





决策树 建模
— This solution ranked 4th out of 10,000+ in All-India AI Hackathon, Automated Multi Label Classification, in Code Gladiators 2020 by Techgig.
—该解决方案在Techgig的Code Gladiators 2020年的 All-India AI Hackathon (自动多标签分类)中的10,000+ 中排名第4 。
Personal Note:
个人说明:
Mixed were the feelings when I got to know the Top 3 position in Hackathon was a narrow miss by 1 mark. While it was kinda re-assuring to stand 4th among Finalist Teams, despite myself participating alone, the void of one passionate team partner, was quite disquieting.
当我知道Hackathon的前三名是1个百分点的小失误时,我的感觉很复杂。 尽管我自己一个人参加,虽然在总决赛队伍中排名第四确实有些让人放心,但一个热情的团队合作伙伴的虚无却令人不安。
The Hackathon challenge was to multi-categorize 1M+ multi-lingual articles with meta-information, at high precision. The meta-information denotes the category-tree information hidden in the URL text sequence and also the title of each article. You can get a glance at the input data-set below.
Hackathon面临的挑战是高精度地对具有元信息的1M +多语言文章进行多分类。 元信息表示隐藏在URL文本序列中的类别树信息,以及每个文章的标题。 您可以浏览下面的输入数据集。
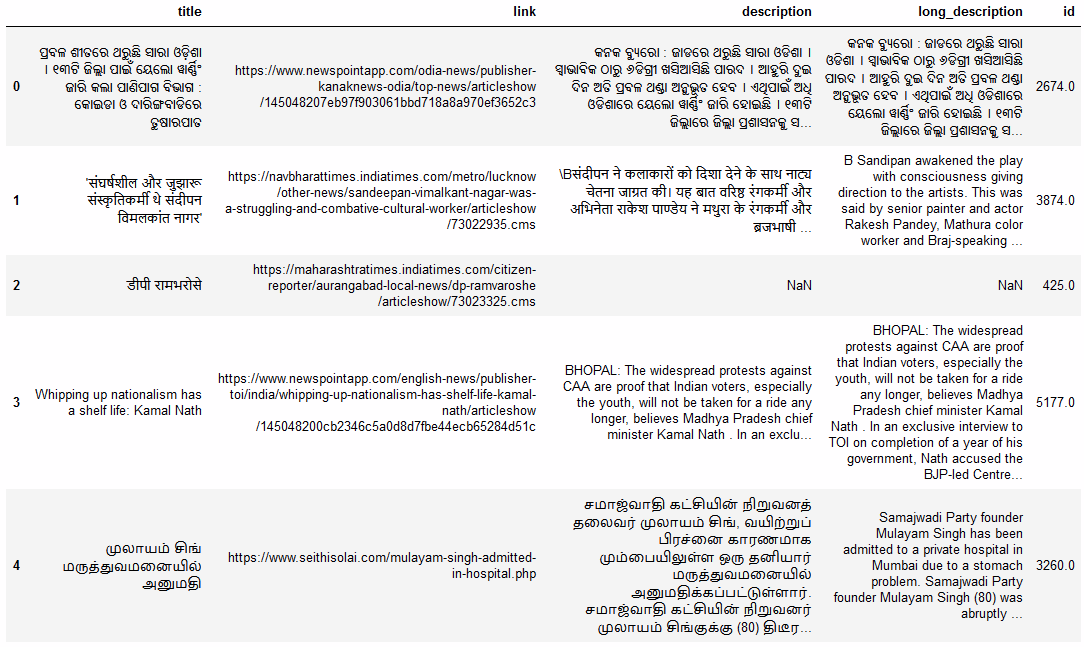
The above articles are to be categorized into a category hierarchy based on the article topic. For instance, “Modi visits to China” are to be categorized in “Politics^International” while “Corona tally reached record high” as “Health^Pandemic”.
以上文章将基于文章主题分类为类别层次结构。 例如,“莫迪访问中国”将被归类为“政治^国际”,而“电晕总数将创历史新高”归类为“健康^泛滥”。
As above data-set is very huge, enormous effort is required to label the articles manually. Our aim is to reduce the manual work to the extent possible. Hence, we aim to do Topic Modelling over the above data-set.
由于上述数据集非常庞大,因此需要大量的精力来手动标记商品。 我们的目标是尽可能减少人工工作。 因此,我们旨在对以上数据集进行主题建模。
主题建模与分类 (Topic Modelling vs Classification)
Topic Modelling is an ‘unsupervised’ ML technique to classify documents into different topics.
主题建模是一种“无监督”的 ML技术,用于将文档分类为不同的主题。
Topic Classification is a ‘supervised’ ML technique which consumes manually tagged data, to make predictions later.
主题分类是一种“监督”的机器学习技术,它使用手动标记的数据来进行预测。
Thus, it is clear that we need to do Topic Modelling as the input articles are not labelled, prior. But Topic Modelling won’t guarantee accurate results, though it is quick, as no training is required.
