









Multi-source Heterogeneous Domain Adaptation with Conditional Weighting Adversarial Network
![]()

[paper]
目录
Multi-source Heterogeneous Domain Adaptation with Conditional Weighting Adversarial Network
Conditional Weighting Adversarial Network
Heterogeneous Feature Transformation
Adversarial Distribution Alignment
Multi-source Conditional Weighting
Abstract
Heterogeneous domain adaptation (HDA) tackles the learning of cross-domain samples with both different probability distributions and feature representations.
Most of existing HDA studies focus on the single-source scenario. In reality, however, it is not uncommon to obtain samples from multiple heterogeneous domains.
In this paper, we study the multi-source heterogeneous domain adaptation problem, and propose a Conditional Weighting Adversarial Network (CWAN) to address it. The proposed CWAN adversarially learns a feature transformer, a label classifier, and a domain discriminator. To quantify the importance of different source domains, CWAN introduces a sophisticated conditional weighting scheme to calculate the weights of the source domains according to the conditional distribution divergence between the source and target domains. Different from existing weighting schemes, the proposed conditional weighting scheme not only weights the source domains but also implicitly aligns the conditional distributions during the optimization process. Experimental results clearly demonstrate that the proposed CWAN performs much better than several state-of-the-art methods on three real-world datasets.
第一句,背景介绍:介绍什么是 HDA,异构域适应 (HDA) 解决了具有不同概率分布和不同特征表示的跨域样本的学习问题。
第二、三句,提出问题:大多数现有的 HDA 研究集中在单一源方案上。然而,在现实中,从多个不同的领域获得样本并不少见。
第四句,本文工作:一句话概括本文干了啥,即 本文研究了多源异质域自适应问题,并提出了一种条件加权对抗网络 (CWAN) 来解决该问题。
第五-七句,算法介绍:提出的 CWAN 反向学习一个特征转换器、一个标签分类器和一个域判别器。为了量化不同源域的重要性,CWAN 引入了一种复杂的条件加权方案,根据源域和目标域之间的条件分布差异来计算源域的权重。与现有的加权方案不同,提出的条件加权方案不仅对源域进行加权,而且在优化过程中隐含地对齐条件分布。
最后一句,实验结论。
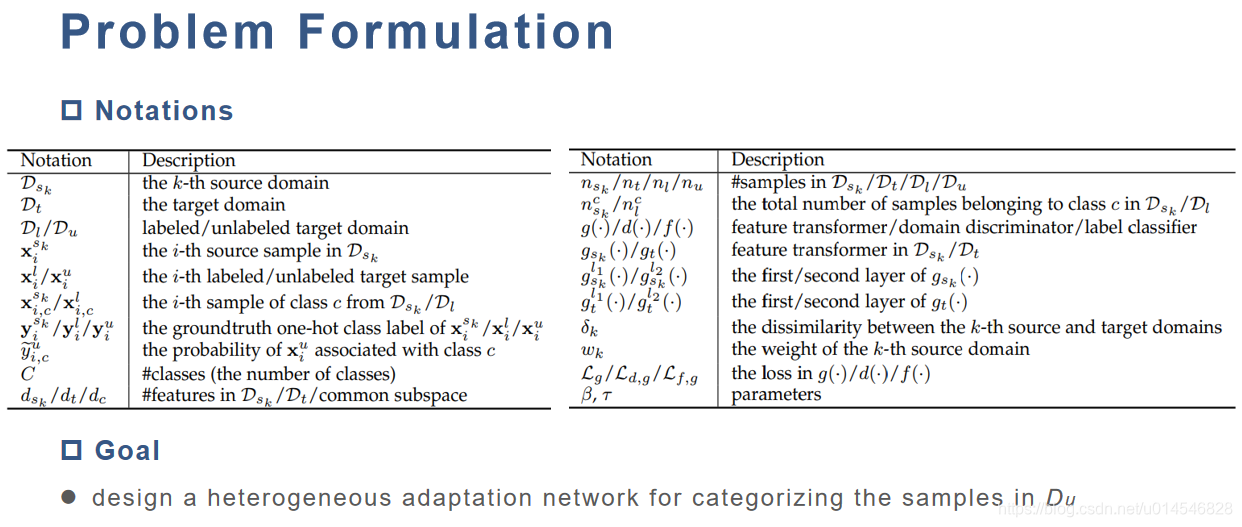
Problem Formulation
Conditional Weighting Adversarial Network
Overview

