





机器学习 算法和模型
A common confusion for beginners in machine learning is the difference between a “machine learning algorithm” and a “machine learning model”. Both terms are used often interchangeably which makes it even more confusing.
对于初学者而言,机器学习的一个普遍困惑是“ 机器学习算法 ”和“ 机器学习模型 ”之间的区别。 这两个术语经常互换使用,这使其更加混乱。
In fact, I was writing another Medium article on machine learning and stumbled on this very dilemma myself! So, are they the same thing?
实际上,我在写另一篇有关机器学习的中型文章,却自己偶然发现了这个难题! 那么,他们是同一回事吗?
The quick answer is NO, a machine learning algorithim is like a procedure run on data to find patterns and rules which are stored in and used to create a machine learning model which is like a program that can be used to make predictions.
简单的回答是NO,机器学习algorithim像上的数据的程序运行发现它们存储在并用于创建一个机器学习模型,就像是可以用来做预测的节目模式和规则。
什么是算法? (What is an Algorithm?)
A machine learning “algorithm” is essentially a procedure that is used to find patterns within data and learn from the data. It is commonly said to be “fit” on a dataset which means it is applied on the dataset.
机器学习“ 算法 ”本质上是一种用于在数据中查找模式并从数据中学习的过程。 通常认为它适合数据集,这意味着它已应用于数据集。
There are many different types of algorithms with many different functions and purposes. The three main ones are:
有许多不同类型的算法,它们具有许多不同的功能和目的。 三个主要的是:
Regression: Used for making predictions where the output is a continuous value, such as Logistic Regression.
回归:用于在输出为连续值的情况下进行预测,例如Logistic回归。
Classification: Used for making predictions where the output is a categorical value, such as K-Nearest Neighbors.
分类:用于在输出为分类值(例如K最近邻居)的情况下进行预测。
Clustering: Used for grouping similar things or data points into clusters, such as K-Means.
聚类:用于将相似的事物或数据点分组为聚类,例如K-Means。
