







前言
截止到24年年底,在过去的这两年,工作之余,我狂写大模型与具身的文章,加之具身大火,每周都有各种朋友通过CSDN私我及我司「七月在线」寻求帮助/指导(当然,也欢迎各大开发团队与我司合作共同交付):
- 要么是做科研想复现,一类是各种机械臂:mobile aloha、umi、dexcap、rekep、RDT,一类是各种人形:humanplus、idp3
- 要么是工厂想做自动化生产线的智能升级,比如物料分拣、智能装配、线缆插拔、打螺钉等
- 要么是想通过机械臂/人形解决各种业务场景问题,比如最简单的端茶倒水
让我感慨:二零一一年,因为算法,首次有「天下无人不识君」的感觉,过去这两年,因为大模型和具身机器人,再次有了这感觉
具身的论文解读过很多之后,便会发现整个今24年的具身模型/策略大概如下所示——目前全网独一份「(建议按照从下至上的顺序看,且所有点我都做了详尽而细致的解读,点击下表中对应的文字即可阅读,我后续也会不断完善之——毕竟还有很多并未囊括于下表中,如转载请于文章开头标明作者July及本文链接」
因为原表太大,后来把其拆分独立成文了,详见《一次性总结数十个具身模型(2024-2025):从训练数据、动作预测、训练方法到Robotics VLM、VLA(如π0等)》
越往后越会发现
- 大模型和机器人的融合会越来越深入、彻底,很多大模型的技术会加速嵌入至机器人中
- 所以说,如果懂大模型对搞具身智能是好处多多的(包括本文涉及的RLHF,如果深入搞过大模型的话,则会和我一样 太熟悉不过了——毕竟两年前,我就是从开写ChatGPT及背后的RLHF开卷的,而写本文时,是在24年12.31日凌晨,真是与23年年初开写ChatGPT原理解析,遥相呼应,算是给这两年弄上一个完美的纪念),建议大家好好学,^_^
到了25年3月底时,我司「七月在线」具身团队并行开发的B端具身订单越来越多了,便持续做以下这两点:
- 针对某个落地场景挑选模型/方法论
- 改进、改造模型/方法论
而场景一多,便会研读各种模型,顺带解读,在解读dexvla的过程中「详见此文《机器人大小脑的融合——从微调VLM起步的VLA发展史:详解RoboFlamingo、Octo、TinyVLA、DexVLA》的第4部分」发现一个Re-VLA的工作还挺有意思的,借鉴deepseek的RL训练llm,RL训练具身vla,故更在了本文第二部分
第一部分 GRAPE:通过偏好对齐提升机器人策略的泛化能力
1.1 GRAPE的提出背景与相关工作
1.1.1 提出背景
近年来,视觉-语言-动作(VLA)模型的快速发展简化了一般的机器人操作任务,在受控环境变化的一系列任务中展示了令人印象深刻的能力
然而,这些模型面临几个关键挑战,例如在新环境、对象、任务和语义上下文中的泛化能力差[26-Openvla]。导致这一限制的一个重要因素是它们依赖于监督微调(SFT),即VLA通过行为克隆简单模仿成功演练的动作,而未能对任务目标或潜在失败模式形成整体理解[27-Should i run offline reinforcement learning or behavioral cloning?]
- 虽然像PPO[42]这样的强化学习(RL)算法在增强其泛化能力方面表现出色[52-Fine-Tuning Large Vision-Language Models as Decision-Making Agents via Reinforcement Learning],但收集足够的在线轨迹和明确定义奖励的高成本使其在训练VLA时不切实际[44-Octo]
- 此外,训练VLA仅仅复制专家行为通常会导致行为崩溃[28-Training language models to self-correct via reinforcement learning,即通过强化学习进行自我纠正,详见此文的2.3 Self-Correct之SCoRe:通过多轮强化学习进行自我纠正],即计划的轨迹往往次优[26-Openvla]
这是因为SFT数据集通常未经策划,由从专家处收集的离线演示组成,这些演示隐含地嵌入了不同的价值观(例如任务完成、安全性和成本效益),而这些并未在数据中明确定义[36-Open x-embodiment,45-Bridgedata v2]
总之,简单地通过SFT模仿这些行为可能会混淆模型,并导致次优-偏离演示实际目标的恶意轨迹 - 一些方法试图通过明确定义一组目标并分层解决它们来应对这一挑战 [24-Rekep,详见此文《ReKep——李飞飞团队提出的让机器人具备空间智能:基于VLM模型GPT-4o和关系关键点约束(含源码解析)》]。然而,这种方法会带来额外的推理开销,并且缺乏可扩展性 [30-HAMSTER: Hierarchical action models for open-world robot manipulation]
为了解决这些问题,24年11月,来自北卡罗来纳大学教堂山分校和华盛顿大学的研究者提出了GRAPE(Generalizing Robot Policy via Preference Alignment):通过偏好对齐来泛化机器人策略,以减轻使用强化学习目标训练VLA的高成本,同时提供灵活性以实现定制化操控目标的对齐
- 其对应的项目地址为:grape-vla.github.io
其对应的论文为:《GRAPE: Generalizing Robot Policy via Preference Alignment》
论文一作为北卡罗来纳大学教堂山分校张子健,指导老师为北卡罗来纳大学教堂山分校助理教授 Huaxiu Yao,共同第一作者为华盛顿大学 Kaiyuan Zheng
其余作者包括来自北卡教堂山的 Mingyu Ding、来自华盛顿大学的 Joel Jang、Yi Li 和Dieter Fox,以及来自芝加哥大学的 Zhaorun Chen、Chaoqi Wang - 如下图图2所示,GRAPE引入了轨迹偏好优化(trajectory-wise preference optimization,简称TPO),通过隐式建模成功和失败试验的奖励,在轨迹层面对VLA策略进行对齐,从而提升对多样化任务的泛化能力

具体而言
1) 给定一个复杂的操作任务(顶部),GRAPE首先采用视觉语言模型——比如HAMSTER将任务分解为几个时间阶段,然后识别每个阶段子任务完成所需的空间关键点
Given a complex manipulation task (top), GRAPE first adopts a vision-language model to decompose thetask into several temporal stages, then identifies spatial keypoints essential for each stage’s subtask completion.
具体而言
首先将包含prompt——比如pick up the grape..和初始状态的图文对输入到视觉语言模型(VLM)Hamster [30]中。利用Hamster生成的阶段信息和阶段点,对收集的轨迹进行了分段。这有助于更精确地分析复杂任务序列,详细关注每个阶段
这些关键点与作者自收集的轨迹数据相结合,使作者能够根据Hamster模型生成的阶段信息优化任务的执行步骤和路径规划
例如,对于一个简单的抓取和放置任务,可以将其分解为多个明确的阶段:抓住葡萄,将葡萄移动到盘子上,将葡萄放在盘子上
2) 然后,给定用户指定的对齐目标「包括:碰撞约束:确保机器人避免与障碍物碰撞。路径约束:优化机器人的运动路径的效率和安全性」,GRAPE提示一个强大的视觉语言模型比如GPT4o——为每个阶段获得一系列成本函数(准确的说,生成每个阶段的详细操作信息和成本函数),其中较低的成本意味着更高的对齐合规性
Then given user-specifiedalignment goals, GRAPE prompts a powerful vision-language model to obtain a series of cost functions for each stage, where lower costimplies higher alignment compliance.
