






HLS简介
高层次综合HLS(High Level Synthesis)是一种从更高抽象层次描述生产电路的技术,这项技术的出现使得电路设计不用再局限于使用硬件思维的电路设计语言,可以通过一定的编码方式使用C/C++进行电路设计,并使用相应的优化方法将电路资源最大化利用。
HLS有三个关键的子流程,分别是行为描述,行为综合,分析与优化。
行为描述
HLS的行为描述流程,就是用C/C++语言按照一定的编程方式对电路行为进行表达。在编程时,需要注意按照软件语言的行为规范,同时又要舍弃一些软件系统的思维理念,各个HLS工具有各自的规范,但它们有相同的约束:禁止递归和动态指针。
行为描述的基本对象有输入输出接口,数据位宽,并行化描述等。
行为综合
在行为综合的过程中,会将行为描述中使用的变量,数组,运算分别使用寄存器(FF,LUT),内存(BRAM),运算器(DSP)等数字电路来实现,行为描述中的处理流程(顺序执行,条件分支,循环)以有限状态机的形式来呈现。
HLS在把C/C++转换成HDL(硬件编程语言)时需要完成三件事:
1.将一个行为描述代码的转化为数据流图DFG,将控制流程表示为控制流图

该图表达的是使用高级编程语言描述行为时变量的数据依赖关系,但是源代码中某些复杂的依赖关系无法被转换,所以在编写代码时要注意简洁。
2.调度

首先,代码中可以并行执行的部分会被放到一个控制步中执行
