







昇腾NPU功率监测
参考:https://www.hiascend.com/document/detail/zh/Atlas%20200I%20A2/24.1.RC2/re/npu/npusmi_023.html
npu-smi info -t power -i id
Nvidia GPU功率监测
nvidia-smi --query-gpu=power.draw --format=csv,noheader,nounits -i id
昇腾功率监测脚本
import subprocess
import time
import pandas as pd
import threading
# 初始化一个列表来存储功率记录及其时间戳
power_records = []
def get_power(npu_id):
"获取指定NPU的功率"
try:
# 执行npu-smi info命令并捕获输出
output = subprocess.check_output(['npu-smi', 'info', '-t', 'power', '-i', str(npu_id)]).decode('utf-8')
# 解析输出中的功率信息
for line in output.split('\n'):
if 'NPU Real-time Power(W)' in line:
power = line.split(':')[1].strip()
return float(power)
except subprocess.CalledProcessError as e:
print(f"Failed to get power info: {e}")
return None
def record_power(npu_id, interval):
"记录指定时长内的功率信息"
while True:
power = get_power(npu_id)
if power is not None:
timestamp = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
power_records.append({'Timestamp': timestamp, 'Power': power})
print(f"Recorded Power: {power} W at {timestamp}")
time.sleep(interval)
def save_to_excel(file_name):
"将功率记录保存到Excel文件"
df = pd.DataFrame(power_records)
df.to_excel(file_name, index=False)
print(f"Power records saved to {file_name}")
def calculate_average_power():
"计算平均功率"
if power_records:
average_power = sum(record['Power'] for record in power_records) / len(power_records)
print(f"Average Power: {average_power} W")
else:
print("No power records to calculate average.")
# 设置NPU ID和记录功率的时间间隔(秒)
npu_id = 1
interval = 600 # 10分钟
# 启动记录功率的线程
power_thread = threading.Thread(target=record_power, args=(npu_id, interval))
power_thread.daemon = True # 设置为守护线程,以便主程序结束时线程也结束
power_thread.start()
# 这里放置您的训练代码
# train_your_model()
# 当训练完成后,保存功率记录并计算平均功率
save_to_excel("power_records.xlsx")
calculate_average_power()
昇腾提交训练任务监测功率
这里有一个问题,就是需要获取实机那边的npu id,昇腾提供了一个现成的命令可以查看当前设备的NPU个数和ID:npu-smi info -l
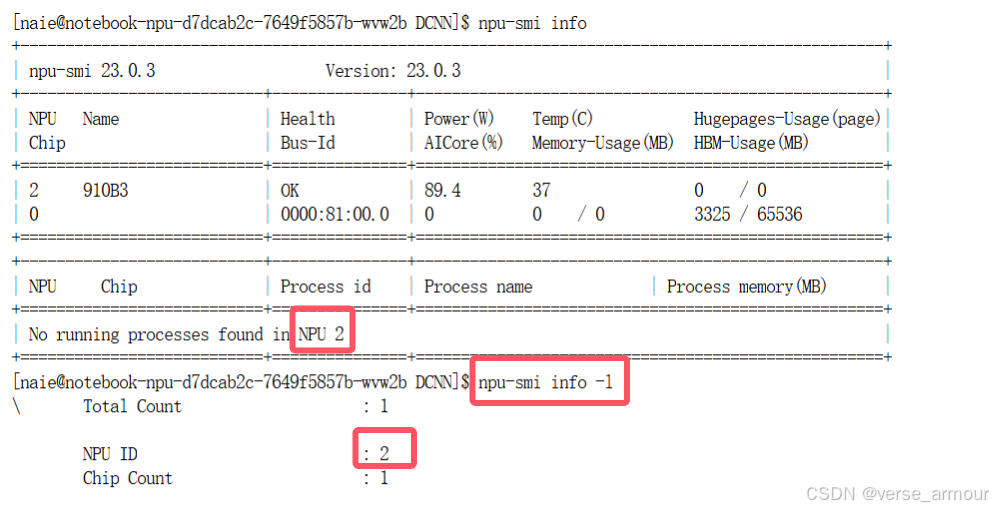
在上面的代码中,npu id是直接指定的,在提交训练任务场景中,需要获取当前设备的npu id。因此需要手动获取:
import subprocess
def get_npu_id():
try:
# 执行npu-smi命令并获取输出
result = subprocess.run(['npu-smi', 'info', '-l'], stdout=subprocess.PIPE, text=True)
# 解析输出结果
output = result.stdout
# 检查输出中是否包含NPU ID信息
if 'NPU ID' in output:
# 提取NPU ID
npu_id_line = [line for line in output.split('\n') if 'NPU ID' in line][0]
npu_id = npu_id_line.split(': ')[1].strip()
return npu_id
else:
return "NPU ID not found"
except Exception as e:
return f"An error occurred: {e}"
# 调用函数并打印NPU编号
npu_id = get_npu_id()
print(f"The NPU ID is: {npu_id}")
Nvidia功率监测脚本
import subprocess
import time
import pandas as pd
import threading
# 初始化一个列表来存储功率记录及其时间戳
power_records = []
def get_power(gpu_id):
"获取指定GPU的功率"
try:
# 执行nvidia-smi命令并捕获输出
output = subprocess.check_output(['nvidia-smi', '--query-gpu=power.draw', '--format=csv,noheader,nounits', '-i', str(gpu_id)]).decode('utf-8')
# 输出是单行的功率值,直接转换为float
power = float(output.strip())
return power
except subprocess.CalledProcessError as e:
print(f"Failed to get power info: {e}")
return None
def record_power(gpu_id, interval):
"记录指定时长内的功率信息"
while True:
power = get_power(gpu_id)
if power is not None:
timestamp = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
power_records.append({'Timestamp': timestamp, 'Power': power})
print(f"Recorded Power: {power} W at {timestamp}")
time.sleep(interval)
def save_to_excel(file_name):
"将功率记录保存到Excel文件"
df = pd.DataFrame(power_records)
df.to_excel(file_name, index=False)
print(f"Power records saved to {file_name}")
def calculate_average_power():
"计算平均功率"
if power_records:
average_power = sum(record['Power'] for record in power_records) / len(power_records)
print(f"Average Power: {average_power} W")
else:
print("No power records to calculate average.")
# 设置GPU ID和记录功率的时间间隔(秒)
gpu_id = 0 # NVIDIA GPU的ID
interval = 600 # 每10分钟记录一次
# 启动记录功率的线程
power_thread = threading.Thread(target=record_power, args=(gpu_id, interval))
power_thread.daemon = True # 设置为守护线程,以便主程序结束时线程也结束
power_thread.start()
# 这里放置您的训练代码
# train_your_model()
# 保存功率记录并计算平均功率
save_to_excel("power_records.xlsx")
calculate_average_power()


















 5002
5002

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











