









5%>100%: Breaking Performance Shackles of Full Fine-Tuning on Visual Recognition Tasks

Abstract
Pre-training & fine-tuning can enhance the transferring efficiency and performance in visual tasks. Recent delta-tuning methods provide more options for visual classification tasks. Despite their success, existing visual delta-tuning art fails to exceed the upper limit of full fine-tuning on challenging tasks like object detection and segmentation.
To find a competitive alternative to full fine-tuning, we propose the Multi-cognitive Visual Adapter (Mona) tuning, a novel adapter-based tuning method. First, we introduce multiple vision-friendly filters into the adapter to enhance its ability to process visual signals, while previous methods mainly rely on language-friendly linear filters. Second, we add the scaled normalization layer in the adapter to regulate the distribution of input features for visual filters.
To fully demonstrate the practicality and generality of Mona, we conduct experiments on multiple representative visual tasks, including instance segmentation on COCO, semantic segmentation on ADE20K, object detection on Pascal VOC, oriented object detection on DOTA/STAR, and image classification on three common datasets.
Exciting results illustrate that Mona surpasses full fine-tuning on all these tasks, and is the only delta-tuning method outperforming full fine-tuning on the above various tasks. For example, Mona achieves 1% performance gain on the COCO dataset compared to full fine-tuning. Comprehensive results suggest that Mona-tuning is more suitable for retaining and utilizing the capabilities of pre-trained models than full fine-tuning. We will make the code publicly available.
预训练与微调可以提升视觉任务中的迁移效率和性能。最近的增量调节(delta-tuning)方法为视觉分类任务提供了更多选择。尽管这些方法取得了成功,但现有的视觉增量调节技术仍未能超越在如目标检测和分割等挑战性任务上全面微调的上限。
为了找到全面微调的一个有竞争力的替代方案,本文提出了多认知视觉适配器(Mona)调节,这是一种新颖的基于适配器的调节方法。
首先,本文在适配器中引入了多个视觉友好的滤波器,以增强其处理视觉信号的能力,而以前的方法主要依赖于语言友好的线性滤波器。
其次,本文在适配器中添加了缩放归一化层,以调节视觉滤波器输入特征的分布。
为了充分展示Mona的实用性和通用性,本文在多个具有代表性的视觉任务上进行了实验,包括在COCO上的实例分割、在ADE20K上的语义分割、在Pascal VOC上的目标检测、在DOTA/STAR上的定向目标检测,以及在三个常用数据集上的图像分类。
结果表明,Mona在所有这些任务上都超越了全面微调,并且是唯一一个在上述各种任务上表现优于全面微调的增量调节方法。例如,与全面微调相比,Mona在COCO数据集上实现了1%的性能提升。综合结果表明,与全面微调相比,Mona调节更适合保留和利用预训练模型的能力。
Introduction
预训练与微调范式能够在同模态任务之间实现令人印象深刻的迁移学习,这在计算机视觉(CV)和自然语言处理(NLP)中已经得到了证明。预训练模型通常由资源充足、经验丰富的团队使用大量干净数据进行训练。出色的预训练模型可以帮助硬件和数据受限的团队节省大量训练成本,并在新任务上训练出性能良好的深度模型。在大模型时代,调整预训练模型的效率是一个重要问题。全面微调在CV任务中已被广泛使用并取得了巨大成功,它在训练过程中调整了预训练主干网络中的所有参数以及额外的特定于任务的头部/颈部。许多令人印象深刻的CV技术通过预训练和全面微调推动了视觉任务的极限。然而,全面微调现在仍然是微调视觉任务的最佳方式吗?
除了全面微调之外,增量调节(Delta tuning)最近在NLP和CV任务中引起了关注。增量调节源自NLP,它仅调整部分主干网络或额外的轻量级结构以实现高效的迁移学习。增量调节方法通常固定大多数主干参数,并在简单任务(包括NLP中的分类任务)上实现与全面微调相当甚至更好的性能。VPT是首个探索在视觉分类任务上应用提示调节潜力的方法。LoRand率先在密集预测任务上进行适配器调节,并缩小了视觉任务上增量调节与全面微调之间的差距。然而,现有方法无法在视觉识别任务(包括语义分割和实例分割)上超越全面微调。
本文提出了Mona-tuning,这是一种基于多认知视觉适配器(Mona)的新型调节范式。本文分析了最近的技术,并总结了现有视觉适配器中的两个问题。
首先,现有CV适配器的设计遵循了NLP中的线性适配器。事实上,视觉任务处理的是视觉信号,这与语言信号截然不同,并具有独特的二维卷积操作。实验表明,基于卷积的滤波器可以更好地将从预训练模型中学到的视觉知识迁移到其他任务中,因此提出了一种实用的基于卷积的适配器用于视觉任务。
其次,大多数现有适配器使用单个线性层来压缩上游特征。模型在不同滤波器尺度下对特征有不同的认知。因此,本文在适配器的降维层之后采用了多个卷积滤波器,以增强适配器的认知能力。
本文在大量具有代表性的视觉任务上展示了Mona-tuning的通用性和优越性,包括图像分类、目标检测、语义分割、实例分割和定向目标检测。本文使用在ImageNet-22k(上训练的SwinTransformer系列作为预训练模型。
实验表明,所提出的方法在简单的图像分类任务和复杂的视觉任务上均优于传统的全面微调范式。例如,在COCO数据集上,Mona-tuning的mAP比全面微调高出1%。结果表明,全面微调可能不再是视觉任务的最佳选择。
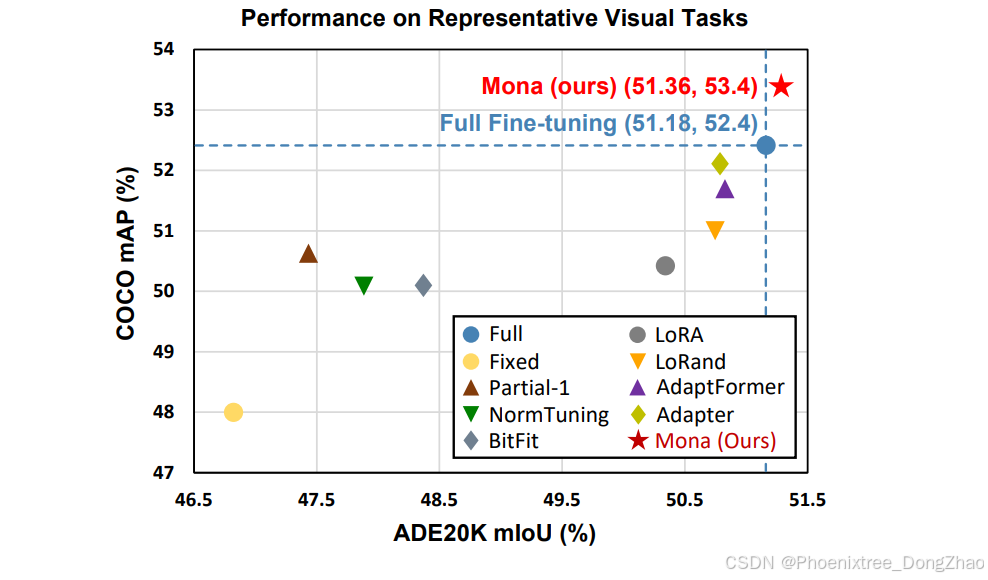
Mona是唯一一种在语义分割、实例分割和定向目标检测上超越全面微调的基于适配器的调节方法。图1展示了所提出方法在具有挑战性的实例分割和语义分割任务上的优越性。

