





西雅图雨衣
Coursera数据科学顶点项目(Coursera Data Science Capstone Project)
介绍(Introduction)
In year 2010, there were 32,999 people killed, 3.9 million were injured, and 24 million vehicles were damaged in motor vehicle crashes in the United States. The economic costs of these crashes totaled $242 billion. Included in these losses are lost productivity, medical costs, legal and court costs, emergency service costs (EMS), insurance administration costs, congestion costs, property damage, and workplace losses. This represents a 1.6 percent of the $14.96 trillion real Gross Domestic Product for 2010.
在2010年,在美国发生的车祸中,有32,999人死亡,390万受伤,2,400万辆汽车受损。 这些事故的经济损失总计达2420亿美元。 这些损失包括生产力损失,医疗成本,法律和法院成本,紧急服务成本(EMS),保险管理成本,交通拥堵成本,财产损失和工作场所损失。 这相当于2010年14.96万亿美元实际国内生产总值的1.6%。
The society as a whole — the accident victims and their families, their employers, insurance firms, emergency and health care personal and many others — is affected by motor vehicle crashes in many ways. It would be great if real-time conditions can be provided to estimate the trip safeness. In this way, it can be decided beforehand if the driver will take the risk, based on reliable information.
整个社会-事故受害者及其家人,他们的雇主,保险公司,紧急情况和个人的医疗保健以及许多其他方面-受到汽车碰撞事故的多种影响。 如果能够提供实时条件以评估旅行安全性,那将是非常不错的。 这样,可以基于可靠的信息预先确定驾驶员是否承担风险。
数据 (Data)
The data used in the analysis is provided by the Traffic Records Group in the SDOT Traffic Management Division from Seattle, WA. It includes all collisions provided by the Seattle Police Department and recorded by the Traffic Record, displayed at the intersection or mid-block of a segment from 2004 to the present. The project purpose is to analyze and predict the severity of an accident based on some particular features that will be chosen.
分析中使用的数据由华盛顿州西雅图市SDOT交通管理部门的交通记录小组提供。 它包括西雅图警察局提供并由交通记录记录的所有碰撞,显示于2004年至今的路口或路段中间。 该项目的目的是基于将要选择的某些特定功能来分析和预测事故的严重性。
数据清理 (Data cleaning)
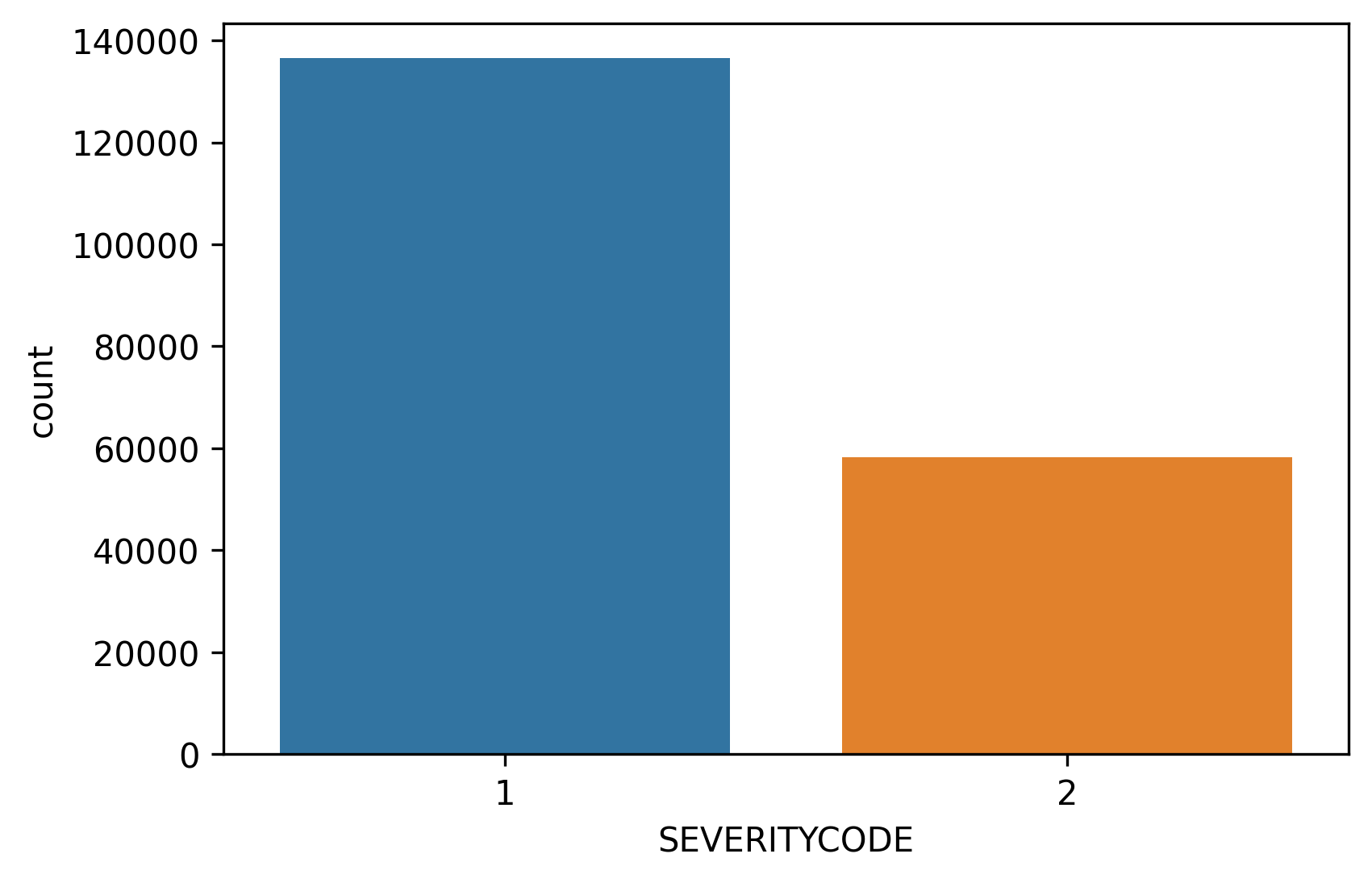
Many of the observations including the features described above has incomplete information, such as ‘NaN’ (Not a Number) values or bad formatted ones. At the same time, the frequency of the property damage accidents are almost as double as the ones involving injuries. Remember also, that the target variable, the one which will be predicted is SEVERITYCODE.
包括上述功能的许多观察结果具有不完整的信息,例如“ NaN”(非数字)值或格式错误的值。 同时,财产损坏事故的频率几乎是受伤事故的两倍。 还要记住,目标变量(将要预测的变量)是SEVERITYCODE。
The data cleaning process must also involve balancing of the data, in this way, the number of entries corresponding to the 2 severities present in the dataset are equal. Severity labeled as 1 correspond to collisions which implies only property damage and the ones labeled as 2, represents personal injuries. This classification is based in the SDOT Traffic Management Division criteria.
数据清理过程还必须涉及数据的平衡,以这种方式,与数据集中存在的2个严重性相对应的条目数相等。 标记为1的严重级别对应于碰撞,这仅表示财产损失,标记为2的严重程度表示人身伤害。 此分类基于SDOT交通管理部门标准。
Some features have categories such as “Unknown” or “Other” which are not representative and do not add predictive information to the training model. These categories together with the empty fields which do not have a valid entry, will also be dropped.
