









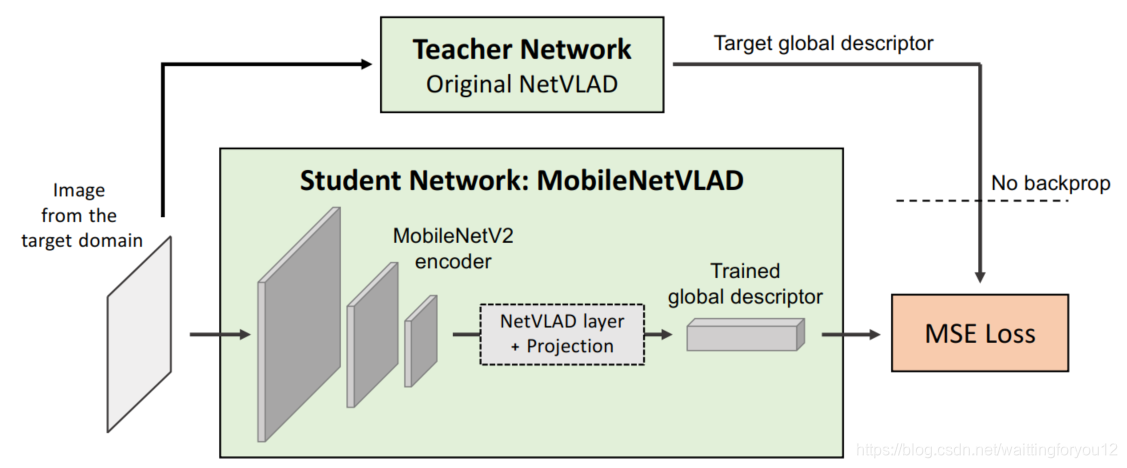
MobileNetVLAD来自于论文“Leveraging Deep Visual Descriptors for Hierachical Efficient Localization”。作者为了在移动平台上部署视觉位置识别网络(Visual Place Recognition),使用知识蒸馏的方式在MobileNetV2的基础训练了一个轻量级的网络。该网络根据作者论文给出的数据显示,在NVIDIA Jetson TX2 board上 ,一张图片inference所需的时间只需要58ms,比原始的NetVLAD网络提速38倍。整个网络的训练和测试都是基于tensorflow1.0版本进行的,具体的实现细节还未去仔细阅读,首先想通过一些实际场景来大体测试一下该网络的性能,因此记录测试过程。
测试思路
- 在Kobuki平台上安装摄像头设备和2D雷达。根据键盘控制kubuki在实际环境中移动,同时采集图像数据和雷达数据。图像数据和雷达数据用ROS bag记录。
- 由于相机采集频率高于雷达频率,因此利用ROS 自带多传感器时间同步机制Time Synchronizer对雷达数据和相机数据进行同步处理,在回调函数中利用雷达每帧数据进行定位,为了不处理更多繁杂的相机数据,设置关键帧筛选机制。比如当雷达定位距离大于0.2m或者角度旋转超过20度时,设定当前帧为关键帧,并记录当前帧的位置(
)与该时刻对应采集到的图像数据。通过这样的处理,成功的获取到了Kobuki移动过程中的关键帧图像位置和对应的定位信息。定位信息通过txt存储。
- 利用python脚本随机的打乱图像数据,分成database和test两个数据文件并同样记录对应的定位信息到txt文件中。
- database用于生成底库描述子,分别将test中的每帧数据送入网络进行inference提取图像特征,最后利用最近邻或者相似性搜索库在底库中搜索与当前测试图像特征最相似的n张图片。我们把两张图片的雷达定位位置做为groundtruth,在测试中,设定两张图片的定位距离小于0.5米,并且角度旋转不超过20度时,这两张图片来自同一场景。最后统计测试网络框架Best1, Best 5, Best 10, Best 20的召回率。
数据采集
数据采集这一步是利用ros bag记录,就不多再赘述。
雷达定位与关键帧刷选
这一步是利用2D雷达数据获取定位信息,并根据定位信息基于适当的阈值设置关键帧,在关键帧的时刻存储对应的图像信息和图像对应的定位信息。这一步的目的是减少测试中过多的冗余数据,并且根据定位信息可以为测试提供真值。主要代码如下所示,通过Time Synchronizer的时间同步机制回调同时获取相机数据和雷达数据,雷达的定位基本上来源于cartographer,只是同事对其进行了功能上的精简,读者可以利用cartographer进行定位, 当判断当前帧为关键帧时,保存对应的图像数据和定位信息。
void combineCallback(const sensor_msgs::LaserScanConstPtr &scan_in, const sensor_msgs::ImageConstPtr &image_in)
{
double time_img = image_in->header.stamp.toSec();
double time_scan = scan_in->header.stamp.toSec();
printf("time scan: %lf, time img: %lf\n", time_scan, time_img);
TranScanToPointCloud(scan_in, scanLaserPoints);
bool add_keyframe = false;
if (isInit == false)
{
slam2D.SetSlamEnable();
slam2D.InitialLaserSlamMap(laserPose, scanLaserPoints);
isInit = true;
v_2d_trajectories.emplace_back(laserPose);
v_times.emplace_back(time_scan);
add_keyframe = true;
}
else
{
double delta_phi;
size_t size_poses = v_2d_trajectories.size();
if (size_poses == 1)
{
delta_phi = v_2d_trajectories.back().Phi();
}
if (size_poses >= 2)
{
Pose2D last = v_2d_trajectories[size_poses - 1];
Pose2D pre_last = v_2d_trajectories[size_poses - 2];
delta_phi = last.Phi() - pre_last.Phi();
}
laserPose.SetPhi(laserPose.Phi() + delta_phi);
slam2D.ScanMatch(laserPose, scanLaserPoints);
laserPose = slam2D.GetCurrentPose();
v_2d_trajectories.push_back(laserPose);
v_times.emplace_back(time_scan);
double delta_x = fabs(laserPose.X - lastPoseKeyframe.X);
double delta_y = fabs(laserPose.Y - lastPoseKeyframe.Y);
double theta = fabs(laserPose.Phi() - lastPoseKeyframe.Phi()) * 180 / 3.1415926;
double dist = sqrtf(std::pow(delta_x, 2) + std::pow(delta_y, 2));
if (dist > dist_threshold || theta > angle_threshold)
{
add_keyframe = true;
}
}
if (add_keyframe == true)
{
printf("Add keyframe at cur time\n");
double tx = laserPose.X;
double ty = laserPose.Y;
double phi = laserPose.Phi();
if (phi < -3.1415926) phi += 2 * 3.1415926;