因此,很明显,我们需要进行主题建模,因为输入文章没有预先标记。 但是,主题建模虽然速度很快 , 但却不能保证准确的结果 ,因为不需要培训。
Hence, we need alternate categorization approaches and arrange them as cascaded fallback, while also improving upon Topic Modelling results.
因此,我们需要替代的分类方法,并将它们安排为级联的后备,同时还要改善主题建模的结果。
该解决方案的完整源代码可以在这里 找到 。 (The complete source code of the solution can be found here.)
级联的后备管道 (Cascaded Fallback Pipeline)
Main Approach: Category Tree Classifier using Description
主要方法:使用描述的类别树分类器
Correlate word vectors of the words present in node categories & article description, computed using Google Word2Vec Model. This model is pre-trained on Google News data-set, which is similar to the input data we need to categorize.
关联使用Google Word2Vec模型计算出的节点类别和文章描述中存在的单词的单词向量。 此模型已在Google新闻数据集上进行了预训练,该数据集与我们需要分类的输入数据相似。
2. Fallback 1: URL based Category Tree Classifier
2. 后备1:基于URL的类别树分类器
The sequence of folders, from left to right embodies the category hierarchy associated with the article. For instance, the below URL should be categorized as “News/Politics/BJP Politics”. If the confidence value of “Approach 1" falls below a threshold, then Fallback 1 is triggered.
文件夹的顺序从左到右体现了与文章关联的类别层次结构。 例如,以下网址应归类为“新闻/政治/ BJP政治”。 如果“方法1”的置信度值下降到阈值以下,则触发回退1。
3. Fallback 2: LDA-NMF Combination Model
3. 后备2:LDA-NMF组合模型
Latent Dirichlet Allocation (LDA) is a classic solution to Topic-Modelling. But in practice, it gave huge proportion of wrong classifications. Hence, Non Negative Matrix Factorization (NMF) is also used and numerically combined with LDA, along with Multi Class Binarizer to refine the results.
潜在狄利克雷分配(LDA)是主题建模的经典解决方案。 但实际上,它给出了很大比例的错误分类。 因此,还使用非负矩阵分解(NMF)并将其与LDA进行数值组合,并与多类Binarizer一起对结果进行细化。
4. Fallback 3: Category Tree Classifier using Description
4. 后备3:使用描述的类别树分类器
If all the above approaches fail, then you can either mark the article as “unclassified” or take output of “Main Approach” as the final fallback.
如果上述所有方法均失败,则可以将文章标记为“未分类”,也可以将“主要方法”的输出作为最终的后备方法。
You can also check out “Improvements” head at the bottom of this blog, for further fallback strategies to replace Fallback 4.
您还可以在此博客底部查看“改进”标题,以了解替代后备4的其他后备策略。
解决方案架构 (Solution Architecture)
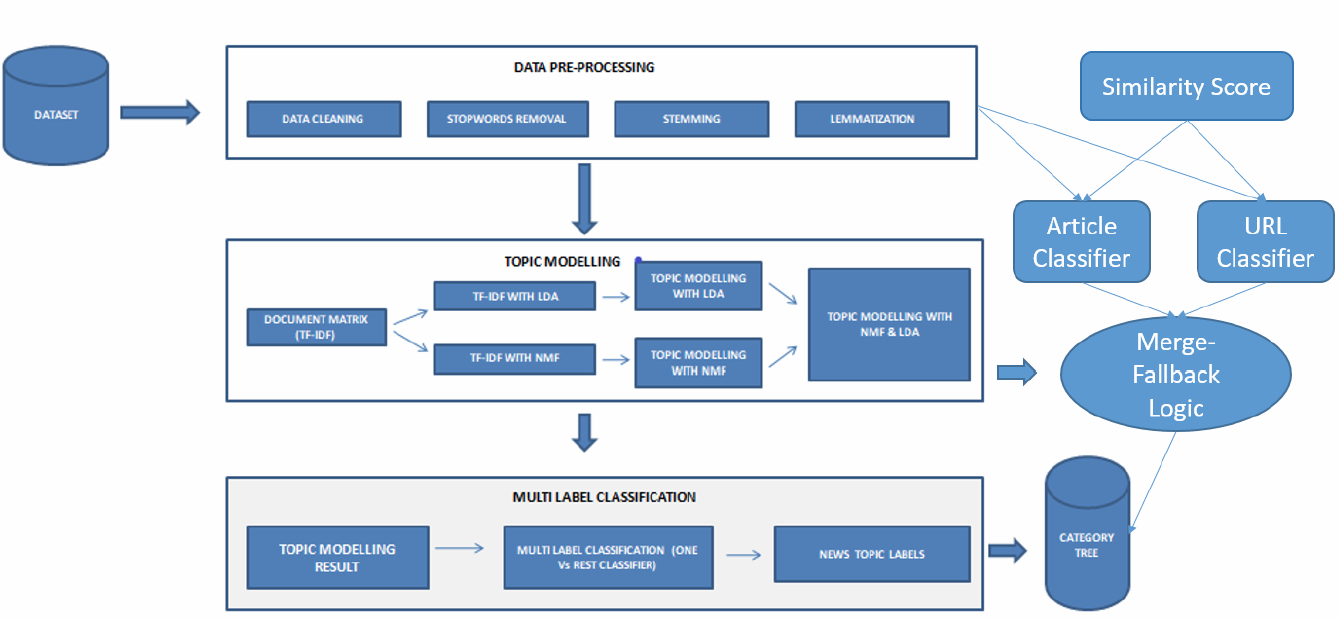
Prior to solution implementation, let's build the input category tree.
