







关键词
Examination, Analysis
来源
arXiv 2016.06.09
问题
针对 CNN/Daily Mail 语料中不能使用外部知识,可能存在的指代消解错误等问题,探究一下几个问题:
- 语料中由于处理错误所产生的噪音有多少?
- 神经模型究竟学到了什么?相比于传统分类器,模型提高了哪些方面?
文章思路
本文的神经网络基于 Attentive Reader,但是又有所改进,见下图。
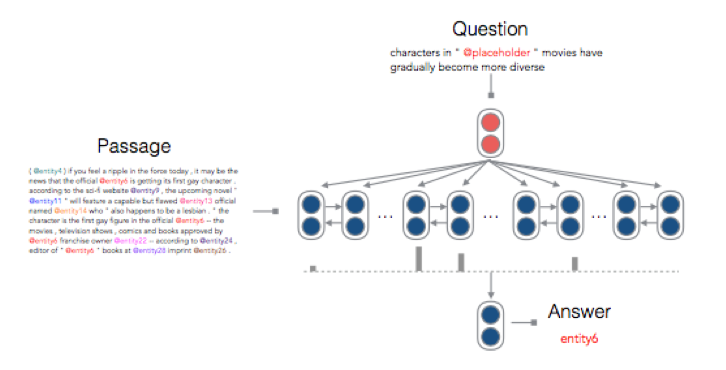
跟 Attentive Reader 相比,主要做了如下改动:
- 计算 document 和 query 之间的 attention 时,不采用 tanh,而是采用 bilinear。
- 获得 context embedding 后,直接去做预测。而不是和 query 一起再做一次非线性变换。
- 原始模型考虑文章中所有单词,现在只考虑实体。
资源
论文地址:https://arxiv.org/abs/1606.02858
代码地址:https://github.com/danqi/rc-cnn-dailymail
相关工作
以实体为中心的分类器 利用 LambdaMART 构建一个传统分类器,选取人工选定的八个特征,探究哪些特征更加有用。
Window-based MemN2Ns 文中经过试验最终认为使用 5-word window 最有效。并且这样得到 contexual embedding: Σ5i=1Ei(xi) 。对于 placeholder 同样编码,并把其他单词忽略。除此之外,还对 query 和 contextual embedding 做了点积计算相关性。
相关任务
- MCTest 数据集是以带有选择题的短片科幻小说构成,难度为 7 岁儿童阅读理解水平。这一数据集要求强大的推理能力,而数据集比较小。
- Children Book Test 包含四种问题:named entity, common noun, preposition and verb。用局部信息就能在后两个任务上取得很好的结果,但是前两种需要扫描这句话来做预测。
- bAbI 数据集包含对 20 种不同的推理能力的考察,但是这个数据词汇量太小 (100-200 词),语言变化小,和真实数据有差距。
简评
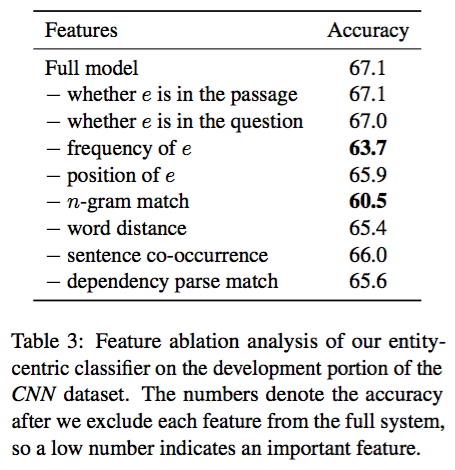
经过试验,对于基于特征的分类器来说:n-gram 和实体出现频率这两个特征最重要。具体结果见下表
然后从 CNN 开发集中随机挑选 100 个样本,人工分析,结果如下
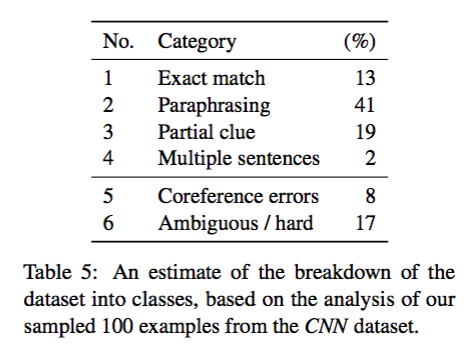
其中第 5、6 两种是不能够处理的类别,也就是噪声,可以看出在样本中只有 75% 可以处理。然后对每一类都做具体分析,结果如下
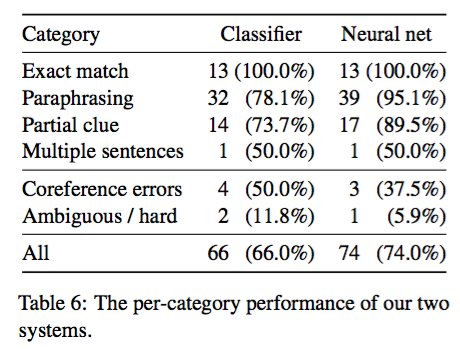
因此,神经网络相比于传统方法,在 paraphrase 和 partial clue 两类问题上有很好的提升。















 871
871

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









