





 本文探讨了数据处理中的关键概念——验证数据和测试数据。通过翻译自Medium的文章,了解如何在数据科学项目中正确使用这些数据集以确保模型的准确性和泛化能力。
本文探讨了数据处理中的关键概念——验证数据和测试数据。通过翻译自Medium的文章,了解如何在数据科学项目中正确使用这些数据集以确保模型的准确性和泛化能力。
验证数据和测试数据
from sklearn.model_selection import train_test_split
from sklearn.model_selection import train_test_split
xtrain,xvalid,ytrain,yvalid = train_test_split(df_raw,train_size=0.8,test_size=0.2)
xtrain,xvalid,ytrain,yvalid = train_test_split(df_raw,train_size=0.8,test_size=0.2)
I have either scared the people who haven’t used sklearn or grabbed the attention of the “ML enthusiasts”. For the former, I would say just bear with me and to the latter, well, maybe you can learn a new perspective on data splitting here!
我或者已经吓坏了没有使用sklearn的人,或者已经 引起了“机器学习爱好者”的注意。 对于前者,我会说,请忍受,对后者,好吧,也许您可以在此处学习有关数据拆分的新观点!
Why split? What are those lines really doing? What is its need? Can we make a custom split function? What would that be like?
为什么要分裂? 这些线到底在做什么? 有什么需要? 我们可以制作自定义拆分功能吗? 那会是什么样的?
All good things for those who wait.
对那些等待的人来说都是美好的事物。
I have been pursuing the fast.ai course, Introduction to Machine Learning for Coders, made available by the amazing professors Rachel Thomas and Jeremy Howard which is based on the fastai library and built upon the top down approach of teaching. It has been an incredible learning experience so far and I would love to share some of the invaluable insights about machine learning that were acquired.
我一直追求的fast.ai过程中, 介绍机器学习的程序员 ,以惊人的教授提供雷切尔·托马斯和杰里米·霍华德这是基于fastai库 ,在自上而下的教学方法构建。 到目前为止,这是一次令人难以置信的学习体验,我很乐意分享一些关于机器学习的宝贵见解 。
Well coming back to our topic. Why split? But more importantly, Split what? Well, for anyone who has a faint idea of data processing for Machine Learning Algorithms would know it is a trivial question.
好了回到我们的话题。 为什么要分裂? 但更重要的是, 拆分是什么? 好吧,对于任何对机器学习算法的数据处理了解不清的人,都会知道这是一个微不足道的问题。
我们分割数据。 (WE SPLIT DATA.)
Machine Learning is dependent upon data. Period. It is the data that we have which makes a machine learn. It can range from audio snippets to distinguish between different species of birds to multiple attributes describing a person who is applying for loan.
机器学习取决于数据 。 期间 。 是我们拥有的数据使机器学习。 它的范围从音频片段到区分不同种类的鸟类,再到描述申请贷款人的多种属性。
Every machine learning algorithm requires a data set with which is trains on and a data on which it is tested. Think of it like a child learning different animal names. How does he or she learn? Let us see
每个机器学习算法都需要一个训练的数据集和一个对其进行测试的数据。 可以把它想象成一个学习不同动物名字的孩子 。 他或她如何学习? 让我们看看
The images which are labelled along with pictures in the textbook can be thought of as the training data for the child. The child looks at the image features and a person who knows what animal it is, pronounces it. This makes a neural association with the child’s brain that for example an image consisting of black and white stripes on an orange body, along with a tail and some whiskers, is a “Tiger”.
可以将教科书中标有图片的图像视为孩子的训练数据。 孩子看着图像特征,然后一个人知道它是什么动物,然后发音。 这与孩子的大脑形成了神经联系,例如,由橙色身体上的黑白条纹,尾巴和一些胡须组成的图像就是“老虎”。
Now what if we show the child an image of a Tiger but with a different orientation; this would be a test data point for the child. This is because, then, the child would not have any label to remind him or her that it is in fact a Tiger. The above analogy works in tandem with machine learning too. Just the way of interpretation by the computer would be different. For instance, the color distribution in the image, the brightness of each pixel and so on.
