







原文链接:
https://aclanthology.org/2022.findings-acl.9.pdf
ACL 2023
介绍
基于span的方法是将NER看作是一个two-stage任务——span的提取和分类,虽然能够很好的解决嵌套实体的问题,但是该方法存在以下问题:1)误差传递;2)长实体识别困难;3)需要大规模标注数据集。
因此作者提出Extract-Select的方法,使用了一种span selection 框架,引入了生成对抗训练,来解决以上问题,能够将不同类别的实体分别进行提取,从而避免误差传递。
方法
作者提出的整体框架如下图示,Exctract-Select由一个(extractor)提取器和一个判别器组成。给定输入序列X和实体标记y*(可以理解为实体类别的解释),提取器通过混合选择策略来提取候选span并计算其表征![]() ,然后将rc送入到判别器中计算属于该类别的分数
,然后将rc送入到判别器中计算属于该类别的分数![]() ,最后通过多次的迭代训练,提取器便能提取出每个类别的所有实体。
,最后通过多次的迭代训练,提取器便能提取出每个类别的所有实体。
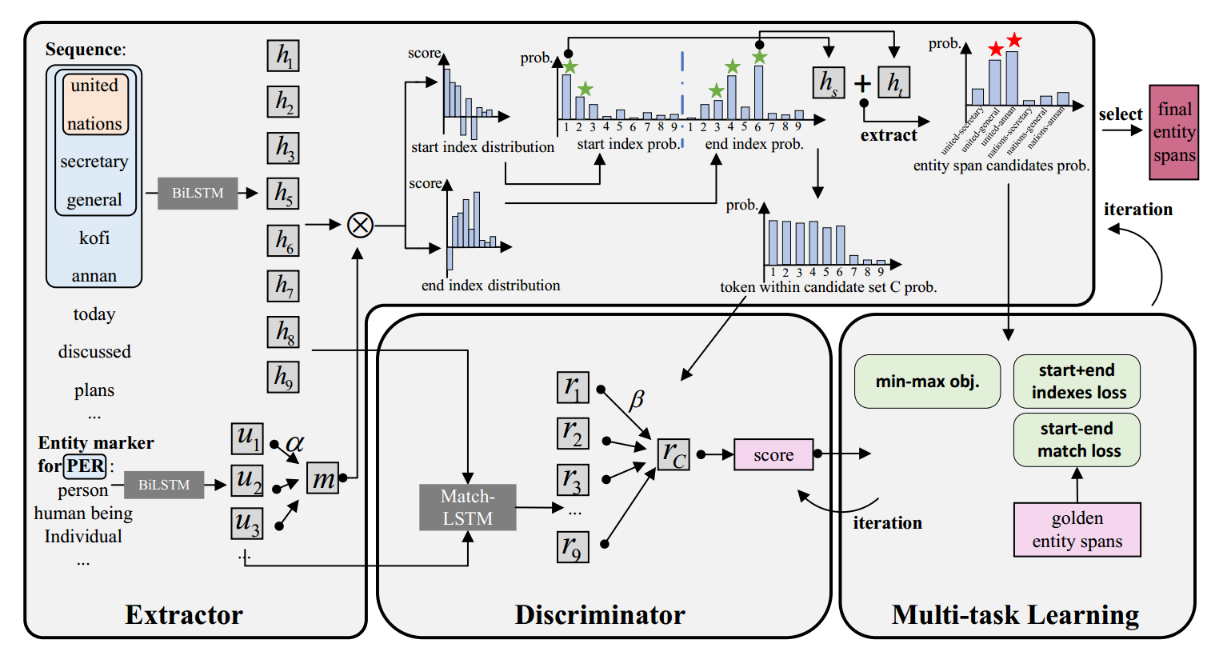
Extractor
sequence embedding
输入序列X的embedding由character embedding、word embedding(来自一个BiLSTM)、contextualized word embedding(使用目标token前或后的句子来获得)和part-of-speech embedding进行concat,然后送入一个BiLSTM获得最终的token表征:
![]()
Entity marker representation
作者认为实体类别对于extractor来说很重要,因此作者将对每个类别设计一个marker,即对实体细粒度的解释,用于extractor的输入。对于每个类别,作者都用“关键字”和“同义词”的方式来进行marker,就像图中“PER”这个类别,使用了“person”"human being" "Individual"来进行mark。
将这些词进行concat送入BiLSTM来得到
(|y*|表示marker的长度),然后使用自注意力机制来融合信息:

Hybrid selection
该部分中,
1)使用以下公式来计算每个token是实体边界得可能性:
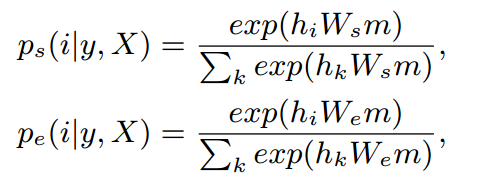
2)分别选取对应下标,计算对应span属于实体span候选集C的可能性,将大于阈值的span加入到候选集C中(这里公式表达的是选择可能性最大的下标,但是按作者的示意图是选择大于某个阈值的下标?):

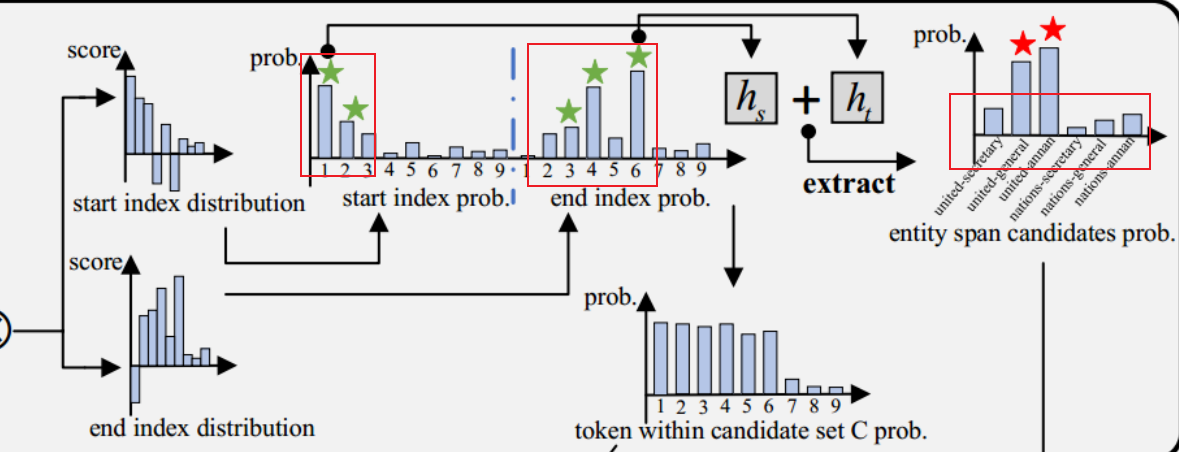
3)计算第i个token属于候选span的概率![]() (感觉这一步跟上面获取最大可能性起止点是无关的,我之前把这两个看作连续的,还在纠结为啥前面就已经拿到了span的边界,这里怎么还在判断每个token是不是属于候选span中),第i个token出现在C中的频率越高,属于候选span的这个概率就越高。这样内容信息Pc就可以用于候选集评分过程,从而训练提取器。
(感觉这一步跟上面获取最大可能性起止点是无关的,我之前把这两个看作连续的,还在纠结为啥前面就已经拿到了span的边界,这里怎么还在判断每个token是不是属于候选span中),第i个token出现在C中的频率越高,属于候选span的这个概率就越高。这样内容信息Pc就可以用于候选集评分过程,从而训练提取器。
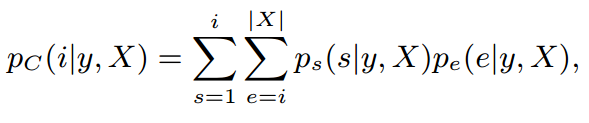
4)最后,有了边界和内容信息,extractor就能很好被训练来获取最终的golden 实体span。这种方式并没有设置最大的span长度,但是也能识别到长实体。
Discriminator
extractor得到了实体span候选集C,判别器的目标就是评估C的分数,主要过程包括以下两个步骤:
1)获取候选集的表征:将实体标记和序列匹配后,使用Match-LSTM得到entity-aware的序列表征,然后使用ri计算实体span候选集rC的表征:
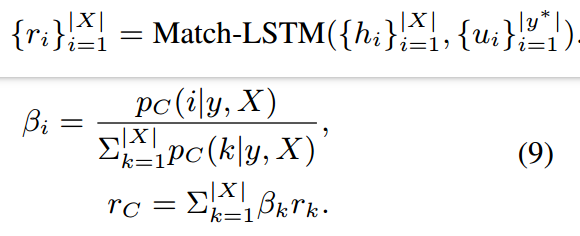
2)计算候选集的分数,这个分数将用于迭代训练extractor去获得更高的分数。
![]()
Multi-task Learning with GAT
在训练过程中,通过多任务学习来训练extractor,使用GAT一起训练extractor和判别器,因此整个模型有3个损失:
1)最小化golden实体span中真实start和end的负对数概率:
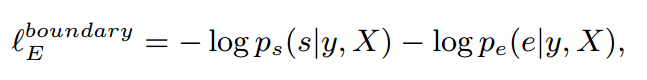
2)最小化起止下标匹配损失:
![]()
3)extractor和判别器的GAT损失:
![]()
即整体训练损失为:
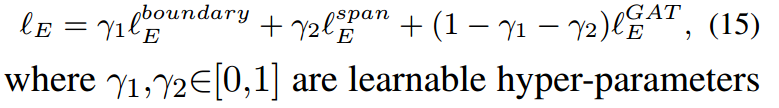
同时还通过最大化和最小化来训练判别器:

实验
对比实验
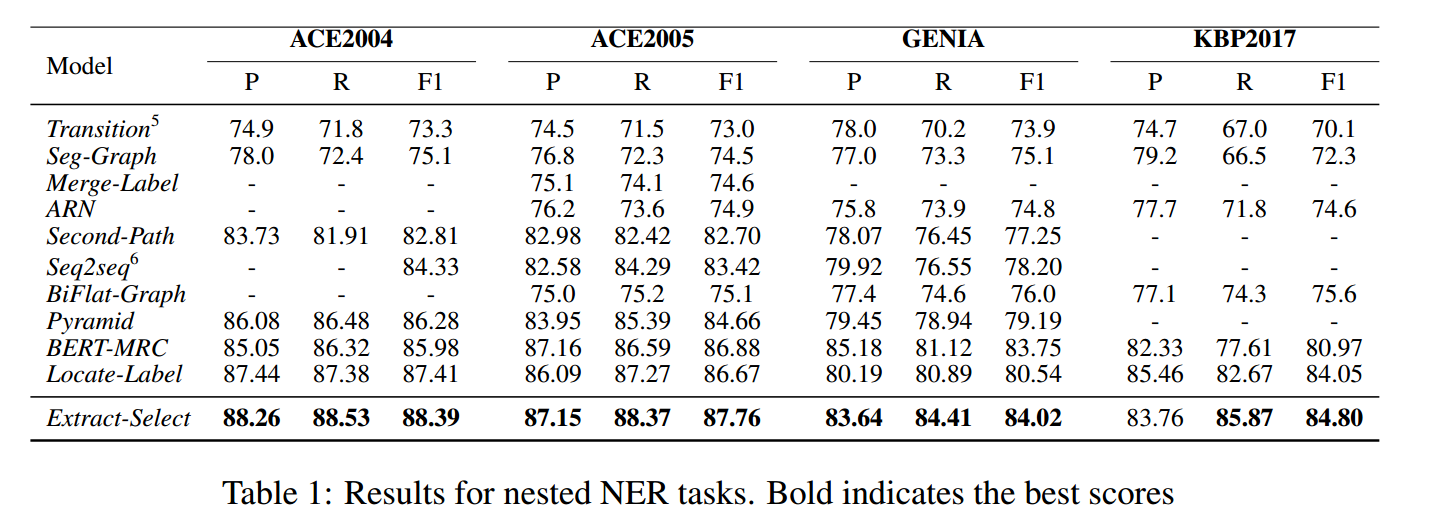
在ACE2004、ACE2005、GENIA、KBP2017这四个数据集上进行实验,结果如下:
消融实验
作者对模型的主要模块进行了消融实验,结果如下(不得不表扬,这是我最近看见做得最皮漂亮的消融实验!):

