







本人项目地址大全:Victor94-king/NLP__ManVictor: CSDN of ManVictor
写在前面: 笔者更新不易,希望走过路过点个关注和赞,笔芯!!!
写在前面: 笔者更新不易,希望走过路过点个关注和赞,笔芯!!!
写在前面: 笔者更新不易,希望走过路过点个关注和赞,笔芯!!!
GGUF简介
GGUF(GPTQ for GPUs Unified Format)是一种针对大语言模型(LLM)权重文件的统一格式,旨在简化和标准化不同模型格式之间的转换和加载。随着大语言模型的快速发展,不同的框架(如Hugging Face Transformers、TensorFlow、PyTorch等)和优化工具(如GPTQ、LoRA、INT8/INT4量化)可能生成不同格式的模型文件。GGUF格式的引入有助于统一这些格式,使得模型的加载和使用更加方便。

GGUF格式在大模型文件性能优化方面表现出色,主要得益于以下核心技术设计与实现:
一、高效的二进制编码与内存映射
- 紧凑二进制结构GGUF采用优化的二进制编码方案,相比传统文本格式(如JSON)减少约30%-50%的存储空间,同时通过内存映射(mmap)实现“零拷贝”加载,模型参数无需复制到内存即可直接访问。示例:70B参数的Llama模型加载时间从分钟级缩短至秒级。
- 按需读取机制通过记录张量偏移量(offset),仅在实际推理时加载所需参数块,降低内存峰值占用,支持在8GB内存设备上运行13B参数模型。
二、灵活的量化支持
- 多级量化策略支持2位(Q2_K)到8位(Q8_0)的混合精度量化,例如Q4_K_M在精度损失小于1%的情况下,将模型体积压缩至原大小的1/4,显存占用降低60%。典型应用:Q5_K_M量化版Llama-3-8B可在RTX 3060显卡流畅推理。
- 量化算法优化集成Imatrix(关键参数识别)和K-Quantization(区间分配)技术,在压缩率与精度间取得平衡,相比GPTQ量化方法减少约15%的推理误差。
三、跨平台兼容性设计
- 硬件架构适配原生支持x86、ARM等CPU架构,并兼容CUDA、Metal等GPU加速框架,实现同一模型文件在Windows/Linux/macOS及移动端无缝运行。
- 自包含元数据文件内嵌模型架构配置、词表信息及量化参数,无需依赖外部配置文件,避免版本冲突导致的加载失败。
四、生态工具链支撑
- 转换与推理工具llama.cpp提供从PyTorch/Safetensors到GGUF的自动化转换流水线,支持超200种主流模型的格式兼容,转换效率达每分钟处理10GB原始权重。
- 部署轻量化推理工具(如ollama)采用C++核心+Go应用层设计,全静态编译包体积小于20MB,启动时间低于1秒。
五、性能对比实测
| 指标 | **GGUF(Q4_K_M)** | Safetensors | 原始PyTorch |
|---|---|---|---|
| 加载时间(70B) | 8秒 | 45秒 | 120秒 |
