







【读论文05】-时空预测 T-GCN / A3T-GCN
摘要
开门见山,明确主题
滑坡位移监测可以直接反映滑坡的变形过程。通过深度学习使用监控的时间序列数据预测滑坡位移是一种有用的滑坡预警方法。
背景介绍与问题定位
(先描述当前研究现状,通过提出现有方法的局限性,自然引出本研究的必要性。):
目前,现有的预测模型主要集中在单点时间序列位移预测上,不考虑监测点之间的空间关系。
本文解决方法总体引出
为充分考虑位移监测数据的时空关联性,本文提出了两种基于图卷积网络(GCN)的模型对唐角1#滑坡的位移进行时空预测。
具体研究方法层层递进
首先,将滑坡监测系统转化为全连接图(FCG),描绘滑坡监测点之间的空间关系;其次,分别建立了基于 GCN 和 GRU 模型的滑坡位移时间图卷积网络 (T-GCN) 模型和注意力时间图卷积网络 (A3T-GCN) 模型;再次,利用两种模型预测唐角1#滑坡的位移。
结果与结论
结果表明,所建立的时空预测模型对唐角1#滑坡的位移预测效果较好,所提出的A3T-GCN模型达到了最高的预测精度。我们的结论验证了注意力机制在预测滑坡位移方面的有效性。
1.引言
引出研究的重要性(为什么要研究滑坡预测?)
滑坡是全球常见的自然灾害,尤其在中国分布广、破坏严重,因此滑坡预测与预警至关重要。滑坡预警系统可实时监测变形趋势,帮助实施预防措施,降低风险。其中,位移预测是关键环节,有助于理解滑坡变形特性并实现早期预警。近年来,GPS 和 InSAR 等技术的发展提升了数据采集和传输能力,积累了大量监测数据。时间序列位移数据能有效反映滑坡变形趋势,已成为滑坡预测的重要手段。
先描述问题背景,再引出解决方案
滑坡变形具有复杂的非线性动力学特性,受内部地质条件(如地形、地貌、岩土结构)和外部因素(如降雨、地震、人类活动)的共同影响。这些因素相互作用,推动滑坡的演化。深度学习作为一种强大的非线性建模工具,能够提取多层特征,实现对滑坡变形的精准预测,为解决滑坡位移预测等复杂问题提供了新机遇。
归纳总结,先总述后举例(“总-分”结构)
近年来,深度学习模型在滑坡位移预测中取得了显著进展,常用方法包括 CNN、LSTM 和 GRU。研究者已成功应用 LSTM 预测三峡库区百家堡滑坡的位移,并开发了 Bi-LSTM 和 LSTM-FC 以提高对白水河和八子门滑坡的预测精度。此外,GRU 被用于酒仙坪和二道河滑坡的变形预测。相比传统机器学习方法(如 SVM),改进的深度学习模型在预测效率和准确性方面表现更优。
先肯定,再指出不足(“先肯定,后引出问题”结构)
上述所有预测模型都产生了良好的结果。它们大多可以完成基于单点数据的时间序列位移预测。然而,监测点之间的空间相关性被忽视了。因此,难以准确判断滑坡的整体变形趋势,忽视了潜在的威胁。此外,如果逐点进行分析,计算成本将增加。因此,迫切需要提出一种兼顾滑坡位移空间相关性的时空预测模型。
引出TCN背景,再具体举例(“背景-方法-问题”结构)
近年来,随着深度学习的快速发展,不断提出融合图卷积网络(GCN)的时空预测模型,其特点是基于区域相关性的时间预测。例如,开发了一个 T-GCN(时间图卷积网络)模型来考虑城市交通预测的时空关系 。基本概念是用图表表示流量。鉴于滑坡监测系统与图表的相似性,提出了一种将滑坡监测系统视为图表的T-GCN模型来预测滑坡位移。尽管已经获得了令人满意的结果,但由于数据集有限,在分析模型精度方面存在一定的误差。
本文方法
