 使用生成对抗网络进行分类
使用生成对抗网络进行分类




 本文探讨了如何利用生成对抗网络(GAN)进行分类任务,通过对抗训练提升分类器的泛化能力,使其适用于实际场景。
本文探讨了如何利用生成对抗网络(GAN)进行分类任务,通过对抗训练提升分类器的泛化能力,使其适用于实际场景。
生成对抗网络用于分类
Co-Authors: Daniel Shin and Kevin Liwen Lin
合著者: Daniel Shin 和林立文
动机:通用AI的目的 (Motivation: The Purpose of Generalizable AI)
The field of computer vision continuously calls for improved accuracy on classifiers. Researchers everywhere are trying to beat the previous benchmark by just some small margins on one particular dataset. We think this trend is great for pushing the edge of human understanding, but we also believe that there is a larger problem that has been largely underexplored— building a generalizable classifier.
计算机视觉领域不断要求提高分类器的准确性。 各地的研究人员都试图在一个特定的数据集上以少量的差距超越先前的基准。 我们认为这种趋势非常有利于推动人类理解的发展,但是我们也相信,还有一个更大的问题尚未得到充分挖掘,那就是建立一个可归纳的分类器。
So, what is a generalizable neural network? And why is generalizability important? Why can’t we just finetune our neural networks every time to a particular dataset, since the specificity allows us to maintain higher overall accuracy for each of those tasks?
那么,什么是广义神经网络? 为什么可概括性很重要? 为什么我们不能每次都将神经网络微调到一个特定的数据集,因为特异性使我们能够为每个任务保持更高的总体准确性?
Generalizability refers to a machine learning model’s resistance to data perturbations that could occur in the real world (i.e random objects in the background, image distortions). The more sensitive it is to randomness, the less generalizable it is. Improving model generalizability allows for models to perform significantly better when we deploy them to solve problems with fully unknown data-distribution.
泛化性是指机器学习模型对现实世界中可能发生的数据干扰(即背景中的随机对象,图像失真)的抵抗力。 它对随机性越敏感,则泛化性就越差。 提高模型的通用性可以使我们在部署模型以解决完全未知的数据分布问题时表现出更好的性能。
This is incredibly important because, in real-world applications when end-users supply us with test-data in real-time, we never know when the underlying data distribution will change! For this reason, it is possible that a breakthrough in generalizing neural models can translate to improvements in performance benchmarks across multiple machine learning tasks such as autonomous driving and voice recognition.
这是非常重要的,因为在实际应用中,当最终用户实时向我们提供测试数据时, 我们永远不知道底层数据的分布何时会改变 ! 因此,神经模型通用化的突破可能会转化为跨多个机器学习任务(例如自动驾驶和语音识别)的性能基准的改进。
Therefore, our group’s goal in this project is to create neural models capable of classifying unseen data with unknown perturbations.
因此,我们小组在该项目中的目标是创建能够对未知扰动未知的数据进行分类的神经模型。
In this article, we will discuss methods of using adversarial examples as training data as well as how to generate them. As a bonus, we will also explore CAM Visualization as a way to explain the adversarial misclassification behaviour at the very end.
在本文中,我们将讨论使用对抗性示例作为训练数据的方法以及如何生成它们。 另外,我们还将探索CAM可视化,作为在最后解释对手错误分类行为的一种方法。
模型设计选择 (Model Design Choices)
Before we started the design process, we considered TensorFlow 2.0 with Keras and PyTorch. Ultimately, we went with TensorFlow with and Keras since it allows for simpler implementations and a wider variety of pre-trained models. We wanted our project to ultimately be more readable and concise.
在开始设计过程之前,我们考虑了带有Keras和PyTorch的TensorFlow 2.0。 最终,我们使用TensorFlow with和Keras,因为它允许更简单的实现和更广泛的预训练模型。 我们希望我们的项目最终更具可读性和简洁性。
Major design choices in our projects include:
我们项目中的主要设计选择包括:
Incorporating Data Augmentation with random flips, random cropping, colour jittering, and common additive Gaussian, Poisson, and Salt-and-Pepper noises.
将数据增强与随机翻转,随机裁剪,颜色抖动以及常见的加性高斯,泊松和椒盐噪声相结合。
Selecting MobileNet v2 as the base model for having very high accuracy to the number of parameters ratio among pre-trained models (see Optimization Choices section), and reasonable model size for Tiny ImageNet, the dataset worked with.
选择MobileNet v2作为基本模型,可以对预先训练的模型之间的参数数量比率具有非常高的准确性(请参阅“优化选择”部分),并且可以使用该数据集的Tiny ImageNet合理的模型大小。
Incorporating Neural Structured Learning (NSL) Adversarial Regularization to improve robustness by injecting adversarial loss in the training process.
