







本人项目地址大全:Victor94-king/NLP__ManVictor: CSDN of ManVictor
写在前面: 笔者更新不易,希望走过路过点个关注和赞,笔芯!!!
写在前面: 笔者更新不易,希望走过路过点个关注和赞,笔芯!!!
写在前面: 笔者更新不易,希望走过路过点个关注和赞,笔芯!!!
1 概述
在解析(1)使用MinerU将PDF转换为Markdown中我们提到了将各种文档解析为Markdown的好处,本文我们接着上一篇文章处理后的Markdown,讲解如何对Markdown文档进行切分。
在很多文档中,标题都是非常重要的信息,例如企业内部的办理流程,稍微规范点的文档,标题里面都会体现重点信息的。
既然转成了Markdown,标题肯定是保留下来了,本文将首先介绍基于Markdown标题的切分方法,以及另外一种常规的Markdown切分方法。Langchain中对于Markdown文档专用的切分器,其实也只有两类:
- 普通的Markdown切分方法(Langchain中的MarkdownTextSplitter),效果和使用PyPDFLoader加载解析PDF的效果是一致的
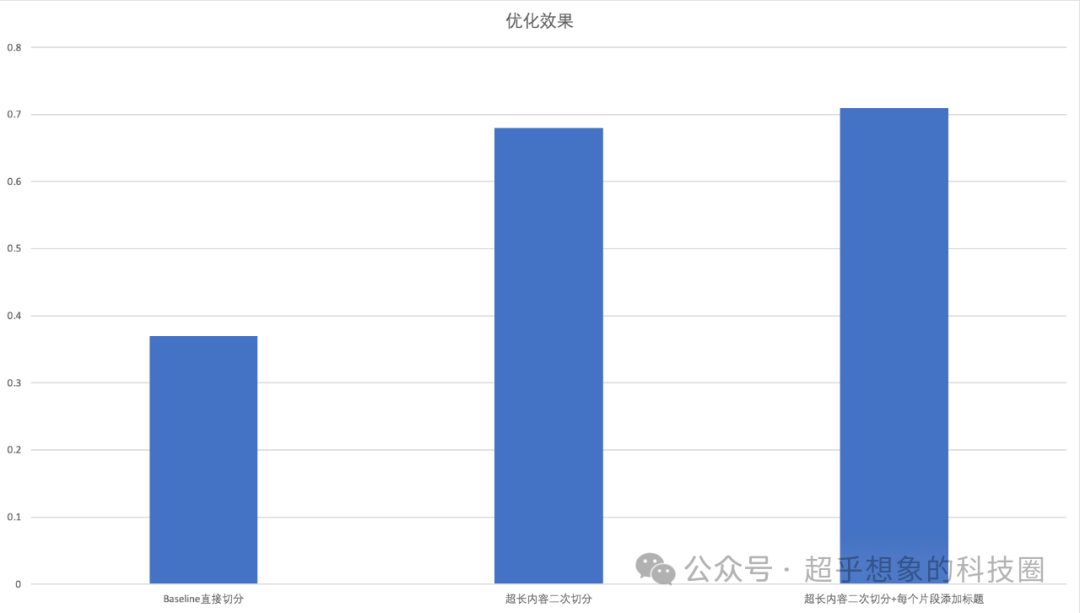
- 基于标题的切分方法(Langchain中的MarkdownHeaderTextSplitter类),与直觉理解还不太一样,直接-使用langchain的Markdown标题切分类,效果并不好,我们将通过对结果的简单分析,尝试发现问题,并进行优化,下图是经过2次优化后的结果,效果答复提升,最终效果基本上是与基础流程打平了
本文将介绍这两种切分方法,并介绍如何通过对基于标题的切分结果进行简单的数据分析,尝试发现问题并进行解决。
2 效果对比
下图是效果对比,从结果上来看,并没有体现出将PDF使用MinerU转换成Markdown的优势,可能的原因有以下两点:
- 我们示例所使用的文档,转成Markdown后只有一级标题,标题的层级不够丰富,意味着转Markdown后,标题所能发挥的作用有限
- 由于最初在使用RAG技术构建企业级文档问答系统之QA抽取构造的测试集是使用PyPDFLoader加载解析PDF并直接切分构造的,从这个角度讲,基础流程是与测试集更加契合的
- 0.71相比0.72只低了1个点,并没有显著得低,这个结果未必置信

3 核心代码
3.1 基于标题切分
3.1.1 直接使用MarkdownHeaderTextSplitter
这部分完整代码在:
https://github.com/Steven-Luo/MasteringRAG/blob/main/split/01_2_markdown_header_text_splitter.ipynb
在Langchain中基于Markdown标题的切分核心样例代码如下:
from langchain.text_splitter import MarkdownHeaderTextSplitter
import os
# 加载文档
markdown_documents = open(os.path.join(os.path.pardir, 'outputs', 'MinerU_parsed_20241204', '2024全球经济金融展望报告.md')).read()
def split_md_docs(markdown_document):
# 指定要切分的标题层级,后面的Header 1/2/3会添加到切分后的metadata中
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on)
md_header_splits = markdown_splitter.split_text(markdown_document)
return md_header_splits
md_splitted_docs = split_md_docs(markdown_documents)