3) 在迭代偏好优化过程中(底部),作者从基础VLA模型中采样多个离线轨迹(一般轨迹条数定义为),并获得具有相关多阶段成本的轨迹。该评分进一步结合了模型对每条轨迹的自我评估和二元任务成功指示器
During iterative preference optimization (bottom), we sample multiple offline trajectories from thebase VLA model and obtain trajectories with associated multi-stage costs. This score further incorporates the model’s self-evaluation ofeach trajectory and a binary task success indicator.
4) 再之后,根据采样轨迹的相应得分对其进行排名,以获得偏好列表——每个任务中奖励最高的轨迹为,奖励最低的轨迹为
Then we rank the sampled trajectories with their corresponding scores to obtain a list ofpreferences.
5) 最后,执行轨迹偏好优化以获得改进的模型,从中进一步采样在线轨迹并迭代直到收敛
Then we perform a trajectory-wise preference optimization to obtain a improved model, from which we further sample onlinetrajectories and iterate until convergence - 且为了进一步缓解轨迹排序和提供任意对齐目标偏好的难度,GRAPE建议将复杂的操控任务分解为多个独立阶段,并采用大型视觉模型为每个阶段提出关键点,每个关键点都与时空约束相关
值得注意的是,这些约束是灵活的,可以定制以使模型与不同的操控目标对齐,例如任务完成、机器人交互安全性和成本效益
1.1.2 相关工作:VLA、强化学习与偏好优化
第一方面,先前的机器人学习工作[14,23-Voxposer,24-Rekep,30-HAMSTER,31-Code as policies,34-Robocodex,35-Embodiedgpt]通常采用分层规划策略
例如,Code asPolicies[31]和EmbodiedGPT[35]采用LLMs和VLMs首先生成一系列高层次的行动计划,然后进一步利用低层次的控制器来解决局部轨迹
然而,这些模型存在低层次技能有限的问题,难以推广到日常任务中
好在VLA通过将大型视觉语言模型作为骨干并直接在模型内生成动作,倾向于扩展低层次任务。它们通常通过两种主流方法实现动作规划:
- 动作空间的离散化 [6-Rt-1,7-Rt-2,26-Openvla],例如 Open-VLA [26],它保留了自回归语言解码目标,并将动作空间均匀地截断为一小组动作token
由于这种离散化不可避免地引入误差,一些方法如π0 [4-π0,详见此文《π0——用于通用机器人控制的VLA模型:一套框架控制7种机械臂(基于PaliGemma和流匹配的3B模型)》] 采用更新的结构 [53-Transfusion] 并直接集成扩散头diffusion head进行动作预测,以避免离散化 - 扩散模型[2,16-Diffusion policy,18-Diffusion models beat gans on image synthesis,25- Planning with diffusion for flexible behavior synthesis,32-Adaptdiffuser,49-Chaineddiffuser]——如 Diffusion Policy [16]作为动作头,不是每次生成一个逐步的动作,而是通过几个去噪步骤生成一系列未来动作
虽然这些模型在结构上有所不同,但它们始终通过行为克隆对成功的展开进行监督训练(they are consistently supervised-trained on successful rollouts via behavior cloning),这很难推广到未见过的操作任务
然而,我们的GRAPE首先通过试错在轨迹层面对VLA策略进行对齐,有效提高了可推广性和可定制性
第二方面,强化学习RL
- [17-2017年6月OpenAI联合DeepMind首次正式提出的:Deep Reinforcement Learning from Human Preferences,即基于人类偏好的深度强化学习,简称RLHF,详见此文《ChatGPT技术原理解析:从RL之PPO算法、RLHF到GPT4、instructGPT》,
- 42-PPO「详见此文《强化学习极简入门:通俗理解MDP、DP MC TC和Q学习、策略梯度、PPO》的第4部分」,
- 56-Fine-Tuning Language Models from Human Preferences,OpenAI进一步阐述RLHF的文章]
在SOTA基础模型(FMs)的后训练中发挥着关键作用,包括
- 文本生成模型[1-GPT4,12,15,19-The llama 3 herd of models,39- Training language models to follow instructions with human feedback,即instructGPT,详见上面刚提到过的ChatGPT原理解析]
- 图像生成模型[13- Mj-bench: Is your multimodal reward model really a good judge for text-toimage generation?,20-DPOK: Reinforcement Learning for Fine-tuning Text-to-Image Diffusion Models]
- 视频生成[50- Cogvideox: Text-to-video diffusion models with an expert transformer]
这些模型通过偏好数据的嵌入被广泛用于使预训练的FMs与人类价值观对齐
同时,RL在训练机器人任务的策略方面也取得了巨大成功
- [10-Decision transformer: Reinforcement learning via sequence modeling,
- 11-Towards human-level bimanual dexterous manipulation with reinforcement learning,
- 14- Safe reinforcement learning via hierarchical adaptive chanceconstraint safeguards,
- 42-PPO,47-EscIRL: Evolving self-contrastive IRL for trajectory prediction in autonomous driving,
- 48- Unidexfpm: Universal dexterous functional pre-grasp manipulation via diffusion policy,55-Dexterous manipulation with
- deep reinforcement learning: Efficient, general, and lowcost]
尽管直观上通过RL后对齐VLA是有益的,但之前的工作尚未报告这样的成功,主要是因为
- 操作目标通常多样且复杂,使得奖励难以进行分析性定义[21];
- 虽然这种奖励可以从人类偏好中建模,但在机器人操作任务中标注此类偏好通常耗时复杂,且需要人类专业知识[45]
- 奖励的不完美数值微分通常会导致RL算法——如PPO[42] 崩溃[8-Reinforcement learning for control: Performance, stability, and deep approximators]
然而,最近的一些研究[40- Direct preference optimization: Your language model is secretly a reward model,详见《RLHF的替代之DPO原理解析:从RLHF、Claude的RAILF到DPO、Zephyr》,46-Preference optimization with multi-sample comparisons]显示了无需这种显式奖励建模即可直接通过RL对策略进行对齐的成功