该文开发了两种基于深度学习的时空预测模型。以唐角 1# 滑坡为例,利用这些模型基于监测的时间序列数据预测位移。首先,构建全连通图(FCG)来表示监测点之间的空间关系;其次,提出了一种将 GRU 与 GCN 相结合的 T-GCN 模型和在 T-GCN 模型上增加注意力机制的注意力-TGCN (A3T-GCN) 模型来捕获监测数据的时空相关性。再次,利用上述两种模型预测唐角1#滑坡的位移。最后,采用图卷积网络 (GCN) 的基线模型来比较所提预测方法的准确性。
2. 研究区域
2.1. 唐江 1# 滑坡简介
唐角 1# 滑坡位于中国重庆市万州区长江右岸的斜坡上,如图1所示。该斜坡可归类为侵蚀和沉积山谷的一部分。滑体结构疏松,由第四纪堆积物组成,包括粉砂质粘土和碎石,后者约占 20%。粉质粘土呈黄棕色,呈塑料至硬塑料状态。碎石碎石的岩性主要是泥岩和砂岩。碎石的常见粒径为 10 至 50 厘米。唐角1#滑坡是三峡库区典型的堆积滑坡。
[图 2]显示了唐角 1# 滑坡的详细形态。该滑坡具有明显的边界,体积为 2500 × 104m3,面积为 125 × 104m2,长 1000 m,宽 1250 m。同时,坡向为 354°,坡度范围为 5° 至 25°。值得注意的是,滑坡的主要滑动方向与斜坡方向一致(如图 [2]a 所示)。滑坡的前缘陡峭,坡度约为 22°。它向下延伸到长江河床,两侧是沟壑([图 2]。滑坡的中间部分包含三个平台,坡度从 5° 到 10° 不等。上层平台相对较短,而下部两个平台较长([图 2]。滑坡的后缘是高约 100 m 的陡峭悬崖。它以 50° 到 60° 的坡度逐步下降,并在损坏后露出基岩([图 2]d)。整体来看,滑坡前陡后平缓,一眼望去呈簸箕状,呈阶梯状轮廓。

2.2. 唐角1#滑坡监测位移数据
自 2003 年三峡水库蓄水以来,滑坡各处开始出现不同程度的变形,变形规模扩大到滑坡前部,表现为前部变形大于中后缘。同时,滑坡前部形成多条裂缝,多栋房屋因地表沉降而倒塌。2007 年 3 月建立了唐角 1# 滑坡监测网络,共有 14 个 GPS 监测点。唐角 1# 滑坡监测点的布置如图 [3]所示。
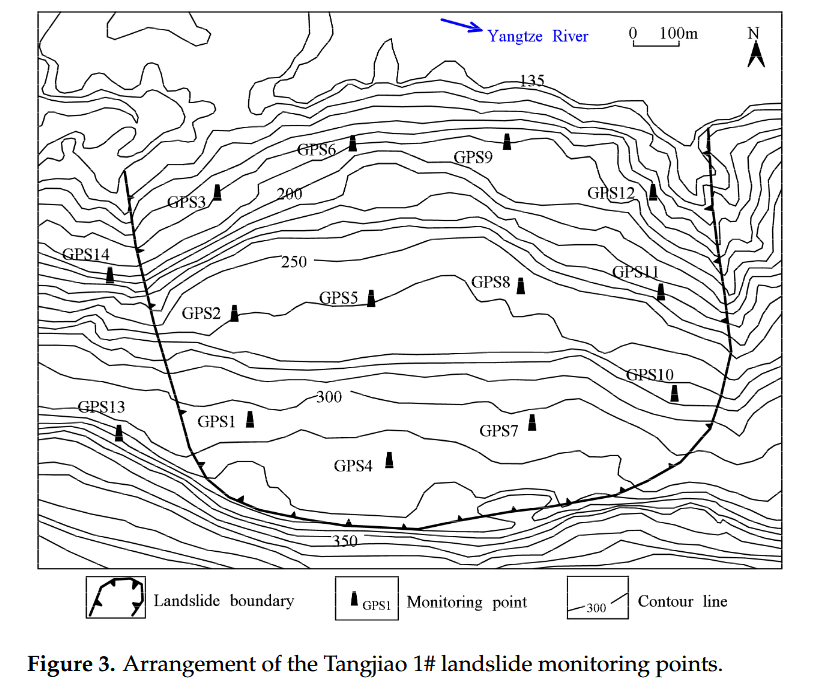
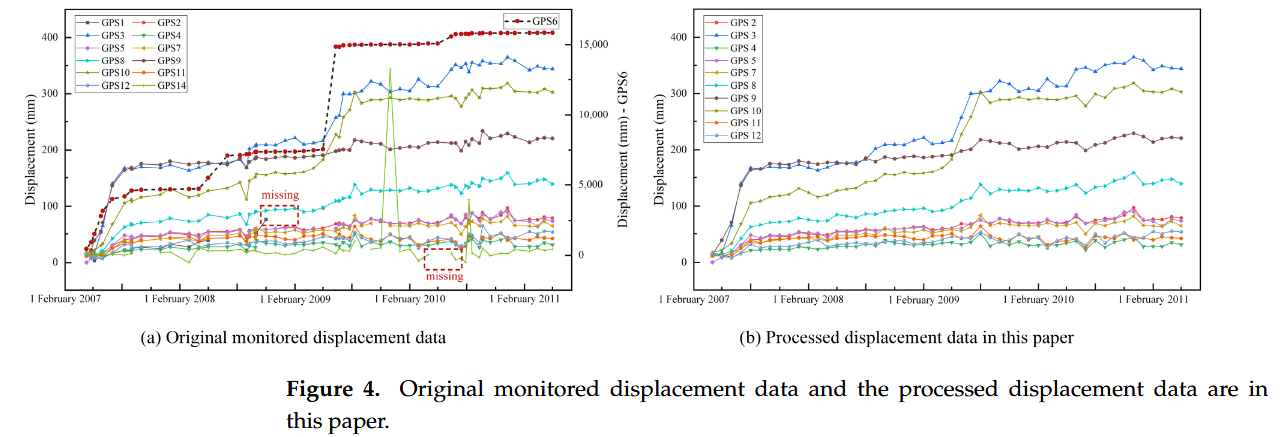
[图 4]a 显示了从 14 个 GPS 监测设备获得的原始位移数据。需要注意的是,由于 GPS13 损坏,因此没有显示 GPS13 处的位移数据,并且没有记录监测数据。GPS14 是位于滑坡体外部的基准点。根据[图 4]a,GPS1 在 2008 年 11 月之后缺乏数据。此外,GPS6 在滑坡地层中的位置发生了变化,导致与其他监测点相比,记录的位移明显更大。因此,在本文中,没有使用 GPS1、GPS6、GPS13 和 GPS14 的数据。相反,选择了其他 10 个监测点,即 GPS2 到 GPS5 和 GPS7 到 GPS12,用于研究。GPS4、GPS7 和 GPS10 位于斜坡的后边缘。GPS2、GPS5、GPS8 和 GPS11 位于斜坡中间,而 GPS3、GPS9 和 GPS12 位于斜坡前部。
由于 GPS 设备记录间隔的变化,有些月份记录 2 次位移,有些月份只记录 1 次,为了创建间隔相等的位移时间序列数据,对于每月记录两次以上的位移数据,选择月初的数据作为当月的位移值。然后,填充缺失值。具体处理程序在 [Section 3.2]中描述。[图 4]b 显示了本文中预处理监测数据的最终选择,数据记录时间为 2007 年 4 月至 2011 年 5 月。
