





1.简介 (1. Introduction)
In the last three posts I have explained Generative Adversarial Network, its problems and an extension of the Generative Adversarial Network called Conditional Generative Adversarial Network to solve the problems in the successful training of the GAN.
在最近的三篇文章中,我已经解释了 生成对抗网络 , 它的问题 以及称为 条件生成对抗网络 的生成对抗网络的扩展, 以解决GAN成功训练中的问题。
As claimed earlier in the last post, Image to Image translation is one of the tasks, which can be done by Conditional Generative Adversarial Networks (CGANs) ideally.
如上一篇文章中先前所述 , 图像到图像的翻译是其中的一项任务,可以由条件生成对抗网络完成 ( CGAN )。
In the task of Image to Image translation, an image can be converted into another one by defining a loss function which is extremely complicated. Accordingly, this task has many applications like colorization and making maps by converting aerial photos. Figures above show great example of Image to Image translation.
在图像到图像转换的任务中,可以通过定义极其复杂的损失函数将图像转换为另一图像。 因此,此任务具有许多应用程序,例如通过转换航空照片来着色和制作地图。 上图显示了图像到图像转换的绝佳示例。
Pix2Pix network was developed based on the CGAN. Some of the applications of this efficient method include object reconstruction from edges, photos synthesis from label maps, and image colorization [source].
Pix2Pix网络是基于 CGAN 开发的 。 一些这种有效的方法的应用包括从边缘对象重建,照片,从标记图的合成,和图像彩色化[ 源 。
2. Pix2Pix网络的架构 (2. The architecture of Pix2Pix Network)
As mentioned above, Pix2Pix is based on conditional generative adversarial networks (CGAN) to learn a mapping function that maps an input image into an output image. Pix2Pix like GAN, CGAN is also made up of two networks, the generator and the discriminator. Figure below indicates a very high-level view of the Image to Image architecture from the Pix2Pix paper.
如上所述,Pix2Pix基于条件生成对抗网络( CGAN ),以学习将输入图像映射到输出图像的映射函数。 像 GAN 一样的Pix2Pix , CGAN 也由两个网络组成,即生成器和鉴别器。 下图显示了Pix2Pix论文从“图像到图像”体系结构的非常高级的视图。

2.1发电机架构 (2.1 The Generator Architecture)
The generator goal is to take an input image and convert it into the desired image (output or ground truth) by implementing necessary tasks. There are two types of the generator, including encoder-decoder and U-Net network. The latter difference is to have skip connections.
生成器的目标是通过执行必要的任务来获取输入图像并将其转换为所需的图像(输出或基本事实) 。 生成器有两种类型,包括编码器-解码器和U-Net网络。 后者的区别是具有跳过连接。
Encoder-decoder networks translate and compress input images into a low-dimensional vector presentation (bottleneck). Then, the process is reversed, and the multitudinous low-level information exchanged between the input and output can be utilized to execute all necessary information across the network. In order to circumvent the bottleneck for information, they added a skip connection between each layer i and n-i where i is the total number of the layers. It should be noted that the shape of the generator with skip connections looks like a U-Net network. Those images are shown below.
编码器/解码器网络将输入图像转换并压缩为低维向量表示形式(瓶颈)。 然后,该过程被逆转,在输入和输出之间交换的大量低级信息可用于在网络上执行所有必要的信息。 为了规避信息瓶颈,他们在第i层和第ni层之间添加了一个跳过连接,其中i是各层的总数。 应该注意的是,带有跳过连接的发生器的形状看起来像一个U-Net网络。 这些图像如下所示。