受此启发,GRAPE通过对比轨迹来对齐策略,从而避免了奖励建模中的数值问题。此外,作者引入了一种自动偏好合成管道,可以轻松扩展到各种操作任务,并能够适应不同的对齐目标
1.2 通过偏好对齐来推广机器人策略
在推理过程中,VLA 通常以任务指令 初始化,并且在每个时间步
,它接收环境观察
(通常是一张图像)并输出一个动作
,如此可以将
表示为由
参数化的VLA 的动作策略
为了完成任务,VLA 与环境反复交互并获得长度为 的轨迹
。通常,VLA通过SFT 进行微调以模仿专家行为(定义为方程1):
其中,表示包含
个专家轨迹的训练集,具体来说,
迫使VLA 记住从分布
中采样的每个观察相关的动作,导致对新任务环境的泛化能力较差
值得注意的是,虽然遵循Brohan 等人[7-Rt-2] 和O’Neill 等人[36-Open x-embodiment] 的做法,并基于马尔可夫决策过程MDP假设[43-Richard S Sutton. Reinforcement learning: An introduction. A Bradford Book, 2018] 考虑逐步策略
- 但作者的方法可以很容易地适应非MDP 情况,该情况将过去的交互历史(通常是视频或一系列图像)作为状态[9-Gr-2,详见此文《字节GR2——在大规模视频数据集上预训练且机器人数据上微调,随后预测动作轨迹和视频(含GR1详解)》]以及扩散策略[16-Diffusion policy]
- 其一次生成多个未来步骤[44-Octo]「which takes past interaction histories (usually a video or a series of images) as state [9] and diffusion policy [16] which generates multiple futuresteps all at once [44]」
1.2.1 TPO:轨迹偏好优化(直接用的DPO的思想)
先来进一步解释下图中右下角的Trajectory-wise Preference Optimization

为了提高泛化能力,作者遵循
- Bai等人[3-Training a helpful and harmless assistant with reinforcement learning from human feedback,相当于早在2022年4月份,目前OpenAI最大的竞争对手Ahthropic就发了其LLM论文:Training a Helpful and Harmless Assistant with Reinforcement Learning from Human Feedback,这篇论文和OpenAI的instructGPT论文极其相似 (如果你之前还没看到instructGPT论文,或者尚不了解ChatGPT的三阶段训练方式,强烈建议先看此文:ChatGPT技术原理解析:从RL之PPO算法、RLHF到GPT4、instructGPT),也就比后者晚发布40多天]
- Schulman等人[42-Proximal policy optimization algorithms,即PPO算法的工作
并通过RL目标进一步微调VLA策略
- 令
表示由
参数化的奖励函数,从而有(定义为方程2)
其中,控制与通过SFT 在方程(1) 中训练的基础参考策略
的偏差,
是在指令
下策略
生成整个轨迹
的可能性
- 然后作者遵循Rafailov 等人的方法[40-Direct preference optimization: Your language model is secretly a reward model,即DPO,详见此文《RLHF的替代之DPO原理解析:从RLHF、Claude的RAILF到DPO、Zephyr》],推导出轨迹奖励
的解析重参数化为(定义为方程3)
- 类似于Rafailov 等人[40-即DPO],作者采用Bradley-Terry(BT) [5-Rank analysis of incomplete block designs: I. the method of paired comparisons] 模型,并从一组带有偏好排序的轨迹中对
具体来说,令和
分别表示从相同初始状态开始的被选择和被拒绝的轨迹,可以将轨迹奖励建模目标公式化为(定义为方程4)
- 然后,我们遵循Rafailov等人DPO[40]的方法,将公式(3)代入公式(4),得到如下轨迹偏好优化(TPO)损失
,相当于公式(2)——定义为方程5
- 然后可以进一步从MDP中提取,并将轨迹
且进一步获得(定义为方程6)
最后,可以将方程(6) 代入方程(5),以获得逐步状态-动作对形式的TPO 损失
最终得到的TPO损失方程6是有益的,因为它:
- 通过简单地使用VLA收集的逐步回合,将策略
在轨迹级别上全局对齐到人类偏好
- 通过在整个轨迹的状态-动作对中反向传播梯度,稳定策略并引导其朝向最终目标
- 通过通过RL目标从成功和失败的轨迹中学习,显著提升泛化能力。尽管Finn等人[21-Guided cost learning: Deep inverse optimal control via policy optimization]指出,扩大采样轨迹的规模可以减少奖励建模中的偏差,但这也增加了训练成本
因此,虽然作者的方法可以轻松扩展,但作者还是建议将讨论限制在仅存在一个选择/拒绝轨迹的二进制情况
1.2.2 引导成本偏好生成:Guided-Cost Preference Generation(GCPG)
然后,再来进一步解释下图右上角,及下图底部的中间部分:目标对齐下的多阶段成本、模型自我奖励、任务是否成功的二元指示器
虽然在给定 TPO 目标方程(5)的情况下,可以通过根据相应偏好排序的轨迹来对策略进行任意目标的对齐,但这会产生很高的成本,因为它需要人类专业知识和冗长的手动注释
因此,为了更好地扩展偏好合成以实现任意对齐目标(例如任务完成、安全性、效率),作者提出引导成本偏好生成 (GCPG),以自动策划集成不同对齐目标的此类偏好「we propose Guided-Cost Prefer-ence Generation (GCPG) to automatically curate such pref-erences that integrate different alignment objectives」
首先,针对多阶段时间关键点约束(Multi-Stage Temporal Keypoint Constraints)
- 基于Huang 等人[24-Rekep,详见《ReKep——李飞飞团队提出的让机器人具备空间智能:基于VLM模型GPT-4o和关系关键点约束(含源码解析)》] 的见解,作者通过将轨迹分解为时间阶段,并为每个阶段分配成本以量化性能,来解决复杂操作任务中指定精确轨迹偏好的复杂性
- 然后,聚合这些特定阶段的成本,以获得对每个轨迹的整体评价
具体来说,采用基于VLM 的阶段分解器(更多详见附录A),将轨迹
划分为一系列
连续阶段,公式化为(定义为方程7)
其中 表示轨迹
的第
阶段
- 在获得阶段分解后,作者进一步使用视觉-语言模型「例如DINOv2 [37]-详见此文《从DINO、DINOv2到DINO-X——自监督视觉Transformer的升级改进之路(基于ViT)》的第二部分」来识别在各个阶段作为参考指标的关键点
- 然后,作者提示一个强大的LLM [1-GPT4o] 为每个阶段提出多个成本函数(参见附录E.2 中的示例),这些函数与对齐目标相对应,其中较低的成本表示更好的目标符合性
- 接着,在阶段
的成本
被公式化(定义为方程8)
其中
表示在阶段
计算的第
个成本
是一个可调的阈值参数,来调整每个成本的容忍度——只有当成本超过阈值时才会应用
是一个权重参数,用于调整每个成本的重要性
- 最后,为了汇总整个轨迹的成本,作者不是线性地对每个阶段求和,而是应用指数衰减来捕捉每个时间阶段的因果依赖关系(例如,如果一个轨迹在前面的阶段产生了高成本,则不期望其随后表现良好)
定义为外部奖励(是为方程9)
其中,方程9汇总了每个阶段的个体成本和子目标,以应对维度灾难,并有效地遵循定制化的对齐方式
其次,针对引导成本偏好生成
为了进一步提高偏好合成的稳定性和最优性,作者从自我奖励[54- Calibrated self-rewarding vision language models]中获得灵感,并确定更优的轨迹应该由外部评判「如公式(9)所示」和模型本身确认
