







 本文探讨了Inception v4和Inception-ResNet架构,研究了残差连接对Inception网络训练速度的提升。在保持计算量相当的情况下,残差Inception网络展现了微弱的性能优势。实验结果表明,Inception-v4和Inception-ResNet-v2在ImageNet分类任务上表现出色,通过模型集成进一步提高了准确性。
本文探讨了Inception v4和Inception-ResNet架构,研究了残差连接对Inception网络训练速度的提升。在保持计算量相当的情况下,残差Inception网络展现了微弱的性能优势。实验结果表明,Inception-v4和Inception-ResNet-v2在ImageNet分类任务上表现出色,通过模型集成进一步提高了准确性。
Inception v4, Inception-ResNet:Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
摘要: 最近几年,深度卷积神经网络对图像识别性能的巨大提升发挥着关键作用。以Inception网络为例,其以相对较低的计算代价取得出色的表现。最近,与传统结构相结合的残差连接网络在2015ILSVRC挑战赛上取得了state of art的成绩;它的性能跟最新的Inception-v3 网络非常接近。这引出一个问题:Inception架构和residual连接的结合能否带来性能的提高。在本文,我们发现残差连接显著地加速了Inception网络的训练。residual Inception网络和Inception网络的计算量相当,但性能有微弱优势。针对残差和非残差Inception网络,本文也提出了一些新的简化版本。这些变种显著提高了ILSVRC 2012分类任务的单帧识别(single-frame recognition)性能。我们进一步说明了:适当的激活缩放如何使得很宽的Residual Inception网络的训练更加稳定。本文通过三个residual和一个Inception网络的集成,在ImageNet分类比赛中取得了top-5: 3.08%的错误率。
总结:
- 本文在Inception v3的基础上,设计了v4,并且研究了Inception和Residual connection的结合。
- Inception-v4在v3的基础上,对Inception架构进行了彻底的探索。
- Inception-ResNet将Inception和ResNet结合进一步肯定了残差连接的效果
1. 简介
\quad    \; 自从AlexNet赢得了ImageNet 2012比赛后,AlexNet已经成功应用到了很多计算机视觉任务上,例如:目标检测[4],分割[10],人体姿势估计[17],视频分类[7],目标追踪[18],超分辨率[3]等。这些只不过是深度卷积网络成功案例中很少的一部分。
\quad    \; 在本文,我们研究了何凯明提出的残差连接[5]和Inception v3[15]的结合。在ResNet中,认为残差连接对非常深的架构的训练非常重要。因为Inception网络趋向于非常深,考虑用残差连接替代滤波器的连结便是很自然的事。这将在保持计算量基本不变的情况下,允许Inception充分利用残差连接的优点。
\quad    \; 除了直接的融合,我们也研究了Inception本身通过变得更深更宽能否能变得更加高效。为了实现这个目的,我们设计了一个新版本的Inception-v4,相比Inception-v3,它有更加统一简化的网络结构和更多的inception模块。回首过去,Inception-v3继承了之前的很多方法。技术性局限主要在于使用DistBelief对分布式训练进行模型分割。
\quad    \; 在本文中,我们将会比较Inception v3、v4和Inception-ResNet。这里的Inception-ResNet和Inception的参数量、计算量基本一样。但作者其实也进行了更深,更宽的Inception-ResNet实验(在ImageNet上,性能基本相似)。
\quad    \; 本文的最后一个实验对当前最高性能模型进行了集成(集成了4个模型,3个ResNet和1个Inception-v4)。可以清晰的看到,Inception-v4和Inception-ResNet-v2性能相近,都超过了当前的state of art,我们想要去探究怎样的集成更能提高准确率(on ImageNet)。意外的是,我们发现single-frame performance的提高不能转变为集成版本类似大的性能提升。尽管如此,它仍然在验证集上取得了top-5: 3.1%的准确率(刷新了记录)。
