






导语:接上一期,本次拆解案例来自于2024年QECon大会北京站-字节跳动。
1. 测试设计生成背景
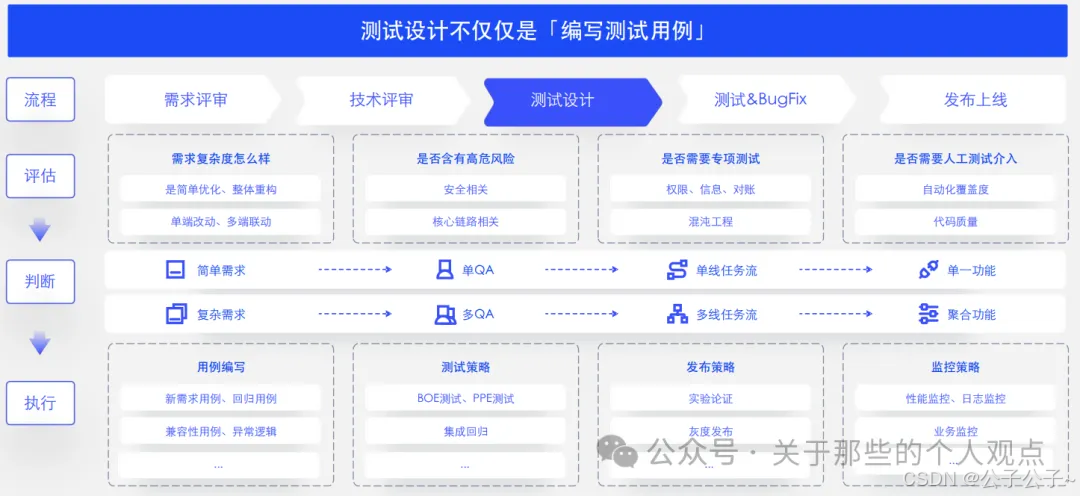
- 测试设计避免无效测试投入,测试设计是智能测试的基础。
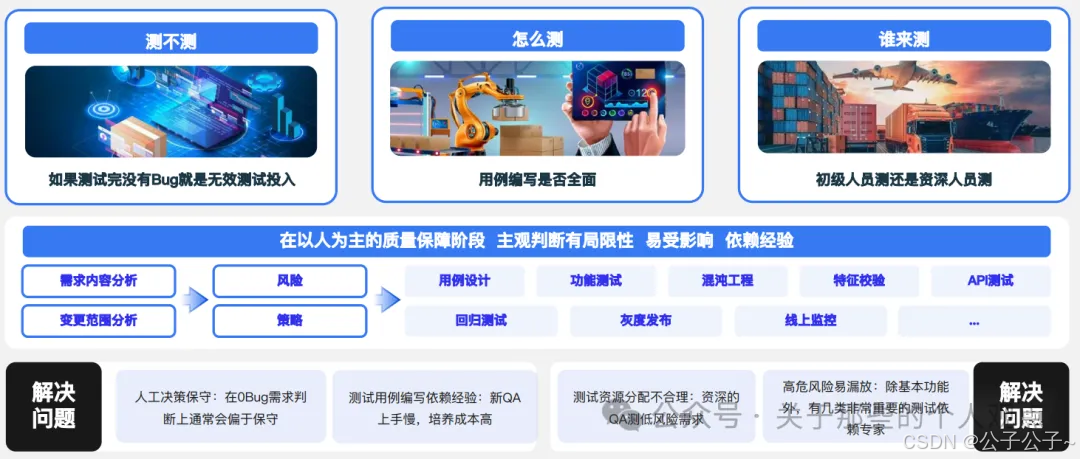
- 测试设计天生具有复杂性,不仅仅只是编写测试用例。好的测试设计需要回答“测不测”、“怎么测”、“谁来测”3个问题。
- 在以人为主的质量保障阶段,主观判断有局限性,易受影响且依赖经验,这些正是需要大模型来解决的问题。

