







前言
之所以写本文,源于三个方面
- 一方面,我司「七月在线」准备在一个人形项目中,试下英伟达通用人形VLA GR00T N1,而GR00T N1中所用的VLM是他们自家于25年1月发布的Eagle 2
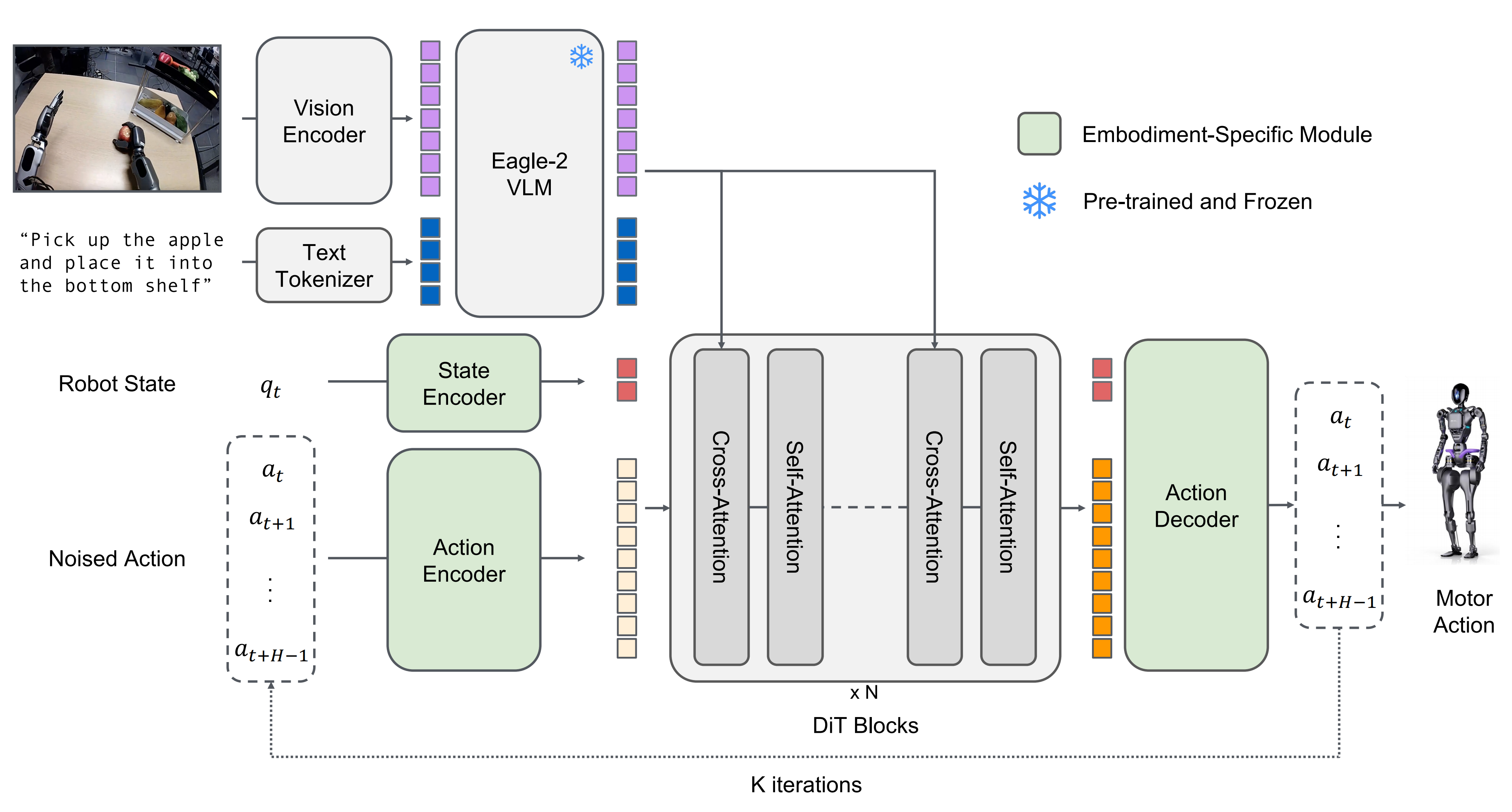
- 二方面,Eagle 2的理念特别好,如其在摘要中所说的,近年来,开源视觉语言模型VLMs在将其能力接近专有前沿模型方面取得了有希望的进展。然而,大多数开源模型仅发布其最终的模型权重,数据策略和实现的关键细节仍然不透明
在Eagle 2的这项工作中,作者从数据为中心的角度解决VLM的后训练问题,展示数据策略在开发前沿VLMs中的关键作用
且通过从头开始研究和构建我们的后训练数据策略,作者分享了开发过程中的详细见解 - 三方面,顺便梳理一下目前主流的多模态大模型,毕竟多模态对具身智能的赋能作用太明显了
比如本文第一部分会先介绍LLaVA
当然了,Eagle2-9B宣称在各种多模态基准上取得了最先进的结果,与参数量高达70B的某些竞争模型相匹敌
于此,本文来了
顺带感谢具身智能,让我有了再次奋战几十年的热情与动力,也感谢大模型与具身智能,让我凭借过去三年 每天当三天的拼命/努力,而有了足够大的底气 自信 实力——全靠勤奋
第一部分 LLaVA
1.1 LLaVA
1.1.1 引言与提出背景
基于最近的LLM LLaMA,OpenFlamingo [5]和LLaMA-Adapter [59]使得LLaMA能够接收图像输入,为构建开源多模态LLM铺平了道路
虽然这些模型表现出有前途的任务迁移泛化能力,但它们并未明确使用视觉-语言指令数据进行微调,因此在多模态任务中的表现通常不及仅语言任务
23年12月,来自Wisconsin–Madison大学、微软研究院、哥伦比亚大学的研究者提出了LLaVA,其将CLIP [40]的开放集视觉编码器与语言解码器Vicuna [9]连接起来,并在生成的指令视觉-语言数据上进行端到端微调
1.1.2 GPT辅助的视觉指令数据生成
受到最近GPT模型在文本注释任务中成功的启发[17],作者提出利用ChatGPT/GPT-4进行多模态指令跟随数据收集——基于广泛存在的图像对数据
- 对于一张图像
及其相关的描述
,自然的做法是创建一组问题
,以引导助手描述图像内容。作者提示GPT-4来策划这样一组问题(详见附录)
因此,将图像-文本对扩展为遵循指令的版本的一种简单方法是
说白了,就是让GPT4 给一张张图像打字幕,以拿到图像-字幕对数据..