图中展示X,Y与E,F之间没有数据依赖关系,所以它们可以合并到一个控制步中执行,提高了运行效率。
该过程由HLS编译器执行,会存在一些编译器认为的无法优化的代码,需要用户加入指令说明。
其次,对优化好的数据流图中的操作分配时钟周期。
3.Binding
将数据流图映射到资源上的过程,除了达到算法的基本功能,更重要的是选择不同的绑定和调度方案在资源、性能、吞吐量等各个指标中做权衡和取舍。
HLS设计流程
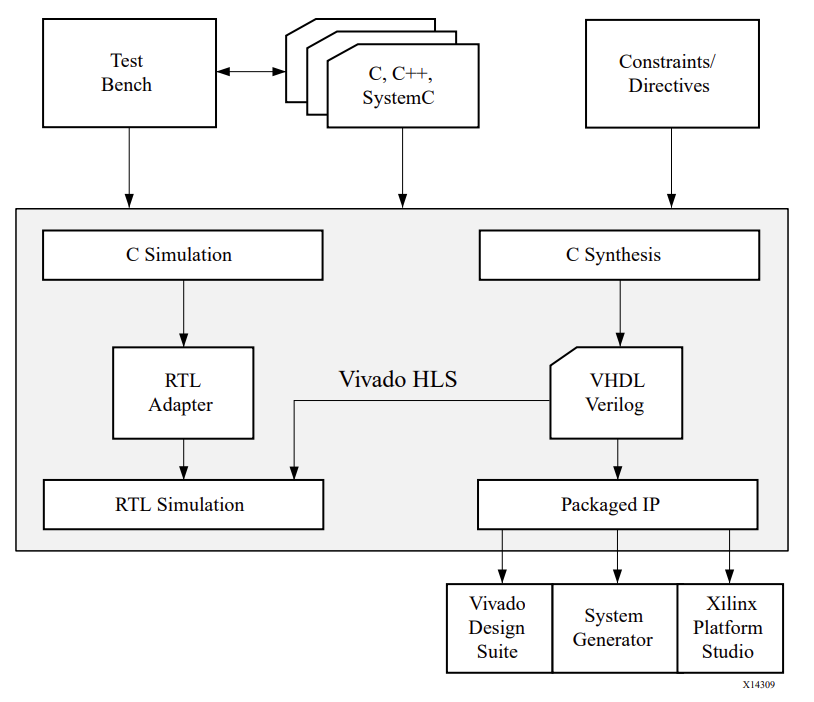
HLS设计的主要输入为C/C++程序设计和一个基于C的测试集(TestBench)。首先要进行c功能性验证,测试集用于测试c中代码是否能被硬件顺利执行,在测试时需要设置一个“黄金参考”,在测试集中调用c代码中的函数,将其输出与黄金参考比对,若输出无误,则代码通过测试,若有误,则修改代码。
接下来要对设计进行高层综合,包括接口综合和算法综合,高层综合结束后会产生包括VDHL或verilog语言编写的RTL设计文件等的一系列文件。
对于得到的RTL模型,vivado HLS会对其进行C/RTL仿真,以此来验证RTL设计的正确性,验证方法类似于C功能性验证。
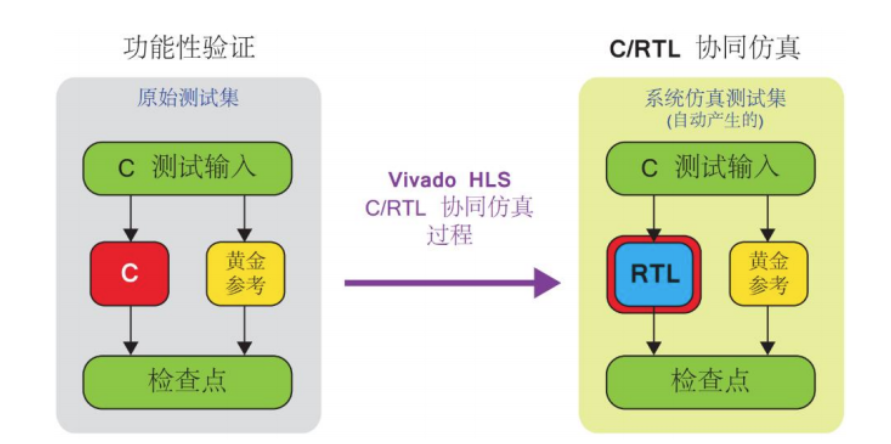