在[图 4]b 中,GPS4、GPS7、GPS2 和 GPS5 的水平位移相对较小。另一方面,GPS3、GPS9 和 GPS8 的水平位移相对较大。可以观察到,滑坡的前部区域,包括监测点 GPS3 和 GPS9,是主要的变形区。该区域驱动滑坡的中间部分滑动,例如 GPS8 点。滑坡右边界后缘监测点GPS10的变形相对较大,而中前缘的监测点GPS11和GPS12的变形相对较小。通过野外调查和数据分析相结合,得出GPS10监测点区域出现局部滑动,而GPS11和GPS12监测点区域无明显滑动。这表明在滑坡的右侧边界没有发生整体滑坡。总体上,滑坡监测点的位移变化与其位置密切相关,监测点之间存在一定的空间相关性。
3. 方法
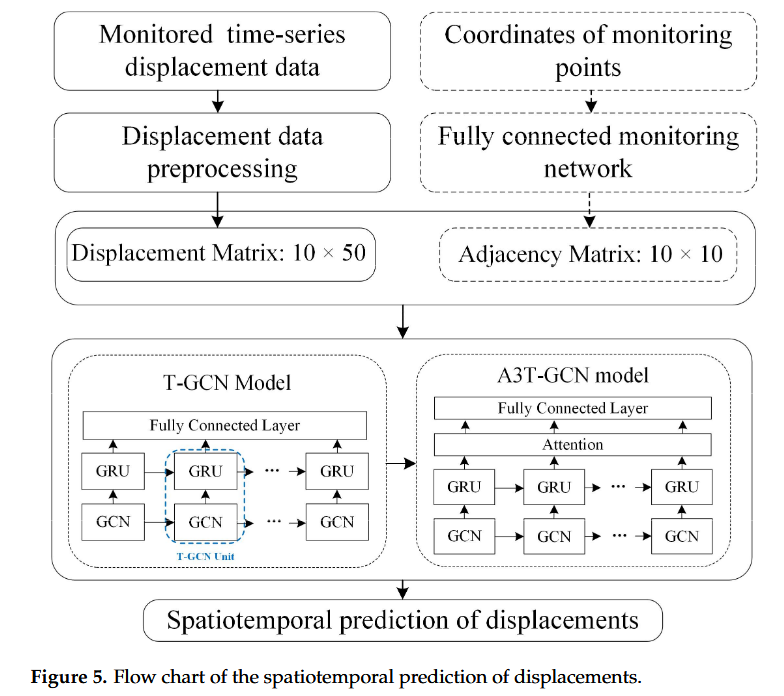
3.1. 概述
本文采用两种模型对唐角 1# 滑坡的时间序列位移进行了预测。[图 5]显示了具体的工作流程。首先,对唐角1#滑坡监测的位移数据进行预处理,形成10 × 50的位移矩阵和10 × 10的邻接矩阵。其次,以上述两个矩阵为输入,构建 T-GCN 和 A3T-GCN 模型来预测唐角 1# 滑坡的位移;数据预处理和模型构建的具体说明如下。
3.2. 时空模型的数据预处理
唐角1#滑坡位移监测时间跨度为2007年4月至2011年5月。在后处理之前,有必要对位移数据进行预处理。这主要由以下四个部分组成。
3.2.1. 位移数据的稳态测试
在进行数据填充和标准化之前,对唐角 1# 滑坡上 10 个监测点的位移进行了平稳性测试。在本文中,采用增强的 Dickey-Fuller 测试 (ADF)来测试平稳性。测试用于确定序列是否具有单位根。在测试过程中,最初假设存在一个单位根,然后计算显著性统计量(p 值)。如果 p 值小于 0.1,则认为序列是平稳的;否则,它不是。[表 1]列出了 10 个监测点的平稳性测试结果。从表中可以看出,所有 p 值都小于 0.1。也就是说,来自监测点的时间序列位移数据是平稳的。

3.2.2. 位移数据填充
2007 年 4 月至 2011 年 5 月对唐角 1# 滑坡进行了监测。记录的时间间隔并不完全相同,并且某些月份的数据缺失。为了充分利用所有位移数据,需要在 10 个监测点对原始数据集进行数据填充以扩展数据。本文采用了基于数据平稳性的线性填充方法。填充后,数据大小为 10 × 50。
3.2.3. 位移数据标准化
采用数据标准化将原始测量值转换为无量纲值,从而将每个指数值置于相同的定量水平。典型的标准化方法包括最小-最大标准化、标准差标准化和非线性归一化等。本文采用 min-max 标准化方法对位移数据进行处理。此方法通过对原始数据执行线性变换来映射 [0,1] 范围内的结果值。在数据填充和标准化之后,滑坡位移数据形成一个无量纲矩阵Xt大小为 10 × 50,用作预测模型的输入。
3.2.4. 位移数据的空间相关性建立
如图 [6] 所示,一个无向的、完全连接的图形𝐺=(𝑉、 E、 𝑊)G=V, E, W构建了基于图的网络,以说明唐角 1# 滑坡上监测点之间的空间关系。这里𝑉={𝑣1,𝑣2,𝑣3,…、𝑣10}V=v1,v2,v3,…,v10代表唐角1#滑坡的十个监测点𝑣1,𝑣2,𝑣3,…、𝑣10v1,v2,v3,…,v10代表 GPS2、GPS3、GPS4、GPS5、GPS7 等监控点GPS12,在[图 6]中缩写为 G2,…, G12。每个监控点分别连接到其他 9 个监控点。E 表示连接监控点的所有 Edge。𝑊∈𝑅10×10 元 W∈R10×10 监测点之间的相关性,并受滑坡监测系统中点的相对位置的影响。
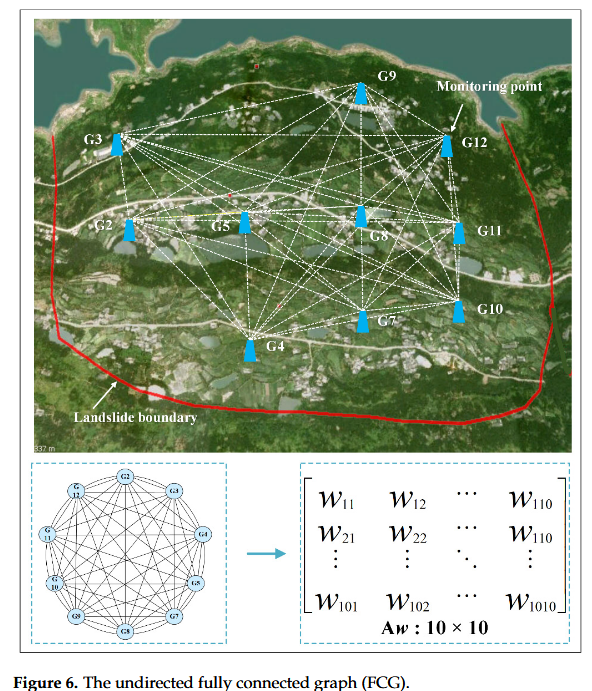
在本文中,无向全连接图的邻接矩阵通过高斯核函数定义,记为 A w A_w Aw,其表达式如下:
其中, w i j w_{ij} wij 表示监测点 v i v_i vi 与 v j v_j vj 之间的空间相关性, dist ( i , j ) \text{dist}(i, j) dist(i,j) 表示两点 v i v_i vi 和 v j v_j vj 之间的距离, σ \sigma σ 为距离的标准差。 w i j w_{ij} wij 的值越大, v i v_i vi 与 v j v_j vj 的空间相关性越高。表2展示了邻接矩阵的权重,该矩阵表征了监测点之间的空间关联关系。
w i j = exp ( − dist ( i , j ) 2 2 σ 2 ) w_{ij} = \exp\left(-\frac{\text{dist}(i, j)^2}{2\sigma^2}\right) wij=exp(−2σ2dist(i,j)2)
A
w
=
[
1
w
12
⋯
w
1
n
w
21
1
⋯
w
2
n
⋮
⋮
⋱
⋮
w
n
1
w
n
2
⋯
1
]
A_w = \begin{bmatrix} 1 & w_{12} & \cdots & w_{1n} \\ w_{21} & 1 & \cdots & w_{2n} \\ \vdots & \vdots & \ddots & \vdots \\ w_{n1} & w_{n2} & \cdots & 1 \end{bmatrix}
Aw=
1w21⋮wn1w121⋮wn2⋯⋯⋱⋯w1nw2n⋮1
3.3. 基于 GCN 的预测模型构建
本文构建了 T-GCN 和 A3T-GCN 模型来预测滑坡位移。A3T-GCN 模型是在 T-GCN 模型的基础上通过增加注意力机制开发的。T-GCN 和 A3T-GCN 模型都基于 GCN。FCG 代表滑坡监测系统的相关性,可以用作模型输入,以实现滑坡位移的时空预测。目前,它们在交通流预测等领域表现出高性能,因此可以作为本文滑坡位移时空预测的基线模型。我们将 [3.2 节]中获得的位移矩阵以 8:2 的比例分为训练集和测试集。构建时空模型后,通过迭代训练集得到最优模型参数,然后对测试集进行预测。
3.3.1. 时空模型构建
(1) T-GCN 系列
T-GCN 模型由两个 GCN 层和一个 GRU 层组成。GCN 层 用于通过执行图卷积运算从邻接矩阵中获得空间相关性。同时,GRU 层用于从位移矩阵中捕获时间相关性。T-GCN 模型的具体结构如图 [7]a 所示。

GCN 是提取非欧几里得结构空间相关性的通用模型。它擅长捕获本地依赖项和保持位移不变。GCN 主要通过图卷积运算从 FCG 获取空间相关性。对于 FCG 中的任何节点,GCN 都可以捕获它与其他节点之间的拓扑关系。在此基础上,GCN 还可以对 FCG 的拓扑和节点上的特征(即位移值)进行编码。
如图所示,在预测滑坡位移时,邻接矩阵
A
w
A_w
Aw和位移矩阵
X
t
X_t
Xt通过两个GCN层提取位移数据的空间关系。图中
n
n
n表示位移数据的总数,在本文中为50。GCN层中的FCG卷积数量将在训练过程中确定,详见第3.3.2节。图卷积过程如公式(2)所示,其中
A
^
=
A
w
+
I
\hat{A} = A_w + I
A^=Aw+I表示具有自连接结构的矩阵;
I
I
I是单位矩阵;
W
0
W_0
W0和
W
1
W_1
W1表示前两层的权重矩阵;softmax和ReLU是非线性激活函数。
f
(
X
t
,
A
w
)
=
softmax
(
A
^
ReLU
(
A
^
X
t
W
0
)
W
1
)
f(X_t,A_w) = \text{softmax}\left(\hat{A}\ \text{ReLU}(\hat{A}X_tW_0)W_1\right)