虽然构造成本低,但这种简单的扩展版本在指令和响应中都缺乏多样性和深入推理 - 为了解决这个问题,作者利用仅支持文本的 GPT-4 或 ChatGPT 作为强大的教师(两者都仅接受文本作为输入),以创建涉及视觉内容的指令跟随数据
具体来说,为了将图像编码为视觉特征,以提示仅支持文本的 GPT,使用两种符号表示:
- 字幕通常从不同的角度描述视觉场景
- 边界框通常定位场景中的对象,每个框都编码对象的概念及其空间位置
通过这种符号表示法使得能够将图像编码为LLM可识别的序列,一个示例如表 14 顶部模块所示,作者使用COCO图像[31]并生成三种类型的指令遵循数据「对于每种类型,首先手动设计一些示例。这些是作者在数据收集中拥有的唯一人工注释,并用作上下文学习中的种子示例以查询GPT-4」

- 对话
作者设计了一段助理与一个人就这张照片进行问答的对话。回答的语气好像助理正在观察图像并回答问题
关于图像的视觉内容,提出了多样化的问题,包括对象类型、对象数量、对象动作、对象位置、对象之间的相对位置。仅考虑有明确答案的问题。详细提示请参见附录 - 详细描述
为了为图像提供丰富而全面的描述,作者创建了一个包含此意图的问题列表。提示GPT-4,然后整理此列表
对于每张图像,从列表中随机抽取一个问题,要求GPT-4生成详细描述 - 复杂推理
这两种类型主要关注于视觉内容本身,在此基础上,进一步创建深入的推理问题。答案通常需要遵循严格的逻辑进行逐步推理
最终,作者总共收集了158K个独特的语言-图像指令跟随样本,包括58K个对话样本,23K个详细描述样本,以及77K个复杂推理样本。在早期实验中,作者对ChatGPT和GPT-4的使用进行了消融实验,发现GPT-4始终提供更高质量的指令跟随数据,例如空间推理
1.2 可视化指令调整
1.2.1 架构
主要目标是有效利用预训练的大语言模型(LLM)和视觉模型的能力。网络架构如下图图1所示
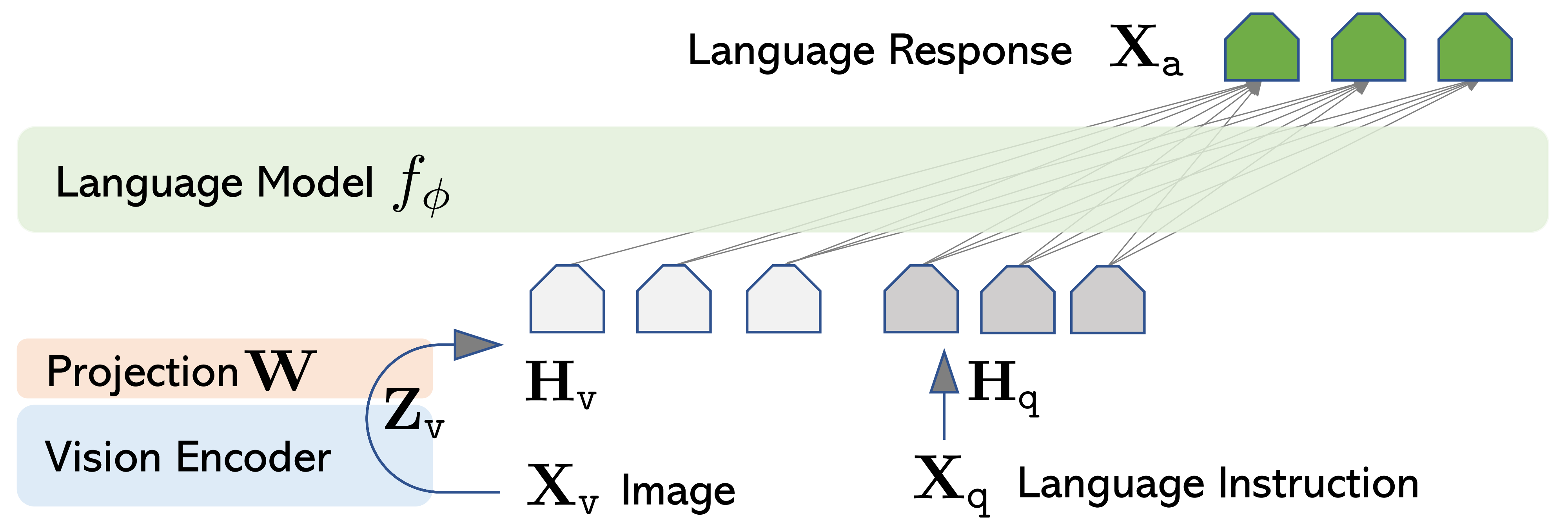
- 作者选择了Vicuna 『9,详见此文《LLaMA的解读与其微调(含LLaMA 2):Alpaca-LoRA/Vicuna/BELLE/中文LLaMA/姜子牙》的「2.3.1 UC Berkeley的Vicuna/FastChat:通过ShareGPT.com的7万条对话数据微调LLaMA」』 作为
,由
参数化
- 因为它在公开可用的检查点中具有语言任务中最佳的指令跟随能力[48,9,38]——注意 此点限定在24年之前
对于输入图像,考虑预训练的CLIP 视觉编码器ViT-L/14 [40],其提供视觉特征
- 在实验中,考虑了最后一个Transformer 层之前和之后的网格特征,以及使用一个简单的线性层将图像特征连接到词嵌入空间
- 具体来说,应用一个可训练的投影矩阵
将
转换为语言嵌入token
,其具有与语言模型中词嵌入空间相同的维度
当然,也可以考虑更复杂的图像和语言表示连接方案,例如Flamingo [2]中的门控交叉注意力和BLIP-2 [28]中的Q-former
1.2.2 训练
// 待更
第二部分 Eagle 2
2.1 提出背景与相关工作
2.1.1 引言:如何构建足够具有竞争力的VLM
基于大语言模型(LLMs),视觉-语言模型(VLMs)[1,2,3,4]旨在使LLMs能够“看见”
