





owin 怎么部署在云中
Through this article we are going to present you with the main mistakes we made during — what was supposed to be — a simple project which aimed to deploy an age guessing Neural Network model in the Cloud.
通过本文,我们将向您介绍我们在一个简单的项目中犯的主要错误,该错误原本是一个简单的项目,旨在在云中部署年龄猜测神经网络模型。
Thankfully, we were able to release a good enough version of our project which can be accessed here. Its source code can be found in the dedicated GitLab link.
幸运的是,我们能够发布项目的足够好的版本,可以在此处访问。 可以在专用的GitLab链接中找到其源代码。
项目背景,目标和方法 (The project context, objectives and approach)
As a cybersecurity consultant and a junior software engineer working for large corporations, we have always had an interest in cloud and seeing how this technology can be leveraged for developing simple AI applications.
作为在大型公司工作的网络安全顾问和初级软件工程师,我们一直对云感兴趣,并看到如何利用此技术来开发简单的AI应用程序。
With Covid-19 and lockdowns, we started having many ideas which would combine the skills we learned during our short careers. However, we decided to start with a very simple — and unoriginal — idea before jumping into a more complex project: To deploy a simple and production-ready web application that would guess people’s age thanks to a trained neural network.
借助Covid-19和锁定功能,我们开始有了许多想法,这些想法将结合我们在短暂职业生涯中学到的技能。 但是,我们决定从一个非常简单且原始的想法开始,然后跳入一个更复杂的项目:部署一个简单且可投入生产的Web应用程序,该应用程序将通过训练有素的神经网络来猜测人们的年龄。
We focused on the creation process and learn the “best way” of doing things. We defined the following constraints:
我们专注于创作过程,并学习做事的“最佳方式”。 我们定义了以下约束:
- Follow “state of the art” practices to train our model and deploy our product; 遵循“最新技术”实践来训练我们的模型并部署我们的产品;
- Have a running cost of 0€ per month; 每月的运营费用为0欧元;
- Have a product which could scale “infinitely” thanks to serverless services (in this context, we knew that the 0€/month running costs would only be possible with little to no traffic); 有了一款可以借助无服务器服务“无限扩展”的产品(在这种情况下,我们知道0欧元/月的运行成本只有在流量很小或没有流量的情况下才有可能);
- Build a user-friendly “final product” allowing people to have fun with it; and 制作易于使用的“最终产品”,使人们可以从中获得乐趣; 和
- Enjoy the building process. 享受建造过程。
Based on our project context and objectives, our approach was to follow the below steps:
根据我们的项目背景和目标,我们的方法是遵循以下步骤:
- Obtain a large data set of images with their associated ages 获取具有相关年龄的大量图像数据集
- Select a state of the art Convolutional Neural Network (CNN) to train (on the cloud) a functional age predictor 选择最先进的卷积神经网络(CNN)以训练(在云上)功能性年龄预测器
- Migrate this trained Neural Network model and serve it freely in AWS SageMaker 迁移经过训练的神经网络模型并在AWS SageMaker中免费提供
- Create an Angular Front-End application and serve it via an S3 bucket 创建一个Angular前端应用程序并通过S3存储桶提供服务
- Create an API with API Gateway and use lambda functions to upload the users pictures to SageMaker and retrieve a result 使用API网关创建一个API,并使用lambda函数将用户图片上传到SageMaker并检索结果
- Voilà! A 0€-running-cost fast and scalable age recognition service 瞧! 0欧元运行成本的快速可扩展年龄识别服务
This project looked quite easy to build and deploy, doesn’t it?
这个项目看起来很容易构建和部署,不是吗?
四个主要错误 (The four major mistakes)
When looking at this approach, there are some key words for which we underestimated the underlying difficulty and didn’t ask ourselves some relevant questions such as:
在研究这种方法时,有些关键词被我们低估了潜在的困难,并且没有问自己一些相关的问题,例如:
Step 1 — “Obtain”: What is the quality of the dataset? Is the data equally distributed and well balanced? Has the dataset been tested by other users?
步骤1 —“获取”:数据集的质量是什么? 数据是否分布均匀且平衡良好? 数据集是否已由其他用户测试过?
Step 2 — “Select”: Is it that simple to select a Neural Network model? How do we train it? How do we know that we are following the right path?
步骤2 —“选择”:选择神经网络模型是否这么简单? 我们如何训练它? 我们怎么知道我们在走正确的道路?