else if (phi > 3.1415926) phi -= 2 * 3.1415926;
double theta = phi * 180 / 3.1415926;
unsigned long int time_path = time_scan * 1e6;
//std::string path_local_img = std::to_string(time_path) + ".png";
// write to txt
f_write << time_path << " " << tx << " " << ty << " " << theta << " " << endl;
printf("laser odo sparse coor: (%lf %lf %lf)\n", tx, ty, theta);
std::string path_img = result_dir + "/" + std::to_string(time_path) + ".png";
cv::Mat img_src = cv_bridge::toCvShare(image_in, sensor_msgs::image_encodings::MONO8)->image.clone();
cv::imwrite(path_img, img_src);
lastPoseKeyframe = laserPose;
num_keyframes++;
}
return;
}拆分获取底库和测试数据
基于上述获得的测试图像和对应的定位信息,首先打乱整个数据集,随机按比例抽取一部分为底库数据,一部分为测试数据。分别存储在base/文件夹和test/文件夹中,每个文件夹中都记录了其包含图像信息的定位信息,命名为loc.txt,为了保证数据的正确关联,txt数据中额外存储了图像的时间戳信息。python程序如下所示
import math
import numpy as np
import shutil
import random
from os.path import join, exists, isfile, realpath, dirname, basename, isdir
from os import mkdir, makedirs, removedirs, remove, chdir, environ, listdir, path, getcwd
import sys
from datetime import datetime
import argparse
parser = argparse.ArgumentParser(description='Randomly split data to two parts')
parser.add_argument('--eg', type=str, help='python random_split_files.py \
--txt ../test_vpr_data/04_16_01/loc.txt \
--folder ../test_vpr_data/04_16_01/ \
--stype image \
--base base \
--query query')
parser.add_argument('--stype', type=str, default='', choices=['txt', 'image'], help='the split type(ST), from txt or from image folder')
parser.add_argument('--txt', type=str, default='', help='the txt file path')
parser.add_argument('--folder', type=str, default='', help='the folder to store images')
parser.add_argument('--ratio', type = float, default = '0.2', help = 'the split ratio for all datas(default 0.2)')
parser.add_argument('--base', type=str, default='base', help = 'the folder to store base images and txt')
parser.add_argument('--query', type=str, default='query', help = 'the folder to store query images and txt')
if __name__ == "__main__":
params = parser.parse_args()
split_type = params.stype
path_txt = params.txt
path_folder = params.folder
split_ratio = params.ratio
local_base_folder = params.base
local_query_folder = params.query
folder_save_base = join(path_folder, local_base_folder)
folder_save_query = join(path_folder, local_query_folder)
if not exists(folder_save_base):
makedirs(folder_save_base)
else:
shutil.rmtree(folder_save_base, ignore_errors=True)
mkdir(folder_save_base)
if not exists(folder_save_query):
makedirs(folder_save_query)
else:
shutil.rmtree(folder_save_query, ignore_errors=True)
mkdir(folder_save_query)
data_txt = None
if split_type == 'txt':
print("split data from txt file information")
if exists(path_txt):
data_txt = np.loadtxt(path_txt)
length = data_txt.shape[0]
print(length)
x = [i for i in range(length)]
random.shuffle(x)
split_node = (int)(length * split_ratio)
base_x = x[0 : split_node]