- 通过具备视觉感知能力,VLMs能够接收多模态信息,从而处理更广泛的智能应用,例如智能代理[5-Cogagent]、自动驾驶[6-DriveVLM,7-LingoQA],和具身人工智能[8-RT-2,9-Palm-e,10- OpenVLA]等
- 研究社区已经深入探讨了视觉语言模型(VLM)的架构和训练方法,并取得了显著进展。一种主要的策略是通过在预训练的大型语言模型(LLM)上进行后训练来对齐视觉和语言模态,其中LLaVA系列[4]是代表性示例
根据透明度的不同,当前的VLM模型也可以大致分为三类:
- 商业闭源模型(例如,GPT-4v/o[11]和Claude[12])
- 具有公开权重的前沿模型(例如,Qwen2-VL[13]、InternVL2[14]和Llama 3.1[15])
- 以及完全开源模型(例如,Cambrian-1[16]和LLaVA系列[4,17])
但不太幸的是,完全开源的LLaVA-OneVision-72B [17]仍略逊于半开源的InternVL2-40B [14]
那如何构建足够具有竞争力的VLM呢,Eagle 2的作者们认为有以下三大关键点
- 数据策略
“多样性优先,然后是质量”——Eagle 2在整个开发过程中遵循这一原则,并将其推向极致
他们对数据的优化使模型持续改进。包括:
1)数据收集策略,构建了一个由180多个来源组成的大规模高多样性数据池
2)数据过滤策略,用于去除低质量样本
3)数据选择策略,用于构建高质量的子集
4)一系列数据增强技术,用于丰富现有数据 - 模型架构
比如尽管有各种设计,例如 Q-Former [19] 和 Hybrid-Attention[20],简单的 MLP 连接器仍然是将视觉编码器与 LLM 连接的最流行选择
再比如,视觉编码器的拼接混合。受到InternVL[21,14]、Eagle [22]和Cambrian-1 [16]的启发,Eagle 2采用了一种以视觉为中心的设计,结合了Dynamic tiling和视觉编码器混合(MoVE)于一个统一的架构中
具体而言,每个图像块通过通道拼接的MoVE进行编码,从而在实现高分辨率输入的同时,保持了MoVE的强大感知能力
Specifically, each imagetile is encoded by channel-concatenated MoVE, therefor eallowing high-resolution input from tiling while maintain-ing the robust perception from MoVE
且与[22]类似,Eagle 2采用了“SigLIP [23] + X (ConvNeXt[24])”的配置
相比单独使用SigLIP,MoVE因为分块tiling 实现了显著的性能提升,尤其在OCR和图表/文档VQA等任务中表现突出
Compared to SigLIP alone, tiled MoVE yields significant improvements despite having tiling, particularly in tasks like OCR and Chart/Document VQA - 训练配方
虽然最先进的VLM [25-Qwen2-VL,14-InternVL2,26- Gpt-4 technical report]的训练配方不太明确,但现有研究[16-Cambrian-1,4-Visual instruction tuning,17-Llava-onevision]分享的细节可以提供一个稳固的基线
