









技术报告:Memory-Efficient Implementation of DenseNets
技术报告链接:https://arxiv.org/abs/1707.06990
这篇技术报告旨在改进DenseNet模型占用显存较大的问题。DenseNet是一个全新的模型,对于特征的极致利用可以提高模型的表现能力,同时由于生成大量的intermediate feature(中间特征),因此存储这些intermediate feature会占用大量的显存。为了能在GPU下跑更深的DenseNet网络,这篇文章通过对intermediate feature采用共享存储空间的方式降低了模型显存,使得在GPU显存限制下(比如单GPU的12GB显存)可以训练更深的DenseNet网络。当然这种共享部分存储的方式也引入了额外的计算时间,因为在反向传播的时候需要重新计算一些层的输出,实现表明差不多增加15%到20%的训练时间。
Figure3表示原来DenseNet的存储机制(左)和改进的DenseNet的存储机制(右)。在figure3左边图中,某个dense block的某一卷积层输入包含前面所有卷积层的输出feature maps(Figure3左上角的3个彩色方框),这些featuer map经过concate操作生成新的特征,然后经过normalization操作得到卷积的输入特征,这里concate和normalization操作生成的特征都重新开辟了存储空间。另外在有些深度学习框架中,比如Torch,反向传播过程中生成的特征也会开辟新的存储空间(如Figure3左下部分)。在figure3右边图中,通过提前分配的shared memory storage和指针将这些intermediate feature(concate和BN操作生成的特征)存储在temporary storage buffers中,可大大减少存储量。
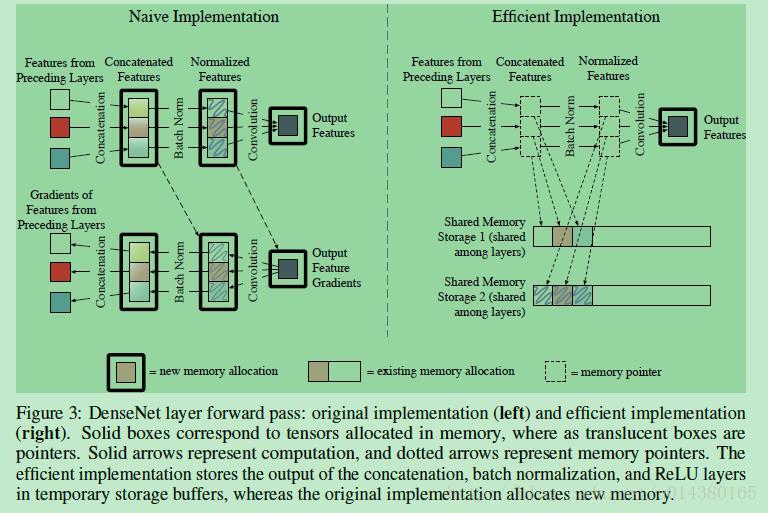
