






导语
接上一期,本次拆解案例来自于2024年QECon大会上海站以及哔哩哔哩技术。尤其是哔哩哔哩技术公众号,万字长文的技术干货满满,推荐关注!文末附资料获取方式。
写在前面
大模型赋能UI自动化测试属于难度较高的领域,而且UI自动化本身也有着细分。在技术应用方面,分为界面图像识别OCR技术和界面XPath元素定位;在应用类型方面,分为基于移动APP和基于Web应用;在测试类型方面,分为探索性测试和回归性测试。而大模型赋能场景下,实际落地效果比较好的是基于图像识别的移动APP探索性测试。
基于图像识别的智能UI尝试
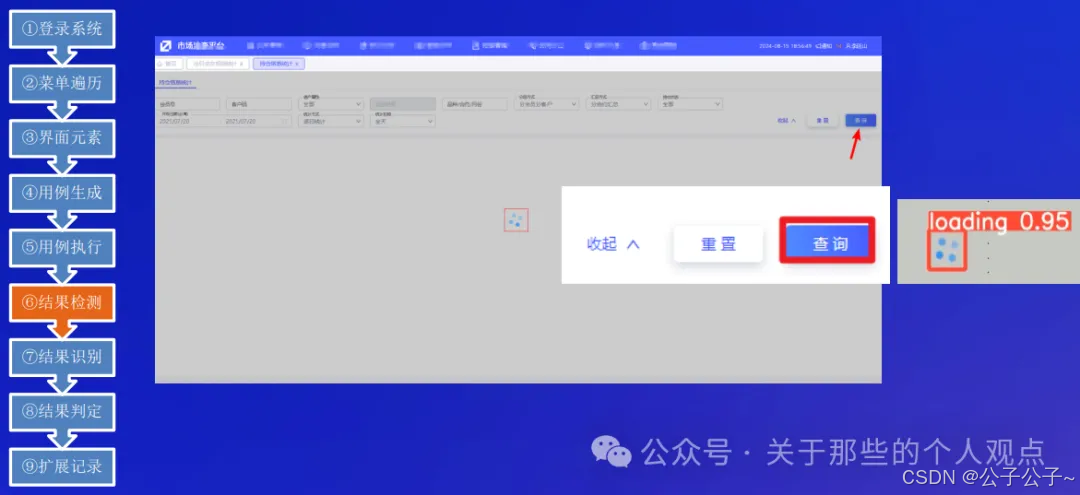
这里是来自易盛信息的案例,仅作为启发,实际含“大模型”量比较少。这个案例比较偏向探索性测试,整个流程如下:
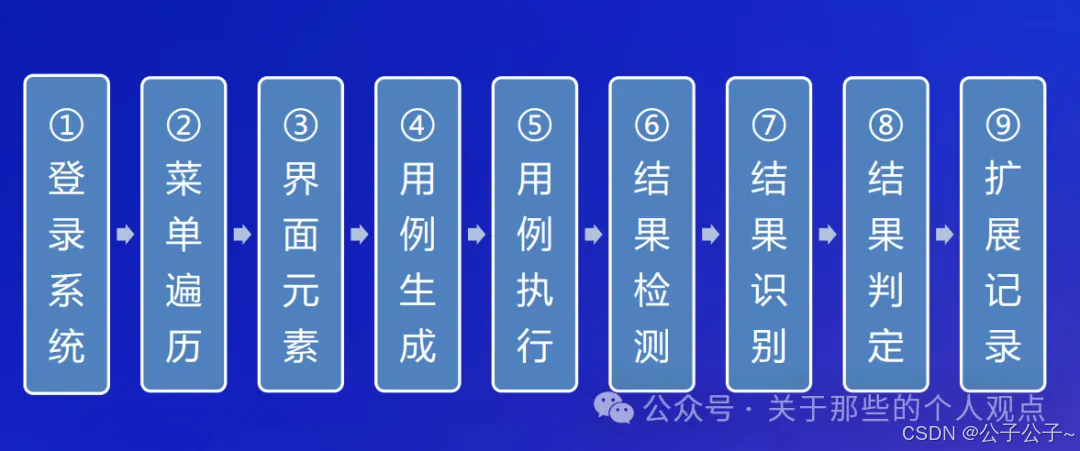

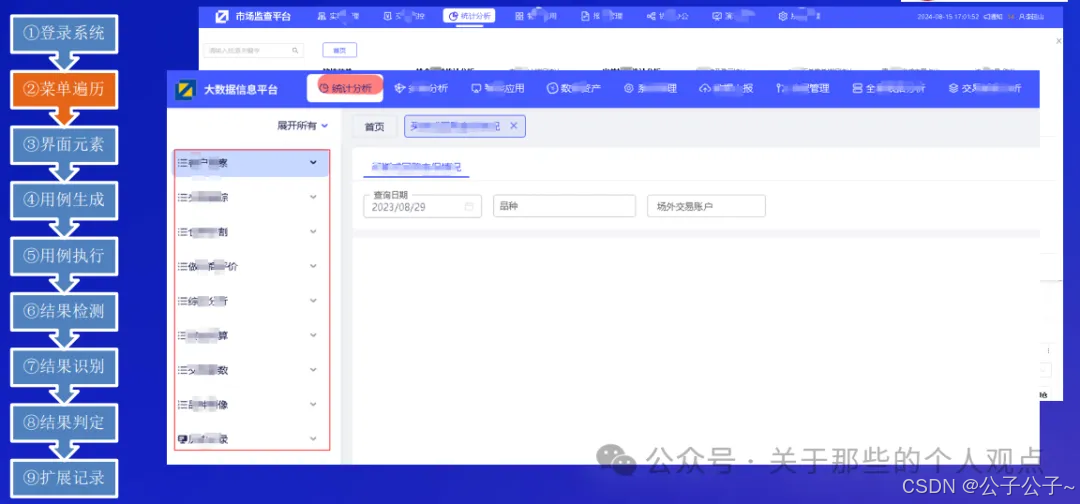

