










Multimodal Mamba: Decoder-only Multimodal State Space Model via Quadratic to Linear Distillation
Bencheng Liao * 1 2; Hongyuan Tao * 2; Qian Zhang 3; Tianheng Cheng 2; Yingyue Li 2; Haoran Yin 3; Wenyu Liu 2; Xinggang Wang 2
1 Institute of Artificial Intelligence, Huazhong University of Science & Technology
2 School of EIC, Huazhong University of Science & Technology
3 Horizon Robotics.
Figure 1: Comprehensive comparison of mmMamba.
(a) Our mmMamba can build linear-complexity and hybrid decoder-only VLM by distilling the knowledge in Transformer to Mamba-2.
(b) By distilling from the quadratic-complexity decoder-only VLM HoVLE, our mmMamba-linear achieves competitive performance against existing linear and quadratic-complexity VLMs with fewer parameters (e.g., 2× fewer than EVE-7B), while mmMamba-hybrid surpasses them across all benchmarks and approaches the teacher model HoVLE’s performance.
(c)-(d) We compare the speed and memory of mmMamba-linear and mmMamba-hybrid with the teacher model HoVLE on the same single NVIDIA 4090 GPU. mmMamba-linear maintains consistently low latency and memory usage, while mmMamba-hybrid’s resource consumption scales significantly better than HoVLE. At 103K tokens, mmMamba-linear demonstrates 20.6× speedup compared to HoVLE and saves 75.8% GPU memory, while mmMamba-hybrid achieves 13.5× speedup and saves 60.2% GPU memory.
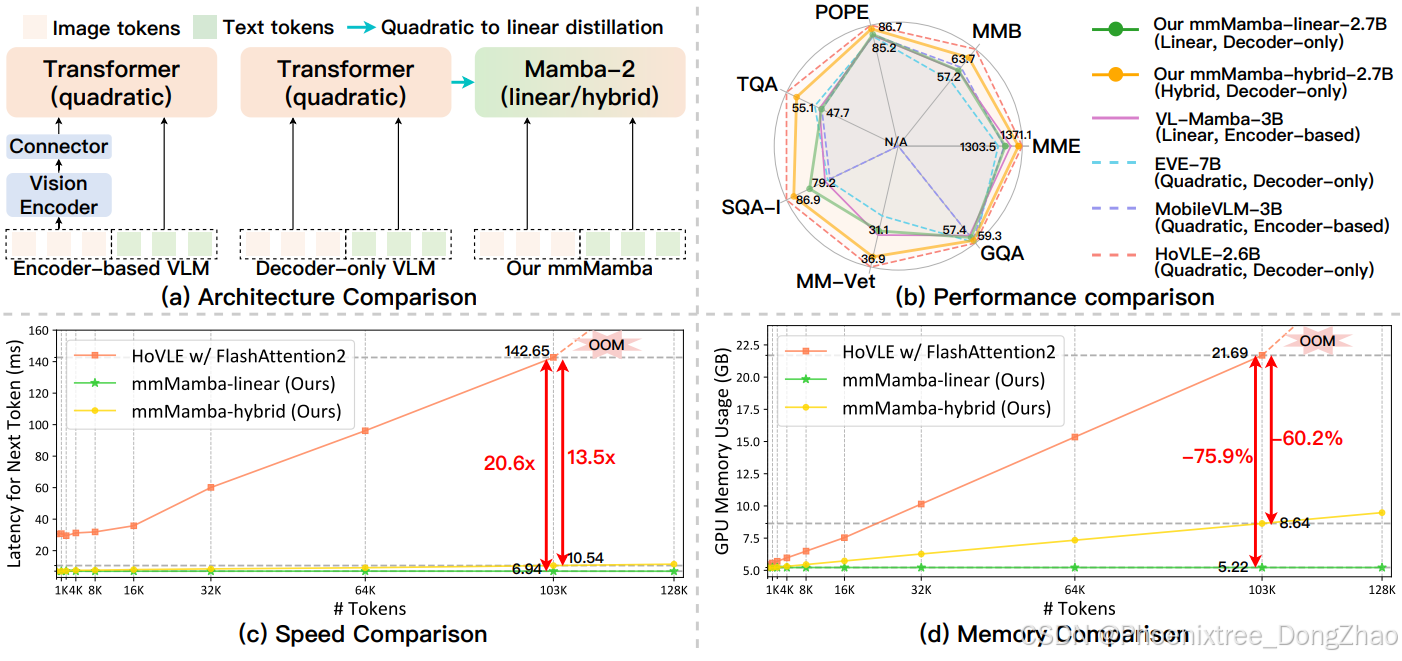
mmMamba综合对比分析。
(a) 本文的mmMamba通过将Transformer中的知识蒸馏到Mamba-2中,能够构建线性复杂度的混合解码器视觉语言模型。
(b) 通过从具有二次方复杂度的解码器视觉语言模型HoVLE进行知识蒸馏,mmMamba-linear在参数量更少的情况下(例如比EVE-7B少2倍)实现了与现有线性和二次方复杂度视觉语言模型相媲美的性能,而mmMamba-hybrid则在所有基准测试中超越这些模型,并接近教师模型HoVLE的性能。
(c)-(d) 本文在同一块NVIDIA 4090 GPU上对比了mmMamba-linear、mmMamba-hybrid与教师模型HoVLE的运行速度和内存占用。mmMamba-linear始终保持较低延迟和内存占用,而mmMamba-hybrid的资源消耗扩展性显著优于HoVLE。在处理103K个token时,mmMamba-linear相比HoVLE实现了20.6倍加速并节省75.8%显存,而mmMamba-hybrid则达到13.5倍加速并节省60.2%显存。
Abstract
Recent Multimodal Large Language Models (MLLMs) have achieved remarkable performance but face deployment challenges due to their quadratic computational complexity, growing Key-Value cache requirements, and reliance on separate vision encoders. We propose mmMamba, a framework for developing linear-complexity native multimodal state space models through progressive distillation from existing MLLMs using moderate academic computational resources. Our approach enables the direct conversion of trained decoder-only MLLMs to linear-complexity architectures without requiring