Step 3 — “Migrate”: How easy is it to port a model to SageMaker? Are training scripts similar to the ones used locally? Is it free to host a trained model?
步骤3 —“迁移”:将模型移植到SageMaker有多容易? 培训脚本是否与本地使用的脚本相似? 托管训练有素的模型是否免费?
When thinking about how to write this article, we realized that most of the mistakes me made could be grouped into four major mistakes. If you are new to AI and/or Cloud, we hope that our very short experience in the field can help you avoid making the same mistakes.
在考虑如何撰写本文时,我们意识到我犯的大多数错误可以归为四个主要错误。 如果您不熟悉AI和/或云,我们希望我们在该领域的短暂经验可以帮助您避免犯同样的错误。
I.根据流行语指导您的技术选择 (I. Guiding your tech choices based on buzzwords)
Over the past couple of years, we have been hearing a lot about the wonderful world of fully managed PaaS (Platform as a Service) and SaaS (Software as a Service) products. For our project, we wanted to use a service that would allow us to deploy our trained model without needing to worry about infrastructure or costs.
在过去的几年中,我们已经听到了很多有关完全托管的PaaS(平台即服务)和SaaS(软件即服务)产品的奇妙世界的信息。 对于我们的项目,我们希望使用一种服务,该服务将使我们能够部署训练有素的模型,而无需担心基础架构或成本。
Thanks to a quick google search, we understood that the most fashionable and cheapest (via free tier advantages) service at the moment was called AWS SageMaker. Our decision to pick this service was based on the very first introduction sentence on the product’s page: “Amazon SageMaker is a fully managed service that provides every developer (…) with the ability to build, train, and deploy machine learning (ML) models quickly”.
借助Google的快速搜索,我们了解到,目前最时尚,最便宜的服务(通过免费套餐优势)称为AWS SageMaker。 我们决定选择此服务的决定是基于产品页面上的第一句话:“ Amazon SageMaker是一项完全托管的服务,为每个开发人员(...)提供构建,训练和部署机器学习(ML)模型的能力。很快”。

As mentioned previously, our goal was to “quickly” develop a TensorFlow Python project and migrate this project to SageMaker in order to train our model once it was functional. We believed that only minor refactoring would be required to migrate our source code to SageMake.
如前所述,我们的目标是“快速”开发一个TensorFlow Python项目并将该项目迁移到SageMaker,以便在模型运行后对其进行训练。 我们认为将源代码迁移到SageMake只需进行少量重构即可。
However, we realized after developing our training scripts that the migration was a non-trivial process which would require major refactoring of our code. In fact, we figured out that our preprocessing would simply not work following SageMaker’s training workflow. In order to train our model, we would have to completely rework our training scripts.
但是,在开发了培训脚本之后,我们意识到迁移是一个不平凡的过程,需要对代码进行重大重构。 实际上,我们发现,按照SageMaker的培训工作流程,预处理根本无法进行。 为了训练我们的模型,我们必须完全重做我们的训练脚本。
Our main (and obvious) mistake was jumping right into code development before validating our understanding and assumptions about how SageMaker works. On top of that, we did not take into consideration SageMaker’s pricing model. Although we knew that SageMaker was free for the first two months (which was supposed to be enough to train our model), we discovered that SageMaker simply relies on EC2 instances. We understood that a Jupyter notebook would have to be constantly running in order to be used in conjunction with API gateway. This would break two of our main requirements:
在验证我们对SageMaker工作方式的理解和假设之前,我们的主要(也是显而易见的)错误是直接进入代码开发。 最重要的是,我们没有考虑SageMaker的定价模型。 尽管我们知道SageMaker在最初的两个月内是免费的(这本来足以训练我们的模型),但我们发现SageMaker仅依赖于EC2实例。 我们知道,Jupyter笔记本必须经常运行才能与API网关结合使用。 这将打破我们的两个主要要求:
- Having no running costs; and 没有运行费用; 和
- Being serverless and scalable. 无服务器且可扩展。
Very quickly, we realized that this could have been avoided by simply reading SageMaker’s documentation and pricing model. “Duh!” you might be thinking. However, we were blindly convinced that such a popular service would provide us with everything we needed to succeed.
很快,我们意识到只需阅读SageMaker的文档和定价模型就可以避免这种情况。 “ Du!” 你可能在想。 但是,我们盲目地相信,如此受欢迎的服务将为我们提供成功所需的一切。
TL;DR: If you do not know the tech, do not assume that it will meet your way of working based on its popularity. In our context, we should have simply adapted our training scripts to SageMaker requirements rather than hoping that the tool could import any training scripts.