2. 探索与实践
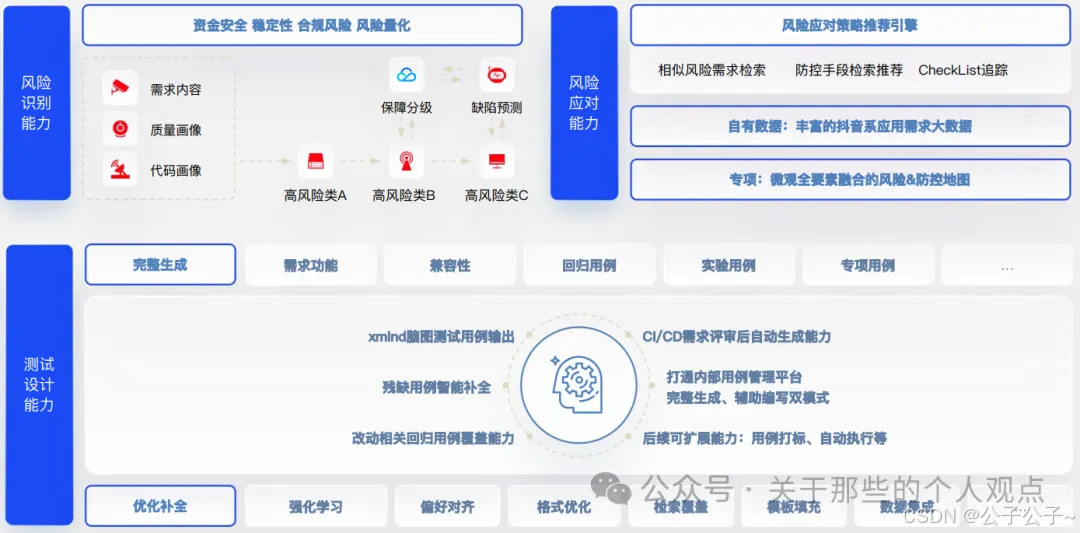
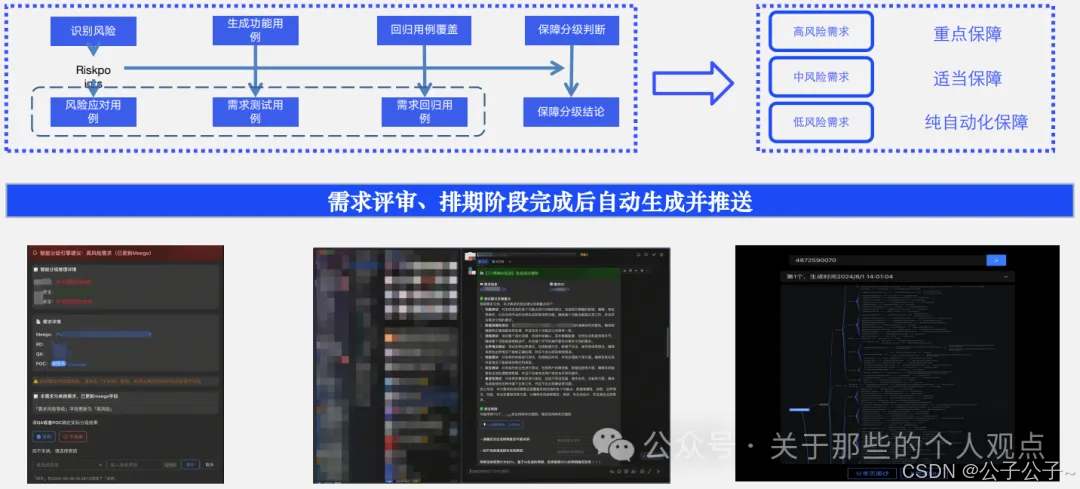
借助大模型,构建风险识别、风险应对、测试设计3大能力,目前做的最好的还是在测试设计部分。测试设计过程中需结合前两者进行辅助重点优化。初步设想是在需求评审和排期阶段完成后,自动生成用例并推送。
3. AI工程
相比于上一期提到的趣玩科技,字节跳动的应用明显就高了一个level,毕竟地主家余粮多的事。他们并没有直接使用通用大模型,而且针对性的训练了风险分析模型和测试设计生成模型,而且搭建了一整套AI工程架构。有实力的企业可以学起来。
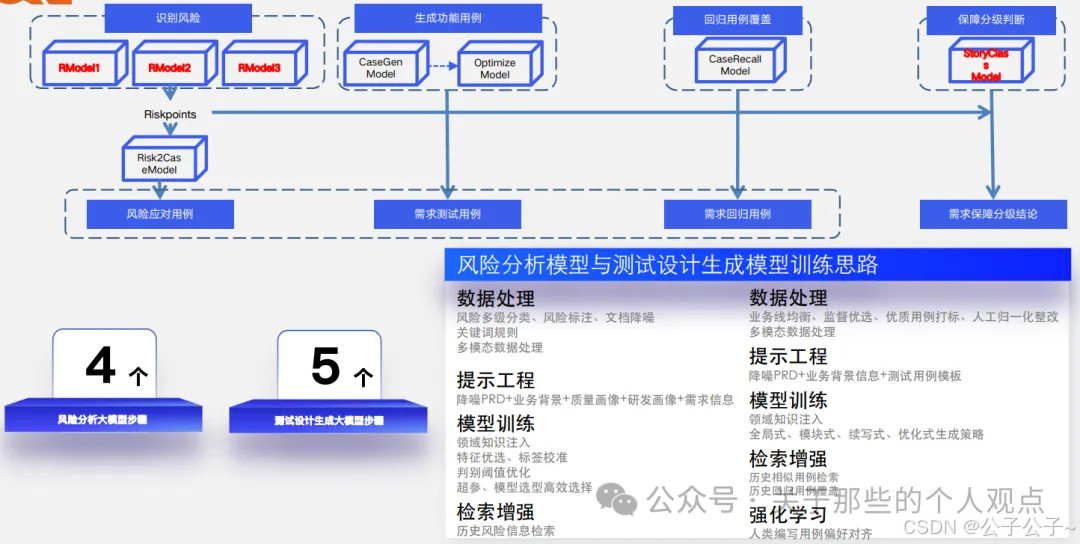