f(Xt,Aw)=softmax(A^ ReLU(A^XtW0)W1)
其中:
•
A
^
=
A
w
+
I
\hat{A} = A_w + I
A^=Aw+I 为带自连接的邻接矩阵
•
X
t
X_t
Xt 为位移特征矩阵
•
W
0
W_0
W0,
W
1
W_1
W1 分别为第一、二层可训练权重矩阵
•
ReLU
\text{ReLU}
ReLU 和
softmax
\text{softmax}
softmax 为非线性激活函数
GRU 是循环神经网络(RNN)的一种变体,常用于分析和自适应捕捉不同时间尺度上的依赖关系。GRU 可以通过控制信息流通过门控单元(更新门 z t z_t zt和重置门 r t r_t rt)来预测当前时间步,如图 7a 所示。重置门 r t r_t rt决定如何将新输入信息与之前的记忆 h t − 1 h_{t-1} ht−1结合起来,而更新门 z t z_t zt决定之前记忆的有效程度。一般来说,GRU 需要训练的参数较少,训练时间也较短。
如图7所示,在预测滑坡位移时,位移矩阵 X t ′ X'_t Xt′进入GRU层以捕捉时间相关性,预测的位移值从全连接层输出。此处,图卷积替代了GRU中的矩阵乘法。具体计算过程如公式(3)所示:
其中:
•
f
(
X
t
,
A
w
)
f(X_t,A_w)
f(Xt,Aw)表示时间步
t
t
t的输入空间特征
•
W
W
W和
b
b
b分别表示训练期间的权重和偏差
•
h
t
−
1
h_{t-1}
ht−1和
h
t
h_t
ht分别表示时间步
t
−
1
t-1
t−1和
t
t
t的隐藏状态
•
u
t
u_t
ut和
r
t
r_t
rt分别表示时间步
t
t
t的更新门和重置门
•
c
t
c_t
ct表示时间步
t
t
t的记忆内容
•
tanh
\tanh
tanh是双曲正切函数,将隐藏状态值保持在
[
−
1
,
1
]
[-1,1]
[−1,1]范围内
具体公式包括:
遗忘门:
u
t
=
σ
(
W
u
[
f
(
X
t
,
A
w
)
,
h
t
−
1
]
+
b
u
)
u_t = \sigma(W_u[f(X_t,A_w),h_{t-1}] + b_u)
ut=σ(Wu[f(Xt,Aw),ht−1]+bu)
重置门:
r
t
=
σ
(
W
r
[
f
(
X
t
,
A
w
)
,
h
t
−
1
]
+
b
r
)
r_t = \sigma(W_r[f(X_t,A_w),h_{t-1}] + b_r)
rt=σ(Wr[f(Xt,Aw),ht−1]+br)
记忆内容:
c
t
=
tanh
(
W
c
[
f
(
X
t
,
A
w
)
,
(
r
t
∗
h
t
−
1
)
]
+
b
c
)
c_t = \tanh(W_c[f(X_t,A_w),(r_t * h_{t-1})] + b_c)
ct=tanh(Wc[f(Xt,Aw),(rt∗ht−1)]+bc)
隐藏状态:
h
t
=
u
t
∗
h
t
−
1
+
(
1
−
u
t
)
∗
c
t
h_t = u_t * h_{t-1} + (1 - u_t) * c_t
ht=ut∗ht−1+(1−ut)∗ct
(2)A3T-GCN模型
A3T-GCN模型通过将注意力机制嵌入T-GCN模型构建而成。该模型由
G
C
N
GCN
GCN、
G
R
U
GRU
GRU和
A
t
t
e
n
t
i
o
n
Attention
Attention三部分组成,其结构如图7b所示。
预测流程:
- 位移矩阵 X i X_i Xi通过 G C N GCN GCN转换为具有空间特征的矩阵 X f X_f Xf