现在,如果我们向孩子展示老虎的图像,但方向不同,该怎么办? 这将是孩子的测试数据点。 这是因为,那么孩子将没有任何标签来提醒他或她实际上是老虎。 以上类比也与机器学习一起工作。 只是计算机的解释方式会有所不同。 例如, 图像中的颜色分布,每个像素的亮度等等。
Now we know just what are training and test data sets. Why do we split? This is because we want to know how accurate our model is. Again referring to the above analogy, unless a child is able to recall the names of the animals without their respective tags, it means that he/she does not remember them well.
现在我们知道什么是训练和测试数据集。 我们为什么分裂? 这是因为我们想知道模型的准确性。 再参照上面的比喻,除非孩子是能够回忆起动物的名称 ,而不其各自的标签,就意味着他/她不记得他们。
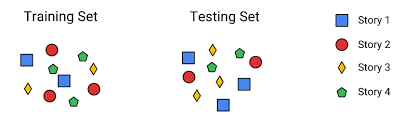
Now that we know what training and test data is let us see how they are generated. Suppose you have a 100 labelled images of cats and dogs and you want to train a model which is able to distinguish between the two. A good way to produce a training and test data set, **here**, is to SPLIT the data into random samples of 80 and 20.(Random sampling works here but why it wouldn’t work on data sets is another story)