As seen in the U-Net architecture, the information from earlier layers will be integrated into later layers and because of using skip connections, they don’t need any size changes or projections.
从U-Net架构中可以看出,来自较早层的信息将被集成到较后层中,并且由于使用了跳过连接,因此不需要任何大小更改或投影。
2.2鉴别器架构 (2.2 The Discriminator Architecture)
The task of the discriminator is to measure the similarity of the input image with an unknown image. This unknown image either belongs to the dataset (as a target image) or is an output image provided by the generator.
鉴别器的任务是测量输入图像与未知图像的相似度 。 此未知图像要么属于数据集(作为目标图像),要么是生成器提供的输出图像。
The PatchGAN discriminator in Pix2Pix network is employed as a unique component to classify individual (N x N) patches within the image as real or fake.
Pix2Pix网络中的PatchGAN鉴别器用作唯一组件,可将图像中的各个(N x N)个补丁分类为真实或伪造 。
As the authors claim, since the number of PatchGAN discriminator parameters is very low, the classification of the entire image runs faster. The PatchGAN discriminator’s architecture is shown in figure below.
正如作者所声称的那样,由于PatchGAN鉴别器参数的数量非常少,因此整个图像的分类运行得更快。 下图显示了PatchGAN鉴别器的体系结构。
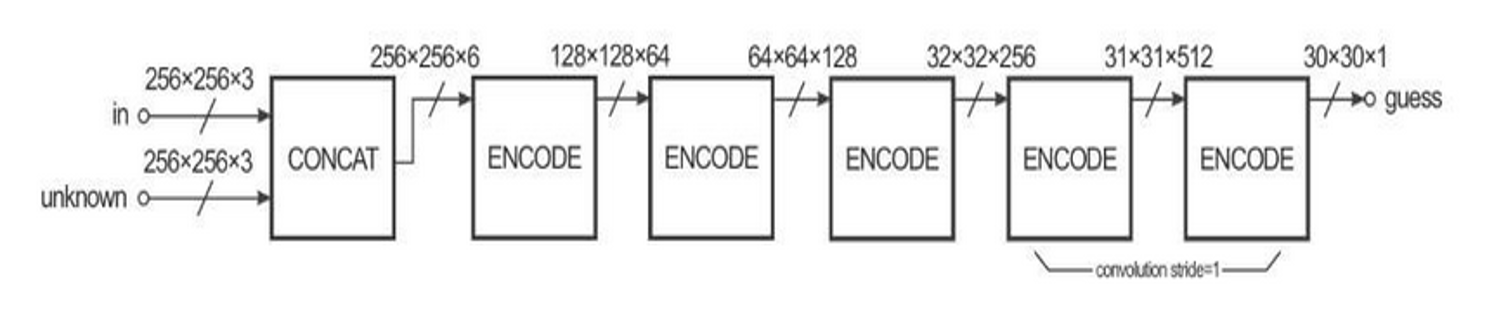
The reason for calling this architecture as “PatchGAN” is that each pixel of the discriminator’s output (30 × 30 image) corresponds to the 70×70 patch of the input image. Also, it’s worth noting that according to the fact the input images size is 256×256, the patches overlay considerably.
之所以将该架构称为“ PatchGAN ”,是因为鉴别器输出的每个像素(30×30图像)对应于输入图像的70×70色块。 另外,值得注意的是,根据输入图像大小为256 × 256的事实,色块会大量重叠。
3.培训策略 (3. The training Strategy)
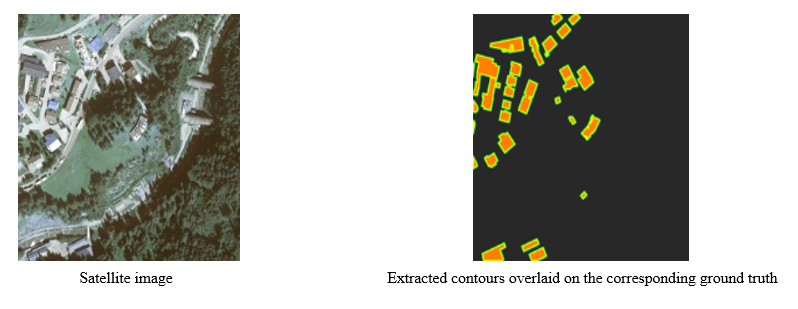
It is well known that there are many segmentation networks, which can segment objects, but the most important thing that they do not consider is to have segmentation networks that their segmented objects look like ground truths from the perspectives of shapes and edges and contours . To make the topic more clear, an example from one of the own practical projects that was carried out is presented below.
众所周知,有许多分割网络可以分割对象,但是他们没有考虑的最重要的事情是拥有一个分割网络,从形状,边缘和轮廓的角度来看,它们的分割对象看起来像地面真相。 为了使主题更清楚,下面提供了一个来自自己的实际项目的示例。

