





keras 嵌入层

Keras Embedding layer is first of Input layer for the neural networks. After the conversion of our raw input data in the token and padded sequence, now its time to feed the prepared input to the neural networks. In our previous two post we had covered step by step conversion of words into token and padded sequence, so i highly recommend to just have a look in my previous two articles on Tokenization and word embedding. The links are below
Keras嵌入层是神经网络输入层的第一层。 在将原始输入数据转换为令牌和填充序列后,现在该将准备好的输入提供给神经网络了。 在我们的前两篇文章中,我们介绍了将单词逐步转换为令牌和填充序列的过程,因此,我强烈建议您看一下前两篇关于令牌化和单词嵌入的文章。 链接在下面
Before going towards the Keras embedding layers first we will briefly cover what and all we have discussed till now. We had started with Tokenization, basically in tokenization we used to convert words into tokens because machine doesn’t understand text and able conversion into tokens we used to pad the sequence of the sentence because context need to be maintained and the conversion of word to sequence also leads to uniformity and same length. Also we need to add dimensions to our each and every word which states that each word has different meaning and we need to scale that all words in fixed dimension spaces based on their similarity in the form of vectors and that dimension we are free too choose. It could be 10,20,100,200,300 anything. For pre trained word embedding we had seen the word2vec step by step in our last tutorial. Now we will cover implementation of GLOVE pre trained embedding quickly before entering in the keras Embedding layer
在首先进入Keras嵌入层之前,我们将简要介绍到目前为止所讨论的内容。 我们从标记化开始,基本上在标记化中,我们用于将单词转换为标记,因为机器不理解文本,并且能够转换为用于填充句子序列的标记,因为需要保持上下文以及将单词转换为序列也导致均匀性和相同的长度。 同样,我们需要为每个单词增加维数,以表明每个单词的含义都不同,并且我们需要基于矢量在形式上的相似性来缩放固定维空间中的所有单词,并且我们也可以自由选择维数。 可能是10,20,100,200,300。 对于预训练的单词嵌入,我们在上一个教程中逐步看到了word2vec。 现在,我们将介绍在进入keras嵌入层之前快速完成GLOVE预训练的嵌入的实现
As we have discussed the basics of GLOVE in our last tutorial that it is also a kind word embedding. In this tutorial we will see the programetic implementation of GLOVE
正如我们在上一教程中讨论GLOVE的基本知识一样,它也是一种词嵌入。 在本教程中,我们将看到GLOVE的程序化实现
First we will download the pre trainned word embedding vector for GLOVE from this link https://github.com/stanfordnlp/GloVe. Open this link and go to Download pre trained word vectors, after downloading we can use it in our IDE. I am using google colab and after downloading i will upload this file in my google colab environment. This file consists of 4 lakh words with 100 vector dimension.
首先,我们将从此链接https://github.com/stanfordnlp/GloVe下载GLOVE的预训练单词嵌入向量。 打开此链接,然后转到下载预训练的单词向量,下载后,我们可以在IDE中使用它。 我正在使用google colab,下载后我将在我的google colab环境中上传此文件。 该文件包含4十万个单词,向量维数为100。

Now we had downloaded the pre trained embedding we will store all 4 lakh word as a key and their weight vector i.e 100 dimension vector as a value in one empty dictionary by using the below code
现在,我们已经下载了预训练的嵌入,我们将使用以下代码将所有40万个单词存储为一个键,并将其权重向量(即100维向量)作为值存储在一个空字典中

