








目录
一、向量和矩阵
我们在上一节课中说到,随着输入数据的特征越来越多,如果一个个的去编写函数表达式未免有点麻烦和拖沓,所以我们需要一个数学工具让这件事情变得简单,矩阵和向量。
一个方程可用向量运算:(简洁、统一)

一组函数可用矩阵运算:

numpy矩阵运算:

二、编程实验1
将上节课代码中数组转化为向量替代:
之前代码
import numpy as np
import dataset
import plot_utils
m = 100
xs, ys = dataset.get_beans(m)
print(xs)
print(ys)
plot_utils.show_scatter(xs, ys)
w1 = 0.1
w2 = 0.2
b = 0.1
## [[a,b][c,d]]
## x1s[a,c]
## x2s[b,d]
## 逗号,区分的是维度,冒号:区分的是索引,省略号… 用来代替全索引长度
# 在所有的行上,把第0列切割下来形成一个新的数组
x1s = xs[:, 0]
x2s = xs[:, 1]
# 前端传播
def forward_propgation(x1s, x2s):
z = w1 * x1s + w2 * x2s + b
a = 1 / (1 + np.exp(-z))
return a
plot_utils.show_scatter_surface(xs, ys, forward_propgation)
for _ in range(500):
for i in range(m):
x = xs[i] ## 豆豆特征
y = ys[i] ## 豆豆是否有毒
x1 = x[0]
x2 = x[1]
a = forward_propgation(x1, x2)
e = (y - a) ** 2
deda = -2 * (y - a)
dadz = a * (1 - a)
dzdw1 = x1
dzdw2 = x2
dzdb = 1
dedw1 = deda * dadz * dzdw1
dedw2 = deda * dadz * dzdw2
dedb = deda * dadz * dzdb
alpha = 0.01
w1 = w1 - alpha * dedw1
w2 = w2 - alpha * dedw2
b = b - alpha * dedb
plot_utils.show_scatter_surface(xs, ys, forward_propgation)
使用向量矩阵后的代码vec_caculate.py:
import numpy as np
import dataset
import plot_utils
m = 100
X, Y = dataset.get_beans(m)
print(X)
print(Y)
plot_utils.show_scatter(X, Y)
# w1 = 0.1
# w2 = 0.2
W = np.array([0.1, 0.1])
# b = 0.1
B = np.array([0.1])
# 前端传播
def forward_propgation(X):
# z = w1 * x1s + w2 * x2s + b
# ndarray的dot函数:点乘运算
# ndarray的T属性:转置运算
Z = X.dot(W.T) + B
# a = 1 / (1 + np.exp(-z))
A = 1 / (1 + np.exp(-Z))
return A
plot_utils.show_scatter_surface(X, Y, forward_propgation)
for _ in range(500):
for i in range(m):
Xi = X[i] ## 豆豆特征
Yi = Y[i] ## 豆豆是否有毒
A = forward_propgation(Xi)
E = (Yi - A) ** 2
dEdA = -2 * (Yi - A)
dAdZ = A * (1 - A)
dZdW = Xi
dZdB = 1
dEdW = dEdA * dAdZ * dZdW
dEdB = dEdA * dAdZ * dZdB
alpha = 0.01
W = W - alpha * dEdW
B = B - alpha * dEdB
plot_utils.show_scatter_surface(X, Y, forward_propgation)
三、Keras
从本节课开始,为了能够快速的上手实现,我们就不再手写神经网络的实践,而使用机器学习框架Keras,让他帮我们彻底摆脱各种底层麻烦的事情。所以Keras框架到底是什么?对于有计算机基础的同学来说,我们可以做一个类比进行理解,我们用汇编语言写程序也是可以的,可是那太麻烦了,你必须完全了解你所面对的机器有多少的寄存器,RAM有多少,怎么分布的,如何响应中断。

所以人们发明的C语言一下子就让我们很大程度上摆脱了计算机底层硬件的琐碎问题,而能专注于编写我们想要的功能。当然,在使用C语言的时候,我们必要时还需要考虑一些底层的琐碎问题,人们希望编程更简单,更注重业务而不是机器,所以出现了Java 、c#等等这些更加上层的语言,直到Python、javascript这种脚本语言的出现,我们几乎不太需要关心底层到底发生了什么。