在实施解决方案之前,让我们构建输入类别树。
构造类别树 (Constructing Category Tree)
The category tree to classify the documents are given as csv file below.
用于分类文档的类别树在下面的csv文件中给出。
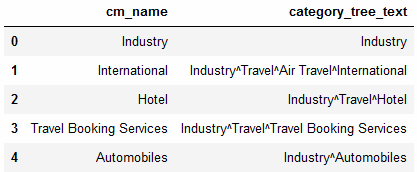
We can represent category tree using any python data structure. AnyTree package is used to create, manipulate & traverse the category tree input.
我们可以使用任何python数据结构表示类别树。 AnyTree包用于创建,操纵和遍历类别树输入。
from anytree import Node, RenderTree, PreOrderIter, find_by_attr
# Creating the Category Tree as Python Data structure - Anytree
with open('cat_tree.csv', 'r') as f:
lines = f.readlines()[1:]
root = Node(lines[0].split(",")[1].strip())
for line in lines:
line = line.split(",")[1]
for idx, cats in enumerate(line.split("^")[1:]):
catNode = find_by_attr(root, cats.strip())
if (catNode is None):
parentNode = find_by_attr(root, line.split("^")[idx])
if parentNode is None:
Node(cats.strip(), parent=root)
else:
Node(cats.strip(), parent=parentNode)
for pre, _, node in RenderTree(root):
print("%s%s" % (pre, node.name))The above code generated the tree structure from the input cat_tree.csv file.
上面的代码从输入的cat_tree.csv文件生成树结构。

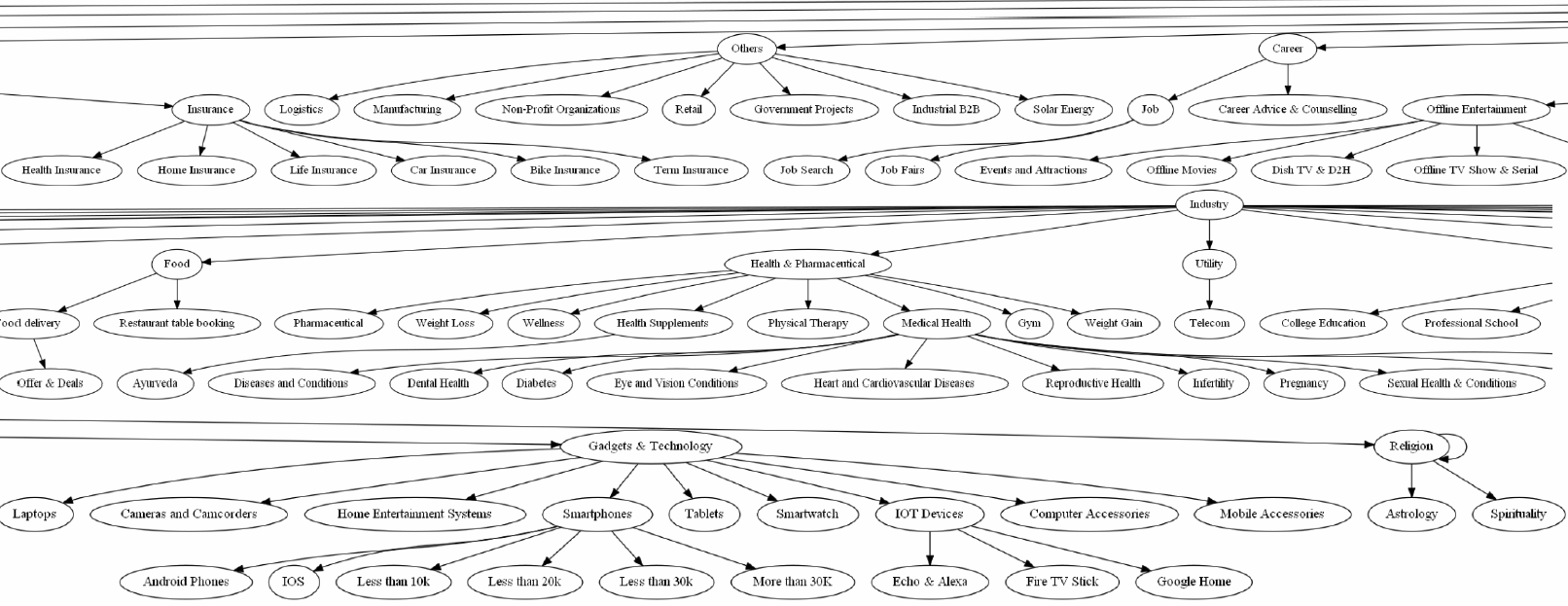
The category tree structure can be visualized using graphviz.