query_x = x[split_node: length]
print(len(base_x))
print(len(query_x))
base_data = np.empty([len(base_x), 4], dtype = float);
query_data = np.empty([len(query_x), 4], dtype = float);
for i, index in enumerate(base_x):
timestamp = str((int)(data_txt[index, :][0]))
old_img_file = join(path_folder, timestamp) + '.png'
new_img_file = join(folder_save_base, timestamp) + '.png'
shutil.copyfile(old_img_file, new_img_file)
base_data[i,:] = data_txt[index, :]
for i, index in enumerate(query_x):
timestamp = str((int)(data_txt[index, :][0]))
old_img_file = join(path_folder, timestamp) + '.png'
new_img_file = join(folder_save_query, timestamp) + '.png'
shutil.copyfile(old_img_file, new_img_file)
query_data[i,:] = data_txt[index, :]
base_loc_txt_path = join(folder_save_base, 'loc.txt');
query_loc_txt_path = join(folder_save_query,'loc.txt');
np.savetxt(base_loc_txt_path, base_data, fmt='%f', delimiter=' ')
np.savetxt(query_loc_txt_path, query_data, fmt='%f', delimiter= ' ')
print('Finished')
else:
raise Exception("can not find txt file")
else:
print("split data from image folder")
files_list = []
files_local_list = []
for filename in listdir(path_folder):
if filename.endswith('.jpg') or filename.endswith('.jepg') or filename.endswith('.png'):
print(filename)
files_list.append(join(path_folder, filename))
files_local_list.append(filename)
length = len(files_list)
print(length)
x = [i for i in range(length)]
random.shuffle(x)
split_node = (int)(length * split_ratio)
base_x = x[0 : split_node]
query_x = x[split_node: length]
print(len(base_x))
print(len(query_x))
for i, index in enumerate(base_x):
old_img_file = files_list[index]
new_img_file = join(folder_save_base, files_local_list[index])
shutil.copyfile(old_img_file, new_img_file)
for i, index in enumerate(query_x):
old_img_file = files_list[index]
new_img_file = join(folder_save_query, files_local_list[index])
shutil.copyfile(old_img_file, new_img_file)
print('Finished')
MobileNetVLAD测试
完成所有前期准备工作后就可以进行测试了,直接从原作者github上获取网络模型,载入模型进行测试。以下是测试python代码,测试环境是tensorflow1.14。额外需要的python opencv和faiss库,其中faiss库是facebook开源的高效的相似性搜索库,效率极高,有对应的cpu和pgu版本。
"""
This files aim to detect net_mobile_vlad based on real enviroment
We test the performance based on ground truth info obtained from lidar localization pos
"""
import tensorflow as tf
import faiss
import cv2
import numpy as np
from datetime import datetime
import time
import math
from os.path import join, exists, isfile, realpath, dirname, basename, isdir
from os import mkdir, makedirs, removedirs, remove, chdir, environ, listdir, path, getcwd
import argparse
parser = argparse.ArgumentParser(description='test mobile net vlad on real environment')
parser.add_argument('--eg', type = str, help = 'example to use script')
parser.add_argument('--base', type = str, default = '', help = 'path to the base images folder')
parser.add_argument('--test', type = str, default = '', help = 'path to the test images folder')
