







 本文深入解析YOLO模型的前向传播过程,包括convolutional层的im2col_cpu()、gemm()、batch normalization以及bias的添加。此外,还介绍了maxpool、local、dropout和connected层的工作原理。最后,重点讨论了detection layer,该层是YOLO的核心,实现目标检测功能。通过阅读,读者将全面理解YOLO的代码框架及其优缺点。
本文深入解析YOLO模型的前向传播过程,包括convolutional层的im2col_cpu()、gemm()、batch normalization以及bias的添加。此外,还介绍了maxpool、local、dropout和connected层的工作原理。最后,重点讨论了detection layer,该层是YOLO的核心,实现目标检测功能。通过阅读,读者将全面理解YOLO的代码框架及其优缺点。
本系列作者:木凌
时间:2016年11月。
文章连接:http://blog.csdn.net/u014540717
QQ交流群:554590241
一、主函数void forward_network(network net, network_state state)
//network.c
void forward_network(network net, network_state state)
{
state.workspace = net.workspace;
int i;
for(i = 0; i < net.n; ++i){
state.index = i;
layer l = net.layers[i];
//如果delta不为零,那么就把所有的输入值输入乘一个系数,用float *delta指针指向它
if(l.delta){
scal_cpu(l.outputs * l.batch, 0, l.delta, 1);
}
//从这里开始我们可以一层一层分析了,重复的层就不再分析了,顺序如下:
//[convolutional]
//[maxpool]
//[local]
//[dropout]
//[connected]
//[detection]
l.forward(l, state);
state.input = l.output;
}
}1、前向传播-convolutional层
//convolutional_layer.c
void forward_convolutional_layer(convolutional_layer l, network_state state)
{
//获取卷积层输出的长、宽
int out_h = convolutional_out_height(l);
int out_w = convolutional_out_width(l);
int i;
//初始化,将输出的数据全部赋值0
fill_cpu(l.outputs*l.batch, 0, l.output, 1);
/*
if(l.binary){
binarize_weights(l.weights, l.n, l.c*l.size*l.size, l.binary_weights);
binarize_weights2(l.weights, l.n, l.c*l.size*l.size, l.cweights, l.scales);
swap_binary(&l);
}
*/
/*
if(l.binary){
int m = l.n;
int k = l.size*l.size*l.c;
int n = out_h*out_w;
char *a = l.cweights;
float *b = state.workspace;
float *c = l.output;
for(i = 0; i < l.batch; ++i){
im2col_cpu(state.input, l.c, l.h, l.w,
l.size, l.stride, l.pad, b);
gemm_bin(m,n,k,1,a,k,b,n,c,n);
c += n*m;
state.input += l.c*l.h*l.w;
}
scale_bias(l.output, l.scales, l.batch, l.n, out_h*out_w);
add_bias(l.output, l.biases, l.batch, l.n, out_h*out_w);
activate_array(l.output, m*n*l.batch, l.activation);
return;
}
*/
if(l.xnor){
binarize_weights(l.weights, l.n, l.c*l.size*l.size, l.binary_weights);
swap_binary(&l);
binarize_cpu(state.input, l.c*l.h*l.w*l.batch, l.binary_input);
state.input = l.binary_input;
}
//m是卷积核的个数,k是每个卷积核的参数数量(l.size是卷积核的大小),n是每个输出feature map的像素个数
int m = l.n;
int k = l.size*l.size*l.c;
int n = out_h*out_w;
if (l.xnor && l.c%32 == 0 && AI2) {
forward_xnor_layer(l, state);
printf("xnor\n");
} else {
//weights顾名思义,就是卷积核的参数,`$grep -rn "l.weights"`可以看到:
//l.weights = calloc(c*n*size*size, sizeof(float))
//说白了a是指向权重的指针,b是指向工作空间指针,c是指向输出的指针
float *a = l.weights;
float *b = state.workspace;
float *c = l.output;
for(i = 0; i < l.batch; ++i){
//im2col就是image to column,就是将图像依照卷积核的大小拉伸为列向量,方便矩阵运算
im2col_cpu(state.input, l.c, l.h, l.w,
l.size, l.stride, l.pad, b);
//这个函数实现矩阵运算,也就是卷积运算
gemm(0,0,m,n,k,1,a,k,b,n,1,c,n);
c += n*m;
//更新输入
state.input += l.c*l.h*l.w;
}
}
//BN层,加速收敛
if(l.batch_normalize){
forward_batchnorm_layer(l, state);
}
//添加偏置项
add_bias(l.output, l.biases, l.batch, l.n, out_h*out_w);
//非线性变化,leaky RELU层,非常简单,不多做介绍
activate_array(l.output, m*n*l.batch, l.activation);
//不太清楚binary和xnor是什么意思,希望有了解的留言,谢谢~
if(l.binary || l.xnor) swap_binary(&l);
}函数剖析
a. im2col_cpu()
这个函数还是很重要的,我们来分析下。这个函数是从caffe中移植过来的
//im2col.c
//From Berkeley Vision's Caffe!
