




前言
如此前的博客所说,我司「七月在线」正在并行开发多个订单,目前正在全力做好每一个订单,因为保密协议的原因,暂时没法拿出太多细节出来分享
但可以持续解读我们所创新改造或二次开发的对象,即解读paper和开源库「当然 有些paper/库虽还没开始用,但也可以提前解读,作为关注了解」
而其中有一个「人形订单」涉及到行走之外的导航、避障,项目组在确定解决方案的过程中,看到了NaVILA这个工作,故本文来解读下
- 当然,因为 我们目前更多侧重人形和机械臂,其次机器狗(比如一些巡检订单),故本文会重点解读人形方面的导航与避障
- 过程中,我把RL方法PPO的实现 也做了重点解读
最后,如想做、在做、曾做该方向的,欢迎私我一两句简介,邀你进NaVILA为代表的「七月具身:视觉语言导航交流群」
第一部分 NaVILA
1.1 提出背景与相关工作
1.1.1 引言
执行视觉与语言导航VLN的能力已成为现代机器人系统的基础组成部分。通过VLN,机器人能够在没有提供地图的情况下,根据语言指令在未见过的环境中导航。这不仅为人类提供了更好的交互界面,还通过语言强化了跨场景的泛化能力
在本文中,来自1UC San Diego、2USC、3NVIDIA的研究者们进一步扩展了对腿式机器人(例如四足或人形机器人)进行VLN研究的范围,提出了NaVILA,其使用腿而非轮子使机器人能够在更具挑战性和混乱的场景中导航
- 其paper地址为:NaVILA: Legged Robot Vision-Language-Action Model for Navigation
- 其GitHub地址为:github.com/yang-zj1026/legged-loco

为了将语言转化为行动,机器人需要理解输入的语言,执行闭环规划以及低级控制。随着大型语言模型(LLMs)和视觉语言模型(VLMs)的最新进展,已经开发了若干端到端的视觉语言行动(VLA)系统
- 这些系统通过大规模机器人操作演示微调通用的VLM,以生成低级行动。尽管将推理和执行统一到一个模型中非常吸引人并且显示了令人鼓舞的结果,但深入探讨一个问题是值得的:是否存在一种比量化的低级命令更好的表示动作的方式?
毕竟,LLMs和VLMs主要是用自然语言进行训练的。当需要将推理转化为精确的非语言行动时,统一推理和执行变得具有挑战性 - 受到最近在空间位置和距离推理的VLM研究进展的启发,他们提出了NaVILA,一个针对腿式机器人VLN的两级框架:
一个VLM被微调以输出以语言形式的中级动作(VLA),例如“向右转30度”,并训练一个低级视觉运动策略以遵循该指令进行执行
VLA的中级动作输出传达了位置和方向信息,而无需低级命令 - 此框架的优势有三点:
(i)通过将低级执行与VLA分离,可以通过更换低级策略将相同的VLA应用于不同的机器人;
为了训练VLA,作者展示了如何:
- 在现有的VLM框架中集成历史上下文和当前观察以用于VLN
- 为VLN任务创建一个专门的导航提示
- 利用来自YouTube人类导览视频的真实数据来改进连续环境中的导航
- 引入一个精心策划的数据集混合设计以增强VLN的泛化能力
这些策略使他们能够将一个通用的基于图像的VLM调整为一个以导航为中心的代理,同时在通用的视觉语言数据集上进行训练,从而保持其广泛的泛化能力
此外,这是第一个展示直接训练人类视频可以改进连续环境中导航的工作
- 且为了训练稳健的运动技能,他们采用单阶段方法来学习基于视觉的运动策略。比如从原始的LiDAR点云中构建一个高度图并引入随机化来弥合模拟与现实的差距。这个控制器从作者的VLA模型输出中获取信息,将其转换为命令速度,并通过控制关节的位置来跟踪这些速度
- 这种端到端的方法使得可以训练出既稳健又安全的视觉运动技能,从而促进在现实世界中具有挑战性的环境(例如强烈的阳光或某些透明表面附近)的部署
- 在他们的实验中,表明该VLA在经典VLN基准测试中显著优于最先进的方法,成功率提高了超过17%。此外,他们的单阶段运动策略在性能上大幅超越了基于策略蒸馏的方法
- 为了更好地模拟VLN中运动导航的挑战,他们还使用Isaac Sim引入了一个新的基准测试VLN-CE-Isaac。这个基准测试考虑了详细的机器人关节运动和与环境的交互,这是之前的VLN工作没有探索的
且在他们的VLN-CE-Isaac实验中,他们的基于视觉的策略显著优于盲策略,成功率提高了14%
此外,他们还展示了他们的VLA可以部署在不同的机器人(UnitreeGo2, Unitree H1, Booster T1)上,每个机器人使用不同的运动技能
最后,他们在现实世界中部署了NaVILA,宣称在25条指令上达到了88%的成功率,其中包括在不同场景中复杂指令的75%成功率
1.1.2 相关工作
第一方面,对于视觉导航
视觉导航一直是机器人领域的长期研究课题 [71–74- Navigating to objects in the real world]。传统方法依赖于预先计算的 [75],或通过深度传感器 [76- Kinectfusion: Real-time dense surface
mapping and tracking] 或单目摄像头构建的几何地图,同时对机器人进行定位SLAM[77-Monoslam: Real-time single camera slam,78-Visual-inertial navigation, mapping and localization: A scalable realtime causal approach]
最近,基于学习的方法
- 使用模仿学习 [79- Gated-attention architectures for task-oriented language grounding,80-Dosovitskiy. End-to-end driving via conditional imitation learning]
- 和强化学习 [81-Human-level control through deep reinforcement learning,82-Continuous control with deep reinforcement learning]
展现了强大的性能,并将应用扩展到视觉-语言导航领域
第二方面,视觉-语言导航
- 视觉-语言导航(VLN)是具身人工智能中的一个基本挑战,其中代理通过使用视觉线索和自然语言指令在复杂环境中导航。这个领域随着时间的推移显著发展
- 早期研究[1-Vision-andlanguage navigation: Interpreting visually-grounded navigation instructions in real environments,30-Room-across-room: Multilingual vision-and-language navigation with dense spatiotemporal grounding,83-Reverie: Remote embodied visual referring expression in real indoor environments]集中于在模拟环境『如MP3D [84]』中的离散导航,在这些环境中代理在导航图上的预定义节点之间传送
[31- Learning to navigate unseen environments: Back translation with environmental dropout,
85-Speaker-follower models for vision-andlanguage navigation,86-Self-monitoring navigation agent via auxiliary progress estimation,
87-Tactical rewind: Self-correction via backtracking in vision-and-language navigation,
88-Language and visual entity relationship graph for agent navigation,
89-History aware multimodal transformer for vision-and-language navigation,
90-Mapgpt: Map-guided prompting with adaptive path planning for vision-andlanguage navigation,
91-Navgpt-2: Unleashing navigational
reasoning capability for large vision-language models]
随着基础模型的进步,许多VLN系统通过利用大规模预训练模型[25- Improving
vision-and-language navigation with image-text pairs from the web,92- Robust navigation with language pretraining and stochastic sampling]