结合神经结构化学习(NSL)对抗性正则化,以通过在训练过程中注入对抗性损失来提高鲁棒性。
We also considered implementing TRadeoff-inspired Adversarial DEfense via Surrogate-loss minimization (TRADES) [Zhang et al. 2019], but ultimately left that out for future consideration.
我们还考虑过通过替代损失最小化(TRADES)实施TRadeoff启发的对抗防御 [Zhang et al。 2019],但最终将其留待将来考虑。
对抗性示例生成的先验研究 (Prior Research in Adversarial Example Generation)
Even though recent neural networks for computer vision tasks have reached remarkable accuracy, they are still extremely vulnerable to small, human-imperceptible perturbations.
尽管最近用于计算机视觉任务的神经网络已经达到了惊人的精度,但是它们仍然极易受到人类难以察觉的微小干扰的影响。
Previously researchers have speculated that this is due to the nonlinear components of the neural networks, polarizing those activations (think exploding gradients). However, in Explaining and Harnessing Adversarial Example, the authors argued that this vulnerability is actually due to the linear components of neural networks, namely in ReLU, LSTM. Even in the case of the nonlinear sigmoid function, the model will often have most values in the linear regime (i.e when x are close to 0), further supporting this finding.
以前,研究人员推测这是由于神经网络的非线性成分 ,使这些激活极化(想像爆炸梯度)。 但是,在“ 解释和利用对抗示例”中 ,作者认为此漏洞实际上是由于神经网络的线性组件引起的,即在ReLU,LSTM中。 即使在非线性S型函数的情况下,模型在线性状态下(即x接近0时)通常也将具有大多数值,从而进一步支持了这一发现。

In this paper, the authors also described a fast way to generate adversarial examples along with an adversarial training method, which we used. The authors introduced the Fast Gradient Sign Method (FGSM) to efficiently generate adversarial examples: calculate the gradient with respect to the input, and then perturb the input such that:
在本文中,作者还描述了一种快速生成对抗性示例的方法以及一种我们使用的对抗性训练方法。 作者介绍了快速梯度符号法(FGSM)以有效地生成对抗性示例:计算相对于输入的梯度,然后扰动输入,使得:
input = input + epsilon * sign(gradient)Below is an example of FGSM applied to a logistic regression model trained on MNIST threes and sevens in the original paper.
以下是将FGSM应用于原始论文中以MNIST三分和七分训练的logistic回归模型的示例。

Perturbation was applied directly on sevens and inverted on threes to make the model misclassify sevens. FGSM can be directly incorporated into the loss function, which indirectly results in additional regularization effect.
直接在7上应用摄动,然后在3上倒置摄动,以使模型对7进行错误分类。 FGSM可以直接合并到损失函数中 ,从而间接导致附加的正则化效果。
The authors sited better final model accuracy and increased robustness. The error rate on adversarial example error rate was reduced to just 17.9% from 89.4% in the base model.
作者发现更好的最终模型准确性和更高的鲁棒性。 对抗性示例错误率的错误率从基本模型中的89.4%降低到仅17.9%。
模型设置:培训和验证 (Model Set-up: Training and Validating)
For our model, we used an adversarial wrapper around our model during training time only. We won’t include all the code here, but the general framework should look like this.
对于我们的模型,我们仅在训练期间在模型周围使用了对抗包装。 我们不会在此处包含所有代码,但是常规框架应如下所示。
base = create_model('base', dim, 2, len(classe))
adv_model = nsl.keras.AdversarialRegularization(
adv_model.compile(optimizer=keras.optimizer.SGD,...))There are some hyperparameters that are most important to the wrapper. They are multiplier and step size. Multiplier had a significant influence on regularization, and step size is used to find the adversarial example later on during validation.
有一些对包装器最重要的超参数。 它们是乘数和步长 。 乘数对正则化有很大影响,步长用于以后在验证期间找到对抗性示例。
config = nsl.configs.make_adv_reg_config(multiplier=0.2,adv_step_size=0.2,adv_grad_norm='infinity',
)Training time procedure is basically the same as other Keras models, but make sure that datasets are converted dictionaries instead of tuples since you are feeding the data to the wrapper, not the actual classifier.
训练时间的过程基本上与其他Keras模型相同,但是请确保将数据集转换为字典而不是元组,因为您是将数据馈送到包装器,而不是实际的分类器。
def convert(image, label):return {IMAGE_INPUT_NAME: image, LABEL_INPUT_NAME: label}train_data_adv = train_data.map(convert)
val_data_adv = val_data.map(convert)During validation, be sure to also create a base reference model to make sure that your adversarial wrapper training working. You should see a significantly higher performance by your adversarial model on perturbed data, and only marginally lower performance on unperturbed data.