\quad    \; 在最后一节,我们研究了一些错误的分类并且得出结论,集成仍然没有达到标记的label噪声对应的准确率,所以,准确率仍有提高的空间。
2. 相关工作
\quad    \; 自从AlexNet之后,卷积网络在大型图像识别任务中越来越流行。接下来的一些重要的里程碑有:NIN、VGGNet、GoogLeNet。
\quad    \; 残差连接是由He等人提出的。在ResNet中,它以令人信服的理论和实践证据,证明了信号的加性合并的优点,在图像识别中,尤其是物体检测任务中。何凯明认为对于非常深的卷积模型的训练,残差连接是必须的。我们的发现看起来不支持这个观点(至少对于图像识别是这样)。However it might require more measurement points with deeper architectures to understand the true extent of beneficial aspects offered by residual connections。在试验部分,我们说明了没有残差连接的深度网络的训练并不难做到。但是,残差连接极大地提高了训练速度,单单这一点就值得肯定。
\quad    \; Inception深度卷积架构在GoogLeNet中提出,后来,Inception v2中引入了BN,v3引入了大尺寸filter的分解。
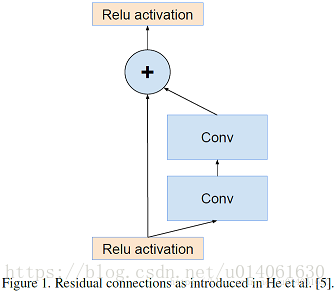
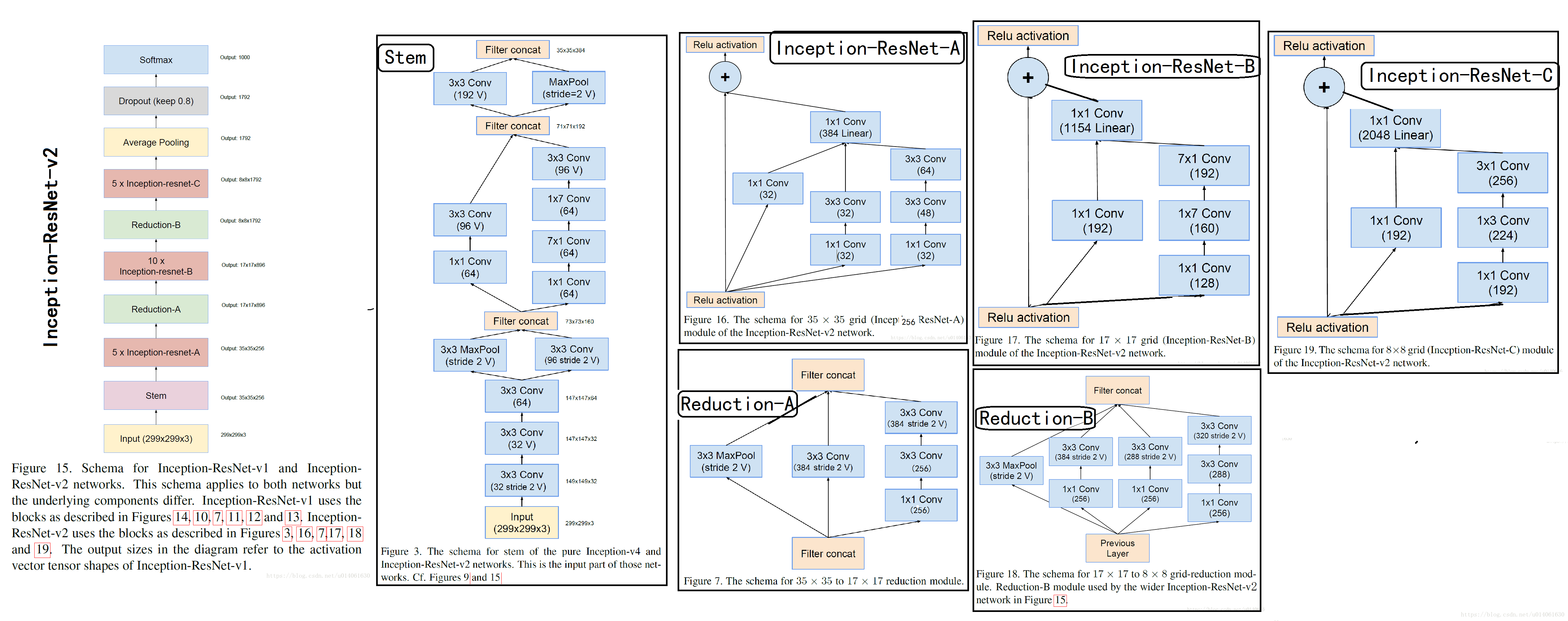
ResNet中提出的残差连接模块
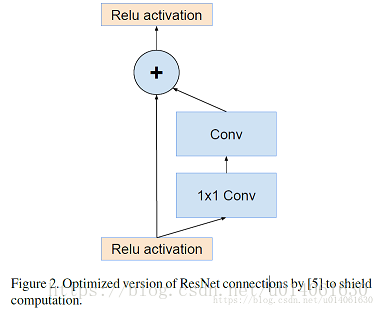
优化版ResNet模块,加入了1x1卷积。
3. 架构的选择
3.1 纯Inception模块
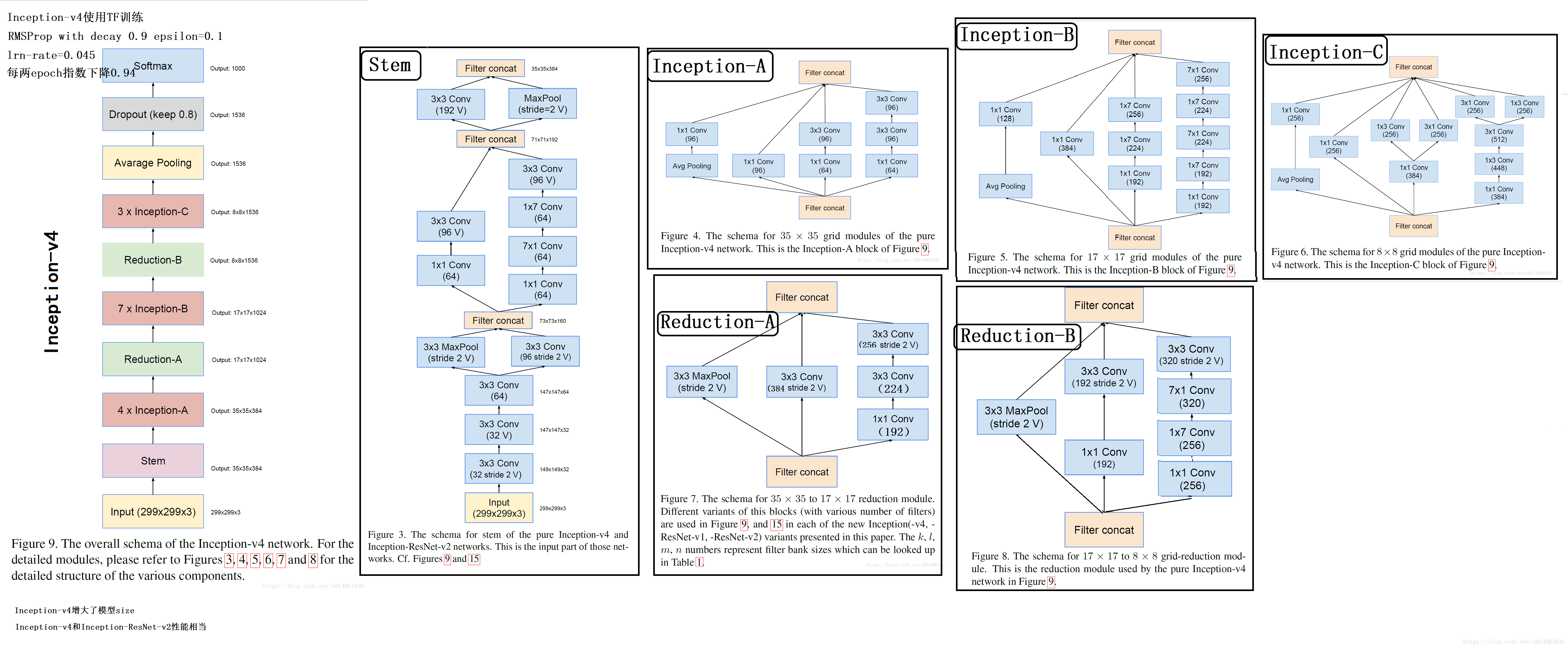