因此,作者加入了两个额外的奖励并获得了GCPG奖励
- 首先是方程10——相当于是对方程9 11 12的汇总
其中是由π 提供的自评得分,其等于生成轨迹
- 其次是,
——一个二元指示函数,指示轨迹
其中是调整每个奖励重要性的权重参数
直观上,方程(11) 可以看作是方程(12) 所提供的稀疏信号的密集近似,这些信号通过方程(9) 进一步校准,以获得对轨迹的整体评估,该评估既考虑其最优性,又考虑通过方程(9) 中的外部奖励指定的定制目标的对齐程度
1.2.3 迭代偏好优化Iterative Preference Optimization
最后,再解释下图最右下角的迭代优化过程
在生成偏好之后,接着讨论迭代偏好优化策略。受在线策略强化学习[42-PPO]实践的启发,这些实践通常比离线训练产生更优的策略
故作者通过在线收集的轨迹使用TPO迭代微调SFT VLA模型
例如,在第 次迭代中

- 首先为各种任务采样大量轨迹并获得
- 然后使用公式(10)计算每条轨迹的成本,并根据每个任务对这些轨迹进行排序
- 将每个任务的前
和后
个选择-拒绝轨迹对
- 然后通过公式(5) 使用TPO 微调相同的采样策略,获得更新后的策略
重复这一过程K 次,并获得与目标目标对齐的最终模型
对了,作者在算法1 中详细介绍了GRAPE迭代偏好优化过程
至此,可能你也看出来了,其实GRAPE
更像Ahthropic的Claude的训练方式——RAIHF「详见此文《RLHF的替代之DPO原理解析:从RLHF、Claude的RAILF到DPO、Zephyr》的1.3 节Claude的两阶段训练方式:先监督微调 后RAIHF」
为何这么说呢?因为GRAPE的本质质是类似 给VLA上RLAIF,这个AI即GPT4o在对齐目标的前提下计算各个轨迹的成本,然后根据计算结果自动排序(不像RLHF 得人工对结果做排序),根据排序结果选择优-差对做DPO优化,所以可以不断刺激机器人选择更优的运动策略——从而不断优化机器人的运动轨迹


第二部分 GRAPE的数据设置、及实验设置
2.1 实验数据集
2.1.1 现实世界数据集
对于SFT数据集,在真实世界机器人实验中,作者使用一个由Franka机器人手臂和Robotiq夹持器组成的机器人平台进行数据收集
- 为了确保数据收集和评估的一致性,所有操作都在相同的实验环境中进行
在数据收集过程中,收集了220个包含常见物体(如香蕉、玉米、牛奶和盐)的抓取和放置任务的数据集 - 此外,收集了50个涉及按下不同颜色按钮的任务的数据。由于用于按钮按压任务的物体数量有限,在测试阶段引入了背景噪音和干扰物体,以创造未见过的场景
且为了进一步增强OpenVLA处理不同动作的能力,还收集了50个推倒任务的数据
这些多样化的任务数据集有助于提高模型在处理不同类型动作时的泛化能力
对于TPO数据集,在真实世界实验中,使用通过OpenVLA在真实世界SFT数据集上微调的模型进行轨迹采样
每个任务进行了五次。在TPO数据集中,实验了15个不同的任务,包括10个抓取和放置任务、3个按钮按压任务和2个推倒任务,共计75个数据条目。经过选择过程,得出一个由30个轨迹组成的偏好数据集
2.1.2 仿真数据集
对于SFT 数据集,对于 Simpler-Env,SFT 数据集包括 100 条轨迹,总计约 2,900 个转换。这些回合是使用 Octo 从Simpler-Env 生成的,遵循 Ye 等人 [51] 中描述的方法
值得注意的是,LIBERO并没有收集新的数据,也没有对OpenVLA模型进行微调。相反,作者直接使用OpenVLA团队提供的OpenVLA-SFT模型,这显著简化了流程
对于TPO数据集,在Simpler-Env的情况下,每个任务的轨迹都是使用OpenVLA-SFT模型采样的,每个任务进行五次试验。这个过程产生了一个包含80条轨迹的TPO数据集
对于LIBERO,使用OpenVLA-SFT模型(每个任务一个模型)在LIBERO中的四个任务中进行数据采样。对于每个任务,每个子任务采样五条轨迹,最终形成一个包含总共20条轨迹的TPO数据集
2.2 实验设置
作者采用OpenVLA [26] 作为基础模型,使用LoRA 微调和AdamW 优化器进行监督和偏好微调。在监督微调阶段,作者使用学习率4 × 10−5,批量大小为16
对于偏好微调应用学习率2 × 10−5,使用相同的批量大小。有关训练过程和数据集的更多详细信息,请参见附录A 和B
在基线模型的选择上,作者将GRAPE与两个在机器人控制任务中以强大性能著称的领先机器人学习模型进行比较
- 第一个模型是Octo [44-详见此文《从Octo、OpenVLA到TinyVLA、CogACT——视觉语言动作模型VLA的持续升级(RT-2和π0在其他文章介绍)》],一个基于大型transformer的策略模型
- 第二个模型是OpenVLA [26,详见此文],一个7B视觉-语言-动作模型
这两个模型均使用从相应环境中采样的相同数据集进行了监督微调。作者分别将监督微调后的模型称为Octo-SFT和OpenVLA-SFT
2.1.1 在真实世界机器人环境中的评估
在真实世界实验中,GRAPE在各种任务中显著优于其他模型
- 值得注意的是,在领域内任务中,GRAPE达到了67.5%的成功率,比OpenVLA-SFT的45%提高了22.5%,且远高于Octo-SFT的20%
- 此外,在视觉泛化任务中,GRAPE展示了更高的适应性,成功率为56%
- 在更具挑战性的动作泛化任务中,尽管OpenVLA-SFT表现尚可,但GRAPE仍优于OpenVLA-SFT,显示了其理解各种动作和基于语言执行命令的潜力
综合所有类别的任务,GRAPE的总平均成功率为52.3%,比OpenVLA-SFT的33.3%提高了19%,且远高于Octo-SFT的5.8%。这一表现突出了GRAPE在处理复杂和多变任务环境中的有效性和高适应性
2.1.2 奖励模型的消融研究
在本节中,作者进行消融研究以分析方程10中每个奖励组件的贡献
最终性能的评估对象包括:外部目标对齐奖励,自我评估奖励
,以及成功指示器
此外,还进行了一项单独的消融研究,以强调使用整个奖励得分进行偏好选择的重要性。该方法与随机选择一个成功轨迹作为首选轨迹和一个失败轨迹作为拒绝轨迹的方法进行了比较
Simpler-Env 环境中的结果在下表表1 中报告

结果表明:
- 将完整的奖励评分方程(10) 用于偏好排序相比仅基于成功的随机选择显著提高了性能;
- 所有奖励组件都有助于提高模型性能。这些发现与预期一致
具体来说,Rself (ζ) 通过鼓励模型选择具有更高生成概率的轨迹来增强GRAPE 模型的稳健性。同时,Rext (ζ) 引导模型学习特定行为,如安全性和效率。最后,Isuccess (ζ) 起到作为一个关键指标的作用,引导模型优先考虑成功的轨迹
总之,GRAPE通过从成功和失败的尝试中学习来增强泛化能力,并通过定制的时空约束提供与安全性、效率和任务成功等目标对齐的灵活性
实验结果表明,GRAPE在域内和未见任务上显著提高了成功率,同时实现了灵活的对齐。虽然GRAPE在泛化和对齐灵活性方面表现出显著的改进,但它也有一些局限性
- 首先,对偏好排序的依赖需要足够多样化的轨迹,这可能限制在仅有有限任务设置的场景中的应用
- 其次,虽然GRAPE支持可定制的对齐,但特定目标的阈值参数的手动调整可能引入主观偏见,并需要领域专业知识。未来的工作可能会探索更高效和自动化的偏好合成和适应方法
// 待更
第三部分 Re-VLA:通过在线强化学习改进VLA模型
3.1 Re-VLA的提出背景与相关工作
3.1.1 Re-VLA的提出背景及其定义
最近,使用强大的预训练大型语言模型(LLM)和视觉语言模型(VLM)来完成超出其原始范围的各种高级任务已成为一种趋势,包括对话系统[1],[2], [3],代码生成[4],任务规划[5], [6],甚至是低级机器人控制[7], [8]
- 通过在机器人数据集上对VLM进行显式动作建模的微调,先前的研究开发了大型视觉语言动作(VLA)模型[9],如RT-2[8],HiRT[10],Roboflamingo[11]等。这些模型能够直接输出低级机器人控制信号,同时还能受益于大型预训练模型中编码的常识知识和推理能力[12]
- VLA 模型的微调通常采用监督微调 (SFT) 方法[8],以其稳定性和可扩展性而闻名。然而,SFT 依赖于高质量的专家数据集,这些数据集在机器人领域中成本高且难以获得 [13]
此外,由于分布偏移问题 [14], [15],监督学习可能无法完全将 VLA 模型与物理环境对齐
那如何通过与物理环境的交互超越监督学习进一步改进如此大的 VLA 模型呢?