同时,在模型训练的过程中,还对数据质量进行了梳理和清洗。可以看到字节总共使用了55W需求数据、10W风险数据、250W用例数据。在大模型时代,数据才是关键资产,就拿其中的风险数据来说,有多少公司可以做到真正去梳理沉淀测试风险呢,又有多少公司可以完完整整写好高质量的需求规格文档呢。没有这些基础知识的沉淀,别想着AI能给你带来多大的提升,去把基础的研发测试流程建立好反而效果来得更快。

有了数据,接下来就是数据的处理,这里不可避免地会遇到多模态问题,就拿我们公司内部来说,测试用例的形式都各不相同,有使用Excel的,有使用思维导图的,其中还涉及截图等。这些都是要进行相应处理的。
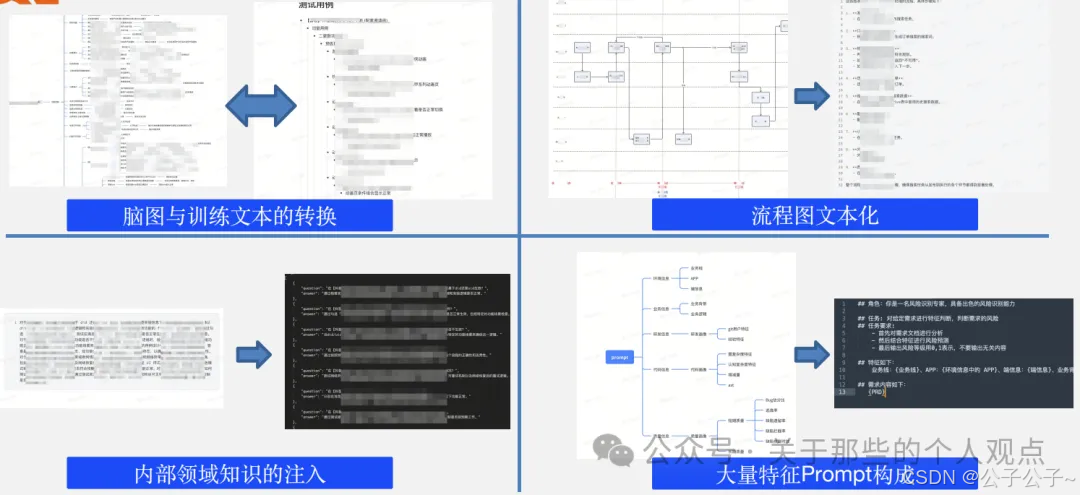
关键的地方又来啦,模型训练始终绕不过Prompt优化,这个偷偷记下来吧,说不定哪天自己能用上。

