






 本文详细介绍了神经网络中的激活函数,包括线性与非线性激活函数,如Sigmoid和ReLU,并探讨了它们的优势与不足。此外,文章讨论了优化技术,如梯度下降和Adagrad,以及针对密集和稀疏特征的适应性学习率算法。最后,作者讲解了损失函数在回归和分类任务中的应用,如均方误差、对数损失和交叉熵损失,以及它们在模型性能评估中的作用。
本文详细介绍了神经网络中的激活函数,包括线性与非线性激活函数,如Sigmoid和ReLU,并探讨了它们的优势与不足。此外,文章讨论了优化技术,如梯度下降和Adagrad,以及针对密集和稀疏特征的适应性学习率算法。最后,作者讲解了损失函数在回归和分类任务中的应用,如均方误差、对数损失和交叉熵损失,以及它们在模型性能评估中的作用。
激活功能: (Activation Functions:)
A significant piece of a neural system Activation function is numerical conditions that decide the yield of a neural system. The capacity is joined to every neuron in the system and decides if it ought to be initiated (“fired”) or not, founded on whether every neuron’s info is applicable for the model’s expectation. Initiation works likewise help standardize the yield of every neuron to a range somewhere in the range of 1 and 0 or between — 1 and 1.
神经系统的重要部分激活函数是决定神经系统产量的数值条件。 该能力与系统中的每个神经元相连,并根据每个神经元的信息是否适用于模型的期望来决定是否应该启动(“发射”)该能力。 初始化工作同样有助于将每个神经元的产量标准化到介于1到0或介于1到1的范围内。
Progressively, neural systems use linear and non-linear activation functions, which can enable the system to learn complex information, figure and adapt practically any capacity speaking to an inquiry, and give precise forecasts.
神经系统逐渐地使用线性和非线性激活函数,这可以使系统学习复杂的信息,计算和适应几乎所有与查询相关的能力,并给出精确的预测。
线性激活功能: (Linear Activation Functions:)
Step-Up: Activation functions are dynamic units of neural systems. They figure the net yield of a neural node. In this, Heaviside step work is one of the most widely recognized initiation work in neural systems. The capacity produces paired yield. That is the motivation behind why it is additionally called paired advanced capacity.
升压:激活函数是神经系统的动态单位。 他们计算出神经节点的净产量。 在这种情况下,Heaviside步骤工作是神经系统中最广泛认可的启动工作之一。 容量产生成对的产量。 这就是为什么将其另外称为成对高级容量的原因。
The capacity produces 1 (or valid) when info passes edge limit though it produces 0 (or bogus) when information doesn’t pass edge. That is the reason, they are extremely valuable for paired order studies. Every rationale capacity can be actualized by neural systems. In this way, step work is usually utilized in crude neural systems without concealed layer or generally referred to name as single-layer perceptions.
当信息通过边缘限制时,容量将生成1(或有效),但当信息未通过边缘时,容量将生成0(或虚假)。 这就是原因,它们对于配对订单研究非常有价值。 神经系统可以实现每个基本能力。 这样,通常在没有隐藏层的粗神经系统中使用步进工作,或通常将其称为单层感知。
- The simplest kind of activation function 最简单的激活功能
- consider a threshold value and if the value of net input say x is greater than the threshold then the neuron is activated 考虑一个阈值,如果净输入值x大于阈值,则激活神经元
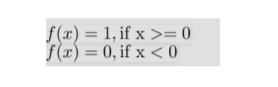
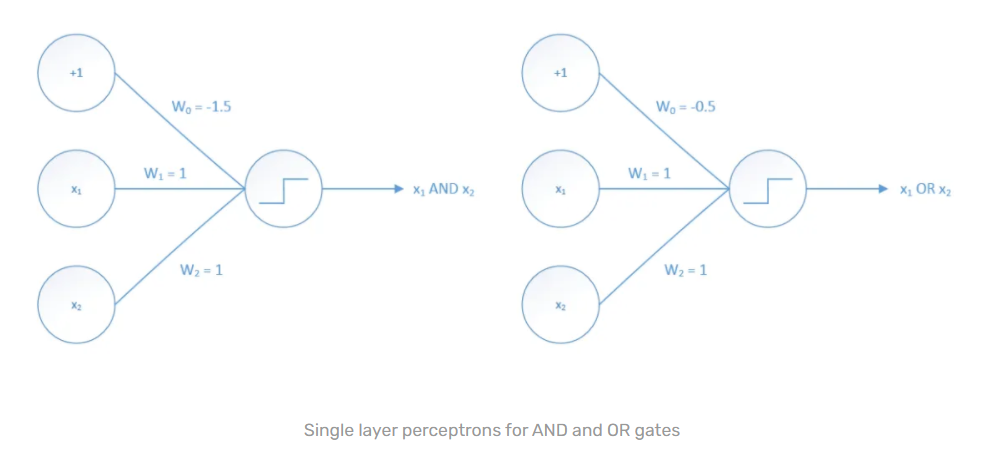
This kind of system can group straightly distinguishable issues, for example, AND-GATE and OR-GATE. As it were, all classes (0 and 1) can be isolated by a solitary straight line as outlined underneathAssume that we got edge an incentive as 0. After that point, the accompanying single layer neural system models will fulfill these rationale capacities.
