







 文章探讨了MaskedAutoencoders(MAEs)作为自监督学习在计算机视觉中的高效方法,通过高遮罩比例减少图像冗余并促进全局特征学习。MAEs的非对称编码结构和轻量级解码器使其在迁移学习中表现出色。研究还引发了关于遥感影像与自然图像差异以及自监督方法在遥感领域的应用的思考。
文章探讨了MaskedAutoencoders(MAEs)作为自监督学习在计算机视觉中的高效方法,通过高遮罩比例减少图像冗余并促进全局特征学习。MAEs的非对称编码结构和轻量级解码器使其在迁移学习中表现出色。研究还引发了关于遥感影像与自然图像差异以及自监督方法在遥感领域的应用的思考。
题目:Masked Autoencoders Are Scalable Vision Learners(2021.12.9)
1.概述
MAE(Masked Autoencoders)是用于CV的自监督学习方法(对照于NLP的BERT),优点是扩展性强的(scalable),方法简单。在MAE方法中会随机mask输入图片的部分patches,然后重构这些缺失的像素。
MAE基于两个核心设计:(1)非对称的(asymmetric)编码解码结构,编码器仅仅对可见的patches进行编码,不对mask tokens进行任何处理,解码器将编码器的输出(latent representation)和mask tokens作为输入,重构image(decoder十分轻量级,可使用1个transformer block进行重建);(2)使用较高的mask比例(如75%)(目的是图像的冗余信息很高,较高的mask比例可以迫使图像学习全局的潜在特征,降低图像的冗余度,这也是与插值方法通过周围信息预测mask patch的很大区别!)。除此之外,使用较高的mask比例,也更effciently(相比于原图所有token。75%mask加速3倍的计算速度)。
在迁移学习上,在相同的预训练数据集上比有监督学习的性能更好,其预测精度与扩大数据集趋势一致!扩大模型性能还能显著提升。
本文引言用问题的方式,引发了大家的思考(很好的一种写作方式:引出问题–分析本质–说明自己的工作)
what makes masked autoencoding different between vision and language?
- Until recently, architectures were different.之前常用CNN架构,不容易嵌入mask和位置编码(基于BERT思想,但这种问题被VIT解决了,故本文工作在VIT提出后一个月所发表的一篇。
- Information density is different between language and vision.信息密度的不同,语言是人工生成的,而图像是自然信号。(那么遥感影像和自然图像又有什么差别呢?)针对于每一个token而言,具有较高的语义信息,很难去预测,而图像存在信息冗余,较易通过“插值”等方式去使用邻近信息预测token。所以为了解决这个信息冗余的问题(动机),使用了较高mask比例。
- The autoencoder’s decoder, which maps the latent representation back to the input, plays a different role between reconstructing text and images.自编码的解码器不同,相对于NLP token的高语义信息重建,只使用简单的MLP即可,但图像重建需要的是浅层的信息表示,需要稍微复杂的解码器。
2.主要内容
2.1 结构说明
整体结构很简单:(具体见原文,这里我用自己的话把重要的地方说明一下)
- masking:将patch进行shuttle(随机打乱),再根据比例按顺序选择(如75%,打乱后选择前25%,后面masked)。
- embedding patch:linear projection和position embeddings。
- encoder:n个transformer块,和VIT一致(只输入未masked的patch)。在encoding后,再unshuttle一下,将所有tokens输入到decoder里。
- decoder:对所有tokens重新加了position embeddings以免之后无法复原masked tokens的位置;m个transformer 块,但默认decoder只有encoder计算量的10%,故是非对称的。
- reconstruction target:使用像素值进行重建。在masked patch上使用MSE(均方误差)计算损失,再reshape还原。
2.2 参数实验
对masked ratio的实验:60%这里表现最好,75%之后开始下降。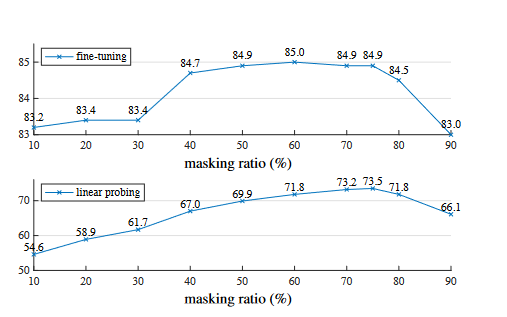 works well for both fine-tuning (top) and linear probing (bottom). The y-axes are ImageNet-1K validation accuracy (%) in all plots in this paper.")
works well for both fine-tuning (top) and linear probing (bottom). The y-axes are ImageNet-1K validation accuracy (%) in all plots in this paper.")
对六个参数进行了实验:解码器深度、解码器输入token长度、编码器是否使用masked patch、目标重建方法、数据增强策略、采样方法。这里ft是end-to-end fine-tuning ,lin是linear probing(只改最后一层线性层).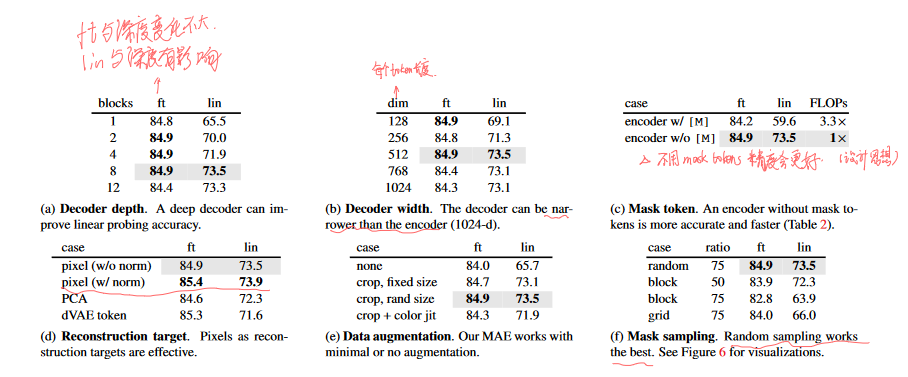
这里我注意的是a、d和f:
a:说明对参数进行全部微调与解码器深度关系不大,故可以设计较小的decoder,而使用linear probing的方法与深度有很大影响!
d:这里比较对所有token进行像素重建、对masked token进行像素重建、PCA(96参数)和dVAE token的方式,发现最简单的masked token像素重建反而效果最好,何乐而不为呢!需要了解一下dVAE token的方式,看一下BEIT(2021.6),比较一下MAE和BEIT的区别。 理解一下tokenizer概念~
BEiT: BERT Pre-Training of Image Transformers
f:是对采样的方式选取,记忆一下技巧。
对部分微调的实验: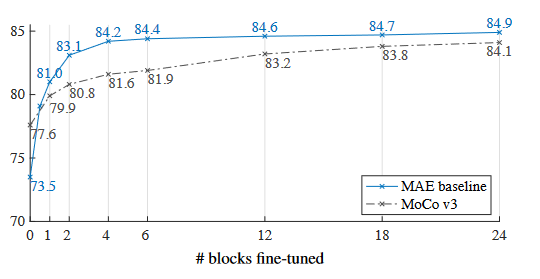
1.对MLP这种非线性变换进行微调可以提高很大性能。
2.只对部分transformer block进行微调也能有很好的性能。
