









update:
【CUDA 博客】TMA简介 & 让矩阵转置在Hopper GPUs上变得更快
很难写一个kernel就能同时在transpose的所有场景都最优,归纳transpose的几种常见场景可以针对性优化。这里只列出了transpose对轴变换的几种情况,没有考虑shape大小。因此在这几种场景上还应该考虑转置的轴 shape大小针对性优化。
场景1: batch 2D,perm:021
二维,三维,或者更高维的tensor,交换最内层的两个维度。这些都可以统一为batch 2D。对于2D矩阵的转置相当于batch=1,大于三维的tensor可以把两个最内层维度以外的所有维度合并看成一个维度。
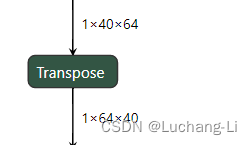
在GPU的实现中,一个重要的优化点是实现输入和输出的合并内存访问。可以每个线程读取4x4的数据块,基于寄存器进行转置,或者一个warp的线程基于shared memory,协作读取更大的一个数据块,基于shared memory和寄存器转置,这样能同时实现线程间数据读取和写回的合并内存访问。
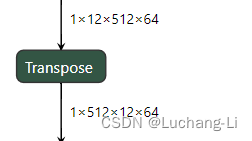
场景2:0213
其特点是内部的两个相邻的维度进行交互,不包含最内层的一个或多个维度。跟上面一样,相邻不交换的维度可以合并看成一个整体,最外层的维度不足可以补1。
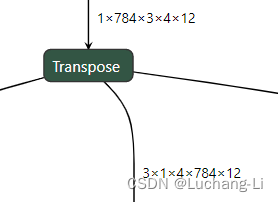
下面这个场景perm=[2, 0, 3, 1, 4],看上去同时转置了多个axes,但是由于shape元素1的特殊性,可以squeeze掉, 因此可以转换为[784, 3, 4, 12]到[3, 4, 784, 12]的transpose,可以使用0213的方法来解决。
删除transpose shape为1的算法
perm = [2, 0, 3, 1, 4]
in_shape = [1, 784, 1, 4, 12]
rm_axes = []
for idx, elem in enumerate(in_shape):
if elem == 1:
rm_axes.append(idx)
print("rm_axes:", rm_axes)
def remove_axis(in_shape, perm, rm_axis):
del in_shape[rm_axis]
perm_rm_idx = -1
for idx, elem in enumerate(perm):
if elem == rm_axis:
perm_rm_idx = idx
if elem > rm_axis:
perm[idx] = perm[idx]-1
del perm[perm_rm_idx]
for rm_axis in reversed(rm_axes):
remove_axis(in_shape, perm, rm_axis)
print("perm:", perm)
print("in_shape:", in_shape)场景3:交换两个相邻的axes,但是其中一个axis对应的shape是1
这个场景并不需要transpose,只需要reshape即可。

使用上面的删除transpose shape为1的算法后,这种transpose的perm会变成[0,1,2,3,...] 可以非常简单的判断这个transpose实际上不需要进行任何操作,直接删除即可。
场景4:交换多个axes,但是部分perm是相邻的
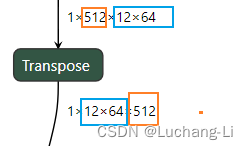
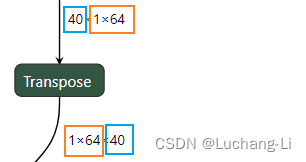
这里perm=[1, 2, 0], 看上去交换了3个axes,实际上1x64这两个是一起交换的,可以合并成一个维度,这个问题就变成了上面的场景1。因此解决方案可以是合并一起变换的相邻轴,从而把问题简化。
场景5:transpose用作depth2space或space2depth
进行针对性替换往往有更好的性能。
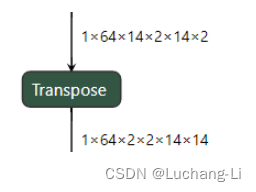
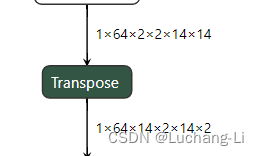
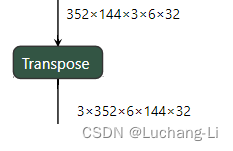
场景6:其他
当然还有少量场景无法使用上面的方法来解决,例如这里输入shape第一个维度不是1的情况。
合并transpose相邻的perm从而降低transpose的维度
如前面所述,transpose可以转换为reshape+transpose+reshape,转换后的transpose通过合并相邻的perm从而降低transpose的维度。例如原始perm=[2, 0, 1] shape=[2,2,2]的transpose可以转换为[1,0], shape=[4, 2]的transpose,参考代码如下:
def get_shape_elem(shape):
elem_num = 1
for elem in shape:
elem_num *= elem
return elem_num
perm = [0, 1, 3, 2, 4, 5]
in_shape = [1, 22, 12, 16, 12, 192]
perm_groups = []
concec_perm = []
last_perm = -10
for elem in perm:
if elem == last_perm + 1:
concec_perm.append(elem)
else:
if concec_perm:
perm_groups.append(concec_perm)
concec_perm = [elem]
last_perm = elem
if concec_perm:
perm_groups.append(concec_perm)
min_perms = [concec_perm[0] for concec_perm in perm_groups]
min_perms_sorted = sorted(min_perms)
new_perms_map = dict(zip(min_perms_sorted, list(range(len(min_perms_sorted)))))
new_perms = [new_perms_map[axis] for axis in min_perms]
min_perm_2_perm_groups=dict(zip(min_perms, perm_groups))
new_shape = []
for min_perm in min_perms_sorted:
concec_perm = min_perm_2_perm_groups[min_perm]
perm_shape = [in_shape[axis] for axis in concec_perm]
new_shape.append(get_shape_elem(perm_shape))
print("old perm:", perm)
print("old shape:", in_shape)
print("new perm:", new_perms)
print("new shape:", new_shape)
更加复杂的情况,也可以考虑把一个transpose拆分为多个reshape+transpose来降低每个transpose的维度。


















 1321
1321

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