TL; DR:如果您不了解这项技术,请不要以其受欢迎程度为前提,认为它会满足您的工作方式。 在我们的上下文中,我们应该简单地根据SageMaker要求调整培训脚本,而不是希望该工具可以导入任何培训脚本。
二。 重新发明轮子 (II. Reinventing the wheel)
This second major mistake is linked to the first one as it is in fact its cause. In this section we will talk about the classic mistake of trying to build things that have already been built by experts in the past. During our project, we realized that we spent too much time trying to re-engineer a well-known and efficient solution: Neural Network Models that provide age recognition.
第二个主要错误与第一个错误有关,因为这实际上是其原因。 在本节中,我们将讨论尝试构建过去由专家构建的事物的经典错误。 在我们的项目中,我们意识到我们花了太多时间尝试重新设计一个众所周知的有效解决方案:提供年龄识别的神经网络模型。

The open source community is awesome, and most of the time, it is very likely that people will have already built awesome tools that do what you’re looking for.
开源社区很棒,而且在大多数情况下,人们很可能已经构建了可以满足您需求的出色工具。
Even if you feel — like us — very excited about the project and you want to build everything yourself, it might be a bad idea to blindly start coding. As you probably know, it is highly recommendable do some research on what has been done about the topic you want to tackle.
即使您像我们一样对项目感到非常兴奋,并且您想自己构建所有内容,盲目地开始编码也可能不是一个好主意。 如您所知,强烈建议您对要解决的主题进行一些研究。
This might sound obvious at first, but you will understand the importance of these words when you experiment and suffer the consequences of not doing it. In our case, we started working on our neural network immediately since we believed we could train and deploy such model without much effort.
乍一看这听起来似乎很明显,但是当您进行实验并遭受不这样做的后果时,您将理解这些词的重要性。 在我们的案例中,我们立即开始研究神经网络,因为我们相信我们可以轻松地训练和部署这种模型。
In fact, even though we were not convinced by our training scripts or the quality of the data, we tried to give it a go on AWS via GPU-optimized instances. The result? After spending 10€ and countless tweaks, our top result was a model with a 20% accuracy on the training dataset. Although we learned a lot about the process, this turned out to be a disaster.
实际上,即使我们对培训脚本或数据质量不满意,我们仍尝试通过GPU优化的实例在AWS上进行尝试。 结果? 在花费了10欧元并进行了无数次调整之后,我们的最高成绩是在训练数据集上获得了20%准确度的模型。 尽管我们了解了很多有关该过程的信息,但事实证明这是一场灾难。
You might be thinking: “If you don’t want to learn how to train a model, why don’t you directly use a public API such as AWS Rekognition or Google Cloud Vision?”. The answer to that question is fairly simple: The main objective of our project was to learn how to deploy an AI model to the cloud and make it scalable and production-ready.
您可能会想:“如果您不想学习如何训练模型,为什么不直接使用AWS Rekognition或Google Cloud Vision之类的公共API?”。 这个问题的答案非常简单:我们项目的主要目标是学习如何将 AI模型部署到云中并使之具有可扩展性和生产就绪性。
After failing to build the local project (the causes of which are explained in the next section), we faced the truth and started looking for an alternative. We started doing some research, and we found what we were looking for with: DEX: Deep EXpectation of apparent age from a single image.
在无法构建本地项目(其原因将在下一节中进行说明)之后,我们面对了事实,并开始寻找替代方案。 我们开始进行一些研究,找到了我们想要的东西: DEX:从一张图像中对表观年龄的深层期望 。

Rasmus Rothe, Radu Timofte and Luc Van Gool published a dataset with more than 500k images with age and gender labels as well as their respective trained model. And the cherry on the cake was that the paper was the winner of the NVIDIA apparent age competition in 2015. We went from trying to build everything on our own to having one of the best ready-to-use age recognition models 👏.
Rasmus Rothe,Radu Timofte和Luc Van Gool发布了一个数据集,其中包含超过500k张带有年龄和性别标签的图像,以及他们各自受过训练的模型。 令人欣喜的是,该论文是NVIDIA在2015年明显年龄竞赛的获胜者。我们从尝试自行构建所有内容,到拥有最好的即用型年龄识别模型👏。
At this point we were confronted with the fact that this paper was better than anything that we could have built, and by far. In fact, we realized that this was not a bad thing since we are not data scientists, and our goal was never to improve the state of the art way of predicting face ages. Although we were sad to see that we could not implement our own trained model, we learned that way better people already built an awesome model. It was therefore obvious to us that we should reuse that model.