- X f X_f Xf输入 G R U GRU GRU获取隐藏状态值序列 ( h t − n , . . . , h t − 1 , h t ) (h_{t-n},...,h_{t-1},h_t) (ht−n,...,ht−1,ht)
- 隐藏状态值输入注意力层捕捉位移全局变化趋势
- 最终预测值从全连接层输出
注意力模块设计:
(a) 从
G
R
U
GRU
GRU获取不同时刻的隐藏状态
H
=
(
h
t
−
n
,
.
.
.
,
h
t
−
1
,
h
t
)
H=(h_{t-n},...,h_{t-1},h_t)
H=(ht−n,...,ht−1,ht)
(b) 通过
s
o
f
t
m
a
x
softmax
softmax计算注意力分数
(
α
t
−
n
,
.
.
.
,
α
t
−
1
,
α
t
)
(α_{t-n},...,α_{t-1},α_t)
(αt−n,...,αt−1,αt),确保输出值在
[
0
,
1
]
[0,1]
[0,1]区间且和为1
© 通过注意力函数计算描述全局位移趋势的向量
(
c
t
−
n
,
.
.
.
,
c
t
−
1
,
c
t
)
(c_{t-n},...,c_{t-1},c_t)
(ct−n,...,ct−1,ct)
(d) 基于该向量的加权平均输出预测位移值
参数计算公式:
e
i
=
W
(
2
)
tanh
(
W
(
1
)
h
i
+
b
(
1
)
)
+
b
(
2
)
e_i = W^{(2)}\tanh(W^{(1)}h_i + b^{(1)}) + b^{(2)}
ei=W(2)tanh(W(1)hi+b(1))+b(2)
α
i
=
exp
(
e
i
)
∑
k
=
t
−
n
t
exp
(
e
k
)
α_i = \frac{\exp(e_i)}{\sum_{k=t-n}^t \exp(e_k)}
αi=∑k=t−ntexp(ek)exp(ei)
c
t
=
∑
i
=
t
−
n
t
α
i
h
i
c_t = \sum_{i=t-n}^t α_i h_i
ct=i=t−n∑tαihi
其中:
•
W
(
1
)
W^{(1)}
W(1)、
W
(
2
)
W^{(2)}
W(2)为第一、二层权重
•
b
(
1
)
b^{(1)}
b(1)、
b
(
2
)
b^{(2)}
b(2)为对应偏置项
3.3.2. 时空模型训练
本文监测的位移数据总数为 50 个,监测周期跨度为 2007 年 4 月至 2011 年 5 月。我们利用滑动窗口法将窗口大小为5的位移数据,从而形成大小为5 × 10 × 44 的训练集和大小为5 × 10 × 6 的测试集。
对于训练数据,我们采用直接策略来形成用于训练的输入数据。直接策略在直接多个步骤中映射大小为 5 的每个位移数组。前四个数据点用作预测输入,而最后一个数据点用作标签。具体方法的公式如公式 (5) 所示。
在 T-GCN 和 A3T-GCN 模型的训练过程中,选择了三个超参数,即学习率、批量大小和 epoch。为了实现最佳性能,对这些超参数进行了三组实验。学习率的值为 0.1、0.01 和 0.001;对于批量大小,它们是 200、100 和 50;对于 epoch,它们是 2000、1000 和 500。经过 27 次调整参数测试后,确定对于位移预测,学习率为 0.01,batch size 为 100,epoch 为 1000。此外,我们将 GCN 设置为 128 个隐藏单元,并使用 ReLU 作为 GCN 层中的激活函数。
3.3.3. 时空模型预测
基于最优T-GCN模型和[3.2.2节]训练的A3T-GCN模型,预测了2010年12月至2011年5月唐角1#滑坡的位移。预测结果在 [Section 4.1]中有详细说明。