一些功能具有诸如“未知”或“其他”之类的类别,这些类别不具有代表性,并且不会将预测信息添加到训练模型中。 这些类别以及没有有效条目的空字段也将被删除。

As mentioned before, the data needs to be balanced between the two categories in order to improve the accuracy of the predictive machine learning models (unless decision tree like models are trained). For this purpose, the imbalanced learn library has been used and particularly the RandomUnderSampler class to perform an under-sampling of the dataframe. This strategy, eliminates randomly the extra entries corresponding to severity grade 1. Up to the point where there is the same amount of entries with both severities.
如前所述,数据需要在两类之间进行平衡,以提高预测性机器学习模型的准确性(除非训练了像模型这样的决策树)。 为此,已经使用了不平衡的学习库,尤其是使用RandomUnderSampler类来执行数据帧的欠采样。 此策略会随机消除与严重等级1相对应的额外条目。直到具有两个严重等级的条目数量相同为止。
功能选择 (Feature Selection)
One of the most important questions before training the model is, are all the features adding the same information to the model? If not so, what variables have more weight on it? To tackle this question some techniques can be used to help select the important features, the ones adding more information to our model. It has to be taken into mind that categorical inputs and output will be used, hence, for this kind of variables there are two common strategies: Chi-Squared Feature Selection and Mutual Information Feature Selection. For this particular project the later will be used, since tends to outperform when compared with Squared Feature selection.
在训练模型之前,最重要的问题之一是,是否所有功能都向模型添加了相同的信息? 如果不是这样,哪些变量具有更大的权重? 为了解决这个问题,可以使用一些技术来帮助选择重要的功能,这些功能可以为我们的模型添加更多信息。 必须考虑到将使用分类输入和输出,因此,对于此类变量,有两种常见策略:卡方特征选择和互信息特征选择。 对于此特定项目,将使用后者,因为与“平方特征”选择相比,它的表现往往更好。
