





算法偏见是什么
Google advertisements and Netflix recommendations have brought more widespread awareness of algorithms, and how they learn from our behaviours. You may have experienced eerily relevant advertisements pop-up on your feed after googling an item (or even just talking about it). As users of data-collecting applications, our identifying information and behaviours (i.e., data) serve as the input for algorithms, a set of instructions, to perform tasks like generating personalized recommendations or targeted advertisements.
摹 oogle广告和Netflix建议带来的算法更广泛的认识,以及他们从我们的行为是如何学习的。 在对某个项目进行谷歌搜索( 甚至只是谈论它 )后,您可能会在Feed上弹出一些异常相关的广告。 作为数据收集应用程序的用户,我们的识别信息和行为(即数据)充当算法(一组指令)的输入,以执行诸如生成个性化推荐或目标广告之类的任务。
Algorithms are silently automating previously manual decision-making processes that have allowed for scalability and optimization of tasks. However, when algorithms are built upon biased data, the byproduct of discriminatory decision-making processes, they inherit that bias. In benign applications like content recommendations, the impact of a biased algorithm is trivial* — perhaps Fuller House would be recommended when you actually wanted to watch Beyoncé: The Formation World Tour for the tenth time. In more pervasive applications the impact, however, can be fatal. This blog post serves to signify the importance of data literacy in the Black community and highlight how unregulated, biased algorithms may amplify the voice of discrimination and disparity.
算法无声地自动化了以前的手动决策过程,从而实现了可伸缩性和任务优化。 但是,当算法基于有偏见的数据(歧视性决策过程的副产品)建立时,它们会继承该偏见。 在诸如内容推荐之类的良性应用中,偏差算法的影响微不足道*-也许当您真正想第十次观看《 碧昂斯:编队世界巡回演唱会》时,就会推荐富勒之家 。 但是,在更普遍的应用中,影响可能是致命的。 这篇博客文章旨在表明数据素养在黑人社区中的重要性,并强调不受监管的,有偏见的算法如何放大歧视和差距的声音。
*Triviality is subjective but was used in this context to draw a distinction between the ability to cause bodily harm or not.
*琐碎性是主观的,但在这种情况下用于区分是否造成身体伤害的能力。
偏色数据 (Bias-colored data)
As humans, we develop our sense of truth, or intuition, from our own experiences, those of others shared with us, and the media we choose to engage. These are all data points that shape our perspective of the world. Well, algorithms also develop intuition, but their’s is derived from data. Let’s work through an example to illustrate how an algorithm develops intuition from data. Figure 1 contains pairs of input (x) and output (y), respectively. The output is a function, f, of the input; in this example, when any x-value is multiplied by 4 plus 3, the result is y (i.e., y=4x+3). You might have recognized this function as the equation of a line, y=mx+b, which is the basis of linear algorithms. If the algorithm only looked to the first data point in Figure 1 for its intuition, it would have incorrectly defined its function as y=x+3. Additionally, you may have noticed the x-values are all positive, even integers, and so we are making the assumption that negative and odd x-values will also follow the same linear trend, which may or may not be valid. This represents the importance of both data quantity and quality when building an algorithm. It is essential to have representative data otherwise it will develop its intuition from a biased dataset that otherwise does not consider the potential disparities of any underrepresented data points. The function derived from the data is analogous to intuition for an algorithm. If you need to brush up on that new math I recommend this course.
作为人类,我们从自己的经验,与我们分享的其他经验以及我们选择参与的媒体中发展出对真理或直觉的认识。 这些都是塑造我们对世界的看法的数据点。 好的,算法也会发展直觉,但是它们是从数据中得出的。 让我们通过一个示例来说明一个算法如何从数据中发展直觉。 图1分别包含输入对(x)和输出(y)。 输出是输入的函数f ; 在此示例中,当任何x值乘以4加3时,结果为y(即y = 4x + 3)。 您可能已经将此函数视为直线方程y = mx + b ,它是线性算法的基础。 如果该算法仅凭直觉看图1中的第一个数据点,则它的函数定义为y = x + 3是错误的。 此外,您可能已经注意到x值都是正数,甚至是整数,因此我们假设负x值和奇数x值也将遵循相同的线性趋势,这可能有效也可能无效。 这代表了构建算法时数据量和质量的重要性。 必须具有代表性的数据,否则它将从有偏见的数据集中发展其直觉,否则该数据就不会考虑任何代表性不足的数据点的潜在差异。 从数据得出的函数类似于算法的直觉。 如果您需要复习该新数学,我建议您参加本课程 。
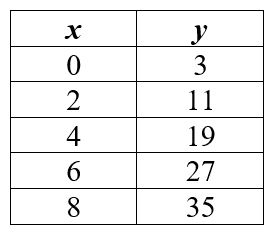
As illustrated, there is tremendous significance to the data that is utilized for training an algorithm. This can be seen through Microsoft’s AI chatbox which learned racism in less than a day from Twitter. The consequences of biased algorithms have already begun to be realized such as the case of facial recognition algorithms misgendering and misidentifying Oprah Winfrey, Michelle Obama, and Serena Williams. The potential ramifications become horrific when you consider the possible integration of these algorithms into autonomous vehicles that have already taken a life. Biased data is inevitable because society and people are inherently biased; it reinforces why regulation and representation are vital to address the negative impacts of biased algorithms.