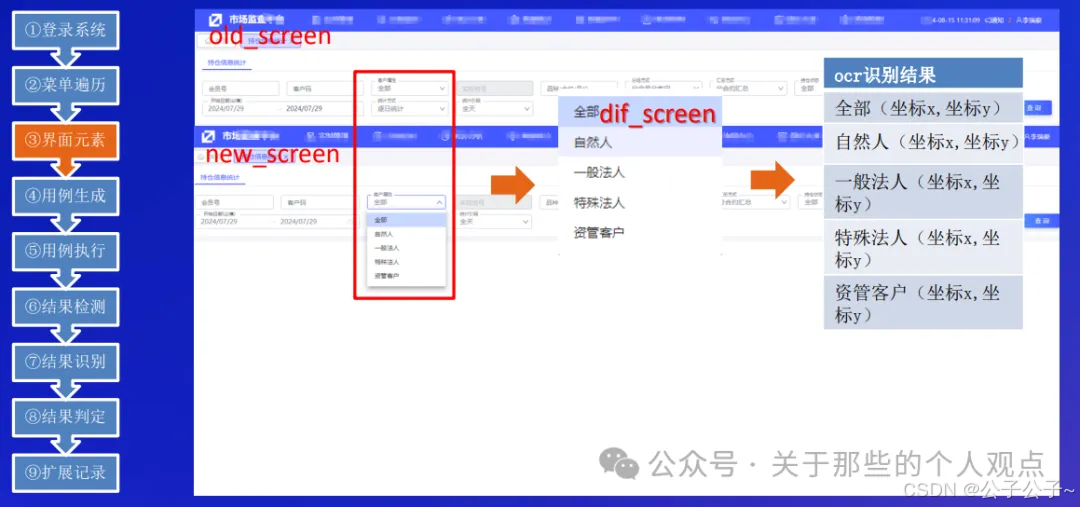
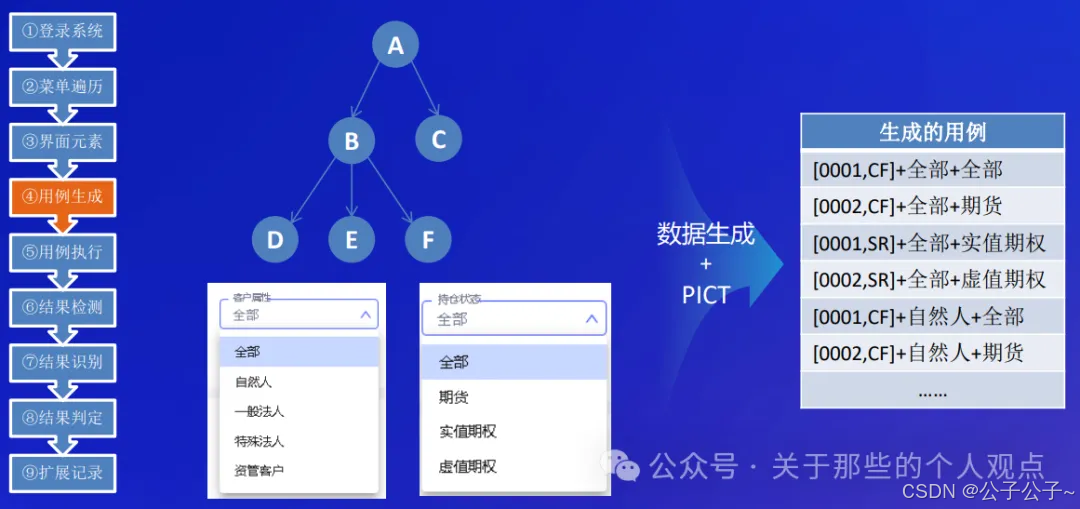

第二个案例来自于美团到店研发平台和复旦大学周扬帆教授团队合作的AUITestAgent。
论文地址:https://arxiv.org/abs/2407.09018
Github 项目地址:https://github.com/bz-lab/AUITest Agent
论文标题:AUITest Agent: Automatic Requirements Oriented GUI Function Testing
这个工具可以做到基于自然语言的测试用例,自动完成终端UI测试,本质的原理是大模型理解自然语言后,同时理解功能界面操作,生成对应的逻辑步骤,再通过调用对应的动作方法,实现APP的操作测试。
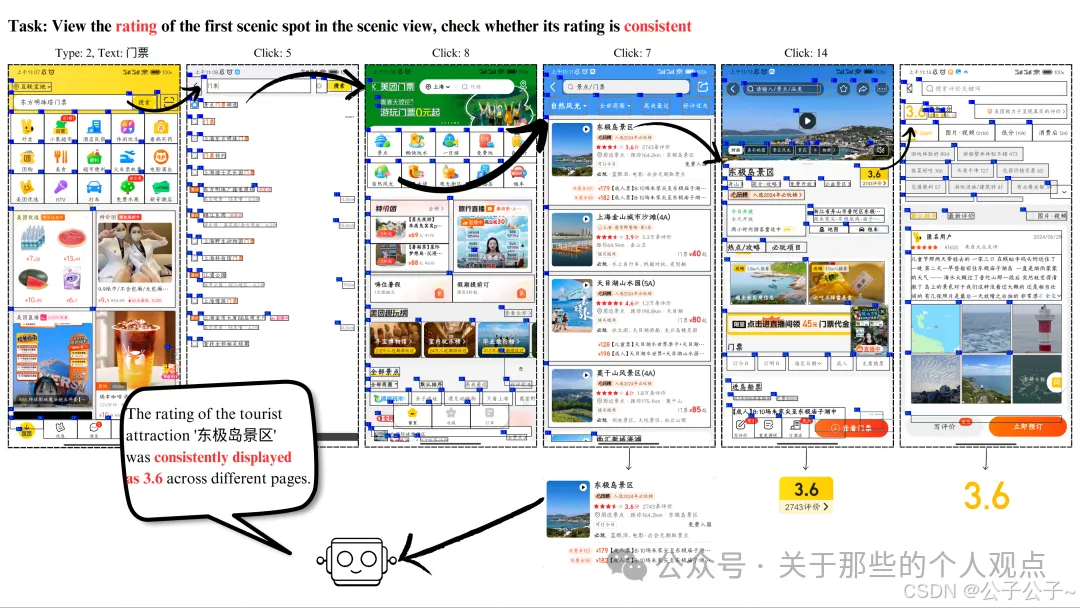