Keras框架就像机器学习里的高级语言,实现了对机器学习神经网络底层复杂的数学运算的封装,我们可以轻松的通过它提供了各种上层接口搭建模型。当然除了Keras以外,还有很多其他的框架,比如最耳熟能详的TenSorflow,还是用编程语言来举例子,Tensorflow更像是C语言,对底层的封装并不是那么完全,但是更加的强大和灵活。而Keras更像是python语言,就两个字,简单。我们可以类比一下一个同样的神经元模型,用Keras和Tensorflow框架实现的代码量,你会很直观的看见它们的区别。
 但不论Keras如何简单,我们也不能在完全不懂底层原理的情况下去使用它,就像不论你使用C语言还是python语言编程,都断然不可完全不懂计算机基本原理一样。或许你能做出一点东西,但最终会很虚无缥缈,也很难向更高的地方前进。
但不论Keras如何简单,我们也不能在完全不懂底层原理的情况下去使用它,就像不论你使用C语言还是python语言编程,都断然不可完全不懂计算机基本原理一样。或许你能做出一点东西,但最终会很虚无缥缈,也很难向更高的地方前进。
Keras框架搭建小蓝的大和之前作对比:
手撸模型:之前为了实现一个简单的神经元,也需要编写各种繁琐的代码,首先是前向传播,然后是计算代价函数,再然后利用反向传播计算误差在每个神经元上的权重和偏置参数的导数进行梯度下降。这些过程想想就很繁琐。

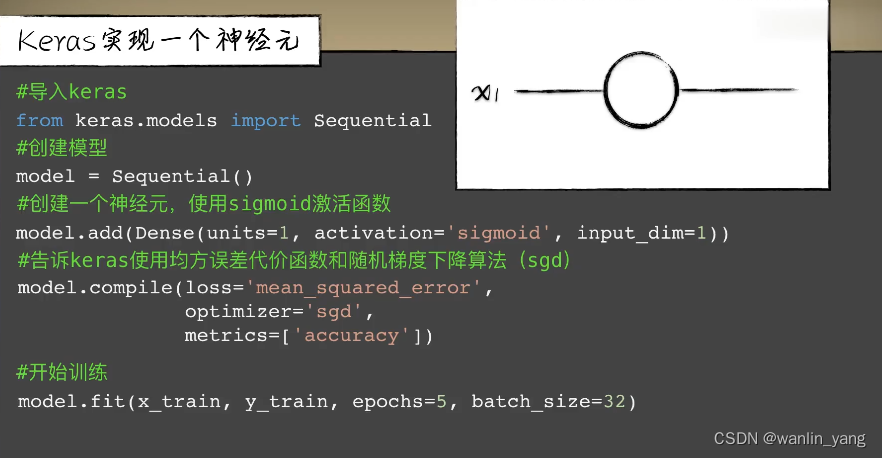
现在如果我们想要把神经元变成两个,你只需要把unite=1改成unite=2就可以了。
 当然,我们的豆豆分类作为一个分类问题,只有一个0或1的单输出,两个神经元有两个输出,所以我们需要在后面再加一个神经元,把这两个神经元汇合一下。如果你想让这个模型更加复杂也更强大一点,比如把第一层的神经元数量改成四,同样也只需要简单的把1设置为4即可。
当然,我们的豆豆分类作为一个分类问题,只有一个0或1的单输出,两个神经元有两个输出,所以我们需要在后面再加一个神经元,把这两个神经元汇合一下。如果你想让这个模型更加复杂也更强大一点,比如把第一层的神经元数量改成四,同样也只需要简单的把1设置为4即可。