在验证期间,请确保还创建一个基本参考模型,以确保您的对抗包装训练有效。 通过对抗模型,您应该在扰动数据上看到明显更高的性能,而在未扰动数据上只能看到较低的性能。

Lastly, remember to use the base model defined in the beginning during test time and validation. The adversarial wrapped model should only be used in training time, and even if you save the adversarial wrapped model’s weights using standard Keras API, it will only save the weight of the base model. So make sure you always load the weights into the base model, then add the wrapper or you will have mismatch issues.
最后, 请记住在测试时间和验证期间使用开始时定义的基本模型 。 对抗包装模型只能在训练时使用,即使您使用标准Keras API保存对抗包装模型的权重,也只会节省基础模型的重量。 因此,请确保始终将权重加载到基本模型中,然后添加包装器,否则将出现不匹配问题。
优化选择 (Optimization Choices)
We used SGD in favour of ADAM due to previous experience and papers suggesting SGD is more suitable for CV tasks. For the same reason, instead of deciding the number of epochs to finetune different layers in advance, we move onto high layers as training loss plateaus.
由于以前的经验,我们使用SGD替代了ADAM,并且有论文表明SGD更适合CV任务。 出于同样的原因,我们没有决定提前微调不同层的时期数,而是将高层移至训练损失的平稳状态。
Since we were using Keras as our framework of choice, we also tested the same training method on other networks architectures:
由于我们使用Keras作为选择的框架,因此我们还在其他网络体系结构上测试了相同的训练方法:
- ResNeXt, DenseNet ResNeXt,DenseNet
- NASNet, NASNet Mobile NASNet,NASNet移动
- EfficientNet B2, B4, B6 EfficientNet B2,B4,B6
NASNet tends to overfit due to its high number of parameters, and we found that MobileNet V2 performed the best. EfficientNet was a close contender, but we were unable to use it due to its late addition to TensorFlow (it was only available in tf-nightly, so we had new technical issues almost every day).
NASNet由于其大量的参数而趋于过度拟合,因此我们发现MobileNet V2表现最佳。 EfficientNet是一个竞争激烈的竞争者,但是由于它在TensorFlow中的后期添加而无法使用(它仅在tf-night可用,因此几乎每天都有新的技术问题)。
We will skip over the process of choosing batch sizes and learning rate since methods for optimizing those are ubiquitous in deep learning papers and other medium posts. We will simply note that they played a big role in training performance and varied across different models.
我们将跳过选择批处理大小和学习率的过程,因为优化这些方法的方法在深度学习论文和其他中等职位中无处不在。 我们将简单地注意到,它们在培训绩效中起着重要作用,并且在不同模型中存在差异。
[EXTRA]可解释的AI挑战 ([EXTRA] Explainable AI Challenge)
Current methods of classification ask for inputs and produce classes without any decipherable explanation for contexts or results. Effectively, this makes deep learning algorithms a black-box for researchers and engineers. In this project, we tackled the Explainable AI Challenge by offering our own explanations for adversarial behaviour and general misclassification.
当前的分类方法要求输入并生成类,而没有对上下文或结果的任何可理解的解释。 有效地,这使深度学习算法成为研究人员和工程师的黑匣子。 在这个项目中,我们通过提供自己的对抗行为和一般错误分类的解释来应对可解释的AI挑战 。
For the next few sections, saliency refers to some unique features for a particular input in the context of visual processing. Basically, saliency visualization method allows for emphasis on visually alluring locations on an image that could have “contributed to” neural work making a particular classification decision.
在接下来的几节中, 显着性是指视觉处理环境中特定输入的一些独特功能。 从根本上讲,显着性可视化方法允许重点放在图像上的视觉诱人位置,这些位置可能“有助于”神经工作做出特定的分类决策。
There are many choices for which type of saliency we should visualize. Some examples include linear activations or noise generation using guided propagation, but we don’t discuss them here. We simply changed the last layer to a linear activation to see which pixels had the biggest influence on classification decision. We used keras-vis module. The two saliency maps show the positive gradients and negative gradients respectively.
我们应该可视化哪种显着类型有很多选择。 一些示例包括线性激活或使用引导传播的噪声生成,但我们在此不进行讨论。 我们仅将最后一层更改为线性激活即可查看哪些像素对分类决策的影响最大。 我们使用了keras-vis模块。 这两个显着图分别显示了正梯度和负梯度。
We will note here that keras-vis is slightly outdated and might not work with some versions of TensorFlow 2.0 Keras.