以对美团 APP测试为例,测试人员输入测试需求“查看景点门票频道中自然风光下第一个景点的评分,检查其评分在不同页面上是否一致”。如下方视频和图片所示,AUITestAgent 从美团首页出发自动搜索并进入美团门票频道,查看自然风光下的第一个景点的评分页面;然后,AUITestAgent 将检查交互过程,从中提取所需的信息,进行判断并给出理由。
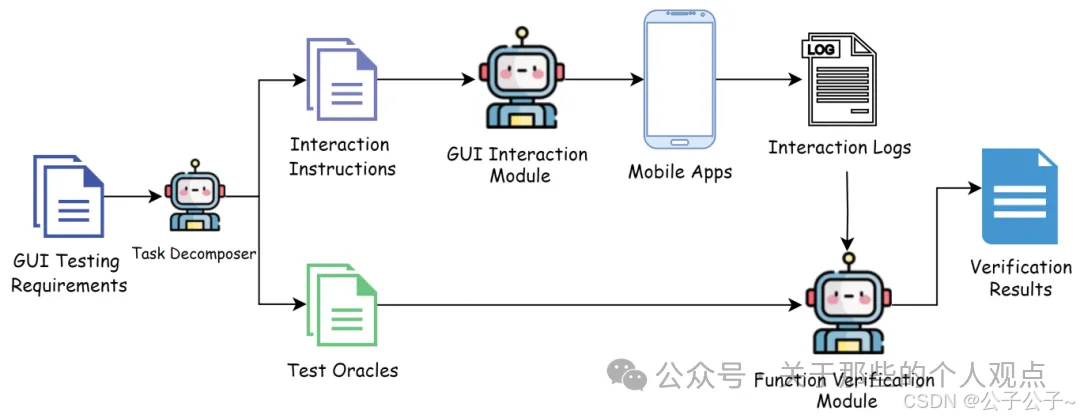
这是实际的工作流程,主要包括三个主要部分:
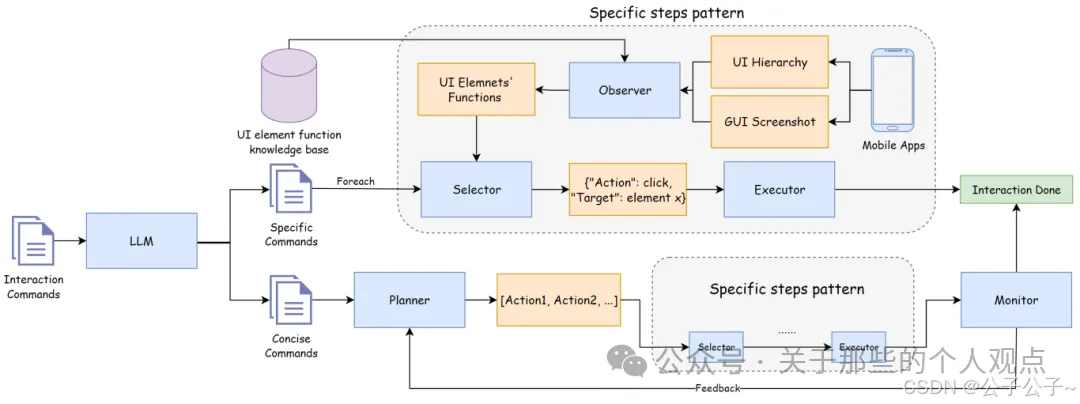
在交互模块中存在多个智能代理进行协作:
基于图像识别的UI自动化测试还有第三种案例,就是前文提到的软件健壮性测试,基本原理是将软件入口界面呈现给大模型,大模型识别并理解界面信息和业务逻辑,然后进行自由输入和探索,以此来测试软件的健壮性。区别于回归测试,这种测试方式每次都是在大模型理解下的随机执行;同样区别于完全随机的monkey测试,大模型辅助下的探索测试具有类人的发散性思维,同时在一些数据输入、选择上成功率更高。之前有论文显示,基于大模型的探索性测试在移动APP的健壮性测试中,探索深度更高、发现问题更多,潜力巨大。