4. 结果
4.1. 预测结果
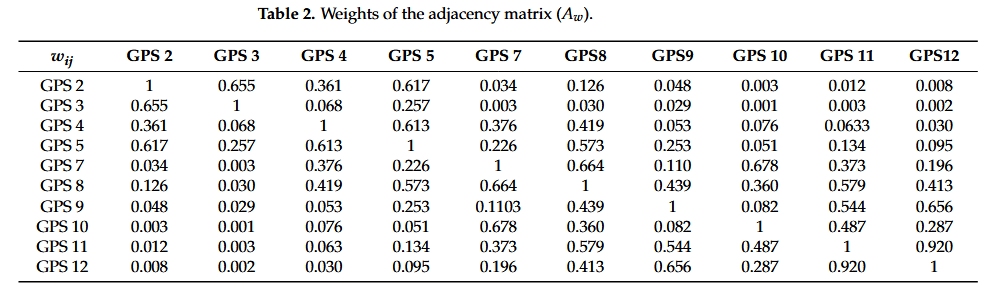
采用两种时空模型预测 2010 年 12 月至 2011 年 5 月期间 10 个监测点的位移。[图 8]中的六个子图分别显示了 2010 年 12 月、2011 年 1 月、2011 年 2 月、2011 年 3 月、2011 年 4 月和 2011 年 5 月在十个监测点的 T-GCN 和 A3T-GCN 的预测位移。这些预测的位移与现场 GPS 设备测量的真实值进行比较。
从[图 8]中可以看出,T-GCN 模型和 A3T-GCN 模型都表现出出色的拟合。所有监测点的预测值都非常接近不同时间的真实值。这些结果表明,所提出的时空预测模型具有很强的位移预测能力。
4.2. 准确率分析
4.2.1. 评估指标
为了评估模型性能,采用深度学习中常用的三种评估指标进行准确性分析 。这些误差包括平均绝对误差 (MAE)、平均绝对百分比误差 (MAPE) 和均方根误差 (RMSE)。MAE 是预测值与真实值之间的绝对差值的平均值。MAPE 是预测值与真实值之间的平均绝对差值除以真实值的百分比。RMSE 是 MSE 的平方根,反映预测值与真实值之间的偏差。MAE、MAPE 或 RMSE 越小,模型误差越小,模型预测效果越好。这三个指标的计算方法如下文 (6) 所示。其中,n 等于所有测试集的个数,𝑦′𝑡 yt′ 是预测值,而𝑦𝑡yt是 true 值。
4.2.2. 分析结果
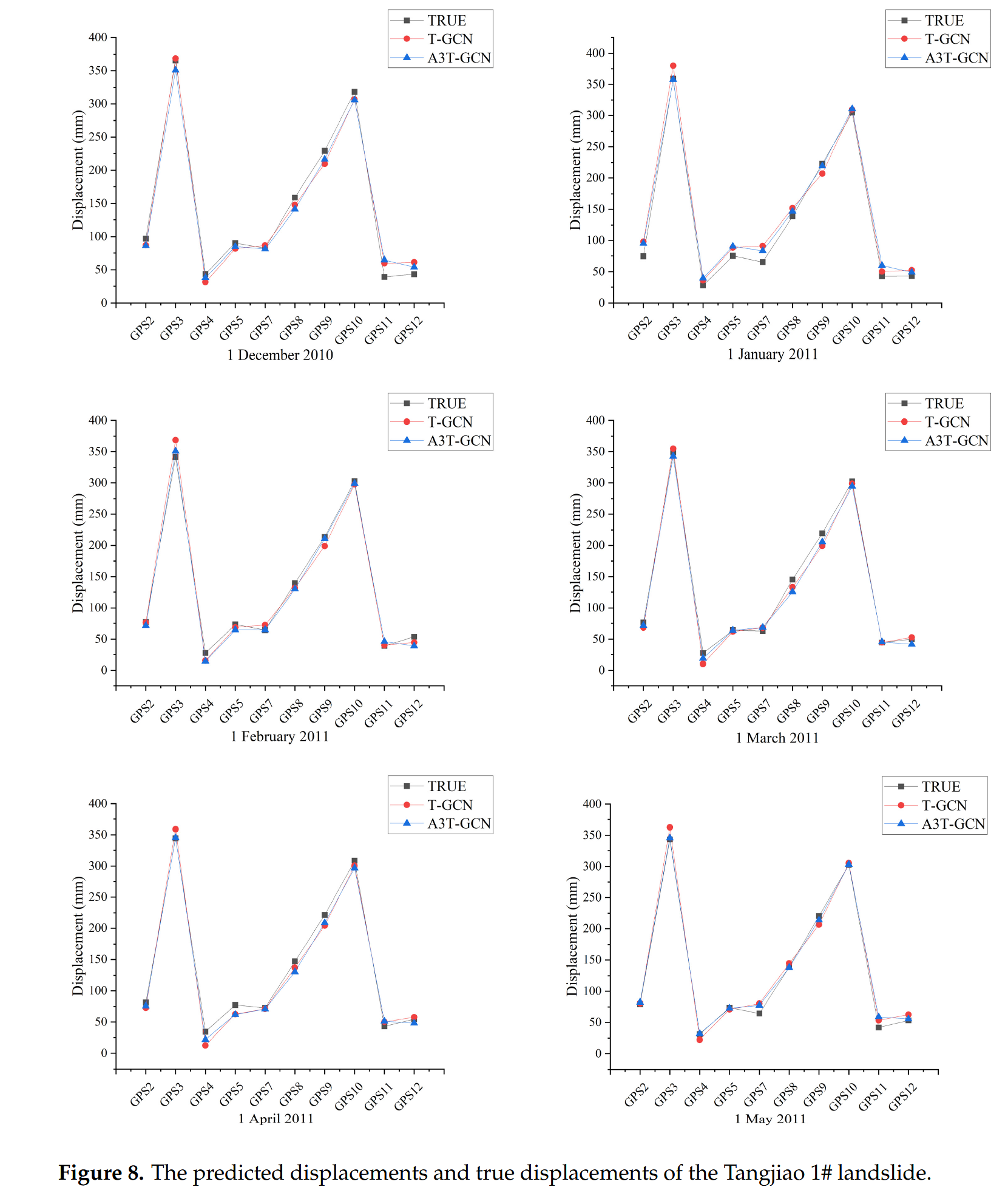
本文将注意力机制纳入 T-GCN 模型,建立 A3T-GCN 模型。为了进行更深入的比较研究,还构建了基于单点监测的 GRU 预测模型。由于单点模型不考虑空间相关性,因此在进行预测时,有必要对十组位移数据中的每组分别进行建模。为了促进更好的比较研究,设置了相同的超参数。具体而言,批处理大小设置为 100,epoch为 1000。[表 4]~[表 6]列出了三种模型的预测精度,其中粗体表示最佳精度值。
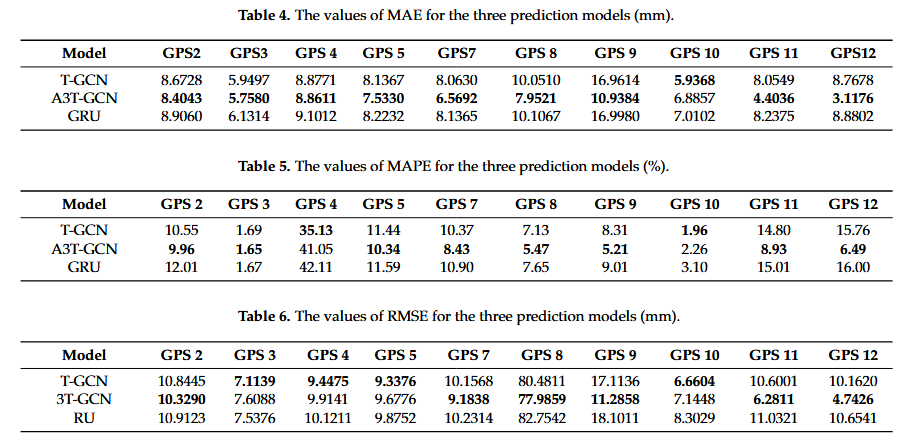
结果表明:(1)总体上,T-GCN和A3T-GCN模型对唐角1#滑坡位移的预测精度高于GRU模型。(2) 当以 MAE、MAPE 和 RMSE 作为评价标准时,A3T-GCN 模型的预测精度高于 T-GCN 模型。这表明集成注意力机制可以进一步增强预测模型的性能。
从以上结果可以看出,本文提出的唐角1#滑坡A3T-GCN模型在所有模型中表现出最佳性能。A3T-GCN 模型和 T-GCN 模型可以通过将所有监测点作为一个整体来预测时间序列位移数据。它们统一处理所有监控数据,而不是单独对来自每个监控点的数据进行建模。同时,他们预测的位移曲线接近现实,这表明时空预测模型是有效的。
5. 讨论
5.1. 监控点位置变化对模型的影响
本文采用深度学习方法对唐角1#滑坡的位移进行预测。预测方法利用 FCG 连接所有监控点进行预测。该方法避免了每个监测点参数的重复调整,提高了滑坡预测的效率。同时,滑坡监测系统是一个整体,监测点之间存在一定的空间关系。时空预测方法可以更好地揭示整个监测系统的位移变化。
该文利用邻接矩阵 Aw 来表示监测点之间的相对距离。即监测点的地理位置信息决定了模型的空间关系。在滑坡变形过程中,监测点的位置可能会发生变化,从而降低模型精度 。然而,在我们的例子中,GPS3、GPS9 和 GPS10 的位置已经发生了一定程度的变化,但 T-GCN 和 A3T-GCN 模型的精度仍然高于 GRU。推测,本文在构建FCG时,已经移除了变形过大的监测点GPS6。同时,其余监测点的位置变化相对较小,对邻接矩阵影响较小,对预测模型精度的影响有限。下一步将收集更多案例,分析监测点位置变化对模型的影响。