除了对功能进行验证,还需要对RTL设计的性能进行评估,比如在 FPGA 中所需的资源的数量,设计的延迟、所支持的最高时钟频率等是否满足要求。如果不满足要求,那么就必须修改指令和约束,再次进行高级综合。HLS的一个solution可能会被经历多次迭代,最终寻找到对于问题的最优解。
HLS中的数据类型
c编码中数据类型以8位位基础,皆为8的倍数,这样子会造成实际计算只需要18位,数据类型占32位的情况,在HLS中应用这种精度的数据类型是不可取的,所以设置了任意精度的数据类型。
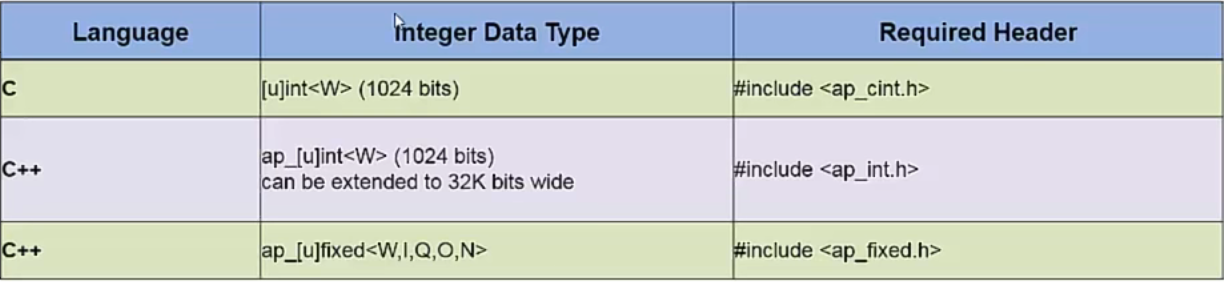
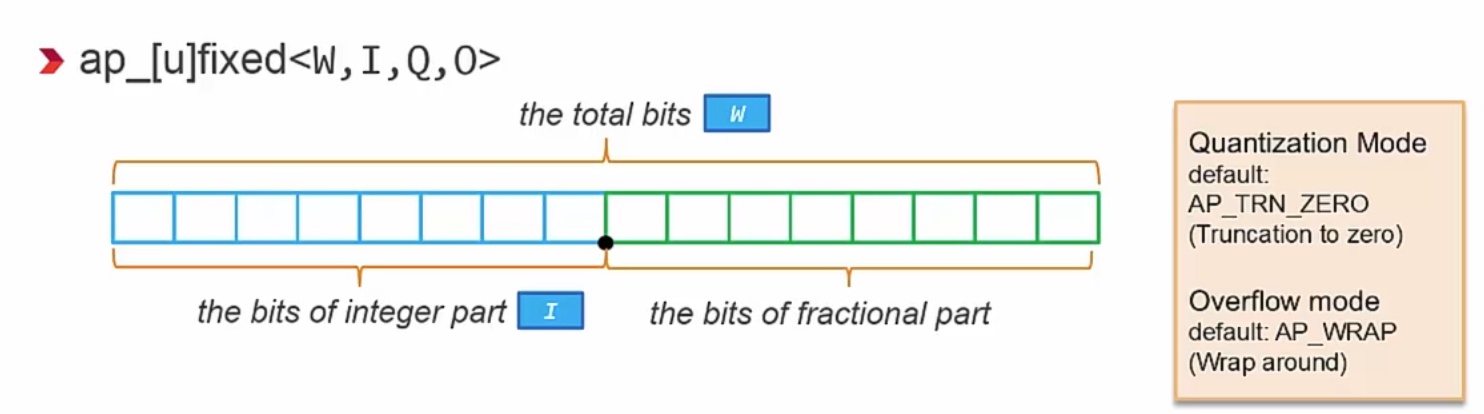
对于整形的数据类型,直接规定位数即可;浮点型的数据类型需要设定W:数据总字长,I:整数部分字长,Q:量化模式,O:溢出模式
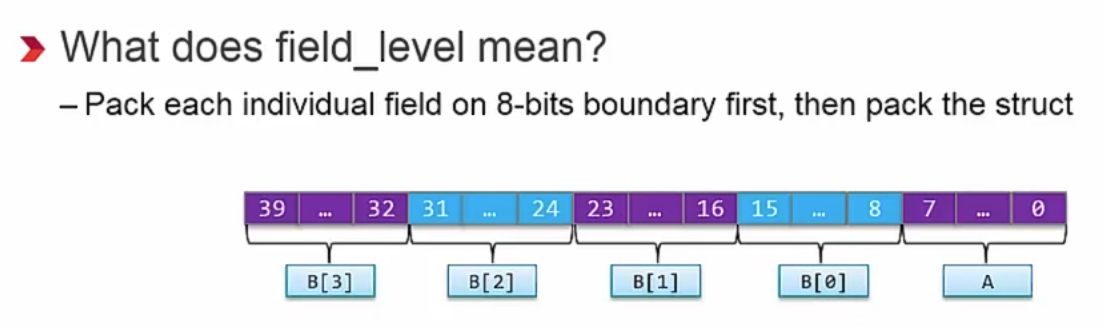
hls中的结构体一般定义在头文件里,结构体的优化方法为DATA_PACK优化,提供了两种优化方法对结构体数据填充:field_level和struct_level,field_level将结构体中每个数据自动填充成8的倍数,struct_level保留每个数据的位数,在数据末尾补充空间到8的倍数位。
DATA_PACK可以把for循环做一个展开,在一个始终周期内完成数组的存取,提高了吞吐率。
HLS的循环优化
1.循环优化的性能指标
loop trip count :循环执行了几次
