






文章目录
摘要
本周阅读了一篇基于残差LSTM的远距离语音识别模型的文章,文章使用残差LSTM,进一步提高了语音识别的准确率。此外,还对张量进行进一步的学习,通过欧式空间基和向量表示等铺垫,对度量张量和张量的表示进行初步的学习。
Abstract
This week, I read an article on a long-distance speech recognition model based on residual LSTM. The model further improves the accuracy of speech recognition. In addition, the tensor is further studied, and the representation of metric tensor and tensor is preliminarily studied through the preparation of Euclidean space basis and vector representation.
文献阅读
题目
Residual LSTM: Design of a Deep Recurrent Architecture for Distant Speech Recognition
引言
深度神经网络的出现从根本上改变了自动语音识别(ASR)的设计。基于神经网络的声学模型相对于现有技术的高斯混合模型(GMM)表现出显著的性能改进。递归神经网络(RNN)成功地应用于学习序列数据的长期依赖性。然而,由于梯度的消失或爆炸,训练深度神经网络是一个困难的问题。本文介绍了一种新highway架构的残差LSTM,减少了对时间梯度流的干扰,节省了超过10%的可学习参数。
方法
Revisiting Highway Networks
Residual Network(残差网络)
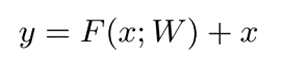
y是输出层,x是输入层,并且F(x; W)是具有内部参数W的函数。如果没有快捷路径,则F(x; W)应该表示来自输入x的y,但是具有单位映射x,F(x; W)只需要学习残差映射y − x。随着层的堆叠,如果不需要新的残差映射,网络可以在不进行训练的情况下绕过身份映射,这可以大大简化深度网络的训练。
Highway Network
Highway Network为深度神经网络提供了另一种实现快捷路径的方式。层输出H(x; Wh)乘以变换门T(x; WT),并且在进入下一层之前,高速公路路径x·(1-T(x; WT))。highway network可以概括为:
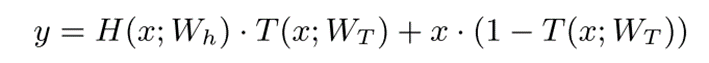
变换门定义为:
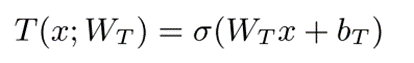
与残差网络不同,Highway Network的高速公路路径并不总是打开的。例如,公路网络可以忽略公路路径,如果T(x; WT)=1,或者当T(x; WT)=0。
LSTM
长短期记忆(LSTM)被提出来解决递归神经网络的消失或爆炸梯度。LSTM有一个内部存储单元,由遗忘和输入门控制。LSTM层中的遗忘门决定了应该将多少先前的内存值传递到下一个时间步。类似地,输入门将新输入缩放到存储器单元。根据两个门的状态,LSTM可以表示序列数据的长期或短期依赖性。LSTM公式如下:
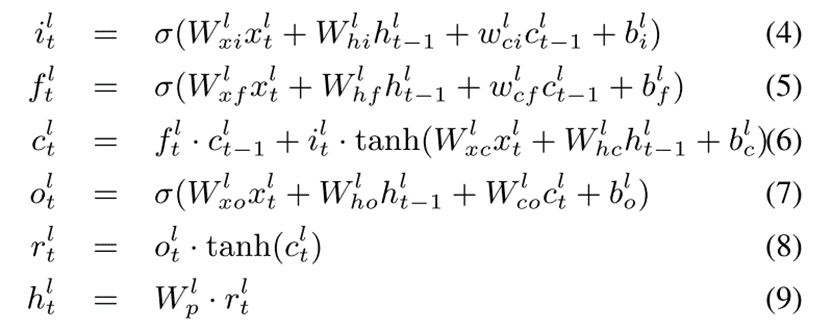
Highway LSTM
Highway LSTM重用LSTM内部存储单元用于堆叠LSTM层之间的空间域高速公路连接。对于高速公路LSTM,等式(4)、(5)、(7)、(8)和(9)不变。更新等式(6)以添加高速公路连接:
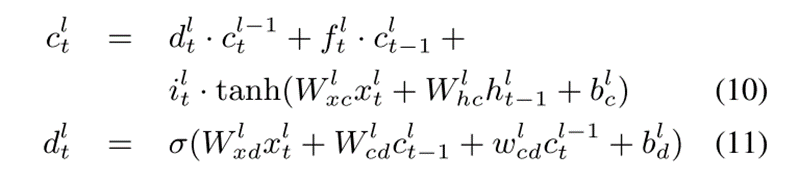
其中 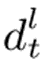 是将第(l-1)层中的
是将第(l-1)层中的 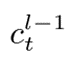 连接到第l层中的
连接到第l层中的 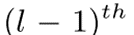 的深度门。结果表明,与普通LSTM网络相比,基于高速公路LSTM网络的声学模型改善了远场语音识别。但当高速公路LSTM网络中的层数从3增加到8时,字错误率(WER)会降低。
的深度门。结果表明,与普通LSTM网络相比,基于高速公路LSTM网络的声学模型改善了远场语音识别。但当高速公路LSTM网络中的层数从3增加到8时,字错误率(WER)会降低。
Residual LSTM
结构如下:

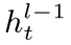 是从
是从 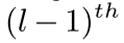 输出层添加到投影输出
输出层添加到投影输出 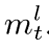 的捷径路径。虽然快捷路径可以是任何较低的输出层,但在本文中,我们使用了以前的输出层。对于残差LSTM,等式(4)、(5)、(6)和(7)不变。更新后的方程如下:
的捷径路径。虽然快捷路径可以是任何较低的输出层,但在本文中,我们使用了以前的输出层。对于残差LSTM,等式(4)、(5)、(6)和(7)不变。更新后的方程如下:
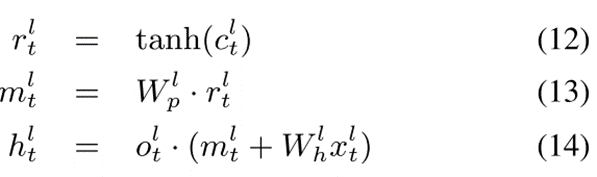
其中,如果 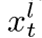 的维度与
的维度与 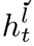 的维度匹配,则
的维度匹配,则 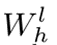 可以由单位矩阵代替。等式(14)可以变为:
可以由单位矩阵代替。等式(14)可以变为:
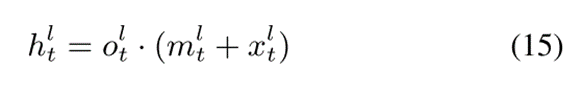
对于残差LSTM,输出门被重复使用,而没有任何额外的层或参数。输出门是一个可训练的网络,可以学习LSTM输出的适当范围。例如,如果输出门被设置为 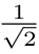 ,则
,则  输出层变为:
输出层变为:
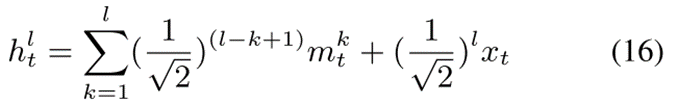
其中, 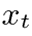 是在时间t时LSTM的输入。如果
是在时间t时LSTM的输入。如果 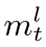 和
