






1.数据质量分析
主要任务是检查原始数据中是否存在脏数据,包括缺失值,异常值,不一致值,重复数据及特殊符号数据
缺失值,包括记录缺失和记录的某字段缺失等
产生原因:无法获取、遗漏、属性值不存在;
影响:有用信息缺乏、不确定性加重、不可靠
处理:删除、补全、不处理
异常值,不合常理的数据,剔除可消除不良影响,分析可进行改进。异常值分析也称离群点分析。
常用的分析方法:简单统计量分析(如max、min);3σ原则(99.7%);箱型图(QL-1.5IQR,QU+1.5IQR)
一致性分析:直属局矛盾性、不相容性
产生原因:数据集成过程中,数据来自不同数据源,存放等未能进行一致性更新
下面是绘制箱图的代码和结果
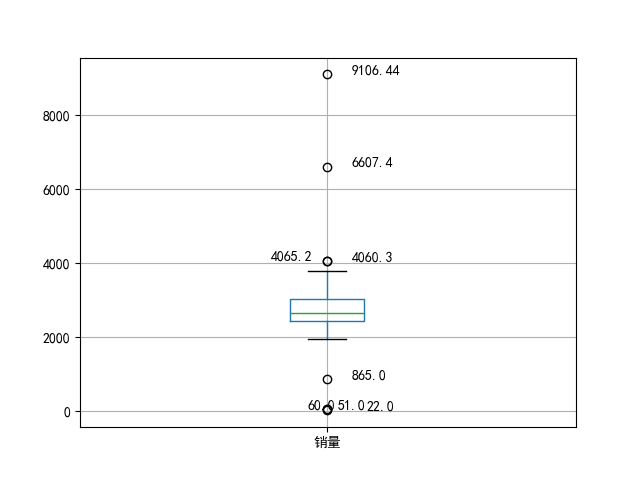
#绘制箱图
#-*- coding: utf-8 -*-
import pandas as pd
catering_sale = '../data/catering_sale.xls' #餐饮数据
data = pd.read_excel(catering_sale, index_col = u'日期') #读取数据,指定“日期”列为索引列
import matplotlib.pyplot as plt #导入图像库
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
plt.figure() #建立图像
p = data.boxplot(return_type='dict') #画箱线图,直接使用DataFrame的方法
x = p['fliers'][0].get_xdata() # 'flies'即为异常值的标签
y = p['fliers'][0].get_ydata()
y.sort() #从小到大排序,该方法直接改变原对象
#用annotate添加注释
#其中有些相近的点,注解会出现重叠,难以看清,需要一些技巧来控制。
#以下参数都是经过调试的,需要具体问题具体调试。
for i in range(len(x)):
if i>0:
plt.annotate(y[i], xy = (x[i],y[i]), xytext=(x[i]+0.05 -0.8/(y[i]-y[i-1]),y[i]))
else:
plt.annotate(y[i], xy = (x[i],y[i]), xytext=(x[i]+0.08,y[i]))
plt.show() #展示箱线图2.数据特征分析
分布分析:数据分布特征与分布类型
①定量数据分布分析:求极差——决定组距和组数——决定分点——列频率分布表——绘频率分布直方图
②定性数据分布分析:采用分类类型来分组,用饼图或条形图来描述分布
对比分析:两个指标进行比较,展示说明大小水平高低,速度快慢,是否协调等
①绝对数比较
②相对数比较:结构相对数(比重),比例相对数(比值),比较相对数(同类不同背景),强度相对数(密度),计划完成程度相对数,动态相对数
统计量分析:统计描述
集中趋势:均值、中位数、众数
离中趋势:极差、标准差、变异系数(CV=标准差/平均值*100%)、四分位数间距(上下四分位数之差)
#-*- coding: utf-8 -*-
#餐饮销量数据统计量分析
from __future__ import print_function
import pandas as pd
catering_sale = '../data/catering_sale.xls' #餐饮数据
data = pd.read_excel(catering_sale, index_col = u'日期') #读取数据,指定“日期”列为索引列
data = data[(data[u'销量'] > 400)&(data[u'销量'] < 5000)] #过滤异常数据
statistics = data.describe() #保存基本统计量
statistics.loc['range'] = statistics.loc['max']-statistics.loc['min'] #极差
statistics.loc['var'] = statistics.loc['std']/statistics.loc['mean'] #变异系数
statistics.loc['dis'] = statistics.loc['75%']-statistics.loc['25%'] #四分位数间距
print(statistics)
#output:
# 销量
#count 195.000000
#mean 2744.595385
#std 424.739407
#min 865.000000
#25% 2460.600000
#50% 2655.900000
#75% 3023.200000
#max 4065.200000
#range 3200.200000
#var 0.154755
#dis 562.600000
周期性分析:是否随时间呈周期变化趋势
贡献度分析:又称帕累托分析,原理是帕累托法则,又称20/80定律。同样的投入在不同的地方产生不同的收益。
相关性分析
①直接绘制散点图
②绘制散点图矩阵,对多个变量两两关系的散点图
③计算相关系数,[1]Pearson相关系数(要求数据服从正态分布);[2]Spearman秩相关系数。两者都要经过假设检验,t检验方法检验其显著性水平以确定其相关成。正态分布下,二者效率等价。对连续测量值,更适合pearson相关系数。[3]判定系数r²
#-*- coding: utf-8 -*-
#餐饮销量数据相关性分析
#from __future__ import print_function
import pandas as pd
catering_sale = '../data/catering_sale_all.xls' #餐饮数据,含有其他属性
data = pd.read_excel(catering_sale, index_col = u'日期') #读取数据,指定“日期”列为索引列
data.corr() #相关系数矩阵,即给出了任意两款菜式之间的相关系数
print data.corr()[u'百合酱蒸凤爪'] #只显示“百合酱蒸凤爪”与其他菜式的相关系数
data[u'百合酱蒸凤爪'].corr(data[u'翡翠蒸香茜饺']) #计算“百合酱蒸凤爪”与“翡翠蒸香茜饺”的相关系数
#output:
#百合酱蒸凤爪 1.000000
#翡翠蒸香茜饺 0.009206
#金银蒜汁蒸排骨 0.016799
#乐膳真味鸡 0.455638
#蜜汁焗餐包 0.098085
#生炒菜心 0.308496
#铁板酸菜豆腐 0.204898
#香煎韭菜饺 0.127448
#香煎罗卜糕 -0.090276
#原汁原味菜心 0.428316
#Name: 百合酱蒸凤爪, dtype: float643.主要函数
主要是Pandas用于数据分析和Matplotlib用于数据可视化
Pandas主要统计特征函数
sum 总和(按列)
mean 算数平均值
var 方差
std 标准差
corr Spearman/Pearson相关系数矩阵
cov 协方差矩阵
skew 偏度(三阶矩)
kurt 峰度(四阶矩)
describe 基本描述
cumsum 依次给出前1-n个数的和
cumprod 依次给出前1-n个数的积
cummax 。。。最大值
cummin 。。。最小值
rolling_sum(D,n)、rolling_mean。。。。D中相邻n个数的计算特征
统计作图函数,基于Matplotlib
Python主要统计作图函数
plot 绘制线性二维图,折线图
pie 绘制饼图
hist 绘制二维条形直方图
boxplot 绘制箱型图 Pandas
plot(logy=True) 绘制y轴的对数图形 Pandas
plot(yerr=error) 绘制误差条形图 Pandas















 4093
4093

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