我们将在此处注意到keras-vis有点过时了,可能不适用于TensorFlow 2.0 Keras的某些版本。
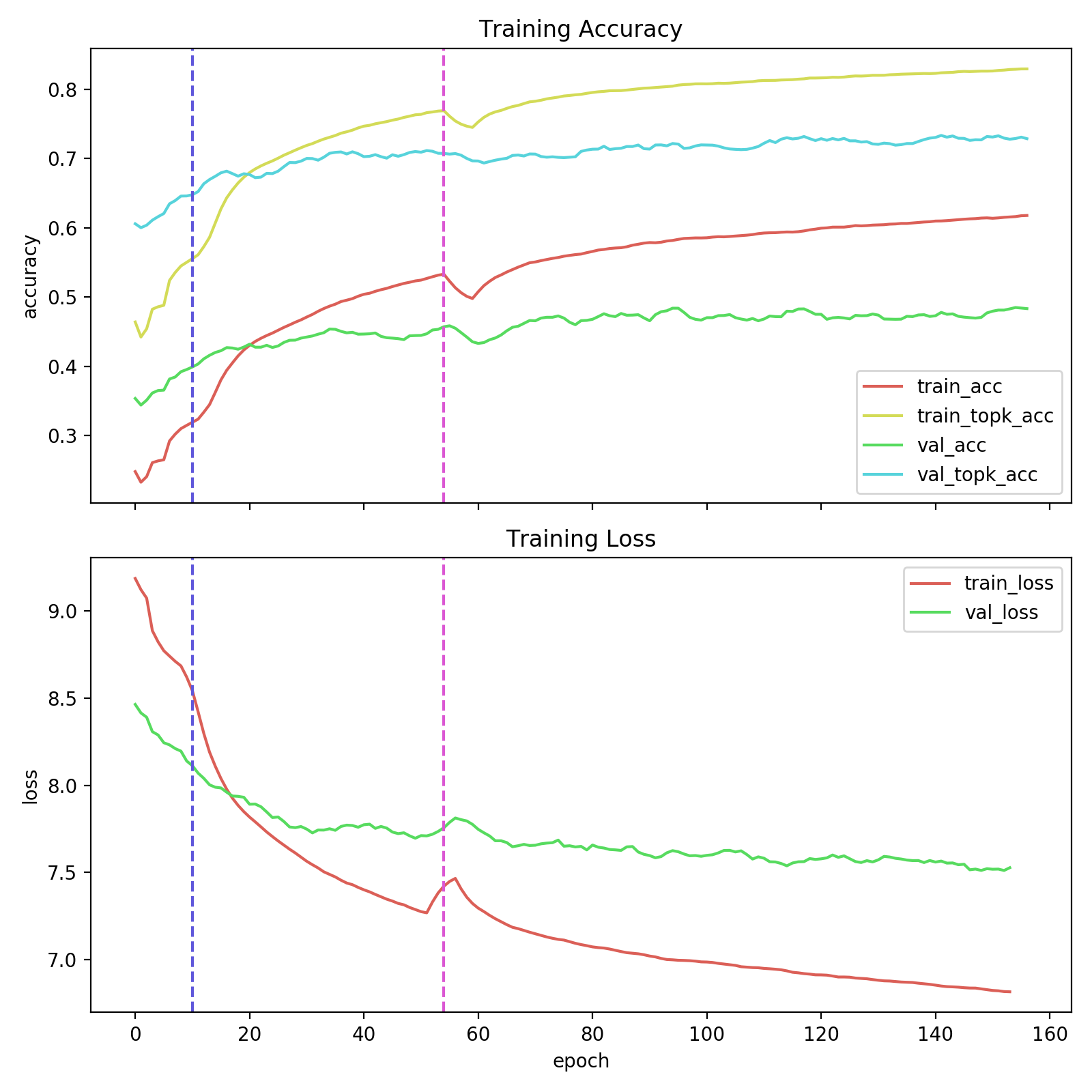
Our model was able to correctly predict the cockroach label. We can see the model was able to do this easily since linear activation maximizations in the last layer clearly show the shape of cockroach.