和 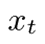 对于所有l彼此独立并且具有固定方差1,则不管层索引l如何,第l层输出的方差变为1。由于输出层的方差在真实的场景中是可变的,因此可训练的输出门将比固定的缩放因子更好地处理爆炸方差。
对于所有l彼此独立并且具有固定方差1,则不管层索引l如何,第l层输出的方差变为1。由于输出层的方差在真实的场景中是可变的,因此可训练的输出门将比固定的缩放因子更好地处理爆炸方差。
实验过程
MI会议语料库用于训练和评估残差LSTM。AMI语料库包括100小时的会议录音。
Kaldi是一个语音识别工具包,用于训练上下文相关的LDA-MLLT-GMM-HMM系统。经过训练的GMM-HMM生成强制对齐的标签,这些标签随后用于训练基于神经网络的声学模型。训练三个基于神经网络的声学模型:没有任何捷径路径的普通LSTM网络、高速LSTM网络和残差LSTM网络。三个LSTM网络都有1024个存储单元和512个输出节点。
计算网络工具包(CNTK)用于训练和解码三个声学模型。截断时间反向传播(BPTT)用于训练LSTM网络,每次截断20帧。交叉熵损失函数与L2正则化一起使用。
在解码时,使用精简的5万字Fisher词典作为词典,并基于该词典,从AMI训练文本中插值出三元语言模型。
实验结果
图2:AMI SDM语料库上的训练和CV PER。
(a)显示了3层和10层高速公路LSTM的训练和交叉验证(CV)交叉熵。
(b)显示了3层和10层残差LSTM的训练和交叉验证(CV)交叉熵。
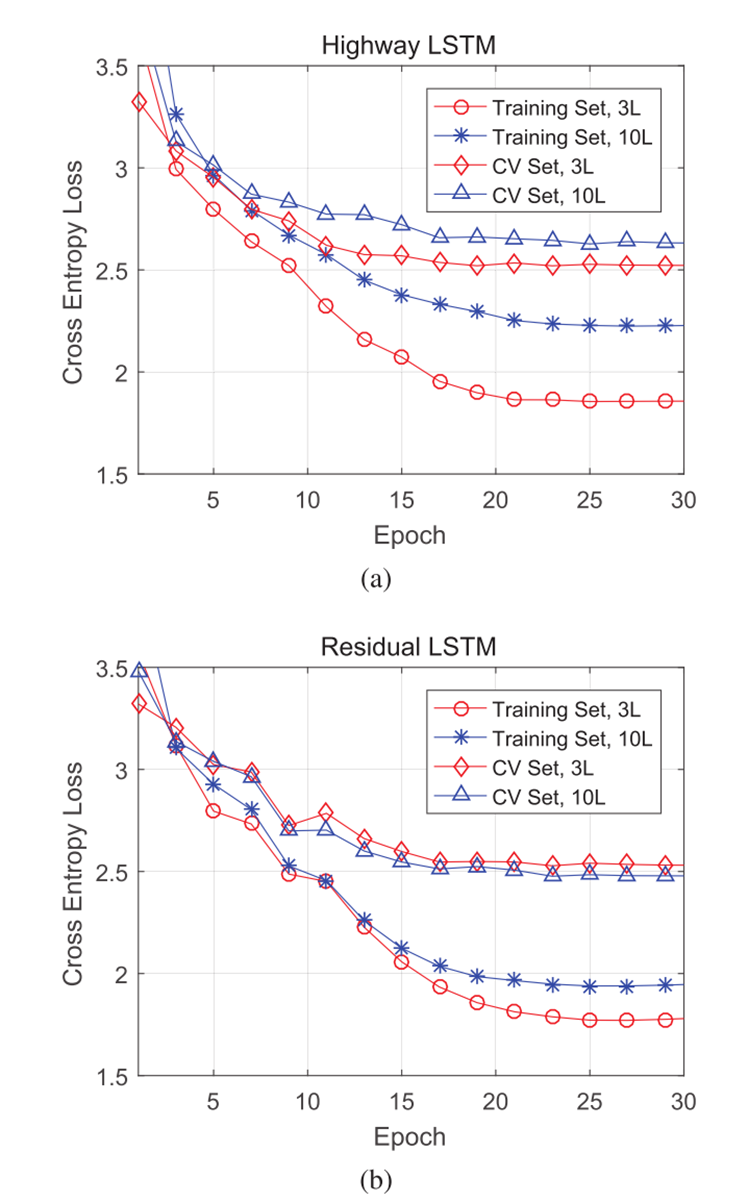
表1:所有三个LSTM网络具有相同大小的层参数:1024个存储单元和512个输出节点。当层数增加时,固定大小的层被堆叠起来。WER(over)是重叠WER,WER(non-over)是非重叠WER。
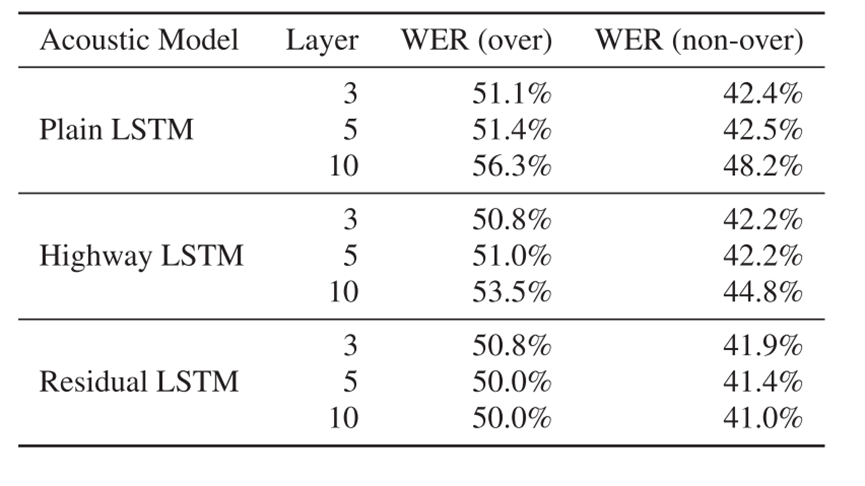
表2:利用组合的SDM和IHM语料库训练高速和残差LSTM。