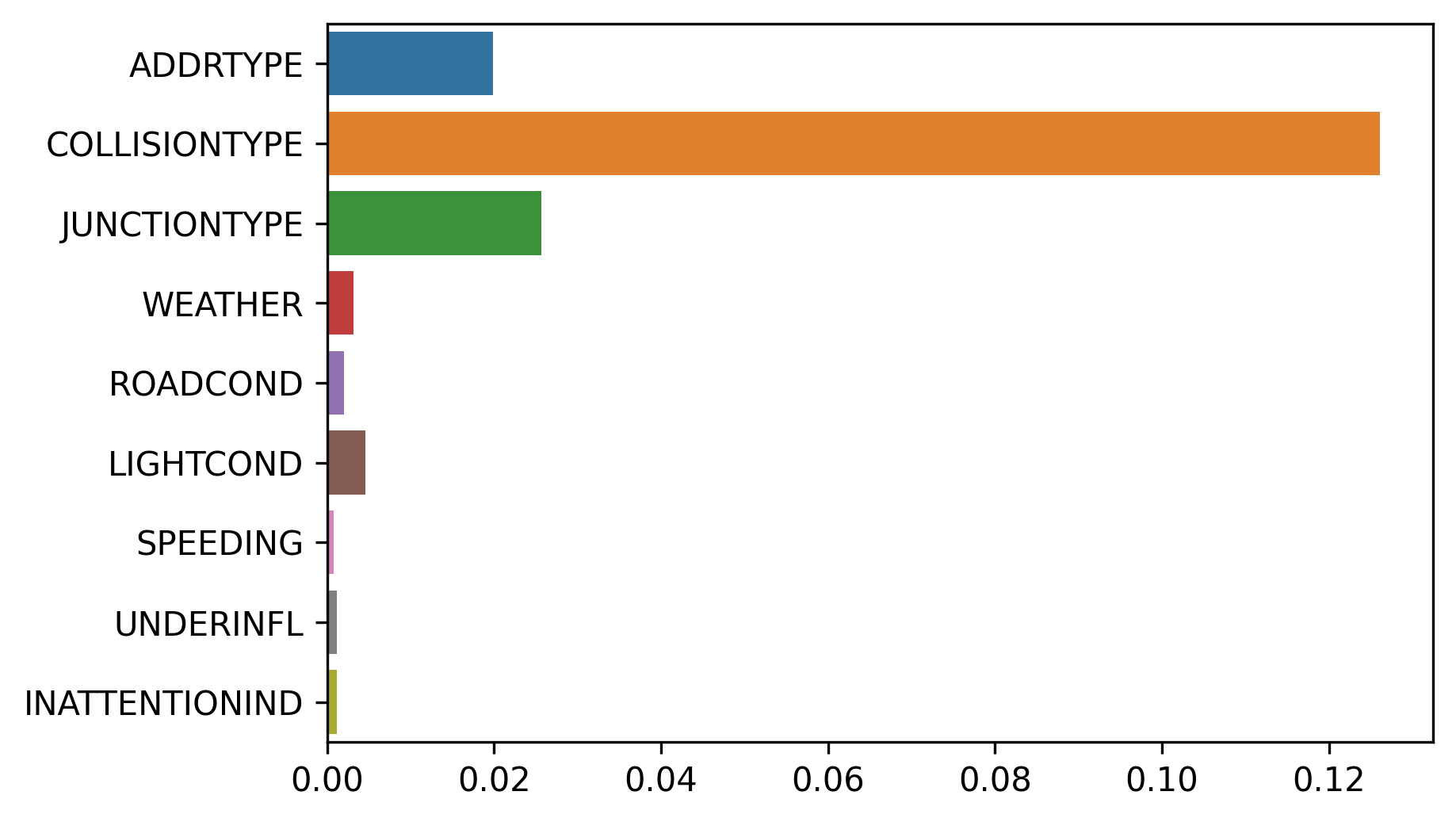
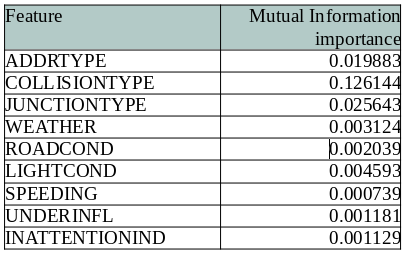
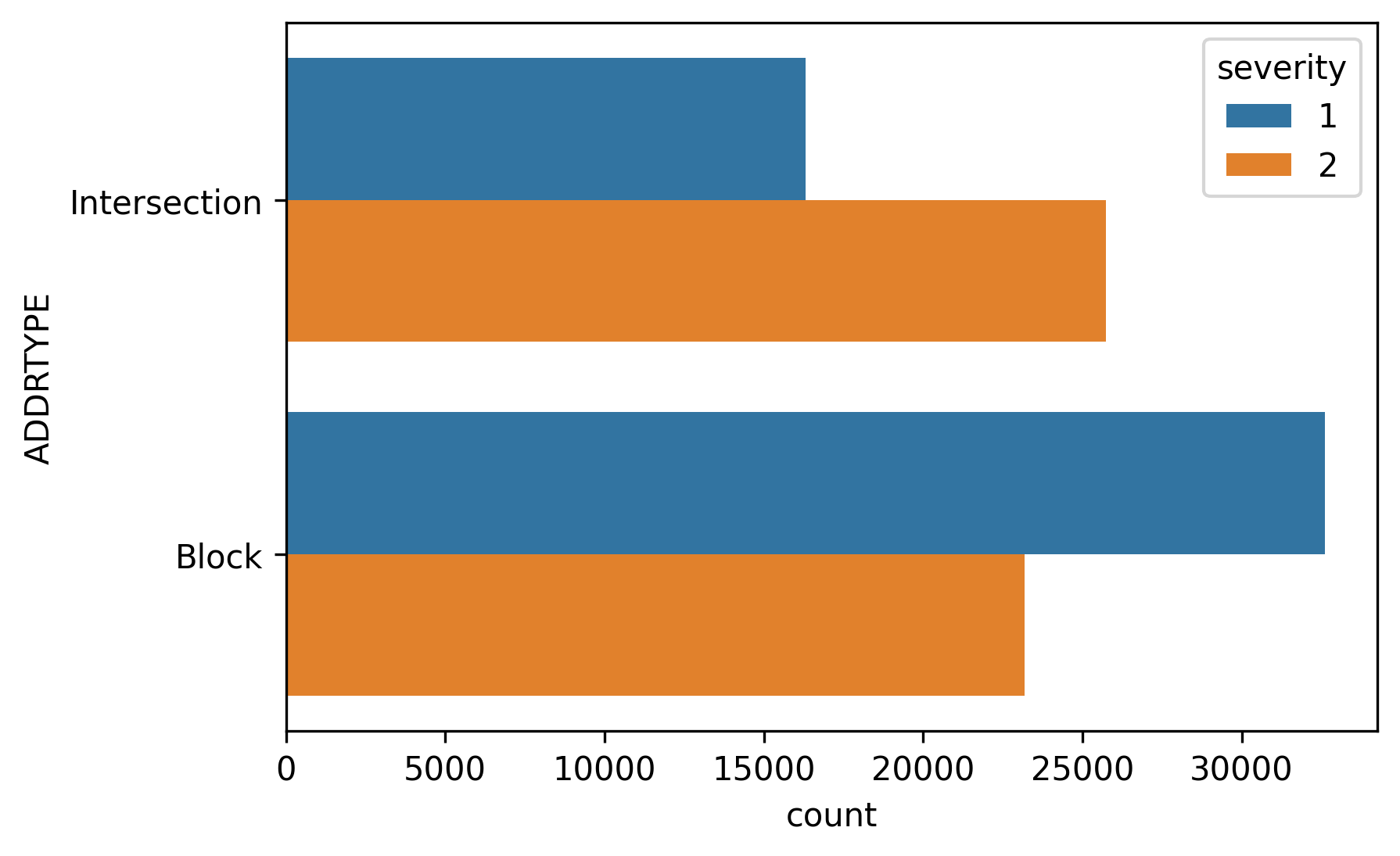
The most important variables to determine the collision severity are: ADDRTYPE, COLLISIONTYPE and JUNCTIONTYPE. Here, there is a clear winner: COLLISIONTYPE. Also, the first and the third feature are related, hence, is reasonable that the addition of information of these two variables is almost the same. We will cover this aspect deeply in the next section.
确定碰撞严重性的最重要变量是:ADDRTYPE,COLLISIONTYPE和JUNCTIONTYPE。 在这里,有一个明显的赢家:COLLISIONTYPE。 而且,第一特征和第三特征是相关的,因此这两个变量的信息的添加几乎相同是合理的。 在下一节中,我们将深入介绍这一方面。
探索性分析 (Exploratory Analysis)
Let’s explore the data to see if we can gather some knowledge from it and get some insights. It is also important to have in mind that some variables chosen can not be used to create a predictive model, since it is based in information collected after the accident had taken place.
让我们探索数据,看看是否可以从中收集一些知识并获得一些见解。 同样重要的是要记住,所选的某些变量不能用于创建预测模型,因为该模型基于事故发生后收集的信息。
碰撞类型 (Type of Collision)
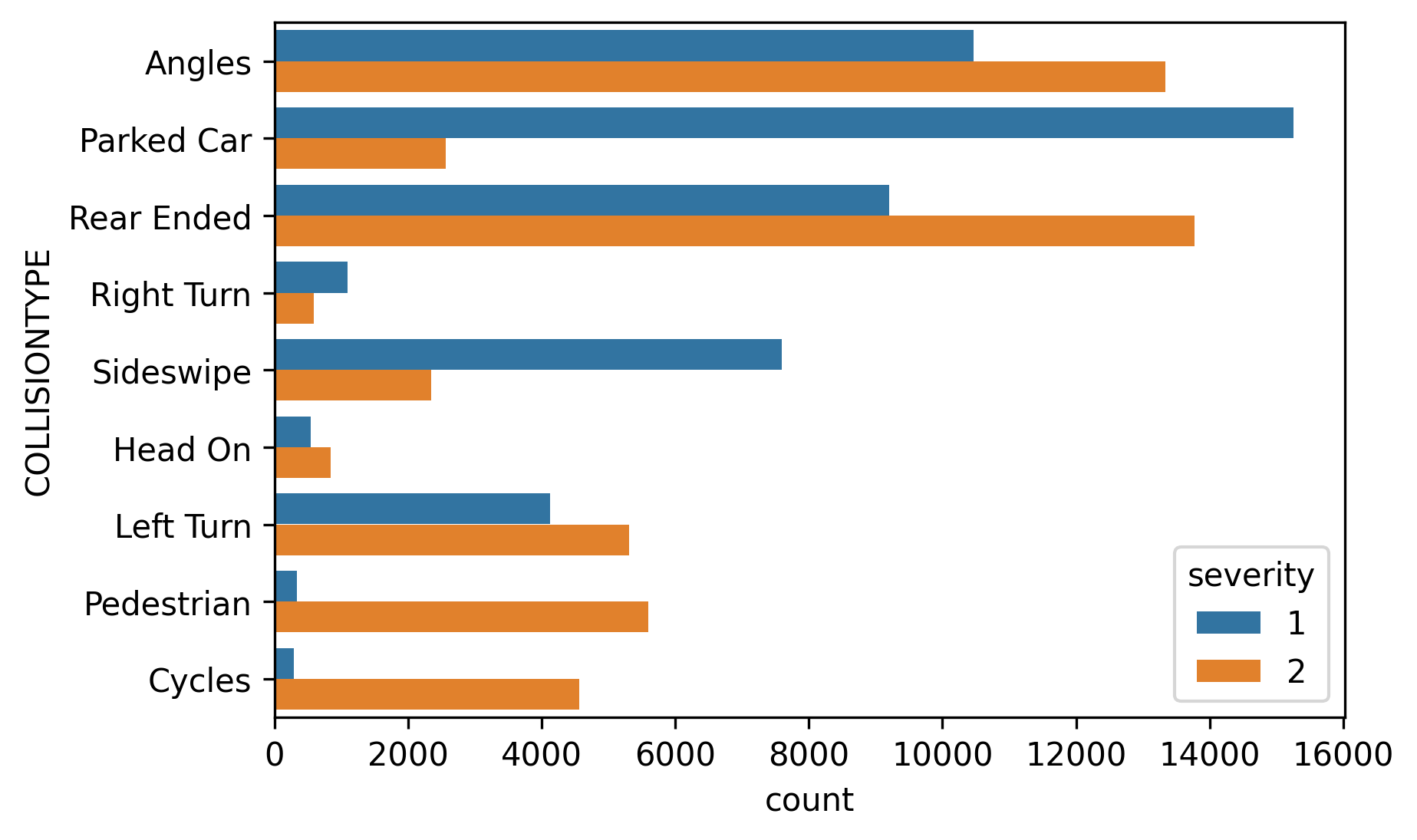
This feature has different characteristics based in the area of impact, such as: angles, parked car, rear end, right turn, sideswipe, head on, left turn, pedestrian and cycles. All those variables, their frequency and the collision severity can be found in the figure below. As can be observed, the entropy of this categorical variable is pretty high (very unbalanced).