这就是我们的Keras框架,作为机器学习神经网络的应用入门,它的极致简单简直就是福音。

我们打开Keras的文档,正如它的第一段话说的那样,你恰好发现的Keras。那说完Keras的酸爽,我们也简单的介绍一下它存在的一些问题。首先,这如文档里说的那样,Keras并不是一个独立的框架,而是通过调用诸如Tensorflow、CNTK或Theano等独立的框架实现的。你可以简单的类比编程语言中python语言的运行环境,使用更底层一点的C或C++写成的。第二,就因为它太简单了,封装的太好了,所以有时候并没有像更加底层的Tensorflow那样灵活。虽然他说高度模块化可扩展性,但众所周知,往往高度封装带来的简单会造成对具体细节控制的流失。当然,经过这么多年的发展,Keras在灵活性上也在不断的增强,而作为同出谷歌之首的两大框架,目前也已经把Keras并入到了Tensorflow之中,作为Tensorflow的高级API。但问题是,如果我使用Keras去做这么细致的事情,那为什么不使用Tensorflow?正如我们在面对谁是最好的编程语言这个问题一样,答案是一致的,没有最好,只有最合适。Keras 的开发重点是支持快速的实验。能够以最小的时延把你的想法转换为实验结果,是做好研究的关键。

🔗参考链接:Keras官网
四、环境准备
安装Tensorflow和Keras:
pip install keras -i https://pypi.mirrors.ustc.edu.cn/simple/
pip install tensorflow -i https://pypi.mirrors.ustc.edu.cn/simple/

如果遇到ddl缺失问题,我们只需要去微软的官网下载一个Visual C++软件包:
参考链接

五、编程实验2
1.导入豆豆数据集dataset.py(包含了本节课的4种数据集)
import numpy as np
def get_beans(counts):
xs = np.random.rand(counts,2)*2
ys = np.zeros(counts)
for i in range(counts):
x = xs[i]
if (x[0]-0.5*x[1]-0.1)>0:
ys[i] = 1
return xs,ys
def get_beans1(counts):
xs = np.random.rand(counts)
xs = np.sort(xs)
ys = np.zeros(counts)
for i in range(counts):
x = xs[i]
yi = 0.7*x+(0.5-np.random.rand())/50+0.5
if yi > 0.8:
ys[i] = 1
else:
ys[i] = 0
return xs,ys
def get_beans2(counts):
xs = np.random.rand(counts)*2
xs = np.sort(xs)
ys = np.zeros(counts)
for i in range(counts):
x = xs[i]
yi = 0.7*x+(0.5-np.random.rand())/50+0.5
if yi > 0.8 and yi < 1.4:
ys[i] = 1
return xs,ys
def get_beans3(counts):
xs = np.random.rand(counts)*2
xs = np.sort(xs)
ys = np.zeros(counts)
for i in range(counts):
x = xs[i]
yi = 0.7*x+(0.5-np.random.rand())/50+0.5
if yi > 0.8 and yi < 1.4:
ys[i] = 1
if yi > 1.6 and yi < 1.8:
ys[i] = 1
return xs,ys
def get_beans4(counts):
xs = np.random.rand(counts,2)*2
ys = np.zeros(counts)
for i in range(counts):
x = xs[i]
if (np.power(x[0]-1,2)+np.power(x[1]-0.3,2))<0.5:
ys[i] = 1
return xs,ys
2.绘图工具封装包:plot_utils.py
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
import numpy as np
from keras.models import Sequential#导入keras
def show_scatter_curve(X,Y,pres):
plt.scatter(X, Y)
plt.plot(X, pres)
plt.show()
def show_scatter(X,Y):
if X.ndim>1:
show_3d_scatter(X,Y)
else:
plt.scatter(X, Y)
plt.show()
def show_3d_scatter(X,Y):
x = X[:,0]
z = X[:,1]
fig = plt.figure()
ax = Axes3D(fig)
ax.scatter(x, z, Y)
plt.show()
def show_surface(x,z,forward_propgation):
x = np.arange(np.min(x),np.max(x),0.1)
z = np.arange(np.min(z),np.max(z),0.1)
x,z = np.meshgrid(x,z)
y = forward_propgation(X)
fig = plt.figure()
ax = Axes3D(fig)
ax.plot_surface(x, z, y, cmap='rainbow')
plt.show()
def show_scatter_surface(X,Y,forward_propgation):
if type(forward_propgation) == Sequential:
show_scatter_surface_with_model(X,Y,forward_propgation)
return
x = X[:,0]
z = X[:,1]
y = Y
fig = plt.figure()
ax = Axes3D(fig)
ax.scatter(x, z, y)
x = np.arange(np.min(x),np.max(x),0.1)
z = np.arange(np.min(z),np.max(z),0.1)
x,z = np.meshgrid(x,z)
X = np.column_stack((x[0],z[0]))
for j in range(z.shape[0]):
if j == 0:
continue
X = np.vstack((X,np.column_stack((x[0],z[j]))))
r = forward_propgation(X)
y = r[0]
if type(r) == np.ndarray:
y = r
y = np.array([y])
y = y.reshape(x.shape[0],z.shape[1])
ax.plot_surface(x, z, y, cmap='rainbow')
plt.show()
def show_scatter_surface_with_model(X,Y,model):
#model.predict(X)
x = X[:,0]
z = X[:,1]
y = Y
fig = plt.figure()
ax = Axes3D(fig)
ax.scatter(x, z, y)
x = np.arange(np.min(x),np.max(x),0.1)
z = np.arange(np.min(z),np.max(z),0.1)
x,z = np.meshgrid(x,z)
X = np.column_stack((x[0],z[0]))
for j in range(z.shape[0]):
if j == 0:
continue
X = np.vstack((X,np.column_stack((x[0],z[j]))))
y = model.predict(X)
# return
# y = model.predcit(X)
y = np.array([y])
y = y.reshape(x.shape[0],z.shape[1])
ax.plot_surface(x, z, y, cmap='rainbow')
plt.show()
def pre(X,Y,model):
model.predict(X)3.第一批豆豆
Sequential #堆叠神经网络序列的载体
Dense #全连接层,一层神经网络
loss(损失函数、代价函数):mean_squared_error均方误差;
optimizer(优化器):sgd(随机梯度下降算法);
metrics(评估标准):accuracy(准确度);
import dataset
import plot_utils
from keras.models import Sequential #堆叠神经网络序列的载体
from keras.layers import Dense #全连接层,一层神经网络
#获取豆豆数据
m = 100
X, Y = dataset.get_beans1(m)
plot_utils.show_scatter(X, Y)
#创建堆叠神经网络序列的载体Sequential
model = Sequential()
#创建全连接层
model.add(Dense(units=1, activation='sigmoid', input_dim=1))
# 当前层神经元的数量为1,激活函数类型:sigmoid,输入数据特征维度:1
#配置模型
model.compile(loss='mean_squared_error', optimizer='sgd', metrics=['accuracy'])
# loss(损失函数、代价函数):mean_squared_error均方误差;
# # optimizer(优化器):sgd(随机梯度下降算法);
# metrics(评估标准):accuracy(准确度);
#训练数据fit
model.fit(X, Y, epochs=5000, batch_size=10)
# epochs:回合数(全部样本完成一次训练)、batch_size:批数量(一次训练使用多少个样本)
#预测数据predict
pres = model.predict(X)
plot_utils.show_scatter_curve(X, Y, pres)
训练结果:

4.第二批豆豆
import dataset
import plot_utils
from keras.models import Sequential #堆叠神经网络序列的载体
from keras.layers import Dense #全连接层,一层神经网络
from keras.optimizers import SGD #引入keras.optimizers调整学习率
#获取豆豆数据
m = 100
X, Y = dataset.get_beans2(m)
plot_utils.show_scatter(X, Y)
#创建堆叠神经网络序列的载体Sequential
model = Sequential()
#创建全连接层,加入隐藏层
model.add(Dense(units=2, activation='sigmoid', input_dim=1))
model.add(Dense(units=1, activation='sigmoid'))#输出层
#配置模型
model.compile(loss='mean_squared_error', optimizer=SGD(lr=0.05), metrics=['accuracy'])
# loss(损失函数、代价函数):mean_squared_error均方误差;
# # optimizer(优化器):sgd(随机梯度下降算法);
# metrics(评估标准):accuracy(准确度);
# 调整学习率为0.05
# sgd优化器默认学习率是0.01
#训练数据fit
model.fit(X, Y, epochs=5000, batch_size=10)
# epochs:回合数(全部样本完成一次训练)、batch_size:批数量(一次训练使用多少个样本)
#预测数据predict
pres = model.predict(X)
plot_utils.show_scatter_curve(X, Y, pres)
训练结果
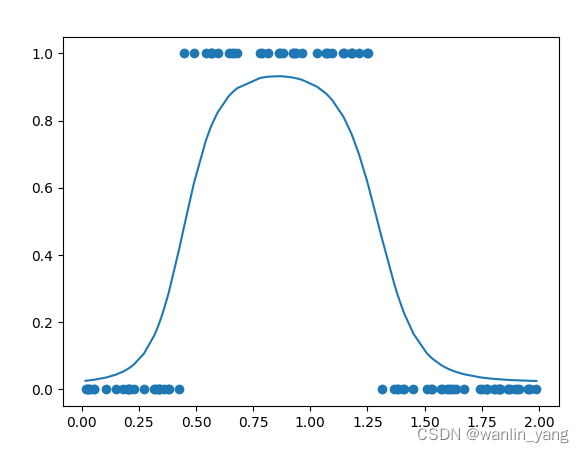
5.第三批豆豆
import dataset
import plot_utils
from keras.models import Sequential #堆叠神经网络序列的载体
from keras.layers import Dense #全连接层,一层神经网络
from keras.optimizers import SGD #引入keras.optimizers调整学习率
#获取豆豆数据
m = 100
X, Y = dataset.get_beans(m)
plot_utils.show_scatter(X, Y)
#创建堆叠神经网络序列的载体Sequential
model = Sequential()
#创建全连接层
# 当前层神经元的数量为1,激活函数类型:sigmoid,输入数据特征维度:2
model.add(Dense(units=1, activation='sigmoid', input_dim=2))
#配置模型
model.compile(loss='mean_squared_error', optimizer=SGD(lr=0.05), metrics=['accuracy'])
# loss(损失函数、代价函数):mean_squared_error均方误差;
# # optimizer(优化器):sgd(随机梯度下降算法);
# metrics(评估标准):accuracy(准确度);
# 调整学习率为0.05
#训练数据fit
model.fit(X, Y, epochs=5000, batch_size=10)
# epochs:回合数(全部样本完成一次训练)、batch_size:批数量(一次训练使用多少个样本)
#预测数据predict
pres = model.predict(X)
plot_utils.show_scatter_surface(X, Y, model)
豆豆毒性分布