由于原文几乎没有二级标题,这意味着每个片段可能会偏大,检查切分后片段的大小:
import pandas as pd
pd.Series([len(d.page_content) for d in md_splitted_docs]).describe()
count 43.000000
mean 749.395349
std 673.945036
min 33.000000
25% 241.000000
50% 462.000000
75% 1075.500000
max 2839.000000
可以看出,50%以上的文档片段长度都在462以上,粗略估计可能有40%的文档片段超过了向量模型的最大长度,这种片段的超长内容必然无法被向量模型捕获到,从而导致后续无法检索。
后续的检索、生成流程与之前的完全一致,篇幅原因大家可以到代码仓库查看完整代码。
使用这种方式切分的片段,所生成的答案最终打分只有0.37,大幅低于Baseline,结合前面对切片长度的分析,我们推测是否答错了的问题是否是片段超长导致的。
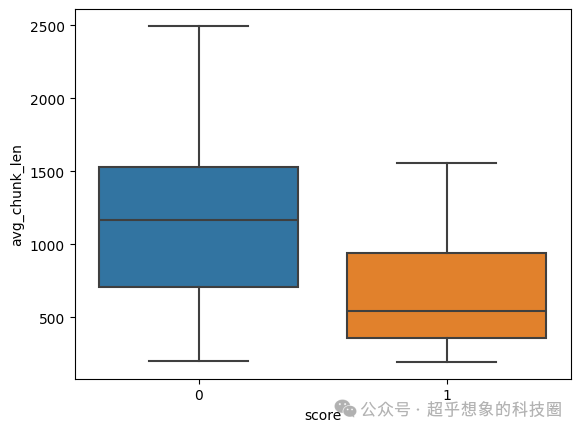
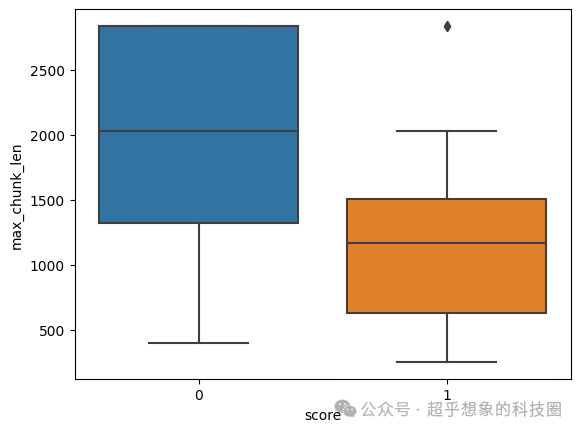
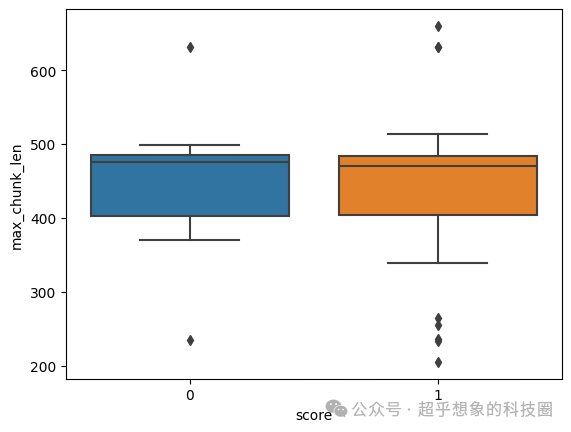
下面对答案正确(下图中score为1的)和错误(下图中score为0的)的问题,对应的最大切片长度、平均切片长度绘制灯箱图进行分析,可以明显看出,回答错了的,无论是最大切片长度,还是平均切片长度,都是比回答正确的问题要大的,推测是正确的。
3.1.2 对超长片段进行二次切分
这部分完整代码在:
https://github.com/Steven-Luo/MasteringRAG/blob/main/split/01_3_markdown_header_text_splitter_v2.ipynb
既然我们上面分析出了问题所在,接下来使用 MarkdownTextSplitter对超长的片段进行二次切分:
from langchain.text_splitter import MarkdownTextSplitter
new_md_splitted_docs = []
splitter = MarkdownTextSplitter(
chunk_size=500,
chunk_overlap=50
)
for doc in md_splitted_docs:
if len(doc.page_content) > 700:
small_chunks = splitter.split_documents([doc])
new_md_splitted_docs.extend(small_chunks)
else:
new_md_splitted_docs.append(doc)
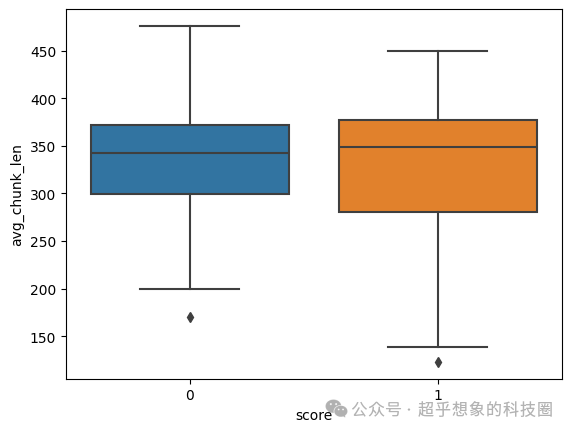
这次处理后的结果,自动打分能达到0.68了,但依然大幅低于基准0.72,下面对结果的分析也表明效果差应该不是切片长度的问题了。
3.1.3 切片增加标题
这部分完整代码在:
https://github.com/Steven-Luo/MasteringRAG/blob/main/split/01_4_markdown_header_text_splitter_v3.ipynb
再次检查代码发现,MarkdownHeaderTextSplitter中有一个参数strip_headers,默认值为True,意思是它会把切出来的标题,放到每个切片的metadata中,这样切片本身就没有标题了,这可以说是一个bug,我们把这个参数关闭:
def split_md_docs(markdown_document):
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
markdown_splitter = MarkdownHeaderTextSplitter(headers_to_split_on, strip_headers=False)