Methods
适配器调整(Adapter-tuning)
之前的工作讨论了适配器微调(adapter fine-tuning),在这里简要介绍相关概念。全面微调(Full fine-tuning)会更新预训练骨干网络中的所有参数,而适配器调整(adapter-tuning)则固定预训练的参数,仅更新适配器中的参数。对于数据集 D = {(x_i, y_i)}^N_i=1,全面微调和适配器调整的优化过程可以分别表示为公式1和公式2:
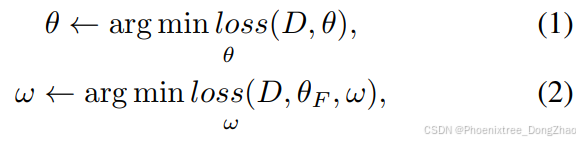
其中,loss表示训练损失,θ代表整个框架的参数,θ_F表示在适配器调整中固定的参数。ω代表在适配器调整中更新的参数,包括适配器内部和骨干网络外部的参数。
Mona
当应用于视觉任务时,典型的线性适配器存在两个问题。
首先,固定层的参数无法微调以匹配新任务的数据分布,导致传递给适配器的特征分布存在偏差。因此,对适配器来说,优化其从固定层接收的输入分布至关重要。
其次,传统的适配器是为自然语言信号设计的,并未针对视觉信号进行优化。之前的计算机视觉(CV)适配器研究基于线性滤波器(主要包括下投影、非线性激活、上投影和跳跃连接),这在传输视觉知识方面效率不高。为了解决这两个问题,本文进行了输入优化并设计了多认知视觉滤波器。
输入优化
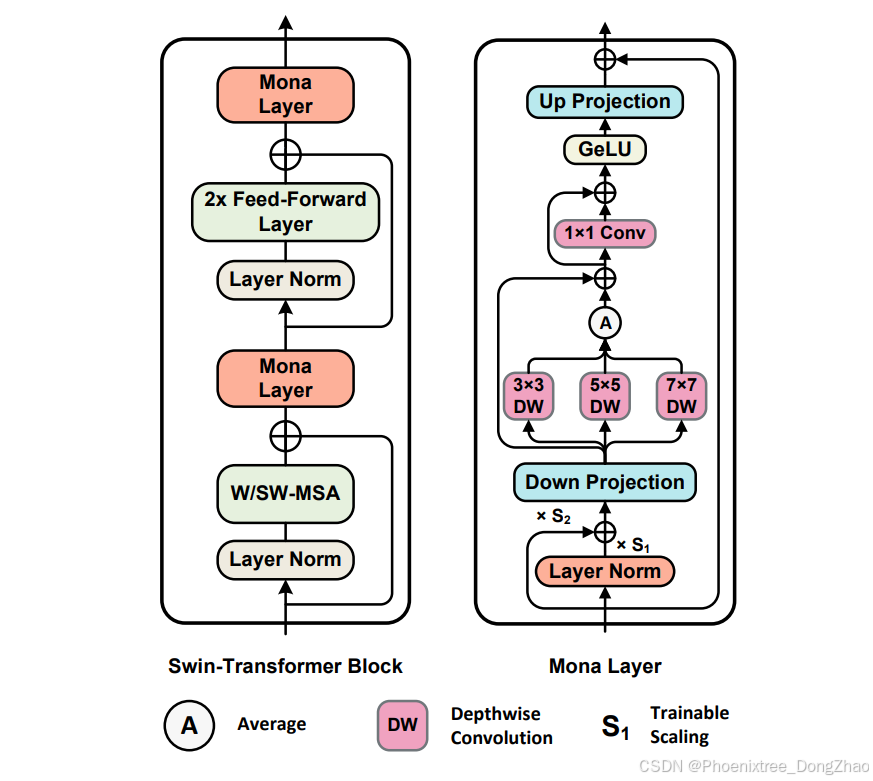
本文使Mona能够调整输入分布以及来自固定层的输入比例。具体来说,在Mona的顶部添加了一个归一化层和两个可学习的权重s1和s2,以调整输入分布。先前的工作表明,归一化有助于稳定前向输入分布和反向传播的梯度。在实践中发现,层归一化(LayerNorm, LN)优于批量归一化(BatchNorm, BN),因此本文在Mona中采用了LN。图2展示了本文设计,可以表示为:
![]()
其中,|·|_LN表示层归一化,x_0表示Mona的原始输入。