训练数据

6.第四批豆豆
import dataset
import plot_utils
from keras.models import Sequential #堆叠神经网络序列的载体
from keras.layers import Dense #全连接层,一层神经网络
from keras.optimizers import SGD #引入keras.optimizers调整学习率
#获取豆豆数据
m = 100
X, Y = dataset.get_beans(m)
plot_utils.show_scatter(X, Y)
#创建堆叠神经网络序列的载体Sequential
model = Sequential()
#创建全连接层
# 当前层神经元的数量为2,激活函数类型:sigmoid,输入数据特征维度:2
model.add(Dense(units=2, activation='sigmoid', input_dim=2))
model.add(Dense(units=1, activation='sigmoid'))#输出层
#配置模型
model.compile(loss='mean_squared_error', optimizer=SGD(lr=0.05), metrics=['accuracy'])
# loss(损失函数、代价函数):mean_squared_error均方误差;
# # optimizer(优化器):sgd(随机梯度下降算法);
# metrics(评估标准):accuracy(准确度);
# 调整学习率为0.05
#训练数据fit
model.fit(X, Y, epochs=5000, batch_size=10)
# epochs:回合数(全部样本完成一次训练)、batch_size:批数量(一次训练使用多少个样本)
#预测数据predict
pres = model.predict(X)
plot_utils.show_scatter_surface(X, Y, model)
六、总结
随着输入数据的特征越来越多,如果一个个的去编写函数表达式未免有点麻烦和拖沓,所以我们需要一个数学工具让这件事情变得简单,矩阵和向量。本节课还介绍了Keras,Keras 的开发重点是支持快速的实验,能够以最小的时延把你的想法转换为实验结果,是做好研究的关键。
七、往期内容

8.初识Keras:轻松完成神经网络模型搭建
9.深度学习:神奇的DeepLearning
10.卷积神经网络:打破图像识别的瓶颈
11. 卷积神经网络:图像识别实战
12.循环:序列依赖问题
13.LSTM网络:自然语言处理实践
14.机器学习:最后一节课也是第一节课
视频链接:
https://pan.baidu.com/s/1TyIPC3UD16zEk7MUEMsHWw?pwd=83nq















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









