







爬山算法 ( Hill Climbing )
介绍模拟退火前,先介绍爬山算法。爬山算法是一种简单的贪心搜索算法,该算法 每次从当前解的临近解空间中选择一个最优解作为当前解,直到达到一个局部最优解 。
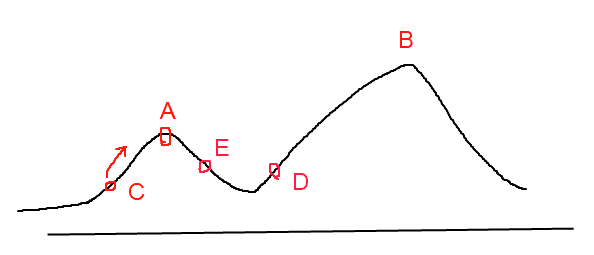
爬山算法实现很简单,其主要缺点是会陷入局部最优解 ,而不一定能搜索到全局最优解。如图1所示:假设C点为当前解,爬山算法搜索到A点这个局部最优解就会停止搜索,因为在A点无论向那个方向小幅度移动都不能得到更优的解。
模拟退火算法(SA)
退火的概念
在热力学上,退火(annealing)现象指物体逐渐降温的物理现象,温度愈低,物体的能量状态会低;够低后,液体开始冷凝与结晶,在结晶状态时,系统的能量状态最低。大自然在缓慢降温(亦即,退火)时,可“找到”最低能量状态:结晶。但是,如果过程过急过快,快速降温(亦称「淬炼」,quenching)时,会导致不是最低能态的非晶形。
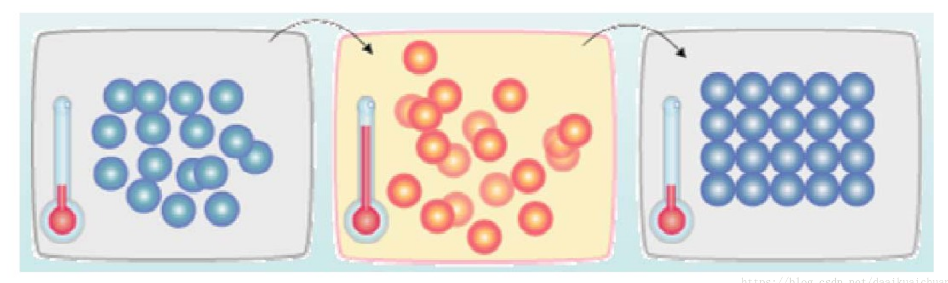
如下图所示,首先(左图)物体处于非晶体状态。我们将固体加温至充分高(中图),再让其徐徐冷却,也就退火(右图)。加温时,固体内部粒子随温升变为无序状,内能增大,而徐徐冷却时粒子渐趋有序,在每个温度都达到平衡态,最后在常温时达到基态,内能减为最小(此时物体以晶体形态呈现)。
似乎,大自然知道慢工出细活:缓缓降温,使得物体分子在每一温度时,能够有足够时间找到安顿位置,则逐渐地,到最后可得到最低能态,系统最安稳。
模拟退火的概念
想象一下如果我们现在有下面这样一个函数,现在想求函数的(全局)最优解。如果采用Greedy策略,那么从A点开始试探,如果函数值继续减少,那么试探过程就会继续。而当到达点B时,显然我们的探求过程就结束了(因为无论朝哪个方向努力,结果只会越来越大)。最终我们只能找打一个局部最后解B。
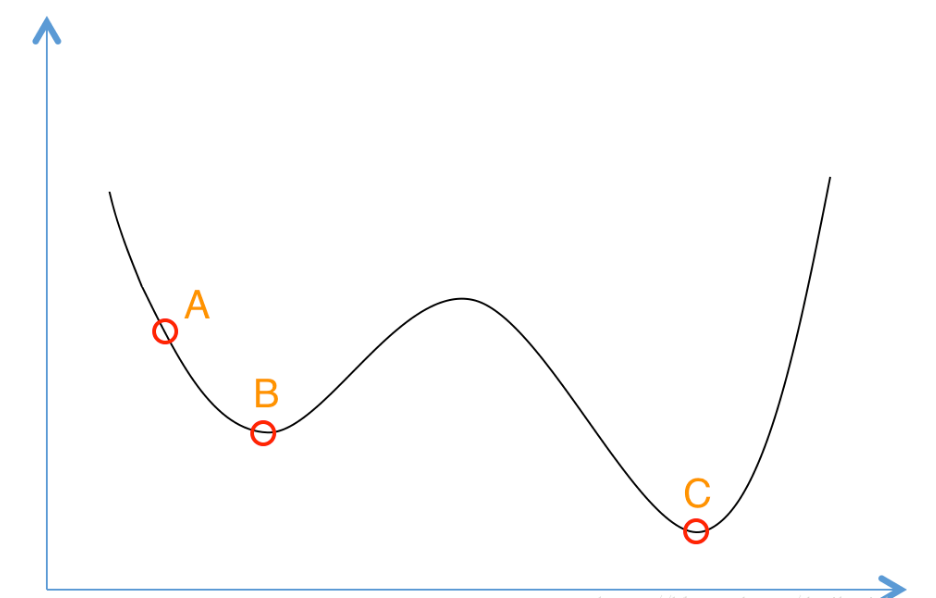
模拟退火其实也是一种Greedy算法,但是它的搜索过程引入了随机因素。模拟退火算法以一定的概率来接受一个比当前解要差的解,因此有可能会跳出这个局部的最优解,达到全局的最优解。 以上图为例,模拟退火算法在搜索到局部最优解B后,会以一定的概率接受向右继续移动。也许经过几次这样的不是局部最优的移动后会到达B 和C之间的峰点,于是就跳出了局部最小值B。
- 若f( Y(i+1) ) <= f( Y(i) ) (即移动后得到更优解),则总是接受该移动;
- 若f( Y(i+1) ) > f( Y(i) ) (即移动后的解比当前解要差),则以一定的概率 接受移动,而且这个概率随着时间推移逐渐降低 (逐渐降低才能趋向稳定)相当于上图中,从B移向BC之间的小波峰时,每次右移(即接受一个更糟糕值)的概率在逐渐降低。如果这个坡特别长,那么很有可能最终我们并不会翻过这个坡。如果它不太长,这很有可能会翻过它,这取决于衰减 t 值的设定。
模拟退火的步骤
-
初始化温度T,初始解状态S,每个温度t下的迭代次数L;
-
当k = 1,2,……,L时,进行3~6;
-
对当前解进行变换得到新解S’(例如对某些解中的元素进行互换,置换);