当时对比模型的时候,DeepSeek还没出来,我相信今年他们内部肯定也会进行再次对比验证了,效果应该会提升不少。

RAG的检索增强技术也是少不了,基本上能想到的技术字节都给用上了,这也是大厂的底蕴。但是我不太建议所有的公司都去这么做,还是要评估自身的实力水平。我推荐的方式还是知识库外挂,模型可以随时切换,这样就能最大限度的享受大模型本身飞速发展的红利,否则训练和替换的成本会非常高。说不定哪天又出了个DeepDrink呢图片
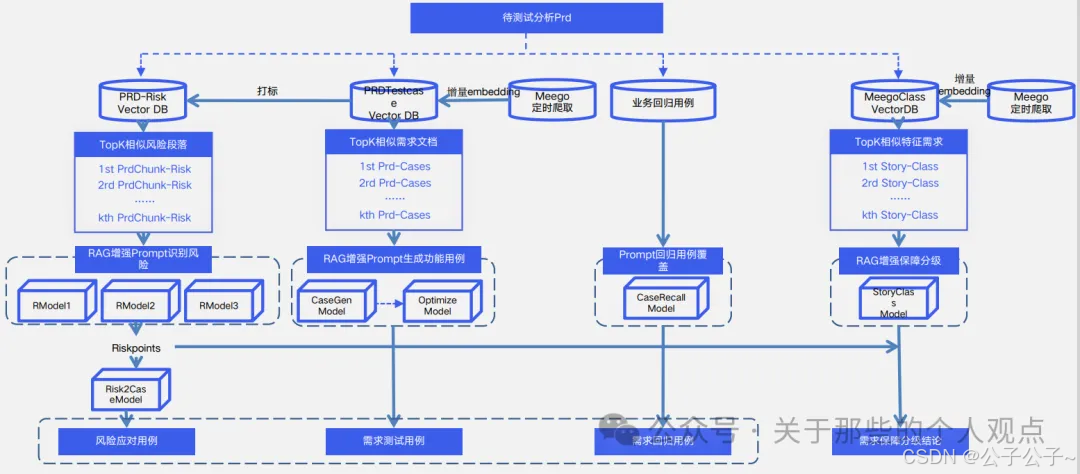
4. 应用效果
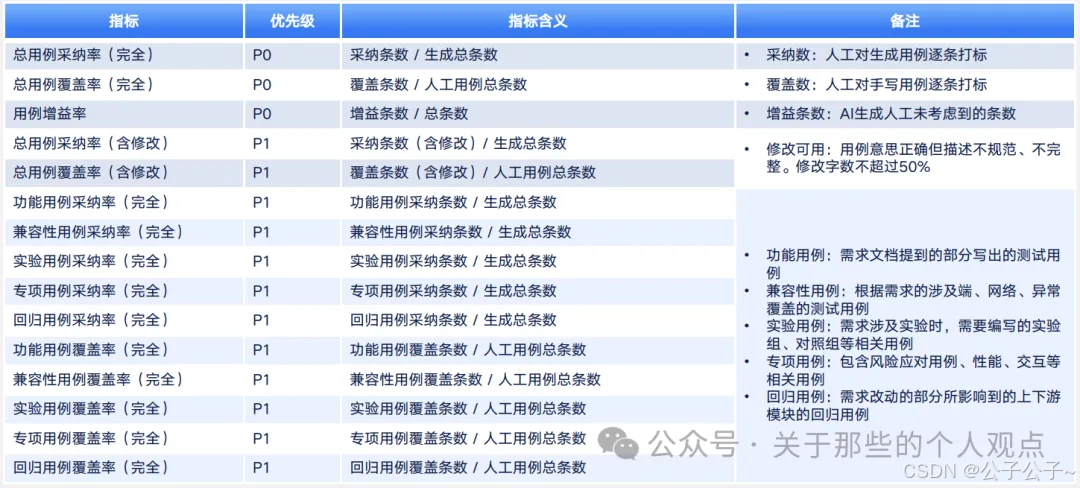
说到效果,首先要明确指标,这里字节给出了几个测试设计生成评测指标,非常具有借鉴意义。