此功能在撞击区域方面具有不同的特征,例如:角度,停放的汽车,后端,右转弯,侧向擦拭,头部向前,左转弯,行人和自行车。 所有这些变量,其频率和碰撞严重性可在下图中找到。 可以看出,该分类变量的熵很高(非常不平衡)。
碰撞的地方 (Collision place)
Looking at the following histogram, we can observe a higher frequency for severe accidents in intersections rather than in the middle of the blocks.
查看下面的直方图,我们可以发现在交叉路口而不是街区中间发生严重事故的频率更高。
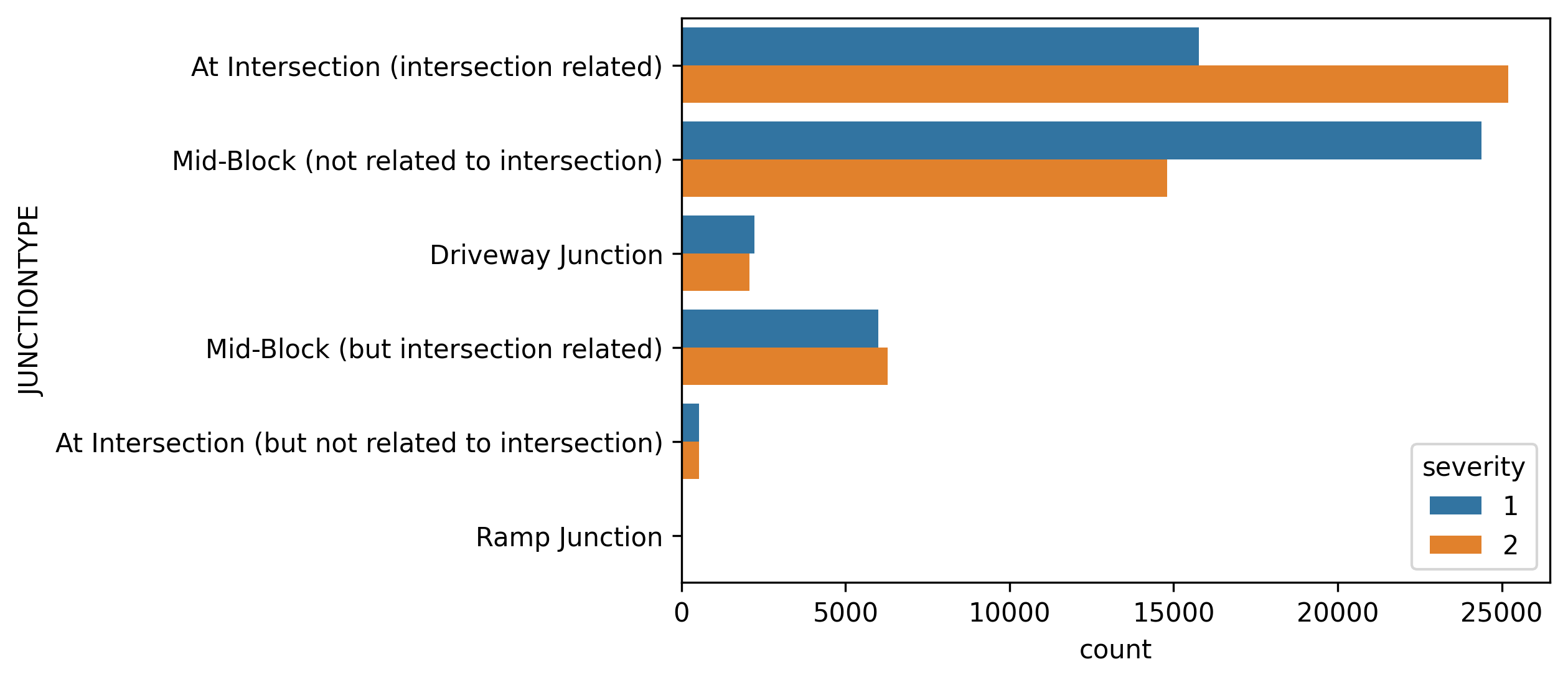
There are some less frequent categories which can be grouped in a meta-category involving intersections and mid-block incidents. Since these categories are relatively balanced, the overall classification does not change. Indeed, the categorical variable ADDRTYPE divides collision in these two categories, as we commented before. Not surprisingly, the amount of information of these two variables is almost similar.
