







本文根据“一文看懂Mamba,Transformer最强竞争者”(机器之心 编辑:Panda)一文修改,并补充了一些新的观点。
在深度学习领域的广阔天地中,随着技术的不断进步,对更高效、更强大模型架构的探索从未停歇。Transformer模型作为近年来的一颗璀璨明星,凭借其强大的序列建模能力,在机器翻译、文本生成、语音识别等前沿领域大放异彩,树立了新的性能标杆。这一成功背后,关键在于Transformer内置的注意力机制,它犹如一盏明灯,照亮了输入序列中的关键信息路径,使模型能够更深入地理解上下文环境,从而做出更为精准的预测和决策。
然而,正如每枚硬币都有其两面,Transformer的注意力机制在赋予其卓越性能的同时,也带来了计算复杂度的显著上升,特别是当面对超长文本序列时,这种二次增长的计算需求成为了制约其应用的一大瓶颈。为了解决这一问题,研究者们不断探索新的路径,以期在保持高效建模能力的同时,降低计算成本。
正是在这样的背景下,结构化状态空间序列模型(SSM)应运而生,它以独特的视角和创新的架构,为深度学习领域带来了新的希望。SSM不仅继承了传统状态空间模型在序列处理方面的优势,还巧妙地融合了RNN的序列记忆和CNN的空间特征提取能力,形成了一种既能捕捉长期依赖又能高效处理局部信息的混合模型。通过优化循环或卷积操作,SSM实现了计算成本随序列长度的线性或近线性增长,有效缓解了Transformer在计算资源上的压力。
SSM家族中的Mamba模型更是其中的佼佼者,它不仅在建模能力上与Transformer不相上下,更在处理长序列数据时展现出了卓越的线性可扩展性。这一成就得益于Mamba引入的精炼选择机制,该机制能够智能地根据输入数据动态调整模型参数,剔除冗余信息,保留关键特征,从而在保证信息精度的同时提高了处理效率。此外,Mamba还充分利用了硬件加速技术,通过扫描操作替代传统卷积,在高性能GPU上实现了计算速度的大幅提升,进一步增强了其实用性和竞争力。
如图1所示,Mamba模型在处理复杂长序列数据时的卓越表现,以及其在计算成本上的显著优势,正逐步奠定其作为未来基础模型的重要地位。随着计算机视觉、自然语言处理、医疗健康等领域对高效、精准模型需求的日益增长,Mamba有望引领一场深刻的变革,推动这些领域的技术进步和应用拓展。
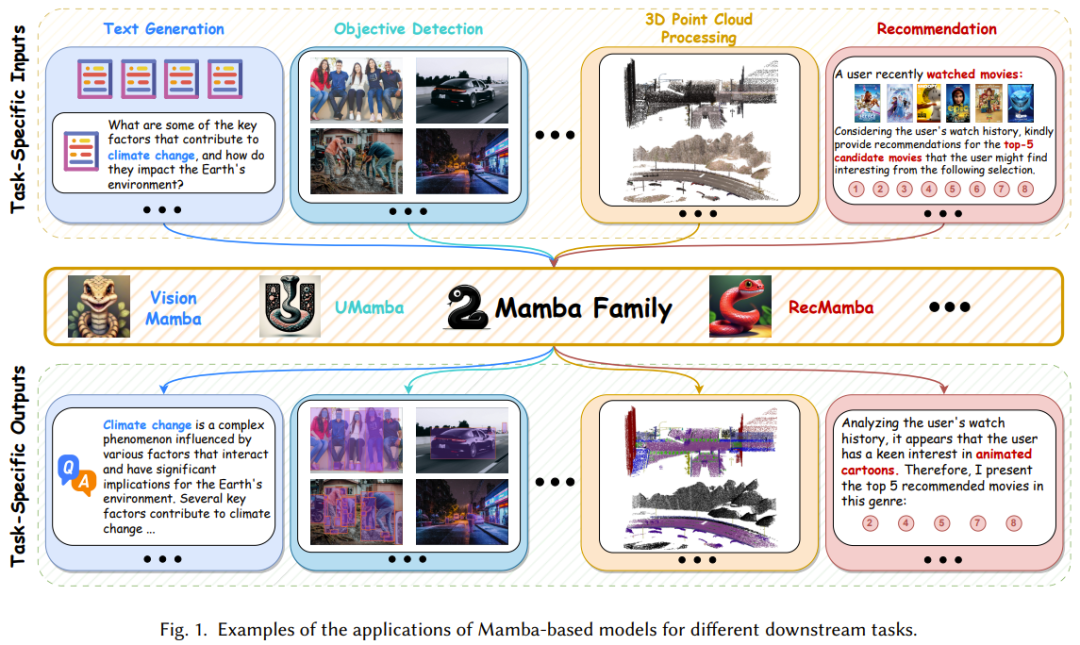
因此,研究和应用 Mamba 的文献迅速增长,让人目不暇接,一篇全面的综述报告必定大有裨益。近日,香港理工大学的一个研究团队在 arXiv 上发布了他们的贡献。

-
论文标题:A Survey of Mamba
-
论文地址:https://arxiv.org/pdf/2408.01129
这份综述报告从多个角度对 Mamba 进行了总结,既能帮助初学者学习 Mamba 的基础工作机制,也能助力经验丰富的实践者了解最新进展。
Mamba 是一个热门研究方向,也因此有多个团队都在尝试编写综述报告,除了本文介绍的这一篇,还有另一些关注状态空间模型或视觉 Mamba 的综述,详情请参阅相应论文:
-
Mamba-360: Survey of state space models as transformer alternative for long sequence modelling: Methods, applications, and challenges. arXiv:2404.16112
-
State space model for new-generation network alternative to transformers: A survey. arXiv:2404.09516
-
Vision Mamba: A Comprehensive Survey and Taxonomy. arXiv:2405.04404
-
A survey on vision mamba: Models, applications and challenges. arXiv:2404.18861
-
A survey on visual mamba. arXiv:2404.15956
预备知识
循环神经网络(RNN)
循环
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1323
1323

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