和预训练技术[24-Airbert: In-domain pretraining for vision-and-language navigation,52 Scaling data generation in vision-and-language navigation,93-A new path: Scaling vision-and-language navigation with synthetic instructions and imitation learning]显著改进,在这种设置中接近人类水平的性能
然而,这种设置强调了高层次的决策,而忽略了底层运动控制的挑战
最近,研究[12-Navid: Video-based vlm plans the next step for vision-and-language navigation,54- Language-aligned waypoint (law) supervision for vision-and-language navigation in continuous environments,55-Cross-modal map learning for vision and language navigation,56-Weaklysupervised multi-granularity map learning for vision-and-language navigation,57-Affordances-oriented planning using foundation models for continuous vision-language navigation]转向了使用诸如Habitat[69]之类的模拟器的连续环境(VLN-CE [58-Beyond the nav-graph: Visionand-language navigation in continuous environments])
这引入了更大的复杂性,因为代理必须执行中层动作,例如向前移动或旋转,而不是在节点之间传送
为了弥合离散和连续导航之间的差距,一些方法[44-Sim-2-sim transfer for
vision-and-language navigation in continuous environments,49- Etpnav: Evolving topological planning for vision-language navigation in continuous environments,51-Bevbert: Multimodal map pre-training for language-guided navigation,94- Hierarchical cross-modal agent for robotics vision-and-language navigation]使用模拟器预训练的航点模型[42-Bridging the gap between learning in discrete and continuous environments for vision-and-language navigation,43-Waypoint models for instruction-guided navigation in continuous environments]来预测代理周围的候选位置,并显示出显著的性能提升
然而,由于它们依赖于特定模拟器的数据,通常难以泛化
此外,这些模型预测的候选位置仅覆盖附近区域,并未考虑低级运动规划或障碍物规避 - 在本文中,作者旨在推动VLN朝向真实世界机器人应用,特别是对具有挑战性的腿式机器人。NaVILA同时处理高级决策并生成低级动作以控制机器人的完整运动
此外,他们引入了一个基于Isaac Sim的新VLN基准,提供了更现实的模拟环境,他们相信这将有利于未来的VLN研究
第三方面,机器人基础模型
机器人基础模型旨在提供一个统一的框架,处理来自各种模态(例如视觉和语言)的输入,并直接输出动作以使机器人执行复杂任务
- 现有工作[7,8,95]在大规模机器人数据集上训练以获取通用机器人策略,但主要集中于操作任务。Doshi等[96]和Yang等[97]提出了用于不同机器人任务的端到端视觉语言跨体现模型
- 最近,提出了几种基础导航模型[98–100]。然而,它们主要关注目标导航,输入为简短的语言描述或目标图像
- 对于腿式机器人,Ding等[101]提出了一个统一模型,以利用视觉和语言输入并生成可执行的低级动作
- 另一类工作[102,103]侧重于训练专门的策略作为技能库以处理特定动作,使用VLM或LLM作为控制器决定执行哪种技能
同样,这些方法无法执行指令跟随任务,因为它们难以理解复杂指令,而复杂指令对于通用导航至关重要。为了解决这一问题,作者提出了一种专门为通用视觉语言导航任务设计的VLA模型
第四方面,腿式机器人运动学习
腿式机器人运动学习的重点是使机器人能够穿越各种地形
- 之前的研究[104,105]仅依赖于机器人的本体感知信息,在诸如避障的场景中表现不佳
- 而其他基于端到端视觉的方法[106–109]由于传感器的限制,在极端环境条件(例如强烈的阳光)下表现脆弱
- Lee等人[38]在深度相机的基础上引入了LiDAR传感器以改善地形感知,但依赖于耗时的两阶段训练
- 此外,在训练过程中,Miki等人[39]查询预定义的地形高度以构建高度图,并在部署期间依赖外部工具[110]生成高度图,从而导致训练和部署之间的差异
- 为克服这些限制,作者提出了一种单阶段RL框架,该框架在训练过程中集成了LiDAR感知输入,使机器人能够通过与环境的交互直接学习,从而在复杂场景中实现更高的效率和鲁棒性
1.2 整体方法:集成高级视觉语言理解与低级运动控制
NaVILA 集成了高级视觉语言理解与低级运动控制,如下图图2所示「VLA 模型处理单视图图像以生成自然语言中的中级动作,然后通过先进的低级运动策略将其转换为精确的关节运动」
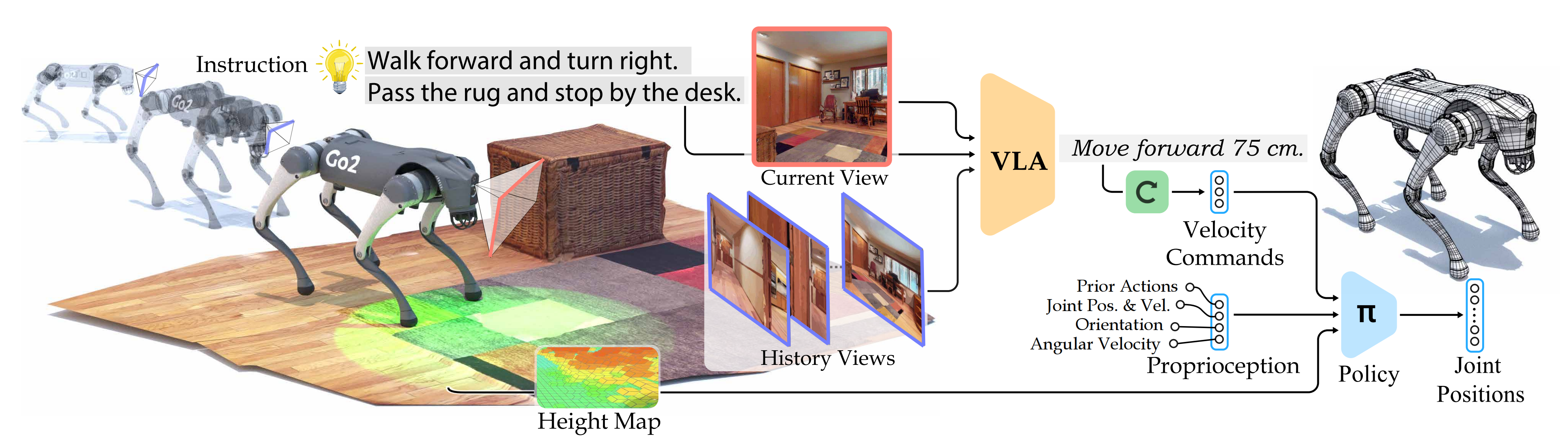
它使用一个视觉语言模型(VLM)处理单视图图像并生成自然语言的路径点指令,而运动策略将这些指令转化为精确的关节运动以实现实时机器人控制
得益于VLM 的推理能力与运动策略的执行能力之间的协同作用,使得 NaVILA 能够在多样化的环境中进行泛化
1.2.1 驯服用于视觉语言导航的VLMs
视觉语言导航VLN需要处理视频输入作为观察
- 处理VLMs中的视频输入的一种常见方法是通过视频编码器[12]。然而,VLMs的最新进展主要受益于图文数据的可用性。尽管已经有一些努力将这种成功扩展到视频编码器上,但由于缺乏大规模、高质量的视频文本数据集,限制了它们的预训练
- 为了解决这个问题,他们在方法中选择了基于图像的视觉语言模型。这些模型表现出更强的泛化能力,并且拥有更广泛的知识,使它们更适合解决VLN中的泛化挑战
具体来说,他们基于VILA[13–19]构建了我们的方法,这是一系列高效的VLMs,既适用于理解也适用于生成。VILA的预训练对多图像推理特别有效,这使其特别适用于需要理解顺序图像关系的VLN任务
1.2.1.1 VILA初步介绍:先预训练连接器,再预训练连接器和LLM,最后微调所有模块
VILA由三个主要组件组成「VILA consists of three main compo-nents: a vision encoder, a projector, and an LLM」:
- 一个视觉编码器
视觉编码器处理输入图像,将其转换为一系列视觉token - 一个投影器
这些token随后被下采样并通过MLP投影器映射到语言领域 - 一个LLM
之后,投影的视觉token与文本token一起被发送到LLM进行自回归生成
在处理视频时,VILA以固定间隔均匀采样帧。它将所有帧信息放在任何文本之前。描述视频的典型提示可能看起来像:“⟨frame3⟩⟨frame6⟩⟨frame9⟩...告诉我关于这个视频的信息。”
值得注意的是,VILA 能够高效地进行序列并行训练[16],处理多达 1024 帧
VILA 经历一个三阶段的训练过程:
- 首先,它使用对齐数据[20]对冻结的LLM和视觉骨干之间的连接器进行预训练
first, it pre-trains a connector between the frozen LLM and vision backbones using alignment data [20]; - 然后,它使用文本图像交错语料库[21, 22]对连接器和 LLM 进行预训练
- 最后,它使用指令调优数据[20, 23]对所有模块(视觉编码器、连接器、LLM)进行微调
1.2.1.2 导航提示
在视觉语言导航任务中,不同时刻的图像有两个不同的用途。在时间步t的图像表示当前的观察,这对于VLN智能体做出即时决策至关重要(例如,在交叉路口右转或在到达目标时停止)