为了进一步提升模型性能,Eagle 2采用三阶段训练策略以最佳利用训练数据。具体而言
第一阶段(阶段1),通过训练MLP连接器实现语言模态和图像模态的对齐
最终,Eagle 2 模型家族涵盖了各种规模,包括 1B、2B 和9B 参数
2.1.2 相关工作
第一,对于视觉-语言模型和大语言模型[187,188,3],其彻底改变了NLP领域,并重塑了更广泛的人工智能格局
- LLMs 的进步通过将视觉特征与 LLMs 融合,推动了视觉理解领域的重大突破,催生了视觉-语言模型(VLMs)[189,11,4,190]
- 具有公开可用权重的VLMs[4,3,191,192,193,17,194,14,25,195,15,196,197,198,199]的性能在持续取得突破,达到了甚至超越了GPT-4V/4o [184,11] 和Gemini-1.5 [185]
- 完全开源的 VLMs[17,16,200] 发布了他们的训练数据和代码库,进一步加速了 VLM 的研究
第二,对于以视觉为中心的VLMs
- VLMs的视觉基础[201,202,203]和改进设计[204,23,195,205,206,207]
- 混合视觉编码器设计[208,209,210,211,212,16,22]
- 以及平铺和高清输入设计[213,214,215,216,21,193,194,217,14,25]
据所知,这项工作是首次探索平铺混合视觉编码器(MoVE)设计,该设计被证明继承了两种方法的优势。提出的平铺MoVE设计还引入了额外的灵活性,以结合先进的视觉基础模型
第三,对于VLMs中的数据工作
数据策略在训练VLMs中至关重要,包括数据集构建、平衡和过滤以及训练方法的各个方面
- 早期探索如LLaVA-150K [4] 使用了GPT-4 [11]的指令调优,后来研究[218,219,193,204]通过通过将多任务学术训练数据融入监督微调阶段实现了改进
研究还扩展了数据类型至视频[220,15]、多图输入[17,14]、图文交错数据[221,222]、多语言数据[186]和合成数据集[15] - 然而,单纯扩展数据集可能会因质量和规模差异而对模型性能产生负面影响。诸如Instruct-BLIP [219]和Cambrian-1 [16]之类的方法通过设计最佳数据比例和平衡技术来解决这一问题,而其他方法如Llama3 [15]和Molmo [223]则通过使用SSCD [178]去重和引入人工标注的图像来提升数据质量
- 此外,训练策略也在不断发展,LLaVA [4]提出了一个成为标准的两阶段训练过程,后来的模型[17-Llava-onevision]引入了中间阶段
VLM的综述[224,225,226]也讨论了用于构建VLM的各种训练方法和数据策略,但它们缺乏定性分析,未能为训练前沿VLM提供足够细致的路径指引
2.2 完整方法论:数据策略、训练方法、视觉编码器的平铺混合
2.2.0 基线设置
如表1所示,Eagle 2的初始基线从Cambrian数据集[16]开始,使用LLaVA的[4]两阶段训练方法
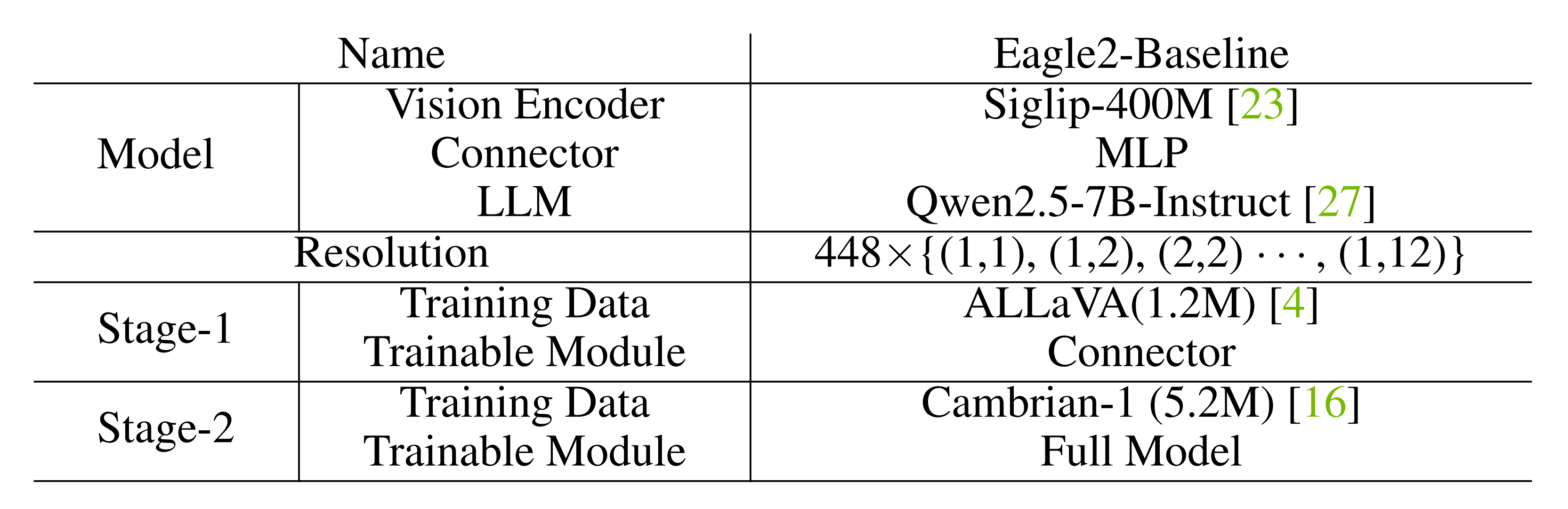
从Cambrian-7M中移除了一些低质量数据,例如ShareGPT-4V、GPT-77K和Data-Engine-161K,最终得到一个包含5.2M样本的子集。该模型引入了一个MLP连接器,用于连接视觉编码器和LLM,并采用图像分块技术以实现动态分辨率