pre-trained RNN-based LLM or vision encoders. We propose an seeding strategy to carve Mamba from trained Transformer and a three-stage distillation recipe, which can effectively transfer the knowledge from Transformer to Mamba while preserving multimodal capabilities. Our method also supports flexible hybrid architectures that combine Transformer and Mamba layers for customizable efficiency-performance trade-offs. Distilled from the Transformer-based decoder-only HoVLE, mmMamba-linear achieves competitive performance against existing linear and quadratic-complexity VLMs, while mmMamba-hybrid further improves performance significantly, approaching HoVLE’s capabilities. At 103K tokens, mmMamba-linear demonstrates 20.6× speedup and 75.8% GPU memory reduction compared to HoVLE, while mmMamba-hybrid achieves 13.5× speedup and 60.2% memory savings. Code and models are released at https: //github.com/hustvl/mmMamba.
当前多模态大语言模型(MLLMs)虽取得显著性能,但其二次方计算复杂度、持续增长的键值缓存需求以及对独立视觉编码器的依赖,导致实际部署面临挑战。本文提出mmMamba框架——一种通过渐进式蒸馏现有MLLMs来开发线性复杂度原生多模态状态空间模型的方法,仅需中等学术计算资源即可实现。该方法可直接将训练好的仅解码器MLLMs转化为线性复杂度架构,无需依赖预训练的RNN基LLM或视觉编码器。本文提出种子策略从训练好的Transformer中构建Mamba,并设计三阶段蒸馏方案,能在保留多模态能力的前提下有效实现Transformer向Mamba的知识迁移。该方法还支持构建灵活的混合架构,可自由组合Transformer与Mamba层,实现可定制的效率-性能权衡。从Transformer基仅解码器模型HoVLE蒸馏得到的mmMamba-linear,在性能上与现有线性和二次方复杂度视觉语言模型相当;而mmMamba-hybrid则进一步显著提升性能,逼近教师模型HoVLE的水平。在处理103K token时,mmMamba-linear相比HoVLE实现20.6倍加速并节省75.8%显存,mmMamba-hybrid则达到13.5倍加速和60.2%显存节省。代码与模型已开源:https://github.com/hustvl/mmMamba。
Introduction
Recent advances in Large Language Models (LLMs) (Brown et al., 2020; Achiam et al., 2023; Touvron et al., 2023a;b; Dubey et al., 2024; Bai et al., 2023a; Jiang et al., 2023; Bi et al., 2024; Javaheripi et al., 2023) have catalyzed significant research interest in expanding their capabilities beyond text to encompass multimodal understanding, particularly in processing both visual and textual information simultaneously. This expansion has given rise to Multimodal Large Language Models (MLLMs), with Vision Language Models (VLMs) emerging as a prominent subset. Notable examples such as LLaVA (Liu et al., 2024a), BLIP (Li et al., 2022), Qwen-VL (Bai et al., 2023b), InternVL (Chen et al., 2024b), and Monkey (Li et al., 2024b) have demonstrated remarkable success in enhancing LLMs’ visual comprehension capabilities through the integration of pre-trained vision encoders and specialized connectors that bridge the modality gap between vision and language.