如图所示,用于训练算法的数据具有极大的意义。 这可以通过微软的AI聊天箱看到,该聊天箱在不到一天的时间内就从Twitter了解了种族主义。 偏见算法的后果已经开始被认识到,例如面部识别算法性别不正确和识别不正确的情况,例如奥普拉·温弗瑞,米歇尔·奥巴马和小威娜。 当您考虑将这些算法集成到已经死亡的自动驾驶汽车中时,潜在的后果将变得可怕。 有偏见的数据是不可避免的,因为社会和人民天生就有偏见。 它强调了为什么调节和表示对于解决偏差算法的负面影响至关重要。
The development of algorithms is just one step in a long and far-reaching process in the lifecycle of data; agnostic of any particular industry or company. Each level represents another opportunity for bias to be introduced which is why it is quintessential to have diversity in the people making these decisions and standardized regulation as guardrails to protect marginalized communities.
算法的开发只是数据生命周期中一个漫长而深远的过程中的一步。 与任何特定行业或公司无关。 每个级别都代表了另一个引入偏见的机会,这就是为什么在决策者和标准化法规制定人员中要有多样性来保护边缘化社区是最典型的原因。
- Funding 资金
- Motivation 动机
- Project Design 项目设计
- Data Collection and Sourcing 数据收集与采购
Algorithm Development
算法开发
- Interpretation 解释
- Communication 通讯
“梦Night药” (‘Medicine for a Nightmare’)
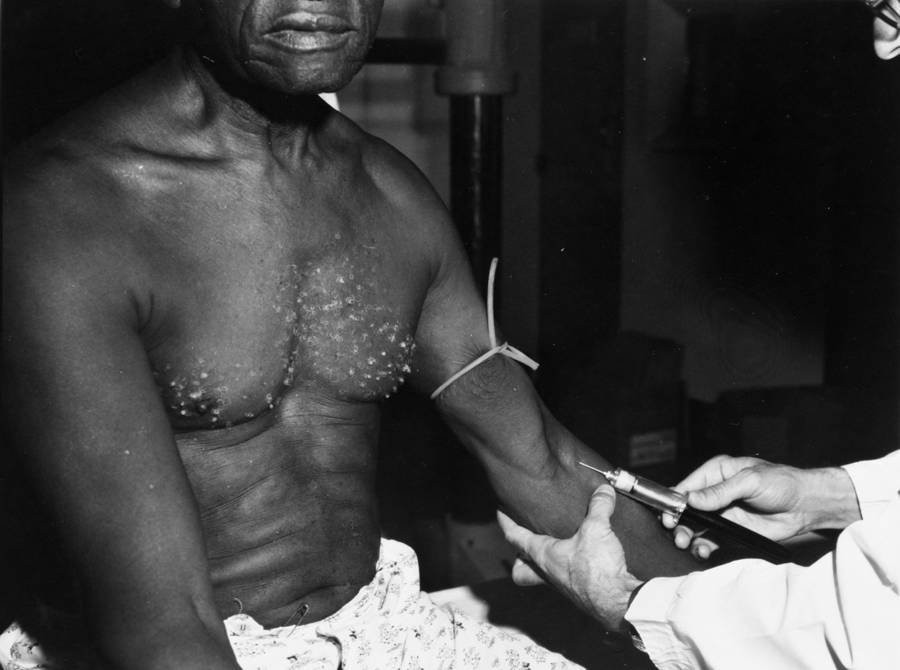
Taking a deeper look into a potentially malignant application of biased algorithms let’s turn to a field with a history of discriminatory practices — Healthcare. Until the 1970s, Black individuals were intentionally exposed to syphilis yet never treated under the Tuskegee Study. Even more, there are inaccurate and harmful stereotypes shared amongst medical professionals including the myth that Black individuals are less prone to pain. Furthermore, there is a staggeringly disproportionate mortality rate in Black women giving birth, in fact, Black women are 2–3x more likely to die during childbirth when compared to White women. The racial and gender bias that persists within Healthcare is one that will assuredly be represented within its resulting data collection.