类别树结构可以使用graphviz可视化。
The non-English articles can easily be translated to ‘English’ using Google API. To save time, identify non-english rows and feed only those to below function.
使用Google API可以轻松地将非英语文章翻译为“英语”。 为了节省时间,请识别非英语行,然后仅将其馈入以下功能。
from googletrans import Translator
translator = Translator()
result = translator.translate('description in any language', dest='en')加载Google Word2Vec模型 (Loading Google Word2Vec Model)
Google’s pre-trained model which includes word vectors for a vocabulary of 3 million words and phrases that they trained on roughly 100 billion words from a Google News dataset. The vector length is 300 features and the training data set is similar to our input data set.
Google的预训练模型,其中包括300万个单词和短语的词汇向量,他们使用Google新闻数据集中的大约1000亿个单词进行了训练。 向量长度为300个特征, 训练数据集与我们的输入数据集相似。
# from gensim.models import Word2Vec
from gensim.models.word2vec import Word2Vec
from gensim.models import KeyedVectors
model = KeyedVectors.load_word2vec_format('GoogleNews-vectors-negative300.bin.gz', binary=True)主要逻辑:使用描述对类别树进行分类 (Main Logic: Category Tree Classn using Description)
Firstly, we correlate words in ‘long description’ with nodes to find category.
首先,我们将“长描述”中的单词与节点相关联以找到类别。
A deep algorithm which peruses GoogleNews vectors of category tree nodes correlated with each word in article description was implemented. Multi-word categories are intelligently handled not to hike up the similarity scores. This function is the core of the solution.
实现了一种深入的算法,该算法可细读与文章描述中每个单词相关的类别树节点的GoogleNews向量。 智能地处理多词类别,以免提高相似性分数。 此功能是解决方案的核心。
Breadth-First Correlation Traversal of category tree is done to find out the best category tree allocation based on Word2Vec similarity.
对类别树进行广度优先相关性遍历,以找到基于Word2Vec相似度的最佳类别树分配。
# To do multi level classification - category tree - using all the words
# in the article (stop words remove and cleaned) and also the words in the category tree nodes.
stop_words = set(stopwords.words('english'))
similarity_cutoff = 0.3
confidence_cutoff = 0.05
categoryMappings = []
for id, fulltxt in zip(idesc['id'], idesc['long_description']):
fulltxt_filtered = [w for w in str(fulltxt).lower().split() if not w in stop_words]
category_levels = [root]
while True:
tree_level = len(category_levels)
subCategories = category_levels[tree_level - 1].children
if len(subCategories) == 0:
categoryMappings.append([id, category_levels[tree_level - 1], confidenceRow])
break
level_similarity = [0] * len(subCategories)
for word in fulltxt_filtered:
# To exclude small words
if len(word) < 3:
continue
if word in model:
# To handle categories with multiple words. Eg: Banking & Finance
for i in range(len(subCategories)):
subCatWords = re.sub(r'[^A-Za-z0-9 ]+', '', subCategories[i].name).lower().split()
similarityCategory = []
for catWords in subCatWords:
if catWords in model:
similarityCategory.append(abs(model.similarity(word, catWords)))
if (len(similarityCategory) > 0):
level_similarity[i] = level_similarity[i] + similarityCategory[np.argmax(similarityCategory)]
maxsim_this_level = max(level_similarity, default=0)
confidence = computeConfidence(level_similarity)
# For level 1 entry, there is no confidence cutoff.
# If level > 1, then confidence score should be > cutoff
if (maxsim_this_level > similarity_cutoff and
(tree_level == 1 or confidence > confidence_cutoff)):
if (tree_level == 1):
confidenceRow = confidence
category_levels.append(subCategories[np.argmax(level_similarity)])
else:
categoryMappings.append([id, category_levels[tree_level - 1], confidenceRow])
break
catDetects = pd.DataFrame(categoryMappings)
catDetects.head(5)The above code is sophisticated enough to generate a rich category tree by analyzing each word in the article, correlated with words in node category.
上面的代码足够复杂,可以通过分析与节点类别中的单词相关的文章中的每个单词来生成丰富的类别树。

To combine the outcome of different algorithms, we need to compute the classification confidence for each article. Hence, saved the (id, tree, confidence) information into CSV file.
为了结合不同算法的结果,我们需要计算每篇文章的分类置信度。 因此,将(id,树,置信度)信息保存到CSV文件中。
The confidence score is computed using a mathematical formula based on the numerical distribution of values in the list. The formula computes the difference between highest similarity value and second highest value, as it denotes ambiguity when the top 2 values are near.