可以将一些较不频繁的类别归为一个包含交叉路口和街区中间事件的元类别。 由于这些类别相对平衡,因此总体类别不会更改。 确实,分类变量ADDRTYPE将碰撞分为两类,正如我们之前评论过的那样。 毫不奇怪,这两个变量的信息量几乎相似。
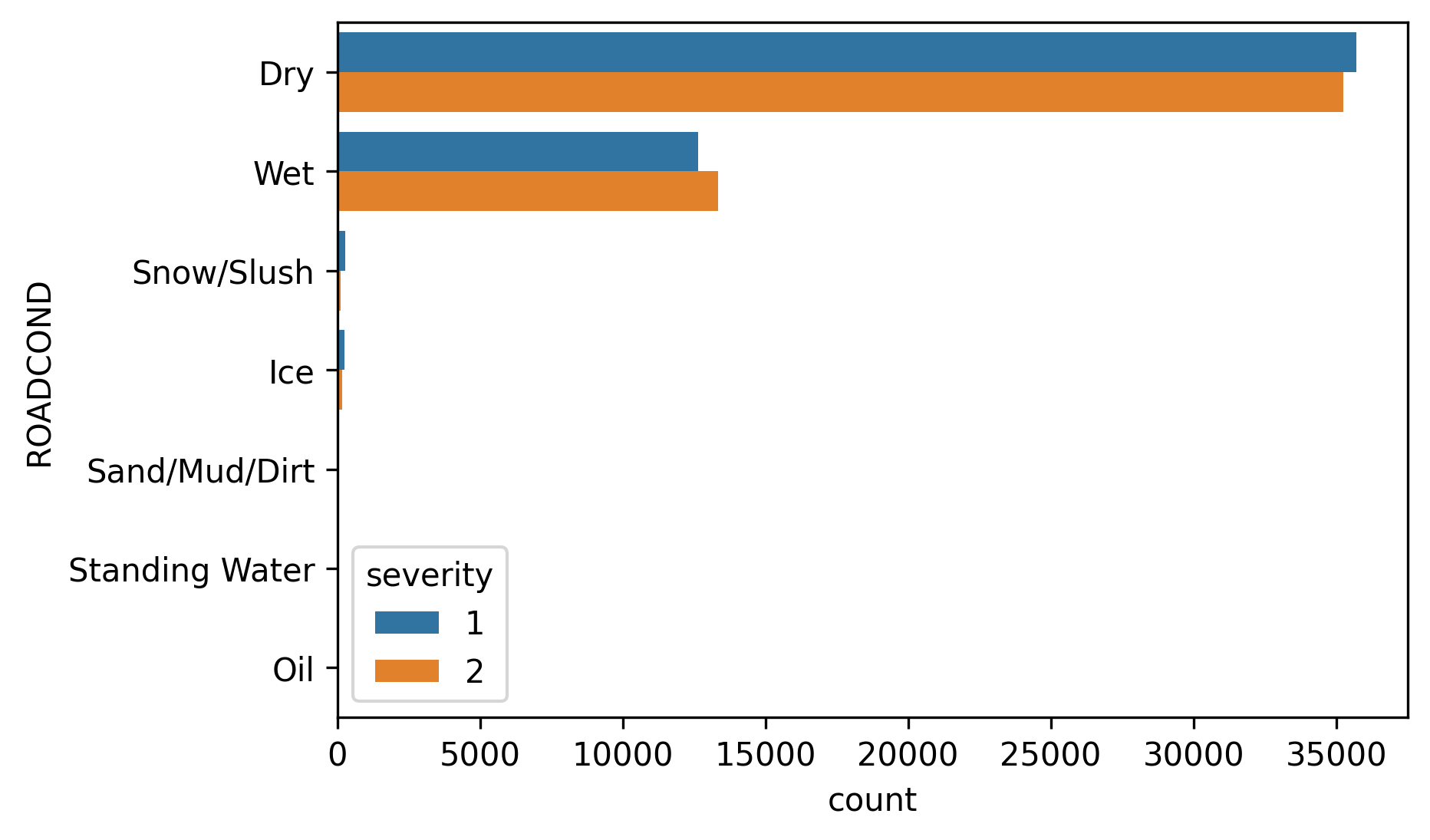
天气,光照和道路状况 (Weather, Light and Road conditions)
There are more occurrences of severe collisions during daylight whereas during the night with the lights on, accidents tend to be less risky. The reason for this, may be related to a more cautious driving during the night which predispose car users to an aware state. Dusk and dawn tend to be related to more severe collisions, maybe because of the visibility reduction while facing the sun directly in the vision zone.
在白天,发生严重碰撞的次数更多,而在开灯的夜晚,发生事故的风险较小。 造成这种情况的原因可能与夜间驾驶更为谨慎有关,这会使汽车使用者容易进入意识状态。 黄昏和黎明往往与更严重的碰撞有关,这可能是因为直接在视区中面对太阳时,能见度降低了。
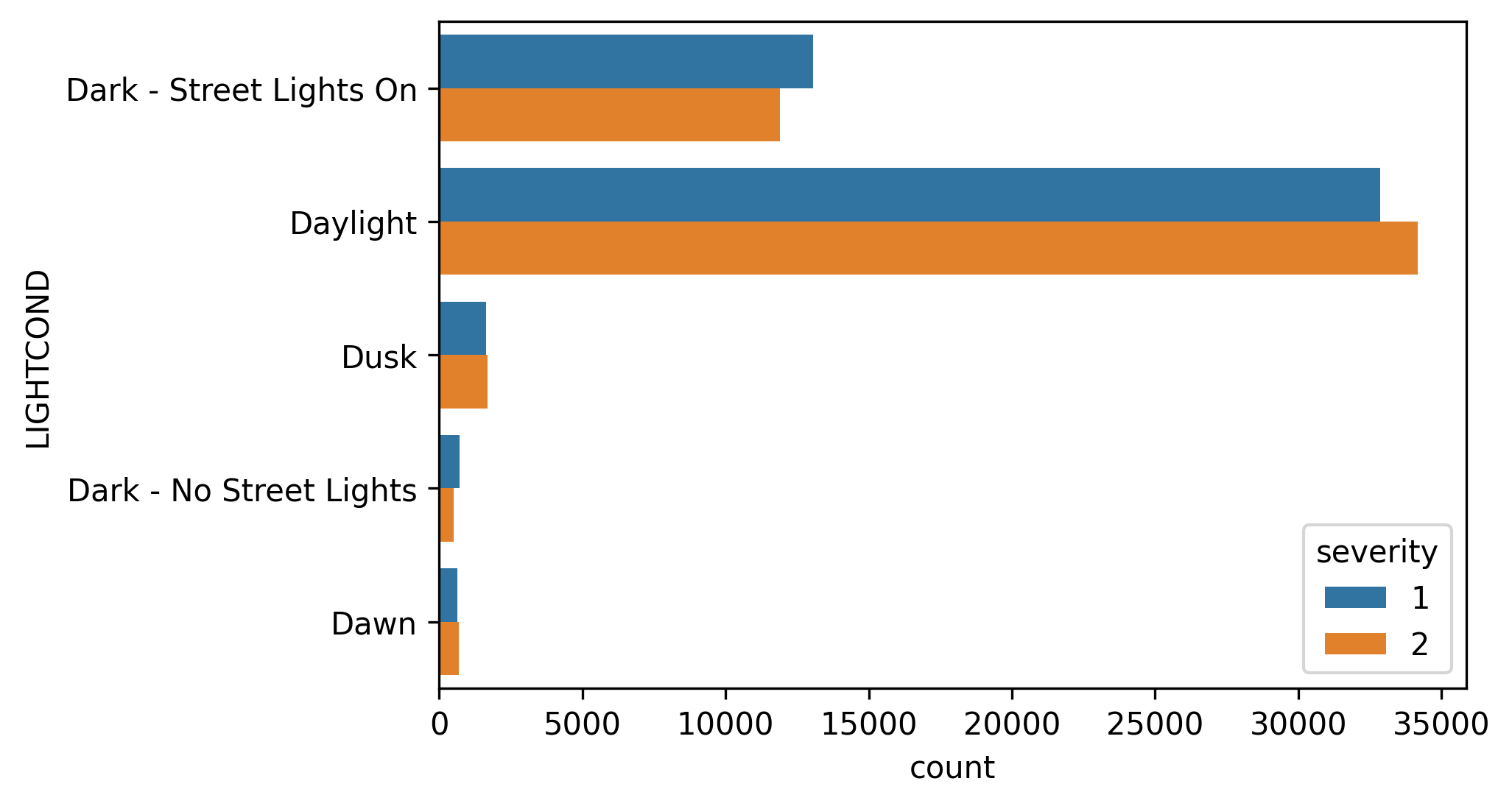
Considering weather data, severe accidents are slightly more frequent during rainy weather as well as with wet roads.
