






会议链接
RACV2021观点集锦 | 视觉transformer 从主干encoder 到任务decoder: 现状与趋势
low/high level的视觉任务都有相应的transformer刷榜。然而,火热研究的背后,真正深层次的问题有没有得到解决,真正的难点有没有得到突破,仍然值得冷静的思考和讨论
邱锡鹏:Transformer促进范式迁移
CV里面Decoder的部分可能是被忽略了,大家都在关注Encoder部分。其实Transformer是个完整的Encoder-Decoder架构,特别在Decoder上面,它有cross-attention会使得它这个模型相当的灵活。
NLP的统一范式
-
它们变成序列到序列的范式
比如说第一个机器翻译任务 that’s good,我们就在前面加一个任务的描述,就是translate English to German,加了这个之后的序列,就输入到T5。然后T5就输出对应的德语。再比如说我们要做Summarization,就在输入序列前面就加个Summarize,然后冒号,它就输出对应的摘要。
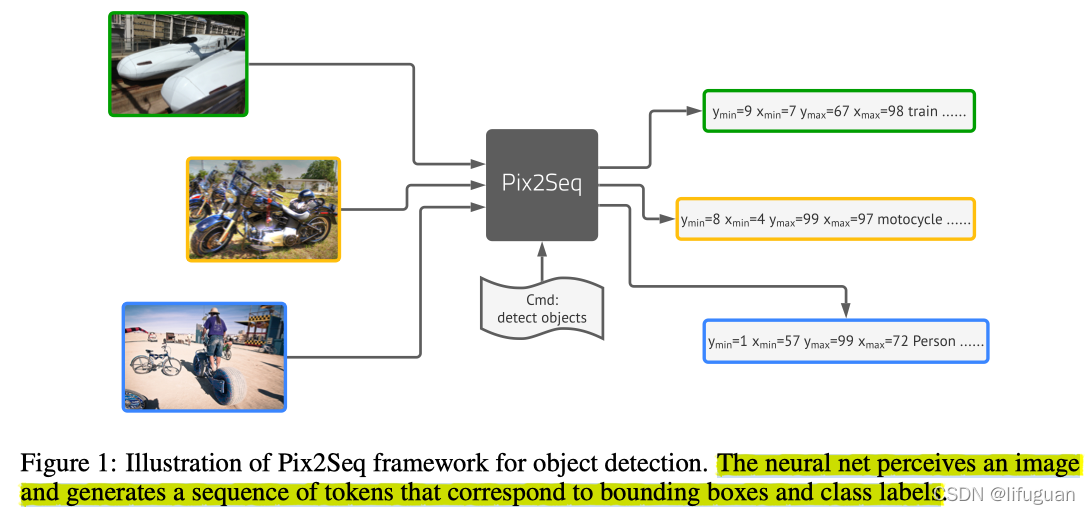
📖 Decoder part is neglected in CV.
Pix2Seq:用于目标检测的语言建模框架
参考链接
https://github.com/gaopengcuhk/Stable-Pix2Seq
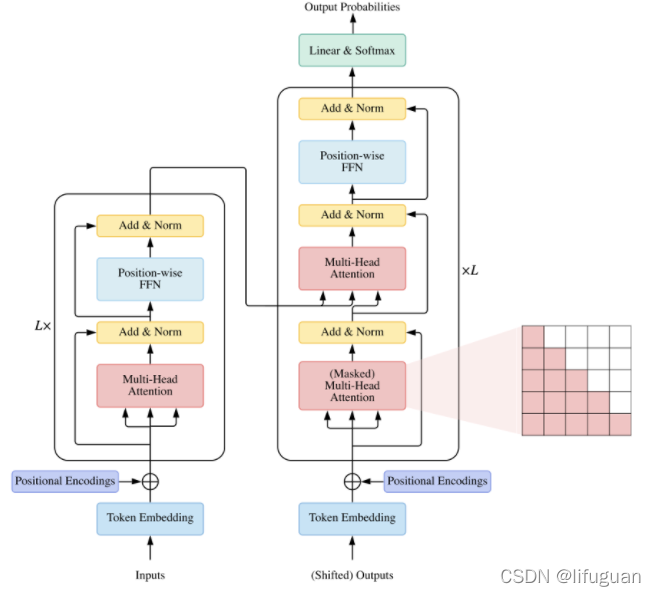
The neural net perceives an image and generates a sequence of tokens that correspond to bounding boxes and class labels
Spotlight
-
现有方法:精心设计的框架
大多数现有的方法都是使用精心设计和高度定制的框架,在模型结构和损失函数的选择方面需要大量的先验知识,比如NMS、ROI Pooling等等
-
作者认为:
如果神经网络知道对象在哪里以及对象是什么,那么我们只需要教它读出它们(即语言生成任务) 。通过学习“描述”对象,模型可以在像素观察的基础上,学习“语言”的生成,从而产生有用的对象表示。
In essence, we cast object detection as a language modeling task conditioned on pixel inputs, for which the model architecture and loss function are generic and relatively simple, without being engineered specifically for the detection task.
架构设计
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HaL1IYFC-1640144582391)(https://s3-us-west-2.amazonaws.com/secure.notion-static.com/4fbd2f91-515d-4c92-bb57-2afa3a1768d0/Untitled.png)]](https://img-blog.csdnimg.cn/78b93894ac444120b689390deb95141c.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbGlmdWd1YW4=,size_20,color_FFFFFF,t_70,g_se,x_16)
- 图像增强(Image Augmentation) :作者使用图像增强来丰富一组固定的训练样本(例如,使用随机缩放和裁剪)。