基于此基准框架,作者从三个关键维度增强了Eagle 2:
- 数据策略
- 训练方法
- 模型架构
2.2.1 数据策略:数据收集、数据过滤、数据选择、数据增强
训练数据对于定义VLM的能力至关重要。然而,大多数商业VLM和具有公开可用权重的领先VLM都保留其数据策略而不对外公布
下图图3展示了Eagle 2的整体数据策略「上部分显示数据收集流程,下部分显示数据优化流程」,包括两个核心组成部分:数据收集和现有数据优化
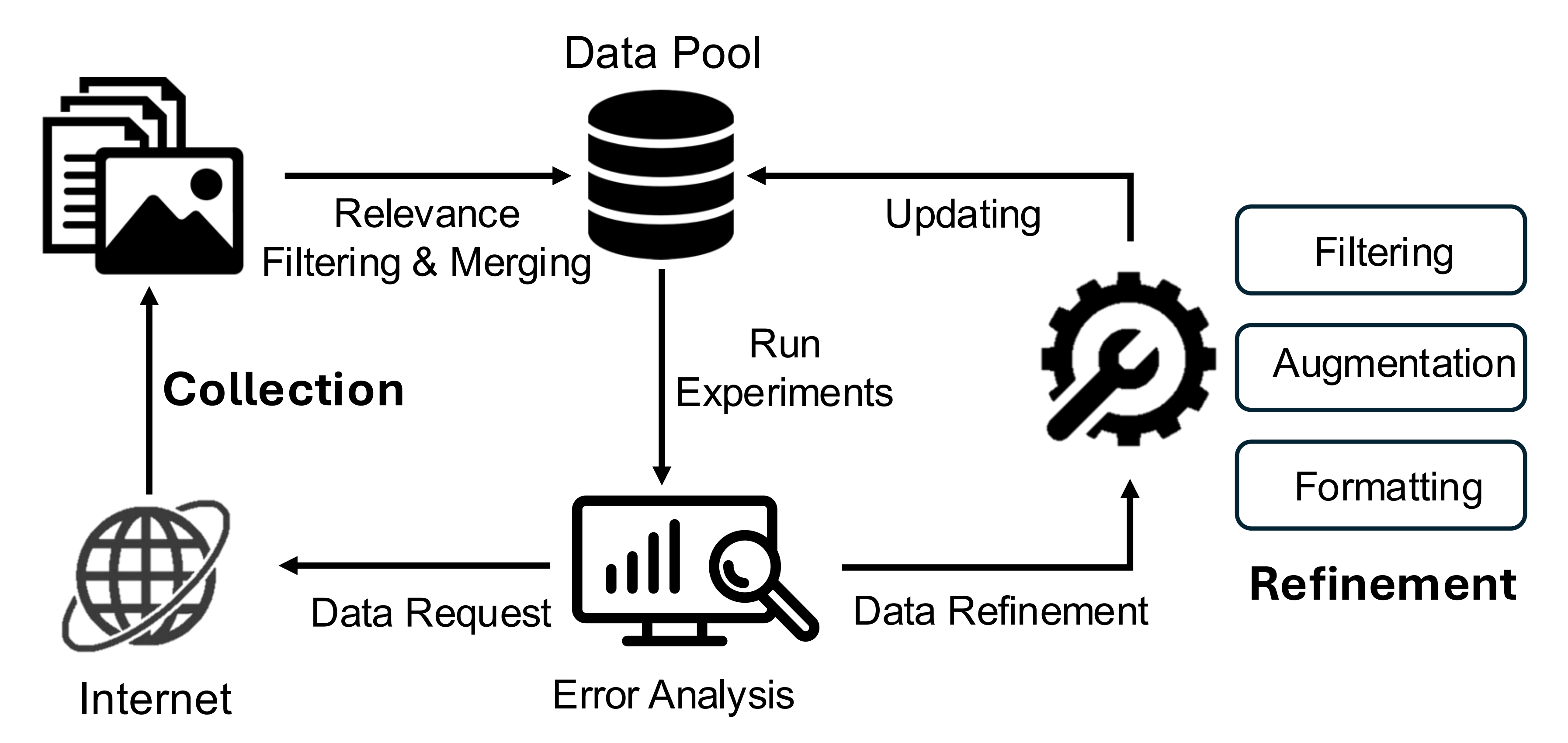
2.2.1.1 数据收集
对于数据收集,其多样性是关键。一个模型的能力与数据的多样性强烈相关。因此,尽可能收集多样化的数据是本工作的关键原则,这导致了两种主要策略:
- 被动收集:监控来自arXiv论文和HuggingFace数据集的最新相关数据集,并将它们纳入到候选清单中
- 主动搜索:针对木桶效应进行补强。如图3所示,在数据池的每次更新中,我们会生成错误分析报告以定位模型缺陷,并据此开展定向数据搜索
最终,Eagle 2的多样化数据来源在表2a中进行了总结,并且通常是公开可用的。且利用了一些预先组织的数据集集合[16,17,151]来加速准备工作,但也进行了仔细检查以防止诸如测试数据泄露等问题
此外,他们还收集了大量的公共非问答数据,例如Google Landmark[31],并通过特定规则或自动标注工具将其转换为VQA数据
另,为了降低训练成本,避免对每个数据集单独进行消融实验。相反,当满足以下条件时,将具有相似领域的数据集批量添加到数据池中:
- 在每个考虑的基准测试中保持整体准确率且没有明显的退化
- 为当前领域引入有价值的多样性
为了量化多样性,作者定义了一个称为相似度评分的指标,用于衡量新数据源与当前数据池之间的相关性,其定义如下
- 其中
是新数据源的索引,包含
个样本,而
是现有数据池的索引,包含
个样本,
表示数据类别
- 仅在相同类别内计算相似性分数,因为跨类别的相似性通常较低
图像嵌入和
由SSCD [178]生成,而文本嵌入
和
由all-mpnet-base-v2 [179]生成
样本之间的相似度得分是图像相似度与文本相似度的乘积。该指标显示大多数来源的相似性较低,而少数高相似性样本作为重复项被移除
且按照Eagle 2的数据收集协议和以下所述的优化步骤,Eagle 2的最终模型
- 在阶段1.5中使用了2160万样本,在阶段2中使用了460万样本,其分布如图4所示
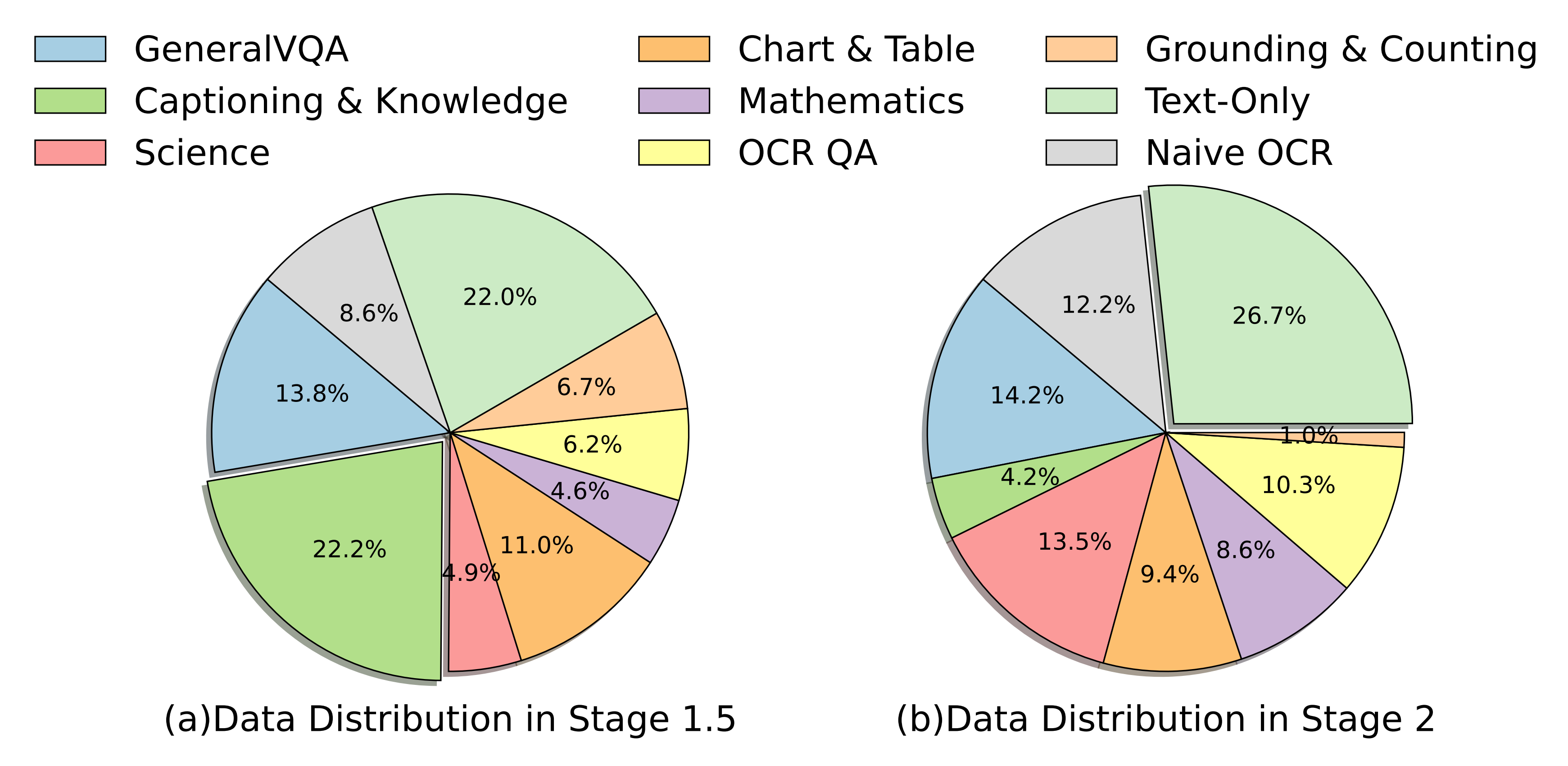
- 且作者确保纯文本数据占比超过20%
在阶段1.5中,字幕数据占据了最大的比例;然而,在阶段2中,出于对过于单一指令的担忧而减少了字幕描述数据的比例
2.2.1.2 数据过滤
正如一粒老鼠屎坏掉一锅粥,公共数据集通常包含许多低质量样本
作者发现,大多数低质量案例属于以下类别,故将其用作Eagle 2的过滤标准
- 问题-答案对不匹配。例如,来自 ShareGPT4o [28]的图 5(a)

- 不相关的图像-问题对,图像和问题无关。例如,图5(b)来自 Cambrian-1 [16]

- 重复的文本。例如,图5(c)来自 ShareGPT

- 数字格式问题
小数位数过多或数值答案过于精确,但图像中缺乏对应信息。例如,图6