张量
欧式空间中的基与克罗内克符号

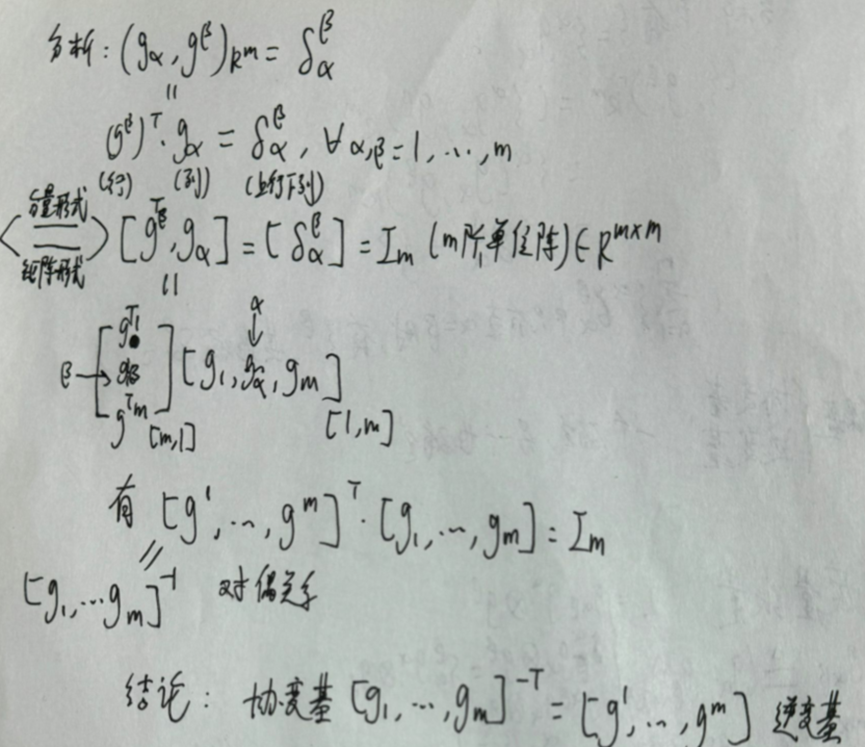
当为正交阵时,斜变基等于逆变基。
向量的表示

当同一个字母出现在一个上标和一个下标,此时为爱因斯坦求和约定,需要对乘积进行求和操作。

度量张量与指标升降游戏
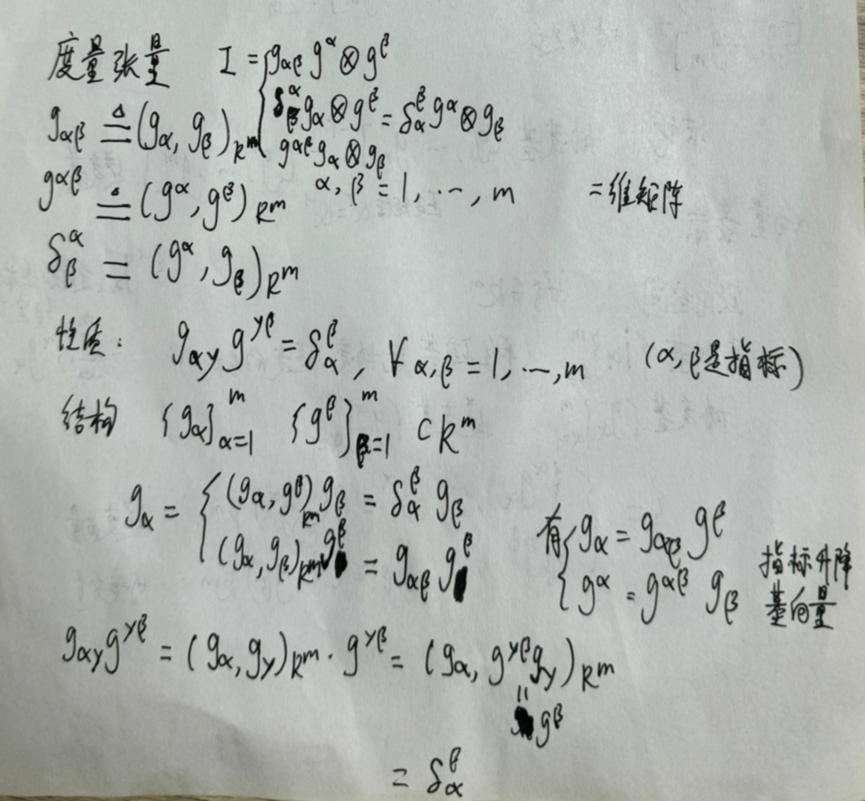

张量表示
有了以上的铺垫,最后进行简单张量表示:
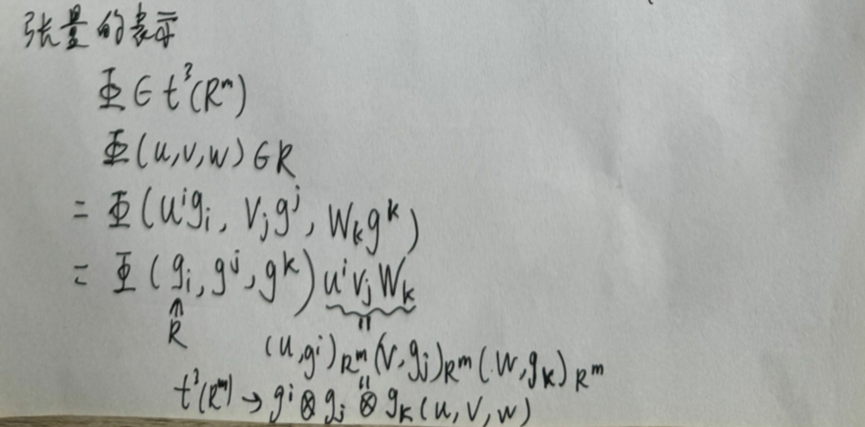
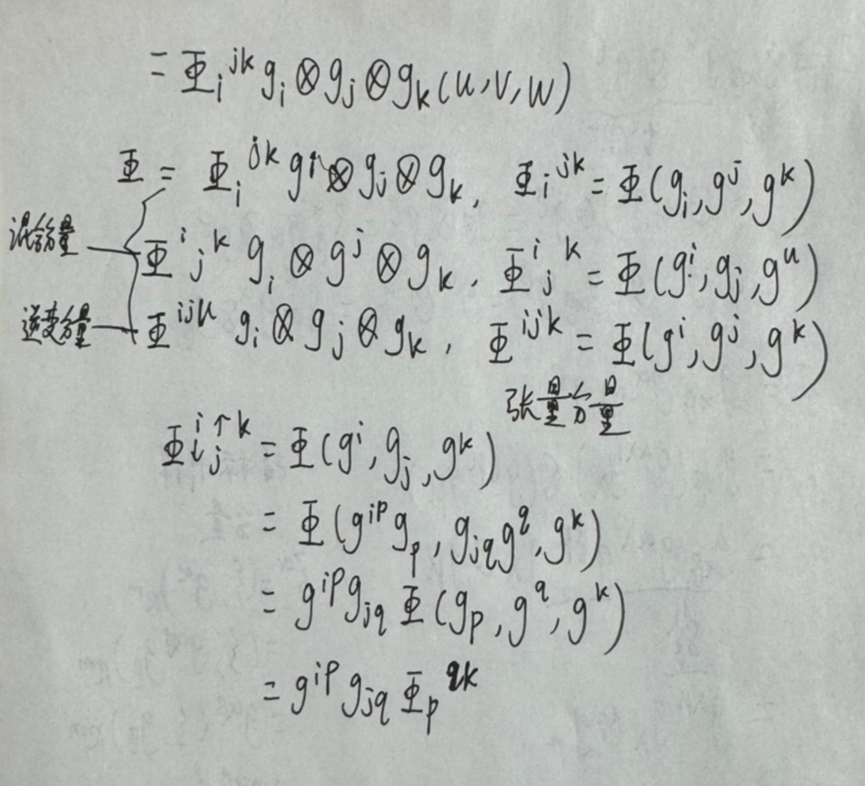
总结
本周阅读了一篇LSTM的文章,并对张量的概念进一步学习,下周将继续学习数学知识和阅读相关文献。















 826
826











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