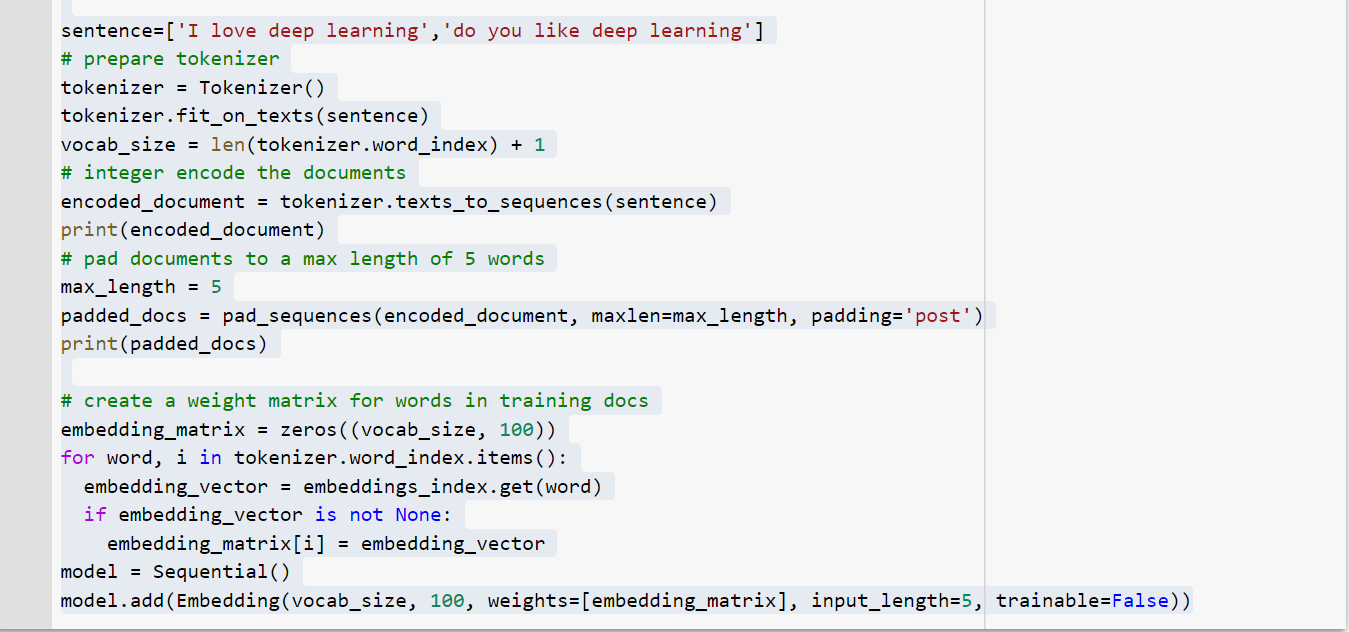
We will import numpy as we are doing numerical computation. Now we will use the same 2 sentence what i had used in my Tokenization blog. i will convert that 2 sentence in token and apply padding to the sentence. Below are the code for same. If you have any doubt in code i highly recommend go through my tokentization blog and link i had mentioned at starting of my post.
在进行数值计算时,我们将导入numpy。 现在,我们将使用与我在Tokenization博客中使用的相同的2个句子。 我将把这2个句子转换为令牌并将填充应用于该句子。 下面是相同的代码。 如果您对代码有任何疑问,我强烈建议您浏览我的标记化博客,并找到我在文章开头提到的链接。

If we want to see all the items(items are nothing but our words that we had feed to tokenizer) in to tokenizer object we can use below command
如果我们想查看所有项目(项目只是给令牌生成器的单词),就可以在令牌生成器对象中使用以下命令

Now we will be assigning the pre-trained weight(already we had stored this in embeddings_index disctionary earlier in this post) to all the items present in our tokenizer object. This we can do by writing below python codes. we have created a matrix of size (vocab_size,100). vocab_size is nothing but (total words+1). In embedding_matrix we have 100 vectorized weight for all the 8 words of our sentence.
现在,我们将分配预训练的权重(已经将其存储在本文前面的embeddings_index词典中)给令牌生成器对象中存在的所有项目。 我们可以通过编写以下python代码来做到这一点。 我们创建了一个大小矩阵(vocab_size,100)。 vocab_size就是(总单词数+1)。 在embedding_matrix中,我们对句子中所有8个单词的权重均为100。