我们的模型能够正确预测蟑螂的标签。 我们可以看到该模型能够轻松完成此操作,因为最后一层中的线性激活最大化清楚地显示了蟑螂的形状。
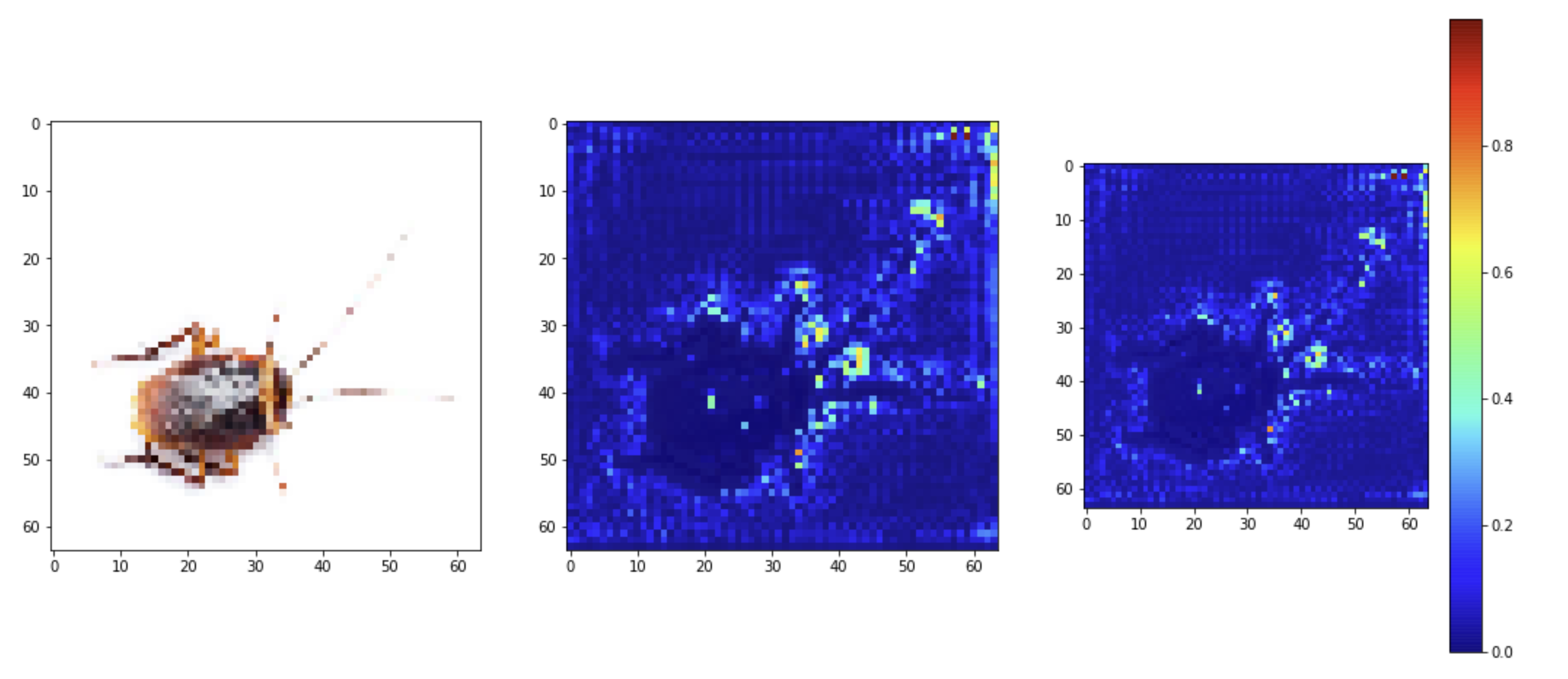
Our model did not classify this object correctly. This can be explained by the fact that Tiny Image Net has generally lower resolution, resulting in similar activations from objects with similar shapes. The misclassification here was Broom (n02906734 in ImageNet). We can also attribute this to our random crops during training data augmentation, where we might have cropped out the broom handle during training.
我们的模型未正确分类此对象。 这可以通过以下事实来解释:Tiny Image Net通常具有较低的分辨率,从而导致形状相似的对象进行了类似的激活。 这里的错误分类是Broom ( ImageNet中的n02906734 )。 我们还可以将其归因于训练数据扩充过程中的随机作物,在训练过程中我们可能已经剪掉了扫帚手柄。
In the following syringe example, the activations from these images are very similar, so our model decided it was a toss between Oboe, Syringe, Broom, and Beer Bottle. These were amongst the top 5 predictions.