基于列表中值的数字分布 , 使用数学公式来计算置信度得分 。 该公式计算最高相似度值和第二最高相似值之间的差,因为它表示当前两个值接近时模棱两可。
# To compute the confidence score of category prediction based on the numerical distribution of values in the list
def computeConfidence(similarityList):
similarScores = set(similarityList)
highest = max(similarScores)
similarScores.remove(highest)
if (len(similarScores) == 0):
return 0
secondHighest = max(similarScores)
return (highest - secondHighest)/ (highest)调整类别树 (Tweaking Category Tree)
Multi-words categories having words of different meanings are combined into similar meaning words so that word vector distance metrics won’t go awry. For instance, “Education” was found similar to “Finance” among word vectors, hence renamed to a similar meaning word, “Schooling”.
具有不同含义的单词的多单词类别被组合成相似的含义单词,从而单词向量距离度量不会出错。 例如,在单词向量中发现“教育”类似于“财务”,因此被重命名为类似意思的单词“学校”。
onlineNode = find_by_attr(root, 'Online Services')
onlineNode.name = 'Online'
family = find_by_attr(root, 'Family and Relationships')
family.name = 'Family Relationships'
career = find_by_attr(root, 'Career & Job')
career.name = 'Profession'
family = find_by_attr(root, 'Real Estate')
family.name = 'Realty'
education = find_by_attr(root, 'Education')
education.name = 'Schooling'
politics = find_by_attr(root, 'News & Politics')
politics.name = 'Politics'
banking = find_by_attr(root, 'Banking & Finance')
banking.name = 'Banking'
food = find_by_attr(root, 'Food & Dining')
food.name = 'Food'
religionNode = find_by_attr(root, 'Religion & Spirituality')
religionNode.name = 'Religion'
sports = find_by_attr(root, 'Sports & Games')
sports.name = 'Sports'
for pre, _, node in RenderTree(root):
print("%s%s" % (pre, node.name))备用1:基于URL的类别树分类器 (Fallback 1: URL based Category Tree Classifier)
No single information may be enough to properly classify an article. First, we use the tree information embedded in the URL links to find the category.
没有任何单一信息可能不足以正确分类文章。 首先,我们使用嵌入在URL链接中的树信息来查找类别。
# To find out category tree based on the URL links
stop_words = set(stopwords.words('english'))
cutoff = 0.25
urlMappings = []
for id, url in zip(idURL['id'], idURL ['link']):
urlCat = url.split("/")[3:-2]
urlCat
totalSimScore = 0
category_levels = [root]
for word in urlCat:
if ('-' in word):
keywords = word.lower().split("-")
else:
keywords = [word.lower()]
filtered_words = [w for w in keywords if not w in stop_words]
for urlWords in filtered_words:
level_similarity = []
subCategories = category_levels[len(category_levels)-1].children
for i in range(len(subCategories)):
subCatWords = re.sub(r'[^A-Za-z0-9 ]+', '', subCategories[i].name).lower().split()
similarityScore = 0
for catWords in subCatWords:
if urlWords in model and catWords in model:
similarityScore += model.similarity(urlWords, catWords)
level_similarity.append(similarityScore/ len(subCatWords))
maxsim_this_level = max(level_similarity, default=0)
if (maxsim_this_level > cutoff):
category_levels.append(subCategories[np.argmax(level_similarity)])
totalSimScore += maxsim_this_level
if (len(category_levels) > 1):
confidence = float(totalSimScore/(len(category_levels)-1))
else:
confidence = 0
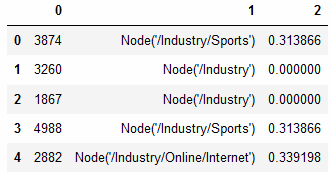
urlMappings.append([id, category_levels[len(category_levels)-1], confidence])
urlCatDetects = pd.DataFrame(urlMappings)
urlCatDetects.head(5)The above code will generate a cat-tree and confidence score corresponding to each article. Note that confidence is 0 when there is not enough info in link.
上面的代码将生成与每篇文章相对应的目录树和置信度得分。 请注意,如果链接中没有足够的信息,则置信度为0。
后备2:LDA-NMF组合模型 (Fallback 2: LDA-NMF Combination Model)
LDA is a probabilistic generative process, while NMF is a linear-algebraic method to classify documents into different topics.
LDA是一个概率生成过程,而NMF是将文档分类为不同主题的线性代数方法 。
Any document is considered to have an underlying mixture of topics associated with it. Similarly, a topic is considered to be a mixture of terms that is likely to generate. Thus, there are two sets of parameters of probability distributions that we need to compute.