考虑到天气数据,在雨天以及潮湿的道路上,严重事故的发生频率稍高一些。
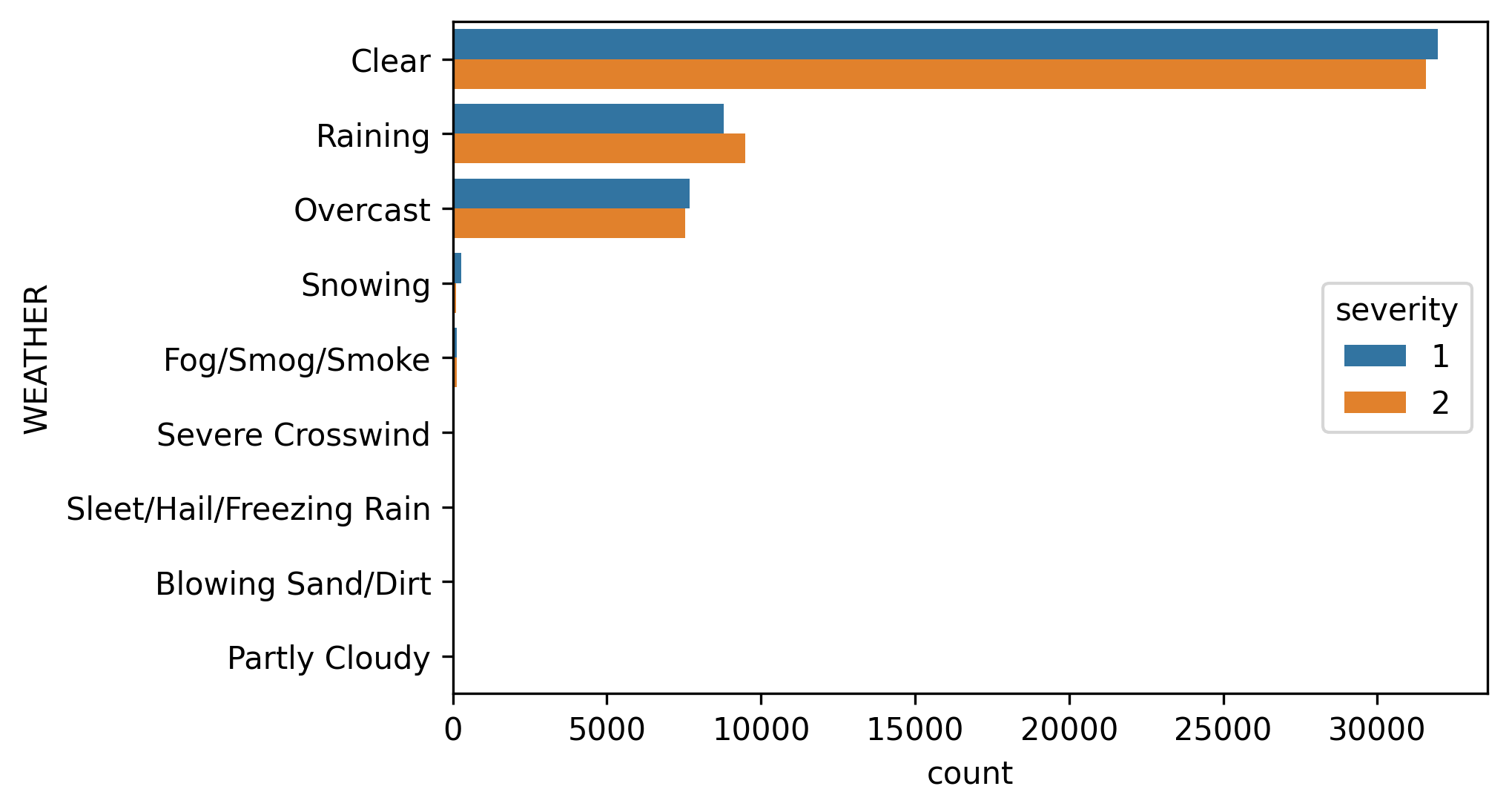
However data is pretty balanced between both severity types and for this reason, the lack of entropy do not add too much information to our model.
但是,两种严重性类型之间的数据相当平衡,因此,缺乏熵不会给我们的模型增加太多信息。
群集碰撞在不同的地理区域 (Clustering collisions in different geographic areas)
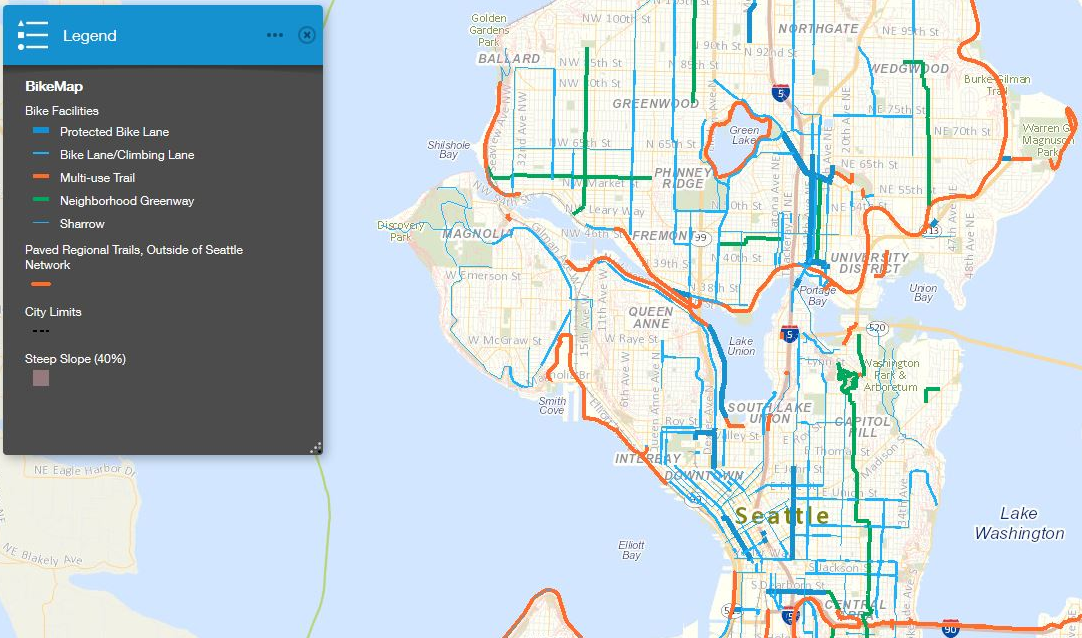
One relevant question to explore is, where are most of the accidents occurring? Are there some hot zones where is most probable to have collisions?. In the following pictures a map including clusters with incidents is displayed.