另一方面,时间步t之前的帧是作为历史帧,充当记忆库,帮助智能体跟踪整体进度(例如,记住起始位置,推理已经访问过的地方并规划下一步)
如下图所示,将紫色方块表示为从历史帧中采样的内存token,红色方块表示当前观测token。 🔥 表示可训练参数「在他们的实验中,他们测试了 t 为 8 到 64 帧的配置」
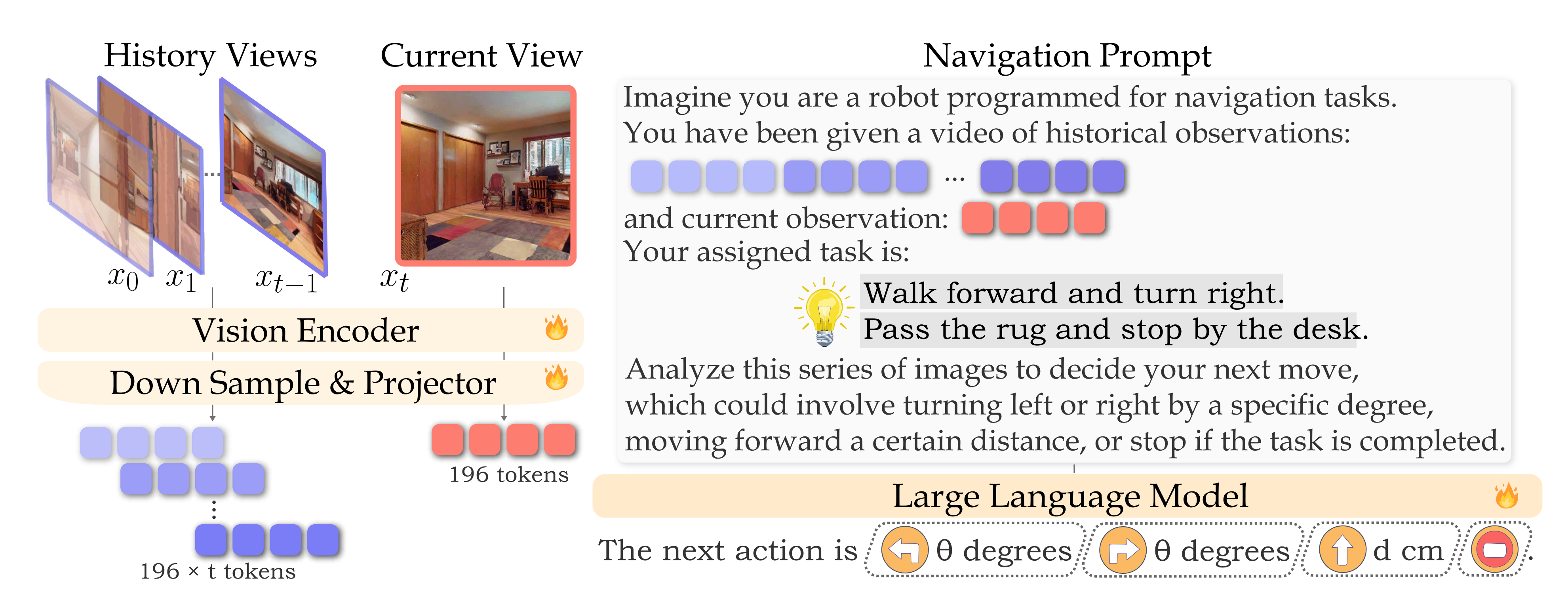
像VILA那样在固定间隔均匀采样帧并不理想,因为它没有区分这两种表示类型
- 因此,他们首先提取最近的帧t作为当前观察,然后从之前的t-1帧中均匀采样帧,确保始终包括第一帧
- 此外,由于当前观察和历史观察的作用不同,他们在任务提示中使用文本提示区分它们,例如“历史观察的视频:”用于记忆帧,“当前观察:”用于最新帧
- 且与[12]不同,他们避免引入可能复杂化LLM学习过程的额外特殊token
相反,他们将LLM的输入和输出保持在语言领域,以充分利用预训练LLM的推理能力。通过将这些历史和当前观察的token与导航指令整合,他们构建了一个导航任务提示,如图2所示
1.2.1.3 从人类视频中学习——以增强导航能力
最近的研究[24-26]表明,从人类视频中收集轨迹-指令对可以增强导航能力。然而,先前的工作局限于离散导航设置,主要使用真实视频进行预训练以减少域间差异或提高地标理解,而不是直接训练导航模型
将这种方法扩展到连续设置中是一个重大挑战,因为获取连续动作标签非常困难。最近在野外度量姿态估计的进展使得这一点成为可能,从而能够从人类视频中提取空间理解并直接训练导航模型
- 他们的数据管道如图4所示,从YouTube上的2000个自我中心的旅游视频开始,这些视频为从人类行为中学习机器人导航提供了丰富的真实世界数据来源

- 他们将这些视频处理成20,000个多样且有代表性的样本——使用基于熵的采样方法[26]对轨迹进行处理
- 接下来,使用MASt3R[27]估计相机姿态以提取逐步操作,并通过基于VLM[13]的字幕生成技术生成每个轨迹的自然语言指令,随后通过LLM[28]进行优化或改写
这种方法使他们能够利用人类示范实现连续导航,要知道,这在以前可是难以实现的能力
Next, we es-timate camera poses using MASt3R [27] to extract step-by-step actions, and we generate natural language instructions for each trajectory using VLM-based [13] captioning followed by LLM [28] rephrasing. This approach allows us to leveragehuman demonstrations for continuous navigation, a capabilitythat was previously non-trivial to achieve.
PS,针对视频字幕的自动生成,我司七月在线之前也开发了这样的系统,回头在本博客中 找个时间分享下技术方案
1.2.1.4 监督微调数据混合:4个角度的SFT数据
有效的监督微调(SFT)数据对于开发一个强大的视觉-语言动作模型至关重要。该模型应专注于具身任务,同时避免对特定动作的过拟合
此外,它还应能够很好地泛化到现实世界场景,同时保留广泛的世界知识。得益于NaVILA的模块化框架,该框架提供了卓越的可扩展性和适应性,将多样化的数据源集成到他们的管道中变得非常简单
他们的SFT数据混合从四个角度设计:(1)来自真实视频的导航数据,(2)来自模拟的导航数据,(3)辅助导航数据,以及(4)通用VQA数据集
- 对于模拟导航数据,在连续环境中的可用VLN 数据集是有限的,仅有R2R-CE [29] 和RxR-CE [30] 提供了从离散VLN 版本转换而来的稀疏路径点
他们在Habitat 模拟器中利用这两个数据集,使用「最短路径跟随器沿测地最短路径」生成动作序列
We leverage both datasetswithin the Habitat simulator, using a shortest path follower to generate action sequences along the geodesic shortest path.
这产生了逐步的导航视频,每个样本包含一个(t + 1) 帧的视频以及对应于时间步t 的oracle 动作
为了鼓励LLM 生成距离和角度的连续值标签,他们合并了连续的动作(例如,将两个前进25 cm 的步骤合并为一个前进50 cm 的步骤),最多合并三个连续动作
此合并过程不仅减少了数据集大小以提高处理效率,还引入了更大的动作多样性,从而缓解过拟合
此外,为了解决标签不平衡问题——特别是停止动作的代表性不足,他们应用了一种重新平衡技术,以实现更均匀的分布。所有与导航相关的数据都经过了前面所述的帧提取策略,并与导航任务提示相匹配 - 为了进一步改善场景理解并解决R2R-CE和RxR-CE中的有限指令问题,他们结合了辅助导航数据集
按照[12]的方法,他们使用来自EnvDrop [31]的增强指令,并引入了导航轨迹摘要的辅助任务
即给定一个轨迹视频,通过保留第一帧并均匀选择历史帧来采样帧,使用标注的指令作为标签 - 然后,LLM的任务是根据这些帧描述机器人的轨迹。为了进一步增强空间场景的理解,我们整合了ScanQA [32]数据集,该数据集包含了基于真实世界3D扫描的问答对,并配有人类编辑的问题和基于3D对象的自由形式答案
在训练中,他们使用来自原始扫描的多视角RGB图像来支持这一任务 - 最后,为了保持模型的通用能力,他们还结合了来自[23,33,34]的通用VQA数据集。这种综合的数据集设计确保了NaVILA能够有效地泛化到新场景和现实世界环境
1.2.1.5 训练和推理范式
他们的训练过程从VILA的第二阶段模型开始,该模型已经经过视觉语言语料库的预训练
然后,应用他们的SFT数据混合来训练整个VLM一个epoch,在此训练过程中,视觉编码器、连接器和LLM这三个组件都被解冻
在推理阶段,他们实现了一个正则表达式解析器[35],从LLM输出中提取动作类型(例如前进或左转)及其对应的参数(如特定距离或角度)
这种方法在模拟环境和现实世界实验中都显示了其有效性,他们通过实验证明,在所有实验中,所有动作都成功地匹配和映射
1.2.2 视觉运动策略:先仿真训练,后实际部署
接下来,咱们来看基于视觉的端到端控制策略的开发,该策略能够解释来自VLM的高级语言导航命令并将其转换为精确的关节运动
此控制策略在Isaac Sim模拟器中使用Isaac Lab [36]进行训练,然后直接部署到真实世界Go2机器人
1.2.2.1 Go2机器人
正如下图图5所示,机器人在其头部底部安装了一个LiDAR传感器,以15Hz的频率广播点云

机器人具有18个自由度(DoFs),包括底座的6个自由度以及每条腿的3个自由度。在策略训练过程中,他们将底座的6个自由度保持不受约束,以便策略仅控制腿部的12个关节电机
1.2.2.2 解释来自VLM的高级指令,以方便执行
VLM 输出一组固定的可执行词汇,例如{move forward, turn left, turnright, stop},作者再将这些指令转换为固定的指令速度,并执行相应的时间持续,以与特定的VLM 值对齐
1.2.2.3 低级动作和观察空间
控制策略的动作空间a 被定义为期望的关节位置,通过刚度和阻尼将其转换为模拟器的扭矩输入
他们采用PPO 算法[37] 来训练策略。在训练过程中
- critic观察特权环境并生成一个价值函数以更新执行者
critic的观察空间包含当前时间步
的本体感知和速度指令,以及机器人周围的特权地形高度扫描
本体感知数据包括机器人线速度和角速度、方向、关节位置、关节速度以及先前的动作 - 而执行者仅接收现实世界中可用的传感器数据
在执行者的观察空间oa 中,由于线速度在现实世界中不可用,因此被排除,取而代之的是使用本体感知数据的历史记录来隐式推断该信息
且该机器人利用激光雷达传感器提供的高度图来感知周围的地形
1.2.2.4 从LiDAR点云中引入高度图
鉴于LiDAR在检测透明物体方面的卓越能力以及在强光下的出色表现,他们选择了由制造商提供的LiDAR作为主要传感器,用于感知机器人周围环境并确保安全导航
Unitree L1生成具有360°×90°宽视野的点云,且基于补充材料中列出的参数创建了一个2.5D高度图。对于每个体素网格,选择范围内的最低值,然后在最后5个LiDAR点云上应用最大滤波器以平滑生成的高度图
1.2.2.5 训练
不同于大多数现有工作[38–41]中采用的两阶段教师-学生训练范式,他们采用单阶段方式训练运动策略
- 与两阶段训练相比,单阶段强化学习更节省时间,因为它消除了策略蒸馏的需求
- 此外,策略直接与环境交互,使其能够探索并有可能发现新的策略。在 Isaac Lab 的光线投射的支持下,他们的基于视觉的强化学习策略训练在 RTX 4090 GPU 上实现了超过 60K FPS 的高吞吐量
1.3 实验
1.3.1 高级别的VLA性能