在这一点上,我们面临这样一个事实,即到目前为止,本文要比我们能建立的任何文件都要好。 实际上,我们意识到这并不是一件坏事,因为我们不是数据科学家,而且我们的目标绝不是改善现有技术来预测面部年龄。 虽然我们痛心地看到,我们无法实现我们自己的训练模型,我们了解到,方式更好的人已经建立了一个真棒模型。 因此,对于我们来说很明显,我们应该重用该模型。
Our problem here was that we started working on parts of the project that weren’t necessarily of interest to us since we assumed that they were trivial. This meant that we ended up re-building a worse and less performant neural network model.
这里的问题是,我们开始研究项目中不必要的部分,因为我们认为这些部分是微不足道的。 这意味着我们最终重建了一个性能更差,性能更差的神经网络模型。
On a positive note, we learned a lot about deep learning by reading the paper, and more specifically the fact that training a model is not a trivial task. On top of that, most of our constraints (learn by doing, having fun, building a real product) remained intact, meaning that we were still motivated to move on!
积极的一点是,通过阅读本文,我们学到了很多有关深度学习的知识,更具体地说,训练模型并不是一件容易的事。 最重要的是,我们的大多数限制(边做边学,玩乐,制作真实的产品)都完好无损,这意味着我们仍然有动力继续前进!
三, 在同一块石头上绊倒两次 (III. Tripping over the same stone twice)
After abandoning the hope to develop and train our very own ML model, we started working on the back-end that would provide users with their age once the upload a picture.
在放弃开发和训练我们自己的ML模型的希望之后,我们开始在后端工作,一旦上传图片,该后端将为用户提供他们的年龄。
We started developing a simple Flask API in order to confirm that we could understand how to use the trained model. The result was a simple ~90 lines-long python script:
我们开始开发一个简单的Flask API,以确认我们可以理解如何使用经过训练的模型。 结果是一个简单的〜90行长的python脚本:

Once we validated that this API worked locally, our next objective was to migrate this to a “free to use” and “infinitely scalable” AWS service. With that in mind, we took the path of using AWS API Gateway and AWS Lambda functions. Since we had a positive previous experience with these tools, we did not even bother checking out any limitations since we “knew” how to do it.
一旦我们确认此API在本地可以工作,我们的下一个目标就是将其迁移到“免费使用”和“无限扩展”的AWS服务。 考虑到这一点,我们采取了使用AWS API Gateway和AWS Lambda函数的方法。 由于我们以前对这些工具有过积极的经验,因此我们“知道”如何做,因此甚至没有费心检查任何限制。
We encountered our first issue when trying to launch a Python Lambda function with OpenCV and other dependencies. We learned that this could be done with Lambda layers and packaging our lambda function with its dependencies. You will find below the lessons learned after a lot of troubleshooting:
当尝试使用OpenCV和其他依赖项启动Python Lambda函数时,我们遇到了第一个问题。 我们了解到,可以使用Lambda层并用其依赖项包装lambda函数来完成此操作。 在进行大量的故障排除后,您会发现以下教训:
In order to download and package correctly lambda functions, you should download the dependencies from an Amazon Linux-compatible system (i.e. running pip install -t . opencv-python from MacOS will download non-compatible binaries);
为了正确下载和打包lambda函数,您应该从与Amazon Linux兼容的系统中下载依赖项(即从MacOS运行pip install -t。opencv-python将下载不兼容的二进制文件);
- Lambda functions running on Python 3.8 cannot import and run OpenCV as system files such as libgthread-2.0 are not included in the runtime environment. Python 3.7 should be used to run OpenCV. 在Python 3.8上运行的Lambda函数无法导入和运行OpenCV,因为系统文件(例如libgthread-2.0)未包含在运行时环境中。 应该使用Python 3.7来运行OpenCV。
After learning how to correctly download our script dependencies and package them, we uploaded the script to the lambda environment and noted that the remaining step was to import and use our trained ML models.
在学习了如何正确下载脚本依赖项并将其打包后,我们将脚本上传到了lambda环境,并指出剩下的步骤是导入和使用我们训练有素的ML模型。
We were confronted with a harsh reality once again: Lambda functions have restrictive storage limits. By reading Lambda’s official documentation, we noted that each functions deployment packages has a maximum size of 250 MB while both our ML models were 500 MB and 600 MB.