这种操作确实能够节省显存,不过同时也增加了计算时间,原因是这样的:在前向计算的时候,concate得到的特征放在暂存器中,然后BN层直接从暂存器中读取特征作为输入,这部分都没什么问题。但是当反向传播要用到concate层的输出或者BN层的输出时,就要重新计算这两层的输出(因为暂存器的内容在前向传播过程中会被不断覆盖,所以需要重新计算),这就增加了计算时间。如果是传统的做法,每个concate操作和BN操作生成的feature map都开辟新的存储空间,那么反向传播的时候就可以直接读取在前向过程中保存的特征,不需要重新生成。
在文章中作者主要在Torch和PyTorch两种深度学习框架下做对比,对比的模型包括传统的不共享存储的操作,只共享反向传播中的梯度存储,共享concate、BN、梯度等全部存储这三种模型,如Figure4所示,(因为PyTorch中自动共享梯度存储,所以蓝色线只有Torch):
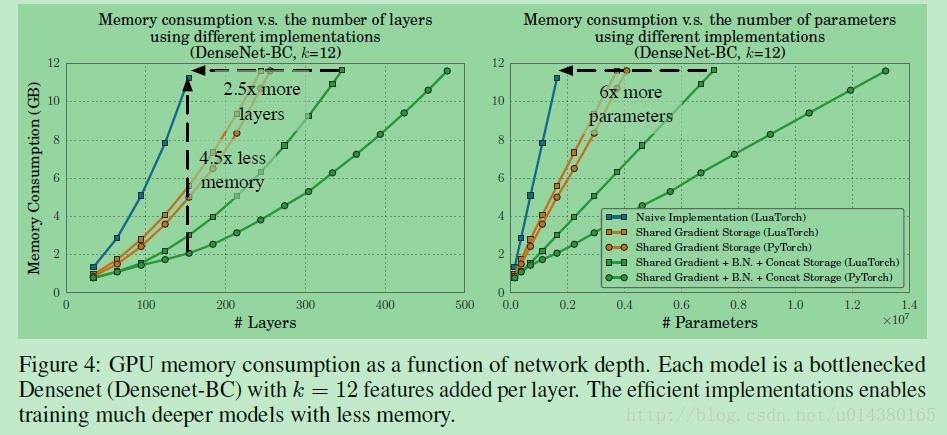
不同颜色的线表示不同的存储共享机制。PyTorch的在存储方面的效果要比Torch好,可以从Figure4看出,PyTorch可以最多训练500层的DenseNet(在12GB显存的限制下)。
作者提到这种共享存储的做法的显存占用量并不会随着网络深度的增加而线性增加,主要是因为网络参数的存储大小要远远小于feature map的存储大小。
前面说过,虽然这种共享存储的做法可以减少显存的占用,但是会在一定程度上增加计算时间,Figure5就是计算时间上的对比:可以看出时间增加并不明显。
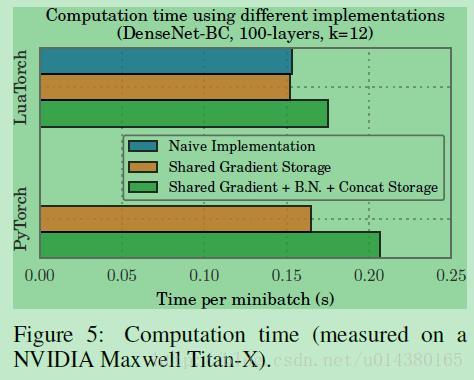
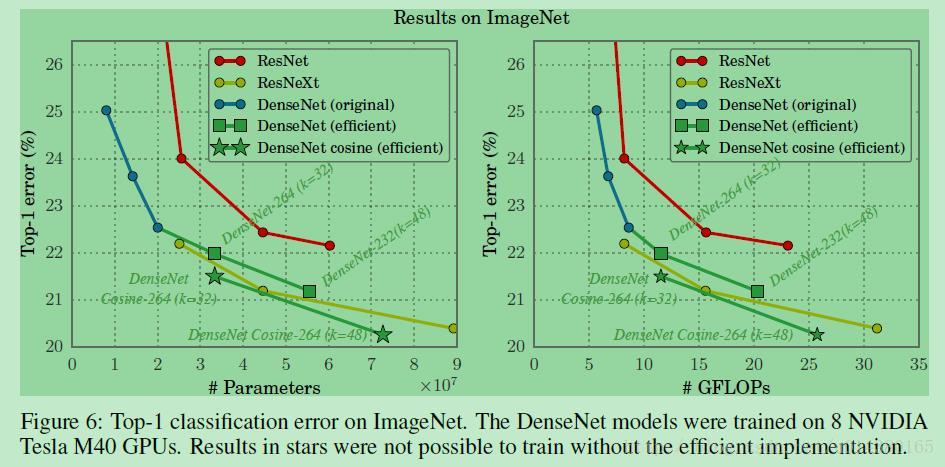
Figure6是在ImageNet数据集上的Top1 error对比。原来只能训练161层的DenseNet,现在可以训练264层,从而有更好的效果。
总的说来,作者的目的是希望能在GPU的显存限制下尽可能训练更深的DenseNet网络,因此有了这篇文章,通过共享intermediate feature的存储空间减少了显存占用,虽然一定程度上增加了计算时间,但是看你的需求了,如果你不care这些增加的时间,就可以用效果更好的模型。















 558
558

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