We have transferred the pre-trained embedding weight of GLOVE to our words in sentence. Now its time for passing this all in the keras embedding layer. Congratulation we have successfully completed our pre trained word embedding concepts. Now we are good to go with keras embedding layer
我们已经将GLOVE的预训练嵌入权重转移到我们的句子中。 现在是时候在keras嵌入层中传递所有这些信息了。 恭喜,我们已经成功完成了预训练的词嵌入概念。 现在我们可以使用keras嵌入层了
Coming to keras embedding layer,as we have already discussed it is the 1st layer that will act as a input to our neural networks layer so we need to understand each and every aspects related to keras embedding layer in detail like what is the dimension of input it accepts? what is the output after the data get processed in the keras embedding layer? so we will answer all these questions one by one
就像我们已经讨论过的那样,来到keras嵌入层,它是神经网络层的输入,因此我们需要详细了解与keras嵌入层相关的各个方面,例如输入的维数是多少。它接受吗? 在keras嵌入层中处理完数据后,输出是什么? 所以我们将一一回答所有这些问题
Keras Embedding requires that the input data be integer encoded so that each word is represented by a unique integer. This data preparation step can be performed using the Tokenizer API also provided with Keras that we had done already.
Keras嵌入要求将输入数据进行整数编码,以便每个单词都由唯一的整数表示。 可以使用我们已经完成的Keras随附的Tokenizer API来执行此数据准备步骤。
Also, This is one of the flexible layer that can be used in variety of ways. These ways are listed below:
而且,这是可以以多种方式使用的柔性层之一。 下面列出了这些方法:
It can be used alone to learn a word embedding that can be saved and used in another model later.It can be used as part of a deep learning model where the embedding is learned along with the model itself.It can be used to load a pre-trained word embedding model, a type of transfer learning, that we had already prepared with word2vec and GLOVE
可以单独使用它来学习单词嵌入,该单词嵌入可以在以后的其他模型中保存和使用。 它可以用作深度学习模型的一部分,在该模型中,可以与模型一起学习嵌入。 它可以用于加载我们已经使用word2vec和GLOVE准备的预训练单词嵌入模型,这是一种迁移学习。
It is also the first hidden layers of neural networks because we had already prepared the input and now we are passing it to first layer and by architecture of neural network we know that input is passed to the hidden layers. It must specify 3 arguments:
它也是神经网络的第一个隐藏层,因为我们已经准备好了输入,现在我们将其传递给第一层,通过神经网络的体系结构,我们知道将输入传递给了隐藏层。 它必须指定3个参数:
input_dim: This is the size of the vocabulary in the text data. For example, if your data is integer encoded to values between 0–10, then the size of the vocabulary would be 11 words. In our use case sentence, it is 8 words
input_dim:这是文本数据中词汇的大小。 例如,如果您的数据是整数编码为0-10之间的值,则词汇表的大小将为11个单词。 在我们的用例句子中,它是8个字
output_dim: This is the size of the vector space in which words will be embedded. It defines the size of the output vectors from this layer for each word. For example, it could be 32 or 100 or even larger. Test different values for your problem. In our use case it is 100 dimension and 8 for baseline model.
output_dim:这是将要嵌入单词的向量空间的大小。 它为每个单词定义了该层输出矢量的大小。 例如,它可以是32或100甚至更大。 为您的问题测试不同的值。 在我们的用例中,它是100维,基线模型是8维。
input_length: This is the length of input sequences, as you would define for any input layer of a Keras model. For example, if all of your input documents are comprised of 1000 words, this would be 1000. In our use case it is 5 because all the 2 sentence comprises of 5 words in our sentence
input_length:这是输入序列的长度,就像您为Keras模型的任何输入层定义的那样。 例如,如果您所有的输入文档都由1000个单词组成, 则为 1000。 在我们的用例中,它是5,因为所有2个句子在我们的句子中都包含5个单词
The above 3 arguments is the most important and we need to keep in mind while dealing with keras embedding layer. The output of the Embedding layer is a 2D vector with one embedding for each word in the input sequence of words (input document).
以上3个参数是最重要的,在处理keras嵌入层时,我们需要牢记。 嵌入层的输出是一个2D向量,每个单词在输入单词序列(输入文档)中嵌入一个。
We have seen enough theory, now we will implement the keras embedding layer programmatically.
我们已经了解了足够的理论,现在我们将以编程方式实现keras嵌入层。
First we need to import the keras embedding class from keras.layers by using below code
首先,我们需要使用以下代码从keras.layers导入keras嵌入类
from keras.layers import Embedding
from keras.layers import Embedding
Now we need to define the sequential model as we had already discussed embedding is the first step to the model creation. Detail of the model creation is out of the scope of this post. we will look the detail architecture of the neural networks and how to implement it using keras in our coming blog. So as of now just need to remember that first we need to create a model object after that only we will be adding all the different different layers to our created model object. We can create a model object by writing below python code
现在我们需要定义顺序模型,正如我们已经讨论过的,嵌入是模型创建的第一步。 模型创建的详细信息超出了本文的范围。 我们将在即将到来的博客中探讨神经网络的详细架构以及如何使用keras来实现它。 因此,到目前为止,只需要记住,我们首先需要创建一个模型对象,然后才将所有不同的不同层添加到我们创建的模型对象中。 我们可以通过编写以下python代码来创建模型对象