值得注意的是,人类反馈强化学习 (RLHF) [1-instructGPT], [16-Learning to summarize from human feedback],[17-Deep reinforcement learning from human preferences] 已经更好地将大型语言模型与人类偏好对齐
关于instructGPT、chatgpt、RLHF等相关的原理,看此文《ChatGPT技术原理解析:从RL之PPO算法、RLHF到GPT4、instructGPT》即够,让你一次性通透
如图 1 左上角所示
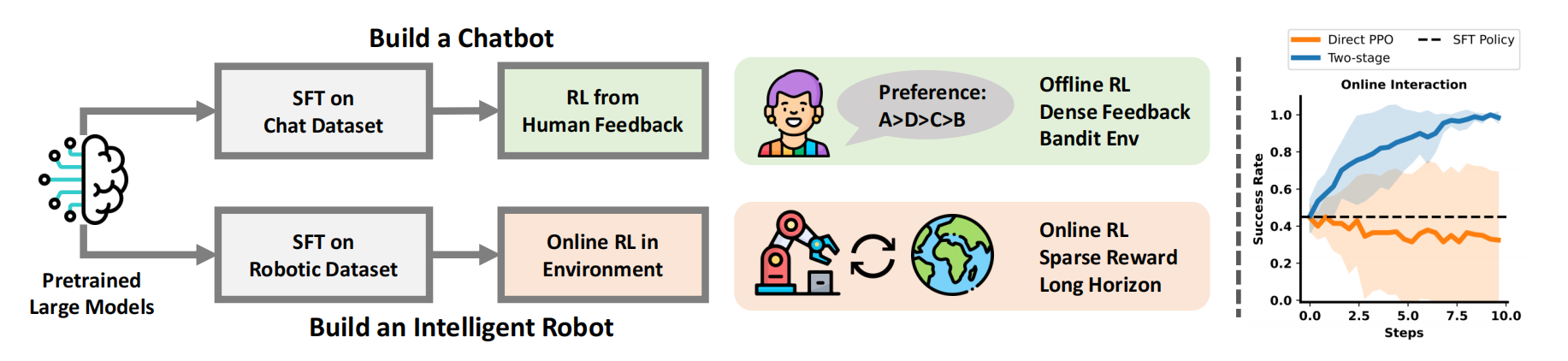
受到 RLHF 成功的启发,25年1月份,来自1 清华大学交叉信息研究院、2 加州大学伯克利分校、3上海市智造研究院的研究者们提出Re-VLA,其对应的论文为《Improving Vision-Language-Action Model with Online Reinforcement Learning》
他们尝试在线 RL 来改进 VLA 模型并更好地将 VLA 模型与物理环境对齐。然而,聊天机器人和具身机器人遇到的环境有显著不同
- 聊天机器人使用具有明确动态的离线人工标注数据集进行优化 [1],而具身机器人需要在具有长时间跨度和稀疏奖励特征的任务中进行在线探索
- 此外,以往的研究表明,将在线强化学习 (RL) 过程应用于大型神经网络时可能会非常不稳定 [18], [19], [20]
从经验上看,我们还观察到直接将标准 RL 算法应用于大型 VLA模型会导致训练不稳定性和性能下降,如图 1右侧所示
为了稳定 RL 过程并有效增强 VLA模型,故提出的新颖的 iRe-VLA 方法,该方法在线强化学习阶段和监督学习阶段之间交替迭代
具体而言
- 在 RL 阶段冻结了VLM参数,仅训练轻量级的动作头以保持训练的稳定性
- 在随后的监督学习阶段,他们对整个模型进行微调,以成功的轨迹为基础,充分利用大型模型的表达能力
从经验上看,这种两阶段方法始终能够提升VLA的性能,稳定训练,并在计算上更加高效。且通过全面的实验验证了iRe-VLA方法,包括模拟环境MetaWorld[21]、Franka-Kitchen [22]以及现实世界中的Panda操作任务集
在这些领域中,iRe-VLA方法不仅更好地使VLA模型与原始任务对齐,还能够自主解决未见过的任务。此外,通过与环境的在线交互,VLA模型的泛化能力也得到了提升
3.1.2 相关工作
相关的工作有
一方面是用于具身控制的基础模型
- 大规模语言模型(LLMs)和视觉语言模型(VLMs)通过在网络规模数据上进行训练,编码了对物理世界的知识并展现出令人印象深刻的推理能力。凭借这种先验知识,LLMs 和 VLMs 可以在多个方面为具身控制任务提供帮助,包括为智能体提供奖励或价值[23],[24],[25],建模世界动态[26],[27],或者直接作为策略[5],[6],[28],[29],[30],[31],[32]
- 至于直接将LLMs/VLMs用作代理策略的工作,可以大致分为两类,即高层规划和低层控制。
然而,这些方法输出的文本计划并未直接与物理世界挂钩,且需要强大的低层技能
由于VLMs的原始输出位于语言空间,这些工作需要额外的动作建模部分,例如添加动作头[10],[11]或用动作替换语言token[8-RT-2]
二方面是用RL微调大模型
- 强化学习已成功应用于自然语言处理下游任务,以更好地将生成文本对齐到人类偏好[1-instructGPT],[35-Learning to summarize with human feedback],[36]
