







下面介绍了在pytorch中如何进行梯度运算,并介绍了在运行梯度计算时遇到的问题,通过解决一个个问题,来深入理解梯度计算。
梯度计算
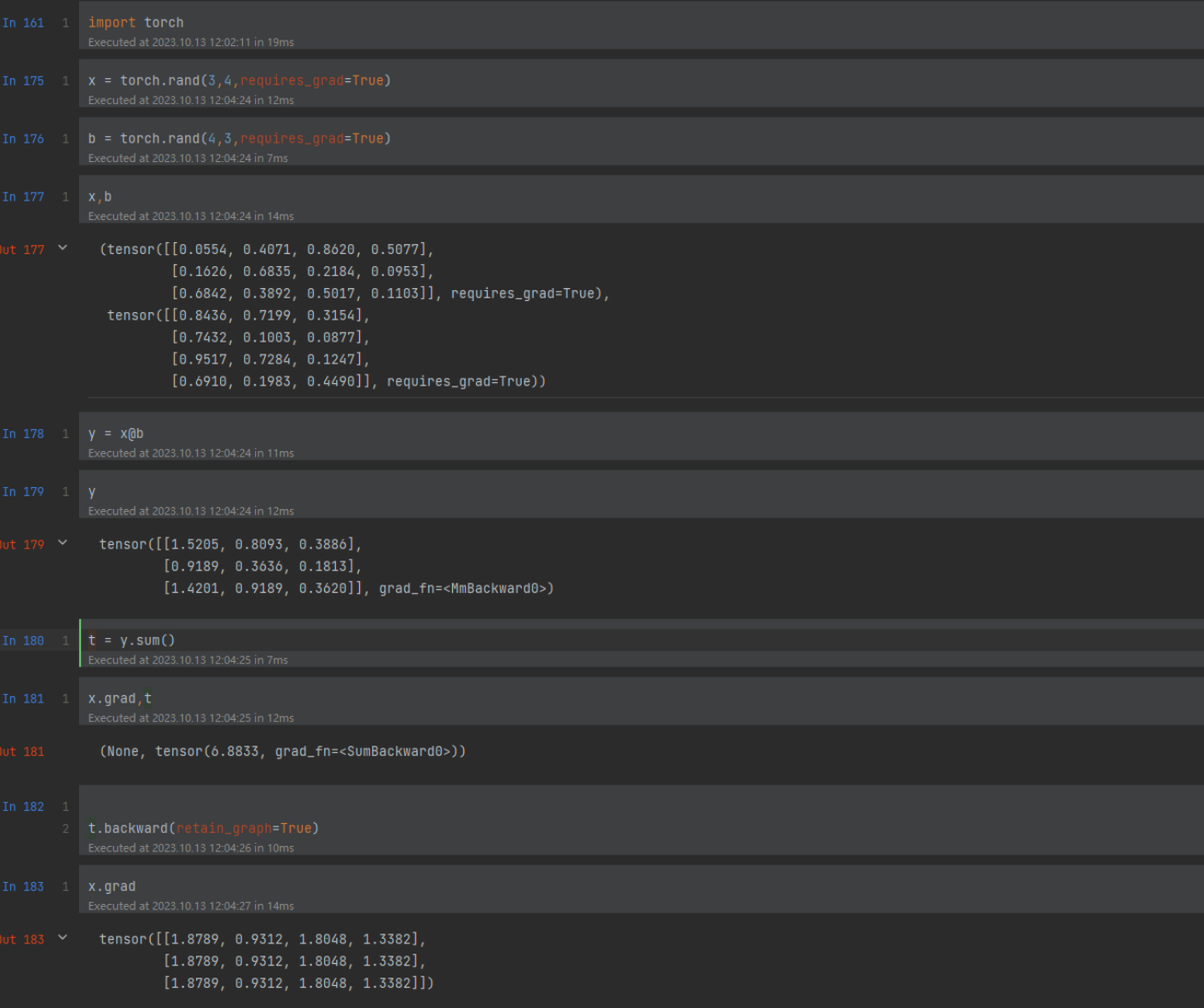
import torch
x = torch.rand(3,4,requires_grad=True)
b = torch.rand(4,3,requires_grad=True)
print(x,b)
y = x@b
t = y.sum()
求导数
t.backward()
x.grad
问题1:
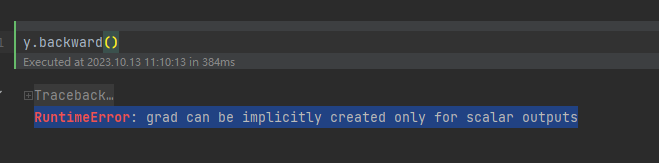
让y运行backward方法
y.backward()
会报错
RuntimeError: grad can be implicitly created only for scalar outputs
为什么会这样呢?
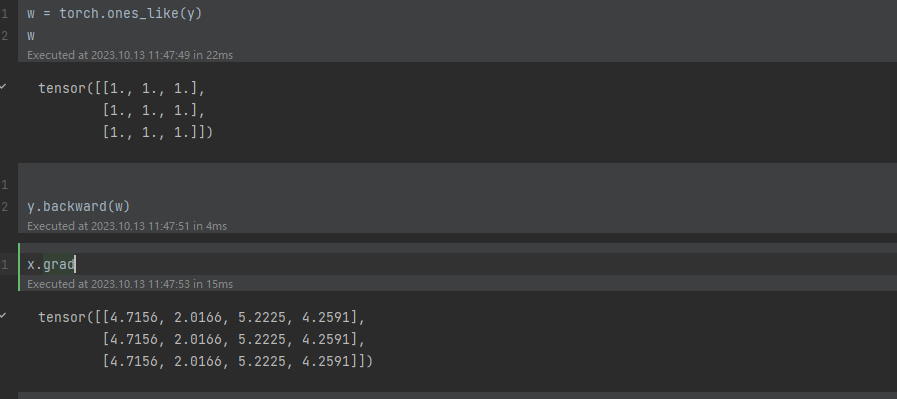
因为y为是多维张量,在pytorch中不允许张量对张量求导,只允许标量对张量求导。正如上面粒子,x为3x4矩阵,b为4x3矩阵,x与b矩阵相乘,得到3x3的矩阵y,如果对y求导,那么x的导数该怎么求呢,x为3x4矩阵,而y为3x3。这是简单例子,如果到更高维度又该如何,干脆不允许多维张量求导。那么该怎么对y求导,定义一个与y同维度的张量w,再运行y.backward(w)那么便可以。而y.backward(w)函数是如何做的呢?先计算L = torch.sum(y * w),而L为标量,然后再用L对自变量x求导。
问题2:
在运行y.backward(w)时,遇到了这个问题