parser.add_argument('--weight', type = str, default = '', help = 'path to the weights folder')
parser.add_argument('--size', type = int, default = '4096', help = 'the size of output feature')
parser.add_argument('--thresh_trans', type = float, default = '1.0', help = 'the threshold of trans error(below this will be judged as positive match)')
parser.add_argument('--thresh_rot', type = float, default = '30.0', help = 'the threshold of rot error(below this will be judged as positive match)')
parser.add_argument('--save_result', action = 'store_true', help = 'to save results into txt')
def get_error_theta(theta_1, theta_2):
relative_theta = math.fabs(theta_1 - theta_2)
if(relative_theta > 180):
return 360-relative_theta
else:
return relative_theta
def get_imgfiles_and_locmat(folder_path):
if folder_path == '':
raise Exception("no folder path given")
print("folder path: ", folder_path)
loc_txt = join(folder_path, "loc.txt")
img_path_lists = []
if exists(loc_txt):
data_txt = np.loadtxt(loc_txt)
length = data_txt.shape[0]
for i in range(length):
timestamp = str((int)(data_txt[i, :][0]))
img_path = join(folder_path, timestamp) + '.png'
if exists(img_path):
img_path_lists.append(img_path)
else:
raise Exception("this image does not exist, which should not happen")
return img_path_lists, data_txt
class Whole_base_test_ground_truth():
def __init__(self, mat_base, mat_test):
self.data_theta_base = mat_base[:, 3]
self.data_theta_test = mat_test[:, 3]
self.data_xy_base = mat_base[:, 1:3].astype('float32')
self.data_xy_test = mat_test[:, 1:3].astype('float32')
faiss_index = faiss.IndexFlatL2(2)
faiss_index.add(np.ascontiguousarray(self.data_xy_base))
n_values = [1, 2, 3, 4, 5]
self.distances, self.predictions = faiss_index.search(self.data_xy_test, max(n_values))
def get_positives(self, test_idx):
distance = []
index = []
sub_distance = self.distances[test_idx, :]
sub_corrs_index = self.predictions[test_idx, :]
theta_1 = self.data_theta_test[test_idx]
for i, dist in enumerate(sub_distance):
if dist < 1:
predict_index = sub_corrs_index[i]
theta_2 = self.data_theta_base[predict_index]
delta = get_error_theta(theta_1, theta_2)
if delta < 30:
distance.append(dist)
index.append(predict_index)
return distance, index
if __name__ == "__main__":
params = parser.parse_args()
base_folder = params.base
test_folder = params.test
weight_folder = params.weight
feature_size = params.size
# prerapre datas
base_img_path_lists, base_data_txt = get_imgfiles_and_locmat(base_folder)
test_img_path_lists, test_data_txt = get_imgfiles_and_locmat(test_folder)
base_length = len(base_img_path_lists)
test_legnth = len(test_img_path_lists)
base_features = np.empty((base_length, feature_size))
test_features = np.empty((test_legnth, feature_size))
prepare = Whole_base_test_ground_truth(base_data_txt, test_data_txt)
with tf.Session(graph=tf.Graph()) as sess:
tf.saved_model.loader.load(sess, ['serve'], weight_folder)
