





Learning the uses of trees and specifically binary search trees with javascript implementation
通过javascript实现学习树的用法,特别是二进制搜索树的用法
Early on in our journey in software development, most of the data structures we encounter are linear. The common ones are arrays, strings perhaps linked lists or even stacks and queues. Depending on the programming language of your choice, some of the data structures mentioned can have varying degrees of similarity. They are relatively easy to understand, and they help us become familiar with the tools that the specific programming language offers. However, linear data structures most definitely do not take care of all of the problems we need to solve, not only in the CS(computer science) world but in the real world as well.
在软件开发过程的早期,我们遇到的大多数数据结构都是线性的。 常见的是数组,字符串,也许是链表,甚至是堆栈和队列。 根据您选择的编程语言,所提到的某些数据结构可能具有不同程度的相似性。 它们相对容易理解,并且可以帮助我们熟悉特定编程语言提供的工具。 但是,线性数据结构绝对不能解决我们需要解决的所有问题,不仅在CS(计算机科学)世界中,而且在现实世界中也是如此。
This is where trees come in. Like many things in nature, trees are a hierarchical structure. You must have heard of the DOM tree. As the name suggests, it is a tree of document object models. The file system in your computer is in a tree structure. If you wanted to find a specific ancestor of yours, it would be in a tree with you at the root. Today, we are going to look specifically at a type of tree, binary search tree.
这就是树木进入的地方。就像自然界中的许多事物一样,树木是一个层次结构。 您一定听说过DOM树。 顾名思义,它是文档对象模型的树。 您计算机中的文件系统为树形结构。 如果您想找到自己的特定祖先,那将是一棵以您为根的树。 今天,我们将专门研究一种树,即二进制搜索树。
介绍BST (Introducing BST)
A binary tree is a tree where each node has a maximum of two children nodes. A binary search tree is a type of binary tree where for each node, the left child is smaller than the root and the right child is greater than the node. In other words, the binary search tree is a sorted tree. Because of the recursive nature of tree structure, every child node is a binary search tree itself as you can see from the example BST below.
二叉树是其中每个节点最多具有两个子节点的树。 二进制搜索树是一种二进制树,其中对于每个节点,左子节点小于根节点,右子节点大于节点根。 换句话说,二分搜索树是排序树。 由于树结构的递归性质,每个子节点本身就是一个二进制搜索树,如下面的示例BST所示。
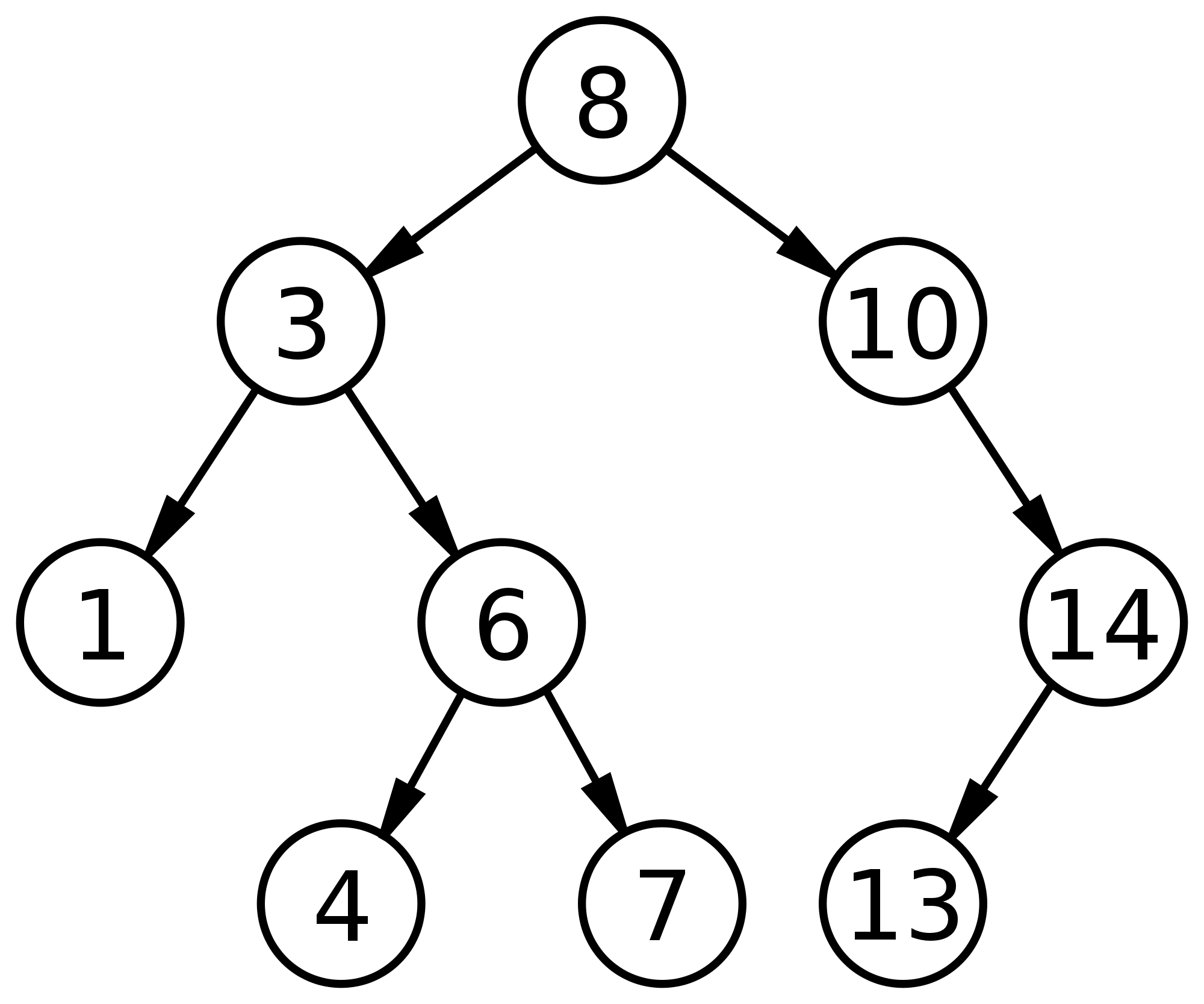
通过BST遍历 (Traversing through a BST)