They are similar to other algorithms in computer science and similarly have a mathematical backbone to them. For example, the simple linear regression algorithm is represented by the familiar equation
它们与计算机科学中的其他算法相似,并且具有类似的数学主干。 例如,简单的线性回归算法由熟悉的方程式表示

Where ŷ is the predicted value of y (the dependent variable), X is the value of X (independent variable), β1 is the slope of the line, and β0 is a constant.
其中ŷ是y的预测值(因变量),X是X的值(因变量),β1是直线的斜率,β0是常数。
This algorithm is then run on the data and tries to optimize, adjusting the slope and constant, to achieve maximum efficiency by minimizing the amount of error, measured by the average of squared errors.
然后对数据运行该算法,并尝试优化,调整斜率和常数,以通过最小化由平方误差的平均值衡量的误差量来实现最大效率。
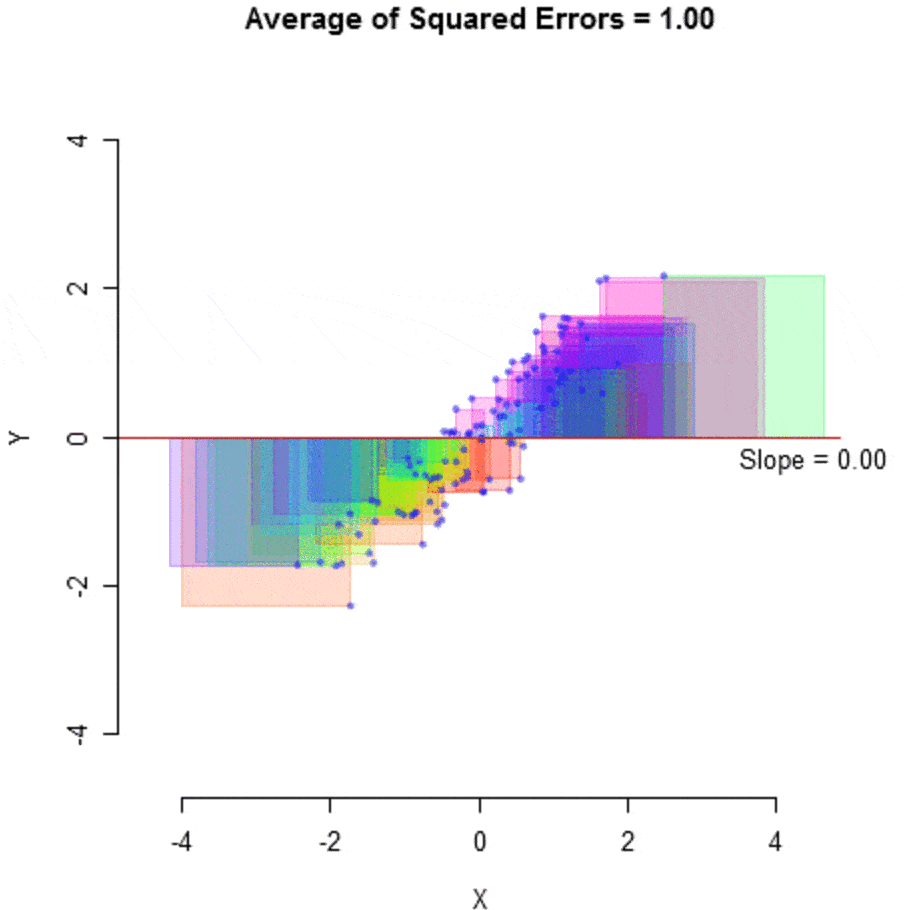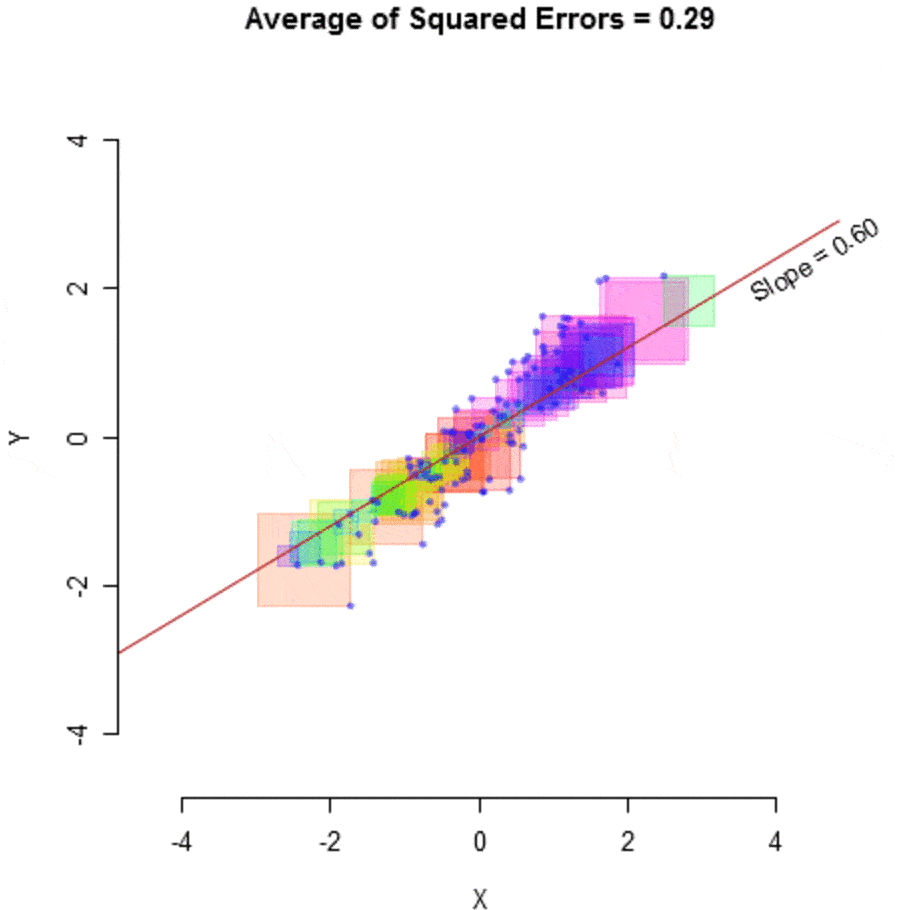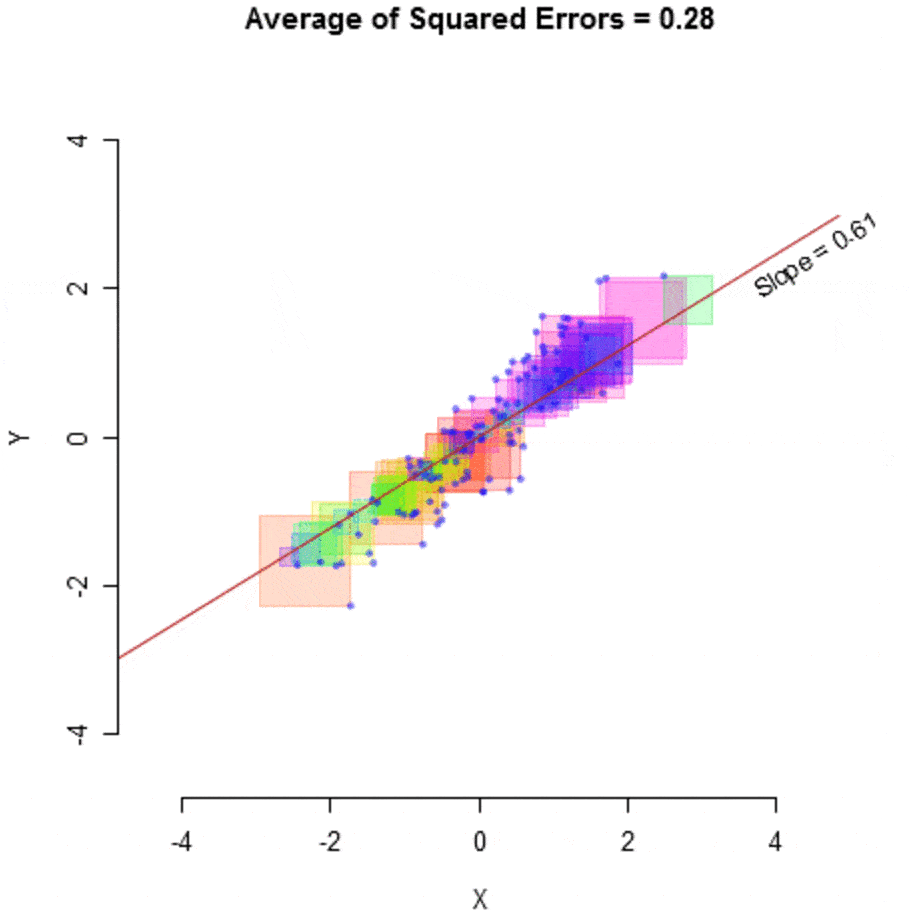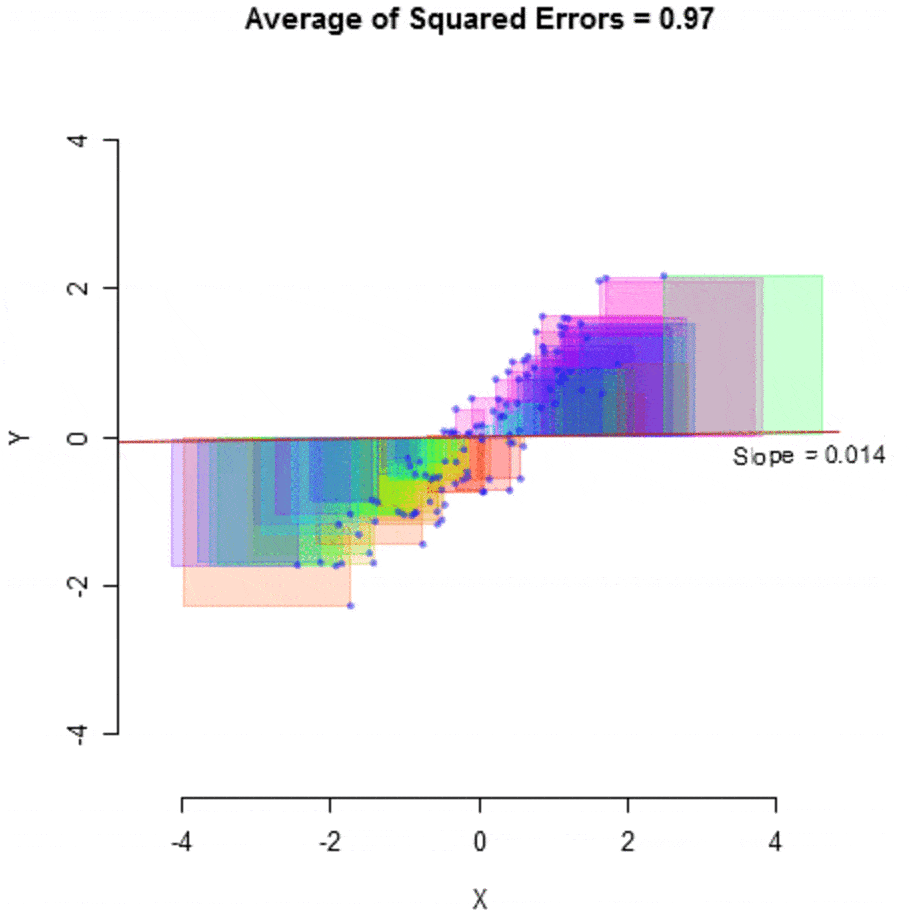
什么是模型? (What is a Model?)