Notably, fine-tuning only one Transformer block boosts the accuracy significantly from 73.5% to 81.0%. Moreover, if we fine-tune only “half” of the last block (i.e., its** MLP sub-block)**, **we can get 79.1%, much better than linear probing. **This variant is essentially fine-tuning an MLP head. Fine-tuning a few blocks (e.g., 4 or 6) can achieve accuracy close to full fine-tuning.
3.MAE比MoCo v3有着更好的非线性特征。(为什么特征的线性可分性对结果影响不大?)
While the MAE representations are** less linearly separable**, they are stronger non-linear features and perform well when a non-linear head is tuned.
2.3 在监督学习和自监督学习上的对比
![Comparisons with previous results on ImageNet1K. The pre-training data is the ImageNet-1K training set (except the tokenizer in BEiT was pre-trained on 250M DALLE data [50]). All self-supervised methods are evaluated by end-to-end fine-tuning. The ViT models are B/16, L/16, H/14 [16]. The best for each column is underlined. All results are on an image size of 224, except for ViT-H with an extra result on 448. Here our MAE reconstructs normalized pixels and is pre-trained for 1600 epochs.](https://img-blog.csdnimg.cn/img_convert/9ec77e418c6207c67bcce198c6a2e207.png) . All self-supervised methods are evaluated by end-to-end fine-tuning. The ViT models are B/16, L/16, H/14 [16]. The best for each column is underlined. All results are on an image size of 224, except for ViT-H with an extra result on 448. Here our MAE reconstructs normalized pixels and is pre-trained for 1600 epochs.“)
. All self-supervised methods are evaluated by end-to-end fine-tuning. The ViT models are B/16, L/16, H/14 [16]. The best for each column is underlined. All results are on an image size of 224, except for ViT-H with an extra result on 448. Here our MAE reconstructs normalized pixels and is pre-trained for 1600 epochs.“)![MAE pre-training vs. supervised pre-training, evaluated by fine-tuning in ImageNet-1K (224 size). We compare with the original ViT results [16] trained in IN1K or JFT300M.](https://img-blog.csdnimg.cn/img_convert/704e553a3b88f4ebdf11a2b9613aa3ef.png) . We compare with the original ViT results [16] trained in IN1K or JFT300M.”)
. We compare with the original ViT results [16] trained in IN1K or JFT300M.”)
MAE在1M和300M的预测趋势在计算量增加的情况下一致!说明MAE可以帮助扩展模型的大小(数据集上的)。
3.结论
- 使用较大的mask比例减少图像的冗余信息,加快计算量且学的更好。
- 使用较少的transformer块直接对像素进行重建,能使用这种简单操作得到较好的重建效果。
4.思考
- MAE这篇文章我觉得更精华的是,引言的问题引出,从而去设计网络,而不是抖机灵。(masked ratio的比例降低图像信息冗余,而解码器的简单倒是从实验出发,发现一层已经很好!提出一个idea,再通过实验去完善!)
- cv领域的自监督方法,能否应用到遥感领域?存在什么问题?遥感影像和自然图像的本质上又是什么区别呢?陈盼师兄的论文也提到这个问题:
遥感影像与自然图像存在较大的差异,对网络模型的特征提取能力有较强的要求。具体包括:(1)遥感影像地物没有景深,但是却存在多尺度地物,这种尺度变化是地物自身固有的属性,与计算机视觉中的由于景深造成的尺度差异有明显区别。(2)遥感影像中地物没有固定的方向性,与自然图像中的目标姿态相对固定不同,遥感地物可以以任意方向任意姿态出现在图像中。(3)遥感地物复杂多样,不同地物可能在影像上表现相似,同一地物在不同时相不同拍摄条件下表现也明显不同。因此,当前缺少针对遥感地物以及高分辨率变化检测数据的预训练模型,遥感图像的变化检测网络缺少可靠的参数初始化,也为模型的特征提取带来了一定的训练难度以及泛化误差。
- 特征的线性可分性对结果影响不大,但非线性特征能力影响很大?















 4423
4423











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