There are typically two ways to traverse/search through a binary tree. One is called the breadth-first search(BFS), and the other is called the depth-first search(DFS). You might think to yourself, these are the terms that I hear people say when talking about graphs? You would be right because a tree is just a special type of graph. Later, we will see the implementation in javascript, but the concept/algorithm should be easily applicable and translatable to any other language.
通常有两种遍历/搜索二叉树的方法。 一个称为广度优先搜索(BFS),另一个称为深度优先搜索(DFS)。 您可能会想自己,这些是我在听到人们谈论图形时所说的术语吗? 您将是对的,因为树只是图的一种特殊类型。 稍后,我们将看到用javascript实现的概念,但是该概念/算法应易于应用并且可以翻译为任何其他语言。
实施BFS (Implementing BFS)
The following is the javascript implementation of BFS. The code also includes the implementation of the basic structure of each node in a tree and a queue. This assumes a basic understanding of the queue data structure. Assuming the initial root node given is not empty, we print out the value in the node while pushing its children into the queue from left to right(the order does not matter here as long as it is consistent). From this point on, we will only be pushing further children into the queue while popping what is already in the queue to print. Because of the nature of the queue, each level will be printed in order.
以下是BFS的javascript实现。 该代码还包括树和队列中每个节点的基本结构的实现。 这假定对队列数据结构有基本的了解。 假设给定的初始根节点不为空,我们在打印该节点中的值的同时将其子级从左到右推入队列(只要顺序一致,顺序就无关紧要)。 从这一点开始,我们将仅弹出更多队列中的孩子,同时弹出队列中要打印的内容。 由于队列的性质,将按顺序打印每个级别。
class node{constructor(val){this.value = val;this.left = null;this.right = null;}}class queue{constructor(){this.value = [];}enqueue(val){this.value.push(val);}dequeue(val){return this.value.shift(val);}front(){return this.value[0];}empty(){return this.value.length === 0;}}const BFS = (root) => {if(!root.value){//returns null for empty treereturn null;}let q = new queue();q.enqueue(root);while(!q.empty()){let current = q.front();q.dequeue();//we console.log the value here to print out each value//but you can replace this with any other operation//fit for the situationconsole.log(current.value);if(current.left !== null){q.enqueue(current.left);}if(current.right !== null){q.enqueue(current.right);}}}The time taken to traverse each node is constant. We only traverse each node once; therefore, the time complexity of this traversal is O(n). However, the space complexity has the best case O(1), but that is seldom the case since we will not always get a tree with each node having only one child. The average and the worst case for space complexity is O(n).