在这种从人类反馈中进行强化学习(RLHF)的框架中,在预收集的人类偏好数据集上训练奖励模型,然后在带有不偏离原始模型太多的约束的赌博环境中优化LLM[1],这可以看作是离线风格的RL[37-Offline reinforcement learning: Tutorial, review, and perspectives on open problems] - 与对话系统的RLHF不同,微调VLA模型面临未知的动态并需要在线探索[38],[39-Large language models as generalizable policies for embodied tasks],[40-Fine-tuning large vision-language models as decision-making agents via reinforcement learning]
例如
- 然而,它们都假设低层技能(例如,拾取,转向)是可用的,并且仅改进高层计划的基础。与它们不同,作者尝试使用强化学习(RL)直接改进由VLA策略输出的低层控制信号,该信号在稀疏奖励的物理环境中具有更长的时间跨度(数百或数千步)
3.2 深入细节:问题定义、模型架构、学习管道
3.2.1 问题定义
首先,关于RL
他们使用标准的深度强化学习部分观察马尔可夫决策过程(POMDP)框架,其中一个任务可以建模为
- 其中,S 和A 分别是任务的状态空间和动作空间,O 是机器人观察,例如视觉图像
是状态转移概率函数
是任务的奖励函数
在机器人任务中,奖励信号通常是稀疏的,因此本文中他们考虑二值奖励,其中,当机器人成功完成任务时R = 1,否则R =0
- PE : S × O →[0, 1] 是观察发射概率
策略πθ : O →A定义了一个由参数θ 决定的动作空间概率分布,而参数θ的目标是最大化策略πθ 在折扣γ 下的期望回报
其次,关于VLM
目前市面上已经开发了许多能够同时处理视觉和语言输入的视觉-语言模型(VLMs)。这些模型大致可以分为两类[8]:
- 表示学习模型,例如CLIP[41]
- 以及生成模型,例如Blip-2[42] 和InstructBlip[43]
按照[8-RT-2],[34-Vision-language models provide promptable representations for reinforcement learning],[11-Vision-language foundation models as effective robot imitators],他们特别采用生成式VLMs,其格式为
形式上,生成式VLMs 从中采样token
和指令
为条件
由于原始生成式VLMs 生成自然语言输出,将这些模型集成到机器人控制任务中需要一个额外的动作建模组件,这将在后续部分详细说明
3.2.2 模型架构
Re-VLA 模型将视觉输入和自由形式的语言指令
转换为低级机器人动作
,表示为
最终,该Re-VLA模型包括一个预训练的大型VLM 和一个轻量级动作头,如下图图2 左侧所示
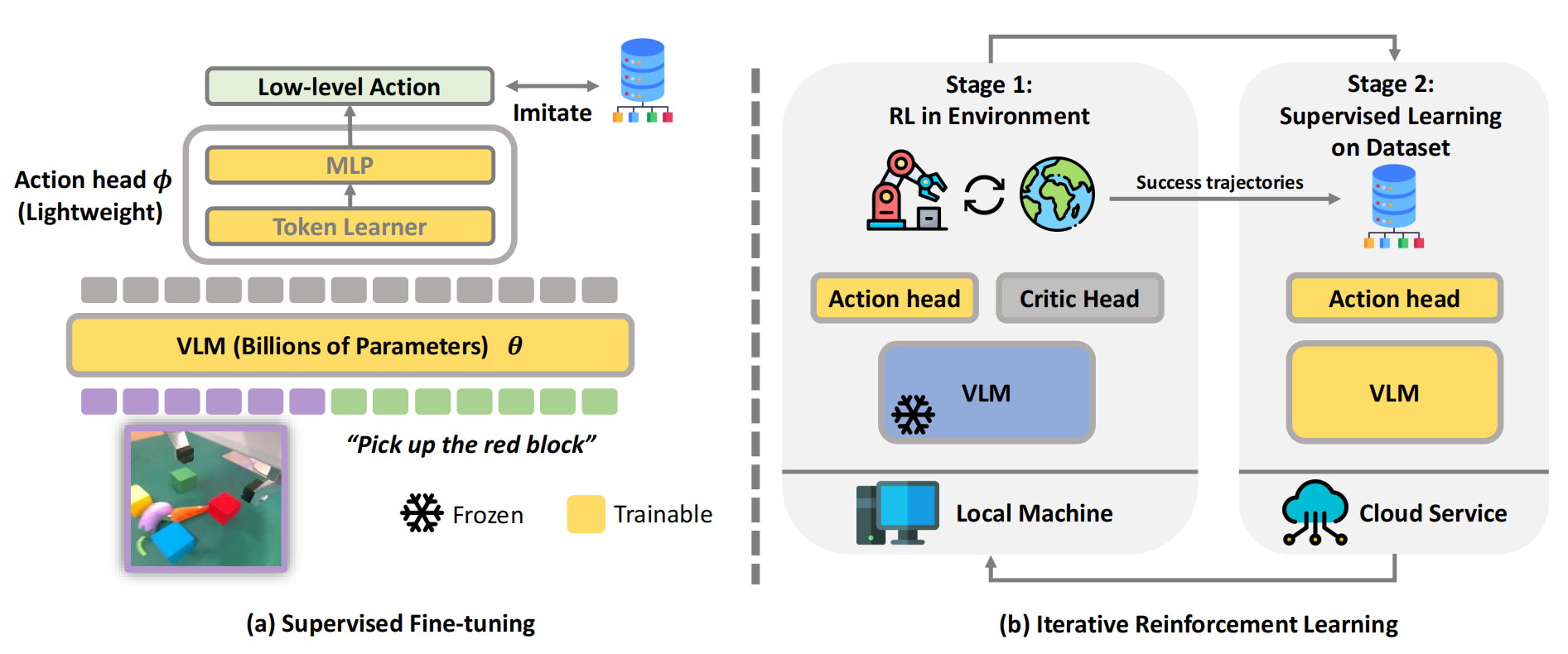
- 且使用BLIP-2 3B模型 [42] 作为主干视觉语言模型(VLM)
- 由于预训练的VLM在语言空间中输出文本token,他们设计了一个动作头来生成低级控制动作。这些动作通常包括末端执行器的姿态变化和夹爪状态
按照[11-RoboFlamingo],[34-Vision-language models provide promptable representations for reinforcement learning]中提出的设计,他们用新初始化的动作头替换了VLM的最终全连接层
在动作头中,token学习器 [44] 首先将VLM的最后隐藏表示转换为
随后,多层感知机MLP [45-Multi layer perceptron]将映射到动作