While these encoder-based compositional VLMs have achieved state-of-the-art (SOTA) performance and established themselves as the de-facto paradigm, they face two critical limitations. First, processing long contexts becomes prohibitively expensive due to the quadratic computational complexity and linearly growing Key-Value (KV) cache with respect to sequence length. This limitation becomes particularly problematic given the increasing demand for long chain-of-thought reasoning (Muennighoff et al., 2025; DeepSeek-AI et al., 2025; Team et al., 2025; Xu et al., 2024) and high-resolution image/video understanding (Chen et al., 2023; Li et al., 2024a). Second, their heterogeneous architecture heavily relies on pre-trained vision encoders, introducing significant complexity in both training procedures and deployment scenarios (Chen et al., 2024a).
Current research efforts to address these limitations have followed two distinct paths. One approach focuses on developing linear-complexity VLMs by adhering to the conventional encoder-based recipe, which requires both pre-trained vision encoders and pre-trained linear-complexity language models (Hou et al., 2024; Qiao et al., 2024). The alternative approach aims to enhance decoder-only VLMs through increased model scale and expanded training datasets, achieving performance competitive with encoder-based counterparts (Bavishi et al., 2023; Diao et al., 2024; Tao et al., 2024; Team, 2024; Wang et al., 2024b).
Despite these advances, the development of linear-complexity decoder-only MLLMs remains an understudied yet critical challenge. Addressing this gap holds substantial value for three key reasons: (1) Unified multimodal understanding: Such models could seamlessly integrate multimodal reasoning within a single architecture, eliminating the need for heterogeneous, modality-specific frameworks. (2) Practical efficiency: Linear-complexity models inherently reduce computational demands during both training and inference, lowering costs and enabling deployment on resource-constrained edge devices. (3) Untapped Potential: While recent linear-time models like Mamba-2 demonstrate high text-processing capabilities, their ability to handle multimodal tasks—particularly in cross-modal alignment and reasoning—remains largely unexplored. The research of linear-complexity decoder-only MLLMs could unlock scalable, cost-effective multimodal systems without sacrificing performance.
A straightforward solution is to synergize the recipe of decoder-only VLMs and linear-complexity encoder-based VLMs. This integration requires a pre-trained linear-complexity LLM and performs image-caption alignment pre-training (PT) and supervised fine-tuning (SFT) using text instructions and image prompts. However, this integrated recipe faces two significant challenges: (1) It demands the curation of different large-scale multimodal datasets for different purposes (i.e., PT and SFT) and requires substantial computational resources. (2) The overall performance is inherently limited by the capabilities of pre-trained linear-complexity LLMs, which consistently underperform mainstream SOTA Transformer-based LLMs in language understanding tasks.
近期大型语言模型(LLMs)[1-9]的突破性进展,激发了研究者将其能力从文本领域拓展至多模态理解的广泛兴趣,特别是视觉与文本信息的协同处理。这一技术演进催生了多模态大语言模型(MLLMs)的兴起,其中视觉语言模型(VLMs)作为重要分支崭露头角。代表性工作如LLaVA[10]、BLIP[11]、Qwen-VL[12]、InternVL[13]和Monkey[14]等,通过整合预训练视觉编码器和跨模态连接器,显著提升了LLMs的视觉理解能力。
尽管这类基于编码器的组合式VLMs已达到顶尖性能并成为主流范式,其仍面临两大关键局限:首先,由于二次方计算复杂度及键值缓存(KV cache)随序列长度线性增长,长上下文处理的计算成本急剧上升。这一缺陷在日益增长的长链推理[15-18]和高分辨率图像/视频理解[19-20]需求下愈发凸显。其次,其异构架构严重依赖预训练视觉编码器,导致训练流程与部署场景复杂度显著增加[21]。
当前研究通过两条路径突破这些限制:一方面延续基于编码器的传统方案,开发需要同时依赖预训练视觉编码器和线性复杂度语言模型的线性VLMs[22-23];另一方面通过扩大模型规模与训练数据,构建性能可比肩编码器方案的仅解码器VLMs[24-28]。
然而,线性复杂度仅解码器MLLMs的开发仍属研究空白但至关重要。突破这一瓶颈具有三重价值:(1) 统一多模态理解:此类模型可在单一架构中实现跨模态推理,消除异构框架需求;(2) 实用高效性:线性复杂度特性从本质上降低训练/推理计算需求,助力边缘设备部署;(3) 潜能释放:尽管Mamba-2等新型线性模型已展现卓越文本处理能力,但其多模态任务(特别是跨模态对齐与推理)潜力尚未开发。线性仅解码器MLLMs的研究有望构建性能不妥协的可扩展低成本多模态系统。
直接解决方案是融合仅解码器VLMs与线性编码器VLMs的技术路径。这需要依赖预训练线性LLMs,并通过图文对齐预训练(PT)和基于文本指令与图像提示的监督微调(SFT)实现。但该方案面临双重挑战:(1) 需为不同目标(PT与SFT)构建大规模多模态数据集,且计算资源需求巨大;(2) 整体性能受限于预训练线性LLMs的语言理解能力,而此类模型始终落后于主流Transformer基LLMs。