我们再次面临着一个严峻的现实:Lambda函数具有严格的存储限制。 通过阅读Lambda的官方文档,我们注意到每个功能部署包的最大大小为250 MB,而我们的ML模型分别为500 MB和600 MB。
Please note that this might not be accurate anymore since Lambda supports EFS now.
请注意,由于 Lambda现在支持EFS ,这可能不再正确 。
Once again, we tripped over the same stone: We did not take the time to read and learn about the limitations of the products we wanted to use. We were, once more, blindly guided by the hype and great use cases delivered by this Function-as-a-Service product. In this case, we overestimated our knowledge of the technology based on great results we had from previous experiences.
我们再次绊倒了一块石头:我们没有花时间阅读和了解我们想要使用的产品的局限性。 我们再一次盲目地被“功能即服务”产品所提供的宣传和大量用例所引导。 在这种情况下,我们会根据以前的经验得出的出色结果高估了对技术的了解。
What should have been done before trying to port our code? Do some basic research and understand if the product is adapted to our needs. It appears that selecting the most popular product can sometimes mean making a very poor technological choice. See for example — what we should have read before even starting — “Why we don’t use Lambda for serverless machine learning”.
在尝试移植我们的代码之前应该做些什么? 做一些基础研究,了解产品是否适合我们的需求。 似乎选择最受欢迎的产品有时可能意味着做出非常差的技术选择。 例如,请参阅“甚至在开始之前都应该阅读的内容”“为什么我们不使用Lambda进行无服务器机器学习” 。
IV。 低估难度,高估您的知识 (IV. Underestimate the difficulty and overestimate your knowledge)
This project was driven by the belief that we knew how to make things “properly” even though we had very little experience on the fields we were addressing (i.e. AI and Cloud). The fourth and last major mistake is in fact the cause of our other mistakes: We underestimated the difficulty of delivering production-ready products while being overly confident that we had sufficient knowledge on how things should be done based on what we had read and heard about each of the underlying technologies.
这个项目是基于这样的信念:即使我们在要解决的领域(即AI和Cloud)上经验很少,我们也知道如何“适当地”做事。 第四个也是最后一个主要错误实际上是导致我们其他错误的原因:我们低估了交付可立即投入生产的产品的难度,同时又过分自信我们已经根据所读和听到的内容对如何做事有足够的了解。每个基础技术。
We started our project having a look at large data sets available online. We mainly searched through Kaggle and found a model with 10.000 faces labelled by their ages. “That’s great!” — we thought — but when we started deep diving a bit into the data we realized that the road to create a good predictor was not going to be as peaceful as we thought.
我们从查看在线可用的大型数据集开始了我们的项目。 我们主要搜索了Kaggle ,找到了一个模型,该模型具有10.000张以年龄标记的面Kong。 “那很棒!” 我们曾想过,但是当我们开始深入研究数据时,我们意识到创建一个好的预测变量的道路不会像我们想象的那样和平。
Firstly, we underestimated how difficult it would be to obtain a proper dataset for free:
首先,我们低估了免费获取适当数据集的难度:
Amount of data: Although we never considered ourselves experts on the field of AI, we knew that having only 10.000 faces from 100 different people would not be sufficient to train an accurate model. In this context, we realized that the amount of data was insufficient. In addition, when we analyzed the amount of faces per age, we realized that the dataset was completely unbalanced. Although we tried to balance the dataset by grouping the faces by range of age, the result remained very unbalanced. We noted that 90% of the available pictures were from 30 to 50 years old individuals.
数据量:尽管我们从未考虑过自己是AI领域的专家,但我们知道,仅100个不同人的10.000张面Kong不足以训练准确的模型。 在这种情况下,我们意识到数据量不足。 另外,当我们分析每个年龄的面Kong数量时,我们意识到数据集是完全不平衡的。 尽管我们尝试通过按范围对面部进行分组来平衡数据集 年龄,结果仍然非常不平衡。 我们注意到,90%的可用图片都是30至50岁的个人。
Quality of data: In addition to the previous issue, we discovered that the data was biased. We noted that most of the pictures were pictures from celebrities. We knew that we could not use pictures from Keanu Reeves and hope that the average looking person looks as young as him. On top of that, we noted that some images were cropped and would show a fairly incomplete part of the face.
