






三人决斗
介绍 (Introduction)
Over the last few articles, we’ve discussed and implemented Deep Q-learning (DQN)and Double Deep Q Learning (DDQN) in the VizDoom game environment and evaluated their performance. Deep Q-learning is a highly flexible and responsive online learning approach that utilizes rapid intra-episodic updates to it’s estimations of state-action (Q) values in an environment in order to maximize reward. Double Deep Q-Learning builds upon this by decoupling the networks responsible for action selection and TD-target calculation in order to minimize Q-value overestimation, a problem particularly evident when earlier on in the training process, when the agent has yet to fully explore the majority of possible states.
在过去的几篇文章中,我们已经在VizDoom游戏环境中 讨论并实现了 深度Q学习 (DQN)和双深度Q学习 (DDQN),并评估了它们的性能。 深度Q学习是一种高度灵活且响应Swift的在线学习方法,它利用快速的内部事件更新对其在环境中的状态作用(Q)值的估计,以最大化回报。 Double Deep Q-Learning以此为基础,通过将负责动作选择和TD目标计算的网络解耦,以最大程度地降低Q值高估,这一问题在训练过程的较早阶段,即代理商尚未完全探索时尤其明显。大多数可能的状态。
Inherently, using a single state-action value in judging a situation demands exploring and learning the effects of an action for every single state, resulting in an inherent hindrance to the model’s generalization capabilities. Moreover, not all states are equally relevant within the context of the environment.
本质上,使用单个状态-动作值来判断情况需要探索和学习每个单个状态的动作效果,从而对模型的泛化能力产生了固有的阻碍。 而且,并非所有状态在环境中都具有同等的相关性。
Recall our Pong environment from our earlier implementations. Immediately after our agent hits the ball, the value of moving left or right is negligible, as the ball must first travel to the opponent and be returned towards the player. Calculating state-action values at this point to use for training may disrupt the convergence of our agent as a result. Ideally, we would like to be able to identify the value of each action without learning its effects specific to each state, in order to encourage our agent to focus on selecting actions relevant to the environment.
回忆一下我们以前的实现中的 Pong环境。 在我们的探员击球后,向左或向右移动的值立即可以忽略不计,因为球必须首先行进对手并返回球员。 计算此时用于训练的状态行动值可能会破坏我们代理的收敛性。 理想情况下,我们希望能够在不了解每个行为特定于每个状态的影响的情况下,识别每个行为的价值,以鼓励我们的代理商专注于选择与环境相关的行为。
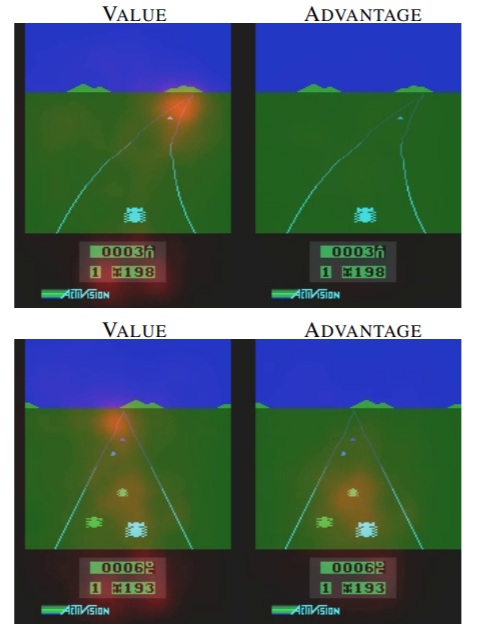
Dueling Deep Q-Learning (henceforth DuelDQN) addresses these shortcomings by splitting the DQN network output into two streams: a value stream and an advantage (or action) stream. In doing so, we partially decouple the overall state-action evaluation process. In their seminal paper, Van Hasselt et. al presented a visualization of how DuelDQN affected agent performance in the Atari game Enduro, demonstrating how the agent could learn to focus on separate objectives. Notice how the value stream has learned to focus on the direction of the road, while the advantage stream has learned to focus on the immediate obstacles in front of the agent. In essence, we have gained a level of short-term and medium-term foresight through this approach.
决斗深度Q学习(以下简称DuelDQN)通过将DQN网络输出分为两个流来解决这些缺点:价值流和优势(或行动)流。 在此过程中,我们将整个状态动作评估过程部分地分离了。 Van Hasselt等人在其开创性论文中。 他等人展示了Atel游戏Enduro中DuelDQN如何影响特工性能的可视化,演示了特工如何学会专注于单独的目标。 请注意,价值流如何学会专注于道路的方向,而优势流如何学会专注于代理商前方的直接障碍。 从本质上讲,我们通过这种方法获得了短期和中期的预测。
To calculate the Q-value of a state-action, we then utilize the advantage function is to tell us the relative importance of an action. The subtraction of the average advantage, calculated across all possible actions in a state, is used to find the relative advantage of our interested action.
为了计算状态动作的Q值,我们利用优势函数来告诉我们动作的相对重要性。 对状态中所有可能的动作计算得出的平均优势的减法用于查找我们感兴趣的动作的相对优势。
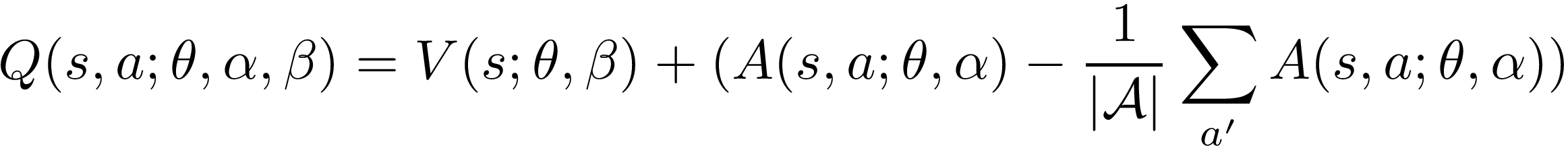
Intuitively, we have partially decoupled the action and state-value estimation processes in order to gain a more reliable appraisal of the environment.
直观上,我们已将操作和状态值估计过程部分分离,以便获得对环境的更可靠评估。
实作 (Implementation)
We’ll be implementing our approach in the same VizDoomgym scenario as in our last article, Defend The Line, with the same multi-objective conditions. Some characteristics of the environment include:
我们将在与上一篇文章Defend The Line相同的VizDoomgym场景中使用相同的多目标条件来实现我们的方法。 环境的一些特征包括:
- An action space of 3: fire, turn left, and turn right.
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