In this paper, we propose a novel distillation-based recipe to develop linear-complexity decoder-only VLMs, which requires only moderate academic resources while circumventing the limitations of pre-trained linear-complexity LLMs. Our method leverages the fundamental similarity between the Transformer attention mechanism and the Mamba-2 state space model (SSM) mechanism. We introduce an initialization scheme that enables direct parameter transfer from Transformer to Mamba-2 layers, effectively converting the attention mechanism into the SSM function while carefully initializing SSM-specific parameters to mimic attention behavior. This approach enables the direct transformation of pre-trained Transformer-based VLMs into linear-complexity Mamba-2-based VLMs without relying on underperforming pre-trained linear-complexity LLMs. While this parameter inheritance and initialization strategy provides a promising starting point, the transformed Mamba-2-based VLM requires further distillation to recover robust multimodal conversation capabilities. To enhance alignment with the Transformer-based teacher VLM, we develop a three-stage progressive distillation strategy: (1) Stage-1: we first train the SSM-specific parameters while freezing inherited parameters, and align layer-wise behavior using MSE distillation loss; (2) Stage-2: we then optimize complete Mamba-2 layer behavior by enabling the training of inherited Transformer parameters; (3) Stage-3: we finally perform complete model alignment using KL-divergence loss on final output logits to recover the teacher model’s multimodal understanding capabilities through end-to-end distillation.
The proposed distillation recipe enables two distinct architectural variants: mmMamba-linear, which converts all Transformer layers into Mamba-2 layers, achieving full linear complexity, and mmMamba-hybrid, which strategically transforms fixed intervals of Transformer layers into Mamba-2 layers. The hybrid design systematically preserves Transformer layers at critical feature hierarchies while leveraging Mamba-2’s linear complexity for the majority of computations, striking a balance between efficiency and capability. During the final end-to-end distillation stage, we can flexibly adjust the number of interleaved Transformer layers, enabling precise control over the computation-performance trade-off. This architectural flexibility makes our approach highly adaptable to diverse deployment scenarios, allowing optimization for specific computational constraints while maintaining desired performance.
By distilling from the recent Transformer-based decoder-only VLM, HoVLE, we demonstrate that mmMamba achieves competitive performance across multiple vision-language benchmarks while significantly improving computational efficiency. Our pure Mamba-2-based linear-complexity variant, mmMamba-linear, achieves comparable performance to existing quadratic/linear-complexity VLMs like Mobile-VLM-3B (Chu et al., 2023), VisualRWKV-3B (Hou et al., 2024), VL-Mamba-3B (Qiao et al., 2024) while eliminating the need for separate vision encoders. mmMamba-pure also matches the performance of the previous SOTA Transformer-based decoder-only EVE-7B with 2× fewer parameters. The hybrid variant, mmMamba-hybrid, significantly improves performance on all benchmarks compared to mmMamba-pure, approaching the teacher model HoVLE. Notably, at the context length of 103K tokens, mmMamba-linear demonstrates 20.6× speedup compared to HoVLE and saves 75.8% GPU memory, while mmMamba-hybrid achieves 13.5× speedup and saves 60.2% GPU memory. These results and extensive ablation studies validate the effectiveness of our distillation recipe and highlight the potential for practical applications.
Our main contributions can be summarized as follows:
• We present a novel three-stage progressive distillation recipe for building native multimodal state space models without the reliance on underperforming pre-trained linear-complexity LLMs, enabling effective knowledge transfer from quadratic to linear architectures.
• With the proposed distillation recipe, we propose the first decoder-only multimodal state space models that include two distinct architectural variants: mmMamba-linear with purely linear complexity and mmMamba-hybrid offering flexible performance-efficiency trade-offs.
• Extensive experimental results demonstrate competitive performance with significantly improved computational efficiency across various vision-language tasks, achieving up to 20.6× speedup and 4.2× memory reduction for long sequence modeling on NVIDIA 4090 GPU.