1.3.1.1 VLN-CE基准测试
他们在VLN-CE基准测试上评估他们的VLA,该基准测试为在重建的真实感室内场景中执行导航动作提供了连续的环境。且专注于R2R(房间到房间)和RxR(跨房间)数据集中的val-unseen分割——因为这是VLN领域中两个最受认可的基准测试
且他们采用以下广泛使用的VLN任务评估指标:导航误差(NE)、Oracle成功率(OS)、成功率(SR)、成功加权路径长度(SPL),以及归一化动态时间规整(nDTW)
- 他们在下表表一中展示了结果,其中NaVILA在两个基准测试中使用单一模型显著超越了所有不依赖模拟器预训练航路点预测器的基线方法
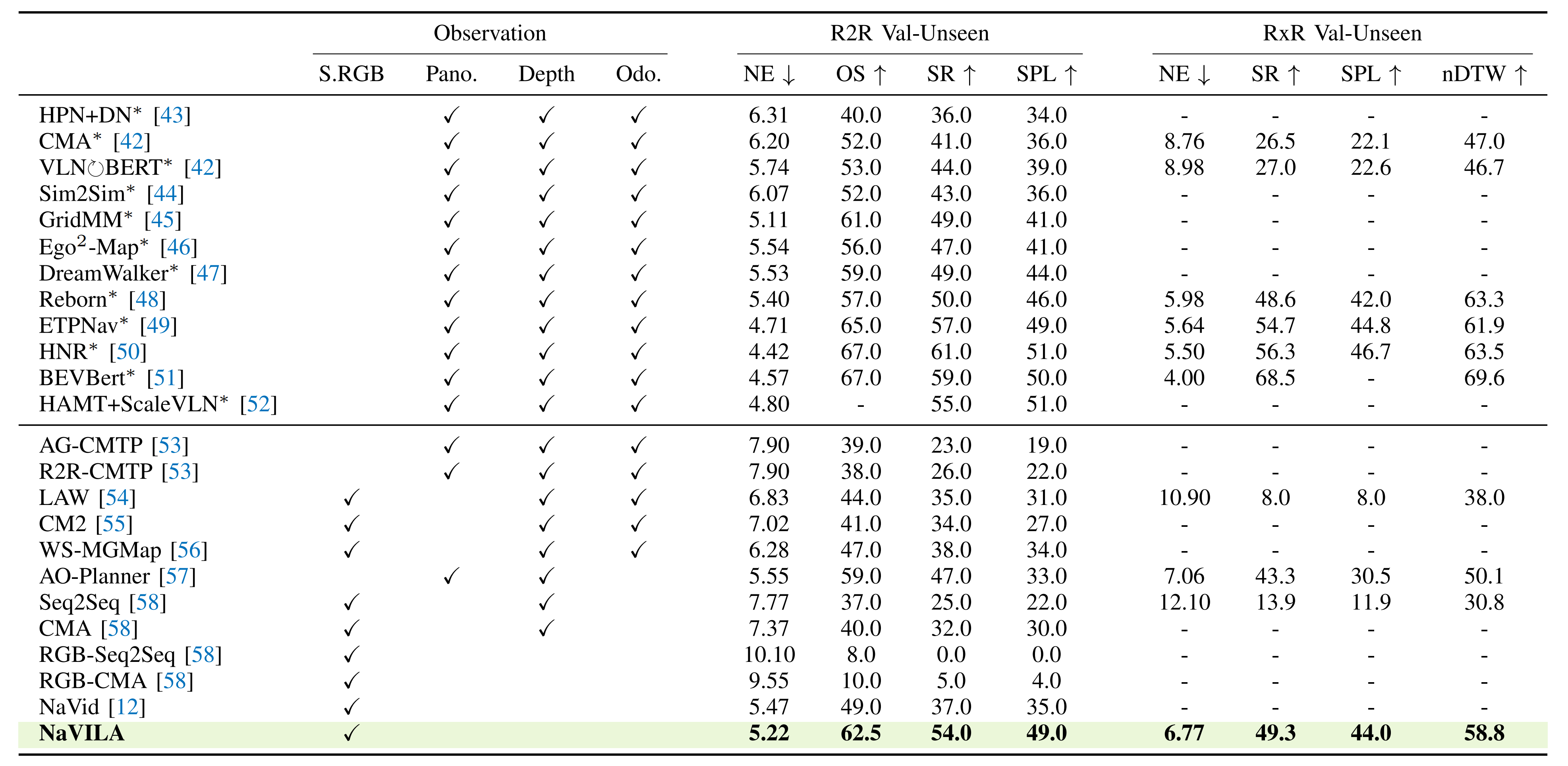
- 值得注意的是,这也是第一次一个仅使用单视图RGB输入训练的VLN代理能够达到或超越使用全景视图、里程计或模拟器预训练航路点预测器的模型的结果
这表明NaVILA的强泛化能力可以有效地弥补RGB视图或传感器中有限的观测
为了评估跨数据集的性能,他们按照[12]的方式,仅在R2R样本上训练NaVILA,而不使用RxR训练集
然后,他们在RxR Val-Unseen分割上评估其零样本性能。如表II所示
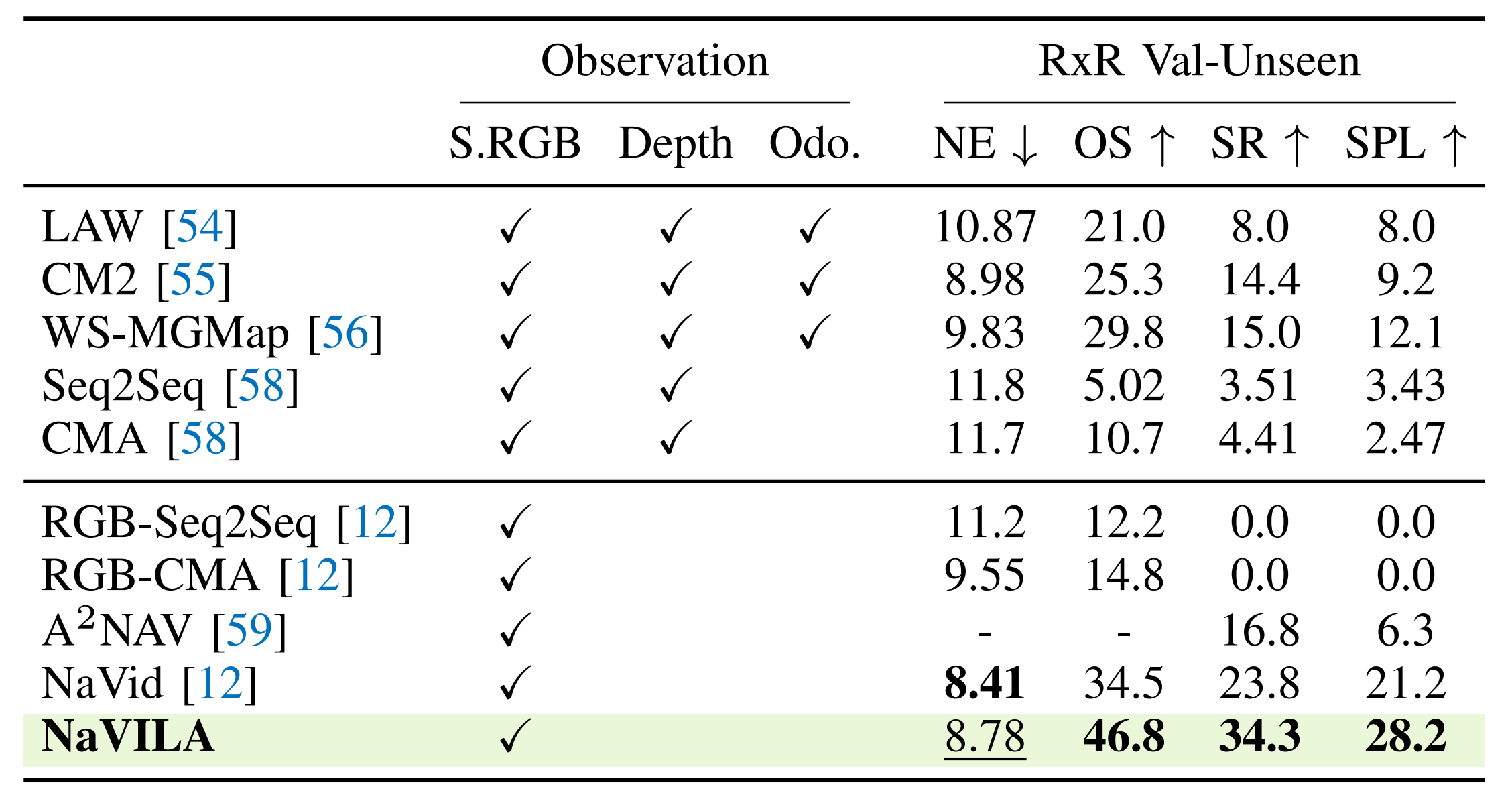
他们宣称他们的方法显著超过了当前最先进的模型NaVid,SR指标提升了10%
1.3.1.2 空间场景理解基准
作为一个通用导航代理,稳健的空间场景理解(例如,物体定位、指代和空间推理)至关重要。为了评估NaVILA在场景理解方面的能力,他们在ScanQA验证基准上进行了评估,这是一个广泛使用的3D问答数据集
ScanQA基于真实世界的扫描,他们使用这些扫描的多视图图像作为输入来查询NaVILA以获得答案
- 如下表表III所示,NaVILA在CIDEr得分上显著超越了之前的最先进模型NaviLLM [60],领先20分
此外,当使用64帧时,NaVILA的表现优于当前最先进的基于3D的大型多模态模型[61,62]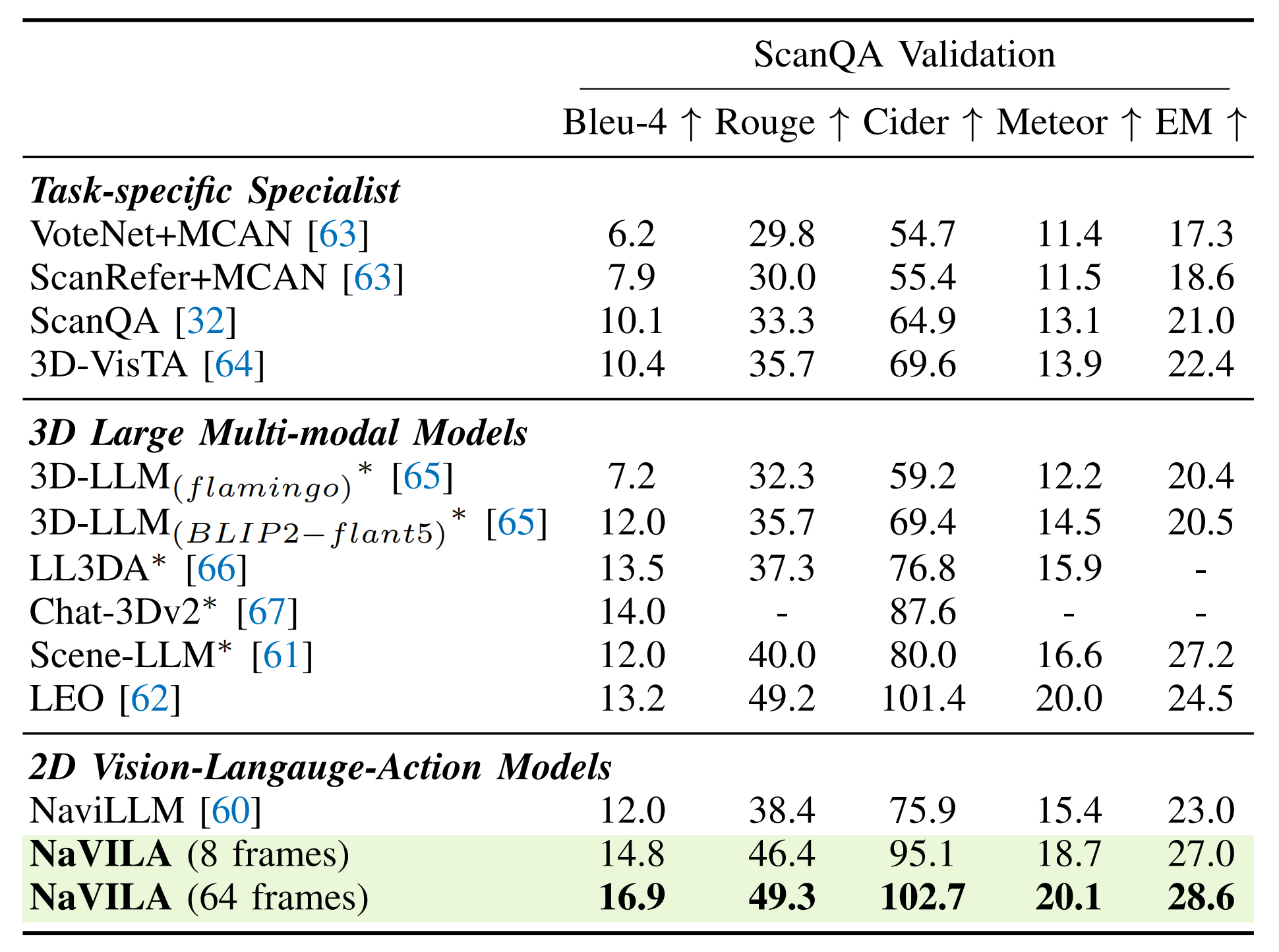
- 这一点尤其值得注意,因为这些其他模型需要3D扫描或带有相机姿态的RGBD数据作为输入,而NaVILA的方法在较少观察的情况下实现了更好的结果
1.3.2 低层级强化学习策略性能
为了突出他们强化学习策略相较于基于策略蒸馏的方法的优势,作者将其与正则化在线适应(ROA)[68]进行了比较
- 在ROA训练中,模型首先学习一个特权编码器,用于处理高度扫描点和其他特权观测。这一特权编码器随后监督一个适应编码器,该编码器以与作者的低层级策略相同的2.5D高度图作为输入
- 随后,作者使用三个指标对两种方法进行了评估:线性速度误差、角速度误差和碰撞率。前两项指标评估策略跟随速度指令的准确性,而第三项指标评估模型的避障能力
如表V所示
他们的低级策略在所有三个指标上均优于ROA,特别是在碰撞率上显著降低,如此,他们宣称他们的训练方法是有效的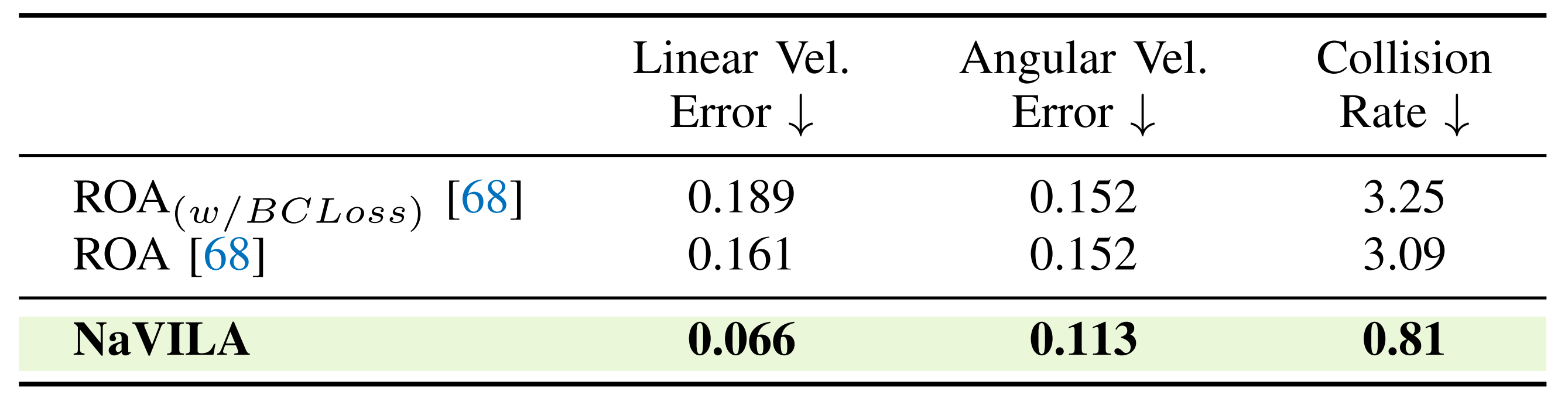
1.3.3 仿真中的足式机器人导航性能
目前,还没有专门为足式机器人设计的 VLN-CE 基准测试
- 现有的视觉语言导航基准测试 [29,30] 基于 Habitat [69]模拟器,该模拟器专注于高级规划,而不涉及精确的低级机器人控制。例如,Habitat 中的代理可以通过狭窄的间隙导航,例如两个沙发之间 10 厘米的空间,这对于四足或人形足式机器人来说是不切实际的
- 为了解决这一局限性,他们引入了一个新的基准测试 VLN-CE-Isaac,它基于 Isaac Sim。Isaac Sim 的高保真模拟捕捉了详细的机器人关节运动和与环境的交互,能够对整个导航流程进行全面评估,从高级规划到精确的机器人执行
且采用了 R2R 的相同场景——让机器人部署在环境中,如下图图6 所示
在 R2R Val-Unseen 分割的 1,839 条轨迹中,他们选择了 1,077 条具有高质量网格的可遍历轨迹,以确保真实的导航场景。为了保持一致性,他们使用与先前工作相同的指标进行性能评估
值得注意的是,VLN-CE-Isaac 可兼容多种机器人平台。为了展示这种灵活性,他们还在 Unitree Go2 机器人和 UnitreeH1 机器人上测试了他们的 NaVILA 模型,并在基准测试中展示了结果
为了突出基于视觉的策略的有效性,他们将其与仅依赖本体感知(盲目)的策略进行了比较,如下表表IV 所示
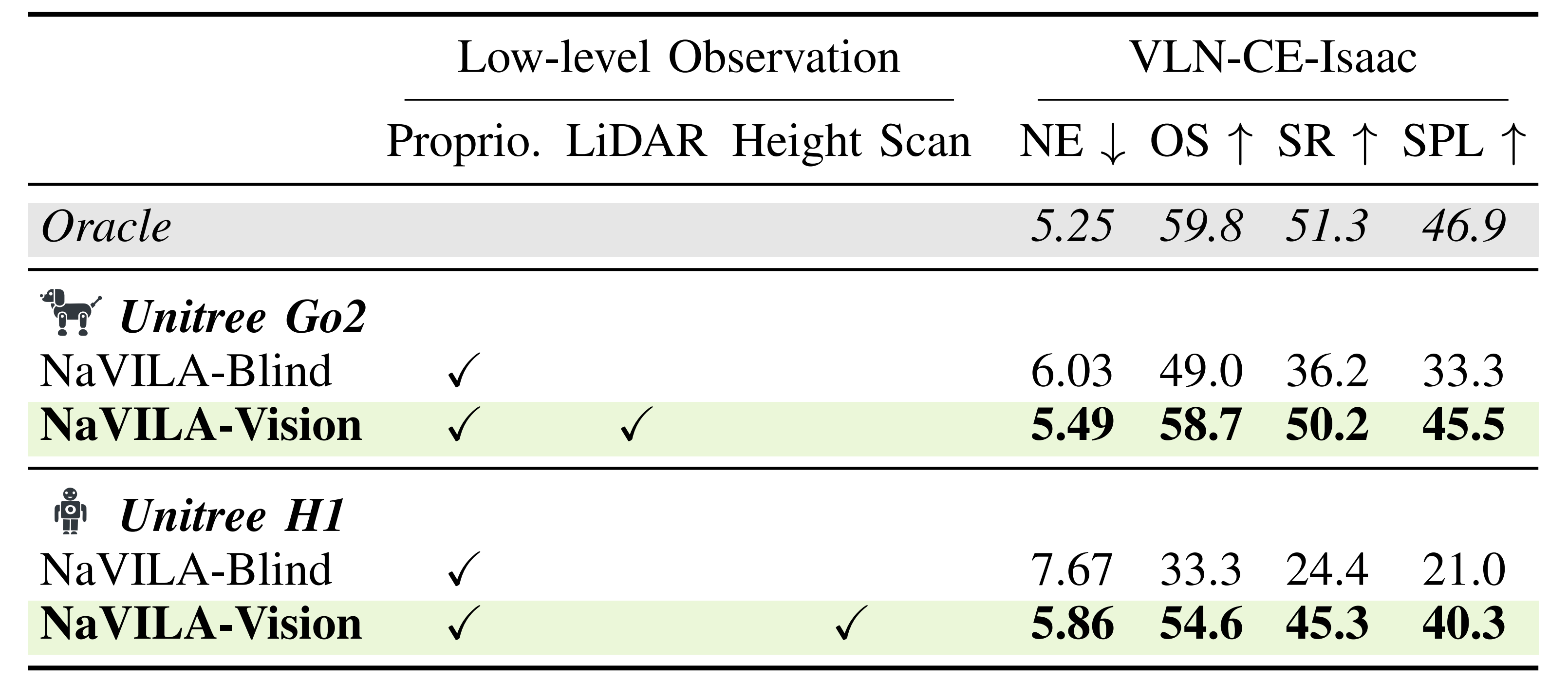
最终,基于视觉的策略在Go2 设置中的成功率比盲策略高14%,在H1 设置中高21 %,这归功于其卓越的避障能力
- 且他们还将NaVILAs 与使用Oracle 低级策略的基线进行了比较(假设在没有现实物理的情况下完美执行命令)。结果显示,在没有Oracle 策略的情况下,Go2 设置的成功率降低了15 %,H1 设置的成功率降低了27 %。这些性能差距突显了他们的基准测试所引入的更高挑战性和真实性
- 此外,他们还观察到NaVILA 在H1 机器人上的成功率显著低于在Go2 上的成功率,这符合预期,因为人形机器人尺寸较大
1.3.4 真实世界评估
然后,他们在实际环境中进行了实验,使用了25条指令,每条指令重复三次,涵盖了三种类型的环境:工作区、家庭和户外开放环境
- 简单指令由一到两个导航命令组成,机器人无需在房间之间导航(例如,“走到椅子旁边并停下”)
- 相反,复杂指令包含三个或更多命令,要求机器人穿越多个房间或地标(例如,“走出房间,向右转,进入前面的房间,并停在桌子旁”)
他们使用标准指标(SR和NE)并将NaVILA与GPT-4o进行比较。如下表表VI所示,NaVILA在SR和NE方面显著优于GPT-4o
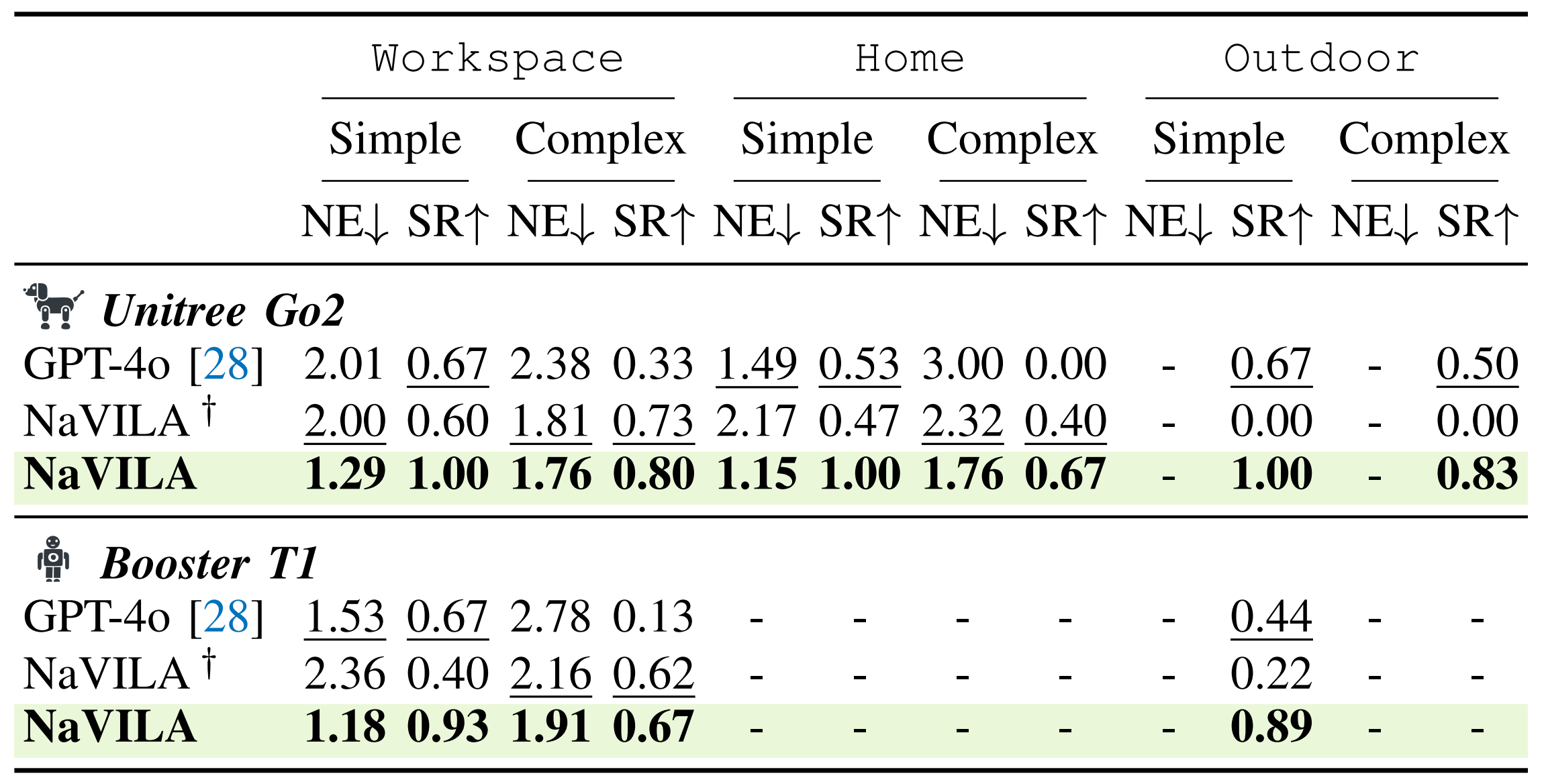
他们还对添加人类视频的效果进行了消融分析,并发现在人类视频的帮助下,模型能够更好地泛化到户外场景,并在所有环境中实现更高的成功率
且他们为了展示他们双层方法的灵活性,他们还在Booster Dynamics T1人形机器人上对其进行了评估,使用相同的VLA模型且无需重新训练。尽管存在摄像机高度和视角变化等差异,NaVILA始终优于基线模型,突出了他们模型的强泛化能力
他们的定性结果展示在图1和图7中。在图7中,他们演示了与语音识别的集成,通过他们的框架实现了语音控制的导航

1.4 部署
本项目在GitHub上开源了这部分的代码:github.com/yang-zj1026/legged-loco,该 repo 用于在 Isaac Lab 中训练 Unitree Go2 和 H1 的低级运动策略

1.4.1 安装
- 使用 python 3.10 创建一个新的 conda 环境
conda create -n isaaclab python=3.10 conda activate isaaclab - 确保你的机器上已安装 Isaac Sim。否则,请按照此指南:Isaac Sim 4.2.0 (OLD) Workstation Installation 进行安装。如果通过 Omniverse Launcher 安装,请确保已选择并安装 Isaac Sim 4.1.0
此外,在 Ubuntu 22.04 或更高版本上,你可以通过 pip 安装它pip install isaacsim-rl==4.1.0 isaacsim-replicator==4.1.0 isaacsim-extscache-physics==4.1.0 isaacsim-extscache-kit-sdk==4.1.0 isaacsim-extscache-kit==4.1.0 isaacsim-app==4.1.0 --extra-index-url https://pypi.nvidia.com - 安装 PyTorch
pip install torch==2.2.2 --index-url https://download.pytorch.org/whl/cu121 - 克隆 Isaac Lab 存储库
注意:此代码库已使用 Isaac Lab 1.1.0 进行测试,可能与较新版本不兼容。请务必使用下方提供的 Isaac Lab 修改版本,其中包含重要的错误修复和更新。由于 Isaac Lab 正在积极开发中,他们将考虑在未来支持较新版本git clone git@github.com:yang-zj1026/IsaacLab.git cd IsaacLab cd source/extensions ln -s {THIS_REPO_DIR}/isaaclab_exts/omni.isaac.leggedloco . cd ../.. - 运行 Isaac Lab 安装程序脚本并在此 repo 中另外安装 rsl rl
./isaaclab.sh -i none ./isaaclab.sh -p -m pip install -e {THIS_REPO_DIR}/rsl_rl cd ..
