








 超级会员免费看
超级会员免费看
文章大纲
简介
本子目录主要是针对,在大数据环境下进行机器学习的相关内容介绍子目录,总体内容和目录还是以 《大数据处理实践探索》 为准, 本子目录的内容主要以spark 尤其是pyspark 进行机器学习为主线,围绕机器学习,深度学习全流程进行介绍。
github 地址: big_data_repo
基于spark 的大数据机器学习 最佳实践
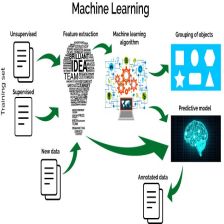
机器学习强调三个关键词:算法、经验、性能,其处理过程如上图所示。在数据的基础上,通过算法构建出模型并对模型进行评估。评估的性能如果达到要求,就用该模型来测试其他的数据;如果达不到要求,就要调整算法来重新建立模型,再次进行评估。如此循环往复,最终获得满意的经验来处理其他的数据。机器学习技术和方法已经被成功应用到多个领域,比如个性推荐系统,金融反欺诈,语音识别,自然语言处理和机器翻译,模式识别,智能控制等。
在大数据上进行机器学习,需要处理全量数据并进行大量的迭代计算,这要求机器学习平台具备强大的处理能力。Spark 立足于内存计算,天然的适应于迭代式计算。即便如此,对于普通开发者来说,实现一个分布式机器学习算法仍然是一件极具挑战的事情。
幸运的是,Spark提供了一个基于海量数据的机器学习库,它提供了常用机器学习算法的分布式实现,开发者只需要有 Spark 基础并且了解机器学习算法的原理,以及方法相关参数的含义,就可以轻松的通过调用相应的 API 来实现基于海量数据的机器学习过程。其次,Spark-Shell的即席查询也是一个关键。算法工程师可以边写代码边运行,边看结果。spark提供的各种高效的工具正使得机器学习过程更加直观便捷。比如通过sample函数,可以非常方便的进行抽样。当然,Spark发展到后面,拥有了实时批计算,批处理,算法库,SQL、流计算等模块等,基本可以看做是全平台的系统。把机器学习作为一个模块加入到Spark中,也是大势所趋。
MLlib是Spark的机器学习(Machine Learning)库,旨在简化机器学习的工程实践工作,并方便扩展到更大规模。MLlib由一些通用的学习算法和工具组成,包括分类、回归、聚类、协同过滤、降维等,同时还包括底层的优化原语和高层的管道API。具体来说,其主要包括以下几方面的内容:
算法工具:常用的学习算法,如分类、回归、聚类和协同过滤;
特征化工具:特征提取、转化、降维,和选择工具;
管道(Pipeline):用于构建、评估和调整机器学习管道的工具;
持久性:保存和加载算法,模型和管道;
实用工具:线性代数,统计,数据处理等工具。
EDA
还有比pandas profiling 更好使的python EDA 工具吗?
经典Titanic 数据集的探索性数据分析报告:
https://pandas-profiling.github.io/pandas-profiling/examples/master/titanic/titanic_report.html
特征工程
特征工程的主要目的是放大数据的价值。有这么一句话在业界广泛流传:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已
传统机器学习算法
使用spark MLlib进行机器学习,参照经典图书《learning spark 2.0》 翻译以及添加上我自己的理解而成,在本章中,我们将让您开始准备使用pyspark MLlib构建ML模型,MLlib是Apache Spark中的实际机器学习库。 我们将首先简要介绍机器学习,然后涵盖分布式ML和功能工程师的最佳实践规模(如果您已经熟悉机器学习的基本原理,您可以直接跳到设计机器学习管道)。通过这里介绍的简短代码片段和本章代码与数据集见参考文献,您将学习如何构建基本的ML模型并使用MLlib。
WSL 是 Windows Subsystem for Linux windows下的linux子系统,由于直接在windows 上安装pyspark 跑很多基于linux 的库的机器学习库很费劲,有什么办法是省时省力并且占用资源少的方式呢?相比虚拟机动辄8g 左右的内存占用量,wsl 当然是一个非常好的选择。
分类
Spark 中常见的 3 种分类模型:线性模型、决策树和朴素贝叶斯模型。线性模型相对简单,而且相对容易扩展到非常大的数据集;
决策树是一种强大的非线性技术,训练过程计算量大并且较难扩展(幸运的是,MLlib 会替我们考虑扩展性的问题),但是在很多情况下性能很好;朴素贝叶斯模型简单、易训练,并且具有高效和并行的优点(实际中,模型训练只需要遍历整个数据集一次)。
当采用合适的特征工程时,这些模型在很多应用中都能达到不错的性能。
朴素贝叶斯模型还可以作为一个很好的模型测试基准,用于度量其他模型的性能。
目前,Spark 的 MLlib 库提供了基于线性模型、决策树和朴素贝叶斯的二分类模型,以及基
于决策树和朴素贝叶斯的多类别分类模型。
聚类
考虑数据没有标注的情况,具体模型称作无监督学习(unsupervised learning),