本文提出一种基于知识蒸馏的创新方法,用于开发线性复杂度仅解码器视觉语言模型(VLMs)。该方法仅需中等学术资源即可实现,同时规避了预训练线性复杂度大语言模型(LLMs)的性能瓶颈。本文的方法基于Transformer注意力机制与Mamba-2状态空间模型(SSM)的核心相似性,设计了实现参数直接迁移的初始化方案:通过将注意力机制数学等价转化为SSM函数,并精心初始化SSM特有参数以模拟注意力行为,实现预训练Transformer基VLMs向Mamba-2基VLMs的无缝转换。这一过程无需依赖性能受限的预训练线性LLMs。
尽管参数继承与初始化策略提供了良好的起点,转换后的Mamba-2基VLM仍需通过蒸馏恢复鲁棒的多模态对话能力。为此,本文设计了三阶段渐进式蒸馏策略:(1) 阶段一:冻结继承参数,训练SSM特有参数,通过MSE蒸馏损失实现层间行为对齐;(2) 阶段二:解冻继承参数,联合优化完整Mamba-2层行为;(3) 阶段三:基于KL散度损失对输出logits进行端到端蒸馏,全面恢复教师模型的多模态理解能力。
该蒸馏方法支持两种架构变体:全线性复杂度的mmMamba-linear(所有Transformer层转换为Mamba-2层)与效率-性能可调的mmMamba-hybrid(按固定间隔转换层)。混合架构通过在关键特征层级保留Transformer层,同时利用Mamba-2的线性复杂度处理主要计算,实现效率与性能的平衡。在最终蒸馏阶段,可通过动态调整Transformer层数量实现计算-性能比的精准控制,使模型能灵活适配不同部署场景。
基于最新Transformer基仅解码器模型HoVLE的蒸馏实验表明,mmMamba在多项视觉语言基准测试中取得竞争力性能,同时显著提升计算效率。纯Mamba-2架构的mmMamba-linear在无需独立视觉编码器的情况下,性能媲美Mobile-VLM-3B[25]、VisualRWKV-3B[22]等二次/线性复杂度VLMs,并以2倍参数量优势达到前SOTA模型EVE-7B的水平。混合架构mmMamba-hybrid在各项基准上显著超越mmMamba-linear,逼近教师模型HoVLE。在103K token长序列场景下,mmMamba-linear相比HoVLE实现20.6倍加速与75.8%显存节省,mmMamba-hybrid则达到13.5倍加速与60.2%显存节省。详尽的消融实验验证了蒸馏方案的有效性,凸显了实际应用潜力。
本文的核心贡献可总结为:
• 提出新型三阶段渐进式蒸馏方法,无需依赖性能受限的预训练线性LLMs即可构建原生多模态状态空间模型,实现二次方架构向线性架构的有效知识迁移
• 基于该蒸馏框架,首次提出包含两种架构变体的仅解码器多模态状态空间模型:全线性复杂度的mmMamba-linear与支持灵活性能-效率权衡的mmMamba-hybrid
• 实验证明所提模型在视觉语言任务中实现竞争力性能,在NVIDIA 4090 GPU上达成最高20.6倍加速与4.2倍显存节省,为长序列建模提供高效解决方案
Preliminary
We firstly give a brief background on quadratic-complexity sequence modeling Transformer and linear-complexity sequence modeling Mamba-2. Given an input sequence
, where T is the sequence length and d is the hidden dimension. The above two sequence modeling layers will compute the output sequence
.
Transformer
The standard autoregressive Transformer used in LLM employs attention mechanism (Vaswani, 2017) by interacting with all historical positions in the sequence, which is defined as:
where
are the learnable parameters. The current output token ot is computed by performing attention over the growing sequence of historical keys
and values
.
Mamba-2
Instead of interacting with all historical positions, Mamba-2 (Dao & Gu, 2024) compresses the historical information into a fixed-size matrix-shaped hidden state, which is defined as:
where
and
are the learnable parameters.
is the fixed-size matrix-shaped hidden state,
is the data-dependent gating term to control the information flow by dynamically decaying the historical information
.