现在我们知道了什么训练和测试数据,让我们看看它们是如何生成的。 假设您有100张带有标签的猫和狗的图像,并且您想训练一个能够区分两者的模型。 一个好方法产生的培训和测试数据集,** **在这里 ,是将数据分割 成80和20随机抽样(随机抽样在这里工作,但为什么它不会对数据集的工作是另一回事)
You may ask why 80 and 20? It is just a rule of thumb. You can also try with various other ratios such as 70/30 , 60/40 but just remember to have more data in the training set so that your model has enough data to actually predict results for your testing data.
您可能会问为什么80和20 ? 这只是一个经验法则。 您还可以尝试使用其他各种比率,例如70/30,60/40,但要记住要在训练集中包含更多数据,以便模型具有足够的数据来实际预测测试数据的结果。
Now we can successfully answer what the second line of our code is doing.
现在,我们可以成功回答代码第二行在做什么。
The train_test_split function returns to us 4 variables. The training and testing data for our independent data and the training and testing data for our dependent data. Think of independent and dependent data here as the images and their labels. A key point to note is that it uses randomisation to select a data point to be in a particular set(training or testing). Another thing to note is that the distributions of data are not changed after we have split into test and training sets. Here is an example from a notebook I created to classify wine quality.
train_test_split函数返回给我们4个变量 。 我们的独立数据的培训和测试数据以及我们的依存数据的培训和测试数据。 在这里将独立和相关的数据视为图像及其标签。 需要注意的关键点是,它使用随机化来选择要归入特定集合(训练或测试)的数据点。 要注意的另一件事是,在将数据分为测试集和训练集之后,数据的分布不会改变。 这是我创建的用于对葡萄酒质量进行分类的笔记本中的一个示例。
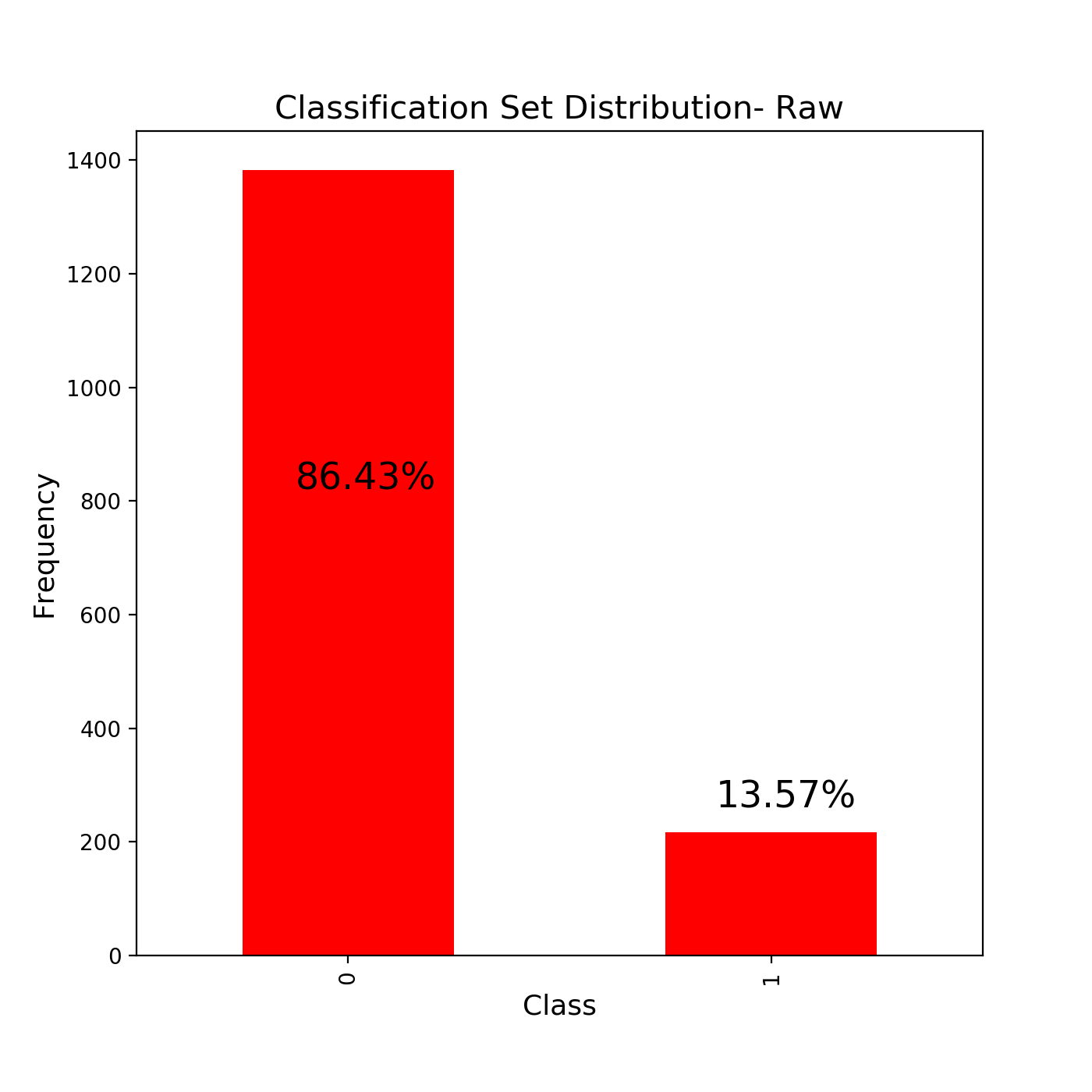
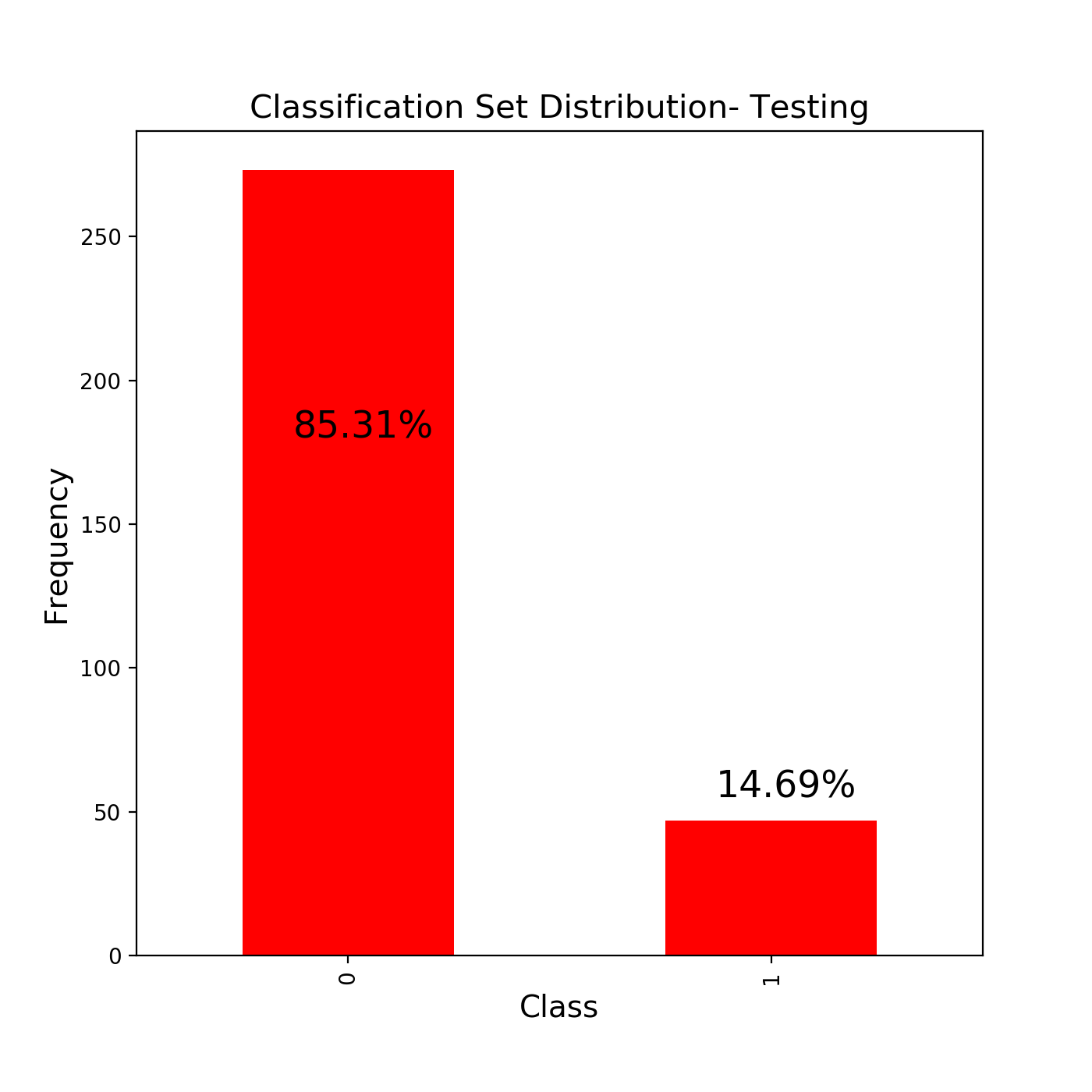
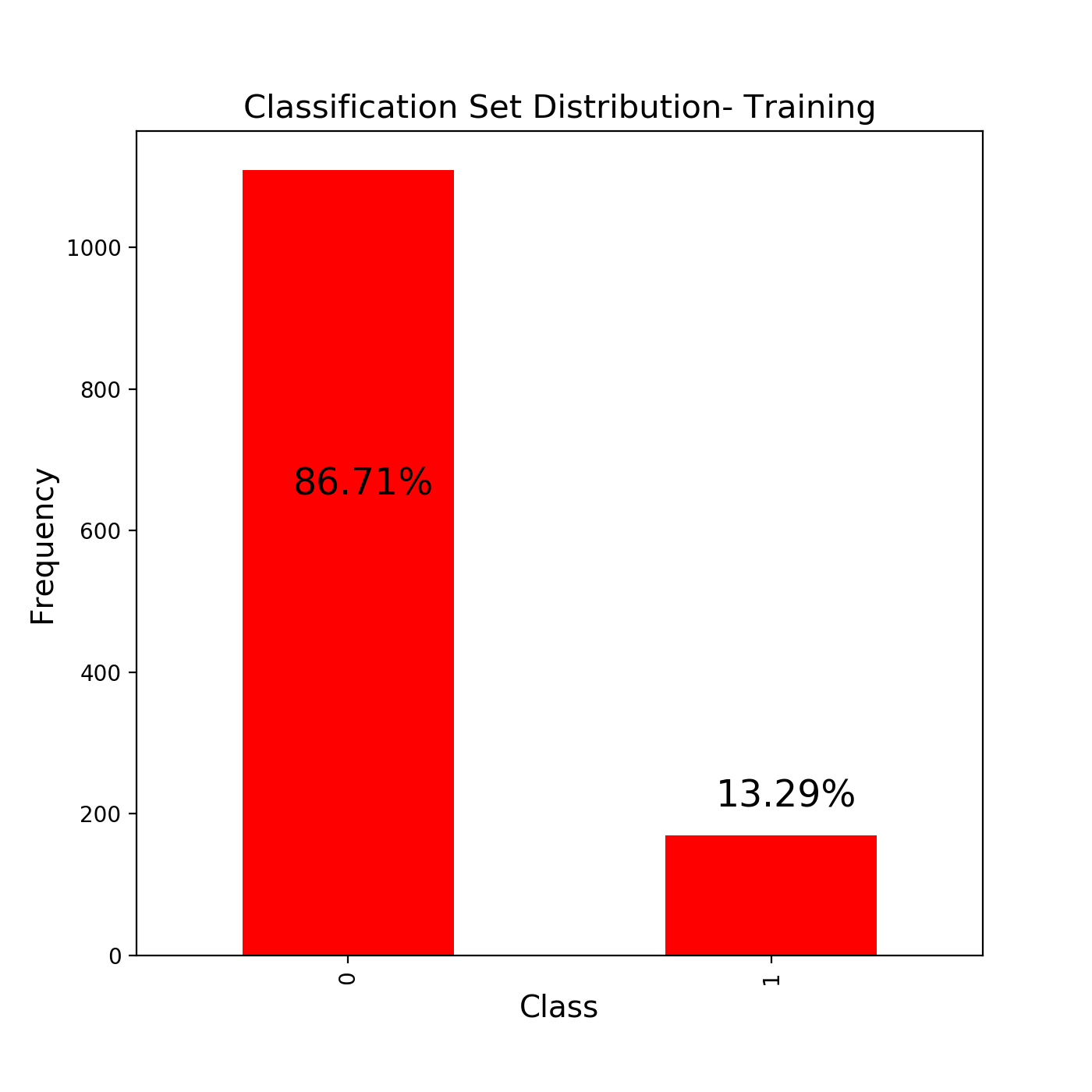
It can be clearly seen that the distribution of the classes does not change very much in both the training and the test sets. This basically is all that little piece of code does but be warned. This type of random splitting of data only works in the data sets where there is NO TIME SERIES.
可以清楚地看到, 在培训和测试集上,班级的分布都没有太大变化。 这基本上是一小段代码所要做的 ,但是要加以警告。 这种类型的数据随机拆分仅适用于没有时间序列的数据集。
What do I mean by a Time Series? Say I want to predict the next month sales for my store or what the accident rate is going to be in my city in the next month. This means that we have a temporal variable( temporal just means relating to time) involved in our data namely the date and we want to predict the dependent variable on a later date.Now imagine if you randomly sampled your data for a time series analysis. This would really mess up with your objective as you want to predict the dependent variable at a LATER DATE. But random sampling would produce a random time series.
时间序列是什么意思? 假设我想预测下个月商店的销售量,或者下个月我所在城市的事故发生率。 这意味着我们有一个时间变量(与时间有关的时间只是手段) 参与我们的数据 即日期 ,我们希望在以后的日期预测因变量。 现在,假设您是否随机采样数据以进行时间序列分析。 当您要在以后日期 预测因变量时,这确实会弄乱您的目标。 但是随机采样会产生随机的时间序列。
So it is always advisable to not use train_test_split blindly. A better way to create a test sample would sort the data on the basis of date and to train on all but the last month or week of data. This excluded subset should now be used as the testing set.
因此,始终建议不要盲目使用train_test_split。 创建测试样本的更好方法是根据日期对数据进行排序,并对除最后一个月或一周之外的所有数据进行训练。 现在应该将此排除的子集用作测试集。
Okay you have made a training set, trained your model corresponding to the best accuracy on your given test set and deployed it to production or tried to predict for some new data.What if it fails?
