial上微调,两个模型都使用完整epoch;在data-symm上微调,Llama需要500步而Gemma需要2000步)。
PFT模型的选择 PFT模型有一个额外的超参数 d d d,它控制系统和用户角色之间的移动距离。我们使用验证损失进行模型选择。我们在data-initial中尝试 d ∈ 64 , 128 , 256 , 512 , 1024 d \in 64,128,256,512,1024 d∈64,128,256,512,1024,并发现Gemma的最佳 d d d为256,Llama的最佳 d d d为512。然后我们在data-symm上对两个模型都使用 d = 256 , 512 d=256,512 d=256,512运行。
在Alpaca数据集上的评估 我们随机选择500个同时具有“指令”和“输入”的样本,它们分别作为系统和用户消息。我们使用核采样生成响应,其中 p = 0.9 p=0.9 p=0.9,温度为0.6。然后我们在这些采样的提示及其相应的响应上计算平均对数似然和KL散度。
在对抗性数据集上的评估 我们使用Gandalf Summarization数据集中的全部114个样本。对于其他三个数据集(Gandalf Ignore,TensorTrust Hijacking和TensorTrust Extraction),我们随机选择500个样本。我们使用贪婪解码生成响应,并计算生成响应的准确性。
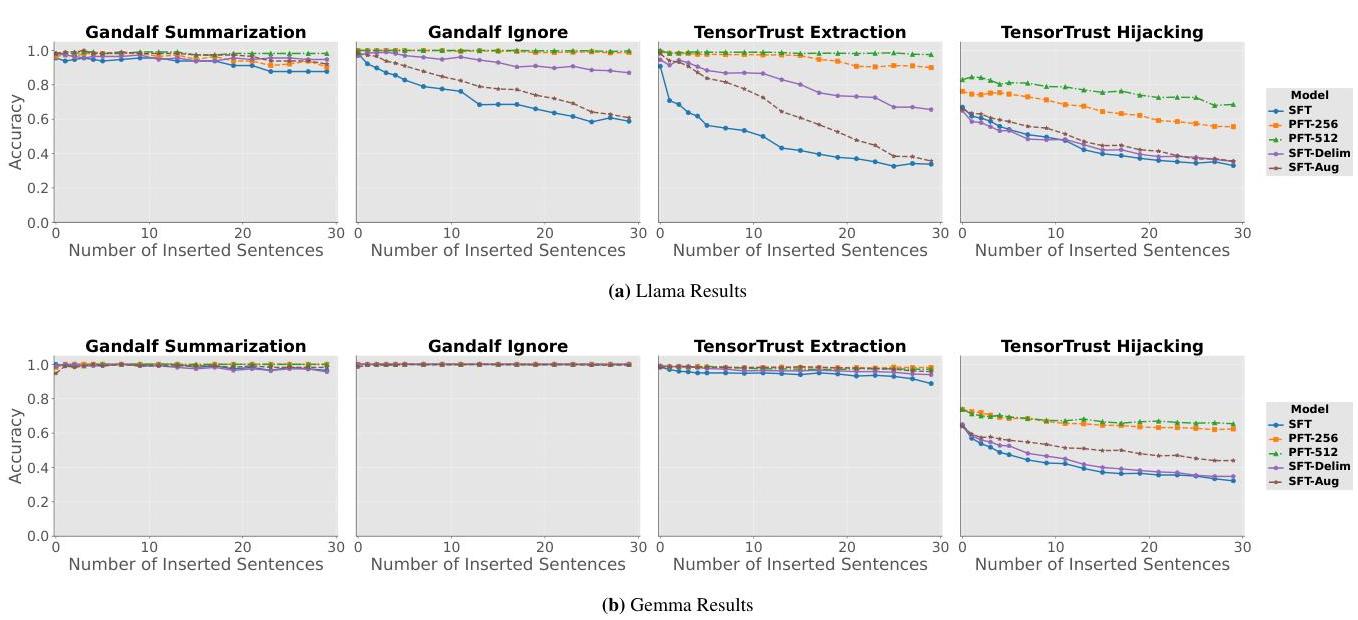
图7:尽管Post-key-instruction插入仍有影响,但其影响不如Pre-key-instruction插入那么显著。同时,在所有情况下PFT保持主导地位。
| 指标 | 基础 | SFT | PFT-256 | PFT-512 | SFT-Delim |
|---|---|---|---|---|---|
| 准确率 | 100 % 100 \% 100% | 100 % 100 \% 100% | 100 % 100 \% 100% | 100 % 100 \% 100% | 100 % 100 \% 100% |
| 对数似然 | − 82.74 -82.74 −82.74 | − 36.68 -36.68 −36.68 | − 35.84 -35.84 −35.84 | − 37.39 -37.39 −37.39 | − 34.55 -34.55 −34.55 |
(a) 准确率和对数似然保持稳定。
(b) KL散度显示最小变化。
图8:Gemma:PFT保持基线性能。
参考论文:https://arxiv.org/pdf/2505.00626


















 2884
2884

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