loop interation latency :循环一次用了几个时钟周期
loop interation latency(Loop II) :两次循环直接间隔了几个时钟周期
loop latency:整个for循环的latency
Function Latency:函数的时钟周期
Function Iteration Interval:函数总共占用时钟周期
2.循环合并merge
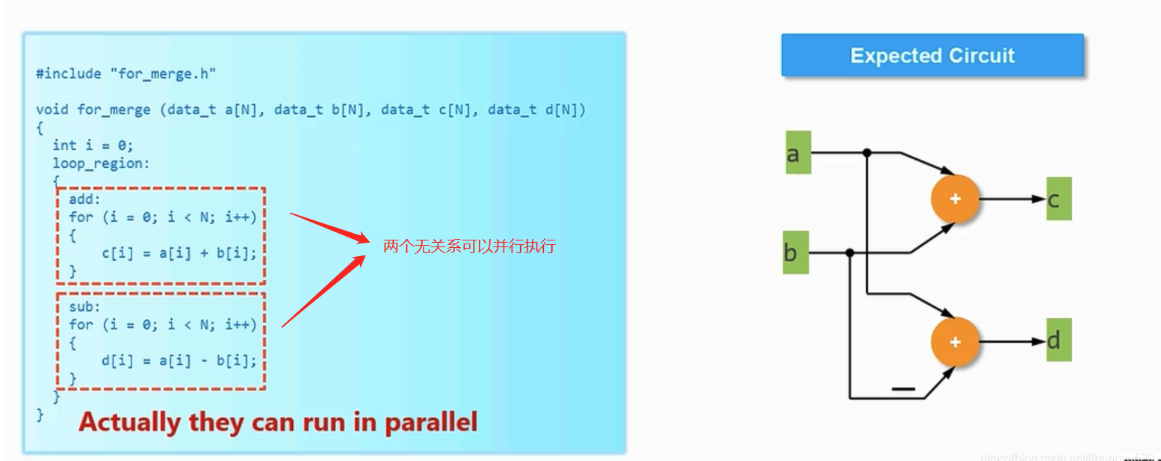
如图所示 ,两次循环中没有数据依赖关系,可以合并成一个电路,在一个时钟周期内完成两次计算,这样可以减少延迟。
合并循环要求两个循环的循环界限一致且为常数,循环边界不一致或循环边界属性不一样则需要一些方法来合并。

当循环边界是变量时,也可以使用以下三种方法:
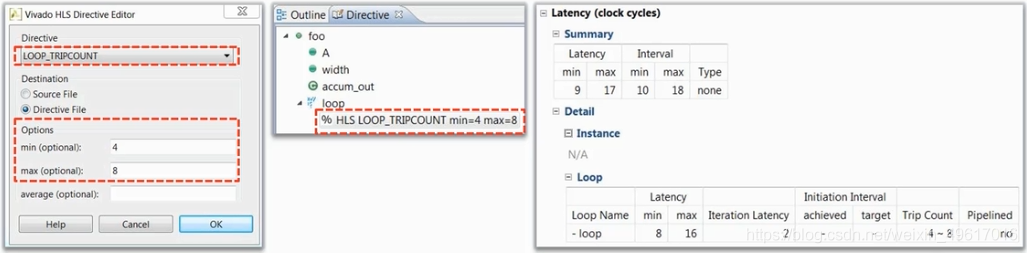
1.使用tripcount directive:手动设定循环边界的最大值最小值。
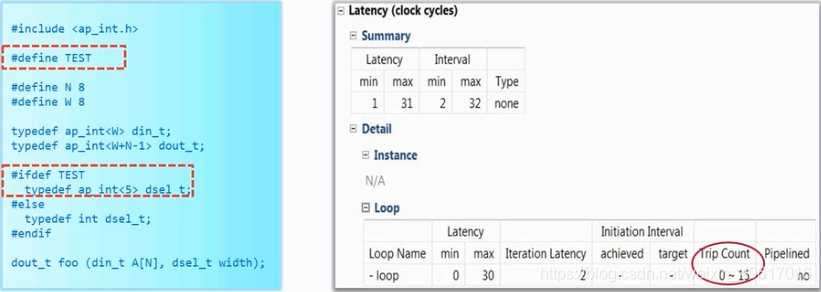
2.把循环边界的数据类型声明成ap_int。
3.使用assert函数对循环边界做一个大致的判断。
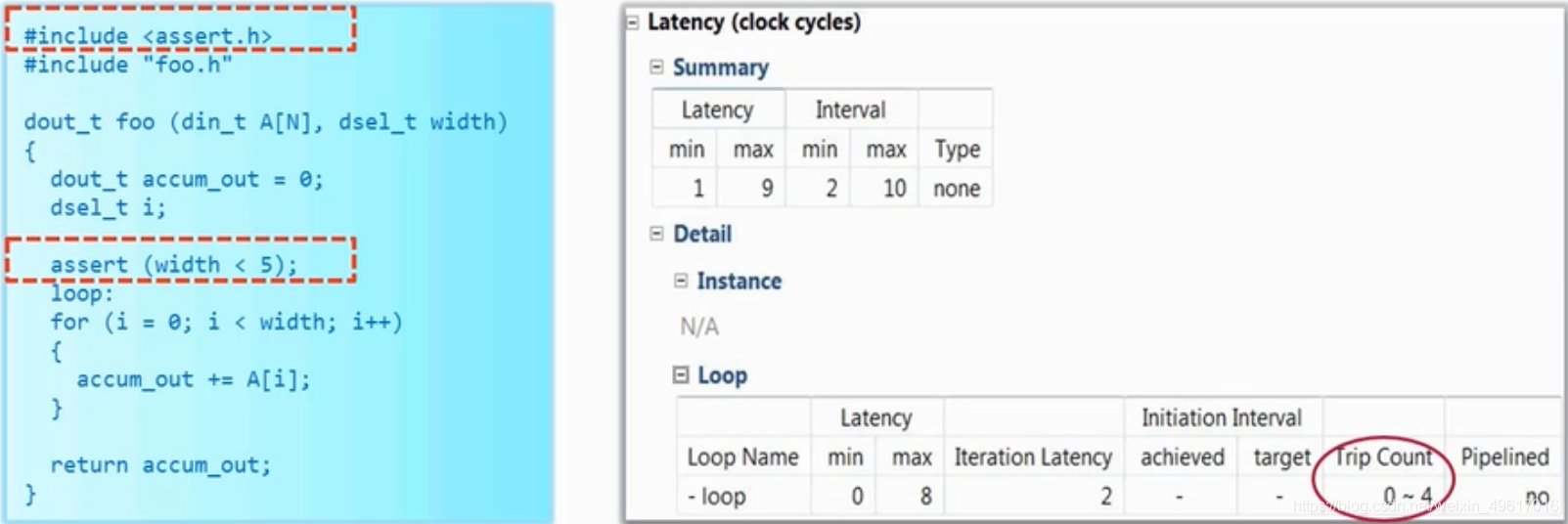
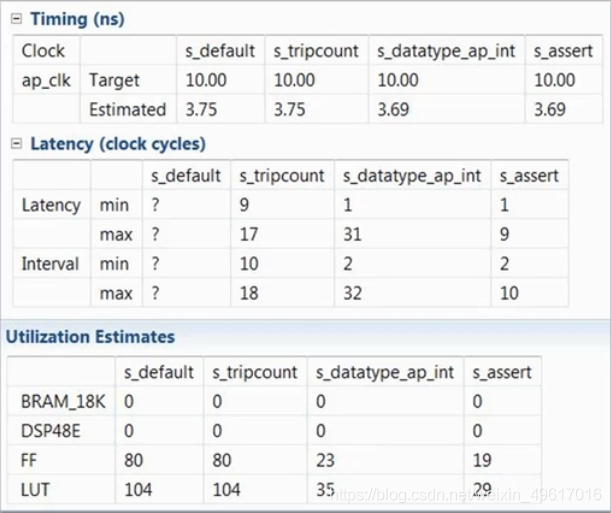
三种方式的优化结果如下