好的,您已经建立了训练集,对与给定测试集上的最佳精度相对应的模型进行了训练,并将其部署到生产中或试图预测一些新数据。 如果失败了怎么办?
If your model has failed to predict for new data it is probably because it overfit. Overfit? It just means that it tried to predict the results to such a great accuracy in the test set that,well, it is only capable of predicting inside it and not outside. The following image would make it clearer.
如果您的模型无法预测新数据,则可能是因为它过拟合。 过度适合吗? 这只是意味着它试图在测试集中以非常高的准确性预测结果,因此,它只能在内部进行预测,而不能在外部进行预测。 下图将使其更清晰。
This is the time when the concept of validation set comes in. So, as the the name suggests, a validation set is like the first layer of checking or validating that our model generalizes well before we move on to the test sets. Validation sets are created with our training data only as can be seen in the below image and they provide a method of evaluation of our models by providing different data samples to test on and not just with different time series.
这是验证集的概念出现的时候。因此,顾名思义, 验证集就像在我们进入测试集之前检查或验证模型的泛化能力的第一层一样。 验证集仅使用我们的训练数据创建,如下图所示,它们通过提供不同的数据样本进行测试,而不仅仅是使用不同的时间序列 ,从而提供了一种评估模型的方法。
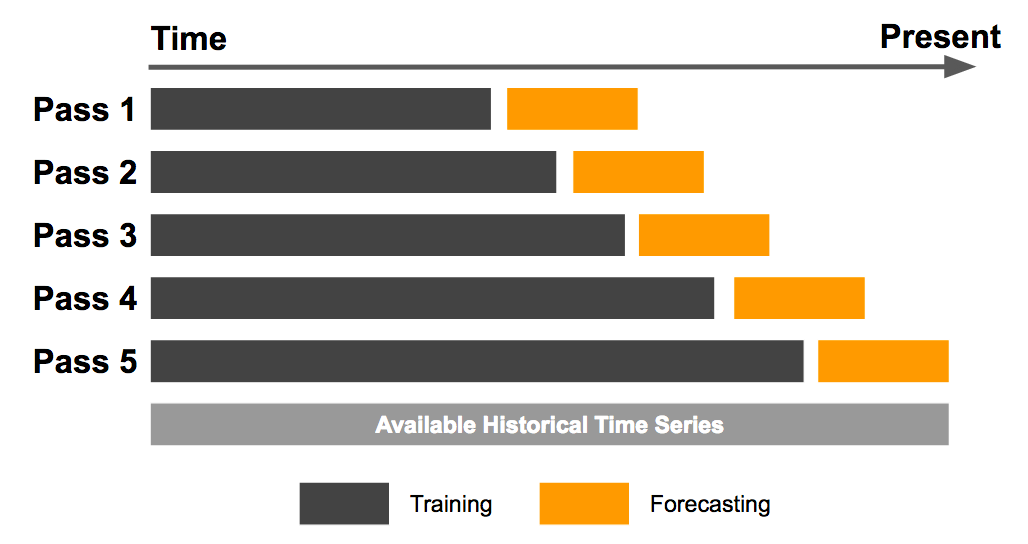
Jeremy(in case you forgot Jeremy Howard)advised to proceed with caution while using test_train_split for creating validation sets as it would for sure destroy your time series order in your data. Considering everything said above, a carefully made validation set can may well be the difference between recognizing whether your model works or not.
Jeremy(以防万一您忘记了Jeremy Howard )建议在使用test_train_split创建验证集时要谨慎行事,因为这肯定会破坏数据中的时间序列顺序。 考虑到以上所述, 精心设计的验证集很可能是识别模型是否有效的区别。
I hope that you may have learned a thing or two from my interpretation of the data splitting in Machine Learning and from hereon, split data with a new perspective. Even if you knew all that I bet a review is never a bad thing to do . Until next time…
我希望您能从我对机器学习中的数据拆分的理解中学到一两个东西,并从此以新的视角拆分数据 。 即使您知道我敢打赌,做评论也绝不是一件坏事。 直到下一次…
验证数据和测试数据















 2352
2352

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