1.4.2 用法
- 训练
python scripts/train.py --task=go2_base --history_len=9 --run_name=XXX --max_iterations=2000 --save_interval=200 --headless python scripts/train.py --task=h1_base --run_name=XXX --max_iterations=2000 --save_interval=200 --headless - 测试
python scripts/play.py --task=go2_base_play --history_len=9 --load_run=RUN_NAME --num_envs=10 python scripts/play.py --task=h1_base_play --load_run=RUN_NAME --num_envs=10
且Use --headless to enable headless mode. Add --enable_cameras --video for headless rendering and video saving
此外,还可以通过将它们置于下方来添加更多环境
isaaclab_exts/omni.isaac.leggedloco/omni/isaac/leggedloco/config第二部分 NaVILA/legged-loco中isaaclab_exts/模块的解析:侧重H1人形机器人配置
整体代码库主要分为以下几个部分:
- isaaclab_exts - Isaac Lab的扩展,包含机器人配置和控制逻辑
- rsl_rl - 强化学习框架实现
- scripts - 训练、演示和使用的脚本
- src - 资源文件,包含演示GIF等
其中的isaaclab_exts/这个目录是Isaac Lab的扩展模块,结构如下:
isaaclab_exts/
omni.isaac.leggedloco/ - 主要扩展模块
setup.py - 安装脚本
config/
extension.toml - 扩展配置文件
omni/
isaac/
leggedloco/
config/ - 不同机器人的配置
g1/ - G1机器人配置
go1/ - Go1机器人配置
go2/ - Go2机器人配置
h1/ - H1机器人配置
leggedloco/ - 核心功能实现
mdp/ - MDP(马尔可夫决策过程)相关实现
actions/ - 动作空间定义
commands/ - 命令生成器
rewards/ - 奖励函数
utils/ - 工具函数`omni/isaac/leggedloco/config`模块是整个系统的核心配置部分,它定义了:
- 四种机器人模型(Go1、Go2、G1、H1)的物理参数和控制特性
- 两种环境模式(基础和视觉增强)的完整配置
G1, Go1, Go2, H1的每个机器人子目录中都遵循一致的配置模式,主要包含两类配置文件:
- 基础配置 (`*_low_base_cfg.py`) - 包含基础运动控制,不使用视觉信息
- 视觉配置 (`*_low_vision_cfg.py`) - 在基础配置上增加了视觉感知能力
- 强化学习训练参数**,包括奖励函数、观察空间、域随机化策略等
2.1 Go1和GO2的机器人配置/omni/isaac/leggedloco/config/go1/
Go1是Unitree公司的四足机器人。它有两个主要配置文件:
2.1.1 go1_low_base_cfg.py
这个文件定义了Go1机器人的基础配置:
- 导入必要的依赖和基础类
- 定义`Go1RoughPPORunnerCfg`训练配置类
- 定义`UNITREE_GO1_CFG`机器人物理配置
- 定义`Go1_BASE_TERRAINS_CFG`地形生成配置
- 定义`Go1SceneCfg`场景配置类
- 定义`CustomGo1RewardsCfg`奖励函数配置
- 定义`ObservationsCfg`观察空间配置
- 定义`EventCfg`事件和域随机化配置
- 定义`Go1BaseRoughEnvCfg`完整环境配置类
- 定义`Go1BaseRoughEnvCfg_PLAY`用于演示的环境配置类
2.1.2 go1_low_vision_cfg.py
在基础配置的基础上,增加了视觉能力:
- 导入基础配置
- 定义`Go1VisionRoughPPORunnerCfg`支持视觉的训练配置
- 扩展`Go1SceneCfg`,添加深度传感器等视觉组件
- 配置视觉观察空间
- 定义`Go1VisionRoughEnvCfg`完整的视觉环境配置
- 定义`Go1VisionRoughEnvCfg_PLAY`用于演示的视觉环境配置
2.2 Go2 机器人配置 (/omni/isaac/leggedloco/config/go2/)
Go2是Unitree公司的另一种四足机器人,配置结构类似于Go1:
2.2.1 go2_low_base_cfg.py
- 定义`Go2RoughPPORunnerCfg`训练配置
- 定义`UNITREE_GO2_CFG`机器人物理配置
- 定义`Go2_BASE_TERRAINS_CFG`地形配置
- 定义`Go2SceneCfg`场景配置
- 定义`CustomGo2RewardsCfg`奖励函数
- 定义观察空间、事件和完整环境配置
2.2.2 go2_low_vision_cfg.py
- 继承基础配置
- 定义`Go2VisionRoughPPORunnerCfg`
- 定义`Go2_Vision_TERRAINS_CFG`视觉地形配置
- 扩展场景配置,添加视觉传感器
- 定义`Go2VisionRoughEnvCfg`视觉环境配置
2.3 G1 人形机器人配置 (/omni/isaac/leggedloco/config/g1/)
G1是一种人形机器人,配置结构与四足机器人类似:
2.3.1 g1_low_base_cfg.py
- 定义`G1RoughPPORunnerCfg`训练配置
- 定义`ROUGH_TERRAINS_CFG`地形配置
- 定义`G1SceneCfg`场景配置
- 定义`RewardsCfg2DoF`针对2自由度关节的奖励
- 定义`CustomG1Rewards`自定义奖励
- 定义`EventCfg`事件和域随机化
- 定义`G1BaseRoughEnvCfg`环境配置
2.3.2 g1_low_vision_cfg.py
- 导入基础配置
- 定义`G1VisionRoughPPORunnerCfg`视觉训练配置
- 定义`G1_NO_ARMS_CFG`无臂版G1机器人配置
- 定义视觉地形和场景配置
- 定义`G1VisionRoughEnvCfg`视觉环境配置
2.4 H1人形机器人配置/omni/isaac/leggedloco/config/h1/
H1是另一种人形机器人,配置结构与G1类似,主要包含h1_low_base_cfg.py、h1_low_vision_cfg.py,而它两的主要区别在此
| h1_low_base_cfg.py | h1_low_vision_cfg.py | |
| 地形类型和复杂度 | 基础配置只有两种简单地形: - 50%平坦地形 - 50%轻微随机粗糙地形,噪声范围较小 | 视觉配置采用了更加复杂多样的地形环境: - 包括7种不同类型的地形(金字塔阶梯、倒金字塔阶梯、箱子地形、随机粗糙地形、两种斜坡地形、离散障碍物) - 每种地形都配置有平坦区域采样点,方便机器人适应不同地形间的过渡 - 障碍物高度最高达1.5米,明显增加了难度 |
| 感知能力与观察空间 | 基础配置: - 策略网络观察中没有地形感知能力 - 只依赖基本的本体感受信息(关节位置、速度、重力等 | 视觉配置的核心特点是: - 策略网络中加入了`height_scan`地形扫描观察,没有噪声干扰 - 通过射线投射技术实现地形感知,使机器人能够"看到"前方地形 - 提供了保留但被注释掉的激光雷达和深度相机配置,为未来拓展做准备 - 使用天空光照(sky_light)而非单一定向光源,更加真实 |
| 重置和初始化策略 | 视觉配置使用了地形感知的重置策略: - `reset_root_state_from_terrain`替换了`reset_root_state_uniform` - 这允许机器人根据地形情况进行更合理的初始化 | |
| 奖励权重调整 | 视觉配置中: - 平坦姿态惩罚权重(`flat_orientation_l2.weight`)从-5.0减轻到-1.0 - 这使机器人在复杂地形上有更大的姿态调整灵活性 | |
| 训练与评估设置 | 基础配置在评估时使用了更简单的环境设置 | 视觉配置更适合在复杂地形上进行评估,因为它保留了多样化的地形类型 |
| 本质区别 | 本质区别在于,h1_low_vision_cfg.py通过环境感知增强了H1机器人的感知能力,使其能够"看到"并适应更加复杂多变的地形,而不仅仅依赖于本体感受和经验。这种感知型策略使得机器人能够预见并规划如何应对前方的地形挑战,而基础配置中机器人则更多依赖于反应式控制策略,缺乏对环境的前瞻性认知 | |
2.4.1 h1_low_base_cfg.py:涉及PPO、地形、场景、观察空间(比如线速度/角速度等)、动作空间、奖励等一系列配置
2.4.1.1 导入部分
这部分导入了
- Isaac Lab的各种模拟工具、资产配置、管理器
- 传感器、地形生成器和噪音模型等组件
- 自定义的MDP(马尔可夫决策过程)组件
- 预定义的H1机器人模型配置(`H1_MINIMAL_CFG`)
2.4.1.2 PPO 训练配置
首先是 `H1RoughPPORunnerCfg` 类,配置了 PPO(近端策略优化)训练算法的参数:
- 每个环境的步数设为 32
- 最大迭代次数 50000,每 500 次迭代保存一次模型
- 使用三层神经网络架构作为 Actor 和 Critic,尺寸分别为 [512, 256, 128]
- 激活函数采用 ELU,初始噪声标准差为 1.0
- PPO 超参数配置:学习率 0.001,衰减因子 γ=0.99,λ=0.95,以及熵系数 0.005
2.4.1.3 地形配置
`BASE_TERRAIN_CFG` 定义了两种地形类型的混合
- 50% 的平坦地形(flat)
- 50% 的随机粗糙地形(random_rough),噪声范围为 0.02 到 0.10
2.4.1.4 场景配置
`BaseSceneCfg` 描述了仿真环境中的各种元素:
- 地形配置,包含物理材质(摩擦系数为 1.0)和视觉材质
- 机器人模型及其位置
- 接触力传感器,用于检测机器人与地面的接触
- 高度扫描器,使用射线投射技术检测地形高度
- 光照设置
2.4.1.5 观察空间配置
`ObservationsCfg` 定义了三组观察空间:
- `PolicyCfg`:策略网络的输入,包含基本动作信息和噪声,如:
- 线速度、角速度、重力投影
- 速度指令
- 关节位置、速度
- 上一步动作 - `ProprioCfg`:类似于 PolicyCfg,但噪声参数有所不同
- CriticObsCfg`:评论家网络的输入,与策略网络类似,但增加了地形高度扫描,没有噪声干扰
2.4.1.6 动作空间与事件配置
- `ActionsCfg` 定义了动作空间,使用关节位置控制
- `EventCfg` 配置了训练过程中的各种随机化事件,包括:
- 物理材质随机化
- 重置机器人位置、姿态和关节状态等
2.4.1.7 奖励与指令配置
- `CustomH1Rewards` 在基础奖励上增加了对脚部绊倒的惩罚
- `CommandsCfg` 定义了速度指令的范围和重采样时间
- `TerminationsCfg` 设置了终止条件,如时间结束或机器人躯干接触地面
2.4.1.8 主环境配置
`H1BaseRoughEnvCfg` 整合了上述所有配置,并在 `__post_init__` 中进行了额外设置:
- 仿真步长为 0.005 秒,每集长度 20 秒
- 优化了摩擦和弹性参数
- 调整了奖励权重,例如平坦姿态奖励权重为 -5.0
2.4.1.9 游戏测试配置
`H1BaseRoughEnvCfg_PLAY` 继承自主环境配置,但做了以下调整:
- 减少环境数量从 4096 到 40,以减轻计算负担
- 延长每集时间到 40 秒
- 固定机器人速度指令(前向速度固定为 0.5)
- 禁用了观察噪声和随机推力
这个配置主要用于在训练后对模型进行评估和演示
2.4.2 h1_low_vision_cfg.py:基础感知之上增加视觉感知导航
这段代码定义了一个面向H1四足机器人的强化学习环境配置,特别针对复杂地形中的视觉感知导航任务。与基础配置相比,该配置加入了更丰富的地形类型和环境感知能力。
2.4.2.1 强化学习算法配置
`H1VisionRoughPPORunnerCfg`类继承自`H1RoughPPORunnerCfg`,保留了原有的PPO算法超参数设置,如学习率、衰减因子、网络架构等,但将实验名称更改为"h1_vision_rough",表明这是一个基于视觉的复杂地形导航实验
2.4.2.2 复杂地形配置
`ROUGH_TERRAINS_CFG`定义了七种不同类型的地形,每种占据不同比例:
- 金字塔阶梯(20%):阶梯高度在0.05到0.3米之间
- 倒金字塔阶梯(20%):与上面相反的阶梯结构
- 随机箱体地形(20%):随机分布的箱形障碍物
- 随机粗糙地形(20%):带有0.02-0.10米噪声的不平整表面
- 金字塔斜坡(10%):斜率在0-0.4之间的斜坡地形
- 倒金字塔斜坡(10%):与上面相反的斜坡结构
- 离散障碍物(20%):固定高度为1.5米的障碍物
同时,为每种地形添加了平坦区域采样点,方便机器人学习从平地过渡到复杂地形。
2.4.2.3 场景与传感器配置
`TrainSceneCfg`类配置了训练场景,包括:
- 地形导入器,使用上述复杂地形生成器
class TrainSceneCfg(InteractiveSceneCfg): # 定义训练场景配置,继承自交互场景配置 """带有腿式机器人的地形场景配置""" # 地面地形 terrain = TerrainImporterCfg( # 地形导入器配置 prim_path="/World/ground", # 地形基元路径 terrain_type="generator", # 使用生成器类型 terrain_generator=ROUGH_TERRAINS_CFG, # 使用上面定义的粗糙地形生成器 max_init_terrain_level=5, # 可以尝试设为9 collision_group=-1, # 碰撞组设为-1 physics_material=sim_utils.RigidBodyMaterialCfg( # 物理材质配置 friction_combine_mode="multiply", # 摩擦力组合模式为乘法 restitution_combine_mode="multiply", # 弹性组合模式为乘法 static_friction=1.0, # 静摩擦系数1.0 dynamic_friction=1.0, # 动摩擦系数1.0 ), # 视觉材质配置 visual_material=sim_utils.MdlFileCfg( # 材质文件路径 mdl_path=f"{ISAACLAB_NUCLEUS_DIR}/Materials/TilesMarbleSpiderWhiteBrickBondHoned/TilesMarbleSpiderWhiteBrickBondHoned.mdl", # 投影UV坐标 project_uvw=True, # 纹理缩放比例 texture_scale=(0.25, 0.25), ), # 不显示调试可视化 debug_vis=False, ) - 机器人模型配置