基于元素定位的智能UI尝试
这部分重点讲解哔哩哔哩的UI自动化测试用例自愈的案例,文末附上了原文链接,大家可以查看完整文章。
其实用过UI自动化测试平台的小伙伴都知道,随着项目迭代频繁,用例脚本维护成本会越来越高。
经过某些迭代后执行用例时,可能很多用例执行不通过,但大部分是页面结构的合理更新后所至,而非新引入的bug,此时需人工一一审阅报错原因,确认是feature或bug。且此次因feature导致的用例不通过,若不及时更新,则下次执行时将有极大概率依然不通过,如此不断叠加,不通过的用例越来越多,导致我们不得不在每次迭代后及时地花费很大精力去排查、更新用例,完全违背了“自动化测试”的初衷。
其实观察该类问题后会发现,它们大部分都出自同一个“简单”的原因:页面更新后,用例执行时获取不到目标元素。针对这种情况,哔哩哔哩对传统的css selector规则进行了扩展,并基于现有的LLM实现了目标元素的智能识别与“用例自愈”。使得在页面结构变化后(非大的功能更新),依然能够获取到目标元素,并自动根据最新页面结构自动更新用例脚本。
首先是用例的录制,哔哩哔哩的自动化测试平台提供了录制功能,部分细节如下(不得不说,哔哩哔哩是真分享啊,不然谁给你画这么详细的示意图)
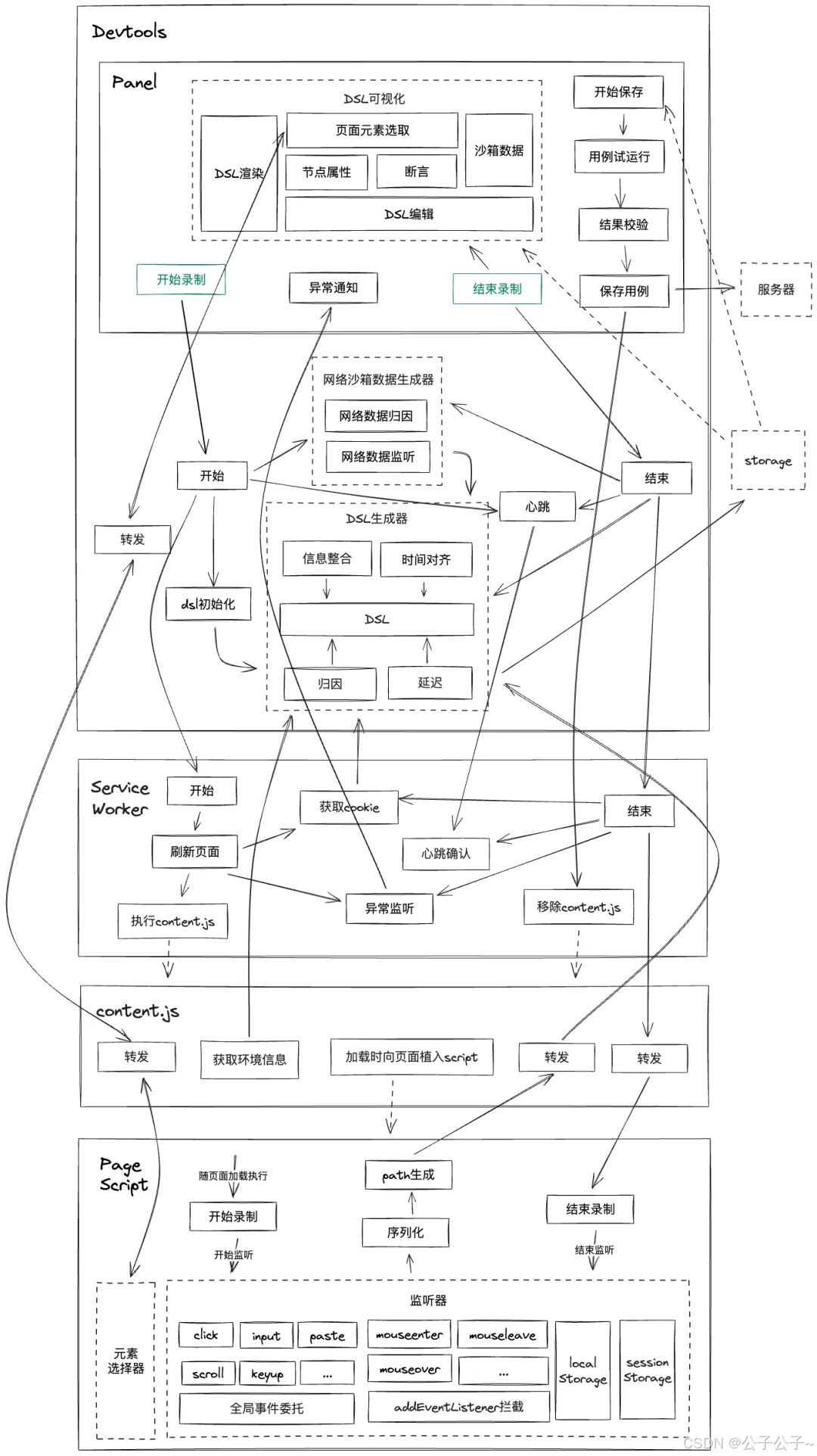
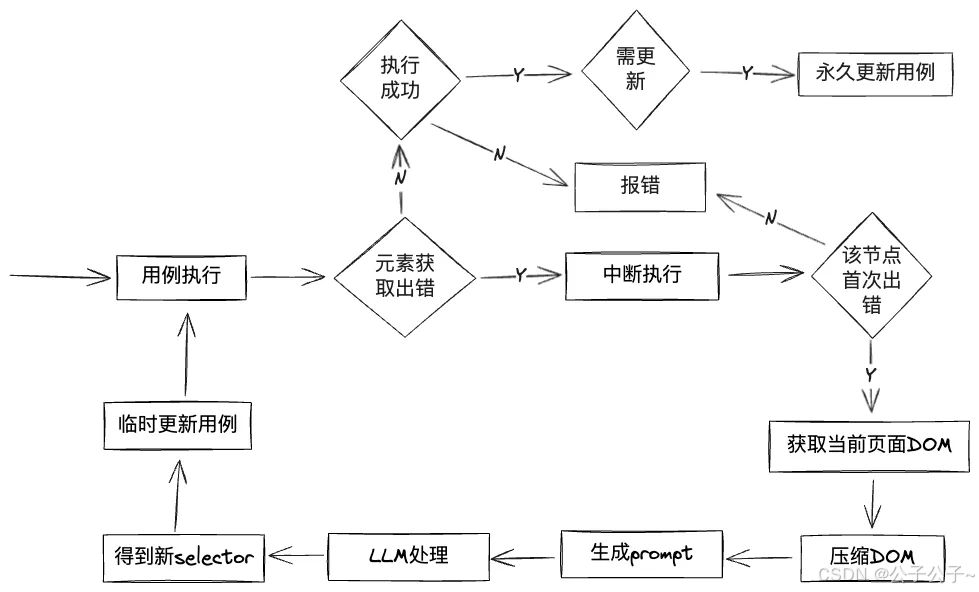
具体用例的执行就不在赘述,直接到“基于LLM的目标元素智能识别与用例自愈”的方案重点部分。该方案大致为:在用例执行中,若selector获取失败,则暂停执行,将页面dom、selector等信息交由LLM进行处理,让其识别出该“过时的”selector真正想获取的元素是什么,返回更新后的selector路径,然后更新相应用例并重新执行,达到“用例自愈”。