任何文档都被认为具有与其相关联的主题的基础。 类似地,主题被认为是可能产生的术语的混合。 因此,我们需要计算两组概率分布参数。
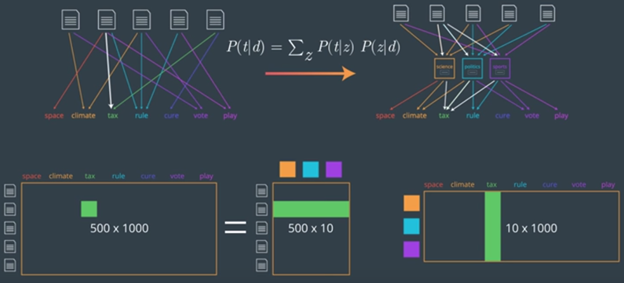
The probability of a topic z given a document d: P (z | d)
给定文档d的主题z的概率: P(z | d)
2. The probability of a term t given a topic z: P ( t | z)
2.给定主题z的条件t的概率: P(t | z)
Thus, probability of document d generate the term t,
因此, 文档d的概率生成 项t,
P (t | d) = sum of product of previous 2 probabilities for all topics.
P(t | d)=所有主题的前两个概率的乘积之和。
If 10 topics are there, then number of parameters = 500 documents x 10 topics + 10 topics x 1000 words = 15K parameters. (better than 500 *1000)
如果有10个主题,则参数数= 500个文档x 10个主题+ 10个主题x 1000个单词= 15K参数。 (大于500 * 1000)
This concept of matrix factorization is called Latent Dirichlet Allocation.
矩阵分解的概念称为潜在Dirichlet分配。
LDA starts by picking some topics for each article and some words for each topic, both of which are represented by multinomial distribution.
LDA首先为每个文章选择一些主题,为每个主题选择一些单词,这两个单词均由多项式分布表示。

The LDA model has a huge advantage that it gives us a bunch of topics also. The algorithm will just throw some topics and we may have to manually group them more meaningfully.
LDA模型具有巨大的优势,它也为我们提供了许多主题。 该算法只会抛出一些主题,我们可能必须手动对其进行更有意义的分组。
However, neither LDA nor NMF could return good results individually, being unsupervised. Hence, a numerical combination of LDA and NMF output matrices post-normalization was implemented to figure out the maximum probable topic.
但是,LDA和NMF都无法在不受监督的情况下单独返回良好的结果 。 因此,实现了LDA和NMF输出矩阵的归一化后的数值组合,以找出最大可能的主题。
After doing pre-processing, apply CountVectorizer and TF-IDF-Vectorizer on ‘article description’ to compute the document-term matrix (DTM) to be fed in to LDA and NMF respectively.
进行预处理后,将CountVectorizer和TF-IDF-Vectorizer应用于“文章描述”以计算分别输入到LDA和NMF的文档项矩阵(DTM)。
vectorizer = CountVectorizer(analyzer='word',
min_df=3, # minimum required occurences of a word
stop_words='english', # remove stop words
lowercase=True, # convert all words to lowercase
token_pattern='[a-zA-Z0-9]{3,}', # num chars > 3
max_features=5000, # max number of unique words. Build a vocabulary that only consider the top max_features ordered by term frequency across the corpus
)
data_vectorized = vectorizer.fit_transform(data['description'])
lda_model = LatentDirichletAllocation(n_components=20, # Number of topics
learning_method='online',
random_state=0,
n_jobs = -1 # Use all available CPUs
)
lda_output = lda_model.fit_transform(data_vectorized)Manually label the topics based on the top 20 words in each cluster, as below.
如下所示,根据每个群集中的前20个单词手动标记主题。
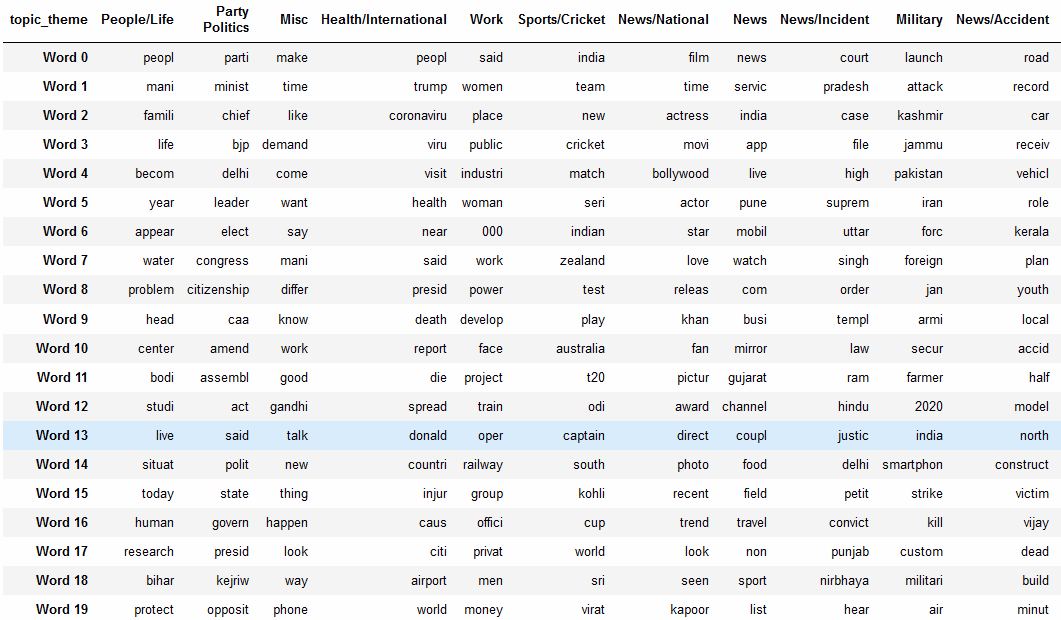
Output of LDA is a matrix of size # of articles * # of topics. Each cell contains the probability of an article belonging to a topic.