遍历每个节点所花费的时间是恒定的。 我们只遍历每个节点一次; 因此,该遍历的时间复杂度为O(n)。 但是,空间复杂度的最佳情况为O(1),但这很少见,因为我们不会总是得到一棵树,而每个节点只有一个孩子。 空间复杂度的平均和最坏情况是O(n)。
实施DFS (Implementing DFS)
As we have seen, the following code is the node structure that makes up a tree. I will leave this here for reference as it is used in all 3 kinds of DFS. They are pre-order, in-order and post-order traversals. They will be explained in detail below.
如我们所见,以下代码是组成一棵树的节点结构。 我将在此保留所有3种DFS使用的参考。 它们是预遍历,有序遍历和后遍历。 它们将在下面详细解释。
class node{constructor(val){this.value = val;this.left = null;this.right = null;}}预购遍历 (Pre-order Traversal)
The first kind of depth-first search we will be implementing is preorder traversal. As the name might suggest, we will print each node’s value first and traverse to the left followed by traversing to the right. When thinking about this on one node, the procedure might seem quite static, but when applied to the entire tree/all nodes, the process is recursive. When you arrive at a node, you first print the value, then you look for whether the left child exists before looking for the right child. You traverse down the tree by recursively calling the child nodes on the left and the right in the desired order. The implementation is as follows.
我们将要实现的第一种深度优先搜索是顺序遍历。 顾名思义,我们将首先打印每个节点的值,然后向左遍历,然后向右遍历。 在一个节点上考虑这一点时,该过程似乎很静态,但是将其应用于整个树/所有节点时,该过程是递归的。 到达节点时,首先打印该值,然后在寻找合适的孩子之前先检查左边的孩子是否存在。 通过以所需顺序递归调用左侧和右侧的子节点,可以遍历树。 实现如下。
const preorder = (root) => {if(!root.value){//return null if the root node given is emptyreturn null;}console.log(root.value);preorder(root.left);preorder(root.right);}The pre-order traversal can be used when trying to make a copy of a binary tree.
尝试遍历二叉树时可以使用预遍历。
有序遍历 (In-order traversal)
The in-order traversal is quite commonly used as it follows the order of a binary search tree. Quite similar to pre-order traversal, in-order traversal only changes when we print the current value. In-order traversal is one of the most efficient methods to determine whether a binary tree is a binary search tree.
有序遍历是非常常用的,因为它遵循二叉搜索树的顺序。 与预遍历非常相似,仅当我们打印当前值时,有序遍历才会更改。 有序遍历是确定二叉树是否为二叉搜索树的最有效方法之一。
const inorder = (root) => {if(!root.value){//return null if the root node given is emptyreturn null;}inorder(root.left);console.log(root.value);inorder(root.right);}后遍历 (Post-order traversal)
The post-order traversal takes printing the current value to the end of the cycle. You check the left child first, then the right child and finally printing the current node. We can use this method to delete the tree.
后遍历将当前值打印到循环结束。 您首先检查左子节点,然后检查右子节点,最后检查当前节点。 我们可以使用这种方法删除树。
const postorder = (root) => {if(!root.value){//return null if the root node given is emptyreturn null;}postorder(root.left);postorder(root.right);console.log(root.value);}DFS的时空复杂性 (Time and space complexity of DFS)
Since we have only one function call for each node, the time complexity for all three DFS is O(n). However, the space complexity for these algorithms is the height of the given tree. That can vary depending on what the tree looks like. The height in the worst case would be the number of nodes minus 1. The space complexity for that would be O(n). But, that is not always the case, hopefully. The best case, which also happens to be the average case, is O(log(n)).
由于每个节点只有一个函数调用,因此所有三个DFS的时间复杂度均为O(n)。 但是,这些算法的空间复杂度是给定树的高度。 视树的外观而定。 最坏情况下的高度为节点数减去1。空间复杂度为O(n)。 但是,希望并非总是如此。 最佳情况(也恰好是平均情况)是O(log(n))。
摘要 (Summary)
We just went over the basic concepts of a binary tree, binary search tree and the implementation of the algorithms for traversals in javascript. Hopefully, next time you encounter a problem that is related to the binary search trees, these tools can help solve it.
我们仅介绍了二叉树,二叉搜索树的基本概念以及javascript中遍历算法的实现。 希望下次您遇到与二分搜索树相关的问题时,这些工具可以帮助解决该问题。
翻译自: https://medium.com/@qchenry.mao/introduction-of-binary-search-tree-in-javascript-b4977bdd3725















 1465
1465

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