数据质量:除了上一期,我们还发现数据存在偏差。 我们注意到,大多数图片是名人的图片。 我们知道我们无法使用基努·里夫斯的照片,希望普通人看起来像他一样年轻。 最重要的是,我们注意到一些图像被裁剪掉,并且会显示出脸部相当不完整的部分。
Lesson learned: Before jumping into training the neural network with a dataset, take the time to ensure that the data you have downloaded has sufficient quality and quantity of samples.
获得的经验教训:在开始使用数据集训练神经网络之前,花时间确保下载的数据具有足够的质量和数量的样本。
Then, we overestimated our knowledge on AI and Cloud and the target solution.
然后,我们高估了我们对AI和云以及目标解决方案的了解。
As very curious people, we have always tried to learn as much as possible about everything in the shortest amount of time. In this context, the concepts of Cloud and Artificial Intelligence were two topics on which we spent a significant amount of time reading about the great things companies and startups make, but a very limited amount of time to understand and deep dive into the technology being used.
作为一个非常好奇的人,我们一直试图在最短的时间内尽可能多地学习一切。 在这种情况下,云和人工智能的概念是两个主题,我们花了大量时间阅读有关公司和初创公司的伟大成就的信息,但是花很少的时间来了解和深入研究所使用的技术。
In essence, we could say that our knowledge of the technologies we wanted to work with was very low, although we felt like we knew a lot. This could be explained by the below graph, which we are sure is very familiar to many of you:
从本质上讲,尽管我们觉得自己了解很多,但可以说我们对要使用的技术的知识很少。 下图可以解释这一点,我们相信许多人对此非常熟悉:

Without spending too much time analyzing this graph, we can confirm that at the beginning of this project we felt somewhere around the “Peak of mount stupid”, and that, over time, we were able to enter the Valley of Dispair. This project helped us realize how little we knew about Machine Learning.
无需花费太多时间来分析此图,我们可以确认,在该项目开始时,我们感觉到了“愚蠢山峰”周围的某个地方,随着时间的推移,我们能够进入绝望谷。 这个项目帮助我们意识到我们对机器学习的了解很少。
We learned the important lesson that selecting the right piece of technology and the right data to begin with is not always simple. There is a significant gap between the creation of a working Proof of Concept, and the deployment of a user-friendly and “final” product.
我们吸取了重要的教训,即选择正确的技术和正确的数据并不总是那么简单。 在创建有效的概念验证与部署用户友好的“最终”产品之间存在巨大差距。
结果? Google云,虚拟机和Docker! (The result? Google Cloud, Virtual Machines and Docker!)
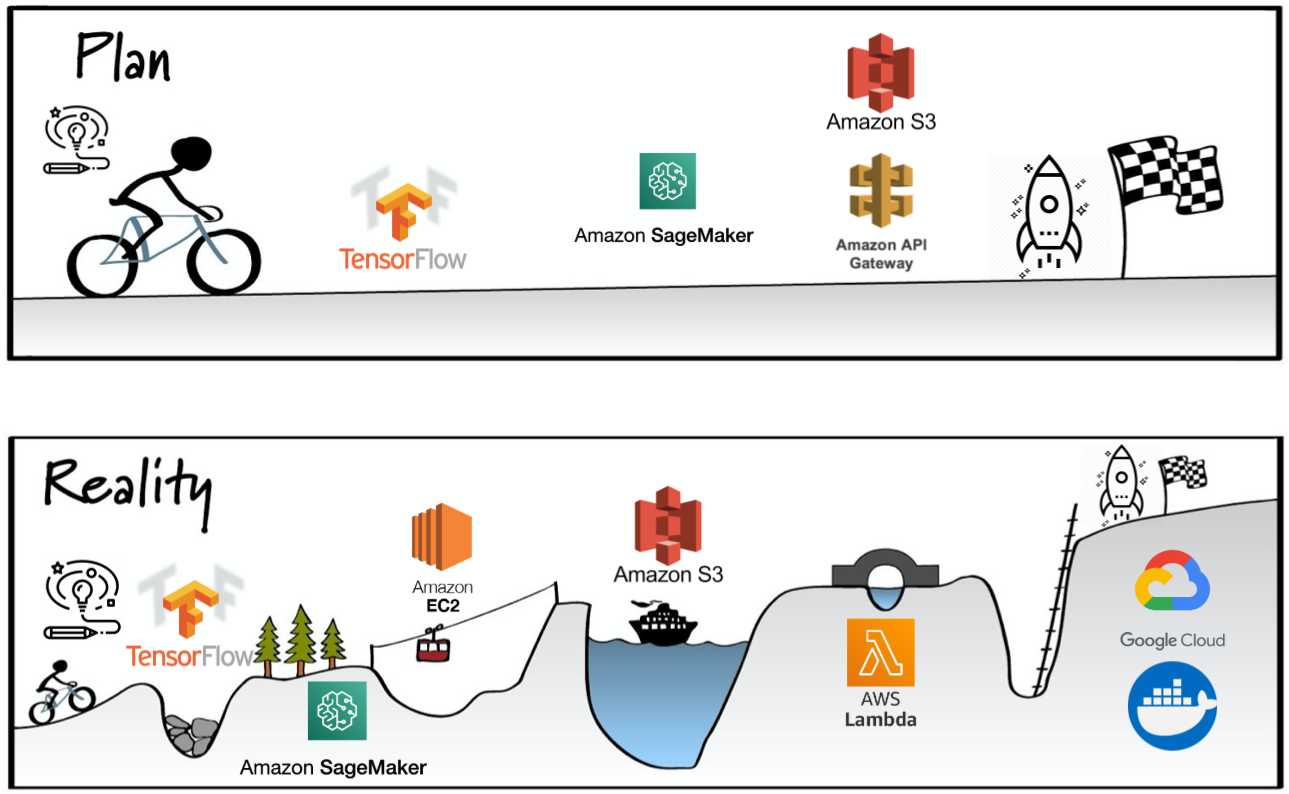
With the above picture you will see a good description of our expectations against the reality. The result of our multiple mistakes and changes led us to the following “final” result:
通过上面的图片,您将很好地描述我们对现实的期望。 我们多次错误和变更的结果使我们得出以下“最终”结果:
- Instead of training a model with our own dataset, we ended up using a trained model with a better dataset; 最终,我们没有使用自己的数据集来训练模型,而是使用了具有更好数据集的训练后模型。
- Instead of porting our back-end to SageMaker, and then to Lambda, we used docker containers to serve a Flask API; 我们没有将后端移植到SageMaker,然后移植到Lambda,而是使用docker容器提供了Flask API;
- Instead of hosting our back-end on AWS, we ended up using Google Cloud and the 300€ provided as part of an account’s free tier. 我们最终没有使用后端在AWS上托管,而是使用了Google Cloud,并将300欧元作为帐户免费套餐的一部分提供。
By doing a self-assessment against our main objectives, we reached the following conclusions:
通过对我们的主要目标进行自我评估,我们得出以下结论:
Follow “state of the art” practices to train our model and deploy our product: Although our solution is not the one we expected, we tried to use the most robust and relevant technology. In that sense, we decided to use a popular and robust trained model rather than our own. Regarding the front-end, it is stored in an S3 bucket served by a CloudFront CDN. This means that tens of thousands of users could access the front-end without having to scale anything on our side. Looking at the back-end, we decided to containerize our flask API and serve it with an NGINX container in order to make our app replicable and portable. We consider ourselves sufficiently satisfied with the result!
遵循“最新技术”实践来训练我们的模型并部署我们的产品: 尽管我们的解决方案不是我们期望的,但我们尝试使用最可靠,最相关的技术。 从这个意义上讲,我们决定使用一种流行且强大的训练模型,而不是我们自己的模型。 关于前端,它存储在由CloudFront CDN服务的S3存储桶中。 这意味着成千上万的用户可以访问前端而不必在我们这边扩展任何东西。 从后端来看,我们决定将Flask API容器化,并与NGINX容器一起使用,以使我们的应用程序可复制和可移植。 我们认为自己对结果足够满意!
Have a running cost of 0€ per month: We actually ended up cheating on this point since our back-end is running in a Virtual Machine in Google Cloud. However, thanks to the free tier account, we will be able to run it for free for 1 year at least. We’ll say that we partially validated this point.
每月的运行费用为0欧元:由于我们的后端在Google Cloud中的虚拟机中运行,因此我们实际上在这一点上作弊。 但是,有了免费套餐帐户,我们至少可以免费运行1年。 我们会说我们部分验证了这一点。
Have a product which could scale “infinitely” thanks to serverless services: We pretty much failed at this point. But we are confident that serverless solutions could still meet our needs in the future. We will document our next steps in a future article soon enough!
得益于无服务器服务,产品可以“无限扩展”:在这一点上,我们几乎失败了。 但是我们有信心,无服务器解决方案将来仍然可以满足我们的需求。 我们将在以后的文章中尽快记录我们的后续步骤!