总之,由于大多数低质量数据通过合成生成,它们通常呈现出可区分的特征,从而能够通过基于规则的过滤方法进行有效剔除
2.2.1.3 子集选择
子集选择——“每个数据都有其代价”。选择最佳子集是高质量训练的关键。最近的研究[16-Cambrian-1]建议限制每个来源的样本数量通常不超过(例如350K)
Eagle 2的数据选择基于两个主要原则:
- 子集数量确定。数据源的多样性和分布决定了样本集的规模
自动标注的数据源通常规模较大,但常存在错误且多样性不足,相比之下,人工标注的数据集往往规模较小
因此,原始规模较大的数据集通常使用较小的采样比例
在Eagle 2的阶段2数据中,每个来源的平均规模约为20K,其中最大的子集Visual-WebInstruct [56]具有263K个样本 - K-means 聚类选择。一旦确定了子集大小,下一步就是选择样本
当前方法通常使用随机选择,这并不是最优的。例如,在图表数据中,直方图样本比折线图或饼图等其他类型更为常见,而随机抽样无法确保这些类型的均衡覆盖
为了解决这个问题,作者对 SSCD [178] 图像嵌入特征实施了无监督K-means 聚类,将具有相似图表类型的样本聚集在相邻空间,从而支持目标数据定向筛选,例如按需包含所有折线图和饼图样本
虽然使用 SSCD 图像嵌入方法K-means 聚类,在自然场景图像上表现较差,但在数学、医学和基于文档的数据上表现出色
2.2.1.4 数据增强与数据格式化
首先,数据增强旨在从输入图像中挖掘出那些在现有QA注释中未充分呈现的丰富信息
为了从图像空间中挖掘潜在有用的信息,一种常见的方法是使用第三方视觉语言模型(VLMs)生成图像的细粒度描述如图7所示(为方便大家更好的理解,我特地把原图和对原图的翻译 放在了一块)
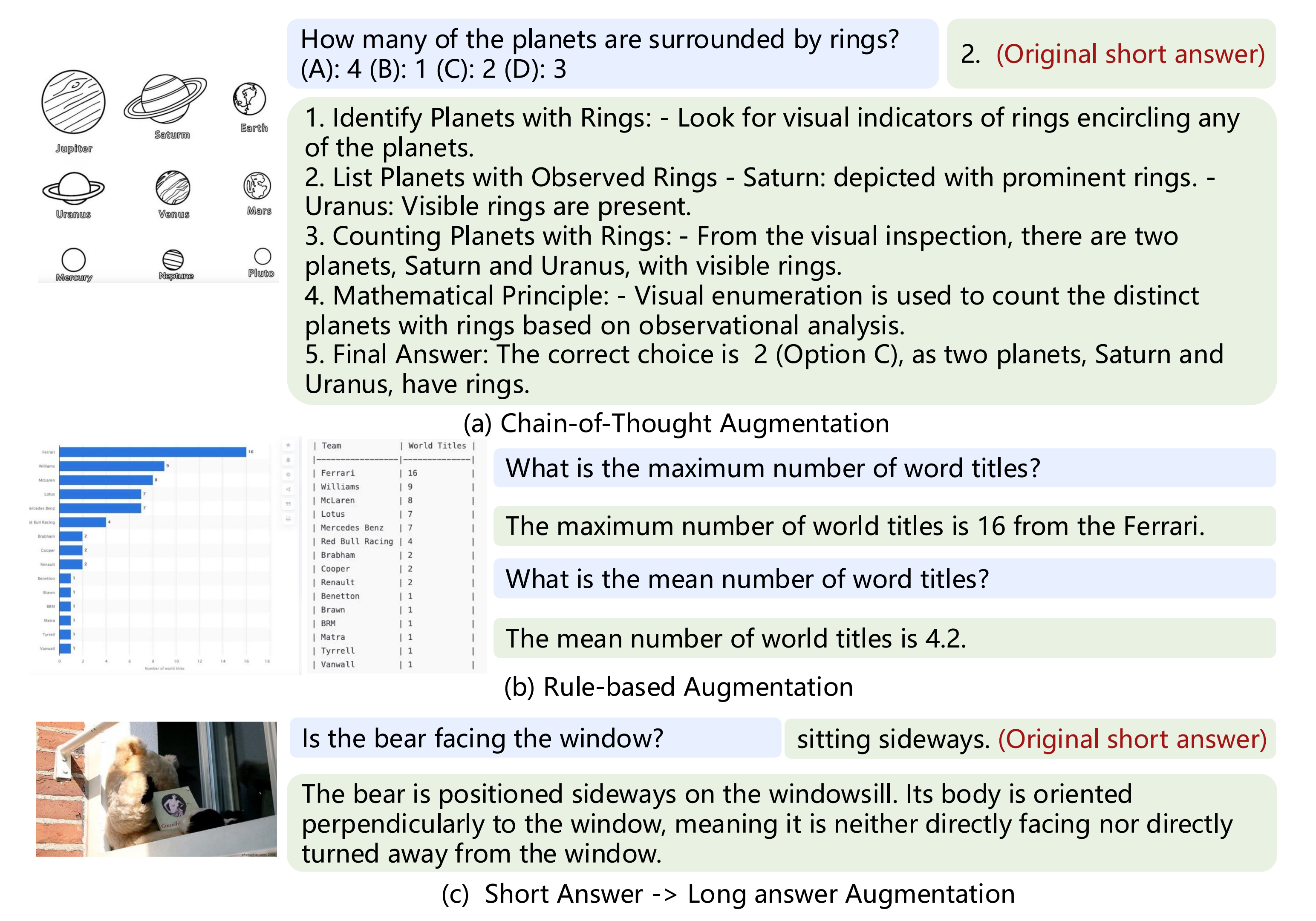
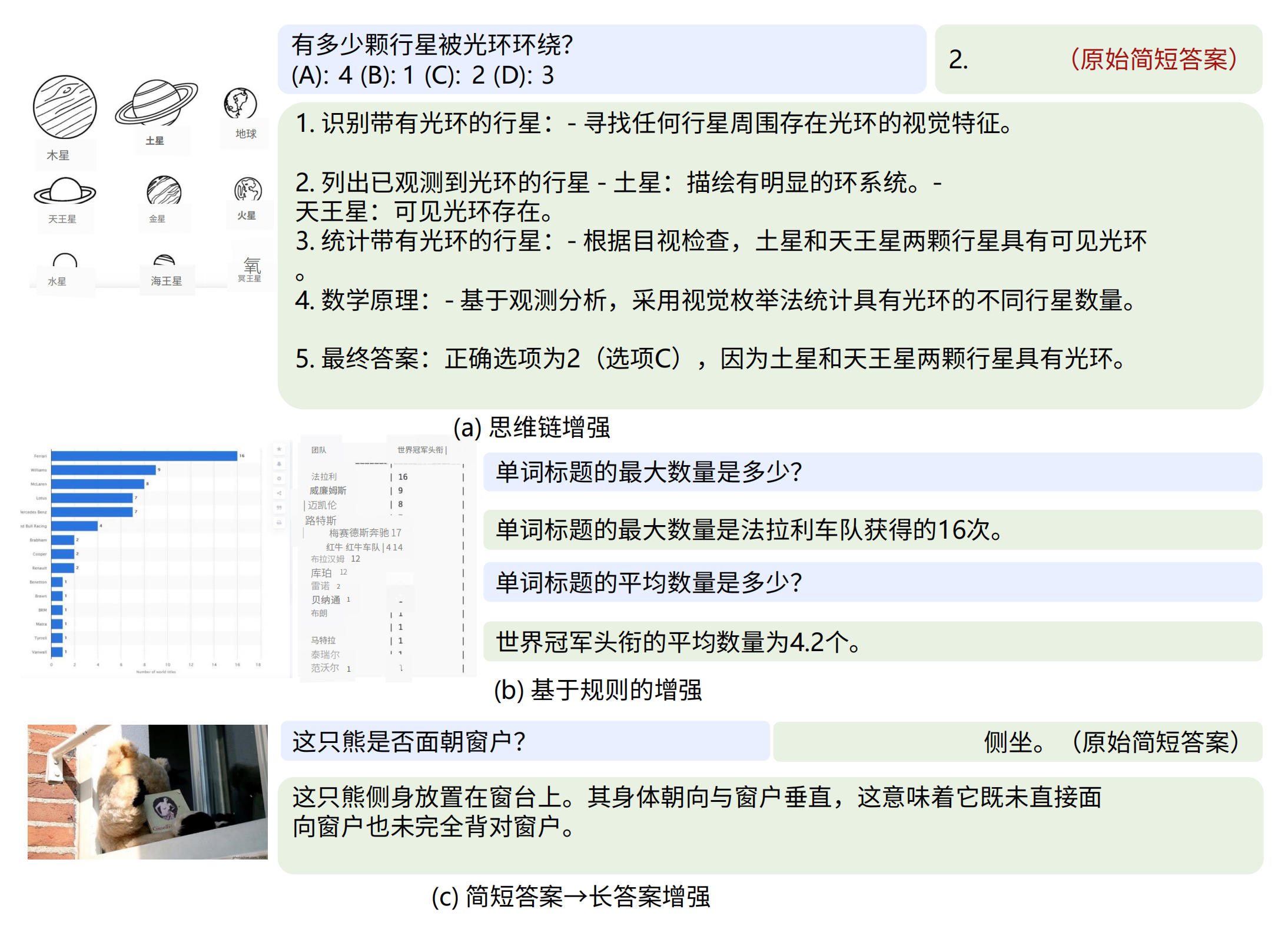
- 添加思维链(Chain-of-Thought)解释说明
- 基于规则的QA生成
- 将简短的回答扩展为详细回答
有关上述生成过程的详细信息,请参阅补充材料
其次,数据格式化将数据转换为正确的格式也是数据准备中的一个关键步骤
基本原之一是:相同任务,相似格式;不同任务,明确区分格式
故Eagle 2的数据格式化包括但不限于:
- 去除不必要的装饰
比如在表3中展示了一个看似不起眼的示例『两个具有相同「从图像提取LaTeX」任务,但格式
不同的样本集』,然而该示例对最终结果产生了深远影响
作者展示了来自不同来源的两个样本,用于从图像中提取 LaTeX 公式
其中的第二个样本包含了一个不必要的固定方程环境——即使仅有限度地使用此类数据,模型仍会持续输出固定的模板(以红色文本显示)——意思就是说 上面那段红色文本所示的固定方程格式 没有意义,直接删掉更好
在移除固定的方程环境后,模型恢复了正常行为,在 OCRBench [180] 上取得了显著的改进 - 添加更具体的指令
根据回复在原始指令中添加详细说明是一种常见的做法
例如,在简短的回答后添加“提供简短答案”有助于防止模型变成只会给出简短回答的“回答机器”。然而,过度使用这种方法也可能妨碍模型的泛化能力。比如,对每个是或否的问题都添加“请回答是或否”,可能会削弱模型在推理过程中没有此类提示时正确回答的能力
2.2.2 训练方法
上面的一系列数据策略使Eagle 2能够构建一个高质量且多样化的数据集,但对同一数据池应用不同的训练方法仍然对最终结果有决定性影响