核心指标
| 指标 | 计算公式 | 优先级 |
|---|---|---|
| 用例采纳率(完全) | 采纳条数/生成总条数 | P0 |
| 用例覆盖率(完全) | 覆盖条数/需求用例总数 | P0 |
| 用例增益率 | 增益条数/总条数 | P0 |
| 功能用例采纳率 | 功能用例采纳条数/生成总条数 | P1 |
效果示例
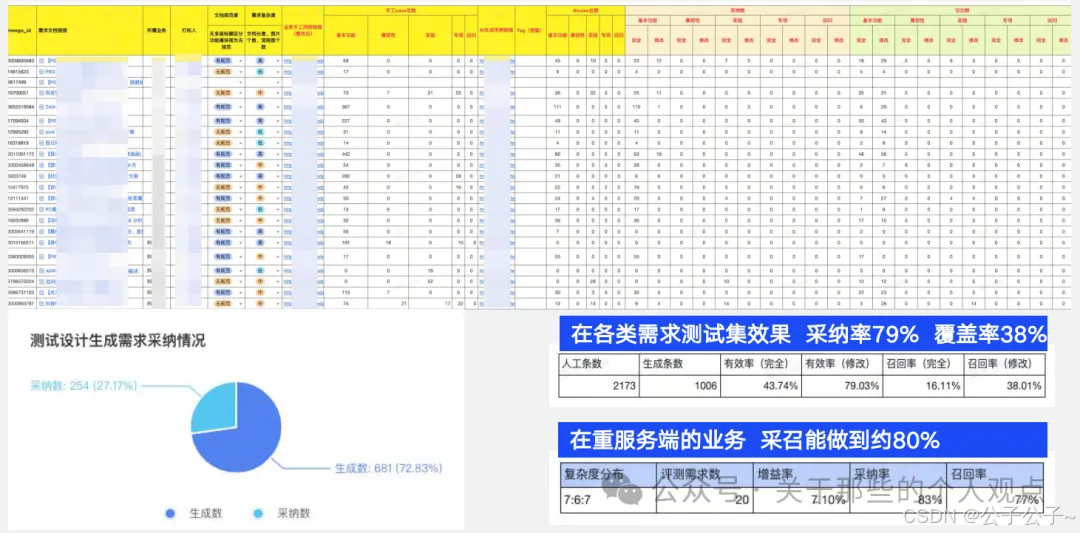
最终的实际效果更是十分可观,需求测试及采纳率高达79%,覆盖率到了38%,而在重服务端的业务下,采纳率更是达到了83%,最终总体的需求投入下降了33%。大厂出手,不服不行。

关注公众号【关于那些的个人观点】,发送消息“智能化测试”,获取完整内容PDF

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