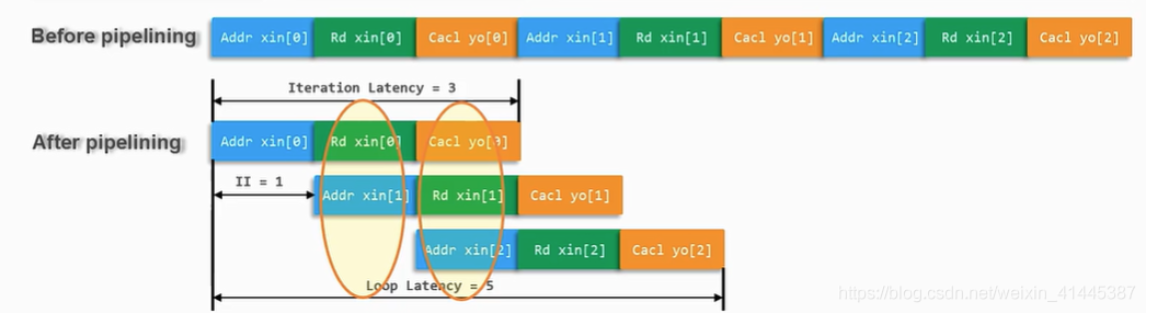
3.流水线优化pipeline
在for循环中,一些寄存器在使用之后短时间内不会再被使用,且循环之间不存在数据依赖,这时候就可以使用pipeline优化,让for循环转换成一个流水线,将空闲的寄存器让给下一个循环语句使用。
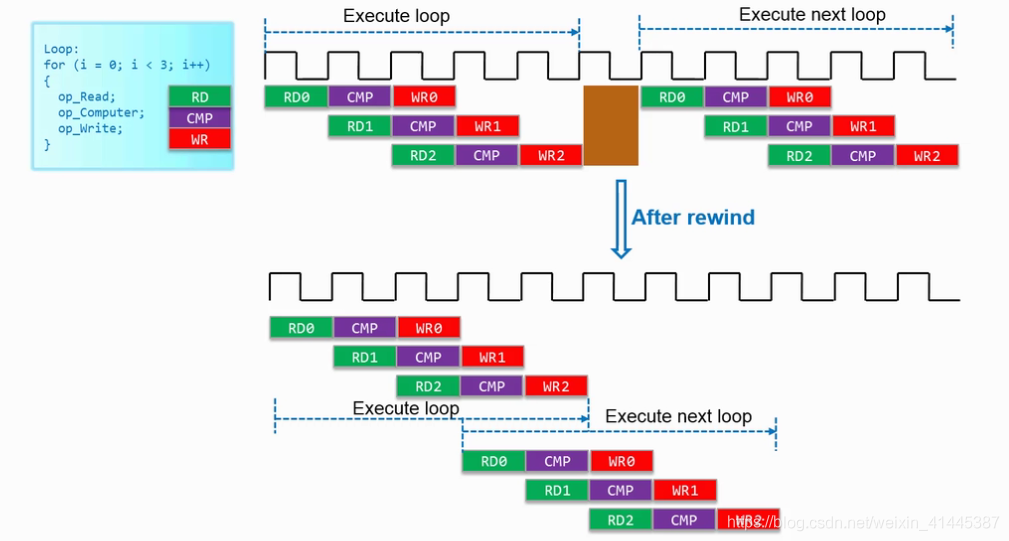
pipeline优化中可以使用rewind操作,将循环之间一个时钟周期的延迟给省略掉,下一个循环直接进流水,提高并行性。
4.for循环的展开unroll
如果FPGA芯片资源足够,可以将for循环展开运行,提高并行性。
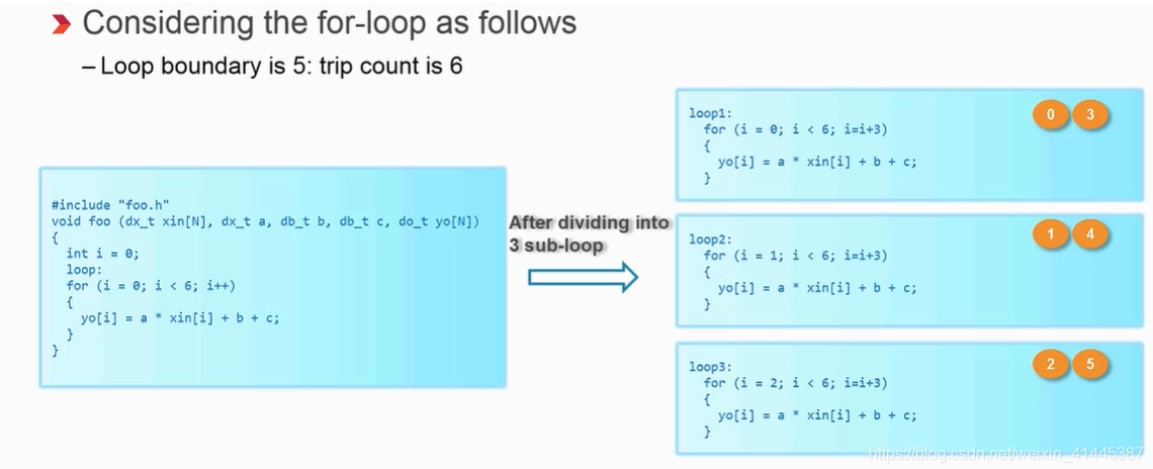
5.嵌套for循环
通过代码优化将后两种嵌套循环替换成前两种
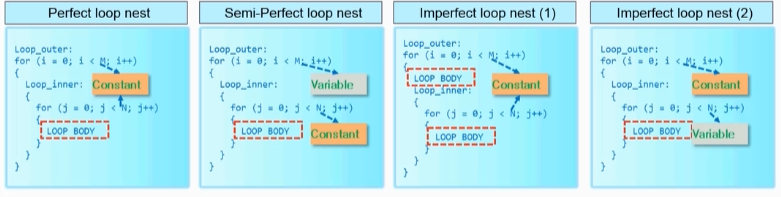
对上层循环pipeline会直接将下层循环全部unroll。
对上层循环unroll可能会导致资源冲突,所以一般对内层循环展开。
6.任务流水线优化dataflow
将一个循环视作一个任务,且任务之间存在数据依赖。

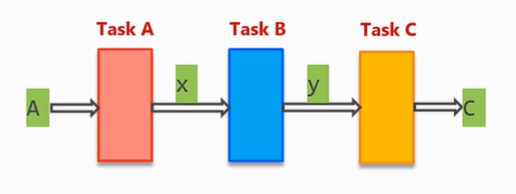
此时不能使用循环合并和内部流水操作来优化,可以使用dataflow将任务从顺序执行转换为流水线执行来优化。