graph = tf.get_default_graph
y = sess.graph.get_tensor_by_name('descriptor:0')
x = sess.graph.get_tensor_by_name('image:0')
# extract features from base dataset
for i, name in enumerate(base_img_path_lists):
print("process " , i , "base frame")
src = cv2.imread(name)
src = cv2.cvtColor(src, cv2.COLOR_BGR2GRAY)
src = cv2.resize(src, None, fx=0.5, fy=0.5, interpolation=cv2.INTER_AREA)
input = np.expand_dims(src, axis = 0)
input = np.expand_dims(input, axis = 3)
output = sess.run(y, feed_dict={x: input})
base_features[i, :] = output
# extract features from test dataset
for i, name in enumerate (test_img_path_lists):
print("process " , i , "test frame")
src = cv2.imread(name)
src = cv2.cvtColor(src, cv2.COLOR_BGR2GRAY)
src = cv2.resize(src, None, fx=0.5, fy=0.5, interpolation=cv2.INTER_AREA)
input = np.expand_dims(src, axis = 0)
input = np.expand_dims(input, axis = 3)
output = sess.run(y, feed_dict={x: input})
test_features[i, :] = output
base_features = base_features.astype('float32')
test_features = test_features.astype('float32')
faiss_descriptor_index = faiss.IndexFlatL2(feature_size)
faiss_descriptor_index.add(np.ascontiguousarray(base_features))
n_values = [1, 2, 3, 4, 5]
distances, predictions = faiss_descriptor_index.search(test_features, max(n_values))
recall_test_values = [1, 5, 10, 20]
correct_at_n = np.zeros(len(recall_test_values))
correct_score = np.zeros((3, test_legnth), dtype = np.float)
for qIx, predict in enumerate(predictions):
distance_truth, predict_truth = prepare.get_positives(qIx)
print("==================================================")
print("truth ", predict_truth)
print("predict ", predict)
for i, n in enumerate(recall_test_values):
if np.any(np.in1d(predict[:n], predict_truth)):
correct_at_n[i:] += 1
break
# prapare data save into txt
for qIx, predict in enumerate(predictions):
distance_truth, predict_truth = prepare.get_positives(qIx)
if np.any(np.in1d(predict[0], predict_truth)):
correct_score[0][qIx]= 1
else:
correct_score[0][qIx]= 0
correct_score[2][qIx] = predict[0]
for qIx, distance in enumerate(distances):
correct_score[1][qIx] = distance[0]
recall_at_n = correct_at_n / test_legnth
for i, n in enumerate(recall_test_values):
print("====> Recall@{}: ({}/{}) {:.4f}".format(n, correct_at_n[i], test_legnth , recall_at_n[i]))
# save into txt
PRC_Matches_writePath = datetime.now().strftime('%b%d_%H-%M-%S_') + 'Mobilevlad_Presicion_recall_Data.txt'
np.savetxt(PRC_Matches_writePath, correct_score, fmt='%f', delimiter=',')
测试结果
在测试中,一共获取124帧图像,随机的选择了其中24帧作为test,剩余的100帧作为底库图像,测试召回率,如下所示:
====> Recall@1: (21.0/24) 0.8750
====> Recall@5: (24.0/24) 1.0000
====> Recall@10: (24.0/24) 1.0000
====> Recall@20: (24.0/24) 1.0000在GTX1080上测试单张图片的平均耗时是26ms
可以看出测试结果还是不错,不过这个只是一个小场景下的测试,而且没有涉及到光照变化,因此还需要更多的测试去做。接下来笔者会进行更多更全面的测试,以及深入了解网络的训练过程,相关学习记录也会同步更新在本文中,欢迎交流。

















 698
698

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