需要探讨的一个相关问题是,大多数事故发生在哪里? 是否有一些最可能发生碰撞的高温区域? 在以下图片中,显示了包含带有事件的聚类的地图。
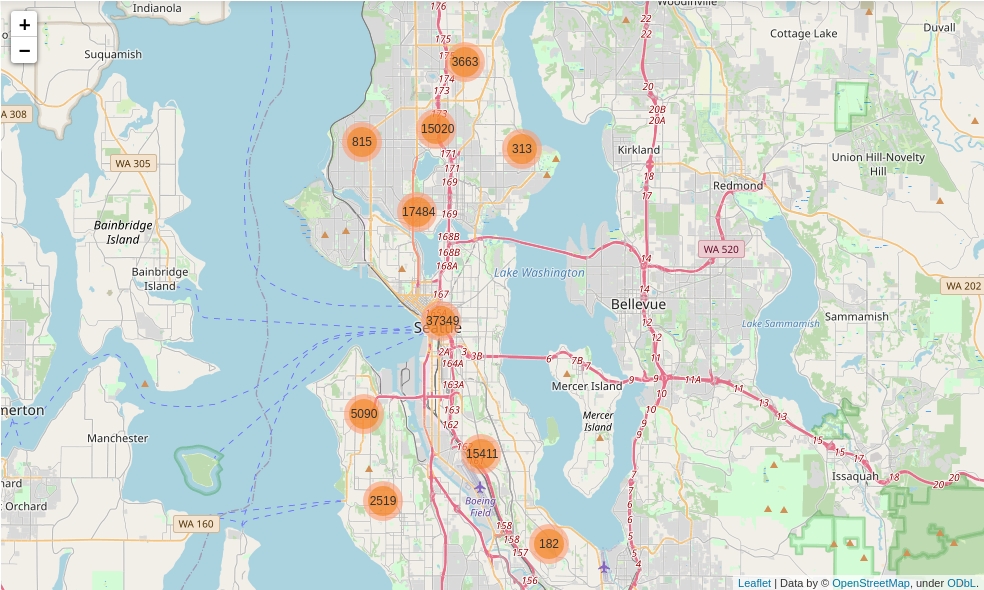
It is pretty clear that most of the accidents occurs in Pioneer Square, Yesler Terrace, the Downtown, Belltown and Pike/Pine. A closer picture let us recreate smaller clusters which shows further information about these areas.
很明显,大多数事故发生在先锋广场,Yesler Terrace,市区,贝尔敦和派克/松树。 通过仔细观察,我们可以重新创建较小的群集,这些群集显示了有关这些区域的更多信息。
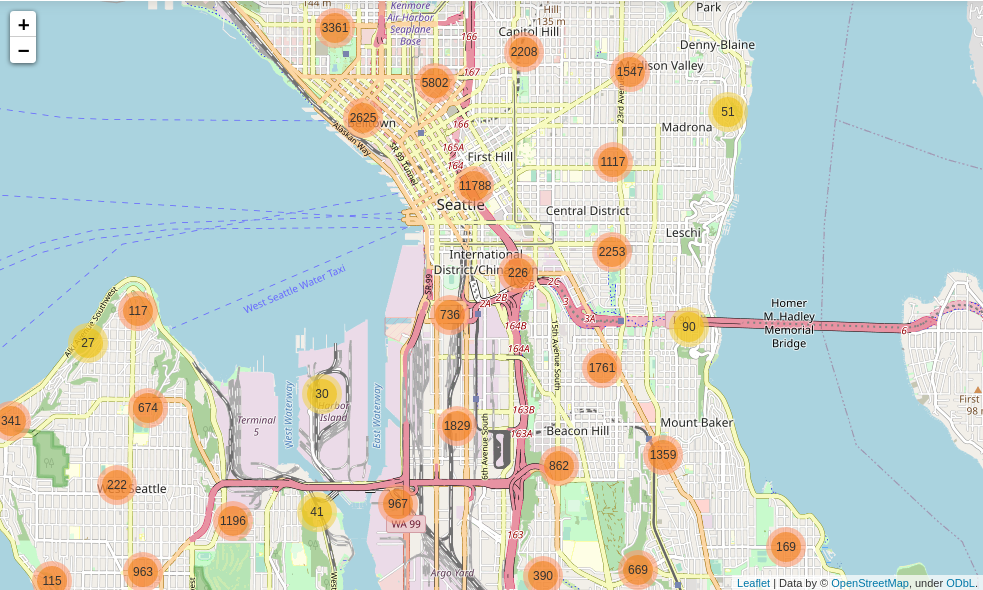
The last picture show us that the Downtown and the North-Eastern neighbors are the ones with more events. These neighbors should take more attention and further evaluation from the local government and transportation division to increase infrastructure and to reduce the collision incidences. Clearly this is the hot accident spot in the metropolis where car users have to pay extra attention in their maneuvers.
最后一张照片向我们显示,市中心和东北邻居是发生更多事件的邻居。 这些邻居应引起当地政府和运输部门的更多关注和进一步评估,以增加基础设施并减少碰撞事故。 显然,这是大都市中最热的事故现场,汽车使用者在操作时必须格外注意。
预测建模 (Predictive Modeling)
We are going to use in particular the following classifier algorithms given the type of data and the predictions we would like to do: K-Nearest Neighbor (KNN), Decision Tree (DT), Support Vector Machine (SVM), Logistic Regression(LR) and Random Forest (RF). The model with the best results will be optimized in order to fine tune it and compare the difference with the standard values.
给定数据类型和我们要进行的预测,我们将特别使用以下分类器算法:K最近邻(KNN),决策树(DT),支持向量机(SVM),对数回归(LR) )和随机森林(RF)。 将对效果最佳的模型进行优化,以对其进行微调并将差异与标准值进行比较。
It is important to select variables which can perform the best in the classification process and at the same time can have predictive use. For this reason and for what was commented in the feature selection paragraph, the predictors are WEATHER, ROADCOND and LIGHTCOND.
重要的是选择在分类过程中表现最好的变量,同时可以预测性地使用变量。 出于这个原因以及在功能选择段落中的注释,预测变量为WEATHER,ROADCOND和LIGHTCOND。
Another important thing to take into account is how to encode the categories in each predictor, since each variable has several categories. The best approach is to convert everything to one hot encoding to avoid the model getting lost in hierarchy issues present in label encoding methods. In those cases, the model may try to predict values which are in the middle of a category. However, this is not representative of the observable universe, because they do not actually exist. Finally, to avoid biases, it is important to normalize information before entering our observation matrix to the training.
要考虑的另一重要事项是如何在每个预测变量中对类别进行编码,因为每个变量都有多个类别。 最好的方法是将所有内容都转换为一种热编码,以避免模型因标签编码方法中出现的层次结构问题而迷失。 在那些情况下,模型可能会尝试预测类别中间的值。 但是,这并不代表可观察的宇宙,因为它们实际上并不存在。 最后,为了避免偏差,在将我们的观察矩阵输入训练之前,对信息进行规范化很重要。
结果 (Results)
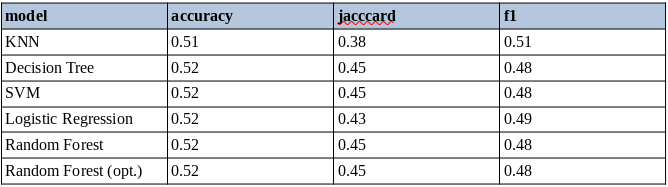
To keep things short, I will only show a table with the performance results per each classifier and also an optimization to the RF algorithm which looked most promising.
为了简短起见,我将仅显示一个表格,其中包含每个分类器的性能结果,以及对最有希望的RF算法的优化。
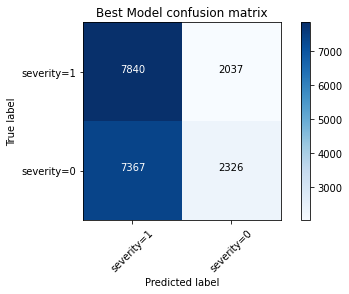
Above you can find the confusion matrix for the best model approach.