As shown in figure above, the right figure represents the result for building footprint segmentation, and the middle figure shows the corresponding ground truth. The model can detect where buildings are located but fails to reflect the boundaries, which are present in the ground truth and edges and contours of the segmented buildings doesn’t match exactly the ground truth.
如上图所示,右图表示建筑物占地面积分割的结果,中图表示相应的地面真实情况。 该模型可以检测建筑物的位置,但是无法反映出地面真实情况中存在的边界,并且分割后的建筑物的边缘和轮廓与地面真实情况不完全匹配。
As known, how buildings look like, depends on how the contours of the building are drawn. The most crucial information of an object is the object boundary and the shape and edges of a segmented building can be controlled or improved with the help of contours (the object boundary). Based on this assumption, the extracted contours of each ground truth were added to the corresponding ground truth again to reinforce the shape and edges of a segmented building for further research.
众所周知,建筑物的外观取决于建筑物的轮廓绘制方式。 对象的最关键信息是对象边界,可以借助轮廓(对象边界)来控制或改善已分割建筑物的形状和边缘。 基于此假设,将每个地面实况的提取轮廓再次添加到相应的地面实况中,以增强分段建筑物的形状和边缘,以供进一步研究。

As seen in figures above, contours were added again to objects of the ground truths after extracting them with the OpenCV library.
如上图所示,使用OpenCV库提取轮廓后,将轮廓再次添加到地面实物的对象中。
After adding corrsponding contours again to objects of the ground truths (on the fly in the code), Satellite images and ground truths with overlaid contours (An example shown in the following) form the dataset used in the training of Pix2Pix network.
在向地面真相的对象再次添加相应的轮廓后(在代码中即时), 具有重叠 轮廓的 卫星图像和地面真相 (如下所示的示例)形成了用于Pix2Pix网络训练的数据集。
After defining th dataset, the weights of Pix2Pix network are adjusted in two steps.
定义数据集后,分两步调整Pix2Pix网络的权重。
In the first step, The discriminator (figure below) takes the input (Satellite image)/target (ground truths with overlaid contours) and then input (Satellite image)/output (generator’ output) pairs, to estimate how realistic they look like. Then the adjustment of the discriminator’s weights is done according to the classification error of the mentioned pairs.
第一步,鉴别器 (下图)获取输入(卫星图像)/目标(具有重叠 轮廓的 地面真相 ) , 然后输入(卫星图像)/输出(发电机的输出)对,以估算它们的真实感。 然后根据所提到的配对的分类误差来调整鉴别器的权重。

In the second step, The generator’s weights (figure below) adjust by using the discriminator’s output and the difference between the output and target images.
第二步,生成器的权重 (下图) 通过使用鉴别器的输出以及输出图像和目标图像之间的差异进行调整。

Based on the paper, the objective function can be expressed as follow:
在此基础上,目标函数可以表示为:

The Authors of Pix2Pix used and added the loss function L1 measuring the standard distance between the generated output and the target.
Pix2Pix的作者使用并添加了损耗函数L1来测量生成的输出和目标之间的标准距离。
4.训练,验证和测试数据集 (4. The training, validation, and test Dataset)
In this section, the characteristics of the Orthofoto Tirol dataset will be explained. This dataset consists of two categories which are shown in Table below.
在本节中,将说明Orthofoto Tirol数据集的特征。 该数据集包括两个类别,如下表所示。

As known, all pixels of an image are important when each pixel is used by a segmentation model with a specific size of the input. Therefore, the data (pixels) will be lost from the image and the size of the image will be much smaller if the number of pixels have to reduce to meet this specific size of the input. It can be crucial to retain more information about images when it comes to resizing an image without losing quality.
众所周知,当细分模型使用具有特定输入大小的每个像素时,图像的所有像素都很重要。 因此,如果必须减少像素数以满足输入的特定大小,则数据(像素)将从图像中丢失,并且图像的大小将小得多。 在调整图像大小而不丢失质量时,保留有关图像的更多信息至关重要。
The images of the Orthofoto Tirol dataset have to cut into 256×256 because Pix2Pix only takes in 256×256 images. In the first attempt, the size of the satellite and corresponding ground truth images was reduced all at once to 256×256, which leads to losing 158.488.281 pixels. According to the fact that each pixel plays an important role in detecting each edge of a building, many pixels got lost. For this reason, a process was designed to select and cut images:
Orthofoto Tirol数据集的图像必须切成256×256,因为Pix2Pix仅可吸收256×256图像。 在第一次尝试中,卫星和相应的地面真实图像的大小立即全部减小到256×256,这导致丢失158.488.281像素。 根据每个像素在检测建筑物的每个边缘中起着重要作用的事实,许多像素丢失了。 因此,设计了一个过程来选择和剪切图像:
1. Due to lack of time and processing power, images with a high building density are selected from the entire dataset.
1.由于缺乏时间和处理能力,因此从整个数据集中选择了具有高建筑物密度的图像。
2. The size (4053×4053 pixels) of each selected image from the dataset (Satellite images and ground truths with overlaid contours) is changed to 4050×4050 pixels (see example blow).
2.从数据集中选择的每个图像(卫星图像和 轮廓 重叠的地面真相)的大小(4053×4053像素) 更改为4050×4050像素(请参见示例打击)。