//https://github.com/BVLC/caffe/blob/master/LICENSE
void im2col_cpu(float* data_im,
int channels, int height, int width,
int ksize, int stride, int pad, float* data_col)
{
int c,h,w;
int height_col = (height + 2*pad - ksize) / stride + 1;
int width_col = (width + 2*pad - ksize) / stride + 1;
int channels_col = channels * ksize * ksize;
//最外层循环是每个卷积核的参数个数
for (c = 0; c < channels_col; ++c) {
int w_offset = c % ksize;
int h_offset = (c / ksize) % ksize;
int c_im = c / ksize / ksize;
//这两层循环是用卷积核把图像遍历一遍,这说起来比较晦涩,一会儿画个图来理解,很简单~
for (h = 0; h < height_col; ++h) {
for (w = 0; w < width_col; ++w) {
int im_row = h_offset + h * stride;
int im_col = w_offset + w * stride;
int col_index = (c * height_col + h) * width_col + w;
data_col[col_index] = im2col_get_pixel(data_im, height, width, channels,
im_row, im_col, c_im, pad);
}
}
}
}
float im2col_get_pixel(float *im, int height, int width, int channels,
int row, int col, int channel, int pad)
{
row -= pad;
col -= pad;
if (row < 0 || col < 0 ||
row >= height || col >= width) return 0;
return im[col + width*(row + height*channel)];
}我画了下面的图来帮助理解下im2col_cpu()这个函数,为了方便理解,这里假设图像尺寸是5*5, stride=2,kernel_size=3
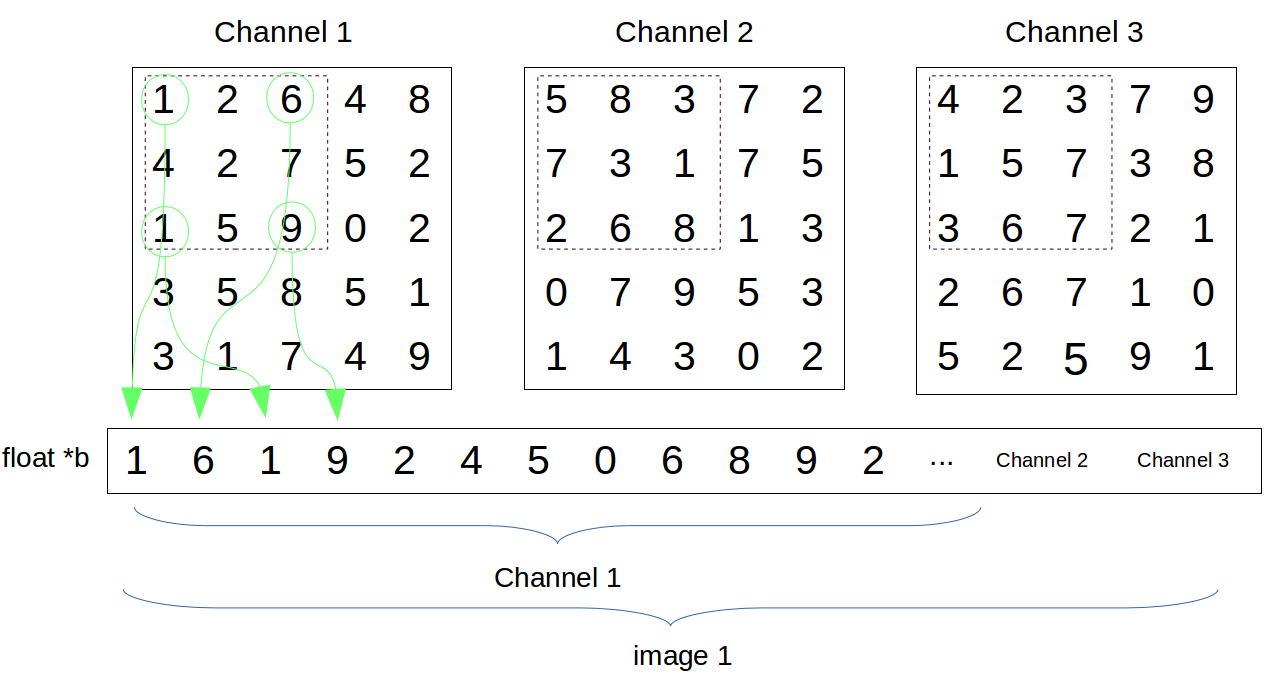
float *b指向state.workspace这个工作空间,也就是把原始数据变成行向量放到工作空间里,然后进行卷积计算
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 193
193

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