即模型训练过程中没有被目标标签监督。实际应用中,无监督的例子非常常见,原因是在许多真实场景中,标注数据的获取非常困难,或者代价非常大(比如,人工为分类模型标注训练数据)。
但是,我们仍然想要从数据中学习基本的结构用来做预测。这就是无监督学习方法发挥作用的情形。通常无监督学习和监督模型会相结合,比如使用无监督技术为监督模型生成新的输入特征来作为输入。
在很多情况下,聚类(clustering)模型等价于分类模型的无监督形式。用分类的方法,我们
可以学习分类模型,预测给定训练样本属于哪个类别。这个模型本质上就是一系列特征到类别的映射。在聚类中,我们对数据进行分割,这样每个数据样本就会属于某个部分,称为类簇(cluster)。类簇相当于类别,只不过不知道真实的类别。
聚类模型有很多种,从简单到复杂都有。Spark MLlib 库目前提供了 K-均值聚类算法,这是
最简单的聚类算法之一,但也非常有效,而简单通常意味着相对容易理解和扩展。
- 大数据聚类算法综述
- Spark 聚类算法 ---- kmeans 简介,源码分析
- Spark 聚类算法 ---- kmeans 实例 解析(pySpark + scala)
- Spark 聚类算法 ----聚类评估
回归
异常检测
深度学习算法
模型融合
基于大数据的机器学习算法实践
基于PySpark2.x or 3.0 快速进行机器学习系列
- 简介
- 设计机器学习pipeline
MLlib对机器学习算法的API进行了标准化,使得将多种算法合并成一个pipeline或工作流变得更加容易。Pipeline的概念主要是受scikit-learn启发。pipeline 又叫做管道或者工作流。
- 2.1 设计机器学习管道-- 数据加载与拆分
- 2.2 设计机器学习管道 – 特征生成与线性回归
- 2.3 设计机器学习管道 – 模型评估与管道构建
- 2.4 设计机器学习管道 – 模型评估
- 2.5 设计机器学习管道 – 保存和加载模型
- 超参调优
为了进行超参数调优,我们一般会采用网格搜索,随机搜索,贝叶斯优化等算法。在spark 中如何进行超参数调优与性能优化呢?
- 算法封装与扩展
spark 提供了非常多的机器学习算法,但是常用xgboost ,DBscan 等效果较好的算法如何封装到spark 的pipeline 中呢,本教程文章提供了一个指导性方法。
基于PySpark 进行机器学习 – 实战案例
- 使用pyspark 进行kaggle比赛Give me some credit数据集的建模与分析(1. 数据准备与EDA)
- 使用pyspark 进行kaggle比赛Give me some credit数据集的建模与分析(2.1 数据清洗)
- 使用pyspark 进行kaggle比赛Give me some credit数据集的建模与分析(2.2 特征工程)
- 使用pyspark 进行kaggle比赛Give me some credit数据集的建模与分析(3. 随机森林进行二分类)
- 使用pyspark 进行kaggle比赛Give me some credit数据集的建模与分析(4. 逻辑回归 Logistic Regression进行二分类)
基于scala 的机器学习案例 系列
spark dataframe 数据 转化为 json 或者自定义格式的字符串
AutoML
21世纪是一个信息的时代,各行各业都面临着一个同样的问题,那就是需要从大量的信息中筛选出有用的信息并将其转化为价值。
随着机器学习2.0的提出,自动化成为了未来机器学习发展的一个方向。各行各业都涉及机器学习,机器学习已经融入我们生活的方方面面,比如金融、教育、医疗、信息产业等领域。
AutoML带来的不仅仅是自动化的算法选择、超参数优化和神经网络架构搜索,它还涉及机器学习过程的每一步。从数据预处理方面,如数据转换、数据校验、数据分割,到模型方面,如超参数优化、模型选择、集成学习、自动化特征工程等,都可以通过AutoML来完成,从而减少算法工程师的工作量,使他们的工作效率得到进一步提升。
AutoML完全改变了整个机器学习领域的游戏规则,因为对于许多应用程序,不需要专业技能和知识。许多公司只需要深度网络来完成更简单的任务,例如图像分类。那么他们并不需要雇用一些人工智能专家,他们只需要能够数据组织好,然后交由AutoML来完成即可。
实践案例:
参考文献与学习路径
spark 代码大全:
- https://sparkbyexamples.com
Spark2.1.0入门:Spark MLlib介绍(Python版)
- http://dblab.xmu.edu.cn/blog/1762-2/
子雨大数据之Spark入门教程(Scala版):
- http://dblab.xmu.edu.cn/blog/spark/
spark 官方ml 文档:
- https://spark.apache.org/docs/latest/ml-guide.html
官方书籍:
- 《learning spark 2.0 第10 章》
其他本人博客:
















 13万+
13万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