# 机器人 # 使用H1最小配置,设置基元路径 robot = H1_MINIMAL_CFG.replace(prim_path="{ENV_REGEX_NS}/Robot") - 接触力传感器,用于检测机器人与地面的接触
# 传感器 # 接触力传感器配置 contact_forces = ContactSensorCfg(prim_path="{ENV_REGEX_NS}/Robot/.*", history_length=3, track_air_time=True, debug_vis=False) - 高度扫描器,使用射线投射技术检测前方地形高度
# 高度扫描器配置 height_scanner = RayCasterCfg( # 基元路径 prim_path="{ENV_REGEX_NS}/Robot/base", # 设置偏移位置,向上20米 offset=RayCasterCfg.OffsetCfg(pos=(0.0, 0.0, 20.0)), # 仅附加偏航角 attach_yaw_only=True, # 网格模式,分辨率0.1,大小1.6x1.0 pattern_cfg=patterns.GridPatternCfg(resolution=0.1, size=[1.6, 1.0]), # 不显示调试可视化 debug_vis=False, # 扫描的网格基元路径 mesh_prim_paths=["/World/ground"], ) # 修改扫描器基元路径为机器人躯干 height_scanner.prim_path = "{ENV_REGEX_NS}/Robot/torso_link" # 相机 # 激光雷达传感器为空 lidar_sensor = None # 深度传感器为空 depth_sensor = None - 天空光照效果
# 灯光 # 天空光配置 sky_light = AssetBaseCfg( # 基元路径 prim_path="/World/skyLight", # 使用半球光 spawn=sim_utils.DomeLightCfg( # 光强度750.0 intensity=750.0, # 天空纹理文件 texture_file=f"{ISAAC_NUCLEUS_DIR}/Materials/Textures/Skies/PolyHaven/kloofendal_43d_clear_puresky_4k.hdr", ), )
值得注意的是,代码中保留了深度传感器和激光雷达的接口,但当前设置为`None`,这表明未来可能会整合这些传感器。
2.4.2.4 观察空间配置
`ObservationsCfg`类定义了三种观察类型:
- `PolicyCfg`:策略网络使用的观察,包括:
基本动态信息:线速度、角速度、重力投影
关节状态:位置、速度# 配置类装饰器 # 策略观察组配置,用于策略网络 class PolicyCfg(ObsGroup): """策略组的观察""" # 观察项(保持顺序) # 基座线速度 base_lin_vel = ObsTerm(func=mdp.base_lin_vel) # 基座角速度 base_ang_vel = ObsTerm(func=mdp.base_ang_vel) # 投影重力 projected_gravity = ObsTerm(func=mdp.projected_gravity)
历史动作# 速度命令 velocity_commands = ObsTerm(func=mdp.generated_commands, params={"command_name": "base_velocity"}) # 关节位置 joint_pos = ObsTerm(func=mdp.joint_pos_rel) # 关节速度 joint_vel = ObsTerm(func=mdp.joint_vel_rel)
地形高度扫描:这是与基础配置的主要区别# 上一步动作 actions = ObsTerm(func=mdp.last_action)# 高度扫描结果 height_scan = ObsTerm( # 高度扫描函数 func=mdp.height_scan, # 使用高度扫描器 params={"sensor_cfg": SceneEntityCfg("height_scanner")}, # 限制值范围在-1到1之间 clip=(-1.0, 1.0), - `ProprioCfg`:本体感受观察,包含噪声干扰
# 配置类装饰器 # 本体感受观察组配置 class ProprioCfg(ObsGroup): """本体感受组的观察""" # 观察项 # 基座线速度,带噪声 base_lin_vel = ObsTerm(func=mdp.base_lin_vel, noise=Unoise(n_min=-0.2, n_max=0.2)) # 基座角速度,带噪声 base_ang_vel = ObsTerm(func=mdp.base_ang_vel, noise=Unoise(n_min=-0.2, n_max=0.2)) # 投影重力,带噪声 projected_gravity = ObsTerm( func=mdp.projected_gravity, noise=Unoise(n_min=-0.05, n_max=0.05), ) # 速度命令 velocity_commands = ObsTerm(func=mdp.generated_commands, params={"command_name": "base_velocity"}) # 关节位置,带噪声 joint_pos = ObsTerm(func=mdp.joint_pos_rel, noise=Unoise(n_min=-0.01, n_max=0.01)) # 关节速度,带噪声 joint_vel = ObsTerm(func=mdp.joint_vel_rel, noise=Unoise(n_min=-1.5, n_max=1.5)) # 上一步动作 actions = ObsTerm(func=mdp.last_action) # 后初始化方法 def __post_init__(self): # 拼接所有观察项 self.concatenate_terms = True - `CriticObsCfg`:评论家网络的观察,类似于策略网络但包含噪声设置
# 评论家观察组配置 class CriticObsCfg(ObsGroup): # 观察项(保持顺序) # 基座线速度,带噪声 base_lin_vel = ObsTerm(func=mdp.base_lin_vel, noise=Unoise(n_min=-0.1, n_max=0.1)) # 基座角速度,带噪声 base_ang_vel = ObsTerm(func=mdp.base_ang_vel, noise=Unoise(n_min=-0.2, n_max=0.2)) # 投影重力,带噪声 projected_gravity = ObsTerm( func=mdp.projected_gravity, noise=Unoise(n_min=-0.05, n_max=0.05), ) # 速度命令 velocity_commands = ObsTerm(func=mdp.generated_commands, params={"command_name": "base_velocity"}) # 关节位置,带噪声 joint_pos = ObsTerm(func=mdp.joint_pos_rel, noise=Unoise(n_min=-0.01, n_max=0.01)) # 关节速度,带噪声 joint_vel = ObsTerm(func=mdp.joint_vel_rel, noise=Unoise(n_min=-1.5, n_max=1.5)) # 上一步动作 actions = ObsTerm(func=mdp.last_action) # 高度扫描结果 height_scan = ObsTerm( func=mdp.height_scan, params={"sensor_cfg": SceneEntityCfg("height_scanner")}, clip=(-1.0, 1.0), )
2.4.2.5 奖励与终止条件
`CustomH1Rewards`类在基础奖励上增加了对脚部绊倒的惩罚,但环境配置中实际使用的是标准`H1Rewards`
终止条件包括时间到期和躯干接触地面
# 自定义H1奖励,继承自H1Rewards
class CustomH1Rewards(H1Rewards):
# 添加脚部绊倒惩罚
feet_stumble = RewTerm(
# 脚部绊倒函数
func=mdp.feet_stumble,
# 权重-0.5(惩罚)
weight=-0.5,
params={
# 使用踝关节的接触力传感器
"sensor_cfg": SceneEntityCfg("contact_forces", body_names=".*ankle_link"),
},
)2.4.2.6 训练与测试环境配置
主环境配置`H1VisionRoughEnvCfg`设定了:
- 4096个并行环境用于训练
- 每集20秒的仿真时间
- 物理参数如摩擦系数、弹性系数等
- 奖励权重调整,如平坦姿态奖励权重为-1.0
- 命令范围:前向速度在0到1之间,角速度在-1到1之间
`H1VisionRoughEnvCfg_PLAY`配置专为测试设计:
- 只使用40个环境
- 延长每集时间到40秒
- 减少地形复杂度以节省内存
- 固定前向速度为0.5,取消转向
- 禁用观察噪声和随机外力
整体看来,这个配置与基础配置相比,最大的不同在于添加了更为多样化的复杂地形以及地形感知能力,使H1机器人能够通过高度扫描获取前方地形信息,从而学习如何应对各种复杂地形的导航策略
第三部分 核心MDP组件omni/isaac/leggedloco/leggedloco/mdp
mdp目录包含了马尔可夫决策过程(MDP)的关键组件,这是强化学习环境的核心部分
3.1 actions/
这个目录包含定义机器人动作空间的类,例如:
- `navigation_actions.py` - 导航动作
- `vlm_navigation_actions_gpt.py` - 基于GPT的视觉-语言模型导航动作
- `vlm_navigation_actions.py` - 视觉-语言模型导航动作
3.1.1 navigation_actions.py:高层导航、底层控制
这段代码实现了一个分层控制系统,用于机器人导航任务。`NavigationAction` 类是一个高层控制器,负责将导航指令转换为低层运动控制动作,形成了一个典型的分层机器人控制架构
- 高层导航控制:接收导航指令(如前进、转向等),频率为10Hz
- 低层运动控制:执行实际的关节控制,频率为50Hz「由于物理引擎运行在200Hz,因此采用了4:1的抽取比例」
这种分层架构允许导航策略专注于路径规划和障碍物避开,而将复杂的运动动力学控制委托给预训练的低层策略
首先,初始化过程中,系统加载一个预训练的低层控制策略:
- 首先检查配置中指定的策略文件是否存在
- 使用`torch.jit.load`加载策略模型,并将其冻结为评估模式
- 准备所需的动作缓冲区,包括原始导航指令、处理后的导航指令和低层动作
低层策略接收来自环境的观察("low_level_policy"组),并生成关节控制命令
# 加载策略
# 加载TorchScript策略模型到指定设备
self.low_level_policy = torch.jit.load(file_bytes, map_location=self.device)
# 冻结策略模型并设为评估模式
self.low_level_policy = torch.jit.freeze(self.low_level_policy.eval()) 这些命令随后通过`low_level_action_term`类处理并应用于机器人
# 准备关节位置动作
# 创建低层动作处理对象
self.low_level_action_term: ActionTerm = self.cfg.low_level_action.class_type(cfg.low_level_action, env) 其次,系统运行时遵循以下流程:
- `process_actions`方法以10Hz的频率处理高层导航动作,将它们转换为速度指令(前进速度、横向速度和角速度)
# 处理动作方法 def process_actions(self, actions): """处理高层导航动作。该函数以10Hz的频率被调用""" # 存储低层导航动作 self._raw_navigation_velocity_actions[:] = actions # 将动作重塑为3D导航命令 self._processed_navigation_velocity_actions[:] = actions.clone().view(self.num_envs, 3) - `apply_actions`方法以200Hz的频率运行,但每4次迭代(即50Hz)才执行一次低层控制计算:
- 更新命令管理器
- 获取环境观察
- 通过低层策略生成关节控制命令
- 处理并应用这些命令def apply_actions(self): # 应用动作方法 """将低层动作应用到物理引擎的模拟器。此函数以200Hz的模拟频率被调用。由于低层运动控制以50Hz运行,我们需要抽取动作。""" # 如果计数器是抽取因子的整数倍 if self._counter % self.cfg.low_level_decimation == 0: self._counter = 0 # 重置计数器 # # -- 更新命令 self._env.command_manager.compute(dt=self._low_level_step_dt) # 更新命令管理器 # 从低层策略获取低层动作 # 使用低层策略处理观察获得动作 self._low_level_actions[:] = self.low_level_policy( self._env.observation_manager.compute_group(group_name="low_level_policy") ) # 处理低层动作 self.low_level_action_term.process_actions(self._low_level_actions) # 应用低层动作到物理引擎 self.low_level_action_term.apply_actions() # 增加计数器 self._counter += 1
这种抽取方法(每4次物理更新执行1次控制计算)能够减少计算负担,同时保持合理的控制频率
`NavigationActionCfg` 类定义了控制器的配置参数,包括:
- 低层抽取系数(默认为4,使低层控制频率为50Hz)
- 低层策略文件路径
- 低层动作配置
- 路径长度(51个点)
- 图像尺寸(暂未使用,代码中有相关注释掉的深度图像处理部分)
值得注意的是,代码中保留了一些已注释的图像处理功能,包括深度CNN和图像调整,表明该系统可能原本设计支持或未来计划支持视觉引导导航
3.1.2 vlm_navigation_actions_gpt.py:高层规划决策、低层运动执行
这段代码实现了一个用于机器人导航的分层控制架构。该系统的设计目的是通过视觉语言模型(VLM)和GPT技术来增强机器人的导航能力,建立了从高级导航指令到低级运动控制的映射关系
`VLMActionsGPT`类采用了典型的分层控制设计:
- 高层导航控制:负责处理速度指令(前进速度、横向速度和旋转速度),以10Hz的频率运行
- 低层运动控制:负责执行实际的关节控制,以50Hz的频率运行(由于物理引擎运行在200Hz,采用4:1抽取比例)
剩下的类似上节..