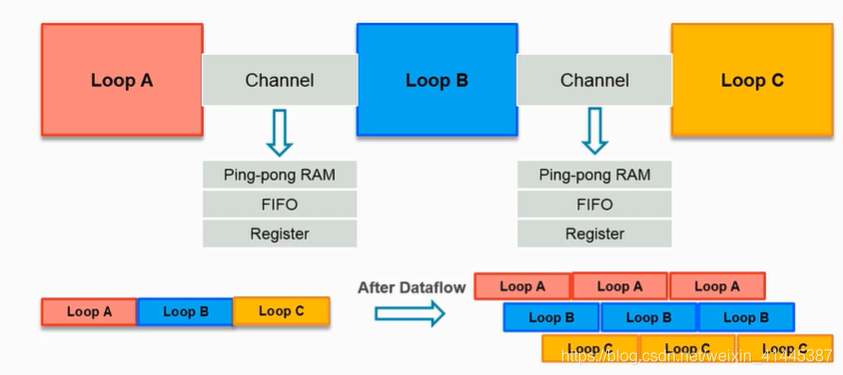
与循环内部流水化操作不太一样的是,dataflow不对循环体内的操作进行优化,而是对循环体与循环体之间所使用的硬件(Ping-pong RAM,FIFO,寄存器)进行流水线的分配。
有两种情况不能直接使用dataflow优化:
1.一个生产者服务两个消费者
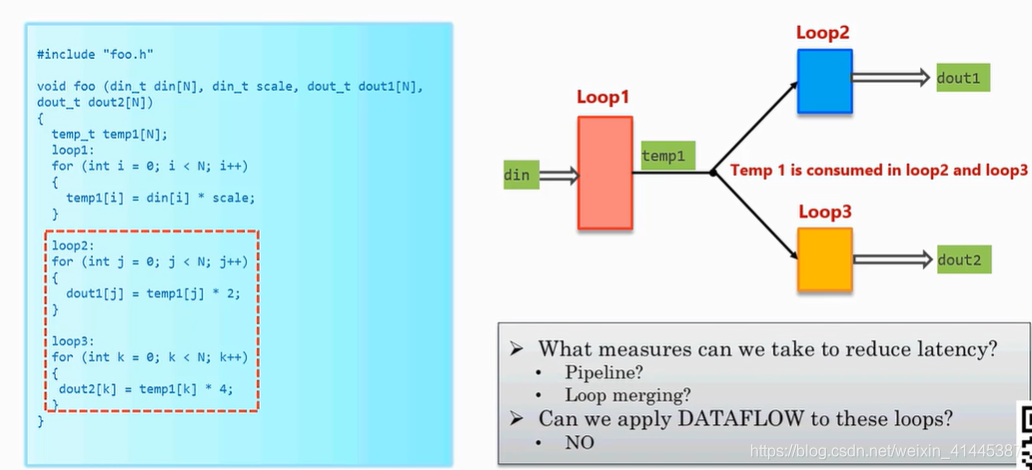
当一个循环任务被其他两个循环任务调用时不能直接用dataflow优化,但可以使用pipeline和merge。
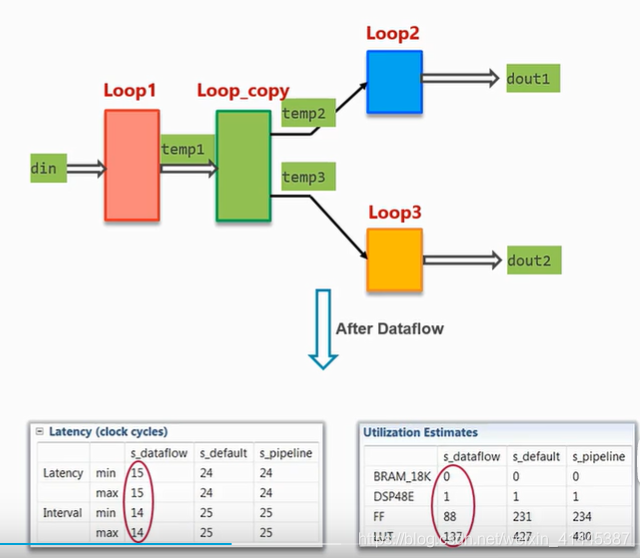
可以在第一个循环后加上一个变量复制的循环,损失一点内存资源来换取更高的并行性。
2.bypass模型
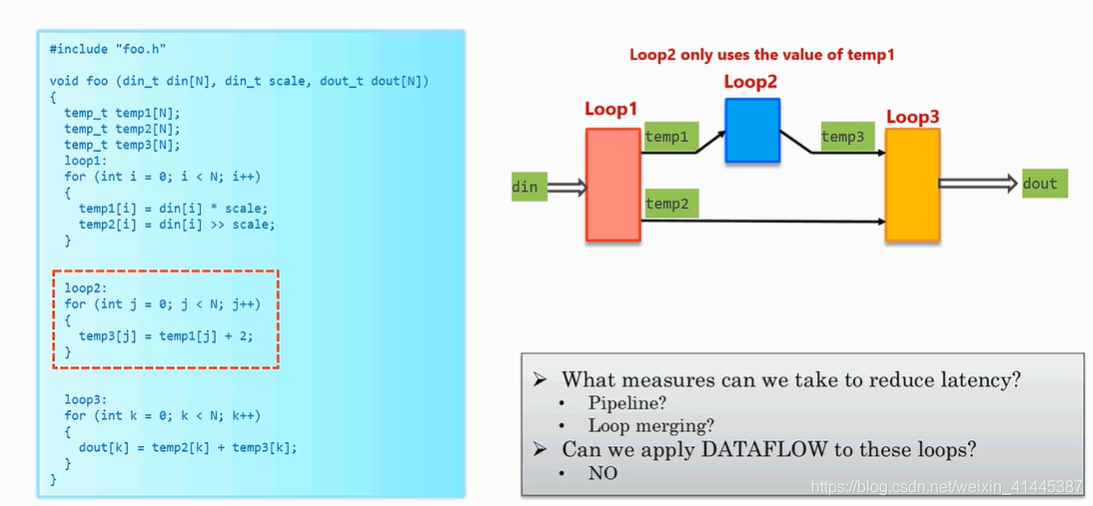
该图中loop2只与loop1部分关联,无法使用dataflow优化。
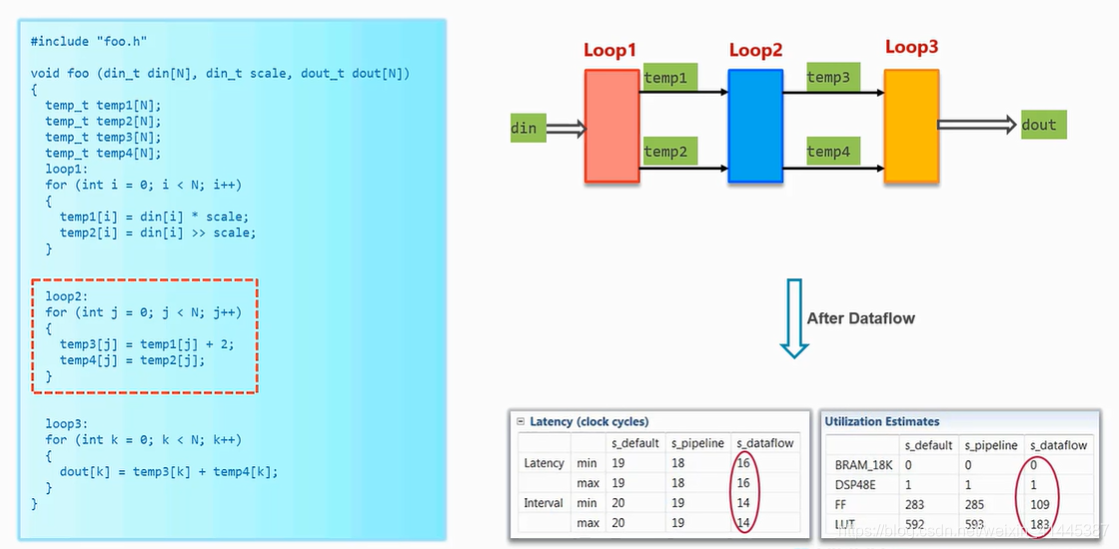
在loop2对temp2进行复制,就可以使用dataflow进行优化。
HLS的数组优化
1.数组分割
Vivado HLS默认使用单端口RAM,只有一个端口的情况下无法同时进行读操作和写操作,可以使用RESORCE指令指定使用双端口RAM,以此来减少启动间隔或减少延迟。