在下面的注射器示例中,来自这些图像的激活非常相似,因此我们的模型确定这是在Oboe , Syringe , Broom和Beer Bottle之间进行的折腾。 这些是前5个预测之一。
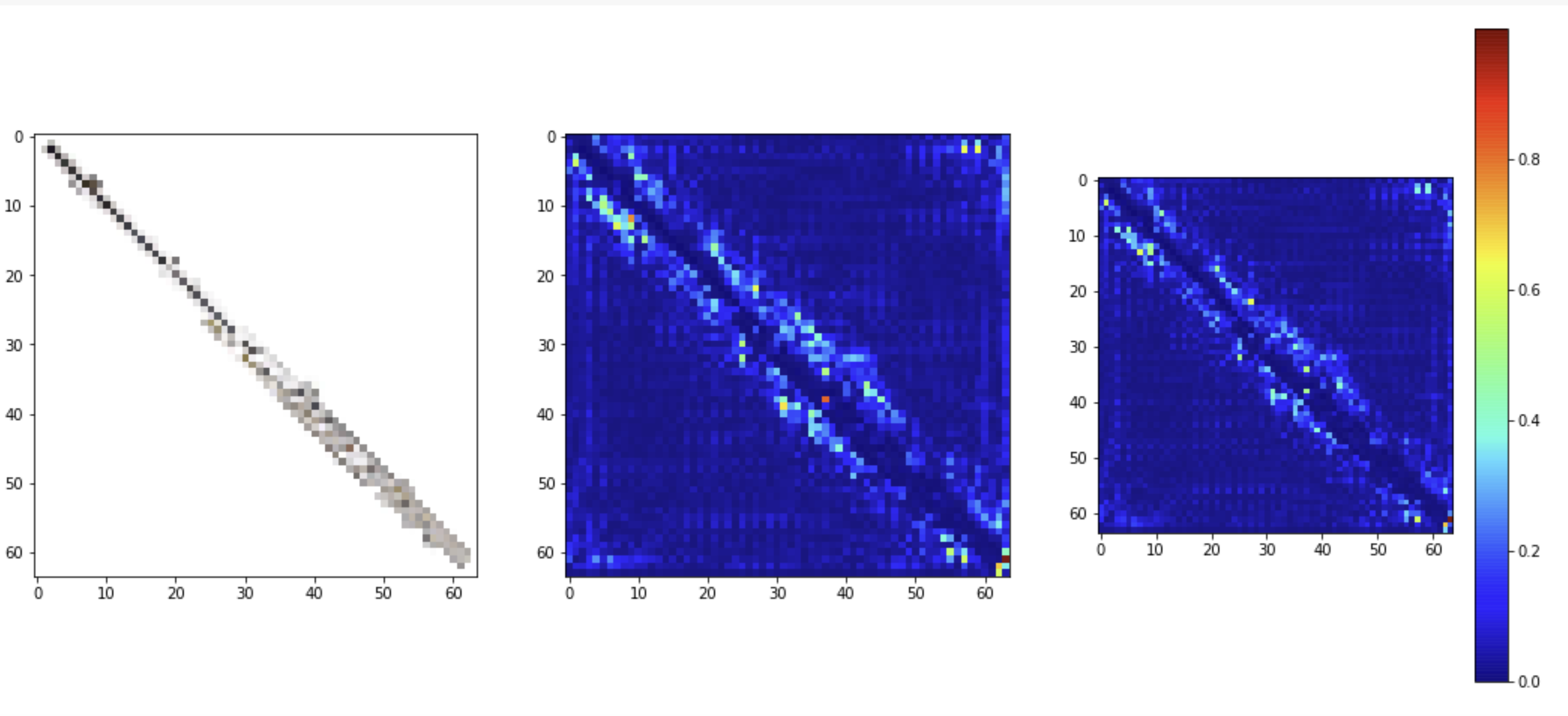
The misclassifications was a Beer Bottle (n02823428), reasonable guess?
错误分类是啤酒瓶(n02823428) ,合理的猜测吗?
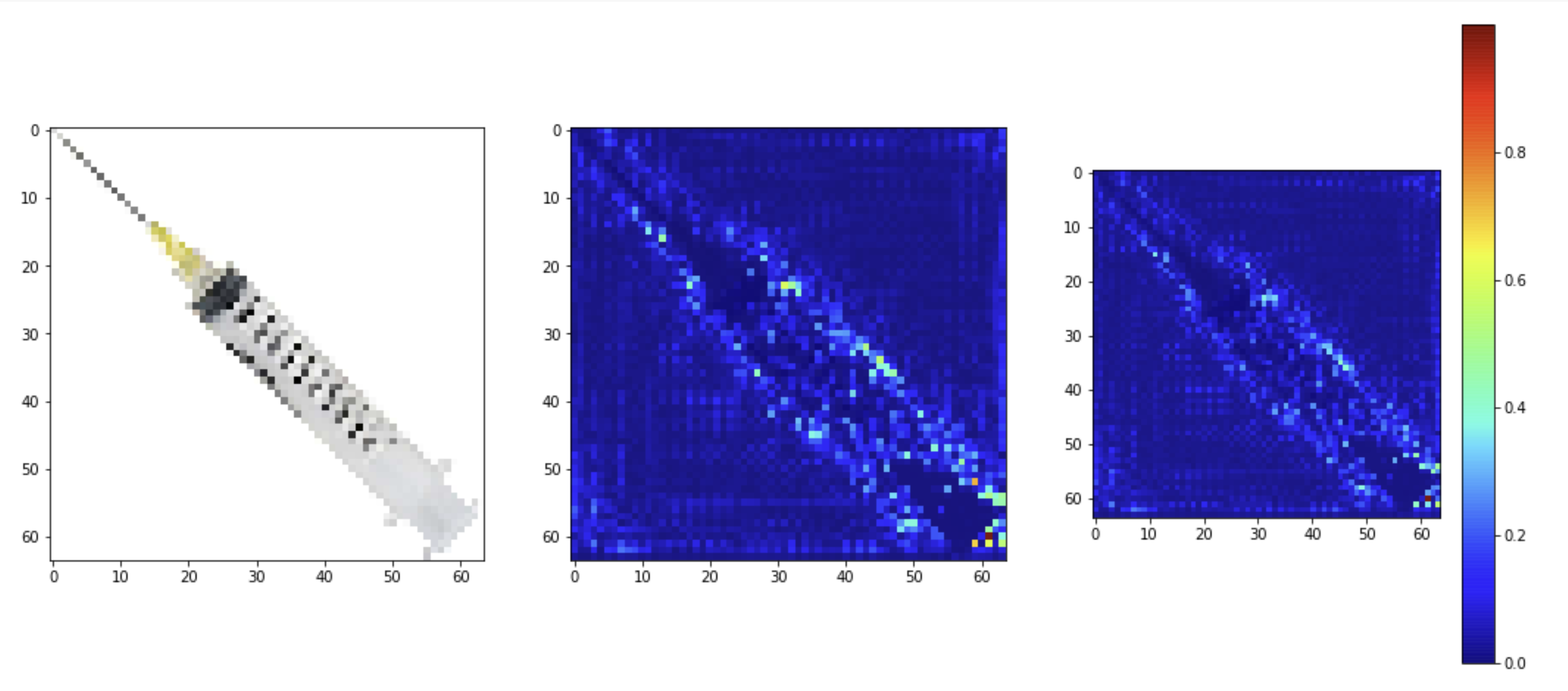
We also visualized some of the adversarial training examples which we generated. The objects are recognizable to humans, but to a neural