多认知视觉滤波器
在视觉认知中,人类眼睛会处理来自不同尺度的视觉信号,并将它们整合以获得更好的理解。为了使适配器在下游任务中表现更好,它们也应该从多个认知角度处理上游特征。本文在Mona中引入了多个卷积滤波器来增加认知维度。与标准卷积不同,Mona采用了深度可分离卷积(DepthWise Convolutions, DWConv)以最小化额外参数的数量。
具体来说,下投影后的上游特征会经过三个DWConv滤波器,卷积核大小分别为3×3、5×5和7×7。本文计算三个滤波器的平均结果,并通过一个1×1卷积来聚合特征。
本文还为两种卷积添加了跳跃连接。在第一个多滤波器卷积中,使用三个深度可分离卷积,权重为![]() ,在第二个卷积中,使用一个点卷积,权重为
,在第二个卷积中,使用一个点卷积,权重为![]() 。上述两个卷积步骤可以表示为:
。上述两个卷积步骤可以表示为:
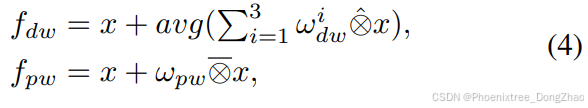
其中,⊗^ 和 ⊗- 分别表示深度可分离卷积和点卷积。然后,特征通过GeLU进行非线性化,并通过上投影恢复。Mona的整体计算过程可以表示为:
![]()
其中,D^l 和 U^l 分别表示第l个适配器的下投影和上投影,σ 表示GeLU激活函数。
参数分析
Mona的参数来源于LN(层归一化)、缩放因子、线性层、DWConv和1×1卷积。假设适配器的输入维度为m,下投影后的维度为n,则LN和缩放因子的参数为2m+2,两个线性层的参数为2mn+m+n,DWConv层的参数为![]() ,而PWConv的参数为n^2。因此,每个Mona模块的总参数为:
,而PWConv的参数为n^2。因此,每个Mona模块的总参数为:
![]()
对于每个块,所有Mona参数的总量是![]() (考虑了输入和输出的处理)。为了减少Mona中的参数数量,本文将n的值设置为常数64。
(考虑了输入和输出的处理)。为了减少Mona中的参数数量,本文将n的值设置为常数64。

















 4876
4876

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