HLS将顶层函数接口上的数组综合成网文外部内存的RTL接口,将内部设计的数组综合成内部BRAM,LUTRAM,UltraRAM,或寄存器,取决于优化设置。
HLS提供三种数组分割的方法:
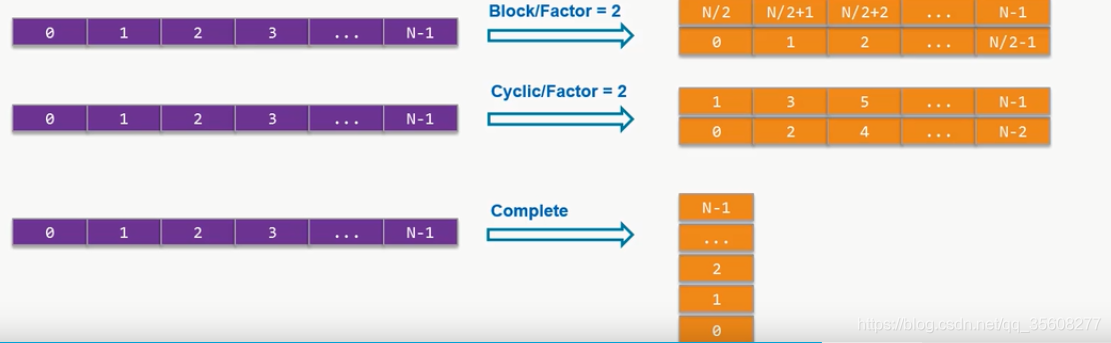
1)Block
将数组按顺序分割,先将数组分为N组,按照数组存储顺序依次填充组内元素。
2)Cycllc
将数组按轮序分割,先将数组分为N组,然后从第一组开始每组填充一个元素,直到N组内元素填充完毕。
3)Register
将数组完全展开,以并行方式处理数组。

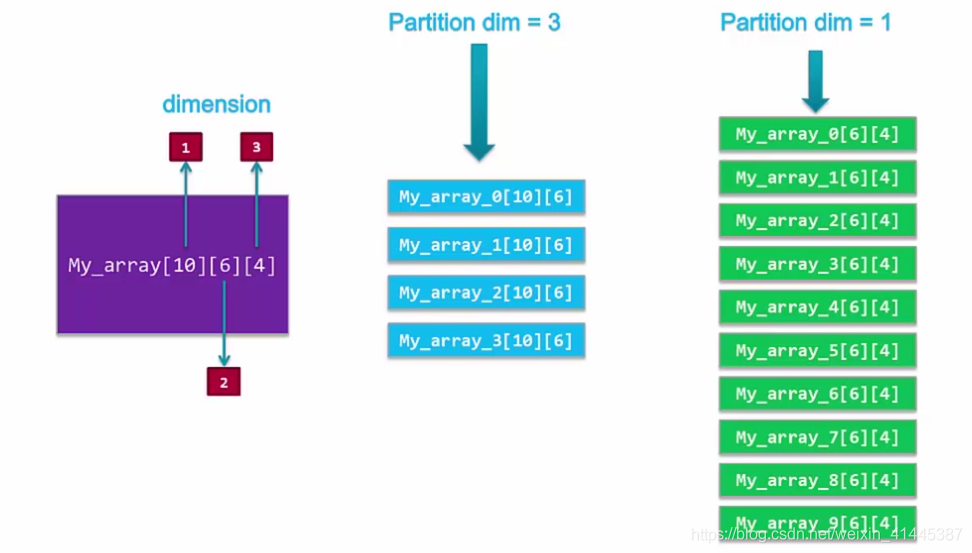
多维数组在进行分割时,需要指定数组的维度进行分割,如下图所示,将该数组的第三维分割,得到四个二维数组,以此类推。
2.数组的映射
C代码中有很多小数组时,可以把这些数组统一映射到一个大数组中,这样可以减少BRAM的使用数量,HLS使用ARRAY_MAP指令将小数组映射到大数组中,有横向和纵向的方式。
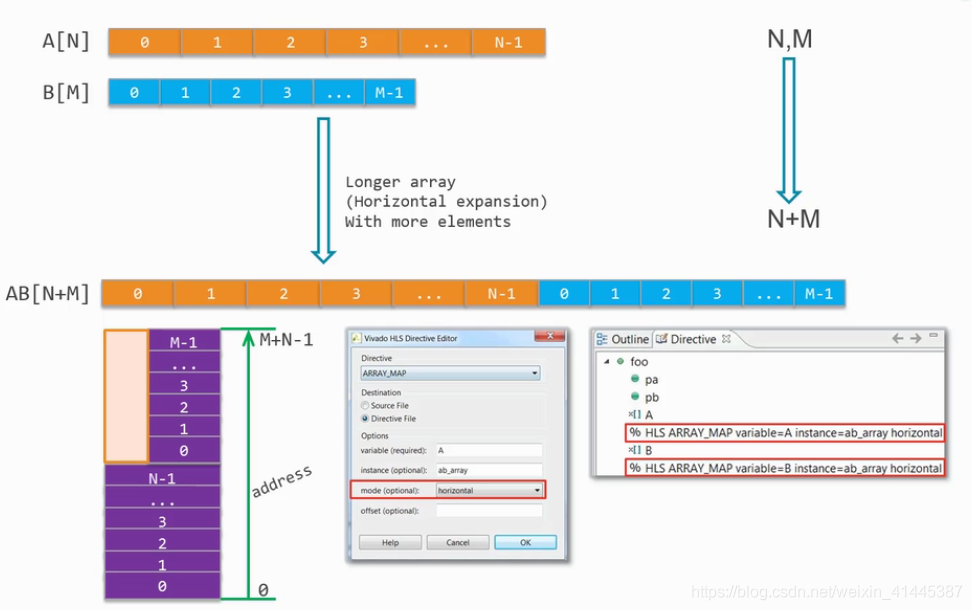
1)水平映射
将长度为M和N的数组拼接成长度为M+N的数组,该方法不需要考虑数据位宽。
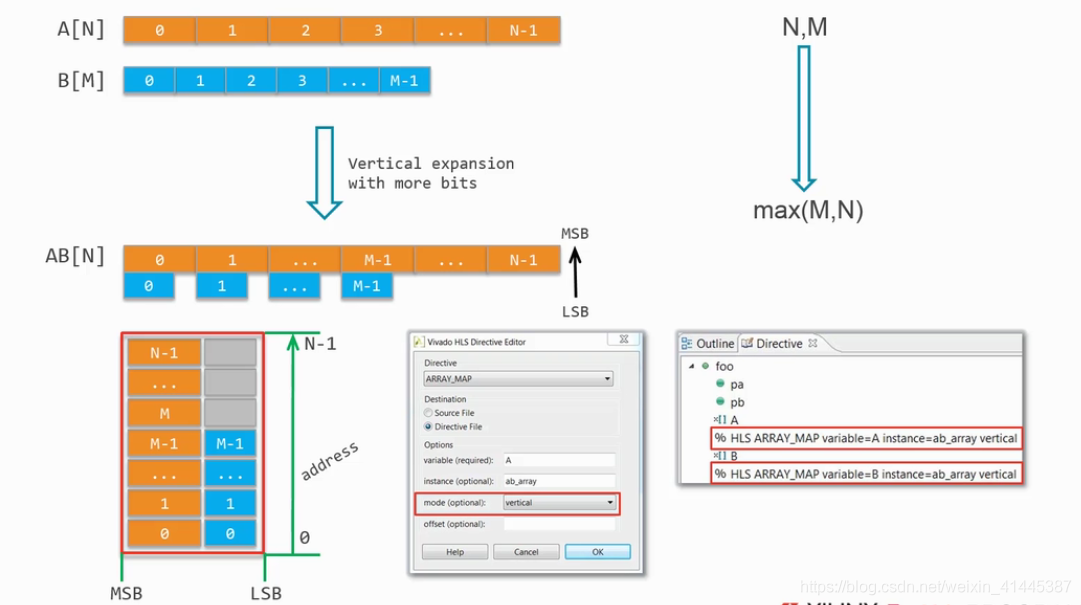
2)垂直映射
将两个数组拼接成较大位宽的单个数组,该方法不需要关注数组长度。