更深入地研究偏见算法的潜在恶性应用,让我们转向具有歧视性实践历史的领域-医疗保健。 直到1970年代,黑人个体被故意暴露于梅毒,但从未受到塔斯克吉研究的治疗。 更甚者,医学专业人士之间存在不准确和有害的刻板印象,包括黑人个体不易遭受疼痛的神话。 此外, 黑人妇女分娩的死亡率惊人地不成比例 ,实际上,与白人妇女相比,黑人妇女在分娩时死亡的可能性要高2–3倍。 医疗保健部门内部存在的种族和性别偏见肯定会在其最终数据收集中得到体现。
Kimberly Deas, Health Informaticist, and current Ph.D. candidate shared her personal and professional experience of health disparities. She highlighted the distrust of medical professionals within the Black community coupled with the lack of Black representation within the field, to be major influencers of biased data. “Although Black people make up 13% of the U.S. population, less than 5% of physicians are Black”. Kimberly highlighted an algorithm designed to screen skin cancer which has had difficulty in accurately identifying positive cases of cancer in Black individuals, especially when darker-skinned. Thus, we need more representation to break the chain of racial inequality in these decision-making processes and mandated regulation to ensure the presence of ethical bias within data is no longer ignored.
健康信息学家Kimberly Deas ,现任博士学位。 候选人分享了她在健康方面的个人和专业经验。 她强调了黑人社区内医疗专业人员的不信任,以及该领域内缺乏黑人代表,这是造成偏见数据的主要影响因素。 “尽管黑人占美国人口的13%,但不到5%的医生是黑人”。 金伯利(Kimberly)着重介绍了一种旨在筛查皮肤癌的算法,该算法难以准确识别黑人个体的阳性癌症病例,尤其是皮肤较黑的患者 。 因此,在这些决策过程和强制性监管中,我们需要更多的代表来打破种族不平等的链条,以确保数据中不再存在道德偏见。
放大黑色声音 (Amplifying Black voices)
As non-data professionals, you makeup roughly 99.9% of the U.S. population, but nonetheless will be impacted by algorithms. With an understanding of data, ethics, and politics you can help to influence necessary change to protect our community. We need stricter regulations around how companies collect and utilize our personal data and harsher penalizations for the misuse of data. To demand change, we must first improve data literacy, fund our public school systems, and vote in Local and State-level elections to ensure we are better represented in impactful fields.
作为非数据专业人员,您构成了大约99.9%的美国人口,但是仍然会受到算法的影响。 通过了解数据,道德和政治,您可以帮助影响必要的更改以保护我们的社区。 我们需要关于公司如何收集和利用我们的个人数据的更严格的法规,以及对滥用数据的严厉处罚。 要要求变革,我们必须首先提高数据素养, 为我们的公立学校系统提供资金 ,并在地方和州一级的选举中投票,以确保我们在有影响力的领域能有更好的代表。
The Data Literacy Project seeks to inform individuals on data and is a great place to start your journey towards data literacy. If you are interested in a career in the data field, Correlation-One is an online certificate course for introductory data analytics focused on communities that are underrepresented in data. Additionally, there are online communities meant to support those in data careers including #BlackTechTwitter, #BlackinData, and BlackTIDES [Technology, Informatics, Data, Epidemiology, Social Sciences] founded and led by DataKimist. We must amplify our voices to ensure that we are no longer an outlier in data.
数据素养项目旨在为个人提供有关数据的信息,并且是开始您进行数据素养之旅的好地方。 如果您对数据领域的职业感兴趣, Correlation-One是在线证书课程,介绍数据分析,重点是数据中代表性不足的社区。 此外,还有一些在线社区旨在支持那些从事数据职业的人们,包括由DataKimist创建和领导的# BlackTechTwitter,#BlackinData和BlackTIDES [技术,信息学,数据,流行病学,社会科学]。 我们必须扩大声音,以确保我们不再是数据的异常者。
“S
“ S

This blog was inspired by my Aunt, ‘Titi’ Lisa Pagan, who on August 12th, 1991 passed away due to medical malpractice at the age of 34. She went into the doctor’s office for a minor infliction and was wrongfully prescribed medication for HIV. My aunt developed hepatic steatosis (excess fat in the liver) which silently evolved into cirrhosis within a few months. It was a case of mistaken identity between Lisa and another Puerto Rican woman with a similar name who was HIV-positive. Both women died due to the negligence of medical professionals and the history of discrimination that is so prevalent within Healthcare. Rest In Peace a beloved Mother, Daughter, Sister, and Aunt — Lisa Pagan.
该博客的灵感来自我的“蒂蒂”姨妈丽莎·帕根(Tisa),丽莎·帕根(Lisa Pagan)于1991年8月12日因医疗事故去世,享年34岁。 我的姨妈患上了肝脂肪变性(肝脏中脂肪过多),并在几个月内无声地发展为肝硬化。 这是一起丽莎(Lisa)和另一名波多黎各妇女(艾滋病毒呈阳性)的身份错误的案例。 两名妇女均因医疗专业人员的疏忽以及医疗保健中普遍存在的歧视史而死亡。 亲爱的母亲,女儿,姐妹和姨妈莉萨·帕根(Lisa Pagan)在和平中休息。
图书推荐 (Book Recommendations)
算法偏见是什么

















 1246
1246

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