首先简要介绍二次复杂度序列建模的 Transformer 与线性复杂度序列建模的 Mamba-2。给定输入序列 (其中T为序列长度,d为隐藏维度),两种序列建模层均计算输出序列
。
Transformer
主流大语言模型采用的自回归Transformer通过注意力机制(Vaswani et al., 2017)与序列中所有历史位置进行交互,其计算过程定义为:
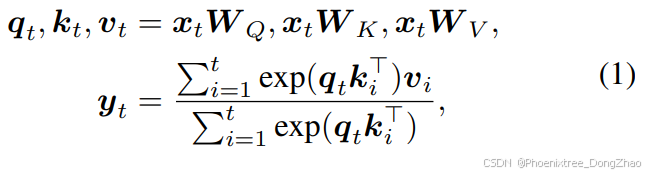
其中为可学习参数。当前输出token ot通过计算历史键向量
与值向量
的注意力权重得到。
Mamba-2
与全历史交互不同,Mamba-2(Dao & Gu, 2024)将历史信息压缩至固定尺寸的矩阵状隐藏状态,其核心机制定义为:
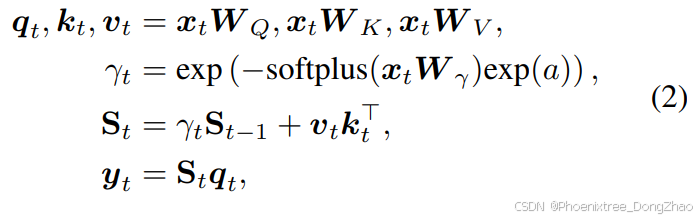
其,
and
为可学习参数。其中,
表示固定尺寸矩阵状隐藏状态,
为数据依赖型门控项,通过动态衰减历史信息
实现信息流的精准调控。
Method
Our method consists of three key components. First, we detail the seeding strategy, which carves the Mamba-2 architecture from a pre-trained Transformer by inheriting parameters and carefully initializing the newly introduced SSM-specific parameters in Sec. 4.1. Building upon this seeding strategy, we present the proposed progressive distillation pipeline in Sec. 4.2, Sec. 4.3 and Sec. 4.4 to effectively transfer knowledge from Transformer to Mamba-2. With the designed distillation training recipe, we then instantiate two model variants in Sec. 4.5: mmMamba-linear using only Mamba-2 layers, and mmMamba-hybrid incorporating interleaved Transformer and Mamba-2 layers
本方法包含三大核心组件:首先在4.1节详述基于预训练Transformer的Mamba-2架构初始化策略,通过参数继承与SSM特有参数的精心初始化实现架构转换;其次在4.2-4.4节提出渐进式蒸馏流程,有效实现Transformer向Mamba-2的知识迁移;最终在4.5节实例化两种模型变体——全Mamba-2层的mmMamba-linear与混合架构的mmMamba-hybrid。
1. Seeding: Initialize Mamba-2 from Transformer
To transfer as much knowledge as possible from quadratic Transformer to linear Mamba-2, we initialize Mamba-2 from Transformer at each layer. By comparing Eq. 1 and Eq. 2, we can find that Mamba-2 shares the similarity with Transformer, which means we can directly inherit WQ,WK,WV and WO projection parameters at each layer instead of building from scratch. Furthermore, we need to introduce extra parameters Wγ and a for state space modeling, replacing the attention mechanism. For better replacement and ease the training difficulty (Trockman et al., 2024), we initialize Wγ and a to make the gating term γt close to 1 at the beginning of training, which means we begin by memorizing all historical information without selectivity.
Beyond the core SSM mechanism, we also introduce extra causal convolution and output gating for enhanced positional awareness and expressiveness. To eliminate the initial impact of causal convolution, we initialize the weights and biases to make it function as an identity layer (i.e., the output of causal convolution is the same as the input) without affecting the original function of SSM at the beginning of training.
The other parts of the model such as the MLP layers and text and image patch embedding layers are directly inherited from the original Transformer-based VLM and kept as frozen.
