










24年4月UT Austin的论文“Pre-training Small Base LMs with Fewer Tokens”。
主要研究从现有的大型基础语言模型 (LM) 开始开发小型基础语言模型 (LM):首先从较大的 LM 继承一些Transformer块,然后在较大模型的原始预训练数据中一个非常小的子集 (0.1%) 上训练这个较小的模型。将这个简单的措施称为 Inheritune,并首先演示它如何用 1B 个tokens构建具有 1.5B 参数的小型基础 LM(以及3B 参数的较大 LM 起始几层);用单个 A6000 GPU 不到半天的时间完成此操作。在 9 个不同的评估数据集以及 MMLU 基准中,生成的模型与 1B-2B 大小的公开基础模型相比毫不逊色,其中一些模型使用 50-1000 倍以上的tokens进行训练。
在略微不同的环境中研究 Inheritune,在该环境中,用较大的 LM 及其完整的预训练数据集来训练小型 LM。小型 LM,利用 GPT2-medium(355M)和 GPT-2-large(770M)的一些层训练,其损失可以有效地匹配那些较大LM,其在 9B tokens 的 OpenWebText 数据集上从头开始训练相同的训练步骤步数。

代码开源在 https://github.com/sanyalsunny111/LLM-Inheritune。
Inheritune
设置。假设存在一个预训练的参考模型 Mref ,包含 k 层,用 Dtrain 训练,表示为 θref = {θ0, θ1, . . . , θk−1},但是这个完整的训练数据不可用,只有一个非常小的子集 D^train。此外,假设分布保持不变,使得 D^train ∼ Dtrain。没有特别选择高质量的子集,而 D^train 只是 Dtrain 所有域的一个随机子集。
步骤 1:继承 Mref 的前 n 层。用 Mref 的前 n 层初始化目标模型 Mtgt;因此 Mtgt 的权重为 {θ0, θ1, . . . , θn−1}。预测头和tokens嵌入也继承自 Mref。
步骤 2:在可用训练数据 D^train 上训练 Mtgt 给定的 E 个时期。
如下图是Inheritune的算法概要:

用 Inheritune 在低数据环境下开发小型基础 LM
数据。用 Redpajama v1 数据集 (Computer, 2023) 的 1B 子集,该子集最初包含来自 7 个不同域的 1T tokens,即 common crawl、c4、wikipedia、books、arxiv papers、github 和 stack exchange。按照(Touvron 2023a)在 LLaMA 中建议的比例组合数据集,这也是用于预训练参考 LM 的比例集合:OpenLLAMA-3B。因此,预训练数据构成了 OpenLLAMA-3B 训练数据集中随机选择的 0.1% 子集。接下来进行扩展评估以分析 Inheritune 的性能,同时用相同数据的更大比例,从 Redpajama v1 数据集中随机抽样 50B 子集(即 5% 子集)。
模型和训练。用 OpenLLaMA-3B v1(Geng & Liu,2023)作为主要结果与 Inheritune 配方功效的参考模型。该模型有 k = 26 层;报告取 n = 13 的结果比较。也就是说,用 Inheritune 得出的模型有 13 个 transformer 块,训练 8 个 epochs(每个 epoch 用所有 1B tokens),批次大小为每批次 131K 个 tokens。用 litGPT 框架(AI,2023)来训练本文的所有小型基础 LM。为了对结果进行更深入的评估,还采用了更大的参考 LM,即 LLaMA2-7B(Touvron,2023b)和 OpenLLaMA-7B v1(Geng & Liu,2023)。
基线模型。下表描述要比较的模型;它们都是公开可用的检查点,大小与本文1.5B 派生模型相似,遵循相关的先前方法(Java-heripi,2023;Xia,2023;Li,2023;Zhang & Lu,2023)。然而,它们在预训练方式上存在一些差异。
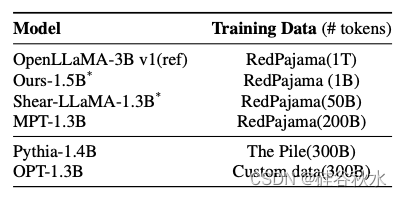
用预训练数据作为选择基线模型的关键标准。根据参数量和预训练数据(即 Redpajama)预先选择公开可用的基线模型。因为预训练数据的质量在模型开发中起着关键作用。为了公平比较,选择使用 Redpajama 训练的 MPT-1.3B、Sheared LLaMA 1.3B。
接下来,还包括模型 OPT-1.3B(Zhang,2022)和 Pythia-1.3B(Biderman,2023),因为这些模型用已知与 Redpajama 接近的数据集进行预训练。Sheared LLaMA-1.3B 用 0.4B tokens进行有针对性的结构修剪并使用 50B 数据进行持续预训练而开发。采用训练的修剪已被证明对整体泛化有一些额外的好处(Jin,2022)。因此,直接将剪枝和持续训练方法与本文配方进行比较有点不公平,该配方可以更好地归类为模型初始化技术。然而,Shearing & Inheritune 都是使用现有模型开始训练的,因此无论如何都会进行比较,同时将其视为单独讨论的特殊情况。
评估。在本研究中,在多个不同的下游任务中使用少样本准确率,特别是 0 样本和 5 样本准确率来衡量基础 LM 的质量。这是评估预训练 LLM 的标准做法,在之前的几项工作中已经做过(Brown,2020;Touvron,2023a;Javaheripi,2023;Biderman,2023)。
评估方法涵盖四个不同类型的下游任务:常识推理、自然语言理解、事实性和自然语言推理。用 5 个不同数据集上的 0 样本测试性能评估常识推理——PIQA(Bisk,2020)、BOOLQ(Clark,2019)、WINO-GRANDE(Sakaguchi,2020)、WINOGRAD(Kocijan,2020)和 LOGIQA(Liu,2020)。用大规模多任务语言理解数据集 (MMLU)(Hendrycks,2020)上的 5 样本测试性能评估语言理解。事实性是 LLM 中的一个关键关注点,用 TruthfulQA(Lin,2022)数据上的 0 样本测试性能来评估事实性。最后,用 MNLI (Bowman et al., 2015)、QNLI (Wang et al., 2018) 和 WNLI (Wang et al., 2018) 数据集上的 0 样本测试性能来评估语言推理能力。对于整个评估,用 lm eval harness 框架 (Gao et al., 2023)。
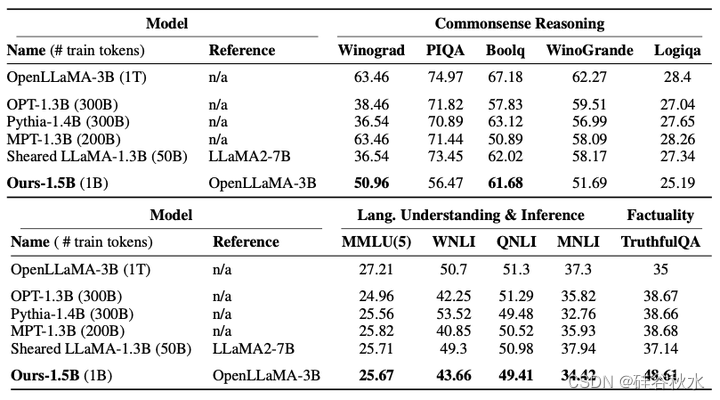
下表是用 Inheritune 得出的目标模型 (Mtgt) 与参考模型 (Mref) ,以及从头开始预训练并用继承的权重和剪枝进行预训练类似大小的其他基线模型,进行比较。本文模型虽然使用较少的tokens进行训练,但与基线模型相比,其性能相当。用粗体突出显示所有分数,其中 本文1.5B 模型与其参考 LM 相比至少获得 90% 的分数,或表现优于至少两个公开可用的基线 LM。除 MMLU 为 5 样本测试外,所有任务均使用 0 样本测试进行评估。提到模型n/a 是指从头开始训练。
Inheritune 在完整预训练数据的探索性分析
下面研究不仅拥有较大的参考基础模型 Mref ,而且拥有用于训练 Mref 整个数据集的情况。
设置
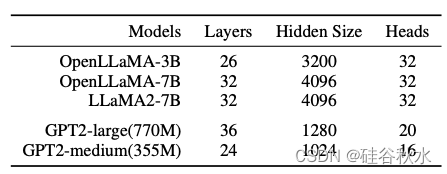
由于计算资源有限,本文各种使用了小于十亿大小的参考模型 GPT2-large 和 GPT2-medium;以及 9B tokens OpenWebText 作为数据集。下表是本文工作的参考模型及其架构配置概述。预训练的 OpenLLaMA-3B,并用由 9B tokens组成的 OpenWebText 训练所有 GPT 2 模型。
实验部分,关注 GPT-2 large;GPT-2 Medium 也遵循相同的过程。
- 首先将该数据集拆分为训练集 Dtrain 和较小的验证子集 Dval。
- 然后,在整个训练集 Dtrain 上训练完整36 层 GPT-2 large 模型一定的训练步数(T),并评估其在 Dval 上的验证损失,称为基准 val 损失。这里的验证损失是指标准的对数困惑(log-perplexity)。
- 然后,用算法 Inheritune v2,输入:作为输入的参考模型是(现已训练好的)36 层模型,较小模型的预期层数为 n = 18,数据集是完整的 Dtrain,基准损失和训练步数与上步 (2) 中用于参考模型的相同。这样得到18 层模型,评估该模型的验证损失。算法概览如下:

4. 如果步 (3) 中模型的验证损失比步 (2) 中参考模型的验证损失更差,重新执行步 (3),但现在 n 增加 2。也就是说,逐步探索继承模型的更大规模,直到验证损失与原始参考模型达到同等水平。
5. 为了进行比较,还单独训练一个随机初始化但其他方面相同的 18 层模型,训练的epochs与步(2) 和 (3) 中的模型相同。
附录:实现细节
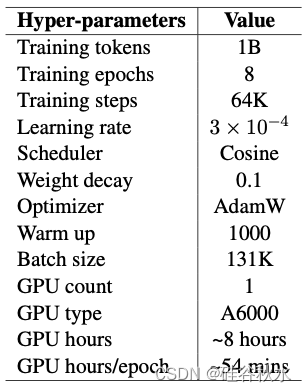
1B 数据训练小型基础 LM。用现有 OpenLLaMA v1(Geng & Liu,2023)和从 1T Redpajama v1 数据中随机抽取的 1B tokens 训练的 1.5B 模型比较。如表提供了与此模型相关的超参。值得注意的是,只使用 1 个 GPU 训练 1.5B 模型的时间不到 12 小时,这特定于用 Inheritune 和 1B 数据得出的模型。接下来,还训练多个子模型,训练细节与前面讨论的初始模型保持一致。但是,增加子模型的层数也会增加训练时间。
50B 数据训练小型基础 LM。用更大的数据子集训练1.5B 模型。值得注意的是,直到 50B 的所有中间tokens都是单次训练运行的中间检查点。下表 讨论训练运行的一些关键超参。还用 3 个不同的参考基础 LM(即 OpenLLaMA-3B、OpenLLaMA-7B 和 LLaMA2-7B)训练了三种小型基础 LM 变型。对于用 OpenLLaMA-3B 开发的目标 LM,用 n=13,即 13 层。对于7B 参数的参考 LM 开发的目标 LM,用 n=7,即 7 层。训练超参在50B 预训练数据子集训练的所有模型中保持一致。
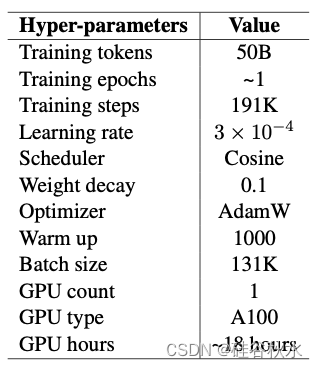
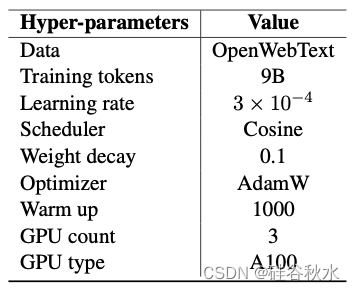
GPT 2 模型的训练。为了进行探索性分析,还训练 GPT2-medium 和 GPT2-large 模型。具有 24 层的 GPT 2-medium 模型以及具有较少层的 inheritune 变型均以每批 50K 个tokens进行训练。使用 Inheritune 开发的 GPT2-large 模型及其变型以每批 16K 个tokens进行训练。训练细节见下表。GPT 2 模型在3 个 A100 和 40 GB 内存组成的单节点上进行训练。















 7513
7513

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