3. Images from the last step cropped to the size of 675×675 pixels (see example blow).
3.来自最后一步的图像被裁剪为675×675像素的大小(请参见示例打击)。

4. The size of all cropped images resized to 256 × 256 pixels, which means that little information is lost (approx. 2.636.718 pixels, which is little compared to 158.488.281 pixels).
4.所有裁剪后的图像的大小均调整为256×256像素,这意味着几乎没有信息丢失(约2.636.718像素,与158.488.281像素相比几乎没有信息)。

The described process is repeated for all Images (Satellite images and ground truths with overlaid contours) to create the training, validation, and test datasets and the properties of each created dataset are indicated in Table below.
对所有图像( 覆盖的卫星图像和地面真相 )重复上述过程 等高线 )以创建训练,验证和测试数据集,每个创建的数据集的属性在下表中列出。

A validation dataset will be needed to evaluate the model in the duration of training. The validation dataset can be employed for training goals to find and optimize the best model. In this experiment, the validation dataset can be employed for overfitting minimization and hyper-parameter fine-tuning.
在训练期间,将需要一个验证数据集来评估模型。 验证数据集可用于训练目标,以查找和优化最佳模型。 在该实验中,验证数据集可用于过度拟合最小化和超参数微调。
5.评估标准和结果 (5. Evaluation Criteria and Results)
After training Pix2Pix on the training dataset, as shown below and tested on the validation and test datasets, the generator of Pix2Pix trying to improve the results and makes predictions which look like ground truths from the perspective of contours and edges.
在训练 数据集上训练了Pix2Pix之后,如下所示,并在验证和测试数据集上进行了测试,Pix2Pix的生成器试图改善结果并从轮廓和边缘的角度看起来像地面真相。




Evaluating the segmentation quality is very important for image processing, particularly in security cases, including autonomous vehicles. There are many evaluation criteria developed for segmentation evaluation so that researchers can make a choice based on their needs. In this post on my github you can read the evaluation criteria of segmentation networks.
评估分割质量对于图像处理非常重要,尤其是在安全情况下,包括自动驾驶汽车。 为细分评估制定了许多评估标准,以便研究人员可以根据自己的需求进行选择。 在我的github上的这篇文章中 ,您可以阅读细分网络的评估标准。
六,结论 (6. Conclusion)
Since the field of computer vision is significantly influenced by artificial neural intelligence and especially deep learning, many researcher and developers are interested in the implementation of a suitable deep learning architecture for building footprint segmentation. One of the most important issues in the field of segmentation are inefficient and inaccurate segmentation networks which output shapes differing from the shape of ground truth.
由于计算机视觉领域受到人工神经智能(尤其是深度学习)的显着影响,因此许多研究人员和开发人员都对实现合适的深度学习体系结构以构建足迹分割感兴趣。 分割领域中最重要的问题之一是效率低下和不准确的分割网络,其输出形状不同于地面真相的形状。
The presented experiment aims at using Pix2Pix network to segment the building footprint. The results of Pix2Pix on the test dataset seem to be good, but there is still much room for improvement of segmentation quality.
提出的实验旨在使用Pix2Pix网络分割建筑物的占地面积。 Pix2Pix在测试数据集上的结果似乎不错,但是仍然有很大的提高分割质量的空间。
On the link below you will find all the code and data set related to the experiment.
在下面的链接上,您将找到与实验相关的所有代码和数据集。

















 1015
1015

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