这里面也提到了一个问题:DOM压缩。在将信息输入LLM前,有一个很明显的问题:页面dom可能会很大,导致LLM处理时间很长,甚至可能直接超过LLM支持的大小上限。而哔哩哔哩给出的解决方式是dom压缩。

实际上原文的发表日期是2024年3月份,已经过去近一年,这一年里大模型的发展也是飞速迭代,比如更长的上下文、更强的语义理解。我相信他们现在的使用效果一定又上了新台阶。
以下是元素智能识别与用例自愈后的执行流程:
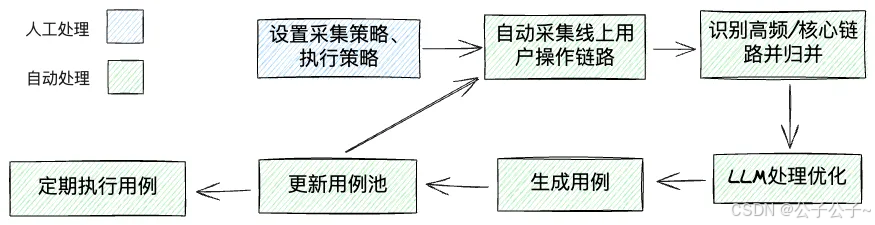
在展望方面,哔哩哔哩这类SaaS服务公司也提出自动采集用户操作生成用例的思路,页面最终是服务于线上用户的,他们的操作本身不就是最好的”用例“么?所以可以自动采集线上线上用户的真实操作链路,自动识别出高频链路、核心链路,自动归总为用例。
关注公众号【关于那些的个人观点】,发送消息“智能化测试”,获取完整内容PDF

















 845
845

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