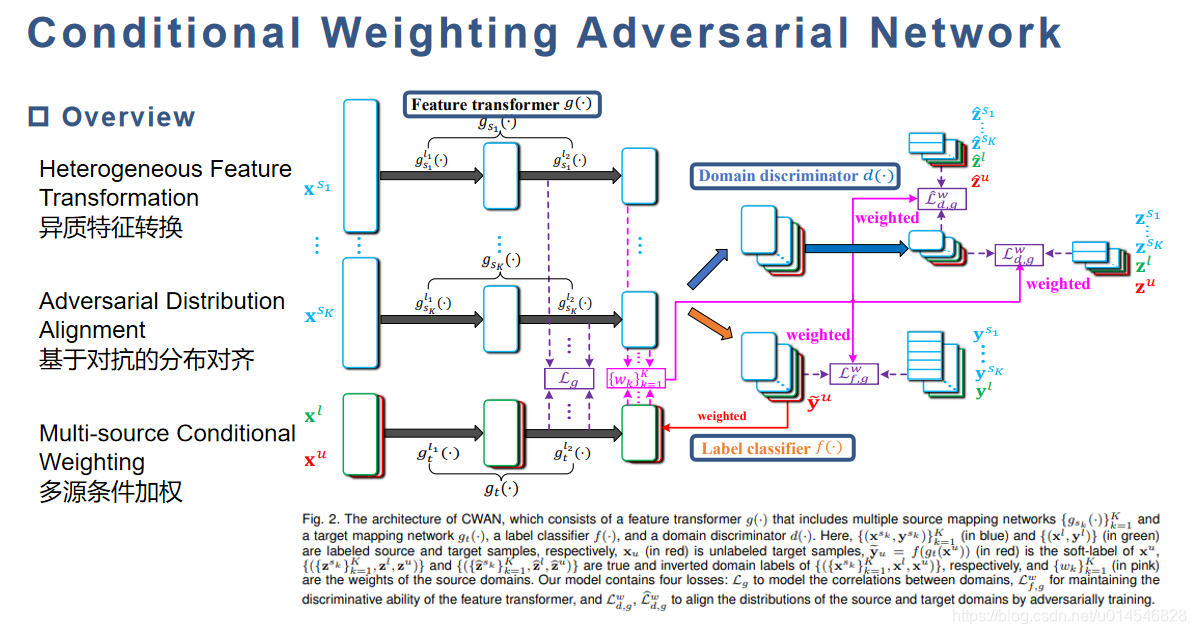
Heterogeneous Feature Transformation


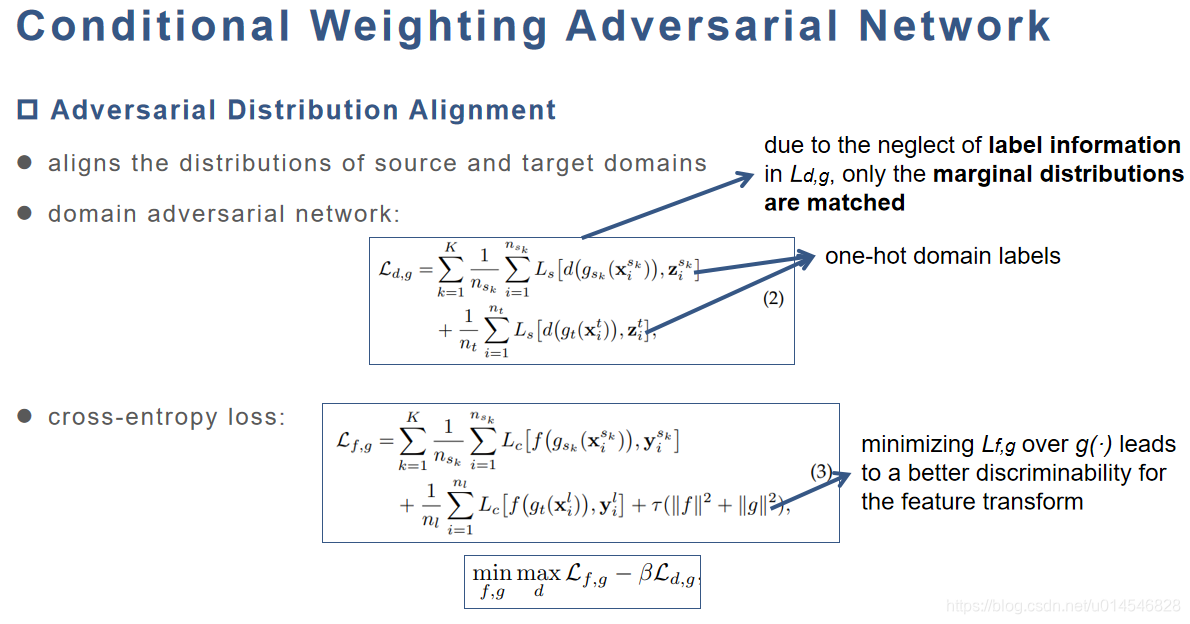
Adversarial Distribution Alignment
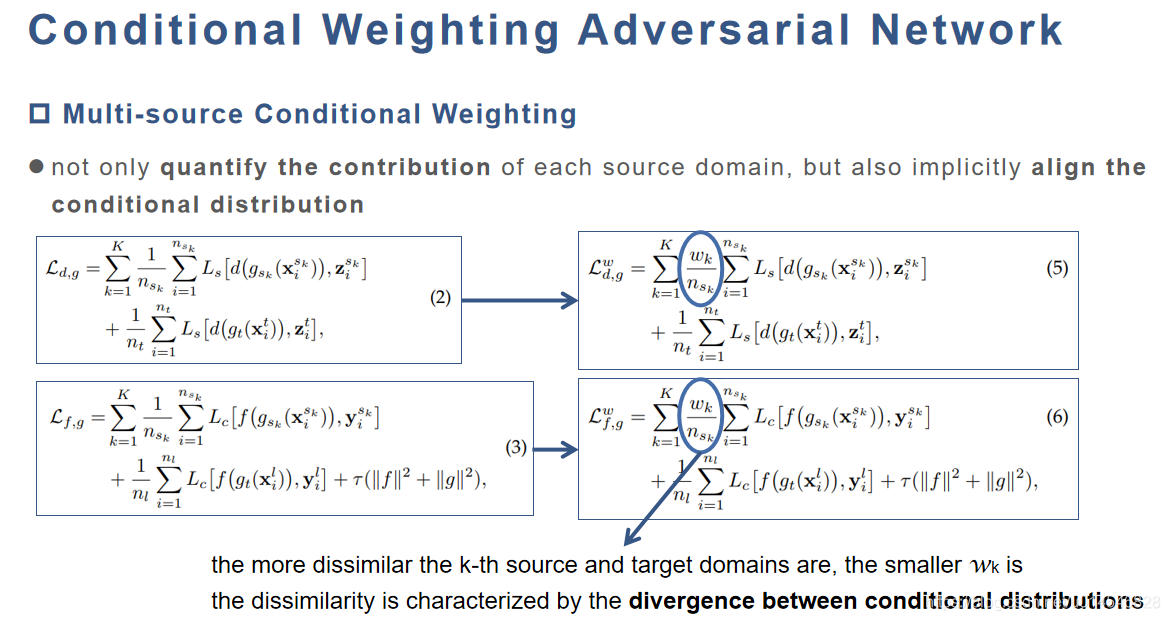
Multi-source Conditional Weighting

The Overall Objective of CWAN


















 514
514

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