作者探究了不同类型marker对模型性能的影响,结果如下所示:
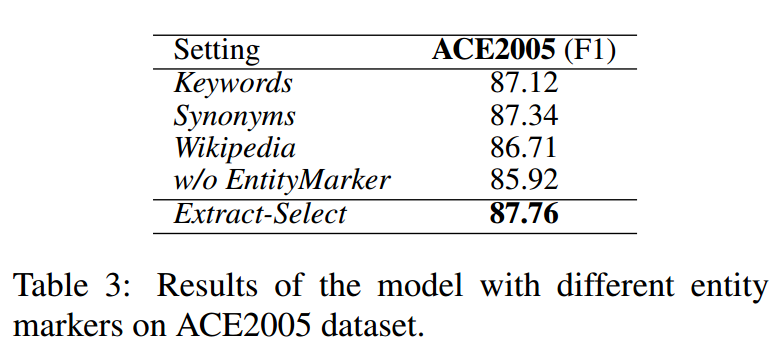
其中维基百科的结果比其他两种设置更低,作者认为可能是维基中对于词的解释并不准确。
分析
作者对模型在小样本训练集上的表现进行了实验,结果如下所示:
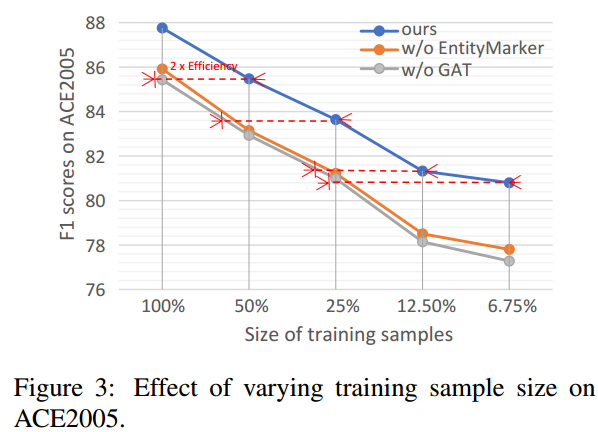
可以看出entity marker和GAT在小样本上有着较好的表现。
作者对模型在长实体识别能力上也进行了实验,结果如下所示:
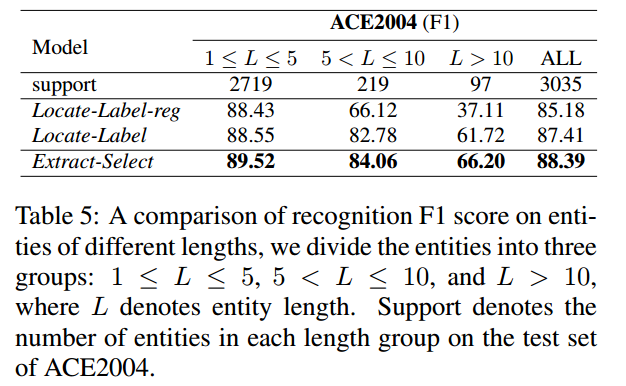
作者对部分句子的预测结果进行了展示:

第一个例子可以看出作者提出的模型能够识别模糊的实体,这是因为该框架为每一个类别分别提取实体,而不是对每个实体做多分类。第二句中,作者提出的模型能够更好的处理长实体。第三句中,可以看出作者提出的模型对于嵌套实体的识别不是很准确,作者认为嵌套实体会对判别器产生混淆的负作用。
总结
作者的方法带来的效果确实很不错,解决了很多传统基于span命名实体识别存在的问题,并且使用生成对抗训练能够使得模型在小样本数据集上也表现比较好。另外,作者将label进行处理也得到了很好的效果,看来或许在label上下点功夫也可能会有较好的效果。
但是这个论文没有公布代码,,,,,
















 790
790











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