3.1.3 vlm_navigation_actions.py
`VLMActions`类设计了一个典型的两层控制系统:
- 高层导航控制:以10Hz的频率运行,处理三维导航指令(前进速度、横向速度和旋转速度)
- 低层运动执行:以50Hz的频率运行(通过4:1的抽取比例从200Hz的物理更新中获得),负责实际的关节控制
这种分层设计思路将复杂的导航问题分解为"决策"和"执行"两个相对独立的子问题,使系统更容易开发和维护。高层专注于"往哪里去"的问题,而低层专注于"如何到达"的问题
首先,系统在初始化阶段执行以下关键步骤:
- 验证低层策略文件是否存在,若不存在则抛出`FileNotFoundError`异常
# 初始化图像计数器为0 self.image_count = 0 # 检查策略文件是否存在 if not check_file_path(self.cfg.low_level_policy_file): # 抛出文件未找到异常 raise FileNotFoundError(f"Policy file '{self.cfg.low_level_policy_file}' does not exist.") # 读取低层策略文件内容为字节 file_bytes = read_file(self.cfg.low_level_policy_file) - 使用`torch.jit.load`加载预训练的低层策略模型,并通过`freeze`和`eval`方法优化其性能
# 加载策略 # 使用JIT加载低层策略模型到当前设备 self.low_level_policy = torch.jit.load(file_bytes, map_location=self.device) # 冻结策略模型并设置为评估模式以提高性能 self.low_level_policy = torch.jit.freeze(self.low_level_policy.eval()) - 初始化低层动作执行器,用于将策略输出转换为物理控制指令
# 准备关节位置动作 # 创建低层动作项实例 self.low_level_action_term: ActionTerm = self.cfg.low_level_action.class_type(cfg.low_level_action, env) - 创建三种动作缓冲区:原始导航动作、处理后的命令速度动作和低层控制动作
# 准备缓冲区 # 设置动作维度为3,包含前向速度、横向速度和旋转角速度 self._action_dim = ( 3 ) # 创建原始导航速度动作张量 self._raw_navigation_velocity_actions = torch.zeros(self.num_envs, self._action_dim, device=self.device) # 创建处理后的命令速度动作张量 self._processed_command_velocity_actions = torch.zeros( (self.num_envs, 3), device=self.device )
值得注意的是,系统预留了图像处理相关的代码(尽管被注释掉了),包括深度图像处理和图像大小调整,这表明该系统可能计划或曾经支持视觉输入处理
其次,动作处理分为两个主要阶段:
- 高层动作处理(`process_actions`方法):
- 接收并存储导航指令
- 将指令重塑为标准三维向量形式(vx, vy, omega)
- 这些指令的范围约束在:vx[-0.5,1.0]、vy[-0.5,0.5]、omega[-1.0,1.0]# 处理动作方法 def process_actions(self, actions): # 处理高层导航动作,此函数以10Hz的频率被调用 # 将输入动作存储到原始导航速度动作缓冲区 self._raw_navigation_velocity_actions[:] = actions # 重塑为3D路径 # 克隆动作并重塑为(num_envs, 3)的形状存入处理后的命令速度动作缓冲区 self._processed_command_velocity_actions[:] = actions.clone().view(self.num_envs, 3) - 低层动作执行(`apply_actions`方法):
- 采用计数器进行频率控制,每4个物理时间步执行一次控制计算
- 更新环境的命令系统
- 通过低层策略处理环境观察,生成关节控制命令
- 应用这些命令到物理引擎def apply_actions(self): # 应用动作方法 # 将低层动作应用到物理引擎,此函数以200Hz的仿真频率被调用,由于低层运动控制以50Hz运行,我们需要降采样动作 # 如果计数器是降采样因子的整数倍 if self._counter % self.cfg.low_level_decimation == 0: self._counter = 0 # 重置计数器为0 # 使用低层步长时间间隔计算命令管理器 self._env.command_manager.compute(dt=self._low_level_step_dt) # 使用观察管理器计算低层策略所需的观察组 # 将低层策略的输出存储到低层动作缓冲区 self._low_level_actions[:] = self.low_level_policy( self._env.observation_manager.compute_group(group_name="low_level_policy") ) # 处理低层动作 # 使用低层动作项处理低层动作 self.low_level_action_term.process_actions(self._low_level_actions) # 使用低层动作项应用动作 self.low_level_action_term.apply_actions() # 计数器加1 self._counter += 1
整个过程形成了一个闭环:高层导航指令→低层运动策略→关节控制命令→物理执行→环境反馈→低层运动策略...
最后,`VLMActionsCfg`类定义了系统的配置参数:
- 低层控制频率抽取系数(默认为4)
- 低层动作配置(由使用者提供)
- 低层策略文件路径(必须提供)
系统设计允许通过配置文件调整这些参数,而无需修改代码,增强了系统的灵活性。值得注意的是,配置中还保留了一些被注释掉的参数(如路径长度和图像尺寸),这可能是未来功能的占位符
3.2 commands/
命令生成器相关文件,例如:
- `goal_command_generator_cfg.py` - 目标命令生成器配置
- `goal_command_generator.py` - 目标命令生成器实现
3.3 rewards/
奖励函数相关的实现,用于在强化学习过程中对机器人行为进行评价。从配置文件中可以看到各种奖励项,例如:
# 终止惩罚
termination_penalty = RewTerm(func=mdp.is_terminated, weight=-200.0)
track_lin_vel_xy_exp = RewTerm( # 跟踪线性速度奖励
func=mdp.track_lin_vel_xy_yaw_frame_exp,
weight=1.0,
params={"command_name": "base_velocity", "std": 0.5},
)其他文件:
- `curriculums.py` - 课程学习相关,用于逐渐增加训练难度
- `events.py` - 事件处理
- `observations.py` - 观察空间定义
3.3.1 rewards/objnav_rewards.py:机器人目标导航中的奖励设计
首先,代码首先定义了最基础的奖励信号:
- `is_alive` 函数为未终止的环境提供正向奖励,鼓励机器人继续运行
# 定义is_alive函数,判断是否存活 def is_alive(env: ManagerBasedRLEnv) -> torch.Tensor: # 为存活提供奖励 # 返回未终止环境的浮点张量,代表存活奖励 return (~env.termination_manager.terminated).float() - `is_terminated` 函数对非超时导致的终止行为施加惩罚
# 定义is_terminated函数,判断是否终止 def is_terminated(env: ManagerBasedRLEnv) -> torch.Tensor: # 对非超时导致的终止进行惩罚 # 返回已终止环境的浮点张量,代表终止惩罚 return env.termination_manager.terminated.float() - `is_terminated_term` 类更加细致地处理不同原因的终止事件,允许选择性地惩罚特定终止条件
这种设计允许对机器人的存活时间进行精细控制,区分"正常结束"和"意外失败"两种情况
其次,代码中大量的奖励函数专注于维持机器人的稳定性和自然姿态:
- `lin_vel_z_l2` 和 `ang_vel_xy_l2` 惩罚不必要的垂直运动和倾斜旋转
- `flat_orientation_l2` 鼓励机器人保持水平姿态
# 定义平面方向的L2惩罚函数 def flat_orientation_l2(env: ManagerBasedRLEnv, asset_cfg: SceneEntityCfg = SceneEntityCfg("robot")) -> torch.Tensor: # 使用L2核惩罚非平面基座方向 # 这通过惩罚投影重力向量的XY分量来计算 # 从环境场景中获取指定名称的资产对象 asset: RigidObject = env.scene[asset_cfg.name] # 返回投影重力向量XY分量的平方和 return torch.sum(torch.square(asset.data.projected_gravity_b[:, :2]), dim=1) - `base_height_l2` 引导机器人维持适当的高度
这些奖励函数在向前移动的同时,抑制了机器人的额外摇摆和不稳定动作,使其行走更加自然流畅
接着,一系列关节相关的奖励函数控制着机器人的精细动作:
- `joint_torques_l2` 和 `power_penalty` 惩罚过大的关节力矩和能量消耗
# 定义关节扭矩的L2惩罚函数 def joint_torques_l2(env: ManagerBasedRLEnv, asset_cfg: SceneEntityCfg = SceneEntityCfg("robot")) -> torch.Tensor: # 使用L2核惩罚施加在关节上的扭矩 # 注意:只有在asset_cfg.joint_ids中配置的关节的扭矩才会计入L2范数 # 从环境场景中获取指定名称的资产对象 asset: Articulation = env.scene[asset_cfg.name] # 返回指定关节ID上施加的扭矩平方和 return torch.sum(torch.square(asset.data.applied_torque[:, asset_cfg.joint_ids]), dim=1) - `joint_vel_l1/l2` 和 `joint_acc_l2` 鼓励平滑的关节运动
- `joint_deviation_l1` 和 `joint_pos_limits` 引导关节保持在合理的活动范围内
这些函数共同作用,使机器人的动作更加自然、高效,避免了抽搐或过度疲劳的运动模式
再之后,代码的核心部分是导航相关的目标导向奖励:
- `track_lin_vel_xy_exp` 和 `track_ang_vel_z_exp` 奖励机器人精确跟踪速度命令
- `goal_distance` 根据机器人到目标的距离提供奖励
def goal_distance( # 定义目标距离奖励函数 # 参数:环境、命令名称、资产配置 env: ManagerBasedRLEnv, command_name: str, asset_cfg: SceneEntityCfg = SceneEntityCfg("robot") ) -> torch.Tensor: # 使用指数核奖励线性速度命令跟踪(注:文档字符串与函数名不完全一致,这是目标距离) # 从环境场景中获取指定名称的资产对象 asset: RigidObject = env.scene[asset_cfg.name] # 计算误差 # 计算目标位置的XY平面距离 goal_track_error_pos = torch.norm(env.command_manager.get_command(command_name)[:,:2], dim=1) # 当距离小于1时奖励为1,否则为指数衰减奖励 reward = torch.where(goal_track_error_pos < 1.0, torch.tensor(1.0, device=env.device), torch.exp(-0.2*goal_track_error_pos)) # 返回奖励 return reward - `robot_goal_velocity_projection` 鼓励机器人朝向目标方向移动
- `goal_direction` 奖励机器人面向目标的行为
特别值得注意的是,这些函数使用了指数奖励机制,随着机器人接近目标,奖励呈非线性增长,这有效地解决了稀疏奖励问题
此外,代码还实现了一些针对特定行为的奖励函数:
- `feet_air_time` 和 `feet_air_time_positive_biped` 鼓励正确的步态模式
- `feet_stumble` 惩罚脚部绊倒的情况
- `stand_still_penalty` 在低速命令时鼓励机器人站定不动
- `stand_still_velocity_penalty` 在达到目标后惩罚继续移动的行为
3.3.2 curriculums.py:课程学习相关,用于逐渐增加训练难度
3.3.3 events.py:事件处理
3.3.4 observations.py:观察空间定义
第四部分 rsl_rl/:经典RL框架的封装(含我对PPO实现的解读)
这是一个强化学习算法框架,包含以下主要组件:
rsl_rl/
config/ - 配置文件
rsl_rl/ - 核心代码
algorithms/ - 强化学习算法实现,如PPO
env/ - 环境封装
modules/ - 模型组件
actor_critic.py - 基础Actor-Critic网络
actor_critic_depth_cnn.py - 带深度视觉的Actor-Critic网络
actor_critic_history.py - 带历史信息的Actor-Critic网络
actor_critic_recurrent.py - 循环神经网络版Actor-Critic
depth_backbone.py - 深度视觉处理网络
runners/ - 训练运行器
storage/ - 数据存储
utils/ - 工具函数这个模块定义了强化学习的核心组件,包括actor-critic网络架构(有普通版、CNN版、历史记忆版和RNN版)、PPO算法实现、训练运行器等
从代码中可以看出,它支持不同类型的输入数据(如关节状态、深度图像等)
4.1 rsl_rl/algorithms/ppo.py:近端策略优化PPO的实现
这段代码定义了一个名为 `PPO` 的类,它实现了近端策略优化(Proximal Policy Optimization)算法,其详细介绍详见此文的《强化学习极简入门:通俗理解MDP、DP MC TD和Q学习、策略梯度、PPO》第4.4节
4.1.1 初始化__init__
- 构造函数接收一个
`actor_critic` 网络(策略网络和价值网络的组合)
学习超参数(如学习周期 `num_learning_epochs`、小批量数量 `num_mini_batches`、裁剪参数 `clip_param`、折扣因子 `gamma`、GAE lambda `lam` 等)
以及优化器设置(学习率 `learning_rate`、梯度裁剪范数 `max_grad_norm`) - 它初始化 PPO 的核心组件:
`actor_critic`: 传入的神经网络模型,并将其移动到指定的设备(如 CPU 或 GPU)
`storage`: 用于存储经验轨迹(transitions)的 `RolloutStorage` 对象,稍后初始化
`optimizer`: 使用 Adam 优化器来更新 `actor_critic` 网络的参数
`transition`: 一个临时的 `RolloutStorage.Transition` 对象,用于在每个环境步骤中收集数据 - 存储 PPO 算法的关键超参数。
- 设置学习率调度策略(`schedule`)和目标 KL 散度(`desired_kl`),用于自适应学习率调整
4.1.2 存储初始化init_storage
- 这个方法根据环境的数量、每个环境收集的转换(transitions)数量、观察空间形状和动作空间形状来创建 `RolloutStorage` 实例
- `RolloutStorage` 负责存储智能体与环境交互产生的数据序列
4.1.3 模式切换test_mode/train_mode
这些方法用于切换 `actor_critic` 网络到评估(测试)模式或训练模式。这对于包含 Dropout 或 Batch Normalization 层的网络很重要
4.1.4 动作选择act
这是智能体与环境交互的核心。给定当前观察 `obs`(用于策略网络)和 `critic_obs`(用于价值网络,可能与 `obs` 相同或包含额外信息),它执行以下操作:
- 如果网络是循环的(RNN/LSTM),获取并存储隐藏状态。
- 使用 `actor_critic` 网络
计算动作 (`actions`)
状态价值 (`values`)# 使用 Actor-Critic 网络计算动作,并分离计算图 self.transition.actions = self.actor_critic.act(obs).detach()
和动作的对数概率 (`actions_log_prob`)# 使用 Actor-Critic 网络评估状态价值,并分离计算图 self.transition.values = self.actor_critic.evaluate(critic_obs).detach()# 获取动作的对数概率,并分离计算图 self.transition.actions_log_prob = self.actor_critic.get_actions_log_prob(self.transition.actions).detach() - 存储动作分布的均值 (`action_mean`) 和标准差 (`action_sigma`)