这种系统可以将可直接区分的问题分组,例如AND-GATE和OR-GATE。 照原样,所有类别(0和1)都可以通过一条孤立的直线来隔离,如下所述。假定我们将边激励设为0。此后,随附的单层神经系统模型将满足这些基本要求。
However, a linear activation function has two major problems:
但是,线性激活函数有两个主要问题:
Unrealistic to utilize backpropagation (slope plunge) to prepare the model — the subordinate of the capacity is consistent, and has no connection to the info, X. So it’s impractical to return and comprehend which loads in the information neurons can give a superior expectation.
利用反向传播 (斜率下降)来准备模型是不现实的-容量的下属是一致的,并且与信息X没有关系。因此,返回和理解信息神经元中的哪些负载可以给出更高的期望是不切实际的。
All layers of the neural network collapse into one with linear activation functions, no matter how many layers in the neural network, the last layer will be a linear function of the first layer (because a linear combination of linear functions is still a linear function). So a linear activation function turns the neural network into just one layer.
神经网络的所有层都折叠成具有线性激活函数的层,无论神经网络中有多少层,最后一层将是第一层的线性函数(因为线性函数的线性组合仍然是线性函数) 。 因此,线性激活函数将神经网络变成仅一层。
非线性激活功能: (Non-Linear Activation Functions:)
Present-day neural system models use non-straight activation capacities. They permit the model to make complex mappings between the system’s sources of info and yields, which are basic for learning and demonstrating complex information, for example, pictures, video, sound, and informational indexes which are non-straight or have high dimensionality.
当今的神经系统模型使用非直线激活能力。 它们允许模型在系统的信息源和收益之间进行复杂的映射,这对于学习和演示复杂的信息(例如图片,视频,声音和非直线或具有高维的信息索引)是基本的。
Practically any procedure conceivable can be spoken to as a useful calculation in a neural system, given that the initiation work is non-straight. Non-straight capacities address the issues of a direct enactment work: They permit backpropagation since they have a subordinate capacity which is identified with the information sources. They permit the “stacking” of various layers of neurons to make a profound neural system.
考虑到启动工作是非直线的,实际上任何可以想到的过程都可以说成是神经系统中的有用计算。 非直接能力解决了直接制定工作的问题:它们允许反向传播,因为它们具有从信息源中识别出的从属能力。 它们允许“堆叠”神经元的各个层以构成一个深奥的神经系统。
Different shrouded layers of neurons are expected to learn complex informational indexes with significant levels of exactness. Thus, types of non-linear activation functions are:
期望神经元的不同覆盖层学习具有显着水平的准确性的复杂信息索引。 因此,非线性激活函数的类型为:
SIGMOID:
SIGMOID:
The fundamental motivation behind why we utilize the sigmoid capacity is that it exists between (0 to 1). In this manner, it is particularly utilized for models where we need to foresee the likelihood as a yield. Since the likelihood of anything exists just between the scope of 0 and 1, sigmoid is the correct decision.
我们为什么使用S形容量的根本动机是它存在于(0到1)之间。 以这种方式,它特别适用于需要预测可能性为收益的模型。 由于任何事情的可能性都介于0和1的范围之间,因此S型是正确的决定。
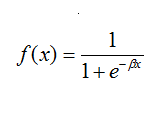
Advantages:
优点:
- Smooth slope, forestalling “bounces” in yield esteems. 平滑的坡度,阻止屈服感的“反弹”。
- Output values bound somewhere in the range of 0 and 1, normalizing the yield of every neuron. 输出值的范围在0到1之间,使每个神经元的产量正常化。
- Clear forecasts — For X over 2 or beneath — 2, will in general bring the Y esteem (the expectation) to the edge of the bend, exceptionally near 1 or 0. This empowers clear expectations. 明确的预测-对于大于2或小于2的X,通常会将Y估计(期望)带到弯道的边缘,特别是接近1或0。这将带来明确的期望。
Disadvantages:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1100
1100

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