As we have created the model successfully now we will add embedding layer to this model and we already discussed in details what all the arguments or parameter we need to provide to create embedding layers.
成功创建模型后,我们将向该模型添加嵌入层,并且我们已经详细讨论了创建嵌入层所需提供的所有参数或参数。
First we will create the embedding layer for baseline embeddings(i.e in which we had not assigned any pre trained weights and that we had already created in our fist tokenization blog again i highly recommend just go through that blog for better understanding)This we can do by writing below python code. We are free to add the output dimension whatever we want in this case. Its recommended just play with the dimension values for the better model accuracy and at last also we will add it to created model object
首先,我们将创建用于基线嵌入的嵌入层(即,在其中我们尚未分配任何预先训练的权重,并且我们已经在拳头标记化博客中再次创建了该嵌入层,我强烈建议您浏览该博客以更好地理解)这可以通过编写以下python代码。 在这种情况下,我们可以随意添加输出尺寸。 为了更好的模型精度,建议使用尺寸值,最后将其添加到创建的模型对象中

Now we will create the embedding layer for GLOVE model and that is the case of pre-trained embedding. One thing need to keep in mind we already had defined the dimension as 100 in this case and also we have the weights for all the 100 dimensions so simply we will assign all this to embedding layers, this is the power of pre trained word embeddings. This can be done by writing below python code. We need to specify trainable as False because we don’t want our embedding layer to be trained because already we had assigned the weights and that we will pass to the embedding layer using weights=[embedding_matrix].
现在,我们将为GLOVE模型创建嵌入层,这就是预训练的嵌入情况。 需要记住的一件事是,在这种情况下,我们已经将维定义为100,并且我们拥有所有100维的权重,因此简单地将所有这些权重分配给嵌入层,这就是预先训练好的词嵌入的强大功能。 这可以通过编写以下python代码来完成。 我们需要将可训练性指定为False,因为我们不希望对嵌入层进行训练,因为我们已经分配了权重,并且将使用weights = [embedding_matrix]传递给嵌入层。

Congratulations, we have successfully created the keras embedding layer and also now we had headed towards the journey of the neural networks model for natural language processing. Lots of things are coming i am very excited for explaining architecture of neural networks and how it works and most important how we can code each and every aspects of the architecture smoothly. I will be giving the complete code for the embedding implementation for both baseline and pre trained word embedding at the end of this post. If you have any questions related to this post or any bit of code you are not understanding, let me know in comment section. I will be very happy to explain.
恭喜,我们已经成功创建了keras嵌入层,并且现在我们已朝着用于自然语言处理的神经网络模型的方向前进。 我将为解释神经网络的体系结构及其工作方式而感到非常兴奋,最重要的是我们如何顺利地对体系结构的每个方面进行编码。 在这篇文章的结尾,我将提供用于基线和预训练词嵌入的嵌入实现的完整代码。 如果您对此帖子有任何疑问或您不理解的任何代码,请在评论部分让我知道。 我很乐意解释。
I am planning to explain the architecture of neural network in my next blog post after that it will be very easy to understand or implement the neural networks and slowly slowly we will see the real time use cases how NLP are used in the industry along with that i am planning for the step step explanation how the neural networks are used in the computer vision world. Lots of things we will understand step by step just wait and have patience :-)
我计划在我的下一个博客文章中解释神经网络的体系结构,因为它将非常容易理解或实现神经网络,然后慢慢地我们将看到实时用例以及如何在行业中使用NLP。我正在计划逐步解释如何在计算机视觉世界中使用神经网络。 我们会逐步了解很多事情,请耐心等待:-)


敬请关注 (Stay Tuned)
keras 嵌入层















 5169
5169

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