3.数组的重组
HLS的数组重组是将数组分割和数组纵向映射结合在一起,对单个数组分割之后纵向映射,并且类似于数组分割,提供了Block、Cyclic和Complete三种重组方式。
4.其他方法
数组不加static关键字,在执行开始时没有被初始化,那么在该数组每次设计执行时,就会加载该数组的值,加上static关键字后对数组处理使用的时间周期会变少。
HLS的函数优化
1.内联
函数内联的操作删除了函数的层次结构,减少了函数之间调用带来的资源使用量增加。HLS可能会自动内联小的函数。
2.分配
HLS使用ALLOCATION对特定函数的RTL实例进行限制,如果C中一个函数有4个实例,那么 ALLOCATION 编译指示可确保最终 RTL 中仅有该函数的 1 个实例。
3.任务级流水线
与循环的DATAFLOW基本一致,只不过是在函数与函数之间进行优化,在函数使用的资源上进行分配,允许任务之间有交叠。
HLS优化指令汇总
1.吞吐率的优化
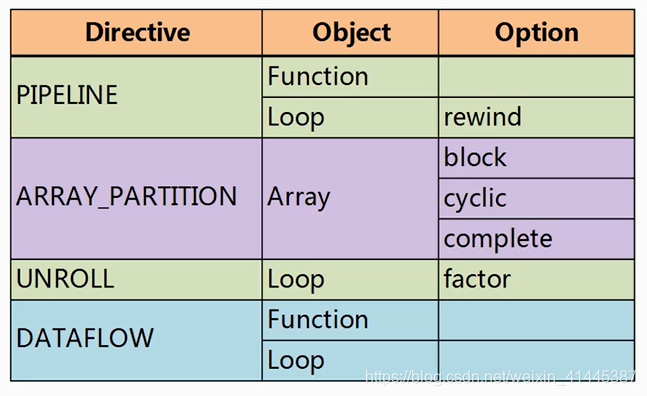
2.面积优化
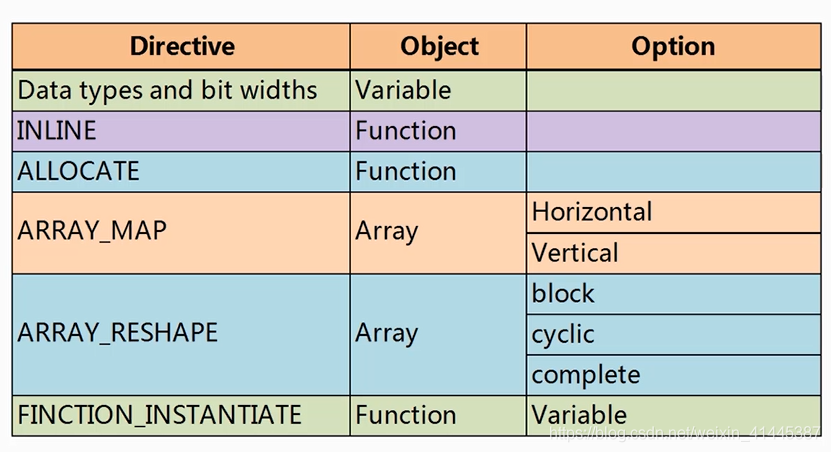















 4101
4101











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