A machine learning “model” is where the output of the “algorithm” is stored. It represents what was learned from the algorithm “training” on the data and holds a specific set of features from the algorithm.
机器学习的“ 模型 ” 是“ algorithm ”输出的存储位置。 它表示从算法对数据的“ 训练 ”中学到的内容,并拥有该算法的一组特定功能。
- A linear regression model stores the vector of coefficients and constants that is best fit for the data. 线性回归模型存储最适合数据的系数和常数向量。
- A decision tree model stores the set of if-then statements corresponding to the individual branches. 决策树模型存储与各个分支相对应的if-then语句集。
- A neural network model stores the weights and biases associated with the separate matrices for backpropagation and gradient descent. 神经网络模型存储权重和与单独矩阵相关的偏差,以进行反向传播和梯度下降。

The model can be saved for later and acts as a program, using previously stored features from the algorithm to make new predictions. If the model is trained effectively and sufficiently, it can be used to make many more predictions on similar data to a certain level of accuracy and confidence.
使用以前存储的算法特征进行新的预测,可以保存模型以供以后使用并充当程序。 如果对模型进行了有效和充分的训练,则可以将其用于对相似数据进行更多的预测,从而达到一定的准确性和置信度。
算法与模型 (Algorithm vs Model)
Now that we know what an algorithm and a model are, it’s easier to see how they relate. As mentioned previously, an algorithm is run on data to create a model.
既然我们知道什么是算法和模型,现在更容易了解它们之间的关系。 如前所述,算法在数据上运行以创建模型。
That model is comprised of both data and a procedure for how to use the data to make a prediction on new data. The procedure is almost like a prediction algorithm.
该模型既包含数据,又包含如何使用数据对新数据进行预测的过程。 该过程几乎类似于预测算法。
Although, not all models store a prediction algorithm. Some, like k-nearest neighbors, store the entire dataset which acts as the prediction algorithm. This is all based on the purpose your model serves, however.
虽然,并非所有模型都存储预测算法。 一些像k最近邻居,存储整个数据集,用作预测算法。 但是,这全都基于模型服务的目的。
We essentially want a machine learning “model” and don’t care as much about the algorithm behind it. It is, however, important to know which algorithm to apply to your model to yield the best results. But once you know that, It’s only a few lines of code and few levels of interaction before you have yourself a perfectly working model.
我们本质上是希望机器学习的“ 模型 ”,而不是在乎其背后的算法。 但是,重要的是要知道将哪种算法应用于模型以产生最佳结果。 但是一旦您知道了这一点,在拥有完善的工作模型之前,只需执行几行代码并进行少量交互。
摘要 (Summary)
- Machine learning algorithms are procedures run on data to find patterns and learn 机器学习算法是在数据上运行以查找模式并学习的过程
- Machine learning models are the output of algorithms and are comprised of data and a prediction algorithm. 机器学习模型是算法的输出,由数据和预测算法组成。
Machine learning algorithms provide a type of automatic programming where machine learning models represent the program itself
机器学习算法提供一种自动编程 ,其中机器学习模型代表程序本身
Gain Access to Expert View — Subscribe to DDI Intel
获得访问专家视图的权限- 订阅DDI Intel
机器学习 算法和模型















 2583
2583











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