md_header_splits = markdown_splitter.split_text(markdown_document)
return md_header_splits
同时,对超长部分的片段,也把这个标题“传播”到每个超长片段二次切分后的子片段中:
from langchain.text_splitter import MarkdownTextSplitter
new_md_splitted_docs = []
splitter = MarkdownTextSplitter(
chunk_size=500,
chunk_overlap=50
)
for doc in md_splitted_docs:
if len(doc.page_content) > 700:
small_chunks = splitter.split_documents([doc])
# 把原始文档的标题回小片段的正文
for doc in small_chunks[1:]:
header_prefix = ''
for head_level in range(1, 4):
if f'Header {head_level}' in doc.metadata:
header_prefix += '#' * head_level + ' ' + doc.metadata[f'Header {head_level}'] + '\n'
doc.page_content = header_prefix + doc.page_content
new_md_splitted_docs.extend(small_chunks)
else:
new_md_splitted_docs.append(doc)
这次处理后,最终自动化打分能达到0.71,基本上追平了基准0.72,但基准模型原文切分后得到了52个切片,而这种方式得到了102个切片,原文总长度是一样的,切片数量多意味着每个切片的平均长度短,都检索TopN作为上下文的话,意味着这种方式总的Prompt会更短,线上实际使用无论是耗时还是消耗API(如果使用在线API服务)的tokens数更少,这可以说是转换成Markdown后最有价值的点了。
3.1.4 对上下文片段数搜参
这部分完整代码在:
https://github.com/Steven-Luo/MasteringRAG/blob/main/split/01_5_markdown_header_text_splitter_v4.ipynb
上一篇文章,包括本文介绍了一堆Markdown的好处,但如果仅从效果的角度看,并没有表现得很能打,是否是超参数设置得不够优导致的?因此本文又对上下文片段数进行了搜参,结果如下表,如果大家回忆之前的使用RAG技术构建企业级文档问答系统:检索优化(11)上下文片段数调参,基准模型的Top6准确率可以达到0.8,而此处只能在0.8时达到0.78。有可能是将超长片段二次切分时,将大标题传播到每个小片段,对检索造成了误解,更多原因有待大家可以进一步探索。
| n_chunks | accuracy |
|---|---|
| 3 | 0.71 |
| 4 | 0.74 |
| 5 | 0.74 |
| 6 | 0.76 |
| 7 | 0.77 |
| 8 | 0.78 |
| 9 | 0.77 |
| 10 | 0.78 |
3.2 普通Markdown切分器这部分完整代码在:https://github.com/Steven-Luo/MasteringRAG/blob/main/split/01_1_markdown_text_splitter.ipynb
from langchain.text_splitter import MarkdownTextSplitter
from langchain.schema import Document
import os