,其中
分别表示VLM的token数和嵌入维度,而
表示动作维度
- 然而,微调整个模型(其参数量以十亿计)需要显著的计算资源。此外,先前的研究[47],[48]表明,在有限数据情况下对整个大型预训练模型进行微调可能导致过拟合。按照[47]中描述的方法,作者采用参数高效的低秩适配LoRA[46]方法来微调VLM部分
总的可训练参数包括LoRA参数和动作头参数
3.2.3 学习管道:先SFT、后RL与SFT循环迭代
首先,在机器人数据集上对VLA 模型进行监督微调(阶段0),然后在在线RL(阶段1)和监督学习(阶段2)之间进行迭代
- 阶段0 SFT:在专家数据集上的监督学习
首先在VLA 模型进行标准的监督微调
形式上,学习目标由均方误差损失(MSE)定义
在监督微调之后,获得了初始VLA 模型,当然了,
的规模和质量高度相关,接下来开始通过在线RL 改进
- 阶段1 在线RL:使用冻结的VLM 进行在线强化学习,仅优化动作头的参数
SFT 模型
接下来,为了提升SFT 策略的性能,他们使用在线RL
且在RL 过程中,引入了一个评价头critic head,其结构与动作头action head相似,但输出维度设置为1
为了防止模型崩溃并加速学习过程,他们在此阶段冻结VLM 参数
通过在线RL之后,机器人可能会发现新的轨迹来解决新任务。然后他们将这些成功的轨迹Success trajectories
中
- 阶段2 SFT:在专家数据和在线收集数据上进行监督学习,优化VLM参数
在阶段1 中,当代理在新任务上进行强化学习时,可能会遗忘之前学过的任务
因此,在阶段2 中,他们使用新收集的在线数据和原始专家数据集
形式上,目标可以写为
从而在阶段1和阶段2之间进行迭代
如前所述,阶段1中的代理会为新任务探索新的解决方案,而在阶段2中,它会模仿所有可用的成功轨迹。通过在阶段1和阶段2之间交替,大型VLA模型逐步解决更广泛的任务范围,同时也防止了在已见任务上的灾难性遗忘。此外,如之前的工作[50-Octo],[13-Open x-embodiment]所建议的,通过模仿更广泛的任务范围,VLA模型可能会变得更具泛化能力
顺带提一下,他们之所以在iRe-VLA方法中,设置整个VLM在第二阶段的监督学习中是可训练的。是因为他们通过在两个阶段中冻结VLM(即iRe-VLA-freeze)进行了消融研究
结果如图5所示,永久冻结VLM会导致性能下降
这可能归因于动作头的表达能力相较于完整VLA模型的有限性。此外,在线机器人动作数据可以增强上层VLM中的表示,从而提高VLA模型在未见任务中的泛化能力,而(如果)在两个阶段中(全都)冻结VLM则无法改善VLM的表示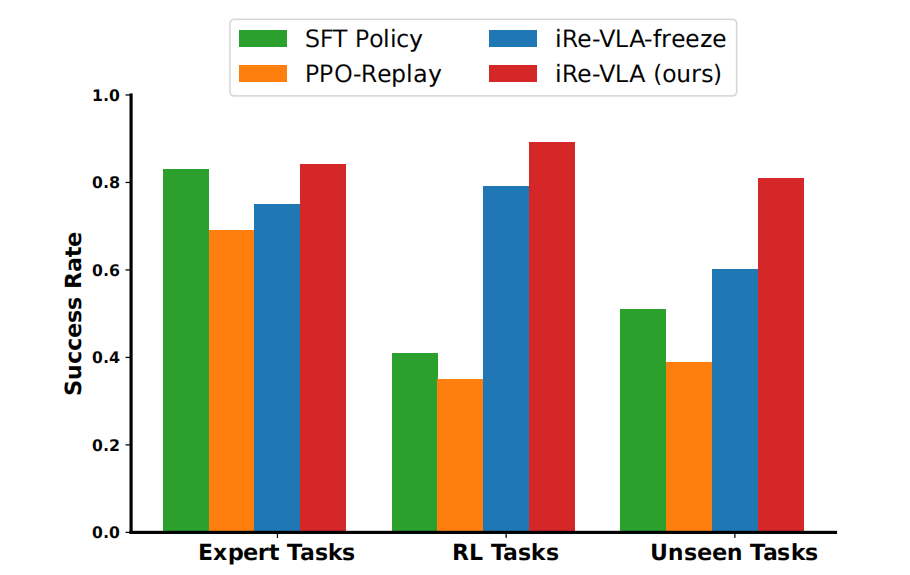
故综合以上,整个流程在算法1中概述,如下所示

3.3 一系列实验
3.3.1 实验设置
他们在三个领域中进行了实验:Meatworld [21]、Franka Kitchen [22]以及真实世界的panda操作,如下图图3所示
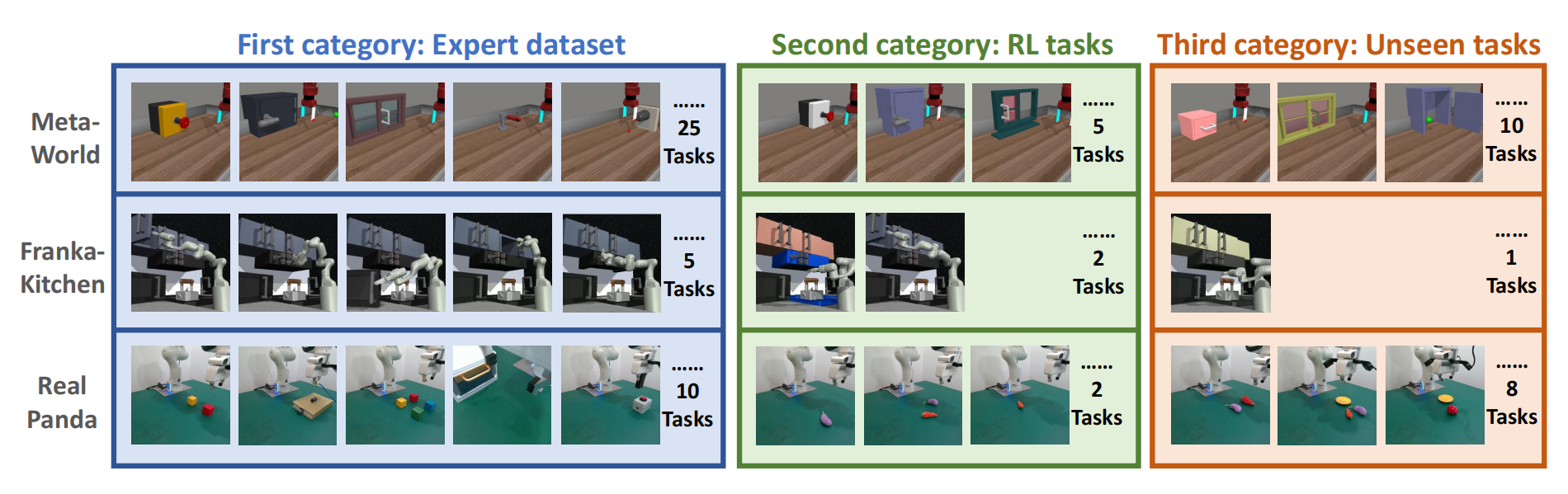
值得注意的是,他们使用单一的文本条件化VLA模型来解决一个领域中的所有任务。每个领域中的任务分为三组:
- 在演示数据集中观察到的专家任务
- 通过在线强化学习增强的强化学习训练任务
- 以及在先前训练中未见的保留任务
通过上节的介绍可知,最初,他们使用专家数据集对VLA模型进行了监督微调。随后,他们改进了其性能,通过在线强化学习在第二类新任务中建立 VLA 模型。最后,利用第三类任务来评估训练好的 VLA 策略的泛化能力
- 在 Metaworld 域中,专家数据集包含 25 个任务,每个任务有 50 条轨迹。第二类和第三类任务引入了具有物体形状、颜色和位置变化的新任务