LDA的输出是文章数量*主题数量的矩阵。 每个单元格包含文章属于某个主题的概率。
We can also use NMF to decompose DTM into two matrices, like below, which is conceptually similar to LDA model, except that here we use linear algebra instead of a probabilistic model.
我们还可以使用NMF将DTM分解为两个矩阵,如下所示,这在概念上类似于LDA模型,不同之处在于,在这里我们使用线性代数而不是概率模型。
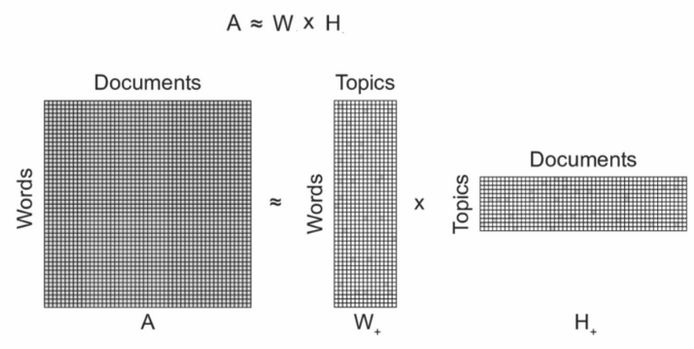
Output of NMF is also a matrix of size # of articles * # of topics and interpretation remains the same. Hence, we can combine the output matrices of LDA and NMF on y-axis to get 1 million * 40 columns. (Input = 1M rows. Topics = 20 each for LDA and NMF)
NMF的输出也是文章数量*主题和解释数量不变的矩阵。 因此,我们可以在y轴上合并LDA和NMF的输出矩阵,以获得100万* 40列。 (输入= 1M行。LDA和NMF主题=20。)
Take the argmax() of each row to find the most probable prediction out of both LDA and NMF
取每一行的argmax()从LDA和NMF中找出最可能的预测
Note: Remember to do normalization before matrix concatenation.
注意 :请记住在矩阵级联之前进行标准化。
LDA_df = pd.DataFrame(v,columns=df_topic_keywords.T.columns)
NMF_df = pd.DataFrame(d,columns=df_topic_keywords1.T.columns)
LDA_normalized = normalize(LDA_df)
NMF_normalized = normalize(NMF_df)
LDANMF = pd.concat([NMF_normalized,LDA_normalized],axis=1)
dominant_topic = np.argmax(LDANMF.values, axis=1)
LDANMF['confidence'] = LDANMF.apply (lambda row: computeConfidence(row), axis=1)
LDANMF['dominant_topic'] = dominant_topicThe combination model produces better categorization results as below.
组合模型产生更好的分类结果 ,如下所示。

The only downside is that this results in 1st level categorization and not tree hierarchy. So is the reason, I have decided to place it as 2nd Fallback.
唯一的缺点是,这会导致第一级分类,而不是树状层次结构。 因此,我决定将其放置为第二次备用。
Ideally, Hierarchical-LDA should be done and be placed as 1st Fallback after Article Classifier in the solution pipeline. Article Classifier should still be the main logic, as Hierarchical-LDA produces word clusters of random categories which may not be same as the category tree we want.
理想情况下,应完成Hierarchical-LDA,并将其作为第一个后备放置在解决方案管道中的文章分类器之后。 文章分类器仍应是主要逻辑,因为Hierarchical-LDA会产生随机类别的词簇,这些词簇可能与我们想要的类别树不同。
合并描述,URL和LDA-NMF分类器 (Merging Description, URL & LDA-NMF Classifiers)
The article description classifier and URL classifier are merged into a pipeline with LDA-NMF combination model, as cascading fallbacks based on the corresponding confidence scores.
文章描述分类器和URL分类器通过LDA-NMF组合模型合并到管道中,作为基于相应置信度得分的级联后备。
Much weightage is given to description classifier as LDA-NMF gives only the category (not category tree) and URL often doesn't contain the required info. If all 3 methods failed then mark it as “unclassified” or use outcome of article classifier, though ambiguous.