# 加载文档
markdown_documents = open(os.path.join(os.path.pardir, 'outputs', 'MinerU_parsed_20241204', '2024全球经济金融展望报告.md')).read()
def split_docs(markdown_document, chunk_size=500, chunk_overlap=50):
splitter = MarkdownTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap
)
splitted_texts = splitter.split_text(markdown_document)
return [Document(page_content=text) for text in splitted_texts]
从Langchain的源代码看,MarkdownTextSplitter其实是我们之前一直使用的 RecursiveCharacterTextSplitter的子类:
https://github.com/langchain-ai/langchain/blob/master/libs/text-splitters/langchain_text_splitters/markdown.py
class MarkdownTextSplitter(RecursiveCharacterTextSplitter):
"""Attempts to split the text along Markdown-formatted headings."""
def __init__(self, **kwargs: Any) -> None:
"""Initialize a MarkdownTextSplitter."""
separators = self.get_separators_for_language(Language.MARKDOWN)
super().__init__(separators=separators, **kwargs)
只是分割符,使用了Markdown的:
...
elif language == Language.MARKDOWN:
return [
# First, try to split along Markdown headings (starting with level 2)
"\n#{1,6} ",
# Note the alternative syntax for headings (below) is not handled here
# Heading level 2
# ---------------
# End of code block
"```\n",
# Horizontal lines
"\n\\*\\*\\*+\n",
"\n---+\n",
"\n___+\n",
# Note that this splitter doesn't handle horizontal lines defined
# by *three or more* of ***, ---, or ___, but this is not handled
"\n\n",
"\n",
" ",
"",
]
...
注意: 看起来
MarkdownTextSplitter的切分符包含了标题切分,似乎可以涵盖MarkdownHeaderTextSplitter的功能,但其实不然,大家如果阅读源代码的话会发现,MarkdownTextSplitter切分只会按照指定的字符串硬切,如果Markdown的代码块中包含这些切分符,也会被切开,会造成语义不连贯,但MarkdownHeaderTextSplitter有诸如split_text这样的方法,可以确保如果切分符出现在代码块中,它是不会硬切开的。


















 1619
1619

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