network, they are often masked with some type of activation nullifications. In the following examples, it is clear that the activations here do not resemble the original object shape in any way as seen earlier.
我们还可视化了我们生成的一些对抗训练示例。 这些对象是人类可识别的,但对于神经网络,它们通常被某种类型的激活无效性所掩盖。 在以下示例中,很明显,此处的激活与前面所见的任何方式都不像原始对象形状。
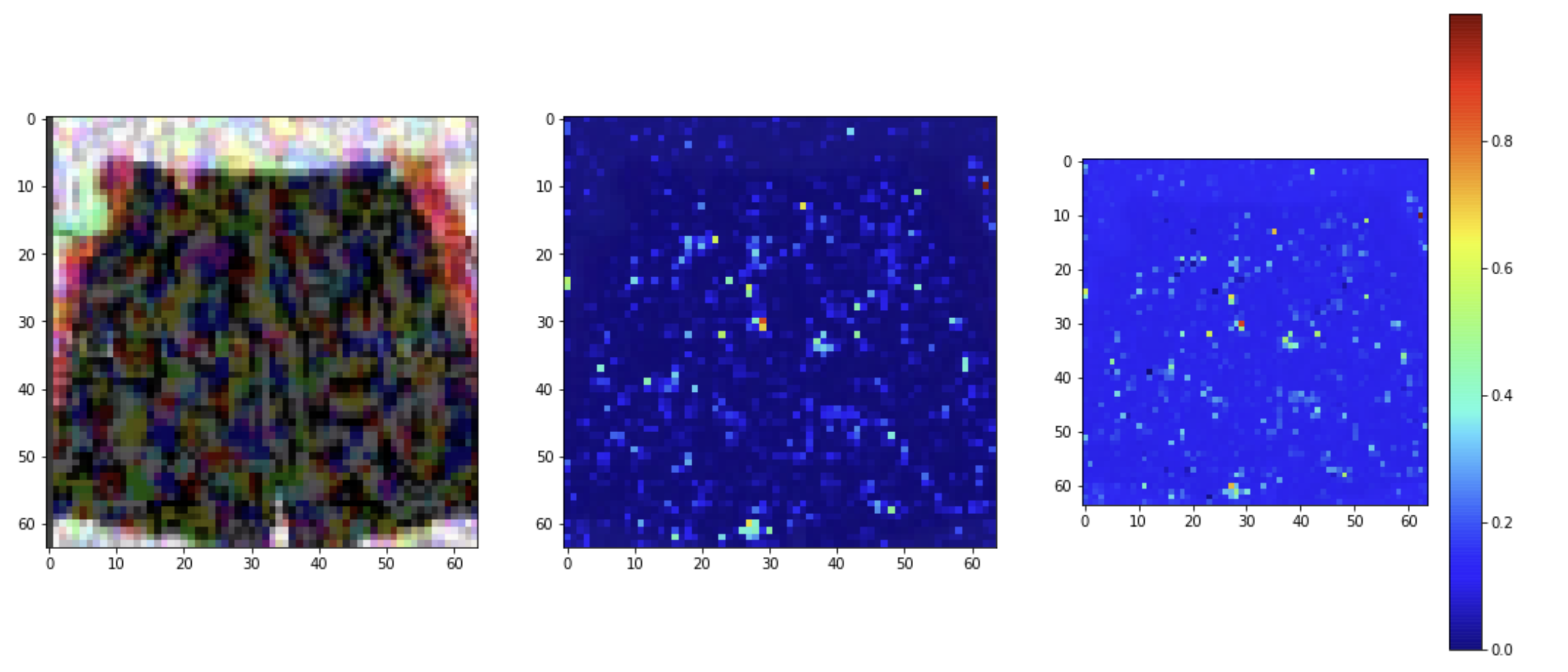
Activation and inhibitions become random and distorted.