- 将当前的观察、评论家观察以及计算出的所有信息存储在临时的 `transition` 对象中
- 返回计算出的动作,供环境执行
4.1.5 处理环境步骤process_env_step
在环境执行动作后调用此方法
- 接收奖励 (`rewards`)、完成标志 (`dones`) 和额外信息 (`infos`)
- 将这些信息存储到 `transition` 对象中
重要: 它实现了"超时引导 (Bootstrapping on time outs)"。如果一个 episode 因为达到时间限制而不是因为失败状态而结束(通过 `infos["time_outs"]` 判断),它会将最后一步的估计价值(乘以 `gamma`)加到奖励中
这可以防止智能体因为时间限制而受到不公平的惩罚,并提供更准确的回报估计 - 将完整的 `transition` 添加到 `storage` 中
- 清空 `transition` 对象,为下一步做准备
- 如果网络是循环的,根据 `dones` 信号重置其隐藏状态
4.1.6 计算回报compute_returns
- 在收集了足够多的 transitions 后调用
- 首先,使用 `actor_critic` 网络评估最后一个状态的价值 (`last_values`)
# 计算回报和优势的方法 def compute_returns(self, last_critic_obs): # 评估最后一个状态的价值 last_values = self.actor_critic.evaluate(last_critic_obs).detach() - 然后,调用 `storage.compute_returns` 方法
这个方法通常使用广义优势估计 (Generalized Advantage Estimation, GAE)来计算每个时间步的回报 (`returns`) 和优势 (`advantages`)# 调用存储器的 compute_returns 方法计算回报和 GAE 优势 self.storage.compute_returns(last_values, self.gamma, self.lam)
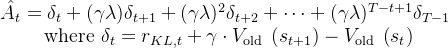
GAE 结合了不同时间步长的价值估计,以减少估计的方差
4.1.7 更新update
这是执行策略和价值网络参数更新的核心循环
# 更新策略和价值网络参数的方法
def update(self):
# 初始化平均价值损失
mean_value_loss = 0
# 初始化平均代理损失
mean_surrogate_loss = 0- 它首先根据网络是否是循环的,选择合适的小批量生成器(`mini_batch_generator` 或 `reccurent_mini_batch_generator`) 从 `storage` 中采样数据
# 检查 Actor-Critic 网络是否是循环网络 if self.actor_critic.is_recurrent: # 如果是循环网络,使用循环小批量生成器 generator = self.storage.reccurent_mini_batch_generator(self.num_mini_batches, self.num_learning_epochs) # 如果不是循环网络 else: # 使用标准小批量生成器 generator = self.storage.mini_batch_generator(self.num_mini_batches, self.num_learning_epochs) - 在多个学习周期 (epochs) 内迭代:
# 遍历小批量生成器产生的数据 for ( obs_batch, # 观察值小批量 critic_obs_batch, # 评论家观察值小批量 actions_batch, # 动作小批量 target_values_batch, # 目标价值小批量 (用于价值损失计算,通常是回报) advantages_batch, # 优势小批量 returns_batch, # 回报小批量 (用于价值损失计算) old_actions_log_prob_batch, # 旧策略下的动作对数概率小批量 old_mu_batch, # 旧策略下的动作均值小批量 old_sigma_batch, # 旧策略下的动作标准差小批量 hid_states_batch, # 隐藏状态小批量 (仅用于循环网络) masks_batch, # 掩码小批量 (仅用于循环网络) ) in generator:
对于每个小批量 (mini-batch)
- 重新计算当前策略下的小批量数据的动作对数概率、价值和熵
# 使用当前策略重新评估动作 (主要为了获取内部状态如均值、标准差) self.actor_critic.act(obs_batch, masks=masks_batch, hidden_states=hid_states_batch[0]) # 获取当前策略下动作的对数概率 actions_log_prob_batch = self.actor_critic.get_actions_log_prob(actions_batch) # 使用当前策略评估状态价值 value_batch = self.actor_critic.evaluate( # 传入评论家观察、掩码和隐藏状态 critic_obs_batch, masks=masks_batch, hidden_states=hid_states_batch[1] ) # 获取当前策略的动作均值 mu_batch = self.actor_critic.action_mean # 获取当前策略的动作标准差 sigma_batch = self.actor_critic.action_std # 获取当前策略的熵 entropy_batch = self.actor_critic.entropy- KL 散度与自适应学习率:如果启用了自适应学习率 (`schedule == "adaptive"`),计算当前策略和旧策略(生成数据时的策略)之间的 KL 散度「 详见此文的《强化学习极简入门:通俗理解MDP、DP MC TD和Q学习、策略梯度、PPO》第4.4节」
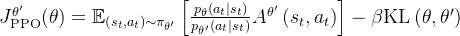 上面这个KL公式稍微有点小复杂,但为方便大家更好的理解 更为大家看着舒服、省心,我还是把上面这段代码对应的公式 写一下,且把代码的每一行 与公式当中的各个项,逐一对应说明下
上面这个KL公式稍微有点小复杂,但为方便大家更好的理解 更为大家看着舒服、省心,我还是把上面这段代码对应的公式 写一下,且把代码的每一行 与公式当中的各个项,逐一对应说明下# KL 散度计算 (用于自适应学习率) # 如果设置了期望 KL 且调度策略是自适应的 if self.desired_kl is not None and self.schedule == "adaptive": # 在无梯度计算模式下进行 with torch.inference_mode(): # 计算当前策略和旧策略之间的 KL 散度 kl = torch.sum( # 对数标准差比项 (+1e-5 防止除零) torch.log(sigma_batch / old_sigma_batch + 1.0e-5) # 旧标准差平方 + 均值差平方项 + (torch.square(old_sigma_batch) + torch.square(old_mu_batch - mu_batch)) # 除以 2 倍当前标准差平方 / (2.0 * torch.square(sigma_batch)) # 减去 0.5 - 0.5, # 沿着最后一个维度求和 axis=-1, )
假设当前策略的均值和标准差分别为 μ 和 σ,旧策略的均值和标准差分别为和
,则 KL 散度的公式为
首先,其中这行代码对应为# 对数标准差比项 (+1e-5 防止除零) torch.log(sigma_batch / old_sigma_batch + 1.0e-5)
其次,接下来的这行代码对应于# 旧标准差平方 + 均值差平方项 + (torch.square(old_sigma_batch) + torch.square(old_mu_batch - mu_batch))
然后其中的「除以 2 倍当前标准差平方」的代码:对应于# 除以 2 倍当前标准差平方 / (2.0 * torch.square(sigma_batch))
接下来,减去0.5的代码 对应为
最后,沿着最后一个维度求和的代码 对应为
![\sum_{i=1}^{d}\left[\log \left(\frac{\sigma_{i}}{\sigma_{\text {old }, i}}+10^{-5}\right)+\frac{\sigma_{\text {old }, i}^{2}+\left(\mu_{\text {old }, i}-\mu_{i}\right)^{2}}{2 \sigma_{i}^{2}}-\frac{1}{2}\right]](https://latex.csdn.net/eq?%5Csum_%7Bi%3D1%7D%5E%7Bd%7D%5Cleft%5B%5Clog%20%5Cleft%28%5Cfrac%7B%5Csigma_%7Bi%7D%7D%7B%5Csigma_%7B%5Ctext%20%7Bold%20%7D%2C%20i%7D%7D+10%5E%7B-5%7D%5Cright%29+%5Cfrac%7B%5Csigma_%7B%5Ctext%20%7Bold%20%7D%2C%20i%7D%5E%7B2%7D+%5Cleft%28%5Cmu_%7B%5Ctext%20%7Bold%20%7D%2C%20i%7D-%5Cmu_%7Bi%7D%5Cright%29%5E%7B2%7D%7D%7B2%20%5Csigma_%7Bi%7D%5E%7B2%7D%7D-%5Cfrac%7B1%7D%7B2%7D%5Cright%5D)
哦了,公式解释好了,那接下来,根据 KL 散度与 `desired_kl` 的比较,动态调整优化器的学习率# 计算 KL 散度的平均值 kl_mean = torch.mean(kl) # 如果 KL 散度远大于期望值 if kl_mean > self.desired_kl * 2.0: # 降低学习率 (最小为 1e-5) self.learning_rate = max(1e-5, self.learning_rate / 1.5) # 如果 KL 散度远小于期望值 (且大于 0) elif kl_mean < self.desired_kl / 2.0 and kl_mean > 0.0: # 提高学习率 (最大为 1e-2) self.learning_rate = min(1e-2, self.learning_rate * 1.5)- 代理损失 (Surrogate Loss): 计算 PPO 的核心损失项。它使用重要性采样比率 (`ratio`) 和优势 (`advantages_batch`),并应用**裁剪 (clipping) 来限制策略更新的幅度,防止策略变化过大
`surrogate_loss` 是裁剪后损失和未裁剪损失中的较大者# 代理损失计算 (PPO 核心目标) # 计算重要性采样比率 (当前概率 / 旧概率) ratio = torch.exp(actions_log_prob_batch - torch.squeeze(old_actions_log_prob_batch)) # 计算未裁剪的代理损失项 surrogate = -torch.squeeze(advantages_batch) * ratio # 计算裁剪后的代理损失项 surrogate_clipped = -torch.squeeze(advantages_batch) * torch.clamp( # 且将比率裁剪到 [1-clip, 1+clip] 范围内 ratio, 1.0 - self.clip_param, 1.0 + self.clip_param ) # 取未裁剪和裁剪后损失中的较大者,并计算平均值 surrogate_loss = torch.max(surrogate, surrogate_clipped).mean()- 价值函数损失 (Value Function Loss):计算价值网络的损失
根据此文《ChatGPT技术原理解析:从RL之PPO算法、RLHF到GPT4、instructGPT》的「3.3.2 GAE之下的优势函数计算、回报序列计算、价值序列的迭代」,有
可以选择使用裁剪的价值损失 (clipped value loss),这类似于策略损失的裁剪,有助于稳定训练# 价值函数损失计算 # 如果使用裁剪的价值损失 if self.use_clipped_value_loss: # 计算裁剪后的价值预测 value_clipped = target_values_batch + (value_batch - target_values_batch).clamp( # 将价值预测与目标价值的差值裁剪到 [-clip, clip] -self.clip_param, self.clip_param ) # 计算未裁剪的价值损失 (均方误差) value_losses = (value_batch - returns_batch).pow(2) # 计算裁剪后的价值损失 (均方误差) value_losses_clipped = (value_clipped - returns_batch).pow(2) # 取未裁剪和裁剪后损失中的较大者,并计算平均值 value_loss = torch.max(value_losses, value_losses_clipped).mean() # 如果不使用裁剪的价值损失 else: # 直接计算价值损失 (均方误差) value_loss = (returns_batch - value_batch).pow(2).mean()- 总损失: 将代理损失、价值损失(乘以系数 `value_loss_coef`)和熵奖励(乘以系数 `entropy_coef`,鼓励探索)结合起来
# 计算总损失 = 代理损失 + 价值损失 - 熵奖励 loss = surrogate_loss + self.value_loss_coef * value_loss - self.entropy_coef * entropy_batch.mean()- 梯度更新: 计算总损失的梯度,执行梯度裁剪 (`clip_grad_norm_`) 防止梯度爆炸,然后让优化器执行一步更新
# 梯度更新步骤 # 清空优化器的梯度 self.optimizer.zero_grad() # 反向传播计算梯度 loss.backward() # 对梯度进行裁剪,防止梯度爆炸 nn.utils.clip_grad_norm_(self.actor_critic.parameters(), self.max_grad_norm) # 执行一步优化器更新 self.optimizer.step() # 累加当前小批量的价值损失 (转换为 Python float) mean_value_loss += value_loss.item() # 累加当前小批量的代理损失 (转换为 Python float) mean_surrogate_loss += surrogate_loss.item()
- 累积并计算平均的价值损失和代理损失,用于监控训练过程
# 计算总的更新次数 num_updates = self.num_learning_epochs * self.num_mini_batches # 计算整个 update 过程中的平均价值损失 mean_value_loss /= num_updates # 计算整个 update 过程中的平均代理损失 mean_surrogate_loss /= num_updates - 清空 `storage`,为下一轮数据收集做准备
# 清空经验存储器,为下一轮数据收集做准备 self.storage.clear() - 返回平均损失值
# 返回平均价值损失和平均代理损失 return mean_value_loss, mean_surrogate_loss
4.2 rsl_rl/env
4.3 rsl_rl/modules
4.3.1 modules/actor_critic_depth_cnn.py
4.3.2 modules/actor_critic_history.py
4.3.3 modules/actor_critic_recurrent.py
4.3.4 modules/actor_critic.py
4.3.5 modules/depth_backbone.py
4.3.6 modules/normalizer.py
4.4 rsl_rl/runners
// 待更
第五部分 scripts/
这个目录包含了用于训练、测试和演示的脚本:
scripts/
cli_args.py - 命令行参数定义
demo_matterport.py - Matterport环境演示脚本
play_low_matterport_keyboard.py - 键盘控制机器人脚本
play.py - 运行训练好的策略
run_data_collection.py - 数据收集脚本
train.py - 训练脚本
utils.py - 工具函数这些脚本提供了与项目交互的接口。从README中我们可以看到使用示例,如:
# 训练
python scripts/train.py --task=go2_base --history_len=9 --run_name=XXX --max_iterations=2000 --save_interval=200 --headless
# 测试
python scripts/play.py --task=go2_base_play --history_len=9 --load_run=RUN_NAME --num_envs=10// 待更


















 2879
2879

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