\quad    \; 以前的Inception模型通过分布式进行训练,将每个副本被划分成一个含多个子网络的模型,以满足内存需求。然而,Inception结构是高度可调的,这就意味着各层滤波器(filter)的数量可以有多种变化,而整个训练网络的质量不会受到影响。为了优化训练速度,我们对层大小进行调整以平衡不同子网络的计算。相反,随着TensorFlow的引入,大部分最新的模型无需分布式的对副本进行训练。它通过反向传播(back propagation)进行内存优化,并仔细考虑梯度计算需要的tensors,以及通过结构化计算减少这类tensors的数量。过去,我们对网络结构的更迭做得非常保守,并限制实验改变独立网络的组分,同时保持其余网络的稳定性。由于之前没有对网络进行简化,导致网络看起来更加复杂。在最新的Inception-v4实验中,我们决定去掉不必要的模块,同时统一各个grid size一样的Inception模块的参数。如图9,展示了大尺寸的Inceptionv4网络结构。图3至8是每个部分的详细结构。所有图中没有标记“V”的卷积使用same的填充原则,意即其输出网格与输入的尺寸正好匹配。使用“V”标记的卷积使用valid的填充原则,意即每个单元输入块全部包含在前几层中,同时输出激活图(output activation map)的网格尺寸也相应会减少。
\quad    \; 在过去的Inception架构(v1、v2、v3)中,作者对于结构的改变是相对保守的,并且作者为了保持网络其余部分的稳定 ,各部分的改变都很有限。复杂的前层的选择导致网络复杂度过高。在本文的实验中(Inception v4),作者将打破前面的限制,均匀改变各个grid size模组。图9是Inception v4的结构图,图3、4、5、6、7、8是每一个部件的细节图。没V的卷积采用same填充,标记V的卷积采用valid填充。
3.2 残差Inception模块(Residual Inception blocks)
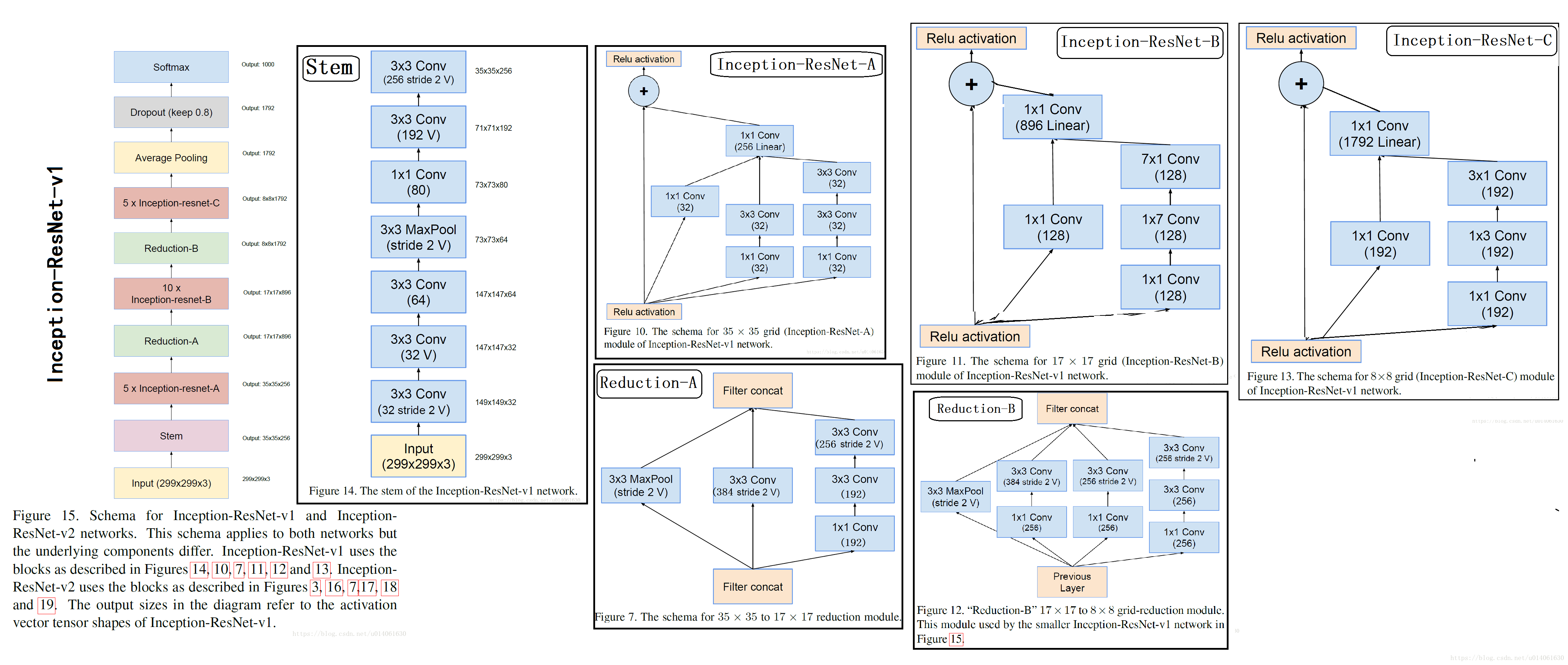