初始化:基于Transformer的Mamba-2参数初始化
为实现二次复杂度Transformer向线性Mamba-2的最大化知识迁移,本文在每层执行参数初始化。通过对比公式(1)与(2),发现Mamba-2与Transformer存在结构相似性,因此可直接继承各层的WQ,WK,WV,WO投影参数,无需随机初始化。为替代注意力机制,需引入状态空间建模特有参数Wγ和a。为降低训练难度[25],初始化时令门控项γt趋近于1,即在训练初期保持全历史信息记忆模式。
在核心SSM机制外,本文引入因果卷积与输出门控增强位置感知与模型表达能力。通过将因果卷积的权重与偏置初始化为恒等变换(即输出等于输入),确保训练初期不干扰SSM原有功能。
模型中其他组件(如MLP层、文本/图像块嵌入层)直接继承自原Transformer基VLM并保持冻结。
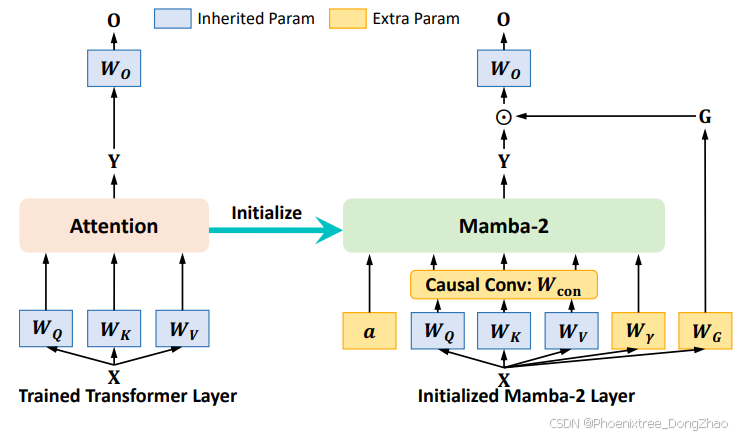
Figure 2: Initialize Mamba-2 from Transformer. By comparing the mechanism similarity in Sec. 3, we directly inherit W_Q, W_K, W_V , W_O parameters (blue) from trained Transformer layer and carefully initialize the extra parameters (orange) including a, W_γ, Wconv, and W_G in Mamba2 to initially mimic the Transformer’s behavior, providing a strong foundation for subsequent distillation.
2. Stage-1: Layerwise Distillation for the Newly Introduced SSM Parameters
We first perform layerwise distillation for the introduced extra parameters to align the proposed Mamba-2 layer with the original trained Transformer layer. Specifically, we instantiate the trained Transformer-based VLM as teacher model, and the transferred Mamba-2 VLM model as student model. The only difference lies in the sequence mixer layer. We feed the multimodal sequence into the teacher model.
To keep the layerwise alignment and diminish the accumulated error of the cascading layers, we input the i-th Mamba-2 layer with the output of the i − 1-th Transformer layer, i.e., i-th Mamba-2 layer and i-th Transformer layer have the same input. And we align the layerwise behavior by applying the MSE distillation loss between the output of the i-th Mamba-2 layer and the output of the i-th Transformer layer:
where
is the trainable parameters of the i-th Mamba-2 layer, which only includes the introduced extra parameters
.
is the input sequence to the i-th Mamba-2 layer and Transformer layer,
is the output of the i-th teacher Transformer layer, Mamba-2
is the output of the i-th student Mamba-2 layer.
阶段一:SSM新参数的层间蒸馏
首先针对新引入参数执行层间蒸馏,对齐Mamba-2层与原始Transformer层的输出行为。具体流程:
模型实例化
- 教师模型:已训练的Transformer基VLM
- 学生模型:参数转换后的Mamba-2 VLM
两者仅在序列混合层结构存在差异
对齐机制
将第i层Mamba-2的输入设为第i−1层Transformer的输出,确保与第i层Transformer输入同步,避免误差累积:
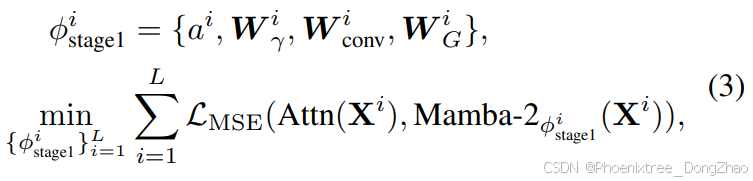
其中:
- Mamba-2
3. Stage-2: Layerwise Distillation for the Whole Mamba-2 Parameters
After the stage-1 distillation, we have obtained good initialization of the introduced extra parameters, and we further train all the Mamba-2 parameters to better align the layer-wise behavior of the student Mamba-2 with the teacher Transformer. The only difference between the stage-1 and stage-2 is that we further include the parameters of W_Q, W_K, W_V for optimizing the distillation loss:
阶段二:全参数层间蒸馏
完成阶段一蒸馏后,SSM 新参数已获得良好初始化。本阶段进一步联合优化所有 Mamba-2 参数,实现学生模型与教师层的全局行为对齐。与阶段一的核心差异在于:将原始 Transformer 的投影参数 W_Q, W_K, W_V 纳入优化范围,扩展蒸馏损失作用域:
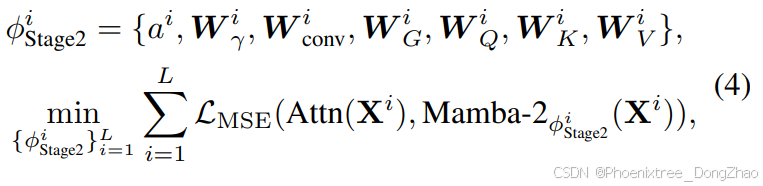
4. Stage-3: End-to-End Distillation
Beyond the layerwise alignment, the final stage-3 distillation aims to align the end-to-end behavior of the student Mamba-2 with the teacher Transformer. Specifically, we input the same multi-modal sequence to both the teacher Transformer and the student Mamba-2 without sharing the intermediate output. For the output of the teacher model and the student model, we apply the word-level KL-Divergence loss, in other words, they are used as soft labels, we enforce the output logits of the student model to be close to the output logits of the teacher model:
where X^0 is the same multi-modal input sequence to the teacher model and the student model, ϕ_Stage3 is the trainable parameters of the student model.