- 序列构造和增强(Sequence construction & augmentation) :目标检测数据中的目标通常用检测框和类别标签来表示,作者在Pix2Seq中将其表示为一些离散token的序列,并在训练过程中对其进行了增强。
- **结构(Architecture) :**作者使用编码器-解码器结构,其中编码器用来感知像素输入,解码器用于生成目标序列。
- 目标函数(Objective/ function): 该模型的训练目标是最大化以图像和之前的token为条件的token对数似然。
根据对象描述构建序列
每个对象(bounding box)都可以描述成 [ y m i n , x m i n , y m a x , x m a x , c ] [y_{min},x_{min},y_{max},x_{max},c] [ymin,xmin,ymax,xmax,c]。
对于坐标 x , y x,y x,y来说,其被离散成 [ 1 , n b i n s ] [1,n_{bins}] [1,nbins]。这里的 n b i n s n_{bins} nbins代表着可能的坐标数值。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3HOhAhMs-1640144638579)(https://s3-us-west-2.amazonaws.com/secure.notion-static.com/7f52513a-15ff-4f9e-86af-8abd10247425/Untitled.png)]](https://img-blog.csdnimg.cn/60c2683a584a44709f7c95fd5e1fbe43.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBAbGlmdWd1YW4=,size_20,color_FFFFFF,t_70,g_se,x_16)
对给定图像,序列化多个对象描述。同时对象的顺序于任务本身无关,所以使用随机排序策略。
胡瀚:为什么Transformer在视觉中如此受欢迎
总结了五大价值和优点
通用性
Transformer可以看作是一个图
它用图的节点和边分别来表示所有概念以及概念之间的关系,这个概念可以是实体,例如视觉物体,也可以是抽象的概念、词汇→Transformer可以表示万事万物。
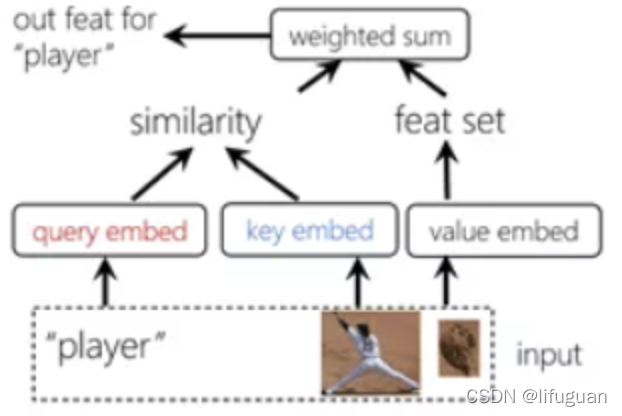
验证的哲学去构建关系
对每个节点的特征做投影,在投影的空间里去比较节点之间的相似度,用这个相似度来刻画节点之间的关系
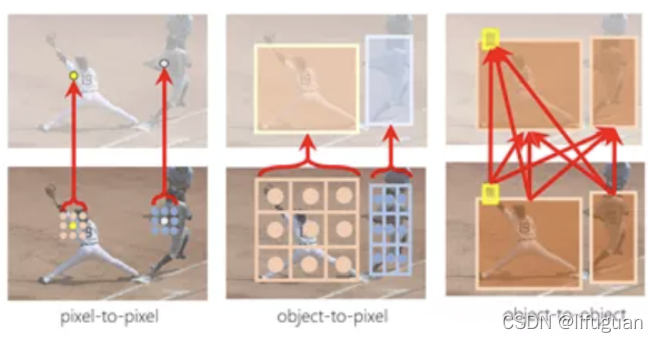
- 像素-像素建模:以前采用卷积,目前主要采用Transformer或者其中的自注意单元了,这个其实主要与Transformer的Encoder部分相关
- 像素-物体建模:采用交叉注意力单元,这与Transformer的Decoder部分相关
- 物体-物体建模:深度学习之前:研究如何引入上下文(context)帮助识别;深度学习时代:研究如何表征学习;Transformer时代:重新对上下文进行建模
建模异构数据
现在在CV和NLP中都有大量基于Transformer的模型,而且也可以利用Transformer进行跨模态的结合。
同时,CV相比NLP需要解决更广泛的问题范畴,事实上CV可以看作是Speech+NLP的结合,它涉及信号处理、感知和认知多个层次的任务。














 401
401











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