回顾一下上文2.1.1节中对Eagle 2三阶段训练的阐述
- 第一阶段(阶段1)用于通过训练MLP连接器对齐语言和图像模态
- 接下来的阶段(阶段1.5)使用大规模多样化数据训练完整模型,且在阶段1.5中,整合了所有可用的视觉指令数据,而不仅限于字幕或知识数据
- 最后阶段(阶段2)继续使用精心设计的高质量视觉指令调优数据集训练完整模型
故作者基于以下核心要点
首先,后预训练阶段是必要的
- 作者最初采用了LLaVA[4] 的两阶段训练策略,其中首先训练一个MLP连接器,然后使用SFT数据进行完整模型训练
虽然这种方法高效,但事实证明它不适合快速更新 SFT 数据,因为不断扩大的 SFT 数据使得追踪新数据的影响变得更加困难,实验效率也随之降低。例如,观察到通过扩展Cambrian-1 [16] SFT数据可以带来改进
然而,模型与最先进的模型之间仍存在差距
考虑到两阶段策略的主要限制是缺乏健壮的预训练,增加了一个额外的预训练阶段(阶段1.5)。阶段1.5在更大的数据集上对模型进行预训练,以减少后续训练中对SFT数据的依赖
其次,大轮驱动小轮
- 事实上,三阶段预训练在现有研究中被广泛采用,例如 LLaVA-OneVision [17]。然而,对于在Stage-1.5阶段使用的数据,作者的观点截然不同
具体而言

如Fig.8所示,在Stage-1.5的基础上随后再进行Stage-2的训练,从而使得能够在高性能的基础上实现更快的迭代
「As shown in Fig. 8, training Stage-2 based onStage-1.5 enables rapid iteration on a high-performancefoundation」
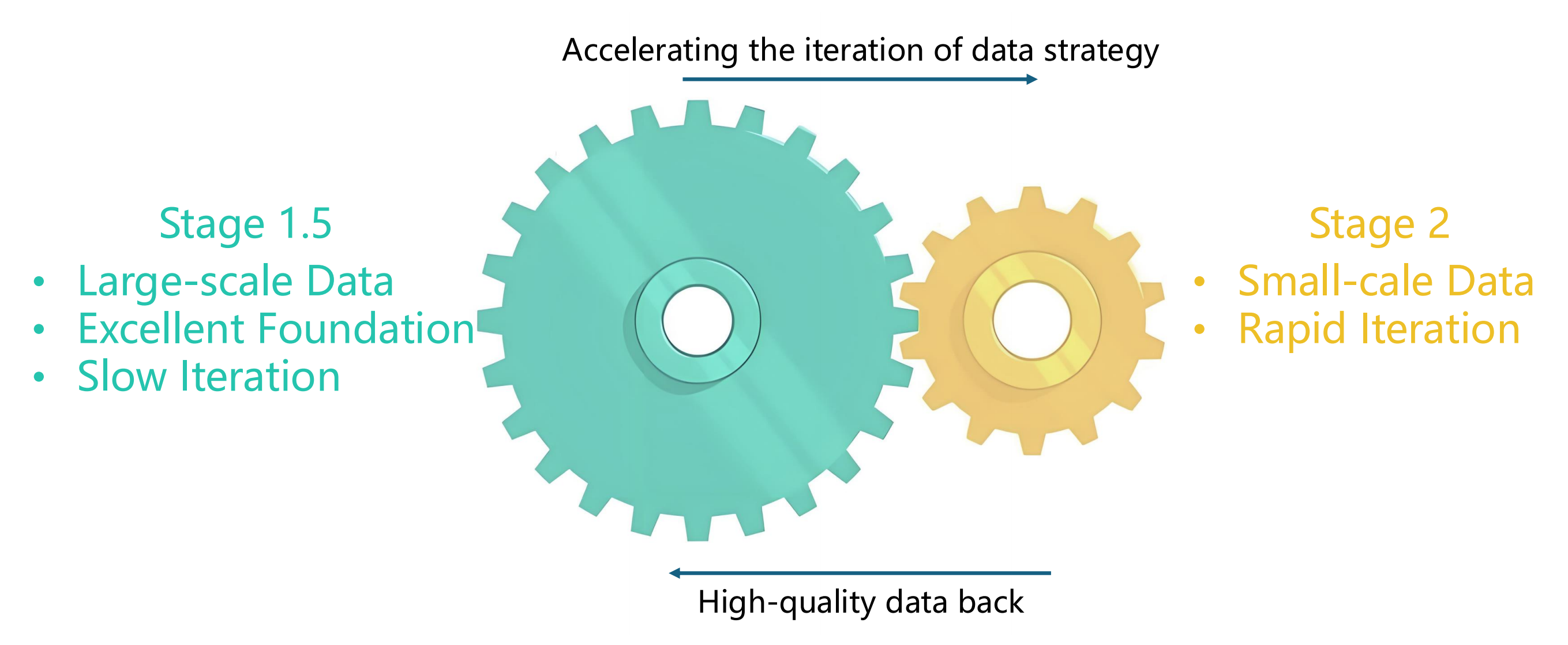
由此得出的结论,比那些在小规模数据上进行的无法推广的消融实验所得出的结论更可靠 - 此外,从Stage-2中得出的有效结论可以用来更新Stage-1.5,从而进一步推动模型性能的提升。详细设置如表4所示
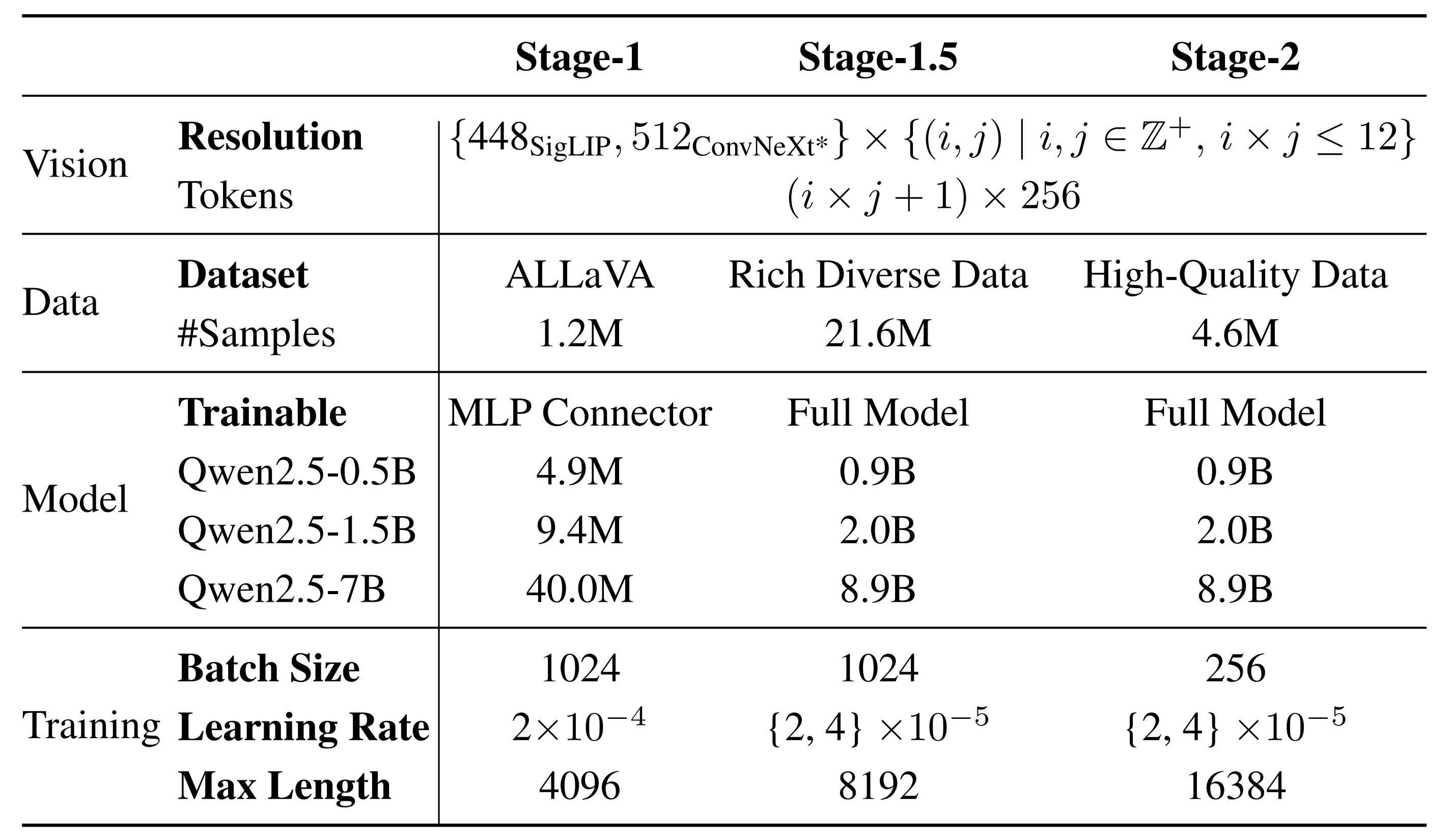
再者,平衡感知的数据打包非常重要
- 数据打包通过将较短的样本连接在一起,从而减少填充的使用,可以加速训练。在作者的实验中,使用数据打包使训练速度提高了2-3倍
打包的一个关键步骤是将长度不同的 - 如图9所示「将64个长度不同的样本打包成组合样本,每个样本的长度小于8192。在LLaMa-Factory [181] 中使用的简单贪婪背包方法(下图图a所示)会导致长度分布不均,而Eagle 2提出的方法在每个背包中实现了更均匀的长度分布(下图图b所示)」
传统的贪婪背包方法将长样本和短样本分别分组,这对于模型训练来说并不理想

因此,作者设计了一种平衡感知贪心背包算法,该算法生成长度分布更均匀的包,如图10所示——它将一组样本(每个样本有规定的长度)尽可能平衡地分配到多个“背包”中,每个背包的最大容量为,确保每个包中既包含长样本也包含短样本
为方便大家更好的理解,我特地在原论文代码的基础上,给代码的每一行 都加上了中文注释