\quad    \; 在Residual-Inception网络中,我们使用比原始Inception模块计算量更低的Inception模块。每个Inception块后紧连接着滤波层(没有激活函数的1×1卷积)以进行维度变换,以实现输入的匹配。这样补偿了在Inception块中的维度降低。
\quad    \; 我们尝试了很多Inception-Residual版本。这里对其中的两个进行具体细节说明。第一个是“Inception-ResNet-v1”,计算量跟Inception-v3大致相同,第二个“Inception-ResNet-v2”的计算量跟Inception-v4网络基本相同。图15是Residual-Inception的架构图。(但是,实验中Inception-v4单个step的时间更慢,这可能是因为有了更多的层)。
\quad    \; 残差和非残差Inception的另外一个小技术性区别是,在Inception-ResNet网络中,我们只在传统层上使用BN。在全部层使用 batch-normalization是合情合理的,但是我们想保持每个模型副本在单个GPU上就可以训练。结果证明,使用更大的activation尺寸消耗更多的GPU内存。省略这些activation后的BN层,我们能够增加更多的Inception模块。我们希望可以更好的利用计算量,因而这种trade-off变得没有必要。
3.3 残差模块的缩放(Scaling of the Residuals)
\quad    \; 我们也发现,如果filter的数量超过1000,残差网络开始出现不稳定,同时网络会在训练过程早期便会出现“死亡”,即经过几万次训练后,平均池化层(average pooling) 之前的层开始只生成0。降低学习率、增加额外的BN层都无法避免这种状况。
\quad    \; 我们发现,在将残差加到前层的activation之前,对本层的activation进行放缩能够稳定训练。通常,我们将残差放缩因子定在0.1到0.3之间去缩放residuals。(如图20)

\quad
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 729
729

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