5.2. 注意力机制对模型准确性的影响
滑坡变形受地形、地貌、地层结构、降雨和地震等许多因素的影响。它们对滑坡的影响反映在监测的位移数据中。这导致了对未来特定时间的位移的预测。早期不同时间的位移对预测的影响会有所不同。T-GCN 模型包括 GCN 和 GRU 神经网络。GRU 可以捕获滑坡位移的时间相关性,但它没有经过训练来关注历史时间序列数据的重要部分。将注意力机制集成到 GRU 中后,模型可以自动学习隐藏在数据中的重要信息,从而增强模型的预测性能。
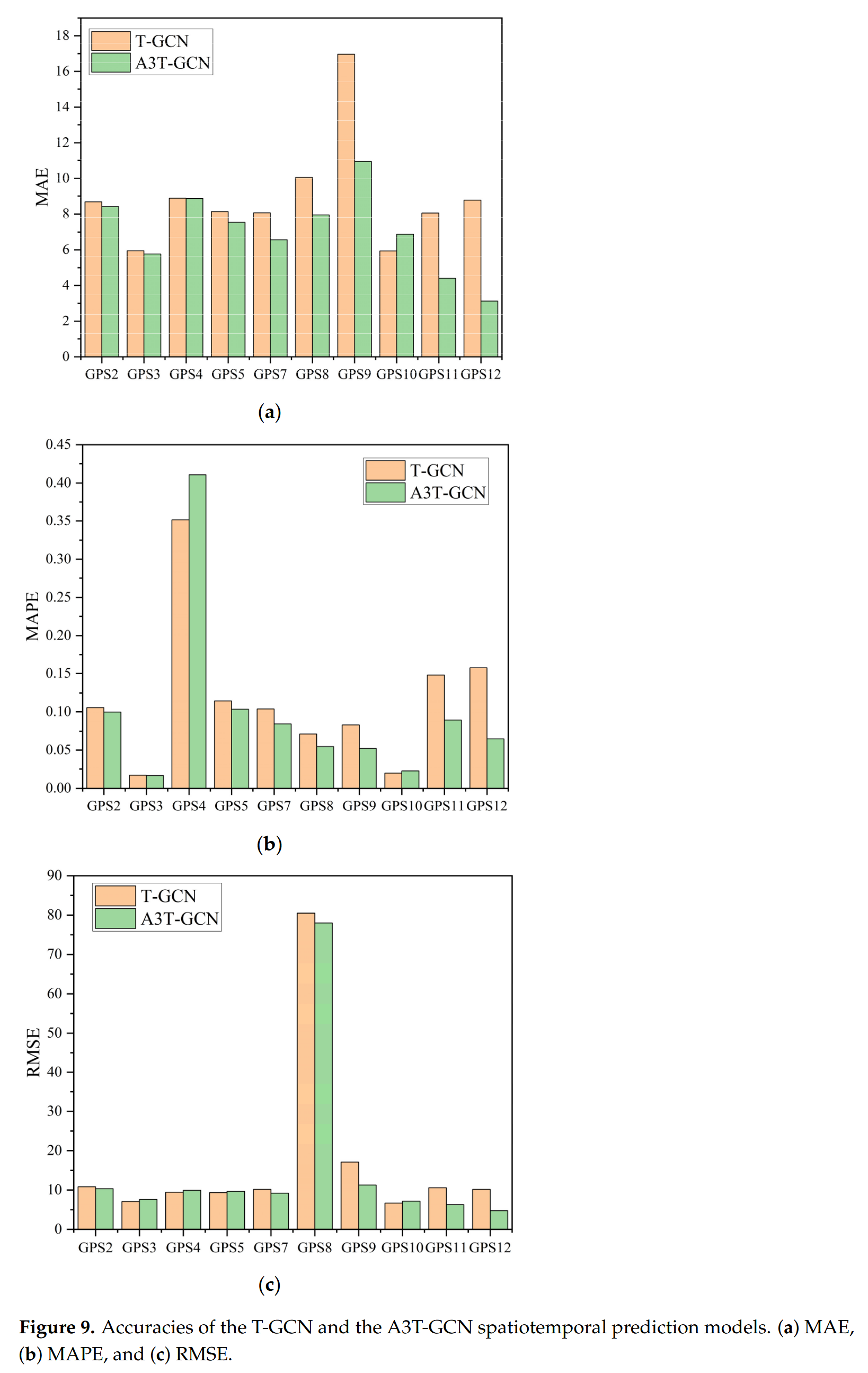
如图 [9] 所示,通过对比 T-GCN 和 A3T-GCN 两个时空预测模型在唐角 1# 滑坡上 10 个监测点的预测结果,可以清楚地观察到,无论采用 MAE、MAPE 还是 RMSE 作为评价指标,总体上,A3T-GCN 模型在大多数监测点的预测精度较高(评价指标值越小表示精度越高)。这表明将注意力机制集成到 T-GCN 中可以提高预测精度。
5.3. 展望和未来工作
本文采用两种深度学习模型对唐角 1# 滑坡的位移进行预测。尽管如此,未来还需要进行几项研究。这些包括:
(1) 滑坡位移受多种因素影响。未来,在时空预测滑坡位移时,将考虑降雨量、库水位波动、地层岩性等因素作为模型的输入。
(2) 滑坡位移预测主要基于时间序列数据。有时,数据收集可能成本高昂或困难,导致获得的数据量有限。对于有限的数据,通常需要特定的解决方案来扩展它。例如,可以使用数据增强技术。数据增强是指扩展数据或增强小样本集的功能。下一步,将采用各种数据增强方法来扩展数据集。随后,新数据集将应用于滑坡等地质灾害的位移预测。
6. 结论
本文以唐角1#滑坡为例,基于图卷积网络构建了两个滑坡位移预测时空模型。首先,将监测系统转化为全连接图(FCG)并表示为邻接矩阵;其次,建立基于图卷积网络的T-GCN和A3T-GCN时空预测模型,预测唐角1#滑坡的位移;再次,利用MAE、MAPE和RMSE分析模型的预测性能,并与GRU模型进行比较。最后,讨论了所提模型的有效性。唐角1#滑坡位移预测结果表明:
(1) 在预测精度方面,时空预测模型优于单点预测模型,证明考虑监测点之间的空间相关性可以提高滑坡位移预测的精度。
(2) 在大多数情况下,与注意力机制相结合的 A3T-GCN 模型比 T-GCN 模型具有更高的预测精度。这表明,注意力机制有助于关注对输入位移序列的当前输出更关键的局部信息,从而实现准确的预测。
受限于唐角1#滑坡监测数据,本文仅实现较短时间尺度的预测。未来将结合更多的滑坡实例实现长期预测,滑坡位移的时空预测将考虑更多影响因素。
[1] Sun Y, Liu T, Zhang C, et al. Spatiotemporal prediction of landslide displacement using graph convolutional network-based models: a case study of the tangjiao 1# landslide in chongqing, china[J]. Applied Sciences, 2024, 14(20): 9288.

















 2468
2468

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