与SPFHP(Shortest-Pack-First Histogram Packing)[182]不同,Eagle 2的方法优先考虑长度分布的平衡性,而不是打包效率,从而帮助平衡长样本和短样本之间的损失权重# Eagle 2提出的贪心背包方法 def balanced_greedy_knapsack(samples, L): # 第1步:对样本进行排序 samples.sort(reverse=True) # 按降序排列样本 total_length = sum(samples) # 计算所有样本的总长度 min_knapsacks = (total_length + L - 1) // L # 计算理论上所需的最少背包数 # 第2步:初始化背包 knapsacks = [[] for _ in range(min_knapsacks)] # 创建指定数量的空背包 knapsack_lengths = [0] * min_knapsacks # 初始化每个背包的当前长度为0 # 第3步:将样本分配到背包中 ks_index = 0 # 当前选择的背包索引 sample_index = 0 # 当前处理的样本索引 # 遍历所有样本 while sample_index < len(samples): length = samples[sample_index] # 获取当前样本的长度 # 尝试将样本放入当前选择的背包 # 如果当前样本的长度加上背包当前长度,不超过最大容量 L,则放入该背包并更新当前长度 if knapsack_lengths[ks_index] + length <= L: knapsacks[ks_index].append(length) # 将样本放入背包 knapsack_lengths[ks_index] += length # 更新背包的当前长度 sample_index += 1 # 移动到下一个样本 else: # 如果无法放入,创建一个新背包 knapsacks.append([]) # 添加一个新背包 knapsack_lengths.append(0) # 初始化新背包的长度为0 # 找到当前最空的背包——且是装填长度最小的背包 ks_index = knapsack_lengths.index(min(knapsack_lengths)) # 返回所有装满的背包 return knapsacks
更多细节见附录
2.2.3 视觉编码器的分块混合
参考 Eagle [22],作者使用 SigLIP [23] 和ConvNeXt-XXLarge [24,183] 作为视觉编码器
- 此外,为了处理任意高分辨率的图像,采用了InternVL-1.5 [21] 提出的图像分块(image tiling)技术
SigLIP 的每个图像分块的输入分辨率为 448×448,而ConvNeXt 的输入尺寸为 512×512 - 另,为了确保它们输出相同数量的图像token,使用 PixelShuffle对 SigLIP 的图像特征进行 2×降采样,最终得到16×16的特征图,与 ConvNeXt 的输出尺寸(输入图像的32×降采样)相匹配
然后,沿通道维度连接这些特征,并通过一个 MLP 层与 LLM 对齐
经作者实验论证,引入视觉编码器的混合在14个基准测试中的12个上带来了性能提升,特别是在与文档、图表和OCR相关的基准测试中。这清楚地表明,视觉编码器的混合显著增强了模型对视觉空间的理解能力
// 待更


















 1794
1794

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