| 内存占用 | 12GB | 32GB | 48GB |
| 推理速度(token/s) | 28 | 18 | 9 |
通过上述技术组合,GGUF在存储效率、加载速度、硬件兼容性等维度均显著优于传统格式,成为大模型边缘计算场景的首选方案
GGUF文件的具体组成信息可分为以下核心模块
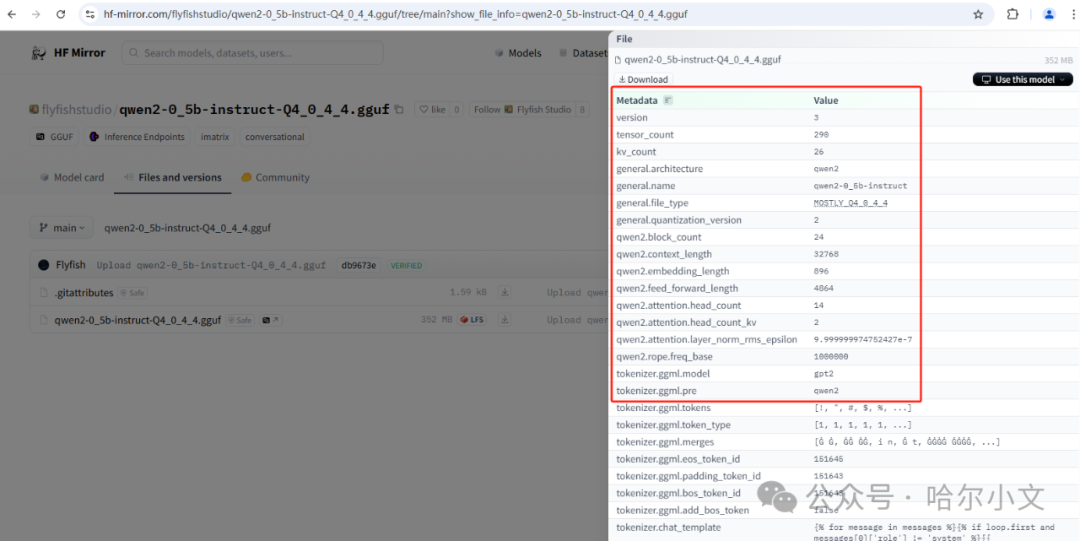
一、**文件头(Header)**
- Magic Number用于标识文件格式的唯一标识符(如固定字符序列),确保文件类型匹配。| 文件类型 | Magic Number(十六进制) | 人类可读形式 |
| ----------------------- | ------------------------------------ | ------------ |
| GGUF |<span leaf="">47 47 55 46</span>| “GGUF” |
| PNG图片 |<span leaf="">89 50 4E 47</span>| “‰PNG” |
| ZIP压缩包 |<span leaf="">50 4B 03 04</span>| “PK…” | - **版本号(Version)**标明文件遵循的GGUF规范版本,确保向后兼容性(如v3、v4等)。
- 元数据与张量数量记录元数据键值对的总数及张量数据的数量,用于快速定位文件内容。
二、**元数据键值对(Metadata Key-Value Pairs)**
- 模型基础信息包括模型名称、作者、训练时间、描述等文本信息。
- 架构参数存储模型结构细节,如层数、注意力头数、隐层维度等关键配置参数。
- 量化参数记录量化类型(如Q4_K_M、Q8_0)、内存对齐方式等优化配置,支持不同硬件环境下的高效推理。
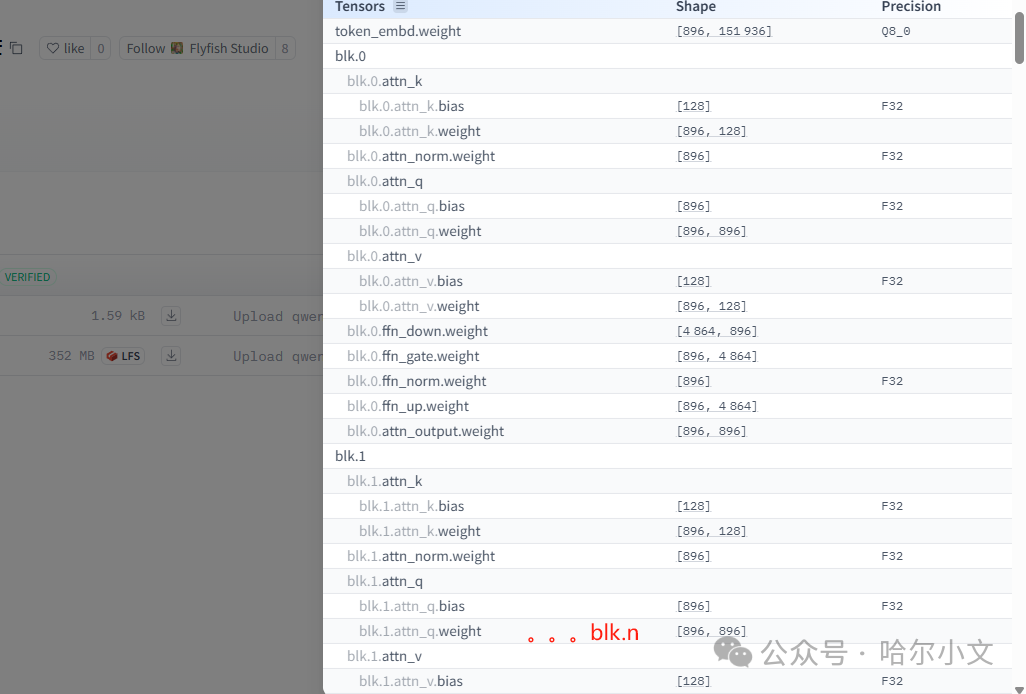
三、**张量信息(Tensor Data)**
- 张量描述信息每个张量包含名称、数据类型(如FP32、INT4)、维度、偏移量等描述字段,用于快速定位和加载。
- 张量数据存储采用紧凑二进制编码存储实际参数,结合内存映射(mmap)技术实现按需加载,避免一次性加载大文件导致的资源浪费。
四、内存映射优化
GGUF通过内存映射技术将文件直接映射到内存地址空间,实现“零拷贝”访问,显著降低加载时间和内存峰值占用。
五、文件结构示例
plaintextCopy Code[Header]
Magic: GGUF
Version: 3
Metadata Count: 50
Tensor Count: 120
[Metadata]
key: general.name → value: "Llama-2-7B"
key: arch.context_length → value: 4096
key: quantization.type → value: Q4_K_M
[Tensors]