- 在 Franka 厨房域中,他们遵循 [47-Tail] 中的设置,专家数据集包含 5 个任务,而第二类和第三类任务涵盖了物体外观和位置的未见变化
- 至于真实世界的任务,他们通过远程操作和脚本收集了 2000 条轨迹,用于抓取(抓握)、放置、按按钮、布线和抽屉打开。真实世界实验中的未见任务包括抓取未见过的物体
3.3.2 为什么采用两阶段迭代优化
有两方面的原因
- 稳定训练过程
他们观察到,直接使用标准强化学习(RL)算法对大型VLA模型进行微调可能会不稳定并导致性能下降
如下图图4所示
他们在Metaworld基准测试中的五个稀疏奖励任务中观察到四个任务的性能下降。这一现象在之前的研究[18-Stabilizing transformers for reinforcement learning]中也有所观察,该研究在基于Transformer的RL策略中遇到了类似的不稳定问题,并且不得不修改Transformer模块以防止崩溃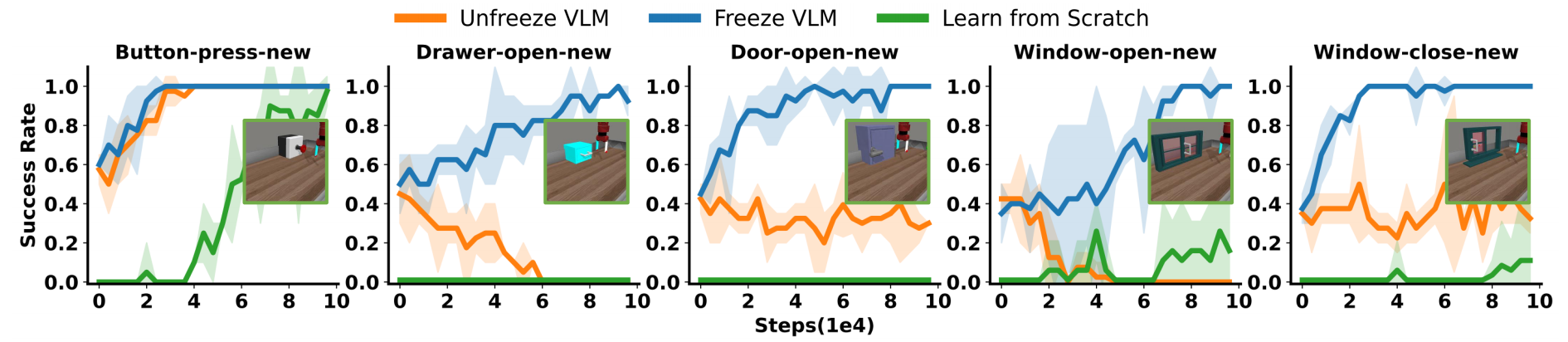
然而,这些修改与预训练的VLMs不兼容,因此他们在RL阶段冻结VLM以防止崩溃 - 管理模型训练负担
完全微调具有数十亿参数的VLA模型超出了大多数本地机器的计算能力,而完全部署在远程服务器上会引入参数传输问题并降低控制频率
故他们的两阶段iRe-VLA框架通过分配计算负载解决了这些挑战
3.3.3 仿真操作实验
最初在模拟的Meta-world和Franka Kitchen基准中进行了实验,其中VLA模型分别在25个任务和5个任务上进行了监督学习
正如图4所示,VLA模型可以为强化学习任务提供一个有效的起点,相较于从零开始的方法,加速了强化学习的过程
随后,他们采用iRe-VLA方法逐一学习强化学习任务,这不断改进了VLA模型。他们将他们的方法与标准的PPO算法[51]进行了比较
且为了确保公平比较,我们还进行了PPO任务的实验——并在每个任务后采用了相同的专家数据回放策略,即PPO-Replay
结果如下表I所示
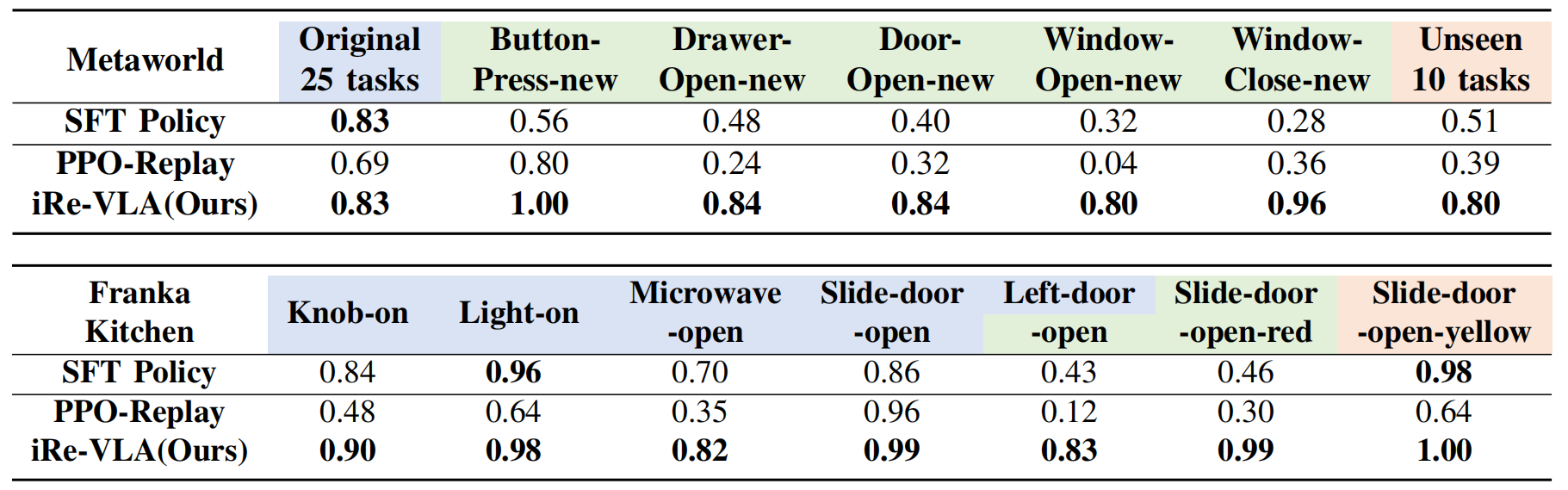
- 标准的PPO算法在引入到强化学习任务时通常表现出不稳定性,如上图图4所示。这种不稳定性不仅影响强化学习任务的性能,还会降低先前学习任务的性能,即使使用了经验回放
- 这种下降可能是由于噪声强化学习梯度对VLA模型中的预训练表示产生了不利影响。相比之下,他们认为他们的两阶段iRe-VLA方法稳定了强化学习过程,并有效地提升了任务性能
3.3.4 真实世界的操作实验
现实世界实验遵循SERL [52], [53]中描述的设置,这是一个有用的用于现实世界强化学习的软件套件
- 他们首先在2000个人类收集的专家数据上训练了一个VLA模型,这些数据涵盖了各种任务类别,包括抓取(握取)、放置、按钮按压、电缆布线和抽屉操作。他们注意到,学习到的VLA模型由于其泛化能力,对未见过的对象表现出一定的成功率
- 然后,采用在线强化学习(RL)进一步提高在未见对象上的成功率。且实施了几个关键的设计选择,以在大规模视觉-语言-动作(VLA)模型的背景下提高样本效率并确保计算的经济性
为了改进样本效率,他们采用了SACfD算法[54],[55]。具体来说,当引入一个新任务时,最初使用零样本转移的VLA模型收集包含20条成功轨迹的演示缓冲区
在训练过程中,他们从演示缓冲区中采样50%的转换,并从在线缓冲区中采样50%的转换,如[52]中所述
为了管理计算成本,每个图像观测仅由VLM处理一次,并将生成的潜在输出存储在缓冲区中。随后,他们在此潜在空间中实现了SACfD算法
后面,如需再继续更


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