您可以在上面找到最佳模型方法的混淆矩阵。
You can find more in-depth information in the report contained in my github repository, together with the jupyter notebook.
您可以在github存储库中的报告以及jupyter笔记本中找到更深入的信息。
讨论区 (Discussion)
Collisions which does not involve personal injuries are twice as frequent as the ones involving damaged people. Much of the useful information for classification is embedded in the post-collision data collected. From this information, it was learned that accidents involving cycles or pedestrians are severe and involves injuries. It is important to take care of them since they are highly vulnerable to traffic incidents. Some efforts are being held to mitigate those risks providing interurban trails, to transit with bikes or simply walking. The downtown, which has the highest collision record, have implemented many protected bike lanes, and multi-use lanes, shared with pedestrians, that extends to nearby neighborhoods such as Queen Anne, Capitol Hill, between others.
不涉及人身伤害的碰撞的频率是受伤人员的碰撞频率的两倍。 用于分类的许多有用信息都嵌入到收集的碰撞后数据中。 从该信息中了解到,涉及自行车或行人的事故是严重的,并且涉及伤害。 重要的是要照顾他们,因为他们极易受到交通事故的影响。 为了减轻城市间步道,骑自行车或步行时的危险,人们正在做出一些努力。 拥有最高碰撞记录的市中心已实施了许多受保护的自行车道和与行人共享的多用途车道,延伸至附近社区,例如安妮女王区,国会山等。
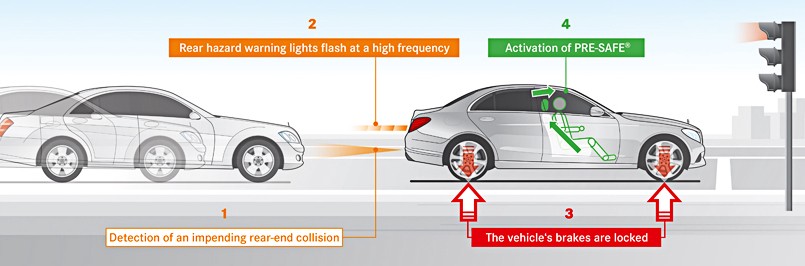
The riskier car collisions are the ones that hit the car from the rear end. This characteristic can aid car automakers to improve the vehicles design in order to mitigate the effects of this kind of collisions. At the same time the frequency of this type of collision is quite high, what put them in central debate. Some studies affirm that many of these accidents are caused by distracted drivers, fatigue, aggressive (speeding) and drunk driving. Efforts are being held to mitigate this incidents with the implementation of crash avoidance systems which take the car brakes control if there is a risk of collision with the car in front of the first. It is rather important and highly recommended, that car users choose this as a safety feature.
高风险的汽车碰撞是从后端撞到汽车的碰撞。 该特性可以帮助汽车制造商改善车辆设计,以减轻这种碰撞的影响。 同时,这种碰撞的频率很高,这引起了人们的广泛争议。 一些研究确认,这些事故中的许多事故是由驾驶员分心,疲劳,激进(超速)和酒后驾驶引起的。 人们正在努力通过实施防撞系统来减轻这种事故的发生,该系统将在汽车与前者发生碰撞的风险时控制汽车的制动器。 汽车使用者选择此项作为安全功能非常重要,因此强烈建议使用。
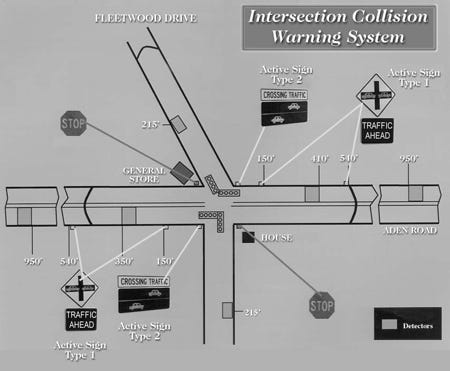
Safety at unsignalized intersections is a major concern. Intersection collisions are one of the most common types of crash, and in the United States, they account for nearly 2 million accidents and 6,700 fatalities every year. However, a fully signalized intersection can sometimes be hard to justify in rural areas, due to the cost of installation, maintenance, and added delays to traffic on the major through streets. The Intersection Collision Warning System (ICWS) project studied the effectiveness of an innovative and potentially less expensive approach to improving safety in these situations. This approach consists of two types of traffic-actuated warning signs linked to pavement loops and a traffic signal controller. Concerning the particular Seattle situation, using the same database, in this page a list of the most dangerous intersections can be found.
无信号交叉口的安全是一个主要问题。 交叉路口碰撞是最常见的碰撞类型之一,在美国,每年造成近200万起事故和6700人死亡。 但是,由于安装,维护的成本以及主要街道上交通的延误,在农村地区有时很难证明一个完全信号化的十字路口是合理的。 交叉路口碰撞预警系统(ICWS)项目研究了在这种情况下提高安全性的创新且可能成本更低的方法的有效性。 该方法由链接到人行道环路和交通信号控制器的两种交通驱动警告标志组成。 关于特定西雅图的情况,使用相同的数据库,在此页面中可以找到最危险的交叉口的列表。
From the collision geographic clustering, the Downtown and the North-Eastern neighborhoods are the ones with more events. These neighborhoods should take more attention and further evaluation from the local government and particularly the transportation division, to increase infrastructure and to reduce the collision incidences. Clearly this is the hot accident spot in the metropolis where car users have to pay extra attention in their maneuvers.
从碰撞地理聚类来看,市区和东北街区是事件较多的街区。 这些社区应得到当地政府特别是交通部门的更多关注和进一步评估,以增加基础设施并减少碰撞事故。 显然,这是大都市中最热的事故现场,汽车使用者在操作时必须格外注意。
结论 (Conclusion)
Much of the data analyzed had revealed some important information about car accidents. Concerning the riskier ones which involve personal injuries, the focus has to be made in some important factors: intersections, rear end collisions, pedestrian and cycles. Left turns are also risky maneuvers which should also be avoided if the road users want to be safe.
分析的许多数据揭示了一些有关车祸的重要信息。 对于涉及人身伤害的高风险人群,必须将重点放在一些重要因素上:交叉路口,追尾碰撞,行人和自行车。 左转弯也是危险的操作,如果道路使用者希望安全,也应避免转弯。
Extremely dangerous weather and road conditions do not produce a quite significant accident rate, such as snow and ice. However ,caution have to be taken with rainy weather and wet roads, since after clear days and dry roads, these are the following conditions in order of importance.
极端危险的天气和道路条件不会产生相当大的事故率,例如雪和冰。 但是,在阴雨天气和潮湿的道路上必须谨慎,因为在晴朗的天气和干燥的道路之后,以下是按重要性顺序排列的条件。
Finally, the results of the machine learning algorithms using predictors such as the weather, road and light conditions throws mediocre results. Other factors have to be considered to improve the prediction rate of the models being used.
最后,使用天气,道路和光照条件等预测变量的机器学习算法的结果将得出中等的结果。 必须考虑其他因素以提高所使用模型的预测率。
翻译自: https://medium.com/@adenevreze/car-accident-severity-in-seattle-wa-b398621f159a
西雅图雨衣














 288
288











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