由于LDA-NMF仅给出类别(而不是类别树),因此描述分类器的权重很大,URL通常不包含必需的信息。 如果所有3种方法均失败,则将其标记为“未分类”或使用文章分类器的结果(尽管模棱两可)。
result = []
for idx in artClassifier.index:
if (artClassifier['confidence'][idx] > 0.05):
result.append([artClassifier['id'][idx], str(artClassifier['category'][idx])[6:-2].replace("/", "^")])
elif (urlClassifier['confidence'][idx] > 0.4):
result.append([urlClassifier['id'][idx], str(urlClassifier['category'][idx])[6:-2].replace("/", "^")])
else:
row = ldanmfClassifier.loc[ldanmfClassifier['id'] == artClassifier['id'][idx]]
if (len(row) == 0):
result.append([artClassifier['id'][idx], str(artClassifier['category'][idx])[6:-2].replace("/", "^")])
else:
result.append([artClassifier['id'][idx], row['category_tree'].to_string(index=False)])Disclaimer: As the above solution is coded in a 24-hour Hackathon, the code may not be perfect. It can be improved upon using the approaches noted below and also hyper-parameters in the code are required to be tuned more.
免责声明:由于上述解决方案是在24小时的Hackathon中编写的,因此代码可能并不完美。 使用下面提到的方法可以对其进行改进,并且还需要对代码中的超参数进行更多的调整。
改进之处 (Improvements)
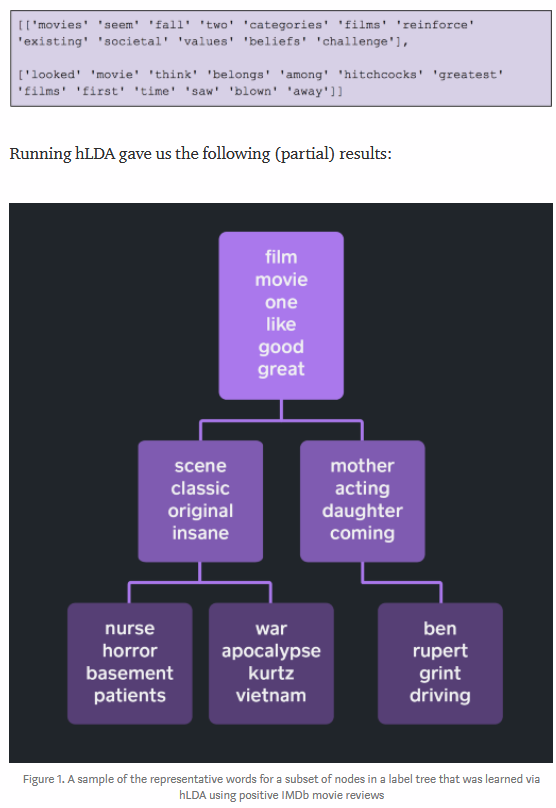
h-LDA: Hierarchical-LDA to group documents by hierarchies of topics and combine with LDA-NMF output.
h-LDA :Hierarchical-LDA,用于按主题层次结构对文档进行分组,并与LDA-NMF输出结合。
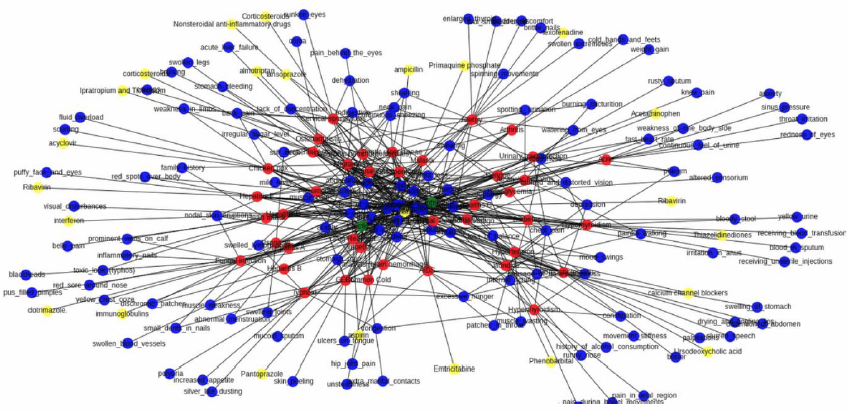
2. Knowledge Graph: Knowledge graph of article text would generate hierarchical relation of words, akin to a category tree. This information can be used to map article to category tree.
2.知识图:文章文本的知识图将生成单词的层次关系,类似于类别树。 此信息可用于将文章映射到类别树。
3. Guided LDA: We can also use Guided LDA to set some seed words for ambiguous categories, when there are not enough documents to differentiate. Seed words will guide the model to converge around those categories.
3. 引导式LDA:当没有足够的文档可区分时,我们也可以使用引导式LDA来为歧义类别设置一些种子词。 种子词将指导模型收敛于这些类别。
该解决方案的完整源代码可以在这里找到。 (The complete source code of the solution can be found here.)
If you have any query or suggestion, you can reach me here
如果您有任何疑问或建议,可以在这里与 我联系
翻译自: https://towardsdatascience.com/topic-modelling-into-a-category-tree-acafad0f0050
决策树 建模















 674
674











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