-
计算增量Δt′=C(S′)-C(S),其中C(S)为评价函数;
-
若Δt′<0则接受S′作为新的当前解,否则以概率exp(-Δt′/(KT))接受S′作为新的当前解(k为玻尔兹曼常数,数值为:K=1.3806505(24) × 10^-23 J/K);
-
如果满足终止条件则输出当前解作为最优解,结束程序;
-
减小T,转到第2步,直到T小于初始设定的阈值。
模拟退火的优缺点
- 迭代搜索效率高,并且可以并行化;
- 算法中有一定概率接受比当前解较差的解,因此一定程度上可以跳出局部最优;
- 算法求得的解与初始解状态S无关,因此有一定的鲁棒性;
- 具有渐近收敛性,已在理论上被证明是一种以概率l 收敛于全局最优解的全局优化算法。
代码实现
import numpy as np
import matplotlib.pyplot as plt
import math
# 绘图
# 定义函数表达式
# define aim function
def aimFunction(x):
y = x ** 3 + 3 * x ** 2 - 6
return y
x = [i / 10 for i in range(-1000, 1000)] # 定义域为[-100,100]
y = [0.0 for i in range(-1000, 1000)]
for i in range(2000):
y[i] = aimFunction(x[i])
plt.plot(x, y)
plt.show()
# 求最值
T = 1000 # 初始温度initiate temperature
Tmin = 10 # 终止温度
x = np.random.uniform(low=-100, high=100) # 当前状态
k = 50 # 每次温度下的循环次数
y = 0 # 评估函数
t = 0 # 用于控制降温的快慢
while T >= Tmin:
for i in range(k):
# 计算y
y = aimFunction(x)
# 产生新解
xNew = x + np.random.uniform(low=-0.055, high=0.055) * T
if (-100 <= xNew and xNew <= 100):
yNew = aimFunction(xNew)
if yNew - y > 0: # 新的评估函数更大,接受新解,若求极小,改为 if yNew - y > 0:
x = xNew
else:
# metropolis 准则 得到新解或执行降温
p = math.exp((yNew - y) / T)#求极大值,若求极小,改为p = math.exp(-(yNew - y) / T)
r = np.random.uniform(low=0, high=1)
if r < p:
x = xNew
t += 1
# print(t)
# 降温退火
T = 10000 / (1 + t)
print(x, aimFunction(x))
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