Build a user-friendly “final product” allowing people to have fun with it without any explanation: We will let you decide for ourselves! Feel free to visit https://www.face2age.app and tell us if the UX is seems appropriate to you!
构建用户友好的“最终产品”,使人们可以在没有任何解释的情况下玩得开心: 我们将让您自己决定! 请随时访问https://www.face2age.app并告诉我们UX是否适合您!
Enjoy the building process: Thankfully, this was the point we were the most successful! We strongly recommend jumping in a small project with a friend or colleague of yours to learn new things!
享受构建过程: 幸运的是,这是我们最成功的一点! 我们强烈建议与您的朋友或同事一起参加一个小项目,以学习新事物!
遗言和下一步 (Last words and what’s next)
During the building process of this project, we noted that the mistakes we kept making were smaller and less time consuming since our ability to find pragmatic solutions grew. Below we listed the lessons learnt from this project:
在该项目的构建过程中,我们注意到,由于我们发现务实解决方案的能力不断增强,我们不断犯下的错误越来越小,所花费的时间也越来越少。 下面我们列出了从该项目中学到的经验教训:
- Before jumping straight into coding, perform multiple google searches and compare other solutions to what you want to make; 在直接进行编码之前,请执行多个Google搜索并将其他解决方案与您要制作的内容进行比较;
- After drafting or architecting a solution, take some time to think about possible limitations and problems that might occur. Usually, these arise whenever you make an assumption without a solid previous experience; and 在草拟或设计解决方案之后,请花一些时间考虑可能的限制和可能发生的问题。 通常,只要您在没有扎实的以往经验的情况下进行假设,就会出现这些情况。 和
- If you have never done something before, avoid feeling overly confident about your plan and multiply your time expectations by 3. 如果您以前从未做过任何事情,请避免对计划感到过度自信,并将时间期望值乘以3。
So whats next?
下一个是什么?
Although we are quite happy with our solution result and the results achieved with this project, we are aware that the solution is far away from being “production-ready” since we are currently hosting our model in a single (and not very performant) Virtual Machine. This means that if our project becomes suddenly popular, it will basically crash. Multiple solutions could be used to ensure the project is scalable for a very limited cost. Below are some of our thoughts:
尽管我们对解决方案的结果以及在该项目中取得的结果感到非常满意,但是我们知道该解决方案远非“可用于生产”,因为我们目前将模型托管在单个(性能不佳)虚拟环境中机。 这意味着,如果我们的项目突然变得流行,它将基本上崩溃。 可以使用多种解决方案来确保该项目可扩展,而成本却非常有限。 以下是我们的一些想法:
- Replace the back-end with an already existing solution. We could for example use AWS Rekognition and have 5000 free monthly predictions. 用现有的解决方案替换后端。 例如,我们可以使用AWS Rekognition并具有5000个免费的每月预测。
- Migrate the back-end to a PaaS product such as AWS ECS or Fargate which would allow us to scale according to demand. However, this solution would translate into higher costs and feels a bit “overkill”. 将后端迁移到PaaS产品(例如AWS ECS或Fargate),这将使我们能够根据需求进行扩展。 但是,此解决方案将转化为更高的成本,并且感觉有些“过头了”。
关于我们 (About us)
I am Jonathan Bernales, a Cyber Security consultant working at Deloitte Luxembourg, I mainly work for the Financial Services Industry and I am passionate about how technology and security can transform industries and create business opportunities over time.
我是在德勤卢森堡(Deloitte Luxembourg)工作的网络安全顾问乔纳森·贝纳莱斯 ( Jonathan Bernales) ,我主要为金融服务业工作,我对技术和安全如何随着时间改变行业和创造商机充满热情。
I am Manuel Cubillo, a Software Engineer who loves technology and the way that it can impact on our lives. I am passionate about artificial intelligence, cloud and software development. I am always looking to learn something new. On my free time, I enjoy sports and reading.
我是Manuel Cubillo ,软件工程师,他热爱技术及其对我们生活的影响。 我对人工智能,云和软件开发充满热情。 我一直在寻找新的东西。 业余时间,我喜欢运动和阅读。
Feel free to get in touch with us shall you have any question or would like to have a tutorial about this project!
如果您有任何疑问或想获得有关该项目的教程,请随时与我们联系!
owin 怎么部署在云中















 208
208

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