tensor: name="embed.weight", dtype=F32, dims=[50257, 4096], offset=0x1A00
tensor•:ml-citation{ref="1" data="citationList"}: name="layers.0.attn.q_proj.weight", dtype=Q4_K_M, dims=[4096, 4096], offset=0x2C00
...
通过模块化设计和标准化元数据,GGUF实现了模型存储与推理的高效平衡,成为大模型部署的主流格式。
Safetensors与GGUF两种大模型文件格式的设计目标和使用场景存在显著差异,GGUF的出现主要解决了以下关键问题:
一、设计目标差异
- Safetensors的核心定位主要用于安全、高效地存储和加载模型权重,通过内存映射和零拷贝技术优化大模型加载速度,但缺乏对模型量化及跨架构推理的深度支持。
- GGUF的针对性优化专为量化模型和跨平台推理设计,支持多种量化等级(如4位、8位),并内嵌完整的模型架构信息,满足资源受限设备的部署需求。
二、关键能力对比
| 特性 | Safetensors | GGUF |
|---|---|---|
| 量化支持 | 无原生量化能力 | 支持多级量化(Q4_K_M等) |
| 依赖管理 | 依赖Python/PyTorch生态 | 完全自包含,无需外部依赖 |
| 硬件兼容性 | 侧重GPU/云端环境 | 优化CPU/边缘设备推理 |
| 文件完整性 | 仅存储权重参数 | 包含权重、配置、词表等全信息 |
| 加载效率 | 内存映射加速加载 | 内存映射+按需读取优化 |
三、GGUF的不可替代性
- 量化推理场景GGUF通过量化技术将模型体积压缩至原大小的1/3~1/5,支持消费级硬件运行大模型,例如Q4量化后的70B参数模型可在24GB显存的GPU上运行。
- 跨平台部署优势无需Python环境或特定框架支持,可在嵌入式设备(如树莓派)、移动端或纯CPU服务器上直接运行,降低部署复杂度。
- 生态适配扩展主流推理工具链(如llama.cpp、ollama)优先支持GGUF格式,且谷歌Gemma、阿里Qwen等模型官方提供GGUF版本,推动其成为边缘计算场景的事实标准。
四、典型应用场景选择
- 使用Safetensors的场景:需在PyTorch/Hugging Face生态中快速加载未量化模型,或要求避免代码注入风险的云端部署。
- 使用GGUF的场景:需在本地设备运行量化模型、追求低资源消耗(如移动端App),或需跨架构统一部署(如同时支持x86和ARM服务器)
总结
Safetensors与GGUF并非替代关系,而是互补共存:前者专注权重存储的安全性与通用性,后者解决量化模型的高效部署问题。随着边缘计算需求增长,GGUF在资源敏感场景中的优势将进一步凸显。


















 687
687

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