激活和抑制变得随机且扭曲。
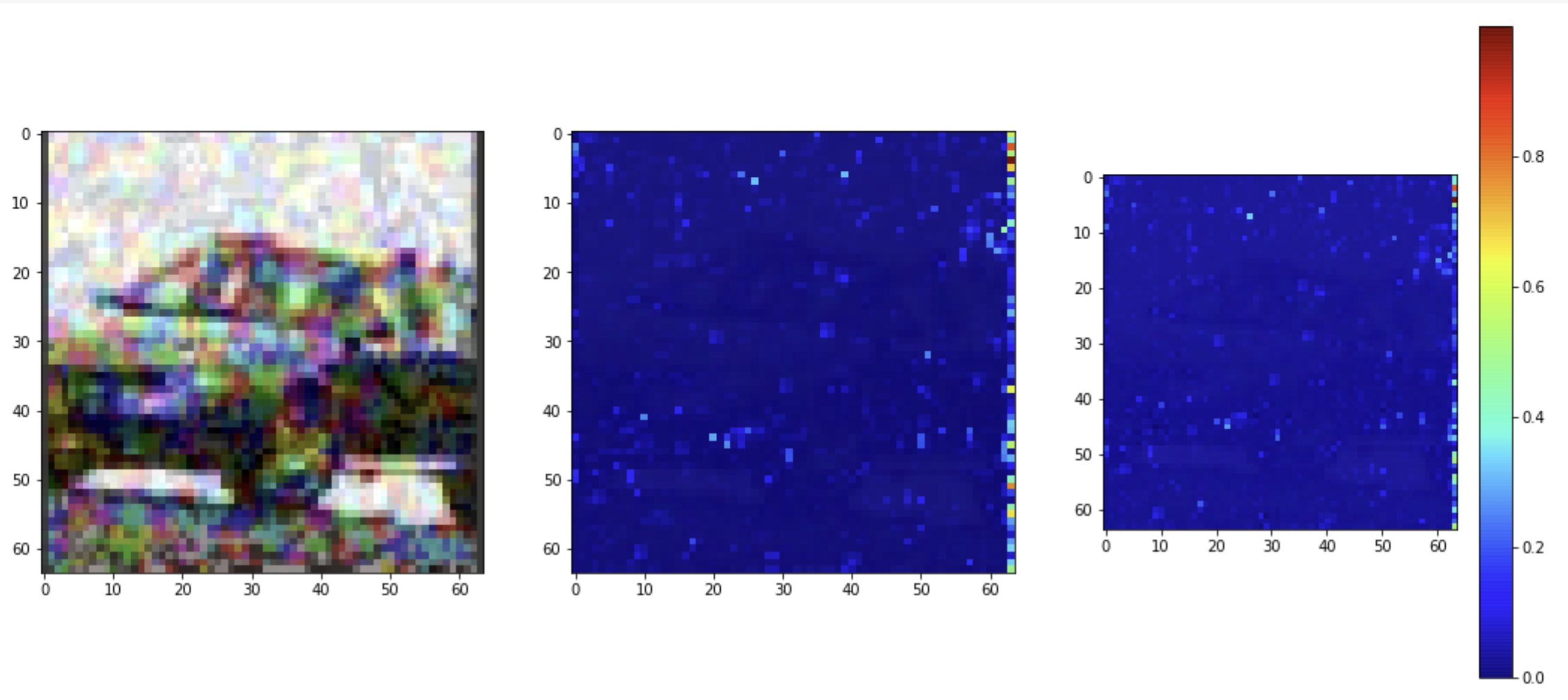
Activation and inhibition are obscured.
激活和抑制被模糊。
生成对抗网络用于分类

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