阶段三:端到端蒸馏
在层间对齐基础上,本阶段通过 KL 散度损失实现学生与教师的全局输出对齐。将相同多模态序列分别输入教师 Transformer 与学生 Mamba-2(不共享中间特征),强制学生输出 logits 逼近教师分布:
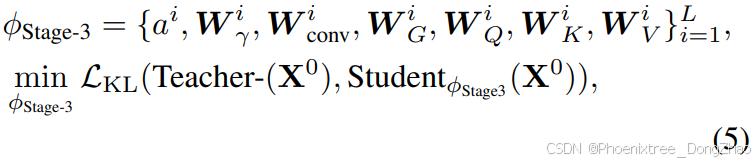
其中 X^0 为原始输入序列,ϕ_{stage3} 为全模型可训练参数。
5. Architecture
Our mmMamba builds upon HoVLE, a decoder-only VLM that consists of 32 Transformer layers. For mmMamba-linear, we convert each Transformer layer into a Mamba-2 layer while preserving the MLP layers, resulting in a linear-complexity decoder-only VLM. To enhance model expressiveness, we adopt a multi-head design in our Mamba-2 layers by partitioning the SSM into multiple groups and implementing shared queries across groups, consistent with the grouped query attention used in HoVLE.
For mmMamba-hybrid, we introduce a systematic layer conversion scheme. Specifically, within every fixed number of consecutive layers, we preserve the first layer as Transformer and convert the remaining layers to Mamba-2. This hybrid scheme maintains the Transformer’s modeling capacity at critical feature hierarchies while leveraging Mamba-2’s linear complexity for the majority of computation. Such design enables an effective and flexible trade-off between computational efficiency and model capability, suitable for various deployment scenarios with varied requirements. In this paper, we set the interval as 4, building mmMamba-hybrid with 8 Transformer layers and 24 Mamba-2 layers in total.
基准架构:mmMamba 基于仅解码器 VLM——HoVLE(32层 Transformer)构建。
mmMamba-linear
本文的mmMamba建立在HoVLE之上,这是一个只有解码器的VLM,由32个Transformer层组成。对于mmMambalinear,本文将每个Transformer层转换为Mamba2层,同时保留MLP层,从而产生仅线性复杂度解码器的VLM。为了增强模型的表达能力,本文在Mamba2层中采用了多头设计,将SSM划分为多个组,并跨组实现共享查询,这与HoVLE中使用的分组查询注意一致。
- 全线性架构:将每层 Transformer 替换为 Mamba-2 层,保留MLP层
- 多头优化:将 SSM 划分为多组,采用跨组共享查询机制(与 HoVLE 的分组查询注意力兼容)
mmMamba-hybrid
对于mmMamba-hybrid,引入了一种系统的层转换方案。具体来说,在每个固定数量的连续层中,将第一层保留为Transformer,并将其余层转换为Mamba-2。这种混合方案在利用Mamba2的线性复杂性进行大部分计算的同时,维护了Transformer在关键特征层次上的建模能力。这样的设计能够在计算效率和模型能力之间进行有效和灵活的权衡,适用于具有不同需求的各种部署场景。本文将层距设为4,共构建了8个Transformer层和24个Mamba-2层的mmMambahybrid。
- 系统级层转换:每连续N层中保留首层为 Transformer,其余转为Mamba-2层
- 效能平衡:
- 关键特征层级(如底层语义/高层推理)保留 Transformer 建模能力
- 80%计算负载由 Mamba-2 以线性复杂度处理
- 部署配置:本文采用间隔 N=4,构建含8层 Transformer+24 层 Mamba-2 的混合架构
架构对比
| 模型变体 | Transformer层 | Mamba-2层 | 复杂度类型 |
|---|---|---|---|
| mmMamba-linear | 0 | 32 | 全线性(O(T)) |
| mmMamba-hybrid | 8 | 24 | 混合(O(T)+O(1)) |

















 1354
1354

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