Trying to backward through the graph a second time (or directly access saved tensors after they have already been freed). Saved intermediate values of the graph are freed when you call .backward() or autograd.grad(). Specify retain_graph=True if you need to backward through the graph a second time or if you need to access saved tensors after calling backward.
原因:
为了减少内存使用,在.backward()调用过程中,所有中间结果在不再需要时都会被删除。因此,如果您尝试再次调用.backward(),中间结果不存在,并且无法执行向后传递(并且您会收到您所看到的错误)。
您可以调用.backward(retain_graph=True)进行向后传递,这不会删除中间结果,因此您将能够.backward()再次调用。除了最后一次向后调用之外的所有调用都应该有这个retain_graph=True选项。
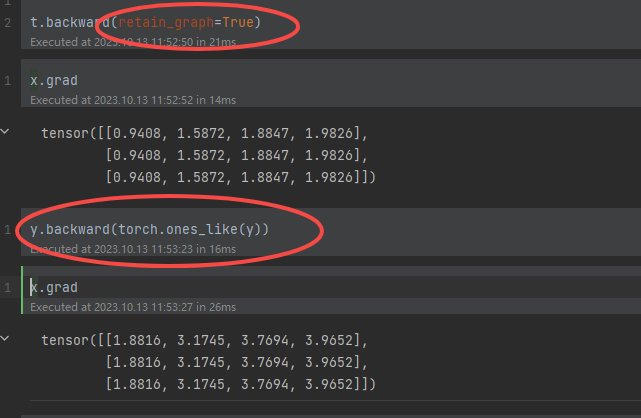
所以我们在第一次调用backward加入retain_graph=True
t.backward(retain_graph=True)
问题3:
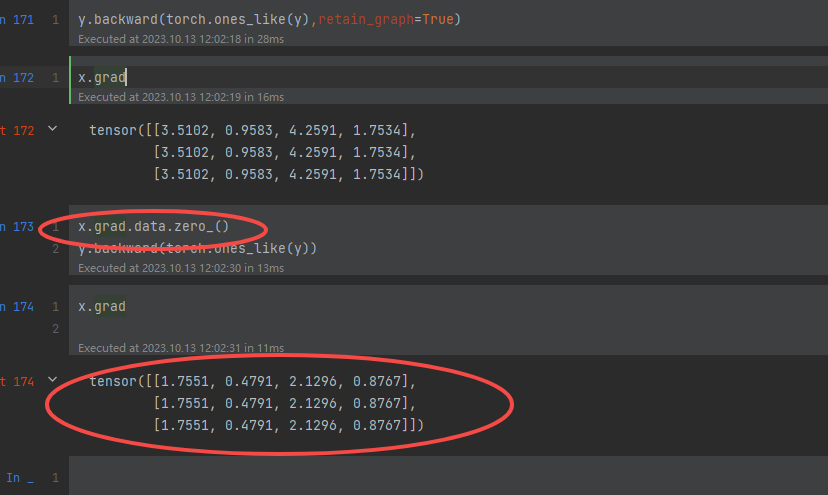
当我们运行时,梯度是累加的,如何清空之前的累加呢?用下面方法
x.grad.data.zero_()

















 341
341

